Einführung in Microsoft Spark-Hilfsprogramme
Microsoft Spark-Hilfsprogramme (MSSparkUtils) sind ein integriertes Paket, mit dem sich gängige Aufgaben leichter erledigen lassen. Sie können MSSparkUtils verwenden, um mit Dateisystemen zu arbeiten, Umgebungsvariablen zu erhalten, Notebooks miteinander zu verketten und mit Geheimnissen zu arbeiten. MSSparkUtils sind in den Notebooks PySpark (Python), Scala, .NET Spark (C#) und R (Preview) sowie in Synapse-Pipelines verfügbar.
Voraussetzungen
Konfigurieren des Zugriffs auf Azure Data Lake Storage Gen2
Synapse-Notebooks verwenden Microsoft Entra-Passthrough für den Zugriff auf den ADLS Gen2-Konten. Sie müssen Mitwirkender an Storage-Blobdaten sein, um auf das ADLS Gen2-Konto (oder den Ordner) zugreifen zu können.
Synapse-Pipelines verwenden die Managed Service Identity (MSI) des Arbeitsbereichs für den Zugriff auf die Speicherkonten. Um MSSparkUtils in Ihren Pipelineaktivitäten zu verwenden, muss Ihre Arbeitsbereichsidentität Mitwirkender an Storage-Blobdaten sein, um auf das ADLS Gen2-Konto (oder den Ordner) zuzugreifen.
Gehen Sie folgendermaßen vor, um sicherzustellen, dass Ihr Microsoft Entra- und Arbeitsbereichs-MSI Zugriff auf das ADLS Gen2-Konto haben:
Öffnen Sie das Azure-Portal und das Speicherkonto, auf das sie zugreifen möchten. Sie können zu dem spezifischen Container navigieren, auf den Sie zugreifen möchten.
Wählen Sie im linken Bereich Zugriffssteuerung (IAM) aus.
Wählen Sie Hinzufügen>Rollenzuweisung hinzufügen aus, um den Bereich „Rollenzuweisung hinzufügen“ zu öffnen.
Weisen Sie die folgende Rolle zu. Ausführliche Informationen finden Sie unter Zuweisen von Azure-Rollen über das Azure-Portal.
Einstellung Wert Role Mitwirkender an Storage-Blobdaten Zugriff zuweisen zu USER und MANAGEDIDENTITY Member Ihr Microsoft Entra-Konto und Ihre Arbeitsbereichsidentität Hinweis
Der Name der verwalteten Identität ist auch der Name des Arbeitsbereichs.

Wählen Sie Speichern aus.
Sie können über die folgende URL mithilfe von Synapse Spark auf Daten in ADLS Gen2 zugreifen:
abfss://<container_name>@<storage_account_name>.dfs.core.windows.net/<path>
Konfigurieren des Zugriffs auf Azure Blob Storage
Synapse verwendet Shared Access Signature (SAS) für den Zugriff auf Azure Blob Storage. Um das Verfügbarmachen von SAS-Schlüsseln im Code zu vermeiden, empfehlen wir, im Synapse-Arbeitsbereich einen neuen verknüpften Dienst mit dem Azure Blob Storage Konto zu erstellen, auf das Sie zugreifen möchten.
Befolgen Sie diese Schritte, um einen neuen verknüpften Dienst für ein Azure Blob Storage-Konto hinzuzufügen:
- Öffnen Sie Azure Synapse Studio.
- Wählen Sie im linken Bereich Verwalten aus, und wählen Sie unter Externe Verbindungen die Option Verknüpfte Dienste aus.
- Suchen Sie rechts im Bereich Neuer verknüpfter Dienst nach Azure Blob Storage.
- Wählen Sie Weiter.
- Wählen Sie das Azure Blob Storage-Konto aus, auf das zugegriffen werden soll, und konfigurieren Sie den Namen des verknüpften Diensts. Schlagen Sie vor, Kontoschlüssel als Authentifizierungsmethode zu verwenden.
- Wählen Sie Verbindung testen aus, um die Richtigkeit der Einstellungen zu überprüfen.
- Wählen Sie zuerst Erstellen und dann Alle veröffentlichen aus, um Ihre Änderungen zu speichern.
Sie können über die folgende URL mithilfe von Synapse Spark auf Daten in Azure Blob Storage zugreifen:
wasb[s]://<container_name>@<storage_account_name>.blob.core.windows.net/<path>
Hier finden Sie ein Codebeispiel:
from pyspark.sql import SparkSession
# Azure storage access info
blob_account_name = 'Your account name' # replace with your blob name
blob_container_name = 'Your container name' # replace with your container name
blob_relative_path = 'Your path' # replace with your relative folder path
linked_service_name = 'Your linked service name' # replace with your linked service name
blob_sas_token = mssparkutils.credentials.getConnectionStringOrCreds(linked_service_name)
# Allow SPARK to access from Blob remotely
wasb_path = 'wasbs://%s@%s.blob.core.windows.net/%s' % (blob_container_name, blob_account_name, blob_relative_path)
spark.conf.set('fs.azure.sas.%s.%s.blob.core.windows.net' % (blob_container_name, blob_account_name), blob_sas_token)
print('Remote blob path: ' + wasb_path)
val blob_account_name = "" // replace with your blob name
val blob_container_name = "" //replace with your container name
val blob_relative_path = "/" //replace with your relative folder path
val linked_service_name = "" //replace with your linked service name
val blob_sas_token = mssparkutils.credentials.getConnectionStringOrCreds(linked_service_name)
val wasbs_path = f"wasbs://$blob_container_name@$blob_account_name.blob.core.windows.net/$blob_relative_path"
spark.conf.set(f"fs.azure.sas.$blob_container_name.$blob_account_name.blob.core.windows.net",blob_sas_token)
var blob_account_name = ""; // replace with your blob name
var blob_container_name = ""; // replace with your container name
var blob_relative_path = ""; // replace with your relative folder path
var linked_service_name = ""; // replace with your linked service name
var blob_sas_token = Credentials.GetConnectionStringOrCreds(linked_service_name);
spark.Conf().Set($"fs.azure.sas.{blob_container_name}.{blob_account_name}.blob.core.windows.net", blob_sas_token);
var wasbs_path = $"wasbs://{blob_container_name}@{blob_account_name}.blob.core.windows.net/{blob_relative_path}";
Console.WriteLine(wasbs_path);
# Azure storage access info
blob_account_name <- 'Your account name' # replace with your blob name
blob_container_name <- 'Your container name' # replace with your container name
blob_relative_path <- 'Your path' # replace with your relative folder path
linked_service_name <- 'Your linked service name' # replace with your linked service name
blob_sas_token <- mssparkutils.credentials.getConnectionStringOrCreds(linked_service_name)
# Allow SPARK to access from Blob remotely
sparkR.session()
wasb_path <- sprintf('wasbs://%s@%s.blob.core.windows.net/%s',blob_container_name, blob_account_name, blob_relative_path)
sparkR.session(sprintf('fs.azure.sas.%s.%s.blob.core.windows.net',blob_container_name, blob_account_name), blob_sas_token)
print( paste('Remote blob path: ',wasb_path))
Konfigurieren des Zugriffs auf Azure Key Vault
Sie können einen Azure Key Vault als verknüpften Dienst hinzufügen, um Ihre Anmeldeinformationen in Synapse zu verwalten. Befolgen Sie diese Schritte, um einen Azure Key Vault als verknüpften Synapse-Dienst hinzuzufügen:
Öffnen Sie Azure Synapse Studio.
Wählen Sie im linken Bereich Verwalten aus, und wählen Sie unter Externe Verbindungen die Option Verknüpfte Dienste aus.
Suchen Sie rechts im Bereich Neuer verknüpfter Dienst nach Azure Key Vault.
Wählen Sie das Azure Key Vault-Konto aus, auf das zugegriffen werden soll, und konfigurieren Sie den Namen des verknüpften Diensts.
Wählen Sie Verbindung testen aus, um die Richtigkeit der Einstellungen zu überprüfen.
Wählen Sie zuerst Erstellen und dann Alle veröffentlichen aus, um Ihre Änderungen zu speichern.
Synapse-Notebooks verwenden Microsoft Entra-Passthrough für den Zugriff auf Azure Key Vault. Synapse-Pipelines verwenden die Arbeitsbereichsidentität (MSI) für den Zugriff auf Azure Key Vault. Um sicherzustellen, dass Ihr Code sowohl im Notebook als auch in der Synapse-Pipeline funktioniert, empfiehlt es sich, sowohl Ihrem Microsoft Entra-Konto als auch Ihrer Arbeitsbereichsidentität Zugriffsberechtigung auf das Geheimnis zu gewähren.
Führen Sie diese Schritte aus, um Ihrer Arbeitsbereichsidentität Zugriff auf das Geheimnis zu gewähren:
- Öffnen Sie das Azure-Portal und den Azure Key Vault, auf den sie zugreifen möchten.
- Wählen Sie im linken Bereich Zugriffsrichtlinien aus.
- Wählen Sie Zugriffsrichtlinie hinzufügen aus:
- Wählen sie Verwaltung von Schlüsseln, Geheimnissen und Zertifikaten als Konfigurationsvorlage aus.
- Wählen Sie in „Prinzipal auswählen“ Ihr Microsoft Entra-Konto und Ihre Arbeitsbereichsidentität (identisch mit Ihrem Arbeitsbereichsnamen) aus, oder stellen Sie sicher, dass sie bereits zugewiesen sind.
- Wählen Sie Auswählen und Hinzufügen aus.
- Wählen Sie die Schaltfläche Speichern aus, um Änderungen zu übernehmen.
Dateisystem-Hilfsprogramme
mssparkutils.fs stellt Hilfsprogramme für die Arbeit mit verschiedenen Dateisystemen bereit, einschließlich Azure Data Lake Storage Gen2 (ADLS Gen2) und Azure Blob Storage. Stellen Sie sicher, dass Sie den Zugriff auf Azure Data Lake Storage Gen2 und Azure Blob Storage entsprechend konfigurieren.
Führen Sie die folgenden Befehle aus, um eine Übersicht über die verfügbaren Methoden zu erhalten:
from notebookutils import mssparkutils
mssparkutils.fs.help()
mssparkutils.fs.help()
using Microsoft.Spark.Extensions.Azure.Synapse.Analytics.Notebook.MSSparkUtils;
FS.Help()
library(notebookutils)
mssparkutils.fs.help()
Ergebnis:
mssparkutils.fs provides utilities for working with various FileSystems.
Below is overview about the available methods:
cp(from: String, to: String, recurse: Boolean = false): Boolean -> Copies a file or directory, possibly across FileSystems
mv(src: String, dest: String, create_path: Boolean = False, overwrite: Boolean = False): Boolean -> Moves a file or directory, possibly across FileSystems
ls(dir: String): Array -> Lists the contents of a directory
mkdirs(dir: String): Boolean -> Creates the given directory if it does not exist, also creating any necessary parent directories
put(file: String, contents: String, overwrite: Boolean = false): Boolean -> Writes the given String out to a file, encoded in UTF-8
head(file: String, maxBytes: int = 1024 * 100): String -> Returns up to the first 'maxBytes' bytes of the given file as a String encoded in UTF-8
append(file: String, content: String, createFileIfNotExists: Boolean): Boolean -> Append the content to a file
rm(dir: String, recurse: Boolean = false): Boolean -> Removes a file or directory
Use mssparkutils.fs.help("methodName") for more info about a method.
Auflisten von Dateien
Listet den Inhalt eines Verzeichnisses auf.
mssparkutils.fs.ls('Your directory path')
mssparkutils.fs.ls("Your directory path")
FS.Ls("Your directory path")
mssparkutils.fs.ls("Your directory path")
Anzeigen von Dateieigenschaften
Gibt Dateieigenschaften zurück, einschließlich Dateiname, Dateipfad, Dateigröße, Dateiänderungszeit, und ob es sich um ein Verzeichnis oder eine Datei handelt.
files = mssparkutils.fs.ls('Your directory path')
for file in files:
print(file.name, file.isDir, file.isFile, file.path, file.size, file.modifyTime)
val files = mssparkutils.fs.ls("/")
files.foreach{
file => println(file.name,file.isDir,file.isFile,file.size,file.modifyTime)
}
var Files = FS.Ls("/");
foreach(var File in Files) {
Console.WriteLine(File.Name+" "+File.IsDir+" "+File.IsFile+" "+File.Size);
}
files <- mssparkutils.fs.ls("/")
for (file in files) {
writeLines(paste(file$name, file$isDir, file$isFile, file$size, file$modifyTime))
}
Neues Verzeichnis erstellen
Erstellt das angegebene Verzeichnis, wenn es noch nicht vorhanden ist, sowie alle erforderlichen übergeordneten Verzeichnisse.
mssparkutils.fs.mkdirs('new directory name')
mssparkutils.fs.mkdirs("new directory name")
FS.Mkdirs("new directory name")
mssparkutils.fs.mkdirs("new directory name")
Datei kopieren
Kopiert eine Datei oder ein Verzeichnis. Unterstützt das Kopieren zwischen Dateisystemen.
mssparkutils.fs.cp('source file or directory', 'destination file or directory', True)# Set the third parameter as True to copy all files and directories recursively
mssparkutils.fs.cp("source file or directory", "destination file or directory", true) // Set the third parameter as True to copy all files and directories recursively
FS.Cp("source file or directory", "destination file or directory", true) // Set the third parameter as True to copy all files and directories recursively
mssparkutils.fs.cp('source file or directory', 'destination file or directory', True)
Leistungsfähiges Kopieren von Dateien
Diese Methode bietet eine schnellere Möglichkeit zum Kopieren oder Verschieben von Dateien, insbesondere bei großen Datenmengen.
mssparkutils.fs.fastcp('source file or directory', 'destination file or directory', True) # Set the third parameter as True to copy all files and directories recursively
Hinweis
Die Methode unterstützt nur in Azure Synapse Runtime für Apache Spark 3.3 und Azure Synapse Runtime für Apache Spark 3.4.
Vorschau von Dateiinhalt anzeigen
Gibt bis zu den ersten „maxBytes“ Bytes der angegebenen Datei als Zeichenfolge zurück, die in UTF-8 codiert ist.
mssparkutils.fs.head('file path', maxBytes to read)
mssparkutils.fs.head("file path", maxBytes to read)
FS.Head("file path", maxBytes to read)
mssparkutils.fs.head('file path', maxBytes to read)
Datei verschieben
Verschiebt eine Datei oder ein Verzeichnis. Unterstützt das Verschieben zwischen Dateisystemen.
mssparkutils.fs.mv('source file or directory', 'destination directory', True) # Set the last parameter as True to firstly create the parent directory if it does not exist
mssparkutils.fs.mv("source file or directory", "destination directory", true) // Set the last parameter as True to firstly create the parent directory if it does not exist
FS.Mv("source file or directory", "destination directory", true)
mssparkutils.fs.mv('source file or directory', 'destination directory', True) # Set the last parameter as True to firstly create the parent directory if it does not exist
Datei schreiben
Schreibt die angegebene Zeichenfolge als Ausgabe in eine Datei, codiert in UTF-8.
mssparkutils.fs.put("file path", "content to write", True) # Set the last parameter as True to overwrite the file if it existed already
mssparkutils.fs.put("file path", "content to write", true) // Set the last parameter as True to overwrite the file if it existed already
FS.Put("file path", "content to write", true) // Set the last parameter as True to overwrite the file if it existed already
mssparkutils.fs.put("file path", "content to write", True) # Set the last parameter as True to overwrite the file if it existed already
Inhalt an eine Datei anfügen
Fügt die angegebene Zeichenfolge an eine Datei an, codiert in UTF-8.
mssparkutils.fs.append("file path", "content to append", True) # Set the last parameter as True to create the file if it does not exist
mssparkutils.fs.append("file path","content to append",true) // Set the last parameter as True to create the file if it does not exist
FS.Append("file path", "content to append", true) // Set the last parameter as True to create the file if it does not exist
mssparkutils.fs.append("file path", "content to append", True) # Set the last parameter as True to create the file if it does not exist
Datei oder Verzeichnis löschen
Entfernt eine Datei oder ein Verzeichnis.
mssparkutils.fs.rm('file path', True) # Set the last parameter as True to remove all files and directories recursively
mssparkutils.fs.rm("file path", true) // Set the last parameter as True to remove all files and directories recursively
FS.Rm("file path", true) // Set the last parameter as True to remove all files and directories recursively
mssparkutils.fs.rm('file path', True) # Set the last parameter as True to remove all files and directories recursively
Notebook-Utilities
Wird nicht unterstützt.
Sie können die MSSparkUtils Notebook Utilities verwenden, um ein Notebook auszuführen oder ein Notebook mit einem Wert zu beenden. Führen Sie den folgenden Befehl aus, um eine Übersicht über die verfügbaren Methoden zu erhalten:
mssparkutils.notebook.help()
Erzielen Sie Ergebnisse:
The notebook module.
exit(value: String): void -> This method lets you exit a notebook with a value.
run(path: String, timeoutSeconds: int, arguments: Map): String -> This method runs a notebook and returns its exit value.
Hinweis
Notebook-Dienstprogramme gelten nicht für Apache Spark-Auftragsdefinitionen (SJD).
Verweis auf ein Notizbuch
Verweist auf ein Notizbuch und gibt dessen Exit-Wert zurück. Sie können Verschachtelungsfunktionsaufrufe in einem Notebook interaktiv oder in einer Pipeline ausführen. Das Notebook, auf das verwiesen wird, wird auf dem Spark-Pool ausgeführt, dessen Notebook diese Funktion aufruft.
mssparkutils.notebook.run("notebook path", <timeoutSeconds>, <parameterMap>)
Beispiel:
mssparkutils.notebook.run("folder/Sample1", 90, {"input": 20 })
Nachdem die Ausführung abgeschlossen ist, wird ein Momentaufnahmelink namens Notebookausführung anzeigen: Notebookname in der Zellausgabe angezeigt. Sie können auf den Link klicken, um die Momentaufnahme für diese Ausführung anzuzeigen.

Parallele Referenzausführung mehrerer Notizbücher
Mit der Methode mssparkutils.notebook.runMultiple() können Sie mehrere Notebooks parallel oder mit einer vordefinierten topologischen Struktur ausführen. Die API verwendet einen Multithread-Implementierungsmechanismus innerhalb einer Spark-Sitzung, was bedeutet, dass die Computeressourcen vom Referenznotebook gemeinsam genutzt werden.
Mit mssparkutils.notebook.runMultiple() haben Sie folgende Möglichkeiten:
Führen Sie mehrere Notebooks gleichzeitig aus, ohne darauf zu warten, dass die einzelnen Notebooks abgeschlossen sind.
Geben Sie die Abhängigkeiten und die Reihenfolge der Ausführung für Ihre Notebooks mithilfe eines einfachen JSON-Formats an.
Optimieren Sie die Verwendung von Spark Compute-Ressourcen, und reduzieren Sie die Kosten Ihrer Synapse-Projekte.
Zeigen Sie die Momentaufnahmen der einzelnen Notebook-Ausführungsdatensätze in der Ausgabe an, und debuggen/überwachen Sie Ihre Notebookaufgaben bequem.
Ermitteln Sie den Beendenwert jeder ausführenden Aktivität und verwenden Sie diesen in nachgelagerten Aufgaben.
Sie können auch versuchen, das Mssparkutils.notebook.help("runMultiple") auszuführen, um das Beispiel und die detaillierte Verwendung zu finden.
Hier ist ein einfaches Beispiel für die parallele Ausführung einer Liste von Notebooks mit dieser Methode:
mssparkutils.notebook.runMultiple(["NotebookSimple", "NotebookSimple2"])
Das Ausführungsergebnis aus dem Stammnotebook lautet wie folgt:

Im Folgenden sehen Sie ein Beispiel für das Ausführen von Notebooks mit topologischer Struktur mithilfe von mssparkutils.notebook.runMultiple(). Verwenden Sie diese Methode, um Notebooks einfach über eine Codeumgebung zu koordinieren.
# run multiple notebooks with parameters
DAG = {
"activities": [
{
"name": "NotebookSimple", # activity name, must be unique
"path": "NotebookSimple", # notebook path
"timeoutPerCellInSeconds": 90, # max timeout for each cell, default to 90 seconds
"args": {"p1": "changed value", "p2": 100}, # notebook parameters
},
{
"name": "NotebookSimple2",
"path": "NotebookSimple2",
"timeoutPerCellInSeconds": 120,
"args": {"p1": "changed value 2", "p2": 200}
},
{
"name": "NotebookSimple2.2",
"path": "NotebookSimple2",
"timeoutPerCellInSeconds": 120,
"args": {"p1": "changed value 3", "p2": 300},
"retry": 1,
"retryIntervalInSeconds": 10,
"dependencies": ["NotebookSimple"] # list of activity names that this activity depends on
}
]
}
mssparkutils.notebook.runMultiple(DAG)
Hinweis
- Die Methode unterstützt nur in Azure Synapse Runtime für Apache Spark 3.3 und Azure Synapse Runtime für Apache Spark 3.4.
- Der Parallelitätsgrad der Ausführung mehrerer Notebooks ist auf die gesamte verfügbare Computeressource einer Spark-Sitzung beschränkt.
Beenden eines Notebooks
Beendet ein Notebook mit einem Wert. Sie können Verschachtelungsfunktionsaufrufe in einem Notebook interaktiv oder in einer Pipeline ausführen.
Wenn Sie eine exit()-Funktion interaktiv aus einem Notebook aufrufen, löst Azure Synapse eine Ausnahme aus, überspringt die Ausführung von nachfolgenden Zellen und behält die Spark-Sitzung bei.
Wenn Sie ein Notizbuch orchestrieren, das eine
exit()Funktion in einer Synapse-Pipeline aufruft, gibt Azure Synapse einen Exit-Wert zurück, schließt die Ausführung der Pipeline ab und beendet die Spark-Session.Wenn Sie eine Funktion in einem Notebook aufrufen, auf das
exit()verwiesen wird, beendet Azure Synapse die weitere Ausführung im Notebook, auf das verwiesen wird, und fährt mit der Ausführung der nächsten Zellen im Notebook fort, welche dierun()Funktion aufruft. Ein Beispiel: Notebook1 hat drei Zellen und ruft in der zweiten Zelle eineexit()Funktion auf. Notebook2 verfügt über fünf Zellen und ruftrun(notebook1)in der dritten Zelle auf. Wenn Sie Notebook2 ausführen, wird Notebook1 in der zweiten Zelle beendet, sobald die Funktion erreichtexit()wird. Notebook2 führt fort, seine vierte Zelle und fünfte Zelle auszuführen.
mssparkutils.notebook.exit("value string")
Beispiel:
Muster1Das Notebook sucht unter folder/ mit den folgenden beiden Zellen:
- Zelle 1 definiert einen Eingabe-Parameter, dessen Standardwert auf 10 festgelegt ist.
- Zelle 2 beendet das Notebook mit Eingabe als Exit-Wert.
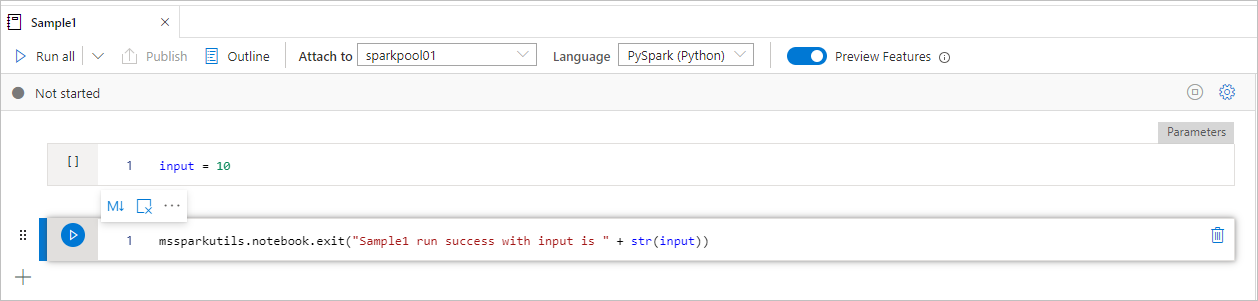
Sie können Muster1 in einem anderen Notebook mit Standardwerten ausführen:
exitVal = mssparkutils.notebook.run("folder/Sample1")
print (exitVal)
Ergebnis:
Sample1 run success with input is 10
Sie können Muster1 in einem anderen Notebook ausführen und den Eingabewert als 20 festlegen:
exitVal = mssparkutils.notebook.run("mssparkutils/folder/Sample1", 90, {"input": 20 })
print (exitVal)
Ergebnis:
Sample1 run success with input is 20
Sie können die MSSparkUtils Notebook Utilities verwenden, um ein Notebook auszuführen oder ein Notebook mit einem Wert zu beenden. Führen Sie den folgenden Befehl aus, um eine Übersicht über die verfügbaren Methoden zu erhalten:
mssparkutils.notebook.help()
Erzielen Sie Ergebnisse:
The notebook module.
exit(value: String): void -> This method lets you exit a notebook with a value.
run(path: String, timeoutSeconds: int, arguments: Map): String -> This method runs a notebook and returns its exit value.
Verweis auf ein Notizbuch
Verweist auf ein Notizbuch und gibt dessen Exit-Wert zurück. Sie können Verschachtelungsfunktionsaufrufe in einem Notebook interaktiv oder in einer Pipeline ausführen. Das Notebook, auf das verwiesen wird, wird auf dem Spark-Pool ausgeführt, dessen Notebook diese Funktion aufruft.
mssparkutils.notebook.run("notebook path", <timeoutSeconds>, <parameterMap>)
Beispiel:
mssparkutils.notebook.run("folder/Sample1", 90, Map("input" -> 20))
Nachdem die Ausführung abgeschlossen ist, wird ein Momentaufnahmelink namens Notebookausführung anzeigen: Notebookname in der Zellausgabe angezeigt. Sie können auf den Link klicken, um die Momentaufnahme für diese Ausführung anzuzeigen.
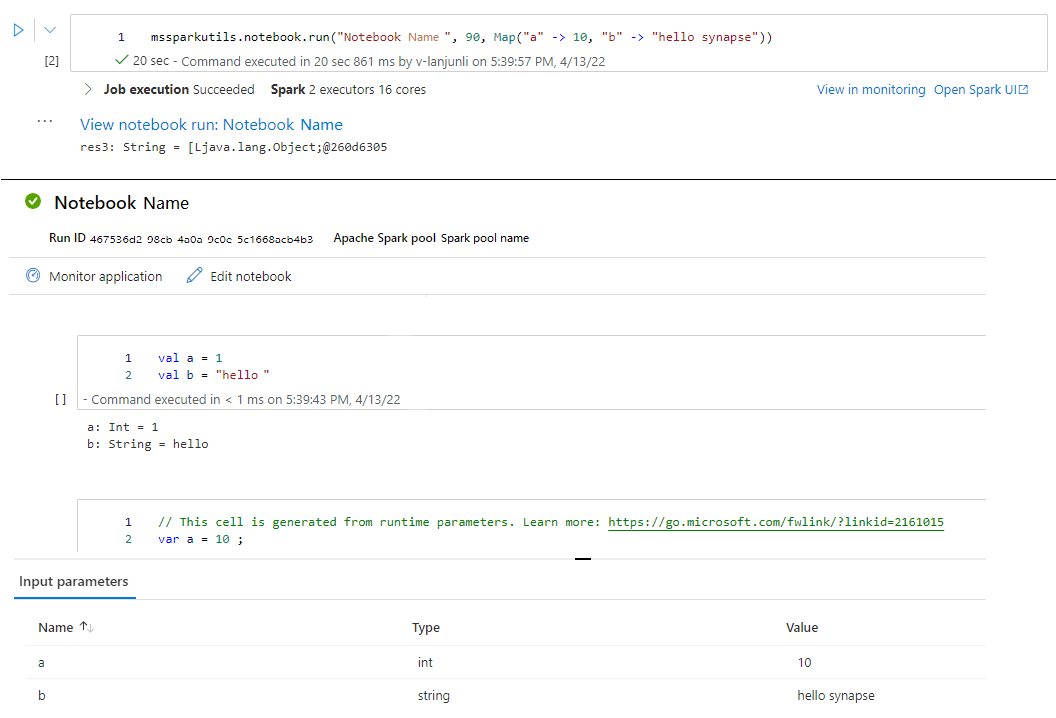
Beenden eines Notebooks
Beendet ein Notebook mit einem Wert. Sie können Verschachtelungsfunktionsaufrufe in einem Notebook interaktiv oder in einer Pipeline ausführen.
Wenn Sie eine
exit()Funktion interaktiv als Notebook aufrufen, löst Azure Synapse eine Ausnahme aus, überspringt die Ausführung von Subsequenz-Zellen und hält die Spark-Session aufrecht.Wenn Sie ein Notizbuch orchestrieren, das eine
exit()Funktion in einer Synapse-Pipeline aufruft, gibt Azure Synapse einen Exit-Wert zurück, schließt die Ausführung der Pipeline ab und beendet die Spark-Session.Wenn Sie eine Funktion in einem Notebook aufrufen, auf das
exit()verwiesen wird, beendet Azure Synapse die weitere Ausführung im Notebook, auf das verwiesen wird, und fährt mit der Ausführung der nächsten Zellen im Notebook fort, welche dierun()Funktion aufruft. Ein Beispiel: Notebook1 hat drei Zellen und ruft in der zweiten Zelle eineexit()Funktion auf. Notebook2 verfügt über fünf Zellen und ruftrun(notebook1)in der dritten Zelle auf. Wenn Sie Notebook2 ausführen, wird Notebook1 in der zweiten Zelle beendet, sobald die Funktion erreichtexit()wird. Notebook2 führt fort, seine vierte Zelle und fünfte Zelle auszuführen.
mssparkutils.notebook.exit("value string")
Beispiel:
Muster1 Notebook sucht unter mssparkutils/folder/ mit den folgenden zwei Zellen:
- Zelle 1 definiert einen Eingabe-Parameter, dessen Standardwert auf 10 festgelegt ist.
- Zelle 2 beendet das Notebook mit Eingabe als Exit-Wert.
Sie können Muster1 in einem anderen Notebook mit Standardwerten ausführen:
val exitVal = mssparkutils.notebook.run("mssparkutils/folder/Sample1")
print(exitVal)
Ergebnis:
exitVal: String = Sample1 run success with input is 10
Sample1 run success with input is 10
Sie können Muster1 in einem anderen Notebook ausführen und den Eingabewert als 20 festlegen:
val exitVal = mssparkutils.notebook.run("mssparkutils/folder/Sample1", 90, {"input": 20 })
print(exitVal)
Ergebnis:
exitVal: String = Sample1 run success with input is 20
Sample1 run success with input is 20
Sie können die MSSparkUtils Notebook Utilities verwenden, um ein Notebook auszuführen oder ein Notebook mit einem Wert zu beenden. Führen Sie den folgenden Befehl aus, um eine Übersicht über die verfügbaren Methoden zu erhalten:
mssparkutils.notebook.help()
Erzielen Sie Ergebnisse:
The notebook module.
exit(value: String): void -> This method lets you exit a notebook with a value.
run(path: String, timeoutSeconds: int, arguments: Map): String -> This method runs a notebook and returns its exit value.
Verweis auf ein Notizbuch
Verweist auf ein Notizbuch und gibt dessen Exit-Wert zurück. Sie können Verschachtelungsfunktionsaufrufe in einem Notebook interaktiv oder in einer Pipeline ausführen. Das Notebook, auf das verwiesen wird, wird auf dem Spark-Pool ausgeführt, dessen Notebook diese Funktion aufruft.
mssparkutils.notebook.run("notebook path", <timeoutSeconds>, <parameterMap>)
Beispiel:
mssparkutils.notebook.run("folder/Sample1", 90, list("input": 20))
Nachdem die Ausführung abgeschlossen ist, wird ein Momentaufnahmelink namens Notebookausführung anzeigen: Notebookname in der Zellausgabe angezeigt. Sie können auf den Link klicken, um die Momentaufnahme für diese Ausführung anzuzeigen.
Beenden eines Notebooks
Beendet ein Notebook mit einem Wert. Sie können Verschachtelungsfunktionsaufrufe in einem Notebook interaktiv oder in einer Pipeline ausführen.
Wenn Sie eine
exit()Funktion interaktiv als Notebook aufrufen, löst Azure Synapse eine Ausnahme aus, überspringt die Ausführung von Subsequenz-Zellen und hält die Spark-Session aufrecht.Wenn Sie ein Notizbuch orchestrieren, das eine
exit()Funktion in einer Synapse-Pipeline aufruft, gibt Azure Synapse einen Exit-Wert zurück, schließt die Ausführung der Pipeline ab und beendet die Spark-Session.Wenn Sie eine Funktion in einem Notebook aufrufen, auf das
exit()verwiesen wird, beendet Azure Synapse die weitere Ausführung im Notebook, auf das verwiesen wird, und fährt mit der Ausführung der nächsten Zellen im Notebook fort, welche dierun()Funktion aufruft. Ein Beispiel: Notebook1 hat drei Zellen und ruft in der zweiten Zelle eineexit()Funktion auf. Notebook2 verfügt über fünf Zellen und ruftrun(notebook1)in der dritten Zelle auf. Wenn Sie Notebook2 ausführen, wird Notebook1 in der zweiten Zelle beendet, sobald die Funktion erreichtexit()wird. Notebook2 führt fort, seine vierte Zelle und fünfte Zelle auszuführen.
mssparkutils.notebook.exit("value string")
Beispiel:
Muster1Das Notebook sucht unter folder/ mit den folgenden beiden Zellen:
- Zelle 1 definiert einen Eingabe-Parameter, dessen Standardwert auf 10 festgelegt ist.
- Zelle 2 beendet das Notebook mit Eingabe als Exit-Wert.
Sie können Muster1 in einem anderen Notebook mit Standardwerten ausführen:
exitVal <- mssparkutils.notebook.run("folder/Sample1")
print (exitVal)
Ergebnis:
Sample1 run success with input is 10
Sie können Muster1 in einem anderen Notebook ausführen und den Eingabewert als 20 festlegen:
exitVal <- mssparkutils.notebook.run("mssparkutils/folder/Sample1", 90, list("input": 20))
print (exitVal)
Ergebnis:
Sample1 run success with input is 20
Hilfsprogramme für Anmeldeinformationen
Sie können die MSSparkUtils-Hilfsprogramme für Anmeldeinformationen verwenden, um die Zugriffstoken von verknüpften Diensten abzurufen und Geheimnisse in Azure Key Vault zu verwalten.
Führen Sie den folgenden Befehl aus, um eine Übersicht über die verfügbaren Methoden zu erhalten:
mssparkutils.credentials.help()
mssparkutils.credentials.help()
Not supported.
mssparkutils.credentials.help()
Ergebnis abrufen:
getToken(audience, name): returns AAD token for a given audience, name (optional)
isValidToken(token): returns true if token hasn't expired
getConnectionStringOrCreds(linkedService): returns connection string or credentials for linked service
getFullConnectionString(linkedService): returns full connection string with credentials
getPropertiesAll(linkedService): returns all the properties of a linked servicegetSecret(akvName, secret, linkedService): returns AKV secret for a given AKV linked service, akvName, secret key
getSecret(akvName, secret): returns AKV secret for a given akvName, secret key
getSecretWithLS(linkedService, secret): returns AKV secret for a given linked service, secret key
putSecret(akvName, secretName, secretValue, linkedService): puts AKV secret for a given akvName, secretName
putSecret(akvName, secretName, secretValue): puts AKV secret for a given akvName, secretName
putSecretWithLS(linkedService, secretName, secretValue): puts AKV secret for a given linked service, secretName
getToken(audience, name): returns AAD token for a given audience, name (optional)
isValidToken(token): returns true if token hasn't expired
getConnectionStringOrCreds(linkedService): returns connection string or credentials for linked service
getFullConnectionString(linkedService): returns full connection string with credentials
getPropertiesAll(linkedService): returns all the properties of a linked servicegetSecret(akvName, secret, linkedService): returns AKV secret for a given AKV linked service, akvName, secret key
getSecret(akvName, secret): returns AKV secret for a given akvName, secret key
getSecretWithLS(linkedService, secret): returns AKV secret for a given linked service, secret key
putSecret(akvName, secretName, secretValue, linkedService): puts AKV secret for a given akvName, secretName
putSecret(akvName, secretName, secretValue): puts AKV secret for a given akvName, secretName
putSecretWithLS(linkedService, secretName, secretValue): puts AKV secret for a given linked service, secretName
getToken(audience, name): returns AAD token for a given audience, name (optional)
isValidToken(token): returns true if token hasn't expired
getConnectionStringOrCreds(linkedService): returns connection string or credentials for linked service
getFullConnectionString(linkedService): returns full connection string with credentials
getPropertiesAll(linkedService): returns all the properties of a linked servicegetSecret(akvName, secret, linkedService): returns AKV secret for a given AKV linked service, akvName, secret key
getSecret(akvName, secret): returns AKV secret for a given akvName, secret key
putSecret(akvName, secretName, secretValue, linkedService): puts AKV secret for a given akvName, secretName
putSecret(akvName, secretName, secretValue): puts AKV secret for a given akvName, secretName
putSecretWithLS(linkedService, secretName, secretValue): puts AKV secret for a given linked service, secretName
Hinweis
Derzeit wird getSecretWithLS(linkedService, secret) in C# nicht unterstützt.
getToken(audience, name): returns AAD token for a given audience, name (optional)
isValidToken(token): returns true if token hasn't expired
getConnectionStringOrCreds(linkedService): returns connection string or credentials for linked service
getFullConnectionString(linkedService): returns full connection string with credentials
getPropertiesAll(linkedService): returns all the properties of a linked servicegetSecret(akvName, secret, linkedService): returns AKV secret for a given AKV linked service, akvName, secret key
getSecret(akvName, secret): returns AKV secret for a given akvName, secret key
getSecretWithLS(linkedService, secret): returns AKV secret for a given linked service, secret key
putSecret(akvName, secretName, secretValue, linkedService): puts AKV secret for a given akvName, secretName
putSecret(akvName, secretName, secretValue): puts AKV secret for a given akvName, secretName
putSecretWithLS(linkedService, secretName, secretValue): puts AKV secret for a given linked service, secretName
Abrufen von Token
Gibt das Microsoft Entra-Token für eine bestimmte Zielgruppe (optional), Name (optional), zurück. In der folgenden Tabelle sind alle verfügbaren Zielgruppentypen aufgeführt:
| Zielgruppentyp | Zeichenfolgenliteral, das im API-Aufruf verwendet werden soll |
|---|---|
| Azure Storage | Storage |
| Azure-Schlüsseltresor | Vault |
| Azure-Verwaltung | AzureManagement |
| Azure SQL Data Warehouse (dediziert und serverlos) | DW |
| Azure Synapse | Synapse |
| Azure Data Lake Store | DataLakeStore |
| Azure Data Factory | ADF |
| Azure-Daten-Explorer | AzureDataExplorer |
| Azure Database for MySQL | AzureOSSDB |
| Azure Database for MariaDB | AzureOSSDB |
| Azure Database for PostgreSQL | AzureOSSDB |
mssparkutils.credentials.getToken('audience Key')
mssparkutils.credentials.getToken("audience Key")
Credentials.GetToken("audience Key")
mssparkutils.credentials.getToken('audience Key')
Token überprüfen
Gibt „true“ zurück, wenn das Token nicht abgelaufen ist.
mssparkutils.credentials.isValidToken('your token')
mssparkutils.credentials.isValidToken("your token")
Credentials.IsValidToken("your token")
mssparkutils.credentials.isValidToken('your token')
Verbindungszeichenfolge oder Anmeldeinformationen für verknüpften Dienst abrufen
Gibt die Verbindungszeichenfolge oder die Anmeldeinformationen für den verknüpften Dienst zurück.
mssparkutils.credentials.getConnectionStringOrCreds('linked service name')
mssparkutils.credentials.getConnectionStringOrCreds("linked service name")
Credentials.GetConnectionStringOrCreds("linked service name")
mssparkutils.credentials.getConnectionStringOrCreds('linked service name')
Geheimnis mithilfe der Arbeitsbereichsidentität abrufen
Gibt das Azure Key Vault-Geheimnis für einen angegebenen Azure Key Vault-Namen, Geheimnisnamen und Namen eines verknüpften Diensts mithilfe der Arbeitsbereichsidentität zurück. Stellen Sie sicher, dass Sie den Zugriff entsprechend auf Azure Key Vault konfigurieren.
mssparkutils.credentials.getSecret('azure key vault name','secret name','linked service name')
mssparkutils.credentials.getSecret("azure key vault name","secret name","linked service name")
Credentials.GetSecret("azure key vault name","secret name","linked service name")
mssparkutils.credentials.getSecret('azure key vault name','secret name','linked service name')
Geheimnis mithilfe der Benutzeranmeldeinformationen abrufen
Gibt das Azure Key Vault-Geheimnis für einen angegebenen Azure Key Vault-Namen, Geheimnisnamen und Namen eines verknüpften Diensts mithilfe der Benutzeranmeldeinformationen zurück.
mssparkutils.credentials.getSecret('azure key vault name','secret name')
mssparkutils.credentials.getSecret("azure key vault name","secret name")
Credentials.GetSecret("azure key vault name","secret name")
mssparkutils.credentials.getSecret('azure key vault name','secret name')
Geheimnis mithilfe der Arbeitsbereichsidentität festlegen
Legt das Azure Key Vault-Geheimnis für einen angegebenen Azure Key Vault-Namen, Geheimnisnamen und Namen eines verknüpften Diensts mithilfe der Arbeitsbereichsidentität fest. Stellen Sie sicher, dass Sie den Zugriff entsprechend auf Azure Key Vault konfigurieren.
mssparkutils.credentials.putSecret('azure key vault name','secret name','secret value','linked service name')
Geheimnis mithilfe der Arbeitsbereichsidentität festlegen
Legt das Azure Key Vault-Geheimnis für einen angegebenen Azure Key Vault-Namen, Geheimnisnamen und Namen eines verknüpften Diensts mithilfe der Arbeitsbereichsidentität fest. Stellen Sie sicher, dass Sie den Zugriff entsprechend auf Azure Key Vault konfigurieren.
mssparkutils.credentials.putSecret("azure key vault name","secret name","secret value","linked service name")
Geheimnis mithilfe der Arbeitsbereichsidentität festlegen
Legt das Azure Key Vault-Geheimnis für einen angegebenen Azure Key Vault-Namen, Geheimnisnamen und Namen eines verknüpften Diensts mithilfe der Arbeitsbereichsidentität fest. Stellen Sie sicher, dass Sie den Zugriff entsprechend auf Azure Key Vault konfigurieren.
mssparkutils.credentials.putSecret('azure key vault name','secret name','secret value','linked service name')
Geheimnis mithilfe der Benutzeranmeldeinformationen festlegen
Legt das Azure Key Vault-Geheimnis für einen angegebenen Azure Key Vault-Namen, Geheimnisnamen und Namen eines verknüpften Diensts mithilfe der Benutzeranmeldeinformationen fest.
mssparkutils.credentials.putSecret('azure key vault name','secret name','secret value')
Geheimnis mithilfe der Benutzeranmeldeinformationen festlegen
Legt das Azure Key Vault-Geheimnis für einen angegebenen Azure Key Vault-Namen, Geheimnisnamen und Namen eines verknüpften Diensts mithilfe der Benutzeranmeldeinformationen fest.
mssparkutils.credentials.putSecret('azure key vault name','secret name','secret value')
Geheimnis mithilfe der Benutzeranmeldeinformationen festlegen
Legt das Azure Key Vault-Geheimnis für einen angegebenen Azure Key Vault-Namen, Geheimnisnamen und Namen eines verknüpften Diensts mithilfe der Benutzeranmeldeinformationen fest.
mssparkutils.credentials.putSecret("azure key vault name","secret name","secret value")
Hilfsprogramme der Umgebung
Führen Sie die folgenden Befehle aus, um eine Übersicht über die verfügbaren Methoden zu erhalten:
mssparkutils.env.help()
mssparkutils.env.help()
mssparkutils.env.help()
Env.Help()
Ergebnis abrufen:
getUserName(): returns user name
getUserId(): returns unique user id
getJobId(): returns job id
getWorkspaceName(): returns workspace name
getPoolName(): returns Spark pool name
getClusterId(): returns cluster id
Benutzernamen abrufen
Gibt den aktuellen Benutzernamen zurück.
mssparkutils.env.getUserName()
mssparkutils.env.getUserName()
mssparkutils.env.getUserName()
Env.GetUserName()
Benutzer-ID abrufen
Gibt die aktuelle Benutzer-ID zurück.
mssparkutils.env.getUserId()
mssparkutils.env.getUserId()
mssparkutils.env.getUserId()
Env.GetUserId()
Auftrags-ID abrufen
Gibt die Auftrags-ID zurück.
mssparkutils.env.getJobId()
mssparkutils.env.getJobId()
mssparkutils.env.getJobId()
Env.GetJobId()
Arbeitsbereichsnamen abrufen
Gibt den Arbeitsbereichsnamen zurück.
mssparkutils.env.getWorkspaceName()
mssparkutils.env.getWorkspaceName()
mssparkutils.env.getWorkspaceName()
Env.GetWorkspaceName()
Poolnamen abrufen
Gibt den Spark-Poolnamen zurück.
mssparkutils.env.getPoolName()
mssparkutils.env.getPoolName()
mssparkutils.env.getPoolName()
Env.GetPoolName()
Cluster-ID abrufen
Gibt die aktuelle Cluster-ID zurück.
mssparkutils.env.getClusterId()
mssparkutils.env.getClusterId()
mssparkutils.env.getClusterId()
Env.GetClusterId()
Laufzeitkontext
„Mssparkutils runtime utils“ hat 3 Laufzeiteigenschaften aufgezeigt. Sie können den „mssparkutils“ Laufzeitkontext verwenden, um die Eigenschaften wie unten aufgeführt zu erhalten:
- Notebookname: Der Name des aktuellen Notizbuchs, gibt sowohl im interaktiven Modus als auch im Pipelinemodus immer einen Wert zurück.
- Pipelinejobid: Die ID des Pipelinelaufs, gibt im Pipelinemodus einen Wert und im interaktiven Modus einen leeren String zurück.
- Activityrunid: Die Kennung des Aktivitätslaufs im Notebook, gibt im Pipeline-Modus einen Wert und im interaktiven Modus einen leeren String zurück.
Derzeit unterstützt der Laufzeitkontext sowohl Python als auch Scala.
mssparkutils.runtime.context
ctx <- mssparkutils.runtime.context()
for (key in ls(ctx)) {
writeLines(paste(key, ctx[[key]], sep = "\t"))
}
%%spark
mssparkutils.runtime.context
Sitzungsverwaltung
Beenden einer interaktiven Sitzung
Anstatt manuell auf die Schaltfläche „Beenden“ zu klicken, ist es manchmal bequemer, eine interaktive Sitzung durch den Aufruf einer API im Code zu beenden. Für solche Fälle stellen wir eine API mssparkutils.session.stop() zur Verfügung, die das Beenden der interaktiven Sitzung per Code unterstützt. Sie ist für Scala und Python verfügbar.
mssparkutils.session.stop()
mssparkutils.session.stop()
mssparkutils.session.stop()
Die mssparkutils.session.stop()-API beendet die aktuelle interaktive Sitzung asynchron im Hintergrund, beendet die Spark-Sitzung und gibt die von der Sitzung belegten Ressourcen frei, sodass sie für andere Sitzungen im selben Pool zur Verfügung stehen.
Hinweis
Wir raten davon ab, in Ihrem Code integrierte APIs wie sys.exit in Scala oder sys.exit() in Python aufzurufen, da solche APIs den Interpreterprozess einfach beenden, sodass die Spark-Sitzung weiterhin aktiv ist und die Ressourcen nicht freigegeben werden.
Package Dependencies
Wenn Sie Notizbücher oder Aufträge lokal entwickeln möchten und auf die relevanten Pakete für Kompilierungs-/IDE-Hinweise verweisen müssen, können Sie die folgenden Pakete verwenden.
Nächste Schritte
Feedback
Bald verfügbar: Im Laufe des Jahres 2024 werden wir GitHub-Issues stufenweise als Feedbackmechanismus für Inhalte abbauen und durch ein neues Feedbacksystem ersetzen. Weitere Informationen finden Sie unter https://aka.ms/ContentUserFeedback.
Feedback senden und anzeigen für