Tutorial: Verwenden von Pandas zum Lesen/Schreiben von Azure Data Lake Storage Gen2-Daten in einem serverlosen Apache Spark-Pool in Synapse Analytics
Erfahren Sie, wie Sie Pandas zum Lesen/Schreiben von Daten in Azure Data Lake Storage Gen2 (ADLS) mithilfe eines serverlosen Apache Spark-Pools in Azure Synapse Analytics verwenden. Die Beispiele in diesem Tutorial zeigen, wie Sie CSV-Daten mit Pandas in Synapse sowie Excel- und Parquet-Dateien lesen.
In diesem Tutorial lernen Sie Folgendes:
- Lesen/Schreiben von ADLS Gen2-Daten mithilfe von Pandas in einer Spark-Sitzung.
Wenn Sie kein Azure-Abonnement besitzen, können Sie ein kostenloses Konto erstellen, bevor Sie beginnen.
Voraussetzungen
Azure Synapse Analytics-Arbeitsbereich mit einem als Standardspeicher (oder primärem Speicher) konfigurierten Azure Data Lake Storage Gen2-Speicherkonto. Für das hier verwendete Data Lake Storage Gen2-Dateisystem müssen Sie über die Rolle Mitwirkender an Storage-Blobdaten verfügen.
Ein serverloser Apache Spark-Pool in Ihrem Azure Synapse Analytics-Arbeitsbereich. Ausführliche Informationen finden Sie unter Erstellen eines Spark-Pools in Azure Synapse.
Konfigurieren Sie das sekundäre Azure Data Lake Storage Gen2-Konto (kein Standardkonto im Synapse-Arbeitsbereich). Für das hier verwendete Data Lake Storage Gen2-Dateisystem müssen Sie über die Rolle Mitwirkender an Storage-Blobdaten verfügen.
Erstellen verknüpfter Dienste: In Azure Synapse Analytics definiert ein verknüpfter Dienst die Informationen Ihrer Verbindung mit dem Dienst. In diesem Tutorial fügen Sie einen verknüpften Azure Synapse Analytics-Dienst und einen verknüpften Azure Data Lake Storage Gen2-Dienst hinzu.
- Öffnen Sie Azure Synapse Studio, und wechseln Sie zur Registerkarte Verwalten.
- Wählen Sie unter Externe Verbindungen die Option Verknüpfte Dienste aus.
- Klicken Sie auf Neu, um einen verknüpften Dienst hinzuzufügen.
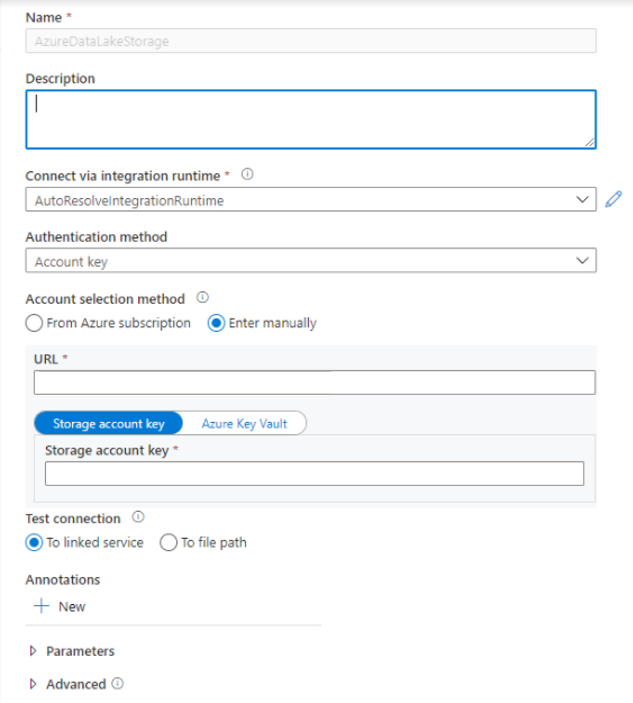
- Wählen Sie in der Liste die Kachel „Azure Data Lake Storage Gen2“ und dann Weiter aus.
- Geben Sie Ihre Anmeldeinformationen für die Authentifizierung ein. Kontoschlüssel, Dienstprinzipal (Service Principal, SP), Anmeldeinformationen und verwaltete Dienstidentität (Managed Service Identity, MSI) sind die derzeit unterstützten Authentifizierungstypen. Stellen Sie für SP und MSI sicher, dass ein Mitwirkender an Storage-Blobdaten im Speicher zugewiesen ist, bevor Sie einen dieser Typen für die Authentifizierung auswählen. Wählen Sie Verbindung testen aus, um Ihre Anmeldeinformationen zu überprüfen. Klicken Sie auf Erstellen.
Wichtig
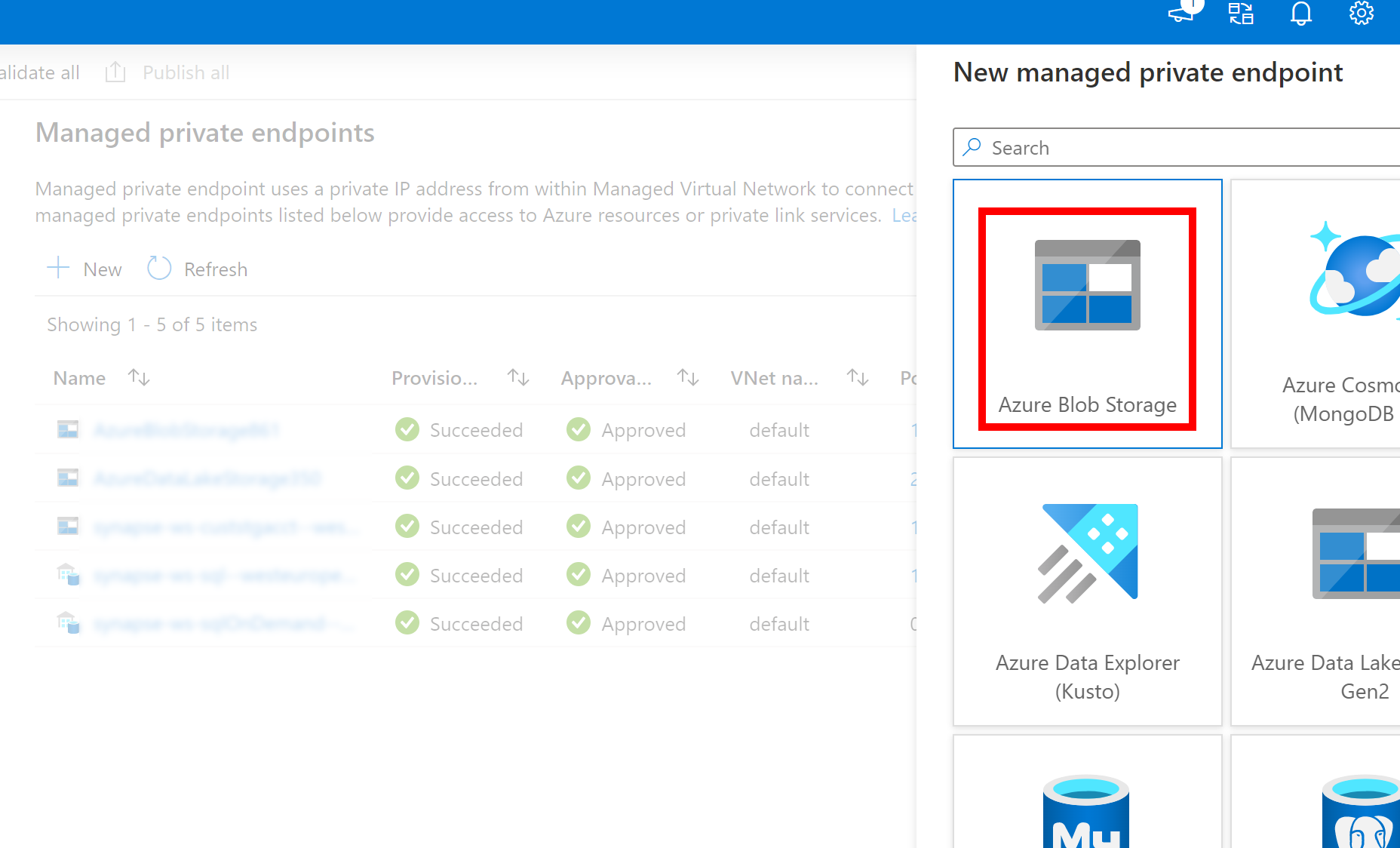
- Wenn der oben erstellte verknüpfte Dienst für Azure Data Lake Storage Gen2 einen verwalteten privaten Endpunkt (mit einem dfs-URI) verwendet, müssen wir einen weiteren sekundären verwalteten privaten Endpunkt mithilfe der Option „Azure Blob Storage“ (mit einem BLOB-URI) erstellen, um sicherzustellen, dass der interne fsspec/adlfs-Code eine Verbindung mithilfe der BlobServiceClient-Schnittstelle herstellen kann.
- Falls der sekundäre verwaltete private Endpunkt nicht ordnungsgemäß konfiguriert ist, wird eine Fehlermeldung wie ServiceRequestError: Es kann keine Verbindung mit dem Host [storageaccountname].blob.core.windows.net:443 ssl:True hergestellt werden [Name oder Dienst nicht bekannt] angezeigt.
Hinweis
- Das Pandas-Feature wird in Azure Synapse Analytics in serverlosen Apache Spark-Pools mit Python 3.8 und Spark3 unterstützt.
- Unterstützung ist für die folgenden Versionen verfügbar: pandas 1.2.3, fsspec 2021.10.0, adlfs 0.7.7.
- Funktionen zur Unterstützung sowohl von Azure Data Lake Storage Gen2-URIs (abfs[s]://file_system_name@account_name.dfs.core.windows.net/file_path) als auch von FSSPEC-Kurz-URLs (abfs[s]://container_name/file_path) sind erforderlich.
Melden Sie sich auf dem Azure-Portal an.
Melden Sie sich beim Azure-Portal an.
Lesen/Schreiben von Daten in das ADLS-Standardspeicherkonto des Synapse-Arbeitsbereichs
Pandas kann ADLS-Daten lesen/schreiben, indem der Dateipfad direkt angegeben wird.
Führen Sie den folgenden Code aus.
Hinweis
Aktualisieren Sie die Datei-URL in diesem Skript, bevor Sie es ausführen.
#Read data file from URI of default Azure Data Lake Storage Gen2
import pandas
#read csv file
df = pandas.read_csv('abfs[s]://file_system_name@account_name.dfs.core.windows.net/file_path')
print(df)
#write csv file
data = pandas.DataFrame({'Name':['A', 'B', 'C', 'D'], 'ID':[20, 21, 19, 18]})
data.to_csv('abfs[s]://file_system_name@account_name.dfs.core.windows.net/file_path')
#Read data file from FSSPEC short URL of default Azure Data Lake Storage Gen2
import pandas
#read csv file
df = pandas.read_csv('abfs[s]://container_name/file_path')
print(df)
#write csv file
data = pandas.DataFrame({'Name':['A', 'B', 'C', 'D'], 'ID':[20, 21, 19, 18]})
data.to_csv('abfs[s]://container_name/file_path')
Lesen/Schreiben von Daten mithilfe des sekundären ADLS-Kontos
Pandas kann sekundäre ADLS-Kontodaten auf folgende Arten lesen/schreiben:
- Unter Verwendung eines verknüpften Diensts (mit Authentifizierungsoptionen: Speicherkontoschlüssel, Dienstprinzipal, verwaltete Dienstidentität und Anmeldeinformationen)
- Unter Verwendung von Speicheroptionen, um Client-ID und Clientgeheimnis, SAS-Schlüssel, Speicherkontoschlüssel und Verbindungszeichenfolge direkt zu übergeben
Unter Verwendung eines verknüpften Diensts
Führen Sie den folgenden Code aus.
Hinweis
Aktualisieren Sie die Datei-URL und den Namen des verknüpften Diensts in diesem Skript, bevor Sie es ausführen.
#Read data file from URI of secondary Azure Data Lake Storage Gen2
import pandas
#read data file
df = pandas.read_csv('abfs[s]://file_system_name@account_name.dfs.core.windows.net/ file_path', storage_options = {'linked_service' : 'linked_service_name'})
print(df)
#write data file
data = pandas.DataFrame({'Name':['A', 'B', 'C', 'D'], 'ID':[20, 21, 19, 18]})
data.to_csv('abfs[s]://file_system_name@account_name.dfs.core.windows.net/file_path', storage_options = {'linked_service' : 'linked_service_name'})
#Read data file from FSSPEC short URL of default Azure Data Lake Storage Gen2
import pandas
#read data file
df = pandas.read_csv('abfs[s]://container_name/file_path', storage_options = {'linked_service' : 'linked_service_name'})
print(df)
#write data file
data = pandas.DataFrame({'Name':['A', 'B', 'C', 'D'], 'ID':[20, 21, 19, 18]})
data.to_csv('abfs[s]://container_name/file_path', storage_options = {'linked_service' : 'linked_service_name'})
Unter Verwendung von Speicheroptionen, um Client-ID und Clientgeheimnis, SAS-Schlüssel, Speicherkontoschlüssel und Verbindungszeichenfolge direkt zu übergeben
Führen Sie den folgenden Code aus.
Hinweis
Aktualisieren Sie die Datei-URL, und die Werte für „storage_options“ in diesem Skript, bevor Sie es ausführen.
#Read data file from URI of secondary Azure Data Lake Storage Gen2
import pandas
#read data file
df = pandas.read_csv('abfs[s]://file_system_name@account_name.dfs.core.windows.net/ file_path', storage_options = {'account_key' : 'account_key_value'})
## or storage_options = {'sas_token' : 'sas_token_value'}
## or storage_options = {'connection_string' : 'connection_string_value'}
## or storage_options = {'tenant_id': 'tenant_id_value', 'client_id' : 'client_id_value', 'client_secret': 'client_secret_value'}
print(df)
#write data file
data = pandas.DataFrame({'Name':['A', 'B', 'C', 'D'], 'ID':[20, 21, 19, 18]})
data.to_csv('abfs[s]://file_system_name@account_name.dfs.core.windows.net/file_path', storage_options = {'account_key' : 'account_key_value'})
## or storage_options = {'sas_token' : 'sas_token_value'}
## or storage_options = {'connection_string' : 'connection_string_value'}
## or storage_options = {'tenant_id': 'tenant_id_value', 'client_id' : 'client_id_value', 'client_secret': 'client_secret_value'}
#Read data file from FSSPEC short URL of default Azure Data Lake Storage Gen2
import pandas
#read data file
df = pandas.read_csv('abfs[s]://container_name/file_path', storage_options = {'account_key' : 'account_key_value'})
## or storage_options = {'sas_token' : 'sas_token_value'}
## or storage_options = {'connection_string' : 'connection_string_value'}
## or storage_options = {'tenant_id': 'tenant_id_value', 'client_id' : 'client_id_value', 'client_secret': 'client_secret_value'}
print(df)
#write data file
data = pandas.DataFrame({'Name':['A', 'B', 'C', 'D'], 'ID':[20, 21, 19, 18]})
data.to_csv('abfs[s]://container_name/file_path', storage_options = {'account_key' : 'account_key_value'})
## or storage_options = {'sas_token' : 'sas_token_value'}
## or storage_options = {'connection_string' : 'connection_string_value'}
## or storage_options = {'tenant_id': 'tenant_id_value', 'client_id' : 'client_id_value', 'client_secret': 'client_secret_value'}
Beispiel für das Lesen/Schreiben einer Parquet-Datei
Führen Sie den folgenden Code aus.
Hinweis
Aktualisieren Sie die Datei-URL in diesem Skript, bevor Sie es ausführen.
import pandas
#read parquet file
df = pandas.read_parquet('abfs[s]://file_system_name@account_name.dfs.core.windows.net/ parquet_file_path')
print(df)
#write parquet file
df.to_parquet('abfs[s]://file_system_name@account_name.dfs.core.windows.net/ parquet_file_path')
Beispiel für das Lesen/Schreiben einer Excel-Datei
Führen Sie den folgenden Code aus.
Hinweis
Aktualisieren Sie die Datei-URL in diesem Skript, bevor Sie es ausführen.
import pandas
#read excel file
df = pandas.read_excel('abfs[s]://file_system_name@account_name.dfs.core.windows.net/ excel_file_path')
print(df)
#write excel file
df.to_excel('abfs[s]://file_system_name@account_name.dfs.core.windows.net/excel_file_path')