Leistungsoptimierung mit einem sortierten gruppierten Columnstore-Index
Gilt für: Dedizierte SQL-Pools in Azure Synapse Analytics, SQL Server 2022 (16.x) und höher
Wenn Benutzer eine Columnstore-Tabelle in dedizierten SQL-Pools abfragen, überprüft der Optimierer die minimalen und maximalen Werte, die in den einzelnen Segmenten gespeichert sind. Segmente, die sich außerhalb der Grenzen des Abfrageprädikats befinden, werden nicht vom Datenträger in den Arbeitsspeicher gelesen. Eine Abfrage kann schneller abgeschlossen werden, wenn die Anzahl der zu lesenden Segmente und deren Gesamtgröße gering ist.
Vergleich sortierter und nicht sortierter gruppierter Columnstore-Indizes
Standardmäßig erstellt eine interne Komponente (Index-Generator) für jede Tabelle, die ohne Indexoption erstellt wurde, einen nicht geordneten gruppierten Columnstore-Index (CCI). Die Daten den einzelnen Spalten werden in einem separaten CCI-Zeilengruppensegment komprimiert. Für den Wertebereich jedes Segments gibt es Metadaten, sodass Segmente, die sich außerhalb der Grenzen des Abfrageprädikats befinden, während der Abfrageausführung nicht von der Festplatte gelesen werden. CCI bietet den höchsten Grad an Datenkomprimierung und verringert die Größe der zu lesenden Segmente, damit Abfragen schneller ausgeführt werden. Da der Index-Generator die Daten jedoch nicht sortiert, bevor er sie in Segmente komprimiert, können Segmente mit überlappenden Wertebereichen auftreten, was dazu führt, dass Abfragen mehr Segmente vom Datenträger lesen muss und die Fertigstellung länger dauert.
Sortierte gruppierte Columnstore-Indizes, indem eine effiziente Segmententfernung aktiviert wurde, was zu einer viel schnelleren Leistung führt, da große Mengen sortierter Daten, die nicht mit dem Abfrage-Prädikat übereinstimmen, übersprungen werden Beim Erstellen einer geordneten CCI-Tabelle sortiert die Engine des dedizierten SQL-Pools die vorhandenen Daten im Arbeitsspeicher nach dem/den Sortierschlüssel(n), bevor sie der Index-Generator in Indexsegmente komprimiert. Bei sortierten Daten wird die Überlappung von Segmenten verringert, sodass Abfragen Segmente effizienter entfernen können und somit eine schnellere Leistung aufweisen, da die Anzahl der Segmente, die vom Datenträger gelesen werden sollen, kleiner ist. Die Überlappung von Segmenten lässt sich vermeiden, wenn alle Daten im Arbeitsspeicher gleichzeitig sortiert werden. Aufgrund großer Tabellen in Data Warehouses kommt dieses Szenario nicht häufig vor.
Wenn Sie die Segmentbereiche für eine Spalte überprüfen möchten, führen Sie den folgenden Befehl unter Angabe Ihres Tabellen- und Spaltennamens aus:
SELECT o.name, pnp.index_id,
cls.row_count, pnp.data_compression_desc,
pnp.pdw_node_id, pnp.distribution_id, cls.segment_id,
cls.column_id,
cls.min_data_id, cls.max_data_id,
cls.max_data_id-cls.min_data_id as difference
FROM sys.pdw_nodes_partitions AS pnp
JOIN sys.pdw_nodes_tables AS Ntables ON pnp.object_id = NTables.object_id AND pnp.pdw_node_id = NTables.pdw_node_id
JOIN sys.pdw_table_mappings AS Tmap ON NTables.name = TMap.physical_name AND substring(TMap.physical_name,40, 10) = pnp.distribution_id
JOIN sys.objects AS o ON TMap.object_id = o.object_id
JOIN sys.pdw_nodes_column_store_segments AS cls ON pnp.partition_id = cls.partition_id AND pnp.distribution_id = cls.distribution_id
JOIN sys.columns as cols ON o.object_id = cols.object_id AND cls.column_id = cols.column_id
WHERE o.name = '<Table Name>' and cols.name = '<Column Name>' and TMap.physical_name not like '%HdTable%'
ORDER BY o.name, pnp.distribution_id, cls.min_data_id;
Hinweis
In einer sortierten CCI-Tabelle werden die neuen Daten aus dem gleichen Batch von DML- oder Datenladevorgängen innerhalb dieses Batches sortiert, es findet jedoch keine globale Sortierung aller Daten in der Tabelle statt. Benutzer können die geordnete CCI-Tabelle neu erstellen (REBUILD), um alle Daten in der Tabelle zu sortieren. Im dedizierten SQL-Pool ist die Neuerstellung des Columnstore-Indexes ein Offlinevorgang. Bei einer partitionierten Tabelle erfolgt die Neuerstellung (REBUILD) der Partitionen nacheinander. Die Daten in der Partition, die neu erstellt wird, sind „offline“ und nicht verfügbar, bis die Neuerstellung (REBUILD) für diese Partition beendet ist.
Abfrageleistung
Der Leistungsgewinn einer Abfrage aus einer geordneten CCI-Tabelle hängt von den Abfragemustern, der Größe der Daten, der Art der Sortierung der Daten, der physischen Struktur von Segmenten und der DWU und Ressourcenklasse ab, die für die Ausführung der Abfrage ausgewählt wurden. Benutzer sollten alle diese Faktoren überprüfen, bevor Sie die Ordnungsspalten beim Entwerfen einer geordneten CCI-Tabelle auswählen.
Abfragen mit all diesen Mustern werden normalerweise schneller mit einer geordneten CCI-Tabelle ausgeführt.
- Die Abfragen verfügen über Gleichheits-, Ungleichheits- oder Bereichsprädikate.
- Die Prädikatspalten und die geordneten CCI-Spalten sind identisch.
In diesem Beispiel verfügt die Tabelle T1 über einen gruppierten Columnstore-Index, der in der Reihenfolge Col_C, Col_B und Col_A sortiert ist.
CREATE CLUSTERED COLUMNSTORE INDEX MyOrderedCCI ON T1
ORDER (Col_C, Col_B, Col_A);
Für Abfrage 1 und Abfrage 2 können sortierte CCI-Daten einen größeren Leistungsvorteil bieten als für andere Abfragen, da sie auf alle sortierten CCI-Spalten verweisen.
-- Query #1:
SELECT * FROM T1 WHERE Col_C = 'c' AND Col_B = 'b' AND Col_A = 'a';
-- Query #2
SELECT * FROM T1 WHERE Col_B = 'b' AND Col_C = 'c' AND Col_A = 'a';
-- Query #3
SELECT * FROM T1 WHERE Col_B = 'b' AND Col_A = 'a';
-- Query #4
SELECT * FROM T1 WHERE Col_A = 'a' AND Col_C = 'c';
Leistung beim Laden von Daten
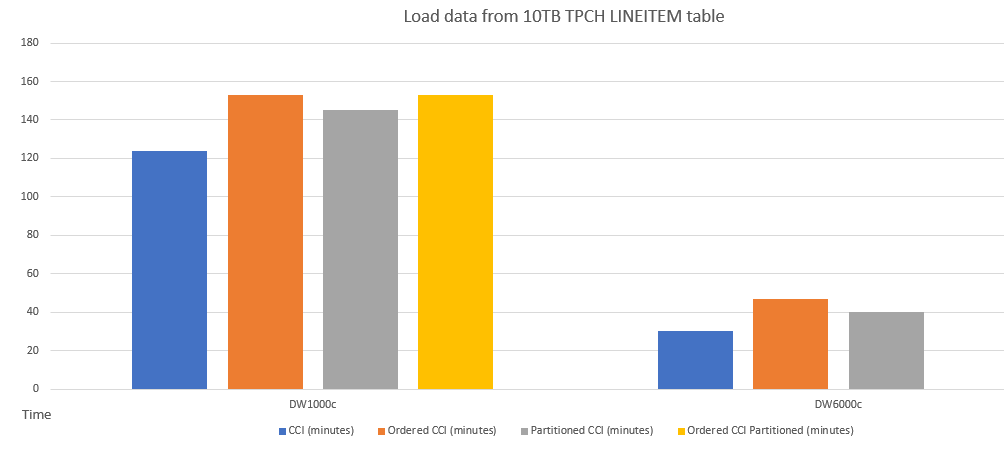
Die Leistung beim Laden von Daten in eine sortierte CCI-Tabelle ähnelt dem Laden einer partitionierten Tabelle. Das Laden von Daten in eine geordnete CCI-Tabelle kann aufgrund des Datensortiervorgangs länger als das Laden in eine nicht geordnete CCI-Tabelle dauern. Abfragen können jedoch später mit einer geordneten CCI-Tabelle schneller ausgeführt werden.
Im Folgenden finden Sie ein Beispiel für einen Leistungsvergleich beim Laden von Daten in Tabellen mit unterschiedlichen Schemas.
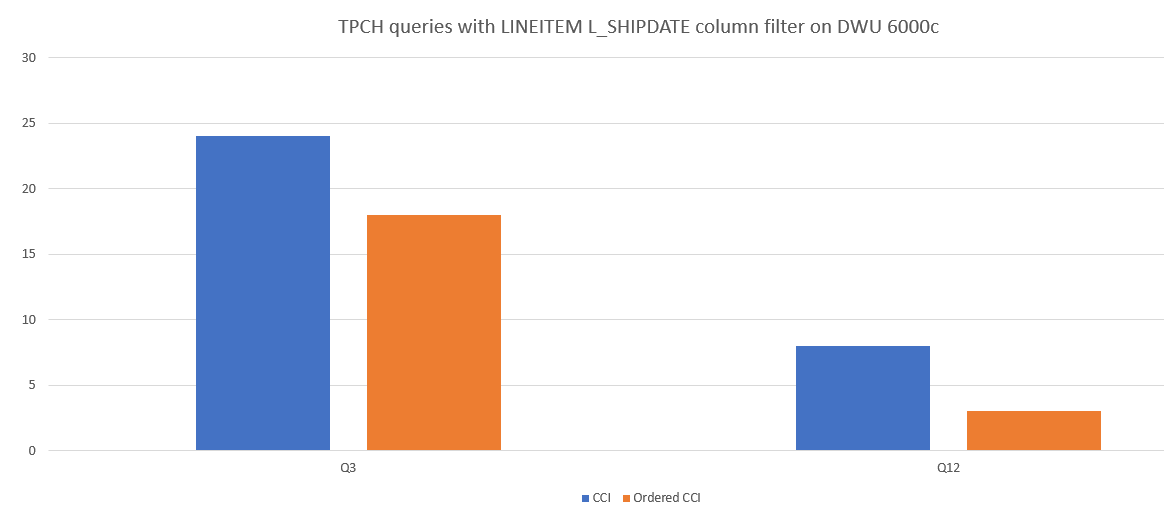
Im Folgenden finden Sie ein Beispiel für einen Abfrageleistungsvergleich zwischen einer CCI-Tabelle und einer sortierten CCI-Tabelle.
Verringern der Überlappung von Segmenten
Die Anzahl der sich überlappenden Segmente hängt von der Größe der zu sortierenden Daten, dem verfügbaren Arbeitsspeicher und der Einstellung des maximalen Parallelitätsgrads (MAXDOP) bei der Erstellung einer geordneten CCI-Tabelle ab. Die folgenden Strategien reduzieren Segmentüberschneidungen beim Erstellen sortierter CCI.
Verwenden Sie die Ressourcenklasse
xlargercfür eine höhere DWU, damit mehr Arbeitsspeicher für die Datensortierung bereitgestellt wird, bevor der Index-Generator die Daten in Segmente komprimiert. In einem Indexsegment kann der physische Speicherort der Daten nicht mehr geändert werden. Innerhalb eines Segments oder segmentübergreifend gibt es keine Datensortierung.Erstellen Sie eine sortierte CCI-Tabelle mit
OPTION (MAXDOP = 1). Jeder Thread, der für die Erstellung eines sortierten CCI verwendet wird, verarbeitet eine Teilmenge an Daten und sortiert diese lokal. Für Daten, die von unterschiedlichen Threads sortiert wurden, gibt es keine globale Sortierung. Mithilfe paralleler Threads kann die Zeit zum Erstellen eines sortierten CCI verkürzt werden. Dabei werden jedoch mehr überlappende Segmente generiert als bei der Verwendung eines einzelnen Threads. Die Verwendung eines einzelnen Threads für einen Vorgang liefert die höchste Komprimierungsqualität. Zum Beispiel:
CREATE TABLE Table1 WITH (DISTRIBUTION = HASH(c1), CLUSTERED COLUMNSTORE INDEX ORDER(c1) )
AS SELECT * FROM ExampleTable
OPTION (MAXDOP 1);
Hinweis
Derzeit wird in dedizierten SQL-Pools in Azure Synapse Analytics die Option MAXDOP nur beim Erstellen einer sortierten CCI-Tabelle mit dem Befehl CREATE TABLE AS SELECT unterstützt. Beim Erstellen einer sortierten CCI-Tabelle mit den Befehlen CREATE INDEX oder CREATE TABLE wird die Option MAXDOP nicht unterstützt. Diese Einschränkung gilt nicht für SQL Server 2022 und höhere Versionen, bei denen Sie MAXDOP mit den Befehlen CREATE INDEX oder CREATE TABLE angeben können.
- Sortieren Sie die Daten vorab nach den Sortierschlüsseln, bevor Sie sie in Tabellen laden.
Im Folgenden finden Sie ein Beispiel für die Verteilung einer sortierten CCI-Tabelle ohne Segmentüberlappungen, bei der die oben genannten Empfehlungen beachtet wurden. Die sortierte CCI-Tabelle wird in einer DWU1000c-Datenbank über CTAS aus einer Heaptabelle mit 20 GB mithilfe von MAXDOP 1 und xlargerc erstellt. Die CCI-Tabelle wird in einer BIGINT-Spalte ohne Duplikate sortiert.
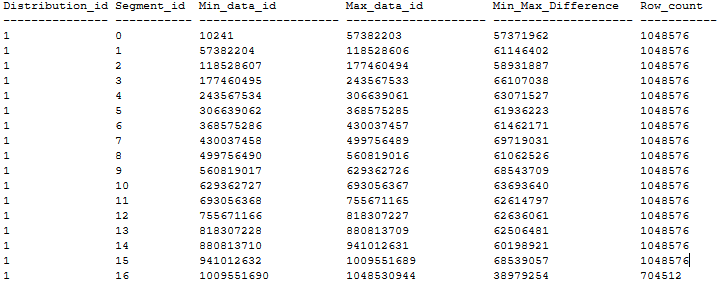
Erstellen eines sortierten CCI für große Tabellen
Das Erstellen eines sortierten CCI ist ein Offlinevorgang. Bei Tabellen ohne Partitionen sind die Daten für Benutzer erst verfügbar, wenn der Erstellungsprozess des sortierten CCI abgeschlossen ist. Da die Engine sortierte CCI-Partitionen für partitionierte Tabellen nach Partition erstellt, können die Benutzer auf die Daten in den Partitionen weiterhin zugreifen, für die die Erstellung des sortierten CCI nicht gerade erfolgt. Mit dieser Option können Sie die Ausfallzeiten beim Erstellen eines sortierten CCI für große Tabellen minimieren:
- Erstellen Sie Partitionen für die große Zieltabelle (
Table_A). - Erstellen Sie eine leere sortierte CCI-Tabelle (
Table_B), die dasselbe Tabellen- und Partitionsschema wieTable_Aaufweist. - Fügen Sie eine Partition von
Table_AinTable_Bein. - Führen Sie
ALTER INDEX <Ordered_CCI_Index> ON <Table_B> REBUILD PARTITION = <Partition_ID>fürTable_Baus, um die eingefügte Partition neu zu erstellen. - Wiederholen Sie die Schritte 3 und 4 für jede Partition in
Table_A. - Nachdem alle Partitionen von
Table_AinTable_Beingefügt und neu erstellt wurden, löschen SieTable_A, und benennen SieTable_BinTable_Aum.
Tipp
Bei einer dedizierten SQL-Pooltabelle mit einem sortierten CCI sortiert ALTER INDEX REBUILD die Daten mit tempdb neu. Überwachen Sie tempdb während der Neuerstellungsvorgänge. Wenn Sie mehr tempdb-Speicherplatz benötigen, können Sie den Pool hochskalieren. Skalieren Sie es nach Abschluss der Indexneuerstellung wieder herunter.
Bei einer dedizierten SQL-Pooltabelle mit einem geordneten CCI sortiert ALTER INDEX REORGANIZE die Daten neu. Verwenden Sie ALTER INDEX REBUILD, um die Daten neu zu sortieren.
Weitere Informationen zur geordneten CCI-Wartung finden Sie unter Optimieren von gruppierten Columnstore-Indizes.
Unterschiede bei den Features und Funktionen von SQL Server 2022
In SQL Server 2022 (16.x) wurden sortierte gruppierte Columnstore-Indizes eingeführt, die mit dem Feature in dedizierten SQL-Pools in Azure Synapse vergleichbar sind.
- Derzeit unterstützen nur SQL Server 2022 (16.x) und höhere Versionen die erweiterten Funktionen gruppierter Columnstore-Indizes zur Segmenteleminierung für die Datentypen „String“, „Binary“ und „GUID“ sowie den Datentyp „datetimeoffset“ für eine Skalierung von mehr als zwei. Zuvor galt diese Segmenteliminierung für numerische, Datums- und Zeitdatentypen sowie für den Datentyp „datetimeoffset“ mit einer Skalierung kleiner oder gleich zwei.
- Derzeit unterstützen nur SQL Server 2022 (16.x) und höhere Versionen für gruppierte Columnstore-Indizes die Zeilengruppenlöschung für das Präfix von
LIKE-Prädikaten, z. B.column LIKE 'string%'. Die Segmenteliminierung wird für die Verwendung von LIKE ohne Präfix wie z. B.column LIKE '%string'nicht unterstützt.
Weitere Informationen finden Sie unter Neuerungen in Columnstore-Indizes.
Beispiele
A. So suchen Sie sortierte Spalten und die Ordnungszahl der Sortierung:
SELECT object_name(c.object_id) table_name, c.name column_name, i.column_store_order_ordinal
FROM sys.index_columns i
JOIN sys.columns c ON i.object_id = c.object_id AND c.column_id = i.column_id
WHERE column_store_order_ordinal <>0;
B. Fügen Sie Spalten aus der Sortierliste hinzu, oder entfernen Sie sie, wenn Sie die Ordnungszahl der Spalte ändern möchten oder von einem CCI zu einem sortierten CCI wechseln möchten:
CREATE CLUSTERED COLUMNSTORE INDEX InternetSales ON dbo.InternetSales
ORDER (ProductKey, SalesAmount)
WITH (DROP_EXISTING = ON);
Nächste Schritte
- Weitere Hinweise zur Entwicklung finden Sie in der Entwicklungsübersicht.
- Columnstore-Indizes: Übersicht
- Neuerungen in Columnstore-Indizes
- Leitfaden zum Entwerfen von Columnstore-Indizes
- Columnstore-Indizes: Abfrageleistung