Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
Azure Synapse Analytics bietet verschiedene Analysemodule, mit denen Sie Ihre Daten aufnehmen, transformieren, modellieren und analysieren können. Ein dedizierter SQL-Pool bietet T-SQL-basierte Compute- und Speicherfunktionen. Nachdem Sie einen dedizierten SQL-Pool in Ihrem Synapse-Arbeitsbereich erstellt haben, können Daten geladen, modelliert, verarbeitet und bereitgestellt werden, um schnellere Analyseerblicke zu erhalten.
In dieser Schnellstartanleitung erfahren Sie, wie Sie Daten aus der Azure SQL-Datenbank in Azure Synapse Analytics laden. Sie können ähnliche Schritte zum Kopieren von Daten aus anderen Typen von Datenspeichern ausführen. Ähnliche Schritte gelten auch für das Kopieren von Daten für andere Quellen und Senken.
Voraussetzungen
- Azure-Abonnement: Wenn Sie nicht über ein Azure-Abonnement verfügen, erstellen Sie ein kostenloses Azure-Konto , bevor Sie beginnen.
- Azure Synapse-Arbeitsbereich: Erstellen Sie einen Synapse-Arbeitsbereich mithilfe des Azure-Portals, indem Sie die Anweisungen in der Schnellstartanleitung befolgen: Erstellen eines Synapse-Arbeitsbereichs.
- Azure SQL-Datenbank: In diesem Tutorial werden Daten aus einem Beispieldataset von Adventure Works LT nach Azure SQL-Datenbank kopiert. Sie können diese Beispieldatenbank in SQL-Datenbank erstellen, indem Sie den Anweisungen unter Schnellstart: Erstellen einer Azure SQL-Einzeldatenbank folgen. Sie können auch andere Datenspeicher verwenden, indem Sie ähnliche Schritte ausführen.
- Azure Storage-Konto: Azure Storage wird als Stagingbereich im Kopiervorgang verwendet. Falls Sie noch nicht über ein Azure-Speicherkonto verfügen, finden Sie Anweisungen dazu unter Erstellen eines Speicherkontos.
- Azure Synapse Analytics: Sie verwenden einen dedizierten SQL-Pool als Spüldatenspeicher. Wenn Sie nicht über eine Azure Synapse Analytics-Instanz verfügen, lesen Sie die Schritte zum Erstellen eines dedizierten SQL-Pools .
Navigieren Sie zum Synapse Studio
Nachdem Ihr Synapse-Arbeitsbereich erstellt wurde, haben Sie zwei Möglichkeiten, Synapse Studio zu öffnen:
- Öffnen Sie Ihren Synapse-Arbeitsbereich im Azure-Portal. Wählen Sie auf der Open Synapse Studio-Karte unter "Erste Schritte" die Option "Öffnen" aus.
- Öffnen Sie Azure Synapse Analytics , und melden Sie sich bei Ihrem Arbeitsbereich an.
In dieser Schnellstartanleitung verwenden wir den Arbeitsbereich "adftest2020" als Beispiel. Es navigiert Sie automatisch zur Synapse Studio-Startseite.
Erstellen von verknüpften Diensten
In Azure Synapse Analytics definiert ein verknüpfter Dienst Ihre Verbindungsinformationen mit anderen Diensten. In diesem Abschnitt erstellen Sie die folgenden zwei Arten verknüpfter Dienste: Azure SQL-Datenbank und Azure Data Lake Storage Gen2 (ADLS Gen2) verknüpfte Dienste.
Wählen Sie auf der Startseite von Synapse Studio im linken Navigationsbereich die Registerkarte "Verwalten " aus.
Wählen Sie unter "Externe Verbindungen" "Verknüpfte Dienste" aus.
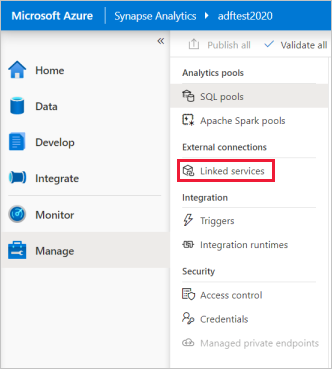
Um einen verknüpften Dienst hinzuzufügen, wählen Sie "Neu" aus.
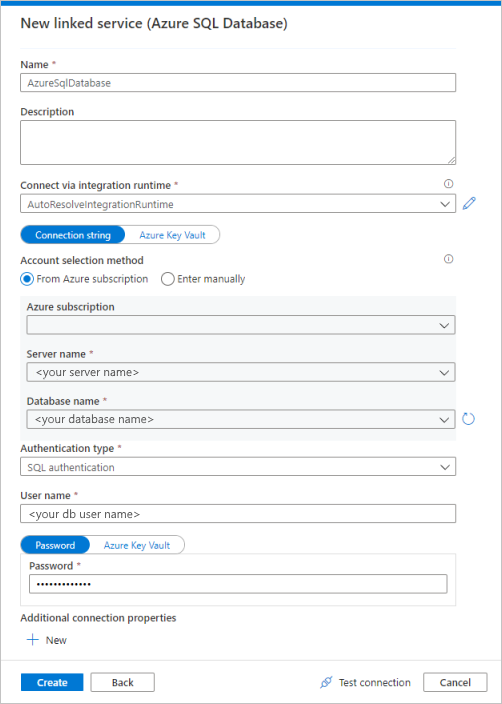
Wählen Sie im Katalog Azure SQL-Datenbank und dann Weiter aus. Sie können "sql" in das Suchfeld eingeben, um die Connectors zu filtern.

Wählen Sie auf der Seite "Neuer verknüpfter Dienst" den Servernamen und den DB-Namen aus der Dropdownliste aus, und geben Sie den Benutzernamen und das Kennwort an. Klicken Sie auf " Verbindung testen" , um die Einstellungen zu überprüfen, und wählen Sie dann "Erstellen" aus.
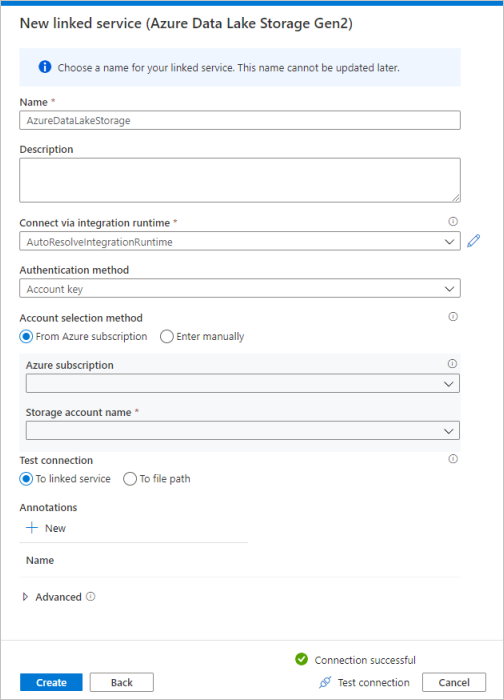
Wiederholen Sie die Schritte 3-4, wählen Sie aber stattdessen azure Data Lake Storage Gen2 aus dem Katalog aus. Wählen Sie auf der Seite "Neuer verknüpfter Dienst" Ihren Speicherkontonamen aus der Dropdownliste aus. Klicken Sie auf " Verbindung testen" , um die Einstellungen zu überprüfen, und wählen Sie dann "Erstellen" aus.
Erstellen einer Pipeline
Eine Pipeline enthält den logischen Fluss für eine Ausführung einer Reihe von Aktivitäten. In diesem Abschnitt erstellen Sie eine Pipeline mit einer Kopieraktivität, die Daten aus der Azure SQL-Datenbank in einen dedizierten SQL-Pool einnimmt.
Wechseln Sie zur Registerkarte " Integrieren" . Wählen Sie neben dem Pipelineheader das Plussymbol aus, und wählen Sie "Pipeline" aus.
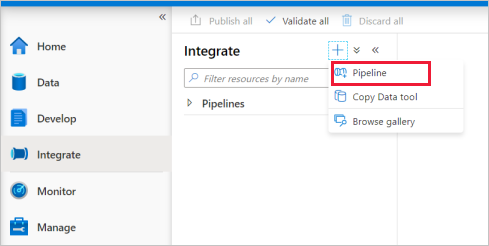
Ziehen Sie unter Verschieben und Transformieren im Bereich AktivitätenDaten kopieren auf das Pipeline-Feld.
Wählen Sie die Kopieraktivität aus, und wechseln Sie zur Registerkarte "Quelle". Wählen Sie "Neu" aus, um ein neues Quelldatenset zu erstellen.
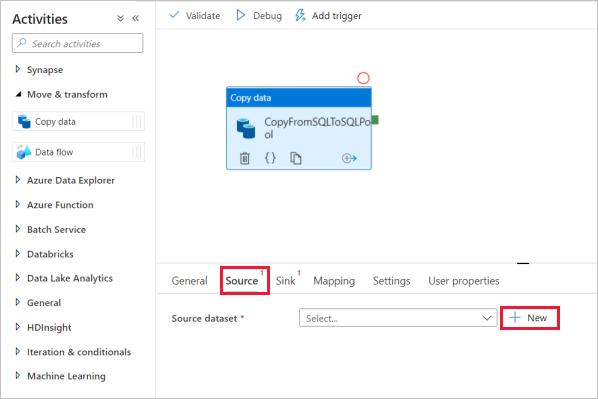
Wählen Sie Azure SQL-Datenbank als Datenspeicher aus, und wählen Sie "Weiter" aus.
Wählen Sie im Eigenschaftenbereich Festlegen den mit der Azure SQL-Datenbank verknüpften Dienst aus, den Sie im vorherigen Schritt erstellt haben.
Wählen Sie unter "Tabellenname" eine Beispieltabelle aus, die in der folgenden Kopieraktivität verwendet werden soll. In dieser Schnellstartanleitung verwenden wir die Tabelle "SalesLT.Customer" als Beispiel.
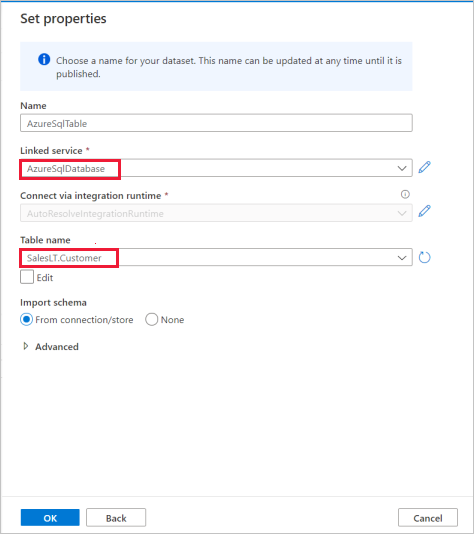
Wählen Sie OK aus, wenn Sie fertig sind.
Wählen Sie die Copy-Aktivität aus, und wechseln Sie zur Registerkarte „Senke“. Klicken Sie auf Neu, um ein neues Senkendataset zu erstellen.
Wählen Sie azure Synapse dedizierten SQL-Pool als Datenspeicher aus, und wählen Sie "Weiter" aus.
Wählen Sie im Eigenschaftenbereich "Festlegen " den SQL Analytics-Pool aus, den Sie im vorherigen Schritt erstellt haben. Wenn Sie in eine vorhandene Tabelle schreiben, wählen Sie ihn unter "Tabellenname " aus der Dropdownliste aus. Aktivieren Sie andernfalls "Bearbeiten", und geben Sie ihren neuen Tabellennamen ein. Wählen Sie OK aus, wenn Sie fertig sind.
Aktivieren Sie für Sink-Dataseteinstellungen die Option "Tabelle automatisch erstellen " im Optionsfeld "Tabelle".
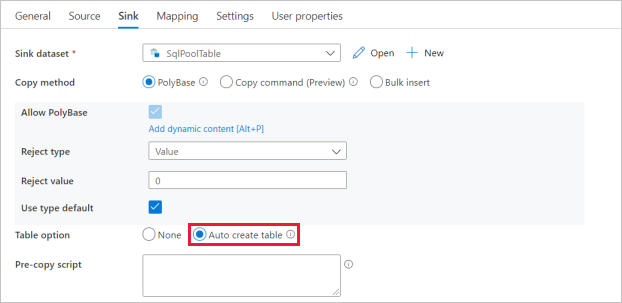
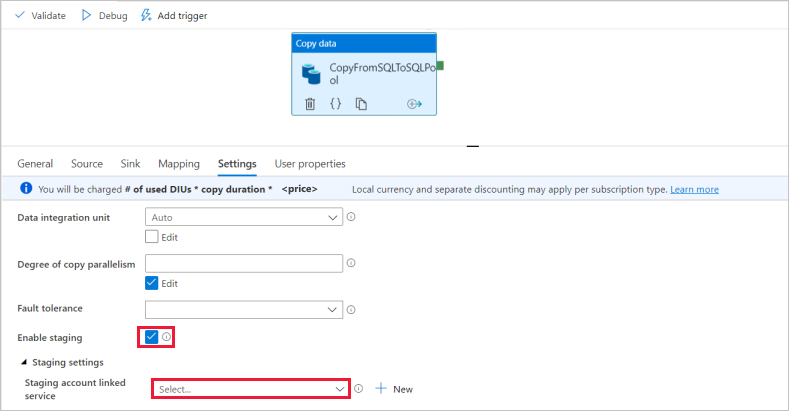
Aktivieren Sie auf der Seite Einstellungen das Kontrollkästchen für Enable Staging (Staging aktivieren). Diese Option gilt, wenn Ihre Quelldaten nicht mit PolyBase kompatibel sind. Wählen Sie im Abschnitt "Stagingeinstellungen " den verknüpften Azure Data Lake Storage Gen2-Dienst aus, den Sie im vorherigen Schritt als Stagingspeicher erstellt haben.
Der Speicher wird für das Staging der Daten verwendet, bevor diese mit PolyBase in Azure Synapse Analytics geladen werden. Nach Abschluss der Kopie werden die Zwischendaten in Azure Data Lake Storage Gen2 automatisch bereinigt.
Um die Pipeline zu überprüfen, wählen Sie auf der Symbolleiste "Überprüfen" aus. Das Ergebnis der Pipelineüberprüfungsausgabe wird rechts auf der Seite angezeigt.
Debuggen und Veröffentlichen der Pipeline
Nachdem Sie die Konfiguration der Pipeline abgeschlossen haben, können Sie eine Debugausführung ausführen, bevor Sie Ihre Artefakte veröffentlichen, um sicherzustellen, dass alles korrekt ist.
Klicken Sie auf der Symbolleiste auf Debuggen, um die Pipeline zu debuggen. Der Status der Pipelineausführung wird unten im Fenster auf der Registerkarte Ausgabe angezeigt.
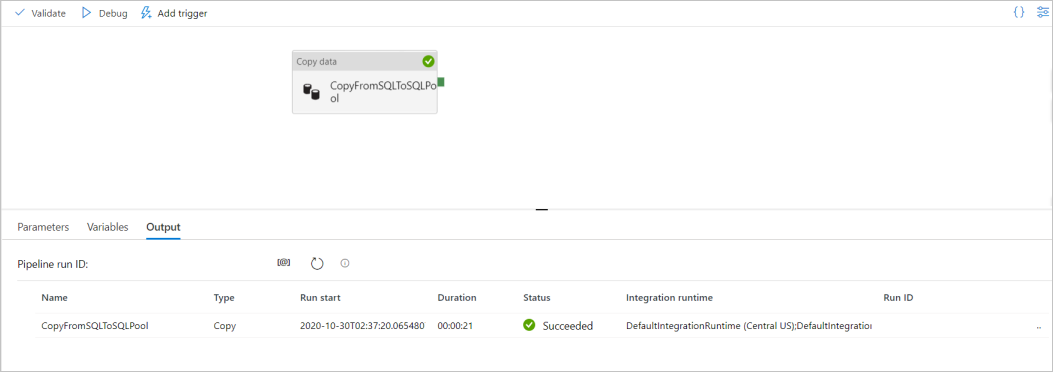
Nachdem der Pipeline-Lauf erfolgreich abgeschlossen ist, wählen Sie in der oberen Symbolleiste "Alle veröffentlichen" aus. Diese Aktion veröffentlicht Entitäten (Datasets und Pipelines), die Sie im Synapse Analytics-Dienst erstellt haben.
Warten Sie, bis die Meldung Erfolgreich veröffentlicht angezeigt wird. Um Benachrichtigungen anzuzeigen, wählen Sie oben rechts die Glockenschaltfläche aus.
Auslösen und Überwachen der Pipeline
In diesem Abschnitt lösen Sie die im vorherigen Schritt veröffentlichte Pipeline manuell aus.
Wählen Sie in der Symbolleiste die Option Trigger hinzufügen und dann Jetzt auslösen. Klicken Sie auf der Seite Pipelineausführung auf OK.
Wechseln Sie zur Registerkarte "Monitor ", die sich in der linken Randleiste befindet. Sie sehen eine Pipelineausführung, die von einem manuellen Trigger ausgelöst wird.
Wenn die Pipeline erfolgreich ausgeführt wird, wählen Sie den Link unter der Spalte " Pipelinename " aus, um Aktivitätsausführungsdetails anzuzeigen oder die Pipeline erneut auszuführen. Da in diesem Beispiel nur eine Aktivität vorhanden ist, wird in der Liste nur ein Eintrag angezeigt.
Wenn Sie Details zum Kopiervorgang anzeigen möchten, wählen Sie unter der Spalte Activity name (Aktivitätsname) den Link Details (das Brillensymbol) aus. Sie können Details wie die Menge der Daten, die aus der Quelle in die Senke kopiert wurden, den Datendurchsatz, die Ausführungsschritte mit entsprechender Dauer sowie die verwendeten Konfigurationen überwachen.
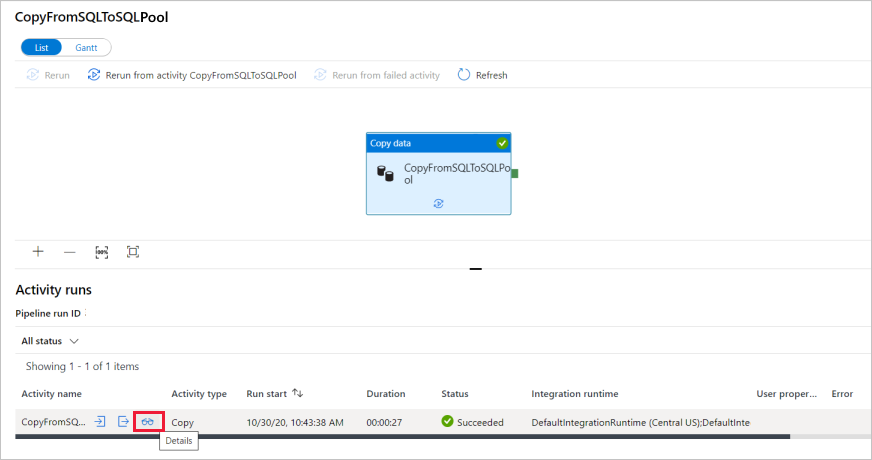
Wählen Sie oben den Link Alle Pipelineausführungen aus, um zurück zur Ansicht mit den Pipelineausführungen zu wechseln. Klicken Sie zum Aktualisieren der Liste auf Aktualisieren.
Überprüfen Sie, ob Ihre Daten ordnungsgemäß im dedizierten SQL-Pool geschrieben wurden.
Nächste Schritte
Lesen Sie den folgenden Artikel, um mehr über die Unterstützung von Azure Synapse Analytics zu erfahren: