Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
In diesem Artikel werden die grundlegenden Schritte zum Laden und Analysieren von Daten mit Data Explorer für Azure Synapse beschrieben.
Erstellen eines Data Explorer-Pools
Wählen Sie in Synapse Studio im linken Bereich die Option Verwalten>Data Explorer-Pools aus.
Wählen Sie Neu, und geben Sie auf der Registerkarte Grundlagen die folgenden Informationen ein:
Einstellung Vorgeschlagener Wert Beschreibung Name des Data Explorer-Pools contosodataexplorer Dies ist der Name des Data Explorer-Pools. Workload Computeoptimiert Diese Workload bietet ein höheres CPU-zu-SSD-Speicherverhältnis. Knotengröße Klein (4 Kerne) Legen Sie diese Einstellung auf die kleinste Größe fest, um die Kosten für diesen Schnellstart zu senken. Wichtig
Beachten Sie, dass für die Namen, die für Data Explorer-Pools verwendet werden können, bestimmte Einschränkungen gelten. Namen dürfen nur aus Kleinbuchstaben und Zahlen bestehen, müssen 4 bis 15 Zeichen lang sein und mit einem Buchstaben beginnen.
Wählen Sie Bewerten + erstellen>Erstellen aus. Ihr Data Explorer-Pool startet den Bereitstellungsprozess.
Erstellen einer Data Explorer-Datenbank
Wählen Sie in Synapse Studio im linken Bereich Daten aus.
Wählen Sie + (Neue Ressource hinzufügen) >Data Explorer-Datenbank aus, und fügen Sie die folgenden Informationen ein:
Einstellung Vorgeschlagener Wert BESCHREIBUNG Poolname contosodataexplorer Name des zu verwendende Data Explorer-Pools Name TestDatabase Der Datenbankname muss innerhalb des Clusters eindeutig sein. Standardaufbewahrungszeitraum 365 Die Zeitspanne (in Tagen), für die garantiert wird, dass die Daten für Abfragen verfügbar bleiben. Die Zeitspanne wird ab dem Zeitpunkt gemessen, zu dem die Daten erfasst werden. Standardcachezeitraum 31 Die Zeitspanne (in Tagen), wie lange häufig abgefragte Daten im SSD-Speicher oder RAM (und nicht im längerfristigen Speicher) verfügbar bleiben. Wählen Sie Erstellen, um die Datenbank zu erstellen. Die Erstellung dauert in der Regel weniger als eine Minute.
Erfassen von Beispieldaten und Analyse mit einer einfachen Abfrage
Wählen Sie nach dem Bereitstellen des Pools in Synapse Studio im linken Bereich Entwickeln aus.
Wählen Sie die Option + (Neue Ressource hinzufügen) >KQL-Skript aus. Im rechten Bereich können Sie Ihr Skript benennen.
Wählen Sie im Menü Verbinden mit den Eintrag contosodataexplorer aus.
Wählen Sie im Menü Datenbank verwenden die Option TestDatabase aus.
Fügen Sie den folgenden Befehl ein, und wählen Sie Ausführen aus, um eine StormEvents-Tabelle zu erstellen.
.create table StormEvents (StartTime: datetime, EndTime: datetime, EpisodeId: int, EventId: int, State: string, EventType: string, InjuriesDirect: int, InjuriesIndirect: int, DeathsDirect: int, DeathsIndirect: int, DamageProperty: int, DamageCrops: int, Source: string, BeginLocation: string, EndLocation: string, BeginLat: real, BeginLon: real, EndLat: real, EndLon: real, EpisodeNarrative: string, EventNarrative: string, StormSummary: dynamic)Tipp
Vergewissern Sie sich, dass die Tabelle erstellt wurde. Wählen Sie im linken Bereich Daten, dann das Menü mit weiteren Optionen für contosodataexplorer und anschließend Aktualisieren aus. Erweitern Sie unter contosodataexplorer den Knoten Tabellen, und stellen Sie sicher, dass die Tabelle StormEvents in der Liste angezeigt wird.
Fügen Sie den folgenden Befehl ein, und wählen Sie Ausführen aus, um Daten in einer StormEvents-Tabelle zu erfassen.
.ingest into table StormEvents 'https://kustosamples.blob.core.windows.net/samplefiles/StormEvents.csv' with (ignoreFirstRecord=true)Fügen Sie nach Abschluss der Erfassung die folgende Abfrage ein, wählen Sie im Fenster die Abfrage aus, und wählen Sie dann Ausführen aus.
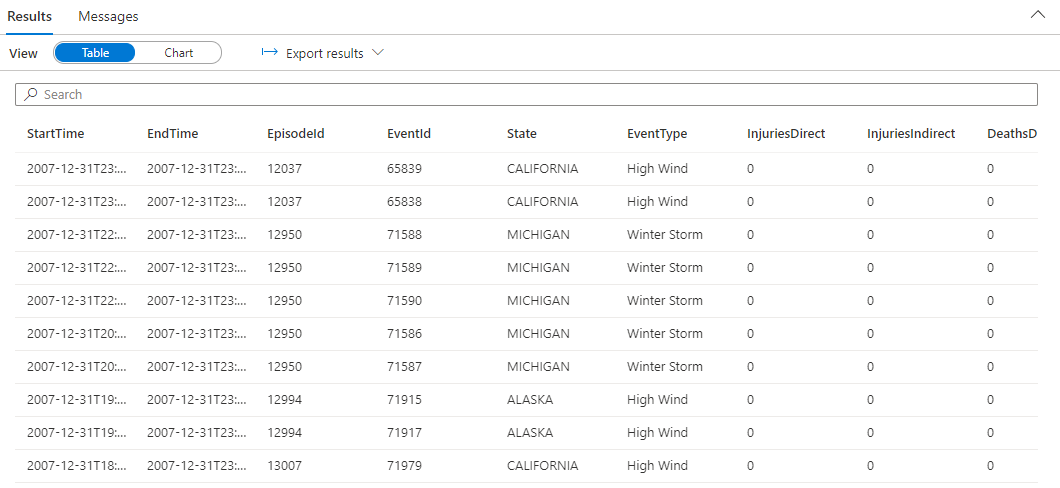
StormEvents | sort by StartTime desc | take 10Die Abfrage gibt die folgenden Ergebnisse aus den erfassten Beispieldaten zurück.