Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
In diesem Tutorial erfahren Sie, wie Sie Apache Spark-Auftragsdefinitionen mithilfe von Synapse Studio erstellen und anschließend an einen serverlosen Apache Spark-Pool übermitteln.
Dieses Tutorial enthält die folgenden Aufgaben:
- Erstellen einer Apache Spark-Auftragsdefinition für PySpark (Python)
- Erstellen einer Apache Spark-Auftragsdefinition für Spark (Scala)
- Erstellen einer Apache Spark-Auftragsdefinition für .NET Spark (C#/F#)
- Erstellen einer Auftragsdefinition durch Importieren einer JSON-Datei
- Exportieren einer Apache Spark-Auftragsdefinitionsdatei in eine lokale Datei
- Übermitteln einer Apache Spark-Auftragsdefinition als Batchauftrag
- Hinzufügen einer Apache Spark-Auftragsdefinition in einer Pipeline
Voraussetzungen
Vergewissern Sie sich zunächst, dass die folgenden Anforderungen erfüllt sind bzw. dass Folgendes vorhanden ist:
- Ein Azure Synapse Analytics-Arbeitsbereich. Entsprechende Anweisungen finden Sie unter Erstellen eines Arbeitsbereichs.
- Ein serverloser Apache Spark-Pool
- Ein ADLS Gen2-Speicherkonto. Sie müssen der Mitwirkende der Speicherblobdaten des ADLS Gen2-Dateisystems sein, das Sie verwenden möchten. Andernfalls müssen Sie die Berechtigung manuell hinzufügen.
- Wenn Sie nicht den Standardspeicher des Arbeitsbereichs verwenden möchten, verknüpfen Sie das erforderliche ADLS Gen2-Speicherkonto in Synapse Studio.
Erstellen einer Apache Spark-Auftragsdefinition für PySpark (Python)
In diesem Abschnitt erstellen Sie eine Apache Spark-Auftragsdefinition für PySpark (Python).
Öffnen Sie Synapse Studio.
Sie können zu Beispieldateien zum Erstellen von Apache Spark-Auftragsdefinitionen navigieren, um Beispieldateien für python.zip herunterzuladen. Entpacken Sie anschließend das komprimierte Paket, und extrahieren Sie die Dateien wordcount.py und shakespeare.txt.
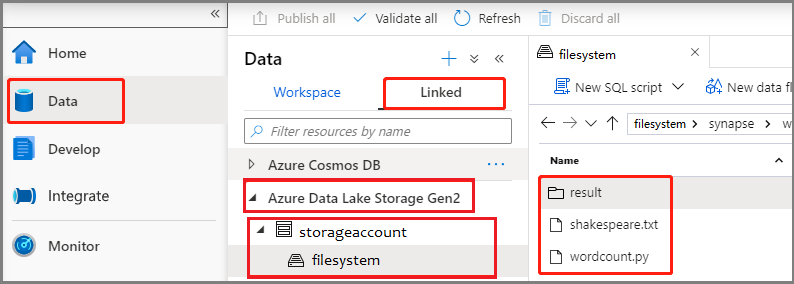
Wählen SieDaten>Verknüpft>Azure Data Lake Storage Gen2 aus, und laden Siewordcount.py und shakespeare.txt in das ADLS Gen2-Dateisystem hoch.
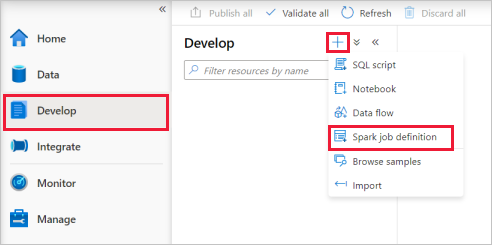
Wählen Sie den Hub Entwickeln, das Plussymbol (+) und anschließend Spark-Auftragsdefinition aus, um eine neue Spark-Auftragsdefinition zu erstellen.
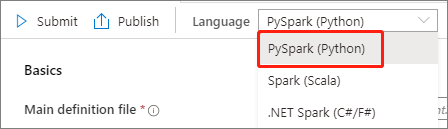
Wählen Sie in der Dropdownliste „Sprache“ im Hauptfenster der Apache Spark-Auftragsdefinition PySpark (Python) aus.
Tragen Sie Informationen für die Apache Spark-Auftragsdefinition ein.
Eigenschaft BESCHREIBUNG Auftragsdefinitionsname Geben Sie einen Namen für Ihre Apache Spark-Auftragsdefinition ein. Dieser Name kann bis zur Veröffentlichung jederzeit aktualisiert werden.
Beispiel:job definition sample„Main definition file“ (Hauptdefinitionsdatei) Die für den Auftrag verwendete Hauptdatei. Wählen Sie eine PY-Datei aus Ihrem Speicher aus. Sie können Datei hochladen auswählen, um die Datei in ein Speicherkonto hochzuladen.
Beispiel:abfss://…/path/to/wordcount.pyBefehlszeilenargumente Optionale Argumente für den Auftrag.
Beispiel:abfss://…/path/to/shakespeare.txtabfss://…/path/to/result
Hinweis: Zwei Argumente für die Beispielauftragsdefinition werden durch ein Leerzeichen getrennt.„Reference files“ (Referenzdateien) Zusätzliche Dateien, die zu Referenzzwecken in der Hauptdefinitionsdatei verwendet werden. Sie können Datei hochladen auswählen, um die Datei in ein Speicherkonto hochzuladen. Spark-Pool Der Auftrag wird an den ausgewählten Apache Spark-Pool übermittelt. Spark-Version Die vom Apache Spark-Pool ausgeführte Version von Apache Spark. Ausführer Die gewünschte Anzahl von Executors im angegebenen Apache Spark-Pool für den Auftrag. „Executor size“ (Executorgröße) Die Anzahl von Kernen und die Menge an Arbeitsspeicher, die für Executors im angegebenen Apache Spark-Pool für den Auftrag verwendet werden sollen. „Driver size“ (Treibergröße) Die Anzahl von Kernen und die Menge an Arbeitsspeicher, die für Treiber im angegebenen Apache Spark-Pool für den Auftrag verwendet werden sollen. Apache Spark-Konfiguration Passen Sie Konfigurationen an, indem Sie die unten aufgeführten Eigenschaften hinzufügen. Wenn Sie keine Eigenschaft hinzufügen, verwendet Azure Synapse ggf. den entsprechenden Standardwert. 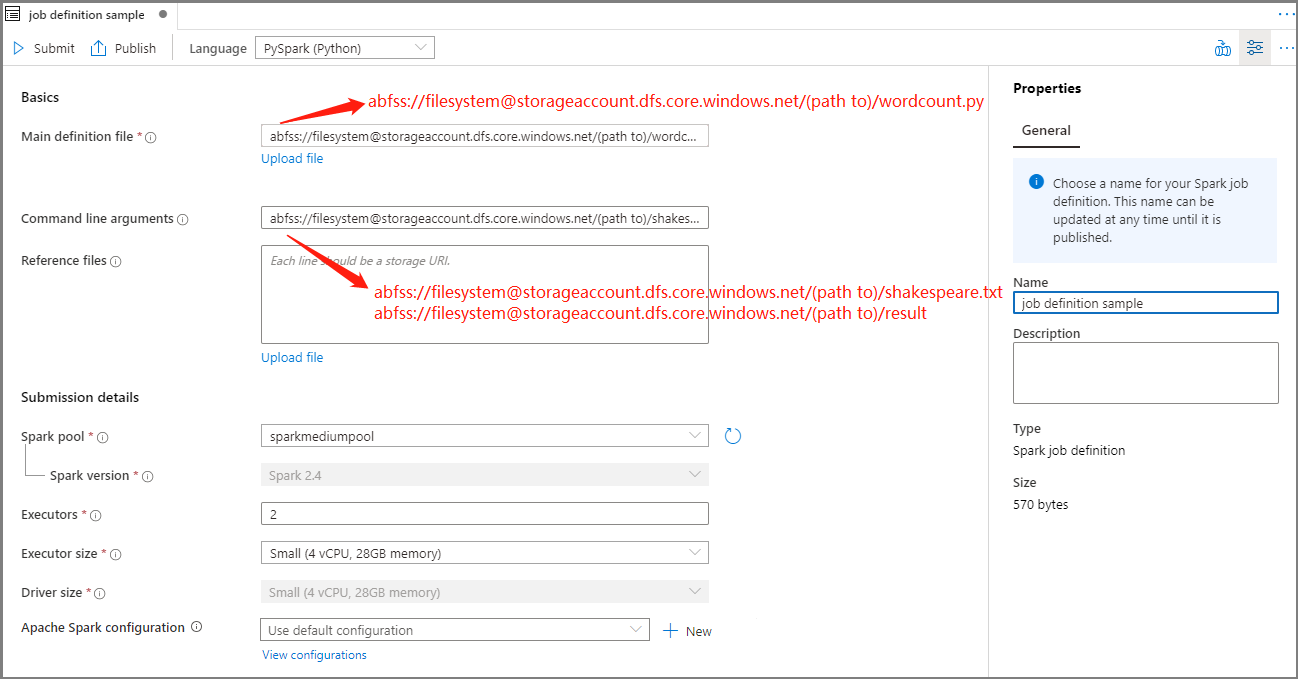
Wählen Sie Veröffentlichen aus, um die Apache Spark-Auftragsdefinition zu speichern.

Erstellen einer Apache Spark-Auftragsdefinition für Apache Spark (Scala)
In diesem Abschnitt erstellen Sie eine Apache Spark-Auftragsdefinition für Apache Spark (Scala).
Öffnen Sie Azure Synapse Studio.
Sie können zu Beispieldateien zum Erstellen von Apache Spark-Auftragsdefinitionen navigieren, um Beispieldateien für scala.zip herunterzuladen. Entpacken Sie anschließend das komprimierte Paket, und extrahieren Sie die Dateien wordcount.jar und shakespeare.txt.
Wählen SieDaten>Verknüpft>Azure Data Lake Storage Gen2 aus, und laden Siewordcount.jar und shakespeare.txt in das ADLS Gen2-Dateisystem hoch.
Wählen Sie den Hub Entwickeln, das Plussymbol (+) und anschließend Spark-Auftragsdefinition aus, um eine neue Spark-Auftragsdefinition zu erstellen. (Die Beispielabbildung ist identisch mit der in Schritt 4 unter Erstellen einer Apache Spark-Auftragsdefinition für PySpark (Python) .)
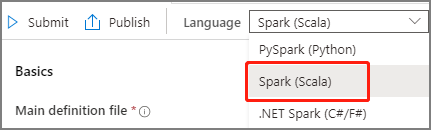
Wählen Sie in der Dropdownliste „Sprache“ im Hauptfenster der Apache Spark-Auftragsdefinition Spark (Scala) aus.
Tragen Sie Informationen für die Apache Spark-Auftragsdefinition ein. Sie können die Beispielinformationen kopieren.
Eigenschaft BESCHREIBUNG Auftragsdefinitionsname Geben Sie einen Namen für Ihre Apache Spark-Auftragsdefinition ein. Dieser Name kann bis zur Veröffentlichung jederzeit aktualisiert werden.
Beispiel:scala„Main definition file“ (Hauptdefinitionsdatei) Die für den Auftrag verwendete Hauptdatei. Wählen Sie eine JAR-Datei aus Ihrem Speicher aus. Sie können Datei hochladen auswählen, um die Datei in ein Speicherkonto hochzuladen.
Beispiel:abfss://…/path/to/wordcount.jar„Main class name“ (Name der Hauptklasse) Der vollqualifizierte Bezeichner oder die Hauptklasse in der Hauptdefinitionsdatei.
Beispiel:WordCountBefehlszeilenargumente Optionale Argumente für den Auftrag.
Beispiel:abfss://…/path/to/shakespeare.txtabfss://…/path/to/result
Hinweis: Zwei Argumente für die Beispielauftragsdefinition werden durch ein Leerzeichen getrennt.„Reference files“ (Referenzdateien) Zusätzliche Dateien, die zu Referenzzwecken in der Hauptdefinitionsdatei verwendet werden. Sie können Datei hochladen auswählen, um die Datei in ein Speicherkonto hochzuladen. Spark-Pool Der Auftrag wird an den ausgewählten Apache Spark-Pool übermittelt. Spark-Version Die vom Apache Spark-Pool ausgeführte Version von Apache Spark. Ausführer Die gewünschte Anzahl von Executors im angegebenen Apache Spark-Pool für den Auftrag. „Executor size“ (Executorgröße) Die Anzahl von Kernen und die Menge an Arbeitsspeicher, die für Executors im angegebenen Apache Spark-Pool für den Auftrag verwendet werden sollen. „Driver size“ (Treibergröße) Die Anzahl von Kernen und die Menge an Arbeitsspeicher, die für Treiber im angegebenen Apache Spark-Pool für den Auftrag verwendet werden sollen. Apache Spark-Konfiguration Passen Sie Konfigurationen an, indem Sie die unten aufgeführten Eigenschaften hinzufügen. Wenn Sie keine Eigenschaft hinzufügen, verwendet Azure Synapse ggf. den entsprechenden Standardwert. 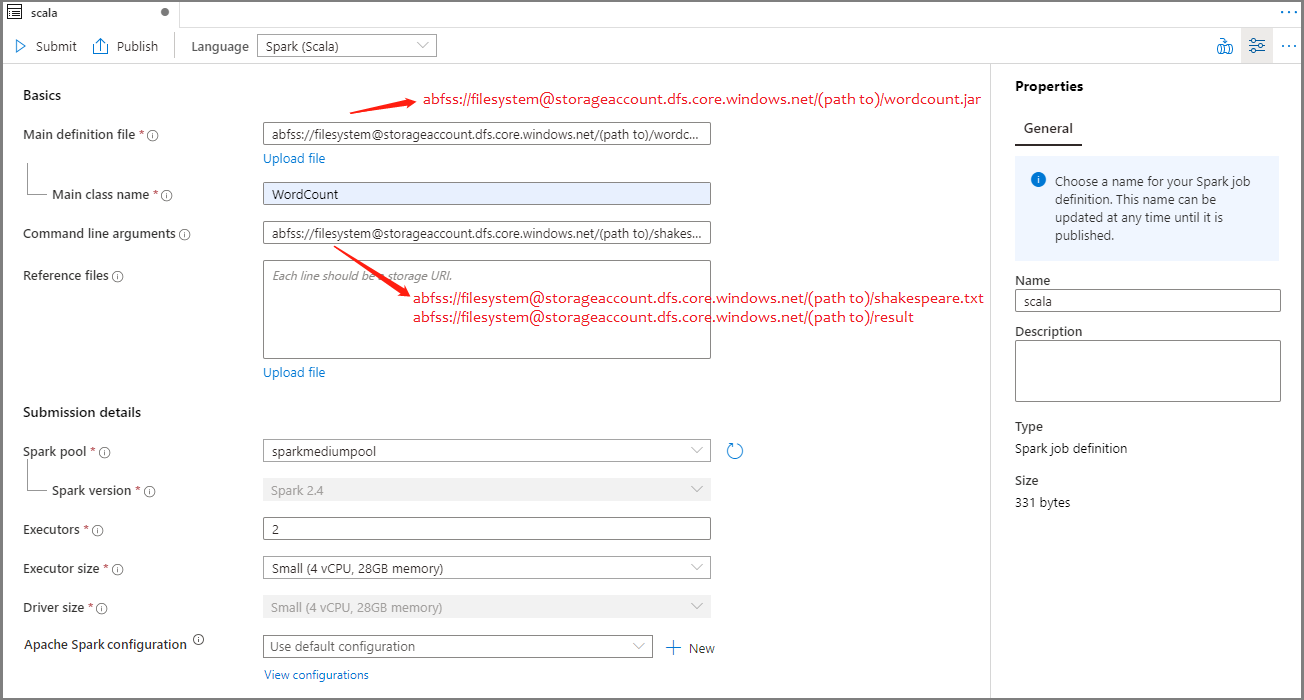
Wählen Sie Veröffentlichen aus, um die Apache Spark-Auftragsdefinition zu speichern.

Erstellen einer Apache Spark-Auftragsdefinition für .NET Spark (C#/F#)
In diesem Abschnitt erstellen Sie eine Apache Spark-Auftragsdefinition für .NET Spark (C#/F#).
Öffnen Sie Azure Synapse Studio.
Sie können zu Beispieldateien zum Erstellen von Apache Spark-Auftragsdefinitionen navigieren, um Beispieldateien für dotnet.zip herunterzuladen. Entpacken Sie anschließend das komprimierte Paket, und extrahieren Sie die Dateien wordcount.zip und shakespeare.txt.
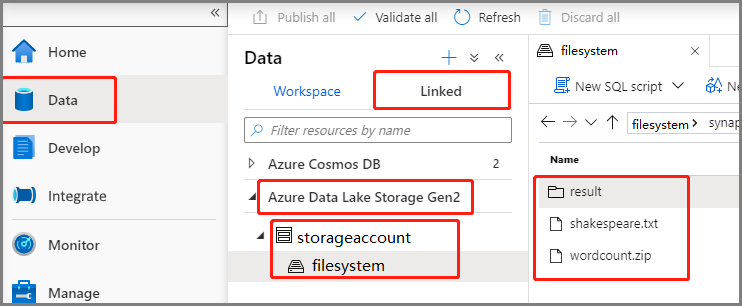
Wählen SieDaten>Verknüpft>Azure Data Lake Storage Gen2 aus, und laden Siewordcount.zip und shakespeare.txt in das ADLS Gen2-Dateisystem hoch.
Wählen Sie den Hub Entwickeln, das Plussymbol (+) und anschließend Spark-Auftragsdefinition aus, um eine neue Spark-Auftragsdefinition zu erstellen. (Die Beispielabbildung ist identisch mit der in Schritt 4 unter Erstellen einer Apache Spark-Auftragsdefinition für PySpark (Python) .)
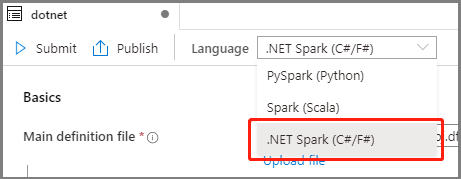
Wählen Sie in der Dropdownliste „Sprache“ im Hauptfenster der Apache Spark-Auftragsdefinition .NET Spark (C#/F#) aus.
Tragen Sie Informationen für die Apache Spark-Auftragsdefinition ein. Sie können die Beispielinformationen kopieren.
Eigenschaft BESCHREIBUNG Auftragsdefinitionsname Geben Sie einen Namen für Ihre Apache Spark-Auftragsdefinition ein. Dieser Name kann bis zur Veröffentlichung jederzeit aktualisiert werden.
Beispiel:dotnet„Main definition file“ (Hauptdefinitionsdatei) Die für den Auftrag verwendete Hauptdatei. Wählen Sie in Ihrem Speicher eine ZIP-Datei aus, die Ihre Anwendung vom Typ „.NET für Apache Spark“ enthält (ausführbare Hauptdatei, DLLs mit benutzerdefinierten Funktionen und andere erforderliche Dateien). Sie können Datei hochladen auswählen, um die Datei in ein Speicherkonto hochzuladen.
Beispiel:abfss://…/path/to/wordcount.zip„Main executable file“ (Ausführbare Hauptdatei) Die ausführbare Hauptdatei in der ZIP-Datei der Hauptdefinition.
Beispiel:WordCountBefehlszeilenargumente Optionale Argumente für den Auftrag.
Beispiel:abfss://…/path/to/shakespeare.txtabfss://…/path/to/result
Hinweis: Zwei Argumente für die Beispielauftragsdefinition werden durch ein Leerzeichen getrennt.„Reference files“ (Referenzdateien) Zusätzliche Dateien, die von den Workerknoten zum Ausführen der Anwendung vom Typ „.NET für Apache Spark“ benötigt werden und nicht in der ZIP-Datei der Hauptdefinition enthalten sind (also abhängige JAR-Dateien, zusätzliche DLLs mit benutzerdefinierten Funktionen sowie andere Konfigurationsdateien). Sie können Datei hochladen auswählen, um die Datei in ein Speicherkonto hochzuladen. Spark-Pool Der Auftrag wird an den ausgewählten Apache Spark-Pool übermittelt. Spark-Version Die vom Apache Spark-Pool ausgeführte Version von Apache Spark. Ausführer Die gewünschte Anzahl von Executors im angegebenen Apache Spark-Pool für den Auftrag. „Executor size“ (Executorgröße) Die Anzahl von Kernen und die Menge an Arbeitsspeicher, die für Executors im angegebenen Apache Spark-Pool für den Auftrag verwendet werden sollen. „Driver size“ (Treibergröße) Die Anzahl von Kernen und die Menge an Arbeitsspeicher, die für Treiber im angegebenen Apache Spark-Pool für den Auftrag verwendet werden sollen. Apache Spark-Konfiguration Passen Sie Konfigurationen an, indem Sie die unten aufgeführten Eigenschaften hinzufügen. Wenn Sie keine Eigenschaft hinzufügen, verwendet Azure Synapse ggf. den entsprechenden Standardwert. 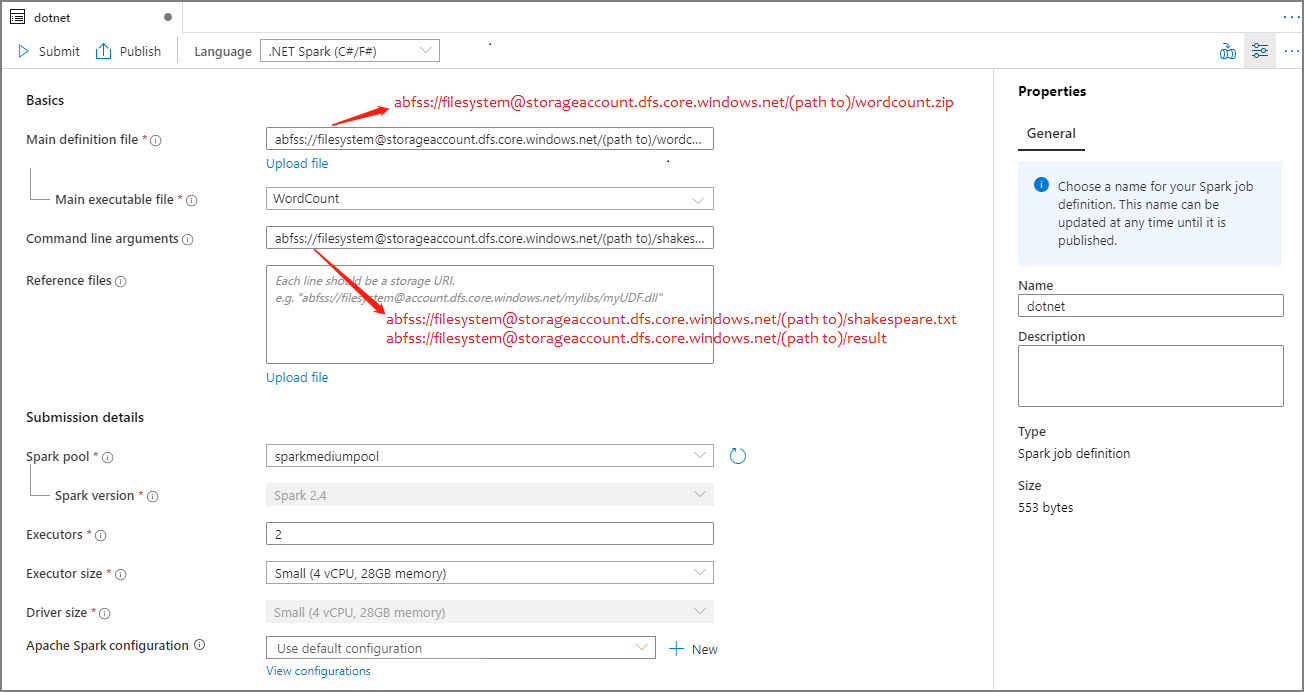
Wählen Sie Veröffentlichen aus, um die Apache Spark-Auftragsdefinition zu speichern.

Hinweis
Wenn durch die Apache Spark-Auftragsdefinition in der Apache Spark-Konfiguration keine spezielle Aktion ausgeführt wird, wird beim Ausführen des Auftrags die Standardkonfiguration verwendet.
Erstellen einer Apache Spark-Auftragsdefinition durch Importieren einer JSON-Datei
Sie können eine vorhandene lokale JSON-Datei über das Menü Aktionen (...) des Apache Spark-Auftragsdefinitions-Explorers in den Azure Synapse-Arbeitsbereich importieren, um eine neue Apache Spark-Auftragsdefinition zu erstellen.
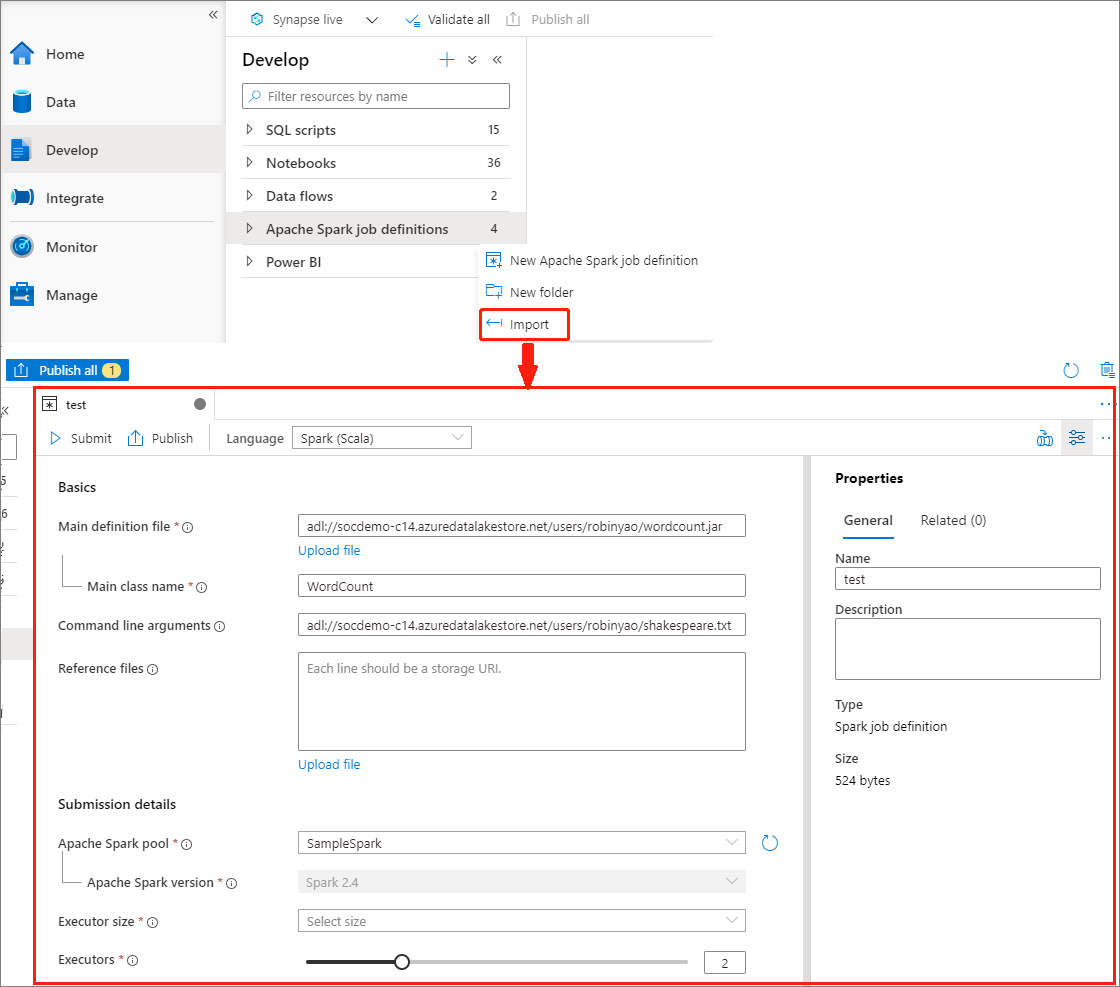
Die Spark-Auftragsdefinition ist vollständig mit der Livy-API kompatibel. Sie können zusätzliche Parameter für andere Livy-Eigenschaften (Livy-Dokumentation: REST-API (apache.org)) in der lokalen JSON-Datei hinzufügen. Sie können die Parameter für die Spark-Konfiguration auch wie unten gezeigt in der config-Eigenschaft angeben. Anschließend können Sie die JSON-Datei wieder importieren, um eine neue Apache Spark-Auftragsdefinition für den Batchauftrag zu erstellen. JSON-Beispiel für den Import der Spark-Definition:
{
"targetBigDataPool": {
"referenceName": "socdemolarge",
"type": "BigDataPoolReference"
},
"requiredSparkVersion": "2.3",
"language": "scala",
"jobProperties": {
"name": "robinSparkDefinitiontest",
"file": "adl://socdemo-c14.azuredatalakestore.net/users/robinyao/wordcount.jar",
"className": "WordCount",
"args": [
"adl://socdemo-c14.azuredatalakestore.net/users/robinyao/shakespeare.txt"
],
"jars": [],
"files": [],
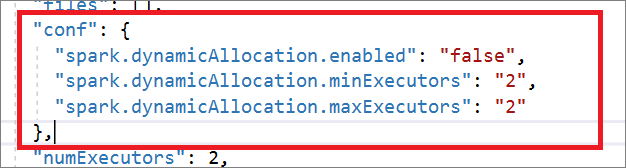
"conf": {
"spark.dynamicAllocation.enabled": "false",
"spark.dynamicAllocation.minExecutors": "2",
"spark.dynamicAllocation.maxExecutors": "2"
},
"numExecutors": 2,
"executorCores": 8,
"executorMemory": "24g",
"driverCores": 8,
"driverMemory": "24g"
}
}
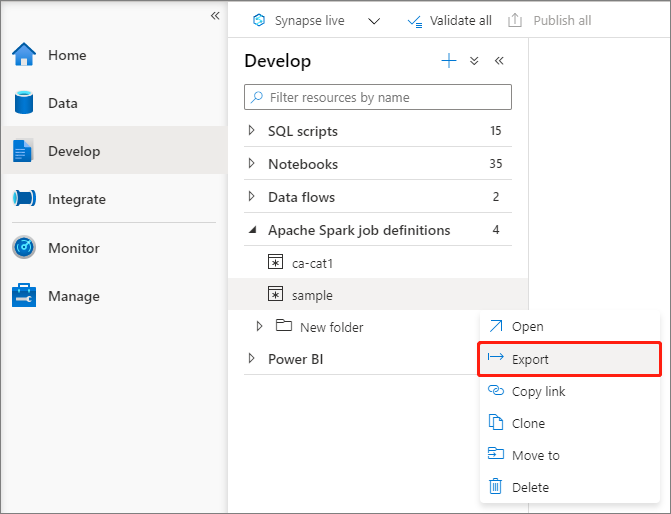
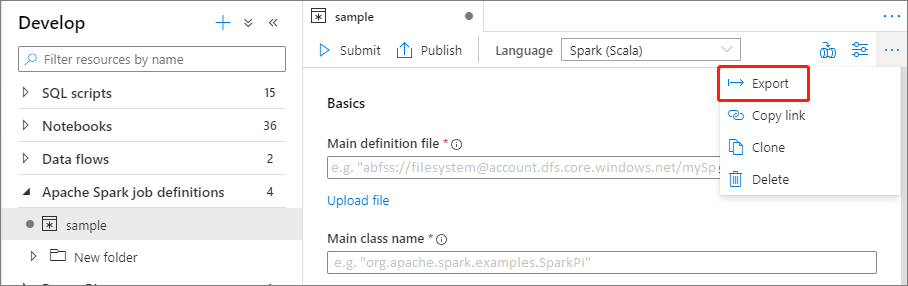
Exportieren einer vorhandenen Apache Spark-Auftragsdefinitionsdatei
Sie können vorhandene Apache Spark-Auftragsdefinitionsdateien über das Menü Aktionen (...) des Datei-Explorers in eine lokale Datei exportieren. Sie können die JSON-Datei für zusätzliche Livy-Eigenschaften weiter aktualisieren und sie wieder importieren, um bei Bedarf eine neue Auftragsdefinition zu erstellen.
Übermitteln einer Apache Spark-Auftragsdefinition als Batchauftrag
Nachdem Sie eine Apache Spark-Auftragsdefinition erstellt haben, können Sie sie an einen Apache Spark-Pool übermitteln. Stellen Sie sicher, dass Sie der Mitwirkende der Speicherblobdaten des ADLS Gen2-Dateisystems sind, das Sie verwenden möchten. Andernfalls müssen Sie die Berechtigung manuell hinzufügen.
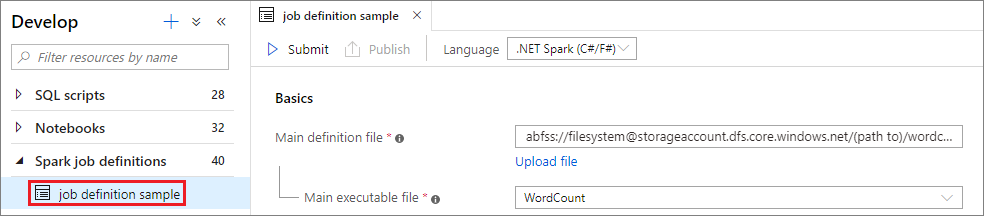
Szenario 1: Übermitteln einer Apache Spark-Auftragsdefinition
Öffnen Sie durch Auswählen ein Apache Spark-Auftragsdefinitionsfenster.
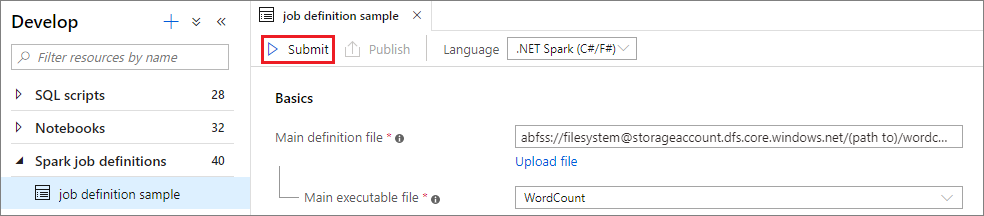
Wählen Sie die Schaltfläche Übermitteln aus, um Ihr Projekt an den ausgewählten Apache Spark-Pool zu übermitteln. Sie können die Registerkarte Spark monitoring URL (Spark-Überwachungs-URL) auswählen, um die Protokollabfrage der Apache Spark-Anwendung anzuzeigen.
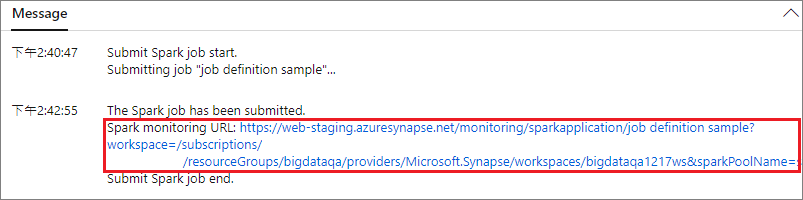
Szenario 2: Anzeigen des Status der Apache Spark-Auftragsausführung
Wählen Sie Überwachen und anschließend die Option Apache Spark-Anwendungen aus. Navigieren Sie zur übermittelten Apache Spark-Anwendung.
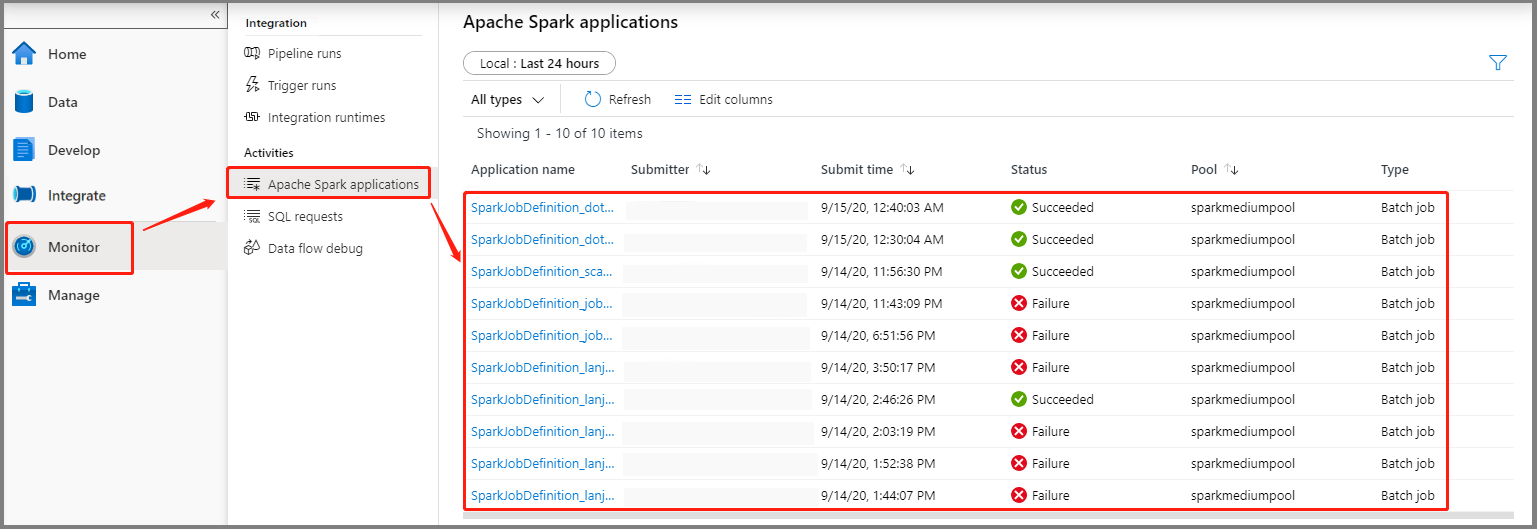
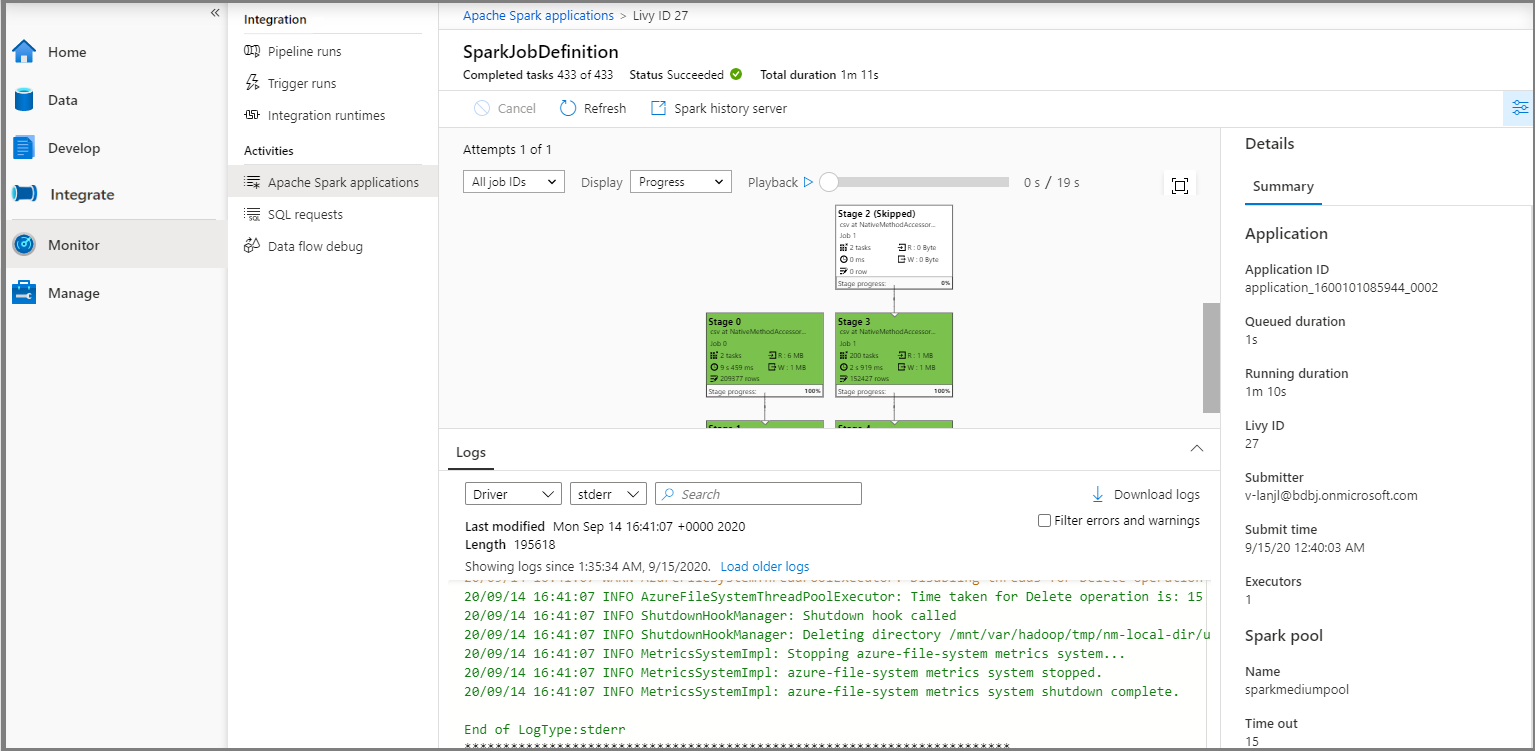
Wählen Sie dann eine Apache Spark-Anwendung aus. Daraufhin wird das Auftragsfenster SparkJobDefinition angezeigt. Sie können den Status der Auftragsausführung in diesem Fenster anzeigen.
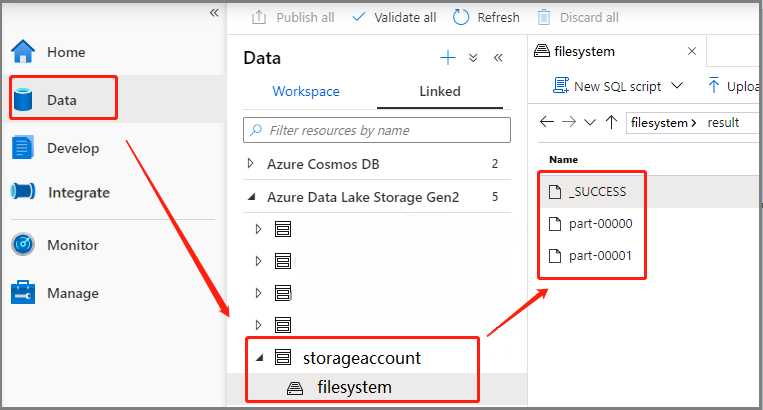
Szenario 3: Überprüfen der Ausgabedatei
Wählen Sie Daten>Verknüpft>Azure Data Lake Storage Gen2 (hozhaobdbj) aus, und öffnen Sie den zuvor erstellten Ordner result. Sie können zum Ordner „result“ navigieren und überprüfen, ob die Ausgabe generiert wurde.
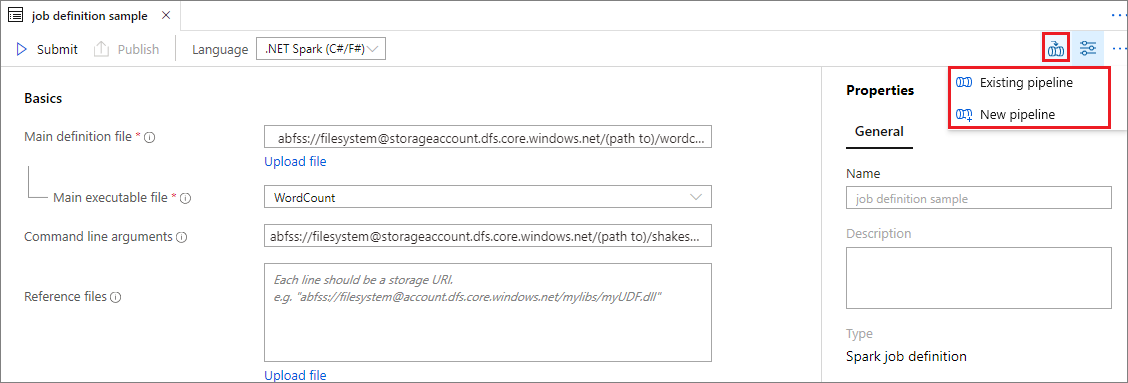
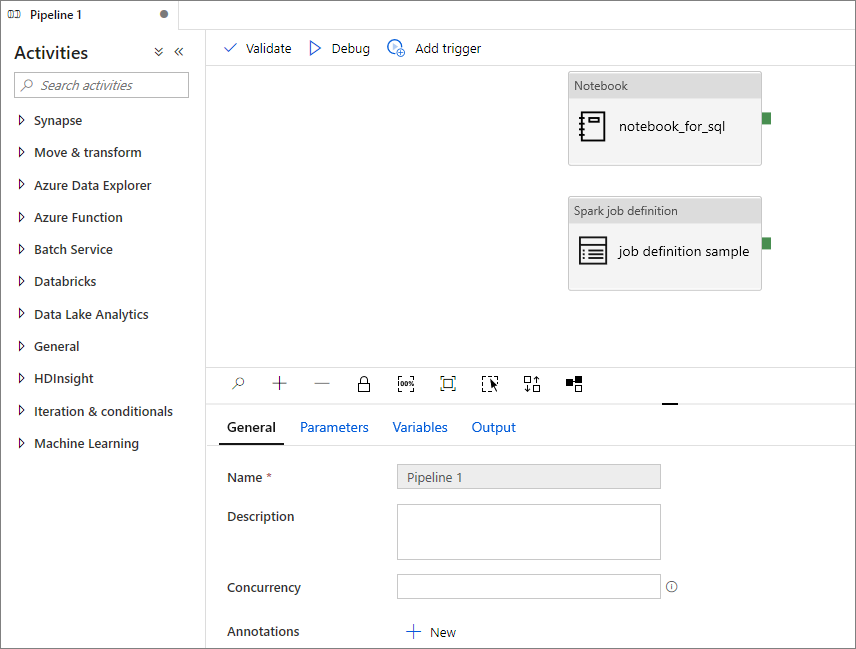
Hinzufügen einer Apache Spark-Auftragsdefinition in einer Pipeline
In diesem Abschnitt fügen Sie eine Apache Spark-Auftragsdefinition in einer Pipeline hinzu.
Öffnen Sie eine vorhandene Apache Spark-Auftragsdefinition.
Wählen Sie das Symbol rechts oben in der Apache Spark-Auftragsdefinition und anschließend Vorhandene Pipeline oder Neue Pipeline aus. Weitere Informationen finden Sie auf der Seite „Pipeline“.
Nächste Schritte
Als Nächstes können Sie Azure Synapse Studio verwenden, um Power BI-Datasets zu erstellen und Power BI-Daten zu verwalten. Weitere Informationen finden Sie im Artikel Schnellstart: Verknüpfen eines Power BI-Arbeitsbereichs mit einem Synapse-Arbeitsbereich.