Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
Bei diesem Artikel handelt es sich um Teil 1 einer siebenteiligen Reihe, die Anleitungen zum Migrieren von Teradata zu Azure Synapse Analytics bereitstellt. Der Schwerpunkt dieses Artikels liegt auf bewährten Methoden für Entwurf und Leistung.
Übersicht
Viele Bestandsbenutzer von Data Warehouse-Systemen von Teradata möchten von den Innovationen profitieren, die moderne Cloudumgebungen bieten. Cloudumgebungen vom Typ Infrastructure-as-a-Service (IaaS) und Platform-as-a-Service (PaaS) ermöglichen Ihnen das Delegieren von Aufgaben wie Infrastrukturwartung und Plattformentwicklung an den Cloudanbieter.
Tipp
Mehr als nur eine Datenbank – die Azure-Umgebung beinhaltet eine umfassende Reihe von Funktionen und Tools.
Auch wenn es sich bei Teradata und Azure Synapse Analytics um SQL-Datenbanken handelt, die Techniken der Massenparallelverarbeitung (Massively Parallel Processing, MPP) verwenden, um eine hohe Abfrageleistung bei außergewöhnlich großen Datenvolumen zu erzielen, gibt es beim Ansatz einige grundlegende Unterschiede:
Teradata-Legacysysteme sind häufig lokal installiert und verwenden proprietäre Hardware, während Azure Synapse cloudbasiert ist und Azure Storage- und Computeressourcen nutzt.
Da Speicher- und Computeressourcen in der Azure-Umgebung voneinander getrennt sind und über die Funktion der elastischen Skalierung verfügen, können diese Ressourcen unabhängig hoch- oder herunterskaliert werden.
Sie können Azure Synapse nach Bedarf anhalten oder die Größe der Instanz ändern, um die Ressourcennutzung und die Kosten zu reduzieren.
Ein Upgrade einer Teradata-Konfiguration stellt eine umfangreiche Aufgabe dar, die zusätzliche physische Hardware und eine potenziell langwierige Neukonfiguration oder das erneute Laden der Datenbank umfasst.
Microsoft Azure ist eine weltweit verfügbare, äußerst sichere und skalierbare Cloudumgebung, die Azure Synapse und ein Ökosystem aus unterstützenden Tools und Möglichkeiten umfasst. Das nächste Diagramm fasst das Azure Synapse-Ökosystem zusammen.
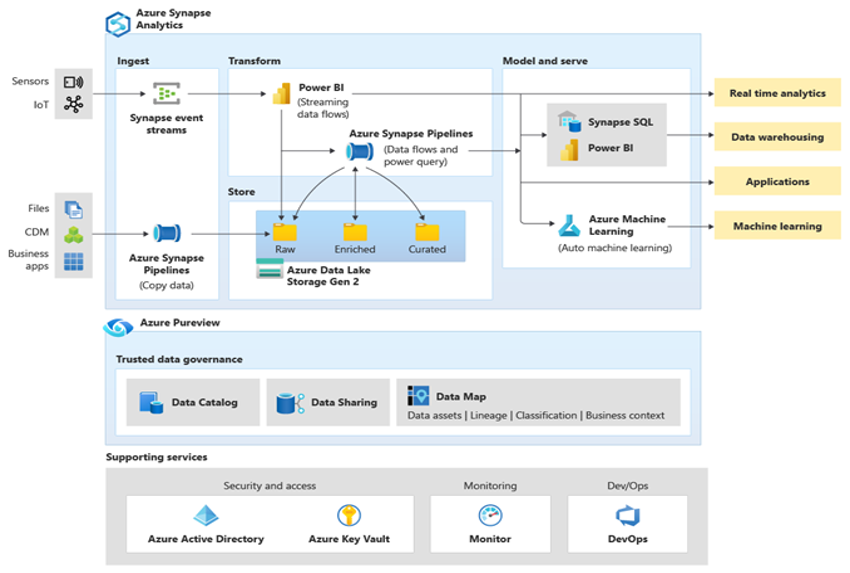
Azure Synapse bietet eine optimale Leistung für relationale Datenbanken, wobei Techniken wie MPP und mehrere Ebenen der automatisierten Zwischenspeicherung für häufig verwendete Daten genutzt werden. Die Ergebnisse dieser Techniken können Sie in unabhängigen Benchmarks einsehen, beispielsweise in dem kürzlich von GigaOm durchgeführten Benchmark, in dem Azure Synapse mit anderen gängigen cloudbasierten Data Warehouse-Angeboten verglichen wurde. Kunden, die zur Azure Synapse-Umgebung migrieren, profitieren von vielen Vorteilen, darunter:
Verbesserte Leistung und besseres Preis-Leistungs-Verhältnis
Höhere Flexibilität und schnellere Amortisierung
Schnellere Serverbereitstellung und Anwendungsentwicklung
Elastische Skalierbarkeit – nur für die tatsächliche Nutzung bezahlen
Verbesserte Sicherheit/Konformität
Niedrigere Kosten für Speicherung und Notfallwiederherstellung
Niedrigere Gesamtkosten, bessere Kostensteuerung und optimierte Betriebsausgaben (OPEX).
Migrieren Sie neue oder bereits vorhandene Daten und Anwendungen zur Azure Synapse-Plattform, um bestmöglich von diesen Vorteilen profitieren zu können. In vielen Organisationen umfasst die Migration das Verschieben eines bestehenden Data Warehouse von einer lokalen Legacyplattform wie Teradata in Azure Synapse. Allgemein umfasst der Migrationsprozess die folgenden Schritte:
Vorbereitung 🡆
Definieren von den Umfang – was migriert werden soll.
Erstellen einer Bestandsaufnahme der Daten und Prozesse für die Migration
Definieren von Datenmodelländerungen (falls erforderlich)
Definieren des Mechanismus zum Extrahieren von Quelldaten
Identifizieren der geeigneten Tools und Features von Azure und Drittanbietern, die verwendet werden sollen
Frühzeitige Schulung von Mitarbeitern für die neue Plattform
Einrichten der Azure-Zielplattform
Migration 🡆
Einfaches Beginnen im kleinen Umfang
Nehmen Sie wann immer möglich eine Automatisierung vor.
Nutzen der integrierten Azure-Tools und -Features zum Verringern des Migrationsaufwands
Migrieren von Metadaten für Tabellen und Sichten
Migrieren von Verlaufsdaten, die beibehalten werden sollen
Migrieren oder Umgestalten von gespeicherten Prozeduren und Geschäftsprozessen
Migrieren oder Umgestalten von ETL/ELT-Prozessen für inkrementelles Laden
Aufgaben nach der Migration
Überwachen und Dokumentieren aller Phasen des Prozesses
Nutzen der gewonnenen Erfahrungen zum Erstellen einer Vorlage für zukünftige Migrationen
Umgestalten des Datenmodells anhand der Leistung und Skalierbarkeit der neuen Plattform (falls erforderlich)
Testen von Anwendungen und Abfragetools
Erstellen von Benchmarks für die Abfrageleistung und Optimieren derselben
Dieser Artikel enthält allgemeine Informationen und Richtlinien zur Leistungsoptimierung beim Migrieren eines Data Warehouse aus einer vorhandenen Teradata-Umgebung zu Azure Synapse. Das Ziel der Leistungsoptimierung besteht darin, nach der Schemamigration die gleiche oder eine bessere Data Warehouse-Leistung in Azure Synapse zu erzielen.
Überlegungen zum Entwurf
Migrationsumfang
Berücksichtigen Sie beim Vorbereiten der Migration aus einer Teradata-Umgebung die folgenden Migrationsoptionen.
Auswählen der Workload für die erste Migration
In der Regel wurden Teradata-Legacyumgebungen im Laufe der Zeit auf mehrere Themenbereiche und gemischte Workloads ausgeweitet. Wählen Sie bei der Entscheidung, wo das Migrationsprojekt ansetzen soll, einen Bereich aus, der Ihnen die folgenden Möglichkeiten bietet:
Belegen der Machbarkeit einer Migration zu Azure Synapse durch schnelles Bereitstellen der Vorteile der neuen Umgebung.
Ermöglichen, dass Ihre internen technischen Mitarbeiter relevante Erfahrungen mit den Prozessen und Tools sammeln können, die sie beim Migrieren anderer Bereiche verwenden.
Erstellen einer Vorlage für weitere Migrationen, die speziell auf die Teradata-Quellumgebung und die bereits vorhandenen aktuellen Tools und Prozesse zugeschnitten ist.
Ein guter Kandidat für eine erste Migration aus einer Teradata-Umgebung unterstützt die oben genannten Punkte und erfüllt Folgendes:
Implementieren einer BI-/Analyseworkload statt einer Workload der Onlinetransaktionsverarbeitung (Online Transaction Processing, OLTP).
Ein Datenmodell, z. B. ein Stern- oder Schneeflockenschema, das mit minimalen Änderungen migriert werden kann.
Tipp
Erstellen Sie eine Bestandsaufnahme der zu migrierenden Objekte, und dokumentieren Sie den Migrationsprozess.
Das Volumen der migrierten Daten in der ersten Migration sollte groß genug sein, um die Möglichkeiten und Vorteile der Azure Synapse-Umgebung aufzuzeigen, aber nicht zu groß, damit der Nutzen schnell veranschaulicht werden kann. In der Regel liegt die Größe im Bereich von 1 bis 10 TB.
Minimieren Sie bei Ihrem ersten Migrationsprojekt die Risiken, den Aufwand und die Migrationsdauer, damit Sie die Vorteile der Azure-Cloudumgebung schnell erkennen können, und beschränken Sie den Umfang der Migration nur auf die Data Marts, z. B. den OLAP DB-Teil eines Teradata-Warehouse. Sowohl der Lift & Shift- als auch der phasenorientierte Migrationsansatz beschränken den Umfang der ersten Migration auf die Data Marts und berücksichtigen keine umfassenderen Migrationsaspekte wie die ETL-Migration und die Migration von Verlaufsdaten. Sie können diese Aspekte jedoch in späteren Phasen des Projekts berücksichtigen, sobald die migrierte Data Mart-Schicht wieder mit Daten und den erforderlichen Erstellungsprozessen gefüllt ist.
Migration per Lift & Shift im Vergleich zu einem phasenorientierten Ansatz
Unabhängig vom Zweck und Umfang der geplanten Migration gibt es im Allgemeinen zwei Typen von Migration: eine unveränderte Migration per Lift & Shift und einen phasenorientierten Ansatz, der Änderungen einbindet.
Lift & Shift
Bei einer Migration per Lift & Shift wird das vorhandene Datenmodell (z. B. ein Sternschema) unverändert zur neuen Azure Synapse-Plattform migriert. Dieser Ansatz minimiert die Risiken und die Migrationsdauer, indem der Aufwand reduziert wird, der erforderlich ist, um die Vorteile der Umstellung auf die Azure-Cloudumgebung nutzen zu können. Die Migration per Lift & Shift eignet sich gut für die folgenden Szenarien:
- Sie verfügen über eine bestehende Teradata-Umgebung mit einem einzigen zu migrierenden Data Mart, oder
- Sie verfügen über eine bestehende Teradata-Umgebung mit Daten, die bereits in einem optimal entworfenen Stern- oder Schneeflockenschema vorliegen, oder
- Sie stehen bei der Umstellung auf eine moderne Cloudumgebung unter Zeit- und Kostendruck.
Tipp
Die Migration per Lift & Shift ist ein guter Ausgangspunkt, auch wenn in nachfolgenden Phasen Änderungen am Datenmodell implementiert werden.
Phasenorientierter Ansatz unter Einbindung von Änderungen
Wenn ein Legacy-Data Warehouse über einen längeren Zeitraum weiterentwickelt wurde, müssen Sie es möglicherweise umstrukturieren, um die erforderlichen Leistungsstufen beibehalten zu können. Möglicherweise müssen Sie auch umstrukturieren, um neue Daten wie Internet of Things (IoT)-Streams zu unterstützen. Migrieren Sie im Rahmen des Umstrukturierungsprozesses zu Azure Synapse, um die Vorteile einer skalierbaren Cloudumgebung nutzen zu können. Die Migration kann auch eine Änderung des zugrunde liegenden Datenmodells umfassen, z. B. eine Umstellung von einem Inmon-Modell zu einem Datentresor.
Microsoft empfiehlt, Ihr vorhandenes Datenmodell unverändert in Azure (optional kann eine VM-Teradata-Instanz in Azure verwendet werden) zu verschieben und die Leistung und Flexibilität der Azure-Umgebung zu nutzen, um die Reengineering-Änderungen anzuwenden. Auf diese Weise können Sie die Funktionen von Azure nutzen, um die Änderungen vorzunehmen, ohne das vorhandene Quellsystem zu beeinträchtigen.
Verwenden einer Teradata-Instanz auf einer Azure-VM als Teil einer Migration
Bei der Migration aus einer lokalen Teradata-Umgebung können Sie Cloudspeicher und elastische Skalierbarkeit in Azure nutzen, um eine Teradata-Instanz auf einer VM zu erstellen. Bei diesem Ansatz wird die Teradata-Instanz mit der Azure Synapse-Zielumgebung verknüpft. Sie können Teradata-Standardhilfsprogramme wie Teradata Parallel Data Transporter verwenden, um die Teilmenge der zu migrierenden Teradata-Tabellen effizient auf die VM-Instanz zu verschieben. Anschließend können alle weiteren Migrationsaufgaben in der Azure-Umgebung ausgeführt werden. Dieser Ansatz hat mehrere Vorteile:
Nach der ersten Replikation von Daten wird das Quellsystem nicht durch die Migrationsaufgaben beeinträchtigt.
Die vertrauten Schnittstellen, Tools und Hilfsprogramme von Teradata sind in der Azure-Umgebung verfügbar.
Die Azure-Umgebung umgeht alle potenziellen Probleme mit der Verfügbarkeit der Netzwerkbandbreite zwischen dem lokalen Quellsystem und dem Zielsystem in der Cloud.
Tools wie Azure Data Factory können Hilfsprogramme wie Teradata Parallel Transporter aufrufen, um Daten effizient und schnell zu migrieren.
Sie können den Migrationsprozess vollständig in der Azure-Umgebung orchestrieren und steuern.
Tipp
Erstellen Sie auf Azure-VMs eine temporäre Teradata-Instanz, um die Migration zu beschleunigen und die Auswirkungen auf das Quellsystem zu minimieren.
Verwenden von Azure Data Factory zum Implementieren einer metadatengesteuerten Migration
Sie können den Migrationsprozess mithilfe der Funktionen der Azure-Umgebung automatisieren und orchestrieren. Bei diesem Ansatz werden die Leistungseinbußen in der vorhandenen Teradata-Umgebung, deren Kapazität möglicherweise bereits nahezu ausgeschöpft ist, minimiert.
Azure Data Factory ist ein cloudbasierter Datenintegrationsdienst, der das Erstellen datengesteuerter Workflows in der Cloud unterstützt, die Datenverschiebungen und Datentransformationen orchestrieren und automatisieren. Mit Data Factory können Sie datengesteuerte Workflows (Pipelines) erstellen und planen, die Daten aus unterschiedlichen Datenspeichern erfassen. Data Factory kann Daten mithilfe von Computediensten wie Azure HDInsight Hadoop, Spark, Azure Data Lake Analytics und Azure Machine Learning verarbeiten und transformieren.
Wenn Sie die Möglichkeiten von Data Factory zum Verwalten des Migrationsprozesses nutzen möchten, erstellen Sie Metadaten, die alle zu migrierenden Datentabellen und deren Speicherort auflisten.
Entwurfsunterschiede zwischen Teradata und Azure Synapse
Wie bereits erwähnt, gibt es zwischen Teradata- und Azure Synapse Analytics-Datenbanken einige grundlegende Unterschiede bei der Vorgehensweise, die im Folgenden erörtert werden.
Mehrere Datenbanken im Vergleich zu einem Singleton und Schemas
In der Teradata-Umgebung sind häufig mehrere separate Datenbanken vorhanden. Beispielsweise könnten separate Datenbanken für Datenerfassungs- und Stagingtabellen, für zentrale Warehousetabellen und für Data Marts (manchmal auch als semantische Ebene bezeichnet) vorhanden sein. Bei ETL- oder ELT-Pipelineprozessen werden möglicherweise datenbankübergreifende Joins implementiert und Daten zwischen den separaten Datenbanken verschoben.
Im Gegensatz dazu enthält die Azure Synapse-Umgebung eine einzige Datenbank, und die Tabellen werden mithilfe von Schemas in logisch getrennte Gruppen unterteilt. Wir empfehlen Ihnen, eine Reihe von Schemas in der Azure Synapse-Zieldatenbank zu verwenden, um die aus der Teradata-Umgebung migrierten einzelnen Datenbanken zu imitieren. Wenn in der Teradata-Umgebung bereits Schemas verwendet werden, müssen Sie möglicherweise die Namenskonvention ändern, wenn Sie die vorhandenen Teradata-Tabellen und -Sichten in die neue Umgebung verschieben. Sie könnten beispielsweise die vorhandenen Teradata-Schema- und -Tabellennamen mit dem neuen Azure Synapse-Tabellennamen verketten und mithilfe der Schemanamen die Namen der ursprünglichen separaten Datenbanken in der neuen Umgebung beibehalten. Wenn die Benennung der Schemakonsolidierung Punkte aufweist, können in Azure Synapse Spark Probleme auftreten. Sie können zwar SQL-Sichten für die zugrunde liegenden Tabellen verwenden, um die logischen Strukturen beizubehalten, dieser Ansatz birgt jedoch potenzielle Nachteile:
Ansichten in Azure Synapse sind schreibgeschützt, sodass alle Updates an den Daten in den zugrunde liegenden Basistabellen erfolgen müssen.
Es kann bereits mindestens eine Ebene von Sichten vorhanden sein, und das Hinzufügen einer zusätzlichen Ebene von Sichten könnte die Leistung und Unterstützbarkeit beeinträchtigen, weil Probleme mit geschachtelten Sichten schwer zu beheben sind.
Tipp
Kombinieren Sie in Azure Synapse mehrere Datenbanken in einer einzelnen Datenbank, und verwenden Sie Schemanamen, um die Tabellen logisch zu trennen.
Überlegungen zu Tabellen
Wenn Sie Tabellen zwischen verschiedenen Umgebungen migrieren, werden in der Regel nur die Rohdaten und die Metadaten, die sie beschreiben, physisch migriert. Andere Datenbankelemente aus dem Quellsystem, wie z. B. Indizes, werden in der Regel nicht migriert, weil sie in der neuen Umgebung möglicherweise nicht benötigt oder anders implementiert werden. Leistungsoptimierungen in der Quellumgebung, wie z. B. Indizes, geben Hinweise darauf, wo Leistungsoptimierungen in der neuen Umgebung vorgenommen werden können. Wenn beispielsweise in der Teradata-Quellumgebung eine Tabelle mit einem nicht eindeutigen sekundären Index (Non-Unique Secondary Index, NUSI) vorhanden ist, kann dies ein Hinweis darauf sein, dass in Azure Synapse ein nicht gruppierter Index erstellt werden sollte. Andere native Techniken zur Leistungsoptimierung wie die Tabellenreplikation sind möglicherweise besser geeignet als die direkte gleichartige Indexerstellung.
Tipp
Vorhandene Indizes bieten Hinweise auf mögliche Kandidaten für die Indizierung im migrierten Warehouse.
Hochverfügbarkeit für die Datenbank
Teradata unterstützt die knotenübergreifende Datenreplikation mit der Option FALLBACK. Hierbei werden Tabellenzeilen, die sich physisch auf einem bestimmten Knoten befinden, auf einen anderen Knoten im System repliziert. Dieser Ansatz garantiert, dass bei einem Ausfall eines Knotens keine Daten verloren gehen, und bildet die Grundlage für Failoverszenarien.
Die Architektur für Hochverfügbarkeit in Azure Synapse Analytics soll garantieren, dass Ihre Datenbank aktiv ist und zu 99,9 % der Zeit ausgeführt wird, ohne dass Sie sich Gedanken über die Auswirkungen von Wartungsvorgängen und Ausfällen machen müssen. Weitere Informationen zur Vereinbarung zum Servicelevel (Service Level Agreement, SLA) finden Sie unter SLA für Azure Synapse Analytics. Azure übernimmt automatisch wichtige Dienste wie Patches, Sicherungen und Windows- und SQL-Upgrades. Azure kümmert sich auch automatisch um ungeplante Ereignisse wie Ausfälle der zugrunde liegenden Hardware, Software oder des Netzwerks.
Die Datenspeicherung in Azure Synapse wird automatisch mittels Momentaufnahmen gesichert. Diese Momentaufnahmen sind ein integriertes Feature des Diensts zum Erstellen von Wiederherstellungspunkten. Sie müssen diese Funktion nicht aktivieren. Benutzer können derzeit keine automatischen Wiederherstellungspunkte löschen, die der Dienst zum Verwalten von Vereinbarungen zum Servicelevel (Service Level Agreements, SLAs) für die Wiederherstellung verwendet.
Der dedizierte SQL-Pool von Azure Synapse erstellt im Laufe des Tages Momentaufnahmen des Data Warehouse, um Wiederherstellungspunkte zu erstellen, die sieben Tage lang verfügbar sind. Dieser Aufbewahrungszeitraum kann nicht geändert werden. Azure Synapse unterstützt eine Wiederherstellungspunktvorgabe (Recovery Point Objective, RPO) von acht Stunden. Sie können das Data Warehouse in der primären Region anhand einer beliebigen Momentaufnahme wiederherstellen, die in den vergangenen sieben Tagen erstellt wurde. Wenn Sie differenziertere Sicherungen benötigen, können Sie eine andere benutzerdefinierte Option verwenden.
Nicht unterstützte Teradata-Tabellentypen
Teradata unterstützt spezielle Tabellentypen für Zeitreihen und temporale Daten. Die Syntax und einige Funktionen für diese Tabellentypen werden in Azure Synapse nicht direkt unterstützt. Sie können die Daten jedoch in eine Standardtabelle in Azure Synapse migrieren, indem Sie die entsprechenden Datentypen zuordnen und die Datums-/Uhrzeitspalte indizieren oder partitionieren.
Tipp
Standardtabellen in Azure Synapse können migrierte Teradata-Zeitreihen und temporale Daten unterstützen.
Teradata implementiert die Funktion für temporale Abfragen über das Umschreiben von Abfragen, um zusätzliche Filter in einer temporalen Abfrage hinzuzufügen und so den entsprechenden Datumsbereich einzuschränken. Wenn Sie diese Funktionalität aus der Teradata-Quellumgebung migrieren möchten, fügen Sie die zusätzliche Filterung in die relevanten temporalen Abfragen ein.
Die Azure-Umgebung unterstützt Time Series Insights für komplexe Analysen von Zeitreihendaten in jeder Größenordnung. Diese Funktionalität ist für IoT-Datenanalyseanwendungen vorgesehen.
Syntaxunterschiede in SQL DML
Zwischen Teradata SQL und Azure Synapse T-SQL gibt es einige Syntaxunterschiede in der SQL-Datenbearbeitungssprache (Data Manipulation Language, DML):
QUALIFY: Teradata unterstützt den OperatorQUALIFY. Beispiel:SELECT col1 FROM tab1 WHERE col1='XYZ' QUALIFY ROW_NUMBER () OVER (PARTITION by col1 ORDER BY col1) = 1;Die Entsprechung in der Azure Synapse-Syntax lautet wie folgt:
SELECT * FROM ( SELECT col1, ROW_NUMBER () OVER (PARTITION by col1 ORDER BY col1) rn FROM tab1 WHERE col1='XYZ' ) WHERE rn = 1;Datumsarithmetik: Azure Synapse verfügt über Operatoren wie
DATEADDundDATEDIFF, die für Felder vom TypDATEoderDATETIMEverwendet werden können. Teradata unterstützt die direkte Subtraktion für Datumsangaben, wie z. B.SELECT DATE1 - DATE2 FROM....GROUP BY: Geben Sie im OrdinalGROUP BYexplizit einen T-SQL-Spaltennamen an.LIKE ANY: Teradata unterstütztLIKE ANY-Syntax wie z. B.:SELECT * FROM CUSTOMER WHERE POSTCODE LIKE ANY ('CV1%', 'CV2%', 'CV3%');Die Entsprechung in der Azure Synapse-Syntax lautet:
SELECT * FROM CUSTOMER WHERE (POSTCODE LIKE 'CV1%') OR (POSTCODE LIKE 'CV2%') OR (POSTCODE LIKE 'CV3%');Je nach Systemeinstellungen wird bei Zeichenvergleichen in Teradata ggf. nicht standardmäßig zwischen Groß- und Kleinschreibung unterschieden. In Azure Synapse wird bei Zeichenvergleichen stets Groß-/Kleinbuchschreibung unterschieden.
Funktionen, gespeicherte Prozeduren, Trigger und Sequenzen
Bei der Migration eines Data Warehouse aus einer ausgereiften Umgebung wie Teradata müssen Sie wahrscheinlich auch andere Elemente als einfache Tabellen und Sichten migrieren. Dazu gehören Funktionen, gespeicherte Prozeduren, Trigger und Sequenzen. Überprüfen Sie, ob Tools in der Azure-Umgebung die Funktionalität von Funktionen, gespeicherten Prozeduren und Sequenzen ersetzen können, da es in der Regel effizienter ist, integrierte Azure-Tools zu verwenden, als diese Elemente für Azure Synapse neu zu codieren.
Erstellen Sie im Rahmen Ihrer Vorbereitungsphase eine Bestandsaufnahme der zu migrierenden Objekte, definieren Sie eine Methode für deren Handhabung, und weisen Sie entsprechende Ressourcen in Ihrem Migrationsplan zu.
Datenintegrationspartner bieten Tools und Dienste, mit denen die Migration von Funktionen, gespeicherten Prozeduren und Sequenzen automatisiert werden kann.
In den folgenden Abschnitten wird die Migration von Funktionen, gespeicherten Prozeduren und Sequenzen näher erläutert.
Functions
Wie die meisten Datenbankprodukte unterstützt Teradata Systemfunktionen und benutzerdefinierte Funktionen innerhalb einer SQL-Implementierung. Wenn Sie eine Legacydatenbankplattform zu Azure Synapse migrieren, können allgemeine Systemfunktionen in der Regel ohne Änderung migriert werden. Einige Systemfunktionen weisen möglicherweise eine etwas andere Syntax auf, aber alle erforderlichen Änderungen können automatisiert werden.
Teradata-Systemfunktionen oder beliebige benutzerdefinierte Funktionen, für die es in Azure Synapse keine Entsprechung gibt, müssen mithilfe einer in der Zielumgebung verwendeten Sprache umprogrammiert werden. In Azure Synapse werden benutzerdefinierte Funktionen mithilfe der Sprache „Transact-SQL“ implementiert.
Gespeicherte Prozeduren
Die meisten modernen Datenbankprodukte unterstützen das Speichern von Prozeduren in der Datenbank. Teradata stellt zu diesem Zweck die SPL-Sprache bereit. Eine gespeicherte Prozedur enthält in der Regel sowohl SQL-Anweisungen als auch prozedurale Logik und gibt Daten oder einen Status zurück.
Azure Synapse unterstützt gespeicherte Prozeduren mithilfe von T-SQL. Daher müssen Sie alle migrierten gespeicherten Prozeduren in dieser Sprache umprogrammieren.
Auslöser
Die Erstellung von Triggern wird von Azure Synapse nicht unterstützt, kann aber mithilfe von Azure Data Factory implementiert werden.
Sequenzen
In Azure Synapse werden Sequenzen auf ähnliche Weise wie in Teradata behandelt, und Sie können Sequenzen mithilfe von IDENTITY-Spalten oder mit SQL-Code implementieren, der die nächste Sequenznummer in einer Reihe generiert. Eine Sequenz stellt eindeutige numerische Werte bereit, die Sie als Ersatzschlüsselwerte für Primärschlüssel verwenden können.
Extrahieren von Metadaten und Daten aus einer Teradata-Umgebung
Generierung von DDL-Anweisungen (Data Definition Language, Datendefinitionssprache)
Der ANSI SQL-Standard definiert die grundlegende Syntax für DDL-Befehle. Einige DDL-Befehle (z. B. CREATE TABLE und CREATE VIEW) gelten sowohl für Teradata als auch für Azure Synapse, bieten aber auch implementierungsspezifische Funktionen wie Indizierung, Tabellenverteilung und Partitionierungsoptionen.
Sie können vorhandene Teradata-Skripts für CREATE TABLE und CREATE VIEW bearbeiten, um entsprechende Definitionen in Azure Synapse zu erzielen. Dazu müssen Sie möglicherweise geänderte Datentypen verwenden und Teradata-spezifische Klauseln wie z. B. FALLBACK entfernen oder ändern.
Alle Informationen, die sich auf die aktuellen Definitionen von Tabellen und Sichten in der vorhandenen Teradata-Umgebung beziehen, werden jedoch in den Systemkatalogtabellen verwaltet. Diese Tabellen sind die beste Quelle für diese Informationen, da sie garantiert aktuell und vollständig sind. Die benutzerseitig verwaltete Dokumentation ist möglicherweise nicht mit den aktuellen Tabellendefinitionen synchron.
In der Teradata-Umgebung sind die aktuellen Definitionen von Tabellen und Sichten in Systemkatalogtabellen angegeben. Im Gegensatz zur benutzerseitig verwalteten Dokumentation sind Systemkataloginformationen immer vollständig und mit aktuellen Tabellendefinitionen synchronisiert. Über Sichten im Katalog, wie z. B. DBC.ColumnsV, können Sie auf Systemkataloginformationen zugreifen, um DDL-Anweisungen vom Typ CREATE TABLE zu generieren, mit denen die entsprechenden Tabellen in Azure Synapse erstellt werden.
Tipp
Verwenden Sie vorhandene Teradata-Metadaten, um die Generierung von DDL-Anweisungen vom Typ CREATE TABLE und CREATE VIEW für Azure Synapse zu automatisieren.
Sie können auch Migrations- und ETL-Tools von Drittanbietern verwenden, die Systemkataloginformationen verarbeiten, um ähnliche Ergebnisse zu erzielen.
Extrahieren von Daten aus Teradata
Sie können Tabellenrohdaten aus Teradata-Tabellen mithilfe von Teradata-Standardhilfsprogrammen wie Basic Teradata Query (BTEQ), Teradata FastExport oder Teradata Parallel Transporter (TPT) in durch Trennzeichen getrennte Flatfiles (z. B. CSV-Dateien) extrahieren. Mit TPT können Sie Tabellendaten auf die effizienteste Weise extrahieren. TPT verwendet mehrere parallele FastExport-Streams, um den höchsten Durchsatz zu erzielen.
Tipp
Mit Teradata Parallel Transporter erzielen Sie die effizienteste Datenextraktion.
Rufen Sie TPT direkt in Azure Data Factory auf. Dies ist die empfohlene Vorgehensweise bei der Datenmigration von lokalen Teradata-Instanzen und Teradata-Instanzen, die auf einer VM in der Azure-Umgebung ausgeführt werden.
Extrahierte Datendateien sollten durch Trennzeichen getrennten Text enthalten – und im Format CSV, Optimized Row Columnar (ORC) oder Parquet vorliegen.
Weitere Informationen zur Datenmigration und zur ETL-Migration aus einer Teradata-Umgebung finden Sie unter Datenmigration, ETL und Ladevorgänge für die Teradata-Migration.
Leistungsempfehlungen für Teradata-Migrationen
Das Ziel der Leistungsoptimierung besteht darin, nach der Migration zu Azure Synapse die gleiche oder eine bessere Data Warehouse-Leistung zu erzielen.
Tipp
Machen Sie sich zu Beginn einer Migration zuerst mit den Optimierungsoptionen in Azure Synapse vertraut.
Unterschiede in Leistungsoptimierungskonzepten
In diesem Abschnitt werden die Unterschiede bei der Implementierung der Leistungsoptimierung auf niedriger Ebene zwischen Teradata und Azure Synapse hervorgehoben.
Datenverteilungsoptionen
Im Hinblick auf die Leistung wurde Azure Synapse mit einer Architektur mit mehreren Knoten entworfen. Außerdem wird die Parallelverarbeitung verwendet. Um die Leistung einzelner Tabellen in Azure Synapse zu optimieren, können Sie in Anweisungen vom Typ CREATE TABLE mit der DISTRIBUTION-Anweisung eine Datenverteilungsoption definieren. Sie können beispielsweise eine Tabelle mit Hashverteilung angeben, die Tabellenzeilen mithilfe einer deterministischen Hashfunktion auf Computeknoten verteilt. Ziel ist es, die beim Ausführen einer Abfrage zwischen den Verarbeitungsknoten verschobene Datenmenge zu reduzieren.
Bei Joins zwischen großen Tabellen verteilen Sie eine oder idealerweise beide Tabellen per Hash auf eine der Joinspalten, die einen großen Wertebereich umfasst, um eine gleichmäßige Verteilung sicherzustellen. Verarbeiten Sie Joins lokal, da sich die zu verknüpfenden Datenzeilen auf demselben Verarbeitungsknoten befinden.
Azure Synapse unterstützt auch lokale Joins zwischen einer kleinen Tabelle und einer großen Tabelle durch Replikation der kleinen Tabelle. Nehmen wir als Beispiel eine kleine Dimensionstabelle und eine große Faktentabelle in einem Sternschemamodell. Azure Synapse kann die kleinere Dimensionstabelle auf alle Knoten replizieren, um sicherzustellen, dass für jeden Wert eines Joinschlüssels der großen Tabelle eine entsprechende, lokal verfügbare Dimensionszeile vorhanden ist. Der Aufwand der Dimensionstabellenreplikation ist bei einer kleinen Dimensionstabelle relativ gering. Bei großen Dimensionstabellen ist ein Hashverteilungsansatz besser geeignet. Weitere Informationen zu Datenverteilungsoptionen finden Sie unter Anleitung für das Verwenden replizierter Tabellen und Leitfaden zum Entwerfen von verteilten Tabellen.
Datenindizierung
Azure Synapse unterstützt mehrere benutzerdefinierbare Indizierungsoptionen, die sich von den in Teradata implementierten Indizierungsoptionen unterscheiden. Weitere Informationen zu den verschiedenen Indizierungsoptionen in Azure Synapse finden Sie unter Indizes von Tabellen in dedizierten SQL-Pools.
Vorhandene Indizes in der Teradata-Quellumgebung bieten nützliche Hinweise auf die Datenverwendung und die Spalten, die für die Indizierung in der Azure Synapse-Umgebung in Frage kommen.
Datenpartitionierung
Im Data Warehouse eines Unternehmens können Faktentabellen Milliarden von Zeilen enthalten. Die Partitionierung optimiert die Verwaltung und Abfrageleistung dieser Tabellen, indem sie in separate Teile aufgeteilt werden, um die verarbeitete Datenmenge zu reduzieren. In Azure Synapse wird die Partitionierungsspezifikation für eine Tabelle in der CREATE TABLE-Anweisung definiert. Partitionieren Sie nur sehr große Tabellen, und stellen Sie sicher, dass jede Partition mindestens 60 Millionen Zeilen enthält.
Für die Partitionierung können Sie nur ein Feld pro Tabelle verwenden. Bei diesem Feld handelt es sich häufig um ein Datumsfeld, da viele Abfragen nach Datum oder Datumsbereich gefiltert werden. Sie können die Partitionierung einer Tabelle nach dem ersten Laden ändern, indem Sie die Tabelle mit einer neuen Verteilung mithilfe der Anweisung CREATE TABLE AS (CTAS) neu erstellen. Eine ausführliche Erläuterung der Partitionierung in Azure Synapse finden Sie unter Partitionieren von Tabellen im dedizierten SQL-Pool.
Datentabellenstatistiken
Sie müssen sicherstellen, dass Statistiken zu Datentabellen auf dem neuesten Stand sind, indem Sie den Schritt Statistik für ETL-/ELT-Aufträge erstellen.
PolyBase oder COPY INTO zum Laden von Daten
PolyBase unterstützt das effiziente Laden großer Datenmengen in ein Data Warehouse mithilfe paralleler Ladedatenströme. Weitere Informationen finden Sie in der PolyBase-Datenladestrategie.
COPY INTO unterstützt auch die Datenerfassung mit hohem Durchsatz und Folgendes:
Datenabruf aus allen Dateien innerhalb eines Ordners und Unterordners.
Datenabruf aus mehreren Speicherorten im selben Speicherkonto. Sie können mehrere Speicherorte angeben, indem Sie durch Trennzeichen getrennte Pfade verwenden.
Azure Data Lake Storage (ADLS) und Azure Blob Storage.
Die Dateiformate CSV, PARQUET und ORC.
Verwalten von Arbeitsauslastungen
Das Ausführen gemischter Workloads kann bei ausgelasteten Systemen zu Ressourcenproblemen führen. Ein erfolgreiches Workload-Management-Schema verwaltet Ressourcen effektiv, stellt eine hocheffiziente Ressourcennutzung sicher und maximiert die Kapitalrendite (ROI). Die Workload-Klassifizierung, die Workload-Priorität und die Workload-Isolation geben mehr Kontrolle darüber, wie die Workload Systemressourcen nutzt.
Der Workload-Management-Leitfaden beschreibt die Techniken zum Analysieren der Workload, Verwalten und Überwachen der Workload-Bedeutung und die Schritte zum Konvertieren einer Ressourcenklasse in eine Workload-Gruppe. Verwenden Sie das Azure-Portal und T-SQL-Abfragen auf DMVs, um die Workload zu überwachen und sicherzustellen, dass die entsprechenden Ressourcen effizient genutzt werden.
Nächste Schritte
Informationen zu ETL und zu Ladevorgängen für die Teradata-Migration finden Sie im nächsten Artikel in dieser Reihe: Datenmigration, ETL und Ladevorgänge für die Teradata-Migration.