Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
Azure Vision in Foundry Tools ist ein Microsoft Foundry-Tool , mit dem Sie Bilder verarbeiten und Informationen basierend auf den visuellen Features zurückgeben können. In diesem Lernprogramm erfahren Sie, wie Sie Vision verwenden, um Bilder in Azure Synapse Analytics zu analysieren.
Dieses Tutorial veranschaulicht die Verwendung der Textanalyse mit SynapseML für Folgendes:
- Extrahieren visueller Merkmale aus dem Bildinhalt
- Erkennen von Zeichen in Bildern (optische Zeichenerkennung)
- Analysieren von Bildinhalten und Generieren von Miniaturansichten
- Erkennen und Identifizieren domänenspezifischer Inhalte in einem Bild
- Generieren von Tags im Zusammenhang mit einem Bild
- Generieren einer Beschreibung eines ganzen Bilds in von Menschen lesbarer Sprache
Bild analysieren
Extrahiert eine große Menge visueller Merkmale basierend auf dem Bildinhalt, wie Objekte, Gesichter, explizite Inhalte und automatisch generierte Textbeschreibungen.
Beispieleingabe

# Create a dataframe with the image URLs
df = spark.createDataFrame([
("<replace with your file path>/dog.jpg", )
], ["image", ])
# Run the Vision service. Analyze Image extracts information from/about the images.
analysis = (AnalyzeImage()
.setLinkedService(ai_service_name)
.setVisualFeatures(["Categories","Color","Description","Faces","Objects","Tags"])
.setOutputCol("analysis_results")
.setImageUrlCol("image")
.setErrorCol("error"))
# Show the results of what you wanted to pull out of the images.
display(analysis.transform(df).select("image", "analysis_results.description.tags"))
Erwartete Ergebnisse
["dog","outdoor","fence","wooden","small","brown","building","sitting","front","bench","standing","table","walking","board","beach","holding","bridge"]
Optische Zeichenerkennung (Optical Character Recognition, OCR)
Dieser Vorgang extrahiert gedruckten und handschriftlichen Text, Ziffern und Währungssymbole aus Bildern, z. B. Fotos von Straßenschildern und Produkten, sowie aus Dokumenten wie u. a. Rechnungen, Finanzberichten und Artikeln. Die API ist für das Extrahieren von Text aus textlastigen Bildern und mehrseitigen PDF-Dokumenten mit gemischten Sprachen optimiert. Sie unterstützt sowohl die Erkennung von gedrucktem als auch von handschriftlichem Text im selben Bild oder Dokument.
Beispieleingabe

df = spark.createDataFrame([
("<replace with your file path>/ocr.jpg", )
], ["url", ])
ri = (ReadImage()
.setLinkedService(ai_service_name)
.setImageUrlCol("url")
.setOutputCol("ocr"))
display(ri.transform(df))
Erwartete Ergebnisse
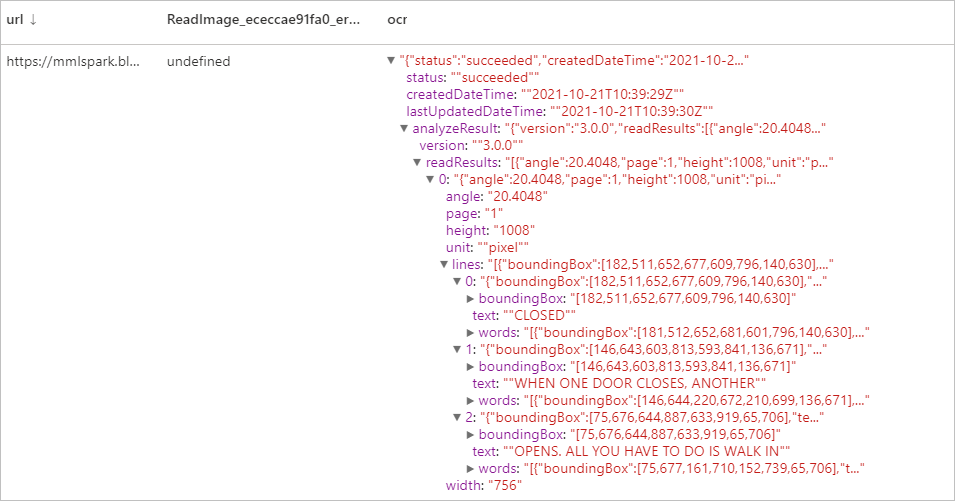
Miniaturansichten generieren
Analysieren Sie den Inhalt eines Bilds, um eine geeignete Miniaturansicht für das Bild zu generieren. Der Vision-Dienst generiert zunächst eine hochwertige Miniaturansicht und analysiert dann die Objekte im Bild, um den relevanten Bereich zu bestimmen. Anschließend schneidet Vision das Bild auf den relevanten Bereich zu. Das Seitenverhältnis der generierten Miniaturansicht kann sich bei Bedarf vom Seitenverhältnis des ursprünglichen Bilds unterscheiden.
Beispieleingabe

df = spark.createDataFrame([
("<replace with your file path>/satya.jpeg", )
], ["url", ])
gt = (GenerateThumbnails()
.setLinkedService(ai_service_name)
.setHeight(50)
.setWidth(50)
.setSmartCropping(True)
.setImageUrlCol("url")
.setOutputCol("thumbnails"))
thumbnails = gt.transform(df).select("thumbnails").toJSON().first()
import json
img = json.loads(thumbnails)["thumbnails"]
displayHTML("<img src='data:image/jpeg;base64," + img + "'>")
Erwartete Ergebnisse

Bild markieren
Dieser Vorgang generiert eine Liste von Wörtern bzw. Tags, die für den Inhalt des angegebenen Bilds relevant sind. Tags werden auf Grundlage von Tausenden erkennbarer Objekte, Lebewesen, Landschaften oder Handlungen in Bildern zurückgegeben. Tags können Hinweise enthalten, um Mehrdeutigkeiten zu vermeiden oder Kontext bereitzustellen. Das Tag „Ascomycet“ kann beispielsweise vom Hinweis „Pilz“ begleitet werden.
Lassen Sie uns weiterhin das Bild von Satya als Beispiel verwenden.
df = spark.createDataFrame([
("<replace with your file path>/satya.jpeg", )
], ["url", ])
ti = (TagImage()
.setLinkedService(ai_service_name)
.setImageUrlCol("url")
.setOutputCol("tags"))
display(ti.transform(df))
Erwartetes Ergebnis
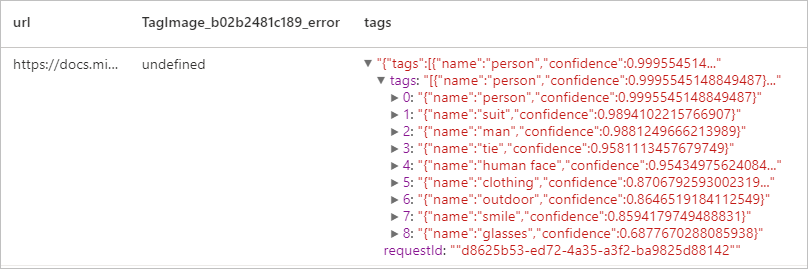
Bild beschreiben
Generieren Sie eine Beschreibung eines gesamten Bilds mit vollständigen Sätzen in lesbarer Sprache. Die Algorithmen des Vision-Diensts generieren verschiedene Beschreibungen auf Grundlage der im Bild erkannten Objekte. Die Beschreibungen werden jeweils ausgewertet, und eine Zuverlässigkeitsbewertung wird generiert. Dann wird eine Liste in der Reihenfolge von höchster Zuverlässigkeitsbewertung zu niedrigster zurückgegeben.
Lassen Sie uns weiterhin das Bild von Satya als Beispiel verwenden.
df = spark.createDataFrame([
("<replace with your file path>/satya.jpeg", )
], ["url", ])
di = (DescribeImage()
.setLinkedService(ai_service_name)
.setMaxCandidates(3)
.setImageUrlCol("url")
.setOutputCol("descriptions"))
display(di.transform(df))
Erwartetes Ergebnis
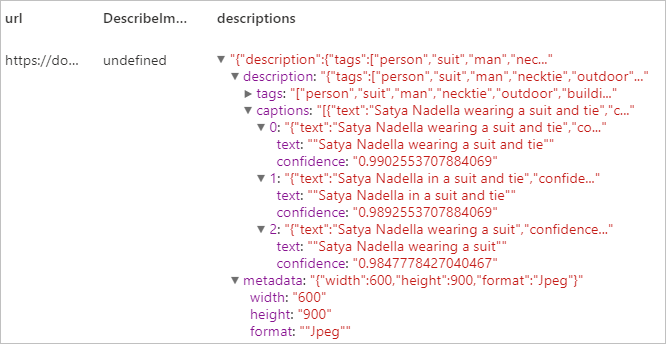
Domänenspezifische Inhalte erkennen
Verwenden Sie Domänenmodelle, um domänenspezifische Inhalte (etwa berühmte Personen und Orientierungspunkte) in einem Bild zu erkennen. Wenn ein Bild also beispielsweise Personen enthält, kann Vision auf ein Domänenmodell für berühmte Personen zurückgreifen und so ermitteln, ob es sich bei den Personen auf dem Bild um berühmte Personen handelt.
Lassen Sie uns weiterhin das Bild von Satya als Beispiel verwenden.
df = spark.createDataFrame([
("<replace with your file path>/satya.jpeg", )
], ["url", ])
celeb = (RecognizeDomainSpecificContent()
.setLinkedService(ai_service_name)
.setModel("celebrities")
.setImageUrlCol("url")
.setOutputCol("celebs"))
display(celeb.transform(df))
Erwartetes Ergebnis
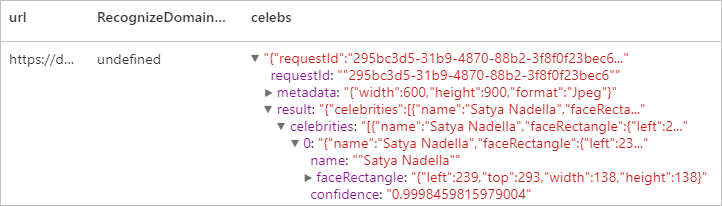
Bereinigen von Ressourcen
Beenden Sie alle verbundenen Sitzungen (Notebooks), um sicherzustellen, dass die Spark-Instanz heruntergefahren wird. Der Pool wird heruntergefahren, wenn die im Apache Spark-Pool angegebene Leerlaufzeit erreicht wird. Sie können auch auf der Statusleiste am oberen Rand des Notebooks die Option Sitzung beenden auswählen.
