Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
Einführung
Der Azure Synapse-Connector für dedizierte SQL-Pools für Apache Spark in Azure Synapse Analytics ermöglicht die effiziente Übertragung umfangreicher Datasets zwischen der Apache Spark-Runtime und dem dedizierten SQL-Pool. Der Connector wird als Standardbibliothek mit dem Azure Synapse-Arbeitsbereich ausgeliefert. Der Connector wird mithilfe der Sprache Scala implementiert. Der Connector unterstützt Scala und Python. Damit der Connector mit anderen Sprachoptionen für Notebooks verwendet werden kann, verwenden Sie den magischen Spark-Befehl %%spark.
Allgemein bietet der Connector die folgenden Funktionen:
- Lesen aus einem dedizierten SQL-Pool in Azure Synapse:
- Lesen großer Datasets aus (internen und externen) dedizierten SQL-Pooltabellen und -Sichten in Synapse.
- Umfassende Unterstützung für den Prädikatpushdown, wobei Filter für den Datenrahmen dem entsprechenden SQL-Prädikatpushdown zugeordnet werden
- Unterstützung für die Spaltenbereinigung
- Unterstützung für Abfragepushdown.
- Schreiben in einen dedizierten SQL-Pool in Azure Synapse:
- Erfassen großer Datenmengen in internen und externen Tabellentypen
- Unterstützen der folgenden Einstellungen für den Speichermodus von Datenrahmen (DataFrame):
AppendErrorIfExistsIgnoreOverwrite
- Beim Schreiben in eine externe Tabelle werden das Parquet- und das Textdateiformat mit Trennzeichen (Beispiel: CSV) unterstützt.
- Beim Schreiben von Daten in interne Tabellen verwendet der Connector jetzt anstelle des CETAS/CTAS-Ansatzes eine COPY-Anweisung.
- Verbesserungen zur Optimierung der End-to-End-Schreibdurchsatzleistung.
- Einführung eines optionalen Rückrufhandles (ein Scala-Funktionsargument), mit dem Clients Metriken nach dem Schreiben empfangen können.
- Zu den wenigen Beispielen gehören die Anzahl der Datensätze, die Dauer zum Abschließen einer bestimmten Aktion und der Fehlergrund.
Orchestrierungsansatz
Lesen
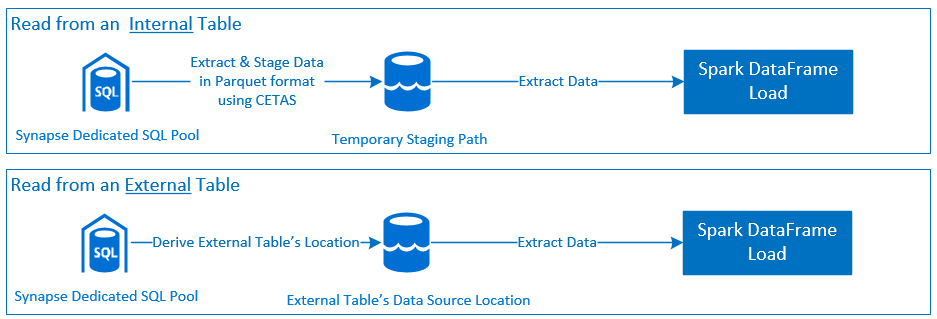
Schreiben
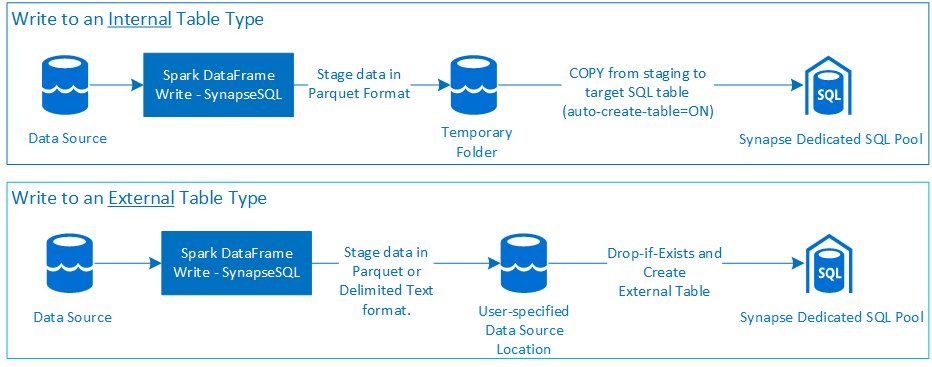
Voraussetzungen
Voraussetzungen wie das Einrichten erforderlicher Azure-Ressourcen und Schritte zu deren Konfiguration werden in diesem Abschnitt erläutert.
Azure-Ressourcen
Überprüfen Sie die folgenden abhängigen Azure-Ressourcen, und richten Sie sie ein:
- Azure Data Lake Storage: Wird als primäres Speicherkonto für den Azure Synapse-Arbeitsbereich verwendet.
- Azure Synapse-Arbeitsbereich: Wird zum Erstellen von Notebooks sowie zum Erstellen und Bereitstellen von DataFrame-basierten Eingangs-/Ausgangsworkflows verwendet.
- Dedizierter SQL-Pool (früher SQL DW): Bietet Data Warehousing-Funktionen für Unternehmen.
- Serverloser Spark-Pool in Azure Synapse: Die Spark-Runtime, in der die Aufträge als Spark-Anwendungen ausgeführt werden.
Vorbereiten der Datenbank
Stellen Sie eine Verbindung mit der dedizierten SQL-Pooldatenbank in Azure Synapse her, und führen Sie die folgenden Einrichtungsanweisungen aus:
Erstellen Sie eine*n Datenbankbenutzer*in, der bzw. die der Microsoft Entra-Benutzeridentität zugeordnet ist, die für die Anmeldung beim Azure Synapse-Arbeitsbereich verwendet wird.
CREATE USER [username@domain.com] FROM EXTERNAL PROVIDER;Erstellen Sie ein Schema, in dem Tabellen definiert werden, damit der Connector erfolgreich in die entsprechenden Tabellen schreiben und aus ihnen lesen kann.
CREATE SCHEMA [<schema_name>];
Authentifizierung
Microsoft Entra ID-basierte Authentifizierung
Die Microsoft Entra ID-basierte Authentifizierung ist ein integrierter Authentifizierungsansatz. Der Benutzer muss sich erfolgreich beim Azure Synapse Analytics-Arbeitsbereich anmelden.
Standardauthentifizierung
Für den Ansatz mit Standardauthentifizierung ist es erforderlich, dass die Benutzer die Optionen username und password konfigurieren. Weitere Informationen zu relevanten Konfigurationsparametern zum Lesen und Schreiben in Tabellen in dedizierten SQL-Pools von Azure Synapse finden Sie im Abschnitt Konfigurationsoptionen.
Autorisierung
Azure Data Lake Storage Gen2
Es gibt zwei Möglichkeiten, einem Azure Data Lake Storage Gen2-Speicherkonto Zugriffsberechtigungen zuzuweisen:
- Rollenbasierte Zugriffssteuerung: Rolle „Mitwirkender an Storage-Blobdaten“
- Durch Zuweisen der
Storage Blob Data Contributor Roleerhält der Benutzer Berechtigungen zum Lesen, Schreiben und Löschen für die Azure Storage Blob-Container. - Die rollenbasierte Zugriffssteuerung bietet eine undifferenzierte Steuerung auf der Containerebene.
- Durch Zuweisen der
-
Zugriffssteuerungslisten (Access Control Lists, ACL)
- Der ACL-Ansatz ermöglicht eine differenzierte Steuerung für bestimmte Pfade und/oder Dateien in einem bestimmten Ordner.
- ACL-Überprüfungen werden nicht erzwungen, wenn dem Benutzer bereits über die rollenbasierte Zugriffssteuerung Berechtigungen zugewiesen wurden.
- Es gibt zwei allgemeine Typen von ACL-Zugriffsberechtigungen:
- Zugriffsberechtigungen (werden auf einer bestimmten Ebene oder auf ein bestimmtes Objekt angewendet)
- Standardberechtigungen (werden zum Zeitpunkt der Erstellung automatisch auf alle untergeordneten Objekte angewendet)
- Folgende Berechtigungstypen stehen zur Verfügung:
-
Executeermöglicht das Durchlaufen der Ordnerhierarchien bzw. Navigieren in den Hierarchien. -
Readermöglicht das Lesen. -
Writeermöglicht das Schreiben.
-
- ACLs müssen so konfiguriert werden, dass der Connector erfolgreich in die Speicherorte schreiben und aus ihnen lesen kann.
Hinweis
Wenn Sie Notebooks mit Synapse-Arbeitsbereichspipelines ausführen möchten, müssen Sie auch die oben aufgeführte Zugriffsberechtigungen der verwalteten Standardidentität des Synapse-Arbeitsbereichs erteilen. Der Name der verwalteten Standardidentität des Arbeitsbereichs entspricht dem Namen des Arbeitsbereichs.
Um den Synapse-Arbeitsbereich mit gesicherten Speicherkonten zu verwenden, muss ein verwalteter privater Endpunkt aus dem Notebook konfiguriert werden. Der verwaltete private Endpunkt muss im Abschnitt
Private endpoint connectionsdes ADLS Gen2-Speicherkontos imNetworking-Bereich genehmigt werden.
Dedizierter SQL-Pool in Azure Synapse
Zum Aktivieren der erfolgreichen Interaktion mit dem dedizierten SQL-Pool von Azure Synapse ist die folgende Autorisierung erforderlich, es sei denn, Sie sind ein Benutzer, der auch als Active Directory Admin für den dedizierten SQL-Endpunkt konfiguriert ist:
Szenario: Lesen
Erteilen Sie dem Benutzer
db_exportermithilfe der gespeicherten Systemprozedursp_addrolemember.EXEC sp_addrolemember 'db_exporter', [<your_domain_user>@<your_domain_name>.com];
Szenario: Schreiben
- Der Connector verwendet den COPY-Befehl, um Daten aus dem Staging in den verwalteten Speicherort der internen Tabelle zu schreiben.
Konfigurieren Sie die hier beschriebenen erforderlichen Berechtigungen.
Der folgende kurze Codeausschnitt zeigt diese Konfiguration:
--Make sure your user has the permissions to CREATE tables in the [dbo] schema GRANT CREATE TABLE TO [<your_domain_user>@<your_domain_name>.com]; GRANT ALTER ON SCHEMA::<target_database_schema_name> TO [<your_domain_user>@<your_domain_name>.com]; --Make sure your user has ADMINISTER DATABASE BULK OPERATIONS permissions GRANT ADMINISTER DATABASE BULK OPERATIONS TO [<your_domain_user>@<your_domain_name>.com]; --Make sure your user has INSERT permissions on the target table GRANT INSERT ON <your_table> TO [<your_domain_user>@<your_domain_name>.com]
- Der Connector verwendet den COPY-Befehl, um Daten aus dem Staging in den verwalteten Speicherort der internen Tabelle zu schreiben.
API-Dokumentation
Azure Synapse-Connector für dedizierte SQL-Pools für Apache Spark: API-Dokumentation
Konfigurationsoptionen
Damit Bootstrapping und Orchestrierung des Lese- oder Schreibvorgangs erfolgreich verlaufen, erwartet der Connector bestimmte Konfigurationsparameter. Die Objektdefinition com.microsoft.spark.sqlanalytics.utils.Constants enthält eine Liste standardisierter Konstanten für jeden Parameterschlüssel.
Nachfolgend sehen Sie die Liste der Konfigurationsoptionen, basierend auf dem Verwendungsszenario:
-
Lesen unter Verwendung der Microsoft Entra ID-basierten Authentifizierung
- Die Anmeldeinformationen werden automatisch zugeordnet, und der Benutzer braucht keine spezifischen Konfigurationsoptionen anzugeben.
- Das dreiteilige Tabellennamenargument für die Methode
synapsesqlist erforderlich, um aus der jeweiligen Tabelle im dedizierten SQL-Pool von Azure Synapse zu lesen.
-
Lesen mit Standardauthentifizierung
- Dedizierter SQL-Endpunkt in Azure Synapse
-
Constants.SERVER: Dedizierter SQL Pool-Endpunkt in Azure Synapse (Server-FQDN) -
Constants.USER: SQL-Benutzername. -
Constants.PASSWORD: SQL-Benutzerkennwort.
-
- Azure Data Lake Storage (Gen2)-Endpunkt: Stagingordner
-
Constants.DATA_SOURCE: Der im Parameter für den Datenquellenspeicherort festgelegte Speicherpfad wird für das Staging von Daten verwendet.
-
- Dedizierter SQL-Endpunkt in Azure Synapse
-
Schreiben unter Verwendung der Microsoft Entra ID-basierten Authentifizierung
- Dedizierter SQL-Endpunkt in Azure Synapse
- Standardmäßig leitet der Connector den dedizierten SQL-Endpunkt in Synapse mithilfe des Datenbanknamens ab, der über den dreiteiligen Tabellennamenparameter der
synapsesql-Methode festgelegt wird. - Alternativ können Benutzer die
Constants.SERVER-Option verwenden, um den SQL-Endpunkt anzugeben. Stellen Sie sicher, dass der Endpunkt die entsprechende Datenbank mit dem jeweiligen Schema hostet.
- Standardmäßig leitet der Connector den dedizierten SQL-Endpunkt in Synapse mithilfe des Datenbanknamens ab, der über den dreiteiligen Tabellennamenparameter der
- Azure Data Lake Storage (Gen2)-Endpunkt: Stagingordner
- Für den internen Tabellentyp:
- Konfigurieren Sie entweder die Option
Constants.TEMP_FOLDERoderConstants.DATA_SOURCE. - Wenn der Benutzer die Option
Constants.DATA_SOURCEangegeben hat, wird der Stagingordner mithilfe deslocation-Werts aus der Datenquelle (DataSource) abgeleitet. - Wenn beide bereitgestellt werden, wird der Wert der
Constants.TEMP_FOLDER-Option verwendet. - Bei fehlender Option für den Stagingordner leitet der Connector eine im Ausgang von der Laufzeitkonfiguration
spark.sqlanalyticsconnector.stagingdir.prefixab.
- Konfigurieren Sie entweder die Option
- Für den externen Tabellentyp:
-
Constants.DATA_SOURCEist eine erforderliche Konfigurationsoption - Der Connector verwendet den Speicherpfad, der im Speicherortparameter der Datenquelle in Kombination mit dem
location-Argument für diesynapsesql-Methode festgelegt ist, und leitet den absoluten Pfad zum dauerhaften Speichern externer Tabellendaten ab. - Wenn das Argument
locationfür diesynapsesql-Methode nicht angegeben ist, leitet der Connector den Speicherortwert als<base_path>/dbName/schemaName/tableNameab.
-
- Für den internen Tabellentyp:
- Dedizierter SQL-Endpunkt in Azure Synapse
-
Schreiben mit Standardauthentifizierung
- Dedizierter SQL-Endpunkt in Azure Synapse
-
Constants.SERVER: Dedizierter SQL Pool-Endpunkt in Synapse (Server-FQDN). -
Constants.USER: SQL-Benutzername. -
Constants.PASSWORD: SQL-Benutzerkennwort. -
Constants.STAGING_STORAGE_ACCOUNT_KEYist dem Speicherkonto zugeordnet, dasConstants.TEMP_FOLDERS(nur interne Tabellentypen) oderConstants.DATA_SOURCEhostet.
-
- Azure Data Lake Storage (Gen2)-Endpunkt: Stagingordner
- Anmeldeinformationen für die SQL-Standardauthentifizierung gelten nicht für den Zugriff auf Speicherendpunkte.
- Stellen Sie daher sicher, dass Sie relevantem Speicher Zugriffsberechtigungen zuweisen, wie im Abschnitt Azure Data Lake Storage Gen2 beschrieben.
- Dedizierter SQL-Endpunkt in Azure Synapse
Codevorlagen
In diesem Abschnitt werden Referenzcodevorlagen vorgestellt, die beschreiben, wie der Azure Synapse-Connector für dedizierte SQL-Pools für Apache Spark verwendet und aufgerufen wird.
Hinweis
Verwenden des Connectors in Python
- Der Connector wird nur in Python für Spark 3 unterstützt. Weitere Informationen finden Sie im Abschnitt Zellenübergreifendes Verwenden von materialisierten Daten.
- Der Rückrufhandle ist in Python nicht verfügbar.
Lesen aus einem dedizierten SQL-Pool in Azure Synapse
Leseanforderung: synapsesql-Methodensignatur.
Lesen aus einer Tabelle unter Verwendung der Microsoft Entra ID-basierten Authentifizierung
//Use case is to read data from an internal table in Synapse Dedicated SQL Pool DB
//Azure Active Directory based authentication approach is preferred here.
import org.apache.spark.sql.DataFrame
import com.microsoft.spark.sqlanalytics.utils.Constants
import org.apache.spark.sql.SqlAnalyticsConnector._
//Read from existing internal table
val dfToReadFromTable:DataFrame = spark.read.
//If `Constants.SERVER` is not provided, the `<database_name>` from the three-part table name argument
//to `synapsesql` method is used to infer the Synapse Dedicated SQL End Point.
option(Constants.SERVER, "<sql-server-name>.sql.azuresynapse.net").
//Defaults to storage path defined in the runtime configurations
option(Constants.TEMP_FOLDER, "abfss://<container_name>@<storage_account_name>.dfs.core.windows.net/<some_base_path_for_temporary_staging_folders>").
//Three-part table name from where data will be read.
synapsesql("<database_name>.<schema_name>.<table_name>").
//Column-pruning i.e., query select column values.
select("<some_column_1>", "<some_column_5>", "<some_column_n>").
//Push-down filter criteria that gets translated to SQL Push-down Predicates.
filter(col("Title").startsWith("E")).
//Fetch a sample of 10 records
limit(10)
//Show contents of the dataframe
dfToReadFromTable.show()
Lesen aus einer Abfrage unter Verwendung der Microsoft Entra ID-basierten Authentifizierung
Hinweis
Einschränkungen beim Lesen aus Abfragen:
- Der Tabellenname und die Abfrage können nicht gleichzeitig festgelegt werden.
- Nur SELECT-Abfragen sind zulässig. DDL- und DML-SQLs sind nicht zulässig.
- Es erfolgt kein Pushdown der Auswahl- und Filteroptionen (select, filter) für den Dataframe in den dedizierten SQL-Pool, wenn eine Abfrage angegeben wird.
- Lesen aus einer Abfrage ist nur in Spark 3 verfügbar.
//Use case is to read data from an internal table in Synapse Dedicated SQL Pool DB
//Azure Active Directory based authentication approach is preferred here.
import org.apache.spark.sql.DataFrame
import com.microsoft.spark.sqlanalytics.utils.Constants
import org.apache.spark.sql.SqlAnalyticsConnector._
// Read from a query
// Query can be provided either as an argument to synapsesql or as a Constant - Constants.QUERY
val dfToReadFromQueryAsOption:DataFrame = spark.read.
// Name of the SQL Dedicated Pool or database where to run the query
// Database can be specified as a Spark Config - spark.sqlanalyticsconnector.dw.database or as a Constant - Constants.DATABASE
option(Constants.DATABASE, "<database_name>").
//If `Constants.SERVER` is not provided, the `<database_name>` from the three-part table name argument
//to `synapsesql` method is used to infer the Synapse Dedicated SQL End Point.
option(Constants.SERVER, "<sql-server-name>.sql.azuresynapse.net").
//Defaults to storage path defined in the runtime configurations
option(Constants.TEMP_FOLDER, "abfss://<container_name>@<storage_account_name>.dfs.core.windows.net/<some_base_path_for_temporary_staging_folders>")
//query from which data will be read
.option(Constants.QUERY, "select <column_name>, count(*) as cnt from <schema_name>.<table_name> group by <column_name>")
synapsesql()
val dfToReadFromQueryAsArgument:DataFrame = spark.read.
// Name of the SQL Dedicated Pool or database where to run the query
// Database can be specified as a Spark Config - spark.sqlanalyticsconnector.dw.database or as a Constant - Constants.DATABASE
option(Constants.DATABASE, "<database_name>")
//If `Constants.SERVER` is not provided, the `<database_name>` from the three-part table name argument
//to `synapsesql` method is used to infer the Synapse Dedicated SQL End Point.
option(Constants.SERVER, "<sql-server-name>.sql.azuresynapse.net").
//Defaults to storage path defined in the runtime configurations
option(Constants.TEMP_FOLDER, "abfss://<container_name>@<storage_account_name>.dfs.core.windows.net/<some_base_path_for_temporary_staging_folders>")
//query from which data will be read
.synapsesql("select <column_name>, count(*) as counts from <schema_name>.<table_name> group by <column_name>")
//Show contents of the dataframe
dfToReadFromQueryAsOption.show()
dfToReadFromQueryAsArgument.show()
Lesen aus einer Tabelle mithilfe der Standardauthentifizierung
//Use case is to read data from an internal table in Synapse Dedicated SQL Pool DB
//Azure Active Directory based authentication approach is preferred here.
import org.apache.spark.sql.DataFrame
import com.microsoft.spark.sqlanalytics.utils.Constants
import org.apache.spark.sql.SqlAnalyticsConnector._
//Read from existing internal table
val dfToReadFromTable:DataFrame = spark.read.
//If `Constants.SERVER` is not provided, the `<database_name>` from the three-part table name argument
//to `synapsesql` method is used to infer the Synapse Dedicated SQL End Point.
option(Constants.SERVER, "<sql-server-name>.sql.azuresynapse.net").
//Set database user name
option(Constants.USER, "<user_name>").
//Set user's password to the database
option(Constants.PASSWORD, "<user_password>").
//Set name of the data source definition that is defined with database scoped credentials.
//Data extracted from the table will be staged to the storage path defined on the data source's location setting.
option(Constants.DATA_SOURCE, "<data_source_name>").
//Three-part table name from where data will be read.
synapsesql("<database_name>.<schema_name>.<table_name>").
//Column-pruning i.e., query select column values.
select("<some_column_1>", "<some_column_5>", "<some_column_n>").
//Push-down filter criteria that gets translated to SQL Push-down Predicates.
filter(col("Title").startsWith("E")).
//Fetch a sample of 10 records
limit(10)
//Show contents of the dataframe
dfToReadFromTable.show()
Lesen aus einer Abfrage mithilfe der Standardauthentifizierung
//Use case is to read data from an internal table in Synapse Dedicated SQL Pool DB
//Azure Active Directory based authentication approach is preferred here.
import org.apache.spark.sql.DataFrame
import com.microsoft.spark.sqlanalytics.utils.Constants
import org.apache.spark.sql.SqlAnalyticsConnector._
// Name of the SQL Dedicated Pool or database where to run the query
// Database can be specified as a Spark Config or as a Constant - Constants.DATABASE
spark.conf.set("spark.sqlanalyticsconnector.dw.database", "<database_name>")
// Read from a query
// Query can be provided either as an argument to synapsesql or as a Constant - Constants.QUERY
val dfToReadFromQueryAsOption:DataFrame = spark.read.
//Name of the SQL Dedicated Pool or database where to run the query
//Database can be specified as a Spark Config - spark.sqlanalyticsconnector.dw.database or as a Constant - Constants.DATABASE
option(Constants.DATABASE, "<database_name>").
//If `Constants.SERVER` is not provided, the `<database_name>` from the three-part table name argument
//to `synapsesql` method is used to infer the Synapse Dedicated SQL End Point.
option(Constants.SERVER, "<sql-server-name>.sql.azuresynapse.net").
//Set database user name
option(Constants.USER, "<user_name>").
//Set user's password to the database
option(Constants.PASSWORD, "<user_password>").
//Set name of the data source definition that is defined with database scoped credentials.
//Data extracted from the SQL query will be staged to the storage path defined on the data source's location setting.
option(Constants.DATA_SOURCE, "<data_source_name>").
//Query where data will be read.
option(Constants.QUERY, "select <column_name>, count(*) as counts from <schema_name>.<table_name> group by <column_name>" ).
synapsesql()
val dfToReadFromQueryAsArgument:DataFrame = spark.read.
//Name of the SQL Dedicated Pool or database where to run the query
//Database can be specified as a Spark Config - spark.sqlanalyticsconnector.dw.database or as a Constant - Constants.DATABASE
option(Constants.DATABASE, "<database_name>").
//If `Constants.SERVER` is not provided, the `<database_name>` from the three-part table name argument
//to `synapsesql` method is used to infer the Synapse Dedicated SQL End Point.
option(Constants.SERVER, "<sql-server-name>.sql.azuresynapse.net").
//Set database user name
option(Constants.USER, "<user_name>").
//Set user's password to the database
option(Constants.PASSWORD, "<user_password>").
//Set name of the data source definition that is defined with database scoped credentials.
//Data extracted from the SQL query will be staged to the storage path defined on the data source's location setting.
option(Constants.DATA_SOURCE, "<data_source_name>").
//Query where data will be read.
synapsesql("select <column_name>, count(*) as counts from <schema_name>.<table_name> group by <column_name>")
//Show contents of the dataframe
dfToReadFromQueryAsOption.show()
dfToReadFromQueryAsArgument.show()
Schreiben in einen dedizierten SQL-Pool in Azure Synapse
Schreibanforderung: synapsesql-Methodensignatur.
synapsesql(tableName:String,
tableType:String = Constants.INTERNAL,
location:Option[String] = None,
callBackHandle=Option[(Map[String, Any], Option[Throwable])=>Unit]):Unit
Schreiben unter Verwendung der Microsoft Entra ID-basierten Authentifizierung
Im Folgenden sehen Sie eine umfassende Codevorlage, die die Verwendung des Connectors für Schreibszenarien beschreibt:
//Add required imports
import org.apache.spark.sql.DataFrame
import org.apache.spark.sql.SaveMode
import com.microsoft.spark.sqlanalytics.utils.Constants
import org.apache.spark.sql.SqlAnalyticsConnector._
//Define read options for example, if reading from CSV source, configure header and delimiter options.
val pathToInputSource="abfss://<storage_container_name>@<storage_account_name>.dfs.core.windows.net/<some_folder>/<some_dataset>.csv"
//Define read configuration for the input CSV
val dfReadOptions:Map[String, String] = Map("header" -> "true", "delimiter" -> ",")
//Initialize DataFrame that reads CSV data from a given source
val readDF:DataFrame=spark.
read.
options(dfReadOptions).
csv(pathToInputSource).
limit(1000) //Reads first 1000 rows from the source CSV input.
//Setup and trigger the read DataFrame for write to Synapse Dedicated SQL Pool.
//Fully qualified SQL Server DNS name can be obtained using one of the following methods:
// 1. Synapse Workspace - Manage Pane - SQL Pools - <Properties view of the corresponding Dedicated SQL Pool>
// 2. From Azure Portal, follow the bread-crumbs for <Portal_Home> -> <Resource_Group> -> <Dedicated SQL Pool> and then go to Connection Strings/JDBC tab.
//If `Constants.SERVER` is not provided, the value will be inferred by using the `database_name` in the three-part table name argument to the `synapsesql` method.
//Like-wise, if `Constants.TEMP_FOLDER` is not provided, the connector will use the runtime staging directory config (see section on Configuration Options for details).
val writeOptionsWithAADAuth:Map[String, String] = Map(Constants.SERVER -> "<dedicated-pool-sql-server-name>.sql.azuresynapse.net",
Constants.TEMP_FOLDER -> "abfss://<storage_container_name>@<storage_account_name>.dfs.core.windows.net/<some_temp_folder>")
//Setup optional callback/feedback function that can receive post write metrics of the job performed.
var errorDuringWrite:Option[Throwable] = None
val callBackFunctionToReceivePostWriteMetrics: (Map[String, Any], Option[Throwable]) => Unit =
(feedback: Map[String, Any], errorState: Option[Throwable]) => {
println(s"Feedback map - ${feedback.map{case(key, value) => s"$key -> $value"}.mkString("{",",\n","}")}")
errorDuringWrite = errorState
}
//Configure and submit the request to write to Synapse Dedicated SQL Pool (note - default SaveMode is set to ErrorIfExists)
//Sample below is using AAD-based authentication approach; See further examples to leverage SQL Basic auth.
readDF.
write.
//Configure required configurations.
options(writeOptionsWithAADAuth).
//Choose a save mode that is apt for your use case.
mode(SaveMode.Overwrite).
synapsesql(tableName = "<database_name>.<schema_name>.<table_name>",
//For external table type value is Constants.EXTERNAL
tableType = Constants.INTERNAL,
//Optional parameter that is used to specify external table's base folder; defaults to `database_name/schema_name/table_name`
location = None,
//Optional parameter to receive a callback.
callBackHandle = Some(callBackFunctionToReceivePostWriteMetrics))
//If write request has failed, raise an error and fail the Cell's execution.
if(errorDuringWrite.isDefined) throw errorDuringWrite.get
Schreiben mit Standardauthentifizierung
Der folgende Codeschnipsel ersetzt die im Abschnitt Schreiben unter Verwendung der Microsoft Entra ID-basierten Authentifizierung beschriebene Schreibdefinition, um die Schreibanforderung mithilfe von SQL-Standardauthentifizierung zu übermitteln:
//Define write options to use SQL basic authentication
val writeOptionsWithBasicAuth:Map[String, String] = Map(Constants.SERVER -> "<dedicated-pool-sql-server-name>.sql.azuresynapse.net",
//Set database user name
Constants.USER -> "<user_name>",
//Set database user's password
Constants.PASSWORD -> "<user_password>",
//Required only when writing to an external table. For write to internal table, this can be used instead of TEMP_FOLDER option.
Constants.DATA_SOURCE -> "<Name of the datasource as defined in the target database>"
//To be used only when writing to internal tables. Storage path will be used for data staging.
Constants.TEMP_FOLDER -> "abfss://<storage_container_name>@<storage_account_name>.dfs.core.windows.net/<some_temp_folder>")
//Configure and submit the request to write to Synapse Dedicated SQL Pool.
readDF.
write.
options(writeOptionsWithBasicAuth).
//Choose a save mode that is apt for your use case.
mode(SaveMode.Overwrite).
synapsesql(tableName = "<database_name>.<schema_name>.<table_name>",
//For external table type value is Constants.EXTERNAL
tableType = Constants.INTERNAL,
//Not required for writing to an internal table
location = None,
//Optional parameter.
callBackHandle = Some(callBackFunctionToReceivePostWriteMetrics))
Bei einem Ansatz mit Standardauthentifizierung sind weitere Konfigurationsoptionen erforderlich, um Daten aus einem Quellspeicherpfad zu lesen. Der folgende Codeausschnitt bietet ein Beispiel für das Lesen aus einer Azure Data Lake Storage Gen2-Datenquelle mithilfe von Dienstprinzipal-Anmeldeinformationen:
//Specify options that Spark runtime must support when interfacing and consuming source data
val storageAccountName="<storageAccountName>"
val storageContainerName="<storageContainerName>"
val subscriptionId="<AzureSubscriptionID>"
val spnClientId="<ServicePrincipalClientID>"
val spnSecretKeyUsedAsAuthCred="<spn_secret_key_value>"
val dfReadOptions:Map[String, String]=Map("header"->"true",
"delimiter"->",",
"fs.defaultFS" -> s"abfss://$storageContainerName@$storageAccountName.dfs.core.windows.net",
s"fs.azure.account.auth.type.$storageAccountName.dfs.core.windows.net" -> "OAuth",
s"fs.azure.account.oauth.provider.type.$storageAccountName.dfs.core.windows.net" ->
"org.apache.hadoop.fs.azurebfs.oauth2.ClientCredsTokenProvider",
"fs.azure.account.oauth2.client.id" -> s"$spnClientId",
"fs.azure.account.oauth2.client.secret" -> s"$spnSecretKeyUsedAsAuthCred",
"fs.azure.account.oauth2.client.endpoint" -> s"https://login.microsoftonline.com/$subscriptionId/oauth2/token",
"fs.AbstractFileSystem.abfss.impl" -> "org.apache.hadoop.fs.azurebfs.Abfs",
"fs.abfss.impl" -> "org.apache.hadoop.fs.azurebfs.SecureAzureBlobFileSystem")
//Initialize the Storage Path string, where source data is maintained/kept.
val pathToInputSource=s"abfss://$storageContainerName@$storageAccountName.dfs.core.windows.net/<base_path_for_source_data>/<specific_file (or) collection_of_files>"
//Define data frame to interface with the data source
val df:DataFrame = spark.
read.
options(dfReadOptions).
csv(pathToInputSource).
limit(100)
Unterstützte DataFrame-Speichermodi
Die folgenden Speichermodi werden beim Schreiben von Quelldaten in eine Zieltabelle in einen dedizierten SQL-Pool von Azure Synapse unterstützt:
- ErrorIfExists (Standardspeichermodus)
- Wenn die Zieltabelle vorhanden ist, wird der Schreibvorgang abgebrochen, und eine Ausnahme wird an die aufgerufene Funktion zurückgegeben. Andernfalls wird eine neue Tabelle mit Daten aus den Stagingordnern erstellt.
- Ignorieren
- Wenn die Zieltabelle vorhanden ist, wird die Schreibanforderung ignoriert, ohne dass ein Fehler zurückgegeben wird. Andernfalls wird eine neue Tabelle mit Daten aus den Stagingordnern erstellt.
- Überschreiben
- Wenn die Zieltabelle vorhanden ist, werden vorhandene Daten im Ziel durch Daten aus den Stagingordnern ersetzt. Andernfalls wird eine neue Tabelle mit Daten aus den Stagingordnern erstellt.
- Anfügen
- Wenn die Zieltabelle vorhanden ist, werden die neuen Daten an sie angefügt. Andernfalls wird eine neue Tabelle mit Daten aus den Stagingordnern erstellt.
Rückrufhandle für Schreibanforderungen
Mit den Änderungen der neuen Schreibpfad-API wurde ein experimentelles Feature eingeführt, um eine Schlüssel->Wert-Zuordnung von Metriken nach dem Schreiben für den Client bereitzustellen. Schlüssel für die Metriken werden in der neuen Objektdefinition Constants.FeedbackConstants definiert. Die Metrikdaten können als JSON-Zeichenfolge abgerufen werden, indem das Rückrufhandle (eine Scala Function) übergeben wird. Im Folgenden sehen Sie die Funktionssignatur:
//Function signature is expected to have two arguments - a `scala.collection.immutable.Map[String, Any]` and an Option[Throwable]
//Post-write if there's a reference of this handle passed to the `synapsesql` signature, it will be invoked by the closing process.
//These arguments will have valid objects in either Success or Failure case. In case of Failure the second argument will be a `Some(Throwable)`.
(Map[String, Any], Option[Throwable]) => Unit
Nachfolgend sind einige wichtige Metriken aufgeführt (in gemischter Groß-/Kleinschreibung dargestellt):
WriteFailureCauseDataStagingSparkJobDurationInMillisecondsNumberOfRecordsStagedForSQLCommitSQLStatementExecutionDurationInMillisecondsrows_processed
Im Folgenden sehen Sie eine JSON-Beispielzeichenfolge mit Metriken nach dem Schreiben:
{
SparkApplicationId -> <spark_yarn_application_id>,
SQLStatementExecutionDurationInMilliseconds -> 10113,
WriteRequestReceivedAtEPOCH -> 1647523790633,
WriteRequestProcessedAtEPOCH -> 1647523808379,
StagingDataFileSystemCheckDurationInMilliseconds -> 60,
command -> "COPY INTO [schema_name].[table_name] ...",
NumberOfRecordsStagedForSQLCommit -> 100,
DataStagingSparkJobEndedAtEPOCH -> 1647523797245,
SchemaInferenceAssertionCompletedAtEPOCH -> 1647523790920,
DataStagingSparkJobDurationInMilliseconds -> 5252,
rows_processed -> 100,
SaveModeApplied -> TRUNCATE_COPY,
DurationInMillisecondsToValidateFileFormat -> 75,
status -> Completed,
SparkApplicationName -> <spark_application_name>,
ThreePartFullyQualifiedTargetTableName -> <database_name>.<schema_name>.<table_name>,
request_id -> <query_id_as_retrieved_from_synapse_dedicated_sql_db_query_reference>,
StagingFolderConfigurationCheckDurationInMilliseconds -> 2,
JDBCConfigurationsSetupAtEPOCH -> 193,
StagingFolderConfigurationCheckCompletedAtEPOCH -> 1647523791012,
FileFormatValidationsCompletedAtEPOCHTime -> 1647523790995,
SchemaInferenceCheckDurationInMilliseconds -> 91,
SaveModeRequested -> Overwrite,
DataStagingSparkJobStartedAtEPOCH -> 1647523791993,
DurationInMillisecondsTakenToGenerateWriteSQLStatements -> 4
}
Weitere Codebeispiele
Zellenübergreifendes Verwenden von materialisierten Daten
createOrReplaceTempView von Spark DataFrames kann verwendet werden, um durch Registrieren einer temporären Ansicht auf Daten zuzugreifen, die in einer anderen Zelle abgerufen werden.
- Zelle, aus der Daten abgerufen werden (beispielsweise mit der Notebook-Spracheinstellung
Scala)
//Necessary imports
import org.apache.spark.sql.DataFrame
import org.apache.spark.sql.SaveMode
import com.microsoft.spark.sqlanalytics.utils.Constants
import org.apache.spark.sql.SqlAnalyticsConnector._
//Configure options and read from Synapse Dedicated SQL Pool.
val readDF = spark.read.
//Set Synapse Dedicated SQL End Point name.
option(Constants.SERVER, "<synapse-dedicated-sql-end-point>.sql.azuresynapse.net").
//Set database user name.
option(Constants.USER, "<user_name>").
//Set database user's password.
option(Constants.PASSWORD, "<user_password>").
//Set name of the data source definition that is defined with database scoped credentials.
option(Constants.DATA_SOURCE,"<data_source_name>").
//Set the three-part table name from which the read must be performed.
synapsesql("<database_name>.<schema_name>.<table_name>").
//Optional - specify number of records the DataFrame would read.
limit(10)
//Register the temporary view (scope - current active Spark Session)
readDF.createOrReplaceTempView("<temporary_view_name>")
- Ändern Sie nun die Spracheinstellung im Notebook in
PySpark (Python), und rufen Sie Daten aus der registrierten Ansicht<temporary_view_name>ab.
spark.sql("select * from <temporary_view_name>").show()
Antwortbehandlung
Das Aufrufen von synapsesql kann zwei mögliche Endzustände einnehmen: „Erfolg“ oder „Fehlgeschlagener Zustand“. In diesem Abschnitt wird beschrieben, wie sie die Anforderungsantwort für jedes Szenario behandeln.
Anforderungsantwort beim Lesen
Nach Abschluss wird der Codeaussschnitt mit der Leseantwort in der Ausgabe der Zelle angezeigt. Fehler in der aktuellen Zelle führen auch zum Abbruch der Ausführung in nachfolgenden Zellen. Detaillierte Fehlerinformationen sind in den Spark-Anwendungsprotokollen verfügbar.
Anforderungsantwort beim Schreiben
Standardmäßig wird eine Schreibantwort in der Zellausgabe angezeigt. Bei einem Fehler wird die aktuelle Zelle als fehlerhaft gekennzeichnet, und die Ausführung nachfolgender Zellen wird abgebrochen. Der andere Ansatz besteht darin, die Rückrufhandle-Option an die Methode synapsesql zu übergeben. Das Rückrufhandle bietet programmgesteuerten Zugriff auf die Schreibantwort.
Andere Aspekte
- Beim Lesen aus den dedizierten SQL-Pooltabellen in Azure Synapse:
- Erwägen Sie die Anwendung erforderlicher Filter auf den DataFrame, um die Bereinigungsfunktion des Connectors für Spalten zu nutzen.
- Im Leseszenario wird die
TOP(n-rows)-Klausel beim Framing derSELECT-Abfrageanweisungen nicht unterstützt. Das Verfahren der Wahl zum Einschränken von Daten besteht in der limit(.)-Klausel von DataFrame.- Mehr dazu finden Sie im Beispiel im Abschnitt Zellenübergreifendes Verwenden von materialisierten Daten.
- Beim Schreiben in die dedizierten SQL-Pooltabellen in Azure Synapse:
- Für interne Tabellentypen:
- Tabellen werden mit ROUND_ROBIN-Datenverteilung erstellt.
- Spaltentypen werden aus dem DataFrame abgeleitet, der zum Lesen von Daten aus der Quelle zur Anwendung käme. Zeichenfolgenspalten werden
NVARCHAR(4000)zugeordnet.
- Für externe Tabellentypen:
- Der anfängliche Parallelismus von DataFrame steuert die Datenorganisation für die externe Tabelle.
- Spaltentypen werden aus dem DataFrame abgeleitet, der zum Lesen von Daten aus der Quelle zur Anwendung käme.
- Bessere Datenverteilung über Executors hinweg kann durch Optimieren der Parameter
spark.sql.files.maxPartitionBytesundrepartition(für DataFrame) erreicht werden. - Beim Schreiben großer Datasets ist es wichtig, den Einfluss der Einstellung DWU Performance Level zu berücksichtigen, die die Transaktionsgröße begrenzt.
- Für interne Tabellentypen:
- Überwachen Sie die Nutzungstrends von Azure Data Lake Storage Gen2, um Drosselungsverhalten zu erkennen, die die Lese- und Schreibleistung beeinträchtigen können.