Verwalten von sitzungsbezogenen Paketen
Zusätzlich zu den Paketen auf Poolebene können Sie zu Beginn einer Notebook-Sitzung auch sitzungsbezogene Bibliotheken angeben. Mithilfe sitzungsbezogener Bibliotheken können Sie Python-, JAR- und R-Pakete innerhalb einer Notebooksitzung angeben und verwenden.
Bei der Verwendung sitzungsbezogener Bibliotheken sind folgende Punkte zu berücksichtigen:
- Wenn Sie sitzungsbezogene Bibliotheken installieren, kann nur das aktuelle Notebook auf die angegebenen Bibliotheken zugreifen.
- Diese Bibliotheken wirken sich nicht auf andere Sitzungen oder Aufträge aus, die denselben Spark-Pool verwenden.
- Diese Bibliotheken werden zusätzlich zur Basisruntime und den Bibliotheken auf Poolebene installiert und haben die höchste Priorität.
- Sitzungsbezogene Bibliotheken werden nicht sitzungsübergreifend beibehalten.
Sitzungsbezogene Python-Pakete
Verwalten sitzungsbezogener Python-Pakete über die Datei environment.yml
So geben Sie sitzungsbezogene Python-Pakete an
- Navigieren Sie zum ausgewählten Spark-Pool, und stellen Sie sicher, dass Sie Bibliotheken auf Sitzungsebene aktiviert haben. Sie können diese Einstellung aktivieren, indem Sie zu Verwalten>Apache Spark-Pool>Registerkarte Pakete navigieren.
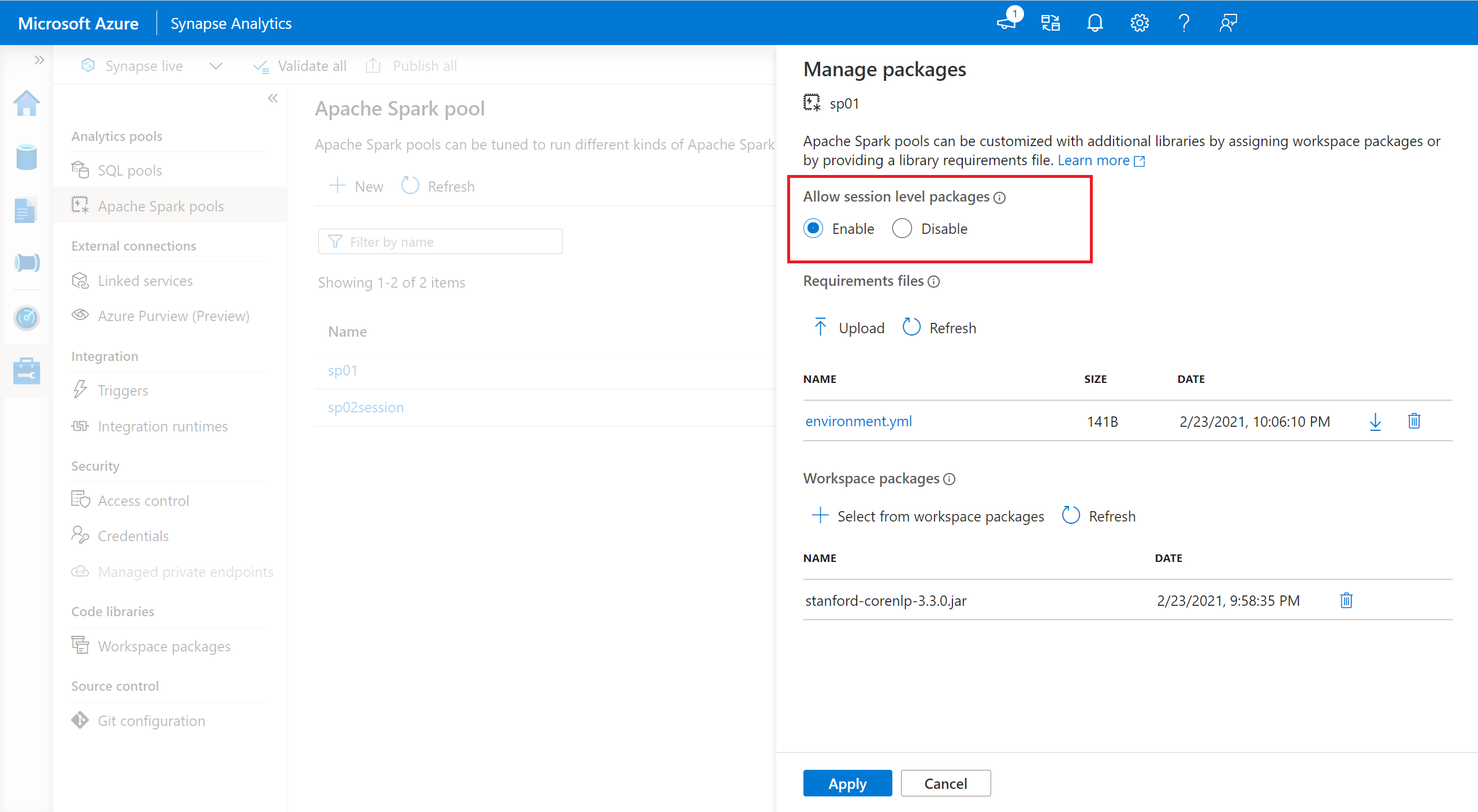
- Sobald die Einstellung angewendet wird, können Sie ein Notebook öffnen und Sitzung konfigurieren>Pakete auswählen.

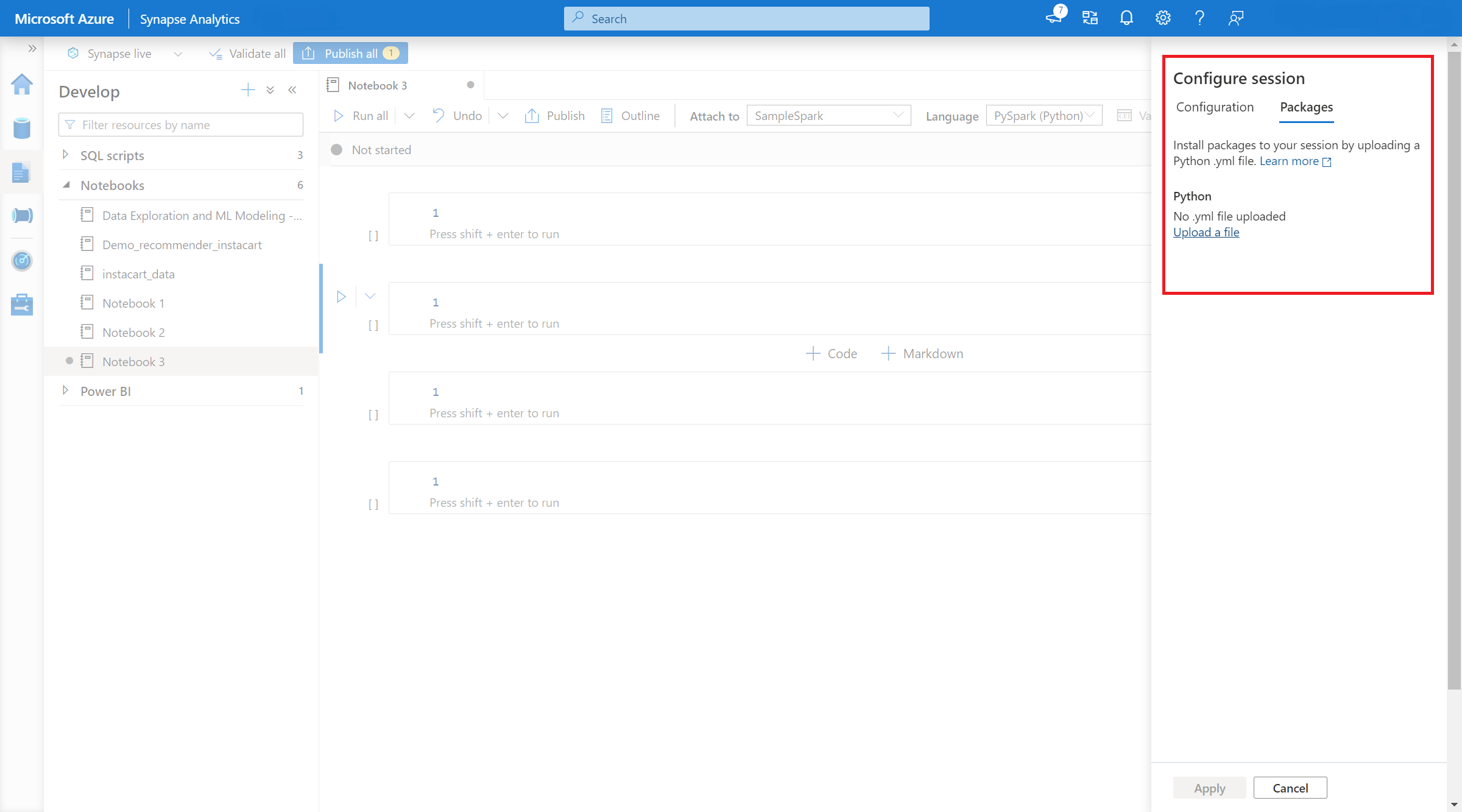
- Hier können Sie eine Conda-environment.yml-Datei hochladen, um Pakete innerhalb einer Sitzung zu installieren oder zu aktualisieren. Die angegebenen Bibliotheken sind vorhanden, sobald die Sitzung gestartet wird. Diese Bibliotheken sind nach dem Ende der Sitzung nicht mehr verfügbar.

Verwalten von Python-Paketen im Sitzungsbereich über %pip- und %conda-Befehle
Sie können die beliebten %pip- und %conda-Befehle verwenden, um zusätzliche Bibliotheken von Drittanbietern oder Ihre benutzerdefinierten Bibliotheken während Ihrer Apache Spark-Notebooksitzung zu installieren. In diesem Abschnitt verwenden wir %pip-Befehle, um mehrere gängige Szenarien zu veranschaulichen.
Hinweis
- Wir empfehlen die %pip- und %conda-Befehle am Anfang Ihres Notebooks zu platzieren, wenn Sie neue Bibliotheken installieren möchten. Der Python-Interpreter wird neu gestartet, nachdem die Bibliothek auf Sitzungsebene verwaltet wurde, um die Änderungen wirksam zu machen.
- Diese Befehle zum Verwalten von Python-Bibliotheken werden beim Ausführen von Pipelineaufträgen deaktiviert. Wenn Sie ein Paket innerhalb einer Pipeline installieren möchten, müssen Sie die Funktionen zur Bibliotheksverwaltung auf Poolebene nutzen.
- Sitzungsbezogene Python-Bibliotheken werden automatisch auf den Treiber- und Workerknoten installiert.
- Die folgenden %conda-Befehle werden nicht unterstützt: erstellen, bereinigen, vergleichen, aktivieren, deaktivieren, ausführen, paketieren.
- Die vollständige Liste der verfügbaren Befehle finden Sie in diesen Artikeln zu %pip-Befehlen und %conda-Befehlen.
Installieren eines Drittanbieterpakets
Sie können eine Python-Bibliothek ganz einfach über PyPI installieren.
# Install vega_datasets
%pip install altair vega_datasets
Um das Installationsergebnis zu überprüfen, können Sie den folgenden Code ausführen, um vega_datasets zu visualisieren.
# Create a scatter plot
# Plot Miles per gallon against the horsepower across different region
import altair as alt
from vega_datasets import data
cars = data.cars()
alt.Chart(cars).mark_point().encode(
x='Horsepower',
y='Miles_per_Gallon',
color='Origin',
).interactive()
Installieren eines Wheel-Pakets über ein Speicherkonto
Um die Bibliothek aus dem Speicher zu installieren, müssen Sie die folgenden Befehle zum Einbinden in Ihr Speicherkonto ausführen.
from notebookutils import mssparkutils
mssparkutils.fs.mount(
"abfss://<<file system>>@<<storage account>.dfs.core.windows.net",
"/<<path to wheel file>>",
{"linkedService":"<<storage name>>"}
)
Anschließend können Sie den Befehl %pip install verwenden, um das erforderliche Wheel-Paket zu installieren.
%pip install /<<path to wheel file>>/<<wheel package name>>.whl
Installieren einer anderen Version der integrierten Bibliothek
Sie können den folgenden Befehl verwenden, um die integrierte Version eines bestimmten Pakets zu ermitteln. Wir verwenden pandas als Beispiel.
%pip show pandas
Das Ergebnis ist wie das folgende Protokoll:
Name: pandas
Version: **1.2.3**
Summary: Powerful data structures for data analysis, time series, and statistics
Home-page: https://pandas.pydata.org
... ...
Sie können den folgenden Befehl verwenden, um die Version von pandas zu wechseln, z. B. zu 1.2.4.
%pip install pandas==1.2.4
Deinstallieren einer sitzungsbezogenen Bibliothek
Wenn Sie ein Paket deinstallieren möchten, das in dieser Notebooksitzung installiert wird, können Sie die folgenden Befehle verwenden. Sie können die integrierten Pakete jedoch nicht deinstallieren.
%pip uninstall altair vega_datasets --yes
Verwenden des %pip-Befehls zum Installieren von Bibliotheken aus einer requirement.txt-Datei
%pip install -r /<<path to requirement file>>/requirements.txt
Sitzungsbereichs-Java- oder Scala-Pakete
Sitzungsbezogene Java- oder Scala-Pakete können über die Option %%configure angegeben werden:
%%configure -f
{
"conf": {
"spark.jars": "abfss://<<file system>>@<<storage account>.dfs.core.windows.net/<<path to JAR file>>",
}
}
Hinweis
- Wir empfehlen Ihnen, %%configure am Anfang Ihres Notebooks auszuführen. In diesem Dokument finden Sie eine vollständige Liste gültiger Parameter.
Sitzungsbezogene R-Pakete (Vorschau)
In den Azure Synapse Analytics-Pools sind viele populäre R-Bibliotheken bereits enthalten. Sie können auch während Ihrer Apache Spark-Notebooksitzung zusätzliche Bibliotheken von Drittanbietern installieren.
Hinweis
- Diese Befehle zum Verwalten von R-Bibliotheken werden beim Ausführen von Pipelineaufträgen deaktiviert. Wenn Sie ein Paket innerhalb einer Pipeline installieren möchten, müssen Sie die Funktionen zur Bibliotheksverwaltung auf Poolebene nutzen.
- Sitzungsbezogene R-Bibliotheken werden automatisch auf den Treiber- und Workerknoten installiert.
Installieren eines Pakets
Sie können eine R-Bibliothek ganz einfach über CRAN installieren.
# Install a package from CRAN
install.packages(c("nycflights13", "Lahman"))
Sie können zudem CRAN-Momentaufnahmen als Repository verwenden, um sicherzustellen, dass immer dieselbe Paketversion heruntergeladen wird.
install.packages("highcharter", repos = "https://cran.microsoft.com/snapshot/2021-07-16/")
Verwenden von Devtools zum Installieren von Paketen
Die devtools-Bibliothek vereinfacht die Paketentwicklung, um gängige Aufgaben zu beschleunigen. Diese Bibliothek wird in der standardmäßigen Azure Synapse Analytics-Runtime installiert.
Sie können mit devtools eine bestimmte Version einer zu installierenden Bibliothek angeben. Diese Bibliotheken werden auf allen Knoten innerhalb des Clusters installiert.
# Install a specific version.
install_version("caesar", version = "1.0.0")
Auf ähnliche Weise können Sie eine Bibliothek direkt aus GitHub installieren.
# Install a GitHub library.
install_github("jtilly/matchingR")
Derzeit unterstützt Azure Synapse Analytics die folgenden devtools-Funktionen:
| Befehl | BESCHREIBUNG |
|---|---|
| install_github() | Installiert ein R-Paket aus GitHub |
| install_gitlab() | Installiert ein R-Paket aus GitLab |
| install_bitbucket() | Installiert ein R-Paket aus BitBucket |
| install_url() | Installiert ein R-Paket über eine beliebige URL |
| install_git() | Installation über ein beliebiges Git-Repository |
| install_local() | Installation über eine lokale Datei auf dem Datenträger |
| install_version() | Installation über eine bestimmte Version aus CRAN |
Anzeigen der installierten Bibliotheken
Sie können alle in Ihrer Sitzung installierten Bibliotheken über den Befehl library abfragen.
library()
Mithilfe der Funktion packageVersion können Sie die Version der Bibliothek überprüfen:
packageVersion("caesar")
Entfernen eines R-Pakets aus einer Sitzung
Sie können die Funktion detach verwenden, um eine Bibliothek aus dem Namespace zu entfernen. Diese Bibliotheken verbleiben auf dem Datenträger, bis sie erneut geladen werden.
# detach a library
detach("package: caesar")
Zum Entfernen eines sitzungsbezogenen Pakets aus einem Notebook verwenden Sie den Befehl remove.packages(). Diese Bibliotheksänderung hat keine Auswirkungen auf andere Sitzungen im selben Cluster. Bibliotheken der Standardruntime von Azure Synapse Analytics können nicht durch Benutzer deinstalliert oder entfernt werden.
remove.packages("caesar")
Hinweis
Sie können Kernpakete wie SparkR, SparklyR oder R nicht entfernen.
Sitzungsbezogene R-Bibliotheken und SparkR
Bibliotheken im Notebook-Bereich sind in SparkR-Workern verfügbar.
install.packages("stringr")
library(SparkR)
str_length_function <- function(x) {
library(stringr)
str_length(x)
}
docs <- c("Wow, I really like the new light sabers!",
"That book was excellent.",
"R is a fantastic language.",
"The service in this restaurant was miserable.",
"This is neither positive or negative.")
spark.lapply(docs, str_length_function)
Sitzungsbezogene R-Bibliotheken und SparklyR
Mithilfe von „spark_apply()“ in SparklyR können Sie jedes R-Paket innerhalb von Spark verwenden. In „sparklyr::spark_apply()“ ist das Argument „packages“ standardmäßig auf FALSE festgelegt. Dadurch werden die Bibliotheken in die aktuelle libPaths-Funktion der Worker kopiert, um sie in die Worker zu importieren und dort zu nutzen. Sie können zum Beispiel den folgenden Befehl ausführen, um mit „sparklyr::spark_apply()“ eine Nachricht mit Caesar-Verschlüsselung zu generieren:
install.packages("caesar", repos = "https://cran.microsoft.com/snapshot/2021-07-16/")
spark_version <- "3.2"
config <- spark_config()
sc <- spark_connect(master = "yarn", version = spark_version, spark_home = "/opt/spark", config = config)
apply_cases <- function(x) {
library(caesar)
caesar("hello world")
}
sdf_len(sc, 5) %>%
spark_apply(apply_cases, packages=FALSE)
Nächste Schritte
- Anzeigen der Standardbibliotheken: Versionsunterstützung für Apache Spark
- Verwalten der Pakete außerhalb des Synapse Studio-Portals: Verwalten von Paketen über Az-Befehle und REST-APIs