Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
Das Laden von Daten ist mit dem Massenladen-Assistenten in Synapse Studio ganz einfach. Synapse Studio ist ein Feature von Azure Synapse Analytics. Der Massenladen-Assistent führt Sie durch die Erstellung eines T-SQL-Skripts mit der COPY-Anweisung zum Massenladen von Daten in einen dedizierten SQL-Pool.
Einstiegspunkte für den Massenladen-Assistenten
Sie können Daten per Massenladen laden, indem Sie mit der rechten Maustaste in Synapse Studio auf eine Datei oder einen Ordner aus einem Azure Storage-Konto klicken, das an Ihren Arbeitsbereich angefügt ist.
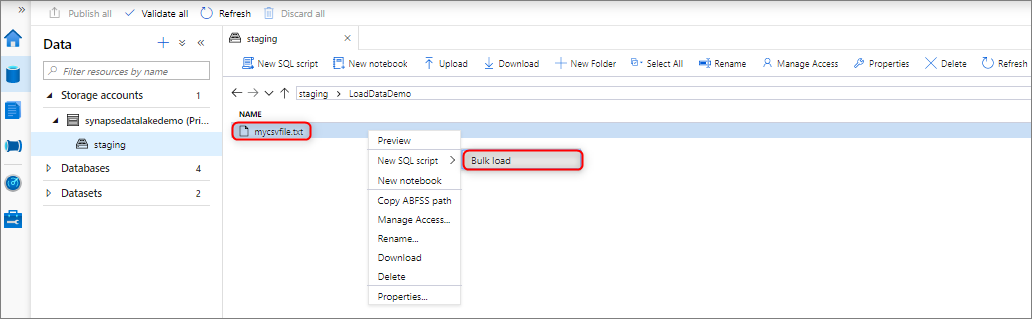
Voraussetzungen
Dieser Assistent generiert eine COPY-Anweisung, die Microsoft Entra-Passthrough für die Authentifizierung verwendet. Ihr Microsoft Entra-Benutzerkonto benötigt Zugriff auf den Arbeitsbereich. Dazu muss ihm mindestens die Azure-Rolle „Mitwirkender an Storage-Blobdaten“ für das Azure Data Lake Storage Gen2-Konto zugewiesen sein.
Falls Sie als Ziel für den Ladevorgang eine neue Tabelle erstellen, müssen Sie über die erforderlichen Berechtigungen für die Verwendung der COPY-Anweisung sowie über Berechtigungen für die Tabellenerstellung verfügen.
Der verknüpfte Dienst, der dem Data Lake Storage Gen2-Konto zugeordnet ist, muss über Zugriff auf die zu ladende Datei oder den zu ladenden Ordner verfügen. Wenn für den verknüpften Dienst beispielsweise „Verwaltete Identität“ als Authentifizierungsmechanismus verwendet wird, muss die verwaltete Identität für den Arbeitsbereich mindestens über die Storage-Blobdatenleseberechtigung für das Speicherkonto verfügen.
Wenn für Ihren Arbeitsbereich ein virtuelles Netzwerk aktiviert ist, stellen Sie sicher, dass für die integrierte Laufzeit, die den verknüpften Diensten des Data Lake Storage Gen2-Kontos für den Speicherort der Quelldaten und der Fehlerdatei zugeordnet ist, interaktives Authoring aktiviert ist. Interaktives Authoring ist für die automatische Schemaerkennung sowie zum Anzeigen einer Vorschau der Quelldateiinhalte und zum Durchsuchen von Data Lake Storage Gen2-Speicherkonten innerhalb des Assistenten erforderlich.
Schritte
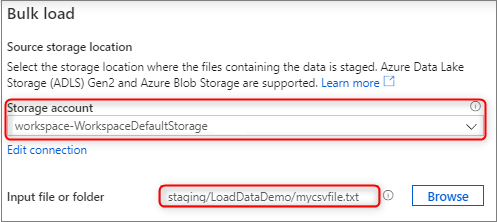
Wählen Sie im Bereich für den Quellspeicherort das Speicherkonto und die Datei bzw. den Ordner aus, die bzw. den Sie als Quelle für den Ladevorgang verwenden möchten. Der Assistent versucht automatisch, Parquet-Dateien und CSV-Dateien (durch Trennzeichen getrennte Textdateien) zu erkennen, einschließlich der Zuordnung der Quellfelder aus der Datei zu den entsprechenden SQL-Zieldatentypen.
Wählen Sie die Dateiformateinstellungen einschließlich Ihrer Fehlereinstellungen für den Fall aus, dass es während des Massenladevorgangs abgelehnte Zeilen gibt. Sie können auch Datenvorschau auswählen, um zu sehen, wie die Datei von der COPY-Anweisung analysiert wird. Dies ist hilfreich beim Konfigurieren der Dateiformateinstellungen. Wählen Sie nach jeder Änderung einer Dateiformateinstellung Datenvorschau aus, um zu sehen, wie die Datei mit der aktualisierten Einstellung von der COPY-Anweisung analysiert wird.
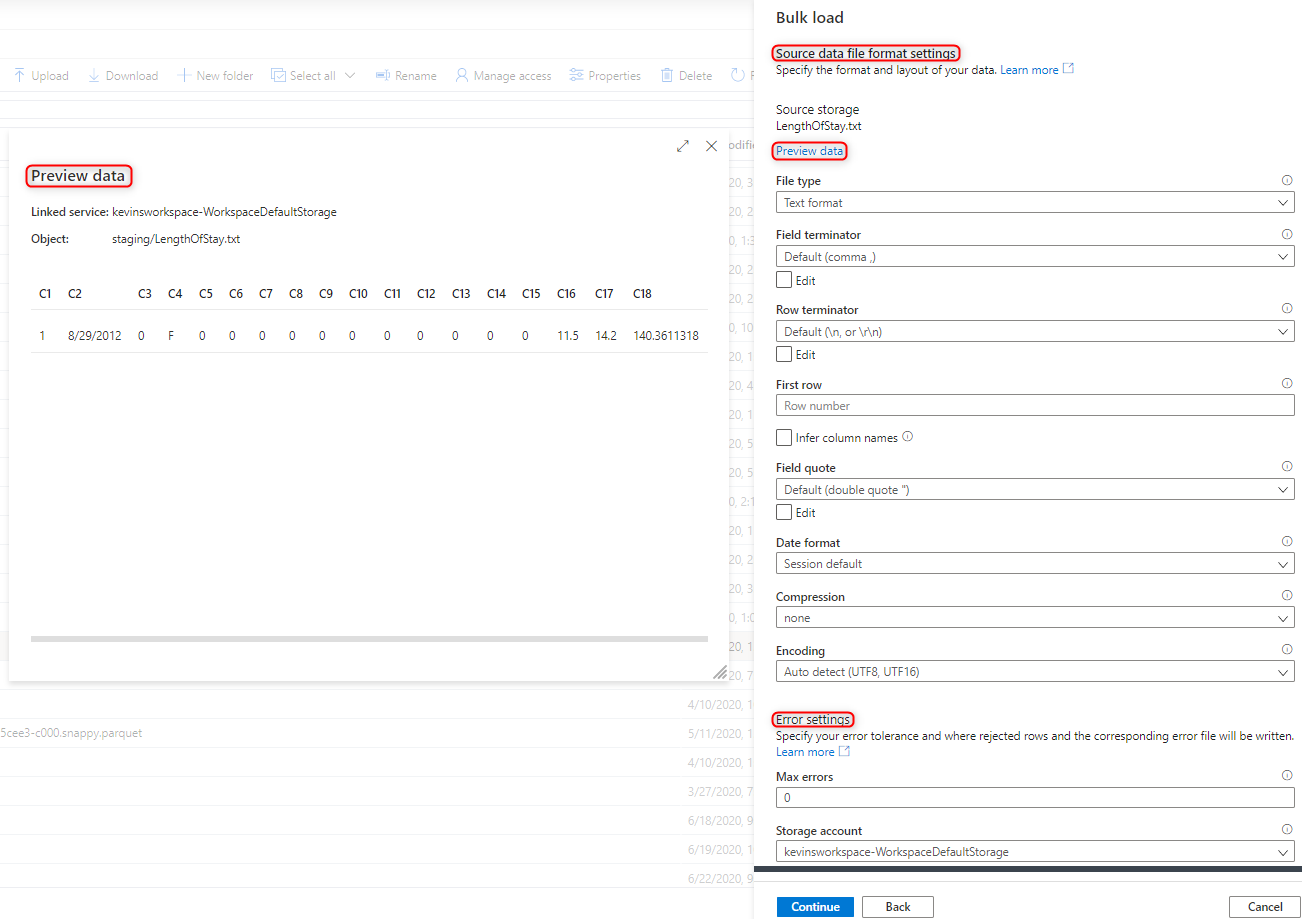
Hinweis
- Vom Massenladen-Assistenten wird das Anzeigen einer Vorschau für die Daten mit mehrstelligen Feldabschlusszeichen nicht unterstützt. Der Assistent zeigt eine Vorschau der Daten in einer einzelnen Spalte an, wenn ein mehrstelliges Feldabschlusszeichen angegeben wird.
- Bei Auswahl von Infer column names (Spaltennamen ableiten) analysiert der Assistent zum Massenladen die Spaltennamen aus der ersten Zeile, die durch das Feld Erste Zeile angegeben wird. Der Massenladen-Assistent erhöht automatisch den Wert
FIRSTROWin der COPY-Anweisung um „1“, damit diese Kopfzeile ignoriert wird. - Die Angabe von mehrstelligen Zeilenabschlusszeichen wird in der COPY-Anweisung unterstützt. Der Massenladen-Assistent unterstützt dies jedoch nicht, und es wird ein Fehler ausgelöst.
Wählen Sie den zum Laden verwendeten dedizierten SQL-Pool aus, und geben Sie an, ob es sich um einen Ladevorgang für eine bereits vorhandene oder für eine neue Tabelle handelt.
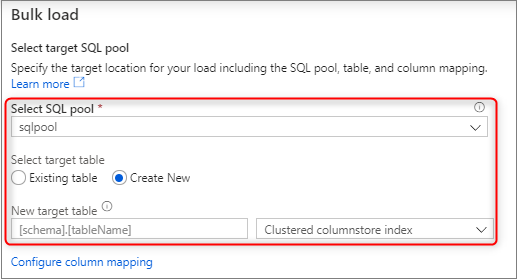
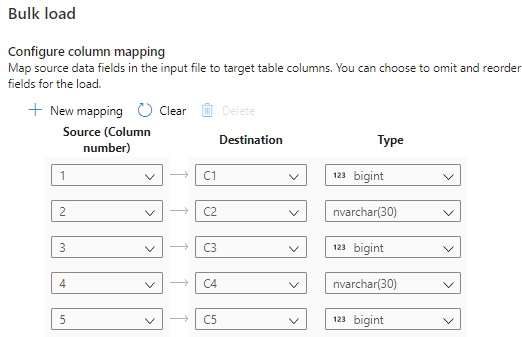
Wählen Sie die Option Spaltenzuordnung konfigurieren aus, und vergewissern Sie sich, dass die Spaltenzuordnung korrekt ist. Beachten Sie, dass Spaltennamen automatisch erkannt werden, wenn Sie Infer column names (Spaltennamen ableiten) aktiviert haben. Bei neuen Tabellen muss die Spaltenzuordnung unbedingt konfiguriert werden, um die Datentypen der Zielspalten zu aktualisieren.
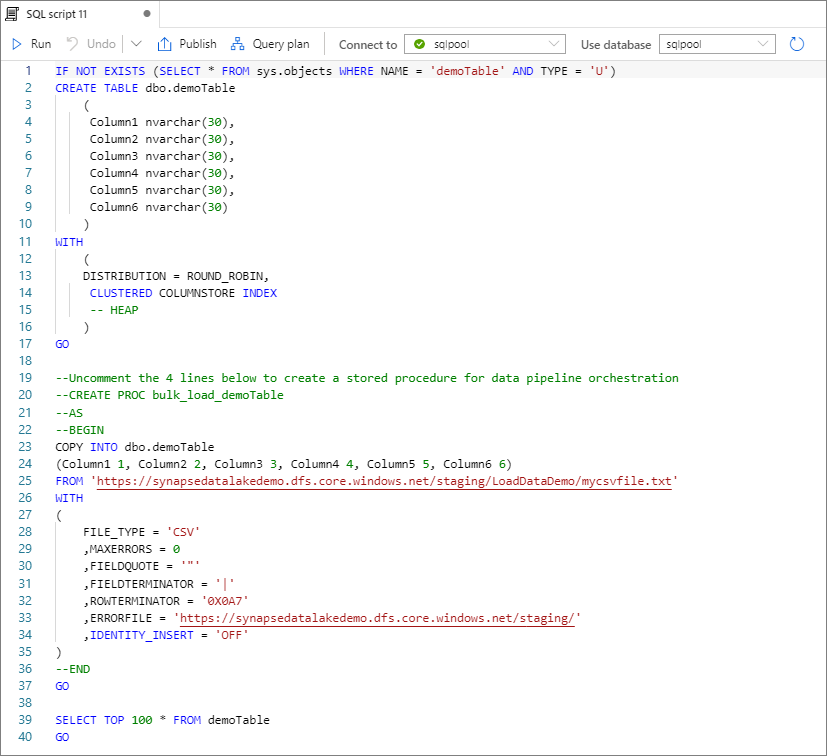
Wählen Sie Skript öffnen aus. Ein T-SQL-Skript mit der COPY-Anweisung wird generiert, um Daten aus Ihrem Data Lake zu laden.
Nächste Schritte
- Lesen Sie den Artikel zur COPY-Anweisung, um weitere Informationen zu Kopierfunktionen zu erhalten.
- Weitere Informationen zur Verwendung eines ETL-Prozesses (Extrahieren, Transformieren und Laden) finden Sie in der Übersicht über das Laden von Daten.