HBv2-series virtual machine sizes
Applies to: ✔️ Linux VMs ✔️ Windows VMs ✔️ Flexible scale sets ✔️ Uniform scale sets
Several performance tests have been run on HBv2-series size VMs. The following are some of the results of this performance testing.
| Workload | HBv2 |
|---|---|
| STREAM Triad | 350 GB/s (21-23 GB/s per CCX) |
| High-Performance Linpack (HPL) | 4 TeraFLOPS (Rpeak, FP64), 8 TeraFLOPS (Rmax, FP32) |
| RDMA latency & bandwidth | 1.2 microseconds, 190 Gb/s |
| FIO on local NVMe SSD | 2.7 GB/s reads, 1.1 GB/s writes; 102k IOPS reads, 115 IOPS writes |
| IOR on 8 * Azure Premium SSD (P40 Managed Disks, RAID0)** | 1.3 GB/s reads, 2.5 GB/writes; 101k IOPS reads, 105k IOPS writes |
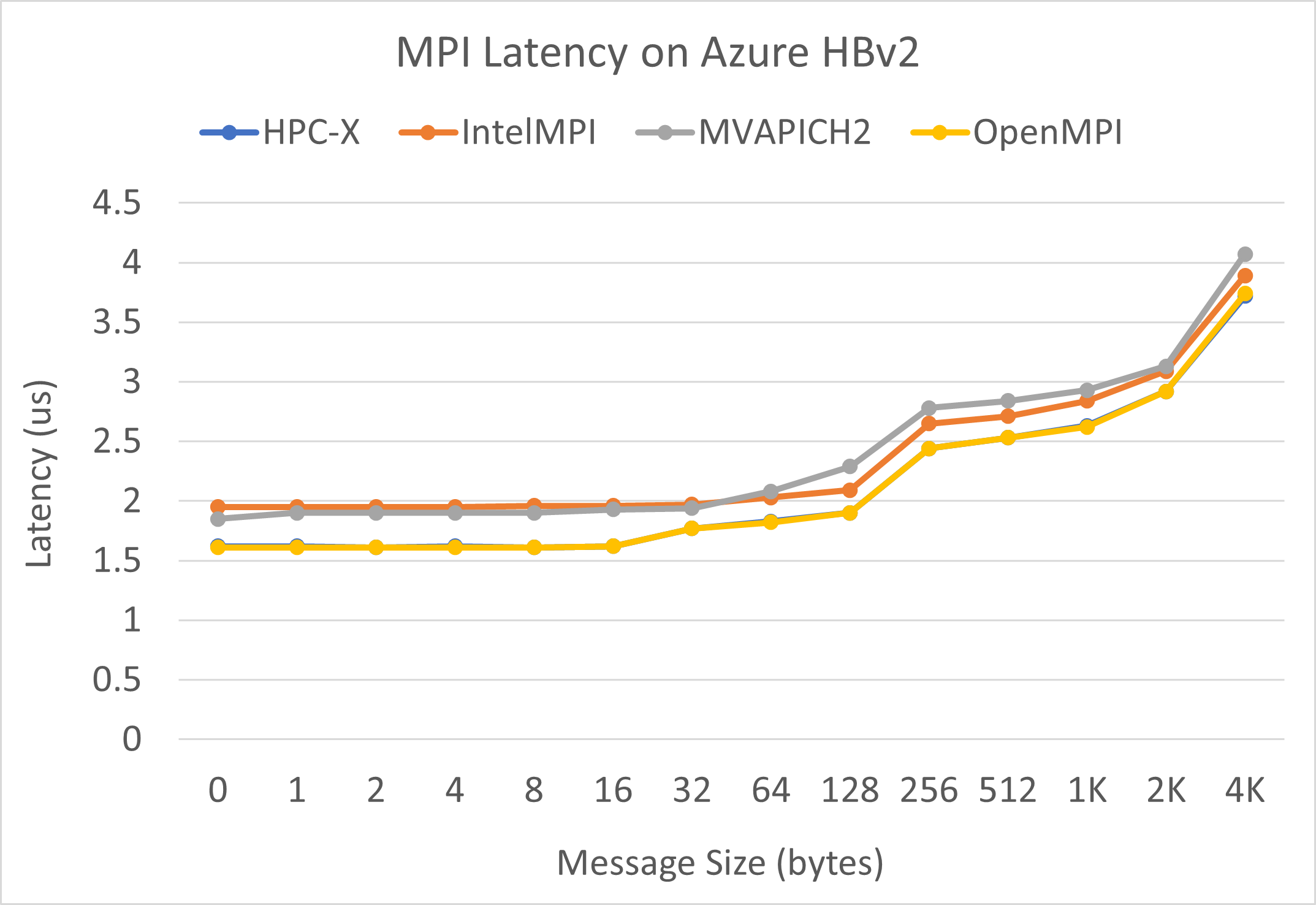
MPI latency
MPI latency test from the OSU microbenchmark suite is run. Sample scripts are on GitHub.
./bin/mpirun_rsh -np 2 -hostfile ~/hostfile MV2_CPU_MAPPING=[INSERT CORE #] ./osu_latency
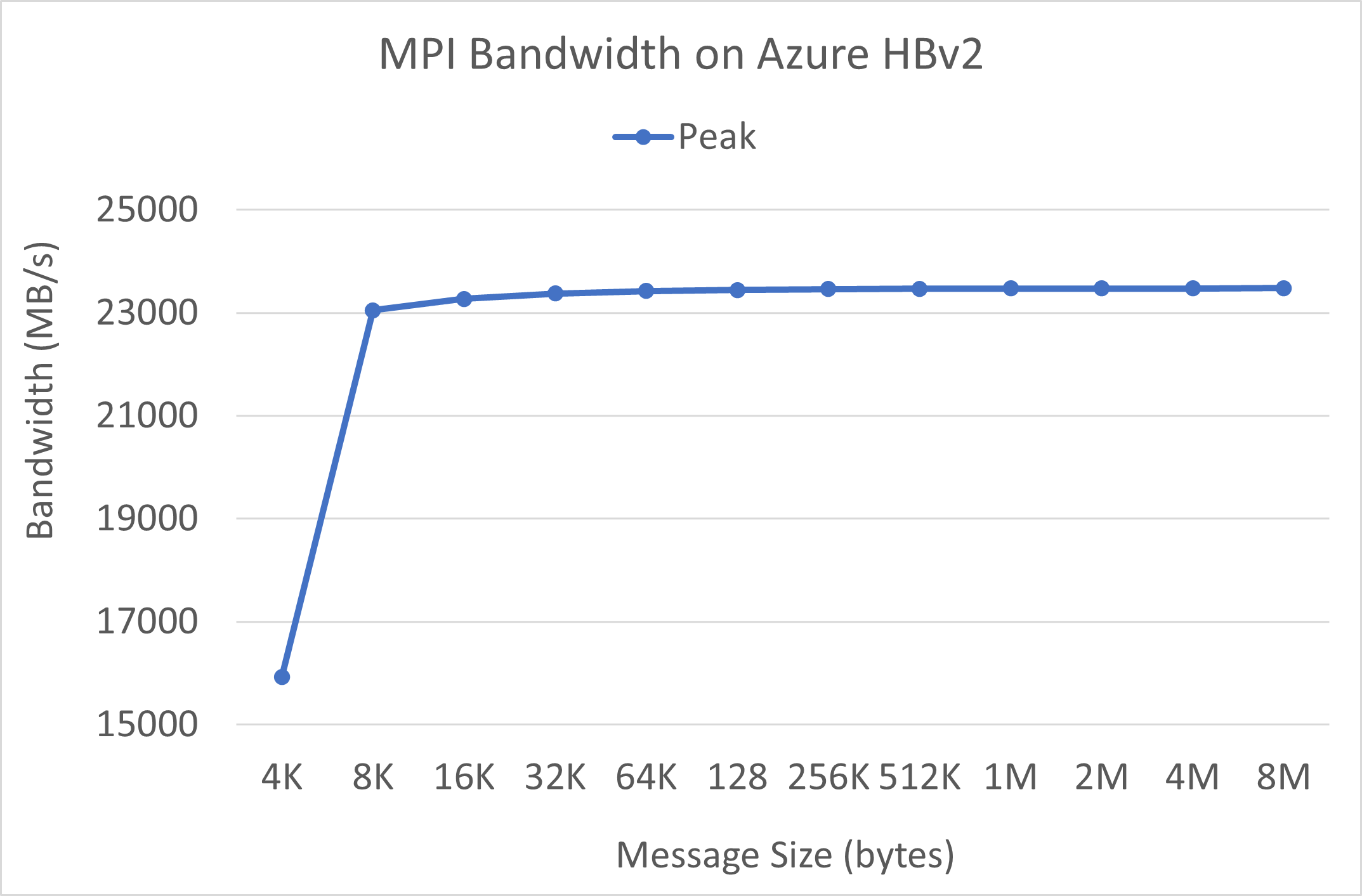
MPI bandwidth
MPI bandwidth test from the OSU microbenchmark suite is run. Sample scripts are on GitHub.
./mvapich2-2.3.install/bin/mpirun_rsh -np 2 -hostfile ~/hostfile MV2_CPU_MAPPING=[INSERT CORE #] ./mvapich2-2.3/osu_benchmarks/mpi/pt2pt/osu_bw
Mellanox Perftest
The Mellanox Perftest package has many InfiniBand tests such as latency (ib_send_lat) and bandwidth (ib_send_bw). An example command is below.
numactl --physcpubind=[INSERT CORE #] ib_send_lat -a
Next steps
- Read about the latest announcements, HPC workload examples, and performance results at the Azure Compute Tech Community Blogs.
- For a higher-level architectural view of running HPC workloads, see High Performance Computing (HPC) on Azure.