Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
Tip
Microsoft Fabric Data Warehouse ist ein relationales Enterprise-Warehouse auf einem Data Lake-Fundament mit zukunftsfähiger Architektur, integrierter KI und neuen Features. Wenn Sie mit Data Warehouse noch nicht vertraut sind, beginnen Sie mit Fabric Data Warehouse. Vorhandene dedizierte SQL-Pool-Workloads können auf Fabric aktualisieren, um neue Funktionen in den Bereichen Data Science, Echtzeitanalyse und Berichterstellung zu nutzen.
In diesem Artikel erfahren Sie, wie Sie in Azure Synapse Analytics eine einzelne CSV-Datei mithilfe eines serverlosen SQL-Pools abfragen. CSV-Dateien können unterschiedliche Formate aufweisen:
- Mit und ohne Kopfzeile
- Werte mit Kommas und Tabstopps als Trennzeichen
- Zeilenenden im Windows- und Unix-Stil
- Werte mit und ohne Anführungszeichen sowie Zeichen mit Escapezeichen
Alle oben aufgeführten Varianten werden im Folgenden behandelt.
Schnellstartbeispiel
Mit der Funktion OPENROWSET können Sie den Inhalt einer CSV-Datei lesen, indem Sie die URL zur Datei bereitstellen.
Lesen einer CSV-Datei
Am einfachsten können Sie den Inhalt Ihrer CSV-Datei anzeigen, indem Sie der Funktion OPENROWSET die Datei-URL bereitstellen und CSV als FORMAT sowie 2.0 als PARSER_VERSION angeben. Wenn die Datei öffentlich verfügbar ist oder Ihre Microsoft Entra-Identität auf diese Datei zugreifen kann, sollten Sie den Inhalt der Datei mithilfe einer Abfrage wie im folgenden Beispiel anzeigen können:
select top 10 *
from openrowset(
bulk 'https://pandemicdatalake.blob.core.windows.net/public/curated/covid-19/ecdc_cases/latest/ecdc_cases.csv',
format = 'csv',
parser_version = '2.0',
firstrow = 2 ) as rows
Mit der Option firstrow wird die erste Zeile in der CSV-Datei übersprungen, bei der es sich in diesem Fall um den Header handelt. Stellen Sie sicher, dass Sie auf diese Datei zugreifen können. Wenn Ihre Datei mit SAS-Schlüssel oder benutzerdefinierter Identität geschützt ist, müssen Sie Anmeldeinformationen auf Serverebene für die SQL-Anmeldung einrichten.
Wichtig
Wenn Ihre CSV-Datei UTF-8 Zeichen enthält, stellen Sie sicher, dass Sie eine UTF-8-Datenbanksortierung verwenden (z. B Latin1_General_100_CI_AS_SC_UTF8. ).
Ein Konflikt zwischen der Textcodierung in der Datei und der Sortierung kann zu unerwarteten Konvertierungsfehlern führen.
Die Standardsortierung der aktuellen Datenbank kann mithilfe der folgenden T-SQL-Anweisung problemlos geändert werden: alter database current collate Latin1_General_100_CI_AI_SC_UTF8
Datenquellennutzung
Im vorherigen Beispiel wird der vollständige Pfad zur Datei verwendet. Alternativ können Sie eine externe Datenquelle mit dem Speicherort erstellen, der auf den Stammordner des Speichers verweist:
create external data source covid
with ( location = 'https://pandemicdatalake.blob.core.windows.net/public/curated/covid-19/ecdc_cases' );
Nachdem Sie eine Datenquelle erstellt haben, können Sie diese Datenquelle und den relativen Pfad zur Datei in der Funktion OPENROWSET verwenden:
select top 10 *
from openrowset(
bulk 'latest/ecdc_cases.csv',
data_source = 'covid',
format = 'csv',
parser_version ='2.0',
firstrow = 2
) as rows
Wenn eine Datenquelle mit SAS-Schlüssel oder benutzerdefinierter Identität geschützt ist, können Sie die Datenquelle mit datenbankbezogenen Anmeldeinformationen konfigurieren.
Explizites Angeben des Schemas
Bei OPENROWSET können Sie mit der WITH-Klausel explizit angeben, welche Spalten aus der Datei gelesen werden sollen:
select top 10 *
from openrowset(
bulk 'latest/ecdc_cases.csv',
data_source = 'covid',
format = 'csv',
parser_version ='2.0',
firstrow = 2
) with (
date_rep date 1,
cases int 5,
geo_id varchar(6) 8
) as rows
Die Zahlen nach einem Datentyp in der WITH-Klausel stellen den Spaltenindex in der CSV-Datei dar.
Wichtig
Wenn die CSV-Datei UTF-8-Zeichen enthält, stellen Sie sicher, dass Sie explizit eine UTF-8-Sortierung (z. B. Latin1_General_100_CI_AS_SC_UTF8) für alle Spalten in der WITH-Klausel angeben, oder legen Sie eine UTF-8-Sortierung auf Datenbankebene fest.
Ein Konflikt zwischen der Textcodierung in der Datei und der Sortierung kann zu unerwarteten Konvertierungsfehlern führen.
Die Standardsortierung der aktuellen Datenbank kann mithilfe der folgenden T-SQL-Anweisung problemlos geändert werden:
alter database current collate Latin1_General_100_CI_AI_SC_UTF8Sie können die Sortierung der Spaltentypen problemlos mit der folgenden Definition festlegen: geo_id varchar(6) collate Latin1_General_100_CI_AI_SC_UTF8 8
In den folgenden Abschnitten erfahren Sie, wie Sie verschiedene Typen von CSV-Dateien abfragen.
Voraussetzungen
Im ersten Schritt erstellen Sie eine Datenbank, in der die Tabellen erstellt werden sollen. Initialisieren Sie dann die Objekte, indem Sie das Setupskript für diese Datenbank ausführen. Mit diesem Setupskript werden die Datenquellen, die für die gesamte Datenbank gültigen Anmeldeinformationen und externe Dateiformate erstellt, die in diesen Beispielen verwendet werden.
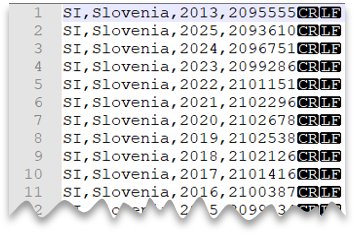
Neue-Zeile-Zeichen im Windows-Stil
Die folgende Abfrage zeigt, wie eine CSV-Datei ohne Kopfzeile gelesen wird, die ein Neue-Zeile-Zeichen im Windows-Stil und Spalten mit Kommas als Trennzeichen enthält.
Dateivorschau:
SELECT *
FROM OPENROWSET(
BULK 'csv/population/population.csv',
DATA_SOURCE = 'SqlOnDemandDemo',
FORMAT = 'CSV', PARSER_VERSION = '2.0',
FIELDTERMINATOR =',',
ROWTERMINATOR = '\n'
)
WITH (
[country_code] VARCHAR (5) COLLATE Latin1_General_BIN2,
[country_name] VARCHAR (100) COLLATE Latin1_General_BIN2,
[year] smallint,
[population] bigint
) AS [r]
WHERE
country_name = 'Luxembourg'
AND year = 2017;
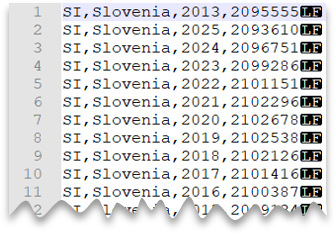
Neue-Zeile-Zeichen im Unix-Stil
Die folgende Abfrage zeigt, wie eine Datei ohne Kopfzeile gelesen wird, die ein Neue-Zeile-Zeichen im Unix-Stil und Spalten mit Kommas als Trennzeichen enthält. Beachten Sie den abweichenden Speicherort der Datei im Vergleich zu den anderen Beispielen.
Dateivorschau:
SELECT *
FROM OPENROWSET(
BULK 'csv/population-unix/population.csv',
DATA_SOURCE = 'SqlOnDemandDemo',
FORMAT = 'CSV', PARSER_VERSION = '2.0',
FIELDTERMINATOR =',',
ROWTERMINATOR = '0x0a'
)
WITH (
[country_code] VARCHAR (5) COLLATE Latin1_General_BIN2,
[country_name] VARCHAR (100) COLLATE Latin1_General_BIN2,
[year] smallint,
[population] bigint
) AS [r]
WHERE
country_name = 'Luxembourg'
AND year = 2017;
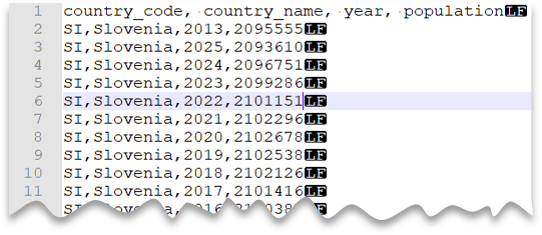
Kopfzeile
Die folgende Abfrage zeigt, wie eine Datei mit einer Kopfzeile, mit einem Neue-Zeile-Zeichen im Unix-Stil und Spalten mit Kommas als Trennzeichen gelesen wird. Beachten Sie den abweichenden Speicherort der Datei im Vergleich zu den anderen Beispielen.
Dateivorschau:
SELECT *
FROM OPENROWSET(
BULK 'csv/population-unix-hdr/population.csv',
DATA_SOURCE = 'SqlOnDemandDemo',
FORMAT = 'CSV', PARSER_VERSION = '2.0',
FIELDTERMINATOR =',',
HEADER_ROW = TRUE
) AS [r]
Die Option HEADER_ROW = TRUE bewirkt, dass Spaltennamen aus der Kopfzeile der Datei gelesen werden. Es eignet sich hervorragend für Erkundungszwecke, wenn Sie nicht mit Dateiinhalten vertraut sind. Optimale Leistung finden Sie im Abschnitt "Geeignete Datentypen verwenden" in "Bewährte Methoden". Auch können Sie mehr über die OPENROWSET-Syntax lesen.
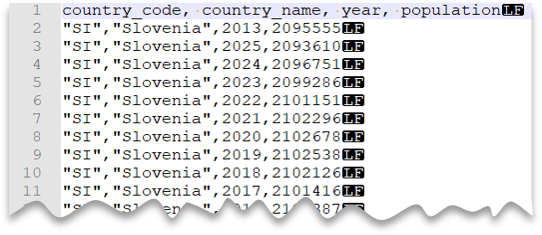
Benutzerdefiniertes Anführungszeichen
Die folgende Abfrage zeigt, wie eine Datei mit Kopfzeile gelesen wird, die ein Neue-Zeile-Zeichen im Unix-Stil, Spalten mit Kommas als Trennzeichen und Werte in Anführungszeichen enthält. Beachten Sie den abweichenden Speicherort der Datei im Vergleich zu den anderen Beispielen.
Dateivorschau:
SELECT *
FROM OPENROWSET(
BULK 'csv/population-unix-hdr-quoted/population.csv',
DATA_SOURCE = 'SqlOnDemandDemo',
FORMAT = 'CSV', PARSER_VERSION = '2.0',
FIELDTERMINATOR =',',
ROWTERMINATOR = '0x0a',
FIRSTROW = 2,
FIELDQUOTE = '"'
)
WITH (
[country_code] VARCHAR (5) COLLATE Latin1_General_BIN2,
[country_name] VARCHAR (100) COLLATE Latin1_General_BIN2,
[year] smallint,
[population] bigint
) AS [r]
WHERE
country_name = 'Luxembourg'
AND year = 2017;
Hinweis
Diese Abfrage würde dieselben Ergebnisse liefern, wenn Sie den FIELDQUOTE-Parameter weglassen, da der Standardwert für FIELDQUOTE ein doppeltes Anführungszeichen ist.
Escape-Zeichen
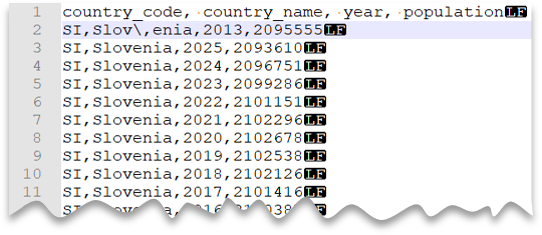
Die folgende Abfrage zeigt, wie eine Datei mit einer Kopfzeile, mit einem Neue-Zeile-Zeichen im Unix-Stil, Spalten mit Kommas als Trennzeichen und einem Zeichen mit Escapezeichen für das Feldtrennzeichen (Komma) innerhalb von Werten gelesen werden kann. Beachten Sie den abweichenden Speicherort der Datei im Vergleich zu den anderen Beispielen.
Dateivorschau:
SELECT *
FROM OPENROWSET(
BULK 'csv/population-unix-hdr-escape/population.csv',
DATA_SOURCE = 'SqlOnDemandDemo',
FORMAT = 'CSV', PARSER_VERSION = '2.0',
FIELDTERMINATOR =',',
ROWTERMINATOR = '0x0a',
FIRSTROW = 2,
ESCAPECHAR = '\\'
)
WITH (
[country_code] VARCHAR (5) COLLATE Latin1_General_BIN2,
[country_name] VARCHAR (100) COLLATE Latin1_General_BIN2,
[year] smallint,
[population] bigint
) AS [r]
WHERE
country_name = 'Slovenia';
Hinweis
Diese Abfrage würde fehlschlagen, wenn ESCAPECHAR nicht angegeben wird, da das Komma in "Slov,enia" anstelle eines Teils des Namens des Landes/der Region als Feldtrennzeichen behandelt wird. „Slov,enia“ würde als zwei Spalten behandelt. Daher hätte die bestimmte Zeile eine Spalte mehr als die anderen Zeilen und eine Spalte mehr als Sie in der WITH-Klausel definiert haben.
Versehen von Anführungszeichen mit Escapezeichen
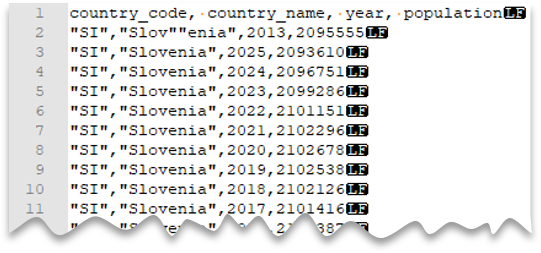
Die folgende Abfrage zeigt, wie eine Datei mit einer Kopfzeile, mit einem Neue-Zeile-Zeichen im Unix-Stil, mit kommagetrennten Spalten und mit einem mit Escapezeichen versehenen doppelten Anführungszeichen innerhalb von Werten gelesen werden kann. Beachten Sie den abweichenden Speicherort der Datei im Vergleich zu den anderen Beispielen.
Dateivorschau:
SELECT *
FROM OPENROWSET(
BULK 'csv/population-unix-hdr-escape-quoted/population.csv',
DATA_SOURCE = 'SqlOnDemandDemo',
FORMAT = 'CSV', PARSER_VERSION = '2.0',
FIELDTERMINATOR =',',
ROWTERMINATOR = '0x0a',
FIRSTROW = 2
)
WITH (
[country_code] VARCHAR (5) COLLATE Latin1_General_BIN2,
[country_name] VARCHAR (100) COLLATE Latin1_General_BIN2,
[year] smallint,
[population] bigint
) AS [r]
WHERE
country_name = 'Slovenia';
Hinweis
Das Anführungszeichen muss mit einem weiteren Anführungszeichen als Escapezeichen versehen werden. Anführungszeichen können nur in Spaltenwerten enthalten sein, wenn der Wert mit Anführungszeichen gekapselt ist.
Dateien mit Tabstopps als Trennzeichen
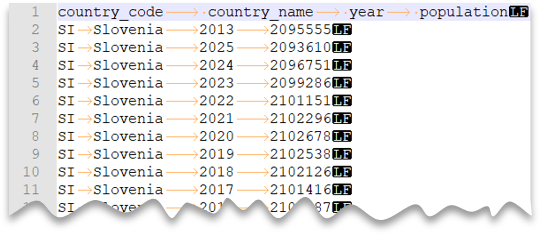
Die folgende Abfrage zeigt, wie eine Datei mit Kopfzeile gelesen wird, die ein Neue-Zeile-Zeichen im Unix-Stil und Spalten mit Tabstopps als Trennzeichen enthält. Beachten Sie den abweichenden Speicherort der Datei im Vergleich zu den anderen Beispielen.
Dateivorschau:
SELECT *
FROM OPENROWSET(
BULK 'csv/population-unix-hdr-tsv/population.csv',
DATA_SOURCE = 'SqlOnDemandDemo',
FORMAT = 'CSV', PARSER_VERSION = '2.0',
FIELDTERMINATOR ='\t',
ROWTERMINATOR = '0x0a',
FIRSTROW = 2
)
WITH (
[country_code] VARCHAR (5) COLLATE Latin1_General_BIN2,
[country_name] VARCHAR (100) COLLATE Latin1_General_BIN2,
[year] smallint,
[population] bigint
) AS [r]
WHERE
country_name = 'Luxembourg'
AND year = 2017
Zurückgeben einer Teilmenge von Spalten
Bisher haben Sie das CSV-Dateischema mit WITH angegeben und alle Spalten aufgelistet. Sie können nur Spalten angeben, die Sie in Ihrer Abfrage tatsächlich benötigen, indem Sie für jede erforderliche Spalte eine Ordnungszahl verwenden. Sie werden auch Spalten weglassen, die Sie nicht interessieren.
Die folgende Abfrage gibt die Anzahl der verschiedenen Länder-/Regionsnamen in einer Datei zurück, wobei nur die erforderlichen Spalten angegeben werden:
Hinweis
Werfen Sie einen Blick auf die WITH-Klausel in der Abfrage unten und beachten Sie, dass am Ende der Zeile, in der Sie die Spalte [country_name] definieren, „2“ (ohne Anführungszeichen) steht. Dies bedeutet, dass die Spalte [country_name] die zweite Spalte in der Datei ist. Die Abfrage ignoriert alle Spalten in der Datei außer der zweiten.
SELECT
COUNT(DISTINCT country_name) AS countries
FROM OPENROWSET(
BULK 'csv/population/population.csv',
DATA_SOURCE = 'SqlOnDemandDemo',
FORMAT = 'CSV', PARSER_VERSION = '2.0',
FIELDTERMINATOR =',',
ROWTERMINATOR = '\n'
)
WITH (
--[country_code] VARCHAR (5),
[country_name] VARCHAR (100) 2
--[year] smallint,
--[population] bigint
) AS [r]
Abfragen von anhängbaren Dateien
Die CSV-Dateien, die in der Abfrage verwendet werden, sollten nicht geändert werden, während die Abfrage ausgeführt wird. In der Abfrage mit langer Ausführungszeit kann es vorkommen, dass der SQL-Pool Leseversuche wiederholt, Teile der Dateien liest oder die Datei sogar mehrmals liest. Änderungen am Dateiinhalt würden zu falschen Ergebnissen führen. Daher schlägt der SQL-Pool die Abfrage fehl, wenn erkannt wird, dass die Änderungszeit einer Datei während der Abfrageausführung geändert wird.
In einigen Szenarien möchten Sie vielleicht die Dateien lesen, die fortlaufend angehängt werden. Um Abfragefehler aufgrund von kontinuierlich erweiterten Dateien zu vermeiden, können Sie der Funktion OPENROWSET erlauben, potenziell inkonsistente Lesevorgänge zu ignorieren, indem Sie die ROWSET_OPTIONS-Einstellung verwenden.
select top 10 *
from openrowset(
bulk 'https://pandemicdatalake.blob.core.windows.net/public/curated/covid-19/ecdc_cases/latest/ecdc_cases.csv',
format = 'csv',
parser_version = '2.0',
firstrow = 2,
ROWSET_OPTIONS = '{"READ_OPTIONS":["ALLOW_INCONSISTENT_READS"]}') as rows
Durch die Leseoption ALLOW_INCONSISTENT_READS wird die Überprüfung der Dateiänderungszeit während des Abfragelebenszyklus deaktiviert, und es werden alle verfügbaren Inhalte der Dateien gelesen. In den anfügebaren Dateien wird der vorhandene Inhalt nicht aktualisiert, und nur neue Zeilen werden hinzugefügt. Dadurch wird die Wahrscheinlichkeit falscher Ergebnisse im Vergleich zu den aktualisierbaren Dateien minimiert. Mit dieser Option können Sie möglicherweise oft angehängte Dateien lesen, ohne Fehler behandeln zu müssen. In den meisten Szenarien ignoriert der SQL-Pool nur einige Zeilen, die während der Abfrageausführung an die Dateien angefügt werden.
Verwandte Inhalte
In den nächsten Artikeln erfahren Sie Folgendes: