VM-Größen der HC-Serie
Gilt für: ✔️ Linux-VMs ✔️ Windows-VMs ✔️ Flexible Skalierungsgruppen ✔️ Einheitliche Skalierungsgruppen
Für die Größen der HC-Serie wurden zahlreiche Leistungstests durchgeführt. Im Anschluss finden Sie einige der Ergebnisse dieser Leistungstests:
| Workload | HB |
|---|---|
| STREAM Triad | 190 GB/s (Intel MLC AVX-512) |
| High-Performance Linpack (HPL) | 3\.520 GigaFLOPs (Rpeak), 2.970 GigaFLOPs (Rmax) |
| RDMA-Wartezeit und -Bandbreite | 1,05 Mikrosekunden, 96,8 GBit/s |
| FIO auf lokaler NVMe-SSD | 1,3 GB/s Lesen, 900 MB/s Schreiben |
| IOR auf vier Azure SSD Premium-Datenträgern (verwaltete Datenträger vom Typ „P30“, RAID0)** | 780 MB/s Lesen, 780 MB/s Schreiben |
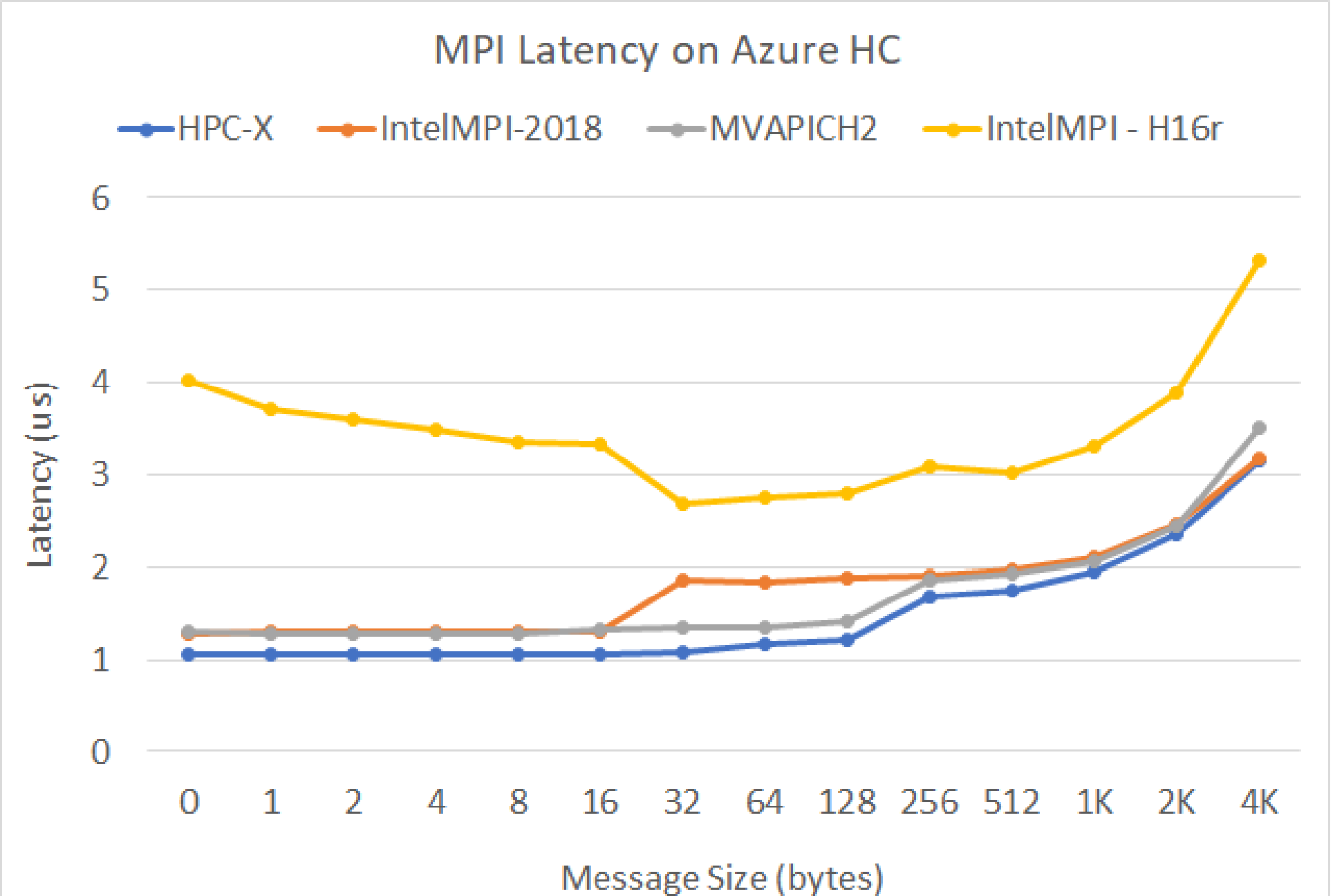
MPI-Latenz
Der MPI-Latenztest von der OSU-Microbenchmark-Suite wird ausgeführt. Beispielskripts finden Sie auf GitHub.
./bin/mpirun_rsh -np 2 -hostfile ~/hostfile MV2_CPU_MAPPING=[INSERT CORE #] ./osu_latency
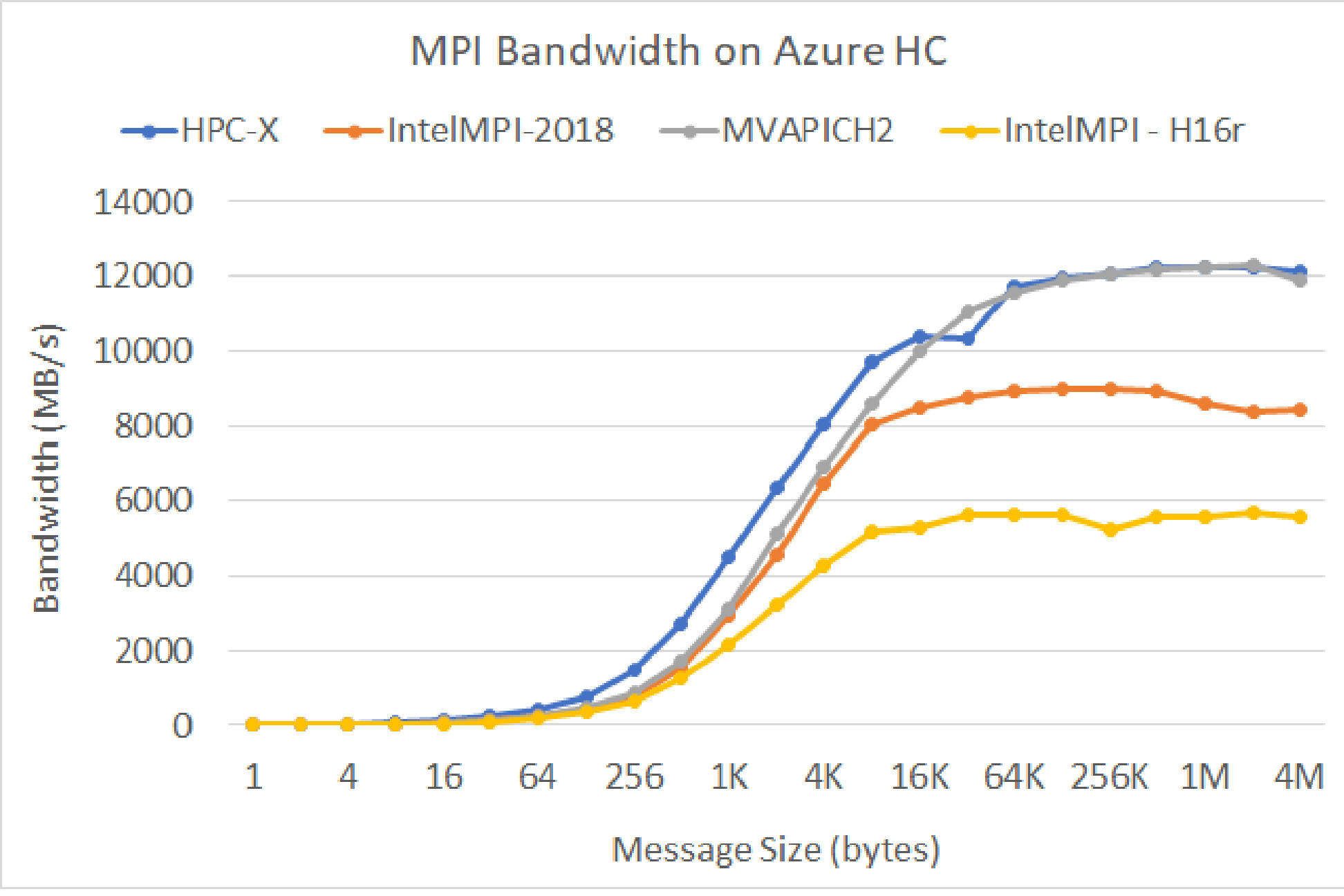
MPI-Bandbreite
Der MPI-Bandbreitentest von der OSU-Microbenchmark-Suite wird ausgeführt. Beispielskripts finden Sie auf GitHub.
./mvapich2-2.3.install/bin/mpirun_rsh -np 2 -hostfile ~/hostfile MV2_CPU_MAPPING=[INSERT CORE #] ./mvapich2-2.3/osu_benchmarks/mpi/pt2pt/osu_bw
Mellanox Perftest
Das Paket Mellanox Perftest enthält viele InfiniBand-Tests, z. B. Latenz (ib_send_lat) und Bandbreite (ib_send_bw). Im Folgenden finden Sie einen Beispielbefehl.
numactl --physcpubind=[INSERT CORE #] ib_send_lat -a
Nächste Schritte
- Informieren Sie sich über die neuesten Ankündigungen, HPC-Workloadbeispiele und Leistungsergebnisse in den Tech Community-Blogs zu Azure Compute.
- Eine allgemeinere Übersicht über die Architektur für die Ausführung von HPC-Workloads finden Sie unter High Performance Computing (HPC) in Azure.