Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
Gilt für: ✔️ Linux-VMs ✔️ Windows-VMs ✔️ Flexible Skalierungsgruppen ✔️ Einheitliche Skalierungsgruppen
Message Passing Interface (MPI) ist eine offene Bibliothek und der De-facto-Standard für die Parallelisierung von verteiltem Arbeitsspeicher. Sie wird für eine Vielzahl von HPC-Workloads verwendet. HPC-Workloads auf RDMA-fähigen VMs der HB-Serie und N-Serie können MPI verwenden, um über das InfiniBand-Netzwerk zu kommunizieren, das sich durch niedrige Latenz und hohe Bandbreite auszeichnet.
- Die SR-IOV-fähigen VM-Größen in Azure gestatten die Verwendung nahezu jeder Variante von MPI mit Mellanox OFED.
- Auf nicht SR-IOV-fähigen virtuellen Computern verwenden unterstützte MPI-Implementierungen die Microsoft Network Direct-Schnittstelle (ND) für die Kommunikation zwischen virtuellen Computern. Daher werden nur die Versionen Microsoft MPI (MS-MPI) 2012 R2 oder höher und Intel MPI 5.x unterstützt. Höhere Versionen (2017, 2018) der Intel MPI-Laufzeitbibliothek sind möglicherweise mit den Azure-RDMA-Treibern kompatibel.
Für SR-IOV-fähige RDMA-fähige VMs sind Ubuntu-HPC-VM-Images und AlmaLinux-HPC VM-Images geeignet. Diese VM-Images sind optimiert und vorab mit den OFED-Treibern für RDMA sowie verschiedenen gängigen MPI-Bibliotheken und Paketen für wissenschaftliches Computing geladen. Damit bieten diese VM-Images einen sehr einfachen Einstieg.
Obwohl die hier genannten Beispiele für RHEL gelten, sind die Schritte allgemein und können für jedes kompatible Linux-Betriebssystem wie Ubuntu (18.04, 20.04, 22.04) und SLES (12 SP4 und 15 SP4) verwendet werden. Weitere Beispiele für das Einrichten weiterer MPI-Implementierungen auf anderen Distributionen finden Sie im azhpc-images-Repository.
Hinweis
Für das Ausführen von MPI-Aufträgen auf SR-IOV-fähigen VMs mit bestimmten MPI-Bibliotheken (z. B. Platform MPI) kann das Einrichten von Partitionsschlüsseln für einen Mandanten für Isolation und Sicherheit erforderlich sein. Eine ausführliche Anleitung zum Ermitteln der Partitionsschlüsselwerte und zum korrekten Festlegen dieser Werte für einen MPI-Auftrag mit dieser MPI-Bibliothek finden Sie unter Ermitteln von Partitionsschlüsseln.
Hinweis
Die folgenden Codeausschnitte sind Beispiele. Es wird empfohlen, die neuesten stabilen Versionen der Pakete zu verwenden oder auf das azhpc-images-Repository zu verweisen.
Auswählen der MPI-Bibliothek
Wenn eine HPC-Anwendung eine bestimmte MPI-Bibliothek empfiehlt, probieren Sie diese Version zuerst aus. Wenn Sie die MPI-Bibliothek frei wählen können und die beste Leistung erzielen möchten, probieren Sie es mit HPC-X. Insgesamt weist die MPI-Bibliothek HPC-X die beste Leistung auf, da sie das UCX-Framework für die InfiniBand-Schnittstelle verwendet und alle InfiniBand-Hardware- und Softwarefunktionen von Mellanox nutzt. Zusätzlich sind HPC-X und OpenMPI mit ABI kompatibel, sodass Sie eine HPC-Anwendung, die mit OpenMPI erstellt wurde, dynamisch mit HPC-X ausführen können. Intel MPI, MVAPICH und MPICH sind ebenfalls ABI-kompatibel.
Die folgende Abbildung veranschaulicht die Architektur für die beliebten MPI-Bibliotheken.
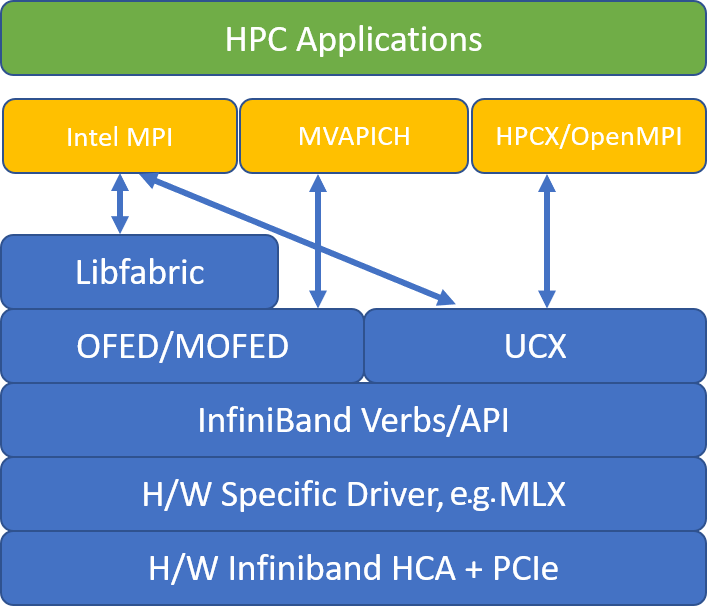
HPC-X
Das HPC-X-Softwaretoolkit enthält UCX und HCOLL und kann für UCX erstellt werden.
HPCX_VERSION="v2.6.0"
HPCX_DOWNLOAD_URL=https://azhpcstor.blob.core.windows.net/azhpc-images-store/hpcx-v2.6.0-gcc-MLNX_OFED_LINUX-5.0-1.0.0.0-redhat7.7-x86_64.tbz
wget --retry-connrefused --tries=3 --waitretry=5 $HPCX_DOWNLOAD_URL
tar -xvf hpcx-${HPCX_VERSION}-gcc-MLNX_OFED_LINUX-5.0-1.0.0.0-redhat7.7-x86_64.tbz
mv hpcx-${HPCX_VERSION}-gcc-MLNX_OFED_LINUX-5.0-1.0.0.0-redhat7.7-x86_64 ${INSTALL_PREFIX}
HPCX_PATH=${INSTALL_PREFIX}/hpcx-${HPCX_VERSION}-gcc-MLNX_OFED_LINUX-5.0-1.0.0.0-redhat7.7-x86_64
Der folgende Befehl enthält einige empfohlene mpirun-Argumente für HPC-X und OpenMPI.
mpirun -n $NPROCS --hostfile $HOSTFILE --map-by ppr:$NUMBER_PROCESSES_PER_NUMA:numa:pe=$NUMBER_THREADS_PER_PROCESS -report-bindings $MPI_EXECUTABLE
Dabei gilt Folgendes:
| Parameter | BESCHREIBUNG |
|---|---|
NPROCS |
Hier wird die Anzahl der MPI-Prozesse angegeben. Beispiel: -n 16 |
$HOSTFILE |
Gibt eine Datei an, die den Hostnamen oder die IP-Adresse enthält, um den Speicherort anzugeben, an dem die MPI-Prozesse ausgeführt werden. Beispiel: --hostfile hosts |
$NUMBER_PROCESSES_PER_NUMA |
Gibt die Anzahl der MPI-Prozesse an, die in jeder NUMA-Domäne ausgeführt werden. Für vier MPI-Prozesse pro NUMA-Domäne verwenden Sie z. B. --map-by ppr:4:numa:pe=1. |
$NUMBER_THREADS_PER_PROCESS |
Hier wird die Anzahl der Threads pro MPI-Prozess angegeben. Für einen MPI-Prozess und vier Threads pro NUMA-Domäne verwenden Sie z. B. --map-by ppr:1:numa:pe=4. |
-report-bindings |
Hiermit wird die Zuordnung der MPI-Prozesse zu den Kernen ausgegeben. Dies ist nützlich, um zu überprüfen, ob Sie die MPI-Prozesse richtig angeheftet haben. |
$MPI_EXECUTABLE |
Hier wird die erstellte ausführbare MPI-Datei angegeben, die die MPI-Bibliotheken einbindet. Bei MPI-Compilerwrappern erfolgt dies automatisch. Zum Beispiel: mpicc oder mpif90. |
Ein Beispiel für die Ausführung der OSU-Latenz-Microbenchmarks ist:
${HPCX_PATH}mpirun -np 2 --map-by ppr:2:node -x UCX_TLS=rc ${HPCX_PATH}/ompi/tests/osu-micro-benchmarks-5.3.2/osu_latency
Optimieren von MPI-Kollektiven
Die MPI-Primitive für kollektive Kommunikation bieten eine flexible, portable Möglichkeit zur Implementierung von Gruppenkommunikationsvorgängen. Deren Verwendung ist in verschiedenen wissenschaftlichen parallelen Anwendungen weit verbreitet und hat einen erheblichen Einfluss auf die Gesamtleistung der Anwendung. Einzelheiten zu den Konfigurationsparametern zur Optimierung der Leistung der kollektiven Kommunikation mit HPC-X und der HCOLL-Bibliothek für kollektive Kommunikation finden Sie im TechCommunity-Artikel.
Wenn Sie beispielsweise vermuten, dass übermäßig viel gemeinsame Kommunikation über Ihre eng gekoppelte MPI-Anwendung erfolgt, können Sie versuchen, Hierarchical Collectives (HCOLL) zu aktivieren. Verwenden Sie die folgenden Parameter, um diese Features zu aktivieren.
-mca coll_hcoll_enable 1 -x HCOLL_MAIN_IB=<MLX device>:<Port>
Hinweis
Bei HPC-X 2.7.4 und höher kann es erforderlich sein, „LD_LIBRARY_PATH“ explizit zu übergeben, wenn sich die UCX-Version unter MOFED von der in HPC-X unterscheidet.
OpenMPI
Installieren Sie UCX, wie oben beschrieben. HCOLL gehört zum HPC-X-Softwaretoolkit und erfordert keine gesonderte Installation.
OpenMPI kann aus den im Repository verfügbaren Paketen installiert werden.
sudo yum install –y openmpi
Es wird empfohlen, ein aktuelles stabiles Release von OpenMPI mit UCX zu erstellen.
OMPI_VERSION="4.0.3"
OMPI_DOWNLOAD_URL=https://download.open-mpi.org/release/open-mpi/v4.0/openmpi-${OMPI_VERSION}.tar.gz
wget --retry-connrefused --tries=3 --waitretry=5 $OMPI_DOWNLOAD_URL
tar -xvf openmpi-${OMPI_VERSION}.tar.gz
cd openmpi-${OMPI_VERSION}
./configure --prefix=${INSTALL_PREFIX}/openmpi-${OMPI_VERSION} --with-ucx=${UCX_PATH} --with-hcoll=${HCOLL_PATH} --enable-mpirun-prefix-by-default --with-platform=contrib/platform/mellanox/optimized && make -j$(nproc) && make install
Führen Sie OpenMPI für eine optimale Leistung mit ucx und hcoll aus. Siehe auch das Beispiel mit HPC-X.
${INSTALL_PREFIX}/bin/mpirun -np 2 --map-by node --hostfile ~/hostfile -mca pml ucx --mca btl ^vader,tcp,openib -x UCX_NET_DEVICES=mlx5_0:1 -x UCX_IB_PKEY=0x0003 ./osu_latency
Überprüfen Sie Ihren Partitionsschlüssel, wie weiter oben erwähnt.
Intel MPI
Laden Sie die gewünschte Version von Intel MPI herunter. Mit dem Intel MPI 2019-Release wurde vom OFA-Framework (Open Fabrics Alliance) auf das OFI-Framework (Open Fabrics Interfaces) umgestellt, und libfabric wird derzeit unterstützt. Es gibt zwei Anbieter für InfiniBand-Unterstützung: mlx und verbs. Ändern Sie die Umgebungsvariable „I_MPI_FABRICS“ abhängig von der Version.
- Intel MPI 2019 und 2021: Verwenden Sie
I_MPI_FABRICS=shm:ofi,I_MPI_OFI_PROVIDER=mlx. Dermlx-Anbieter verwendet UCX. Die Verwendung von Verben wurde als instabil und weniger leistungsfähig eingestuft. Weitere Informationen finden Sie im TechCommunity-Artikel. - Intel MPI 2018: Verwenden Sie
I_MPI_FABRICS=shm:ofa. - Intel MPI 2016: Verwenden Sie
I_MPI_DAPL_PROVIDER=ofa-v2-ib0.
Im Folgenden sind einige Vorschläge für mpirun-Argumente für Intel MPI 2019, Update 5 und höher, aufgeführt.
export FI_PROVIDER=mlx
export I_MPI_DEBUG=5
export I_MPI_PIN_DOMAIN=numa
mpirun -n $NPROCS -f $HOSTFILE $MPI_EXECUTABLE
Dabei gilt Folgendes:
| Parameter | BESCHREIBUNG |
|---|---|
FI_PROVIDER |
Hier wird angegeben, welcher libfabric-Anbieter verwendet werden soll. Dies wirkt sich auf die API, das Protokoll und das Netzwerk aus, die verwendet werden. verbs ist eine weitere Option, doch bietet mlx im Allgemeinen eine bessere Leistung. |
I_MPI_DEBUG |
Hier wird der Umfang der zusätzlichen Debugausgabe angegeben, die Details dazu bereitstellen kann, wo Prozesse angeheftet sind und welches Protokoll und Netzwerk verwendet werden. |
I_MPI_PIN_DOMAIN |
Hier geben Sie an, wie Sie die Prozesse anheften möchten. Sie können sie beispielsweise an Kerne, Sockets oder NUMA-Domänen anheften. In diesem Beispiel wurde diese Umgebungsvariable auf numa festgelegt. Dies bedeutet, dass Prozesse an NUMA-Knotendomänen angeheftet werden. |
Optimieren von MPI-Kollektiven
Es gibt noch einige weitere Optionen, die Sie ausprobieren können, insbesondere dann, wenn gemeinsame Vorgänge viel Zeit beanspruchen. Intel MPI 2019, Update 5 und höher, unterstützt den Anbieter mlx und verwendet das UCX-Framework für die Kommunikation mit InfiniBand. Darüber hinaus wird HCOLL unterstützt.
export FI_PROVIDER=mlx
export I_MPI_COLL_EXTERNAL=1
Nicht-SR-IOV-VMS
Für Nicht-SR-IOV-VMS finden Sie im Folgenden ein Beispiel für das Herunterladen der kostenlosen Evaluierungsversion der 5.x-Runtime:
wget http://registrationcenter-download.intel.com/akdlm/irc_nas/tec/9278/l_mpi_p_5.1.3.223.tgz
Die Installationsschritte finden Sie im Installationshandbuch für die Intel MPI-Bibliothek. Optional können Sie ptrace für Nicht-Debugger-Prozesse ohne Root-Zugriff aktivieren (erforderlich für die neuesten Versionen von Intel MPI).
echo 0 | sudo tee /proc/sys/kernel/yama/ptrace_scope
SUSE Linux
Bei SUSE Linux Enterprise Server-VM-Imageversionen – SLES 12 SP3 für HPC, SLES 12 SP3 für HPC (Premium), SLES 12 SP1 für HPC, SLES 12 SP1 für HPC (Premium), SLES 12 SP4 und SLES 15 – werden die RDMA-Treiber auf der VM installiert, und die Intel MPI-Pakete werden bereitgestellt. Installieren Sie Intel MPI mit dem folgenden Befehl:
sudo rpm -v -i --nodeps /opt/intelMPI/intel_mpi_packages/*.rpm
MVAPICH
Das folgende Beispiel veranschaulicht das Building von MVAPICH2. Beachten Sie, dass neuere Versionen verfügbar sein können, als die unten verwendeten.
wget http://mvapich.cse.ohio-state.edu/download/mvapich/mv2/mvapich2-2.3.tar.gz
tar -xv mvapich2-2.3.tar.gz
cd mvapich2-2.3
./configure --prefix=${INSTALL_PREFIX}
make -j 8 && make install
Ein Beispiel für die Ausführung der OSU-Latenz-Microbenchmarks ist:
${INSTALL_PREFIX}/bin/mpirun_rsh -np 2 -hostfile ~/hostfile MV2_CPU_MAPPING=48 ./osu_latency
In der folgenden Liste sind einige empfohlene mpirun-Argumente aufgeführt.
export MV2_CPU_BINDING_POLICY=scatter
export MV2_CPU_BINDING_LEVEL=numanode
export MV2_SHOW_CPU_BINDING=1
export MV2_SHOW_HCA_BINDING=1
mpirun -n $NPROCS -f $HOSTFILE $MPI_EXECUTABLE
Dabei gilt Folgendes:
| Parameter | BESCHREIBUNG |
|---|---|
MV2_CPU_BINDING_POLICY |
Hier wird angegeben, welche Bindungsrichtlinie verwendet werden soll. Dies wirkt sich darauf aus, wie Prozesse an Kern-IDs angeheftet werden. In diesem Fall geben Sie scatter an, sodass die Prozesse gleichmäßig auf die NUMA-Docks verteilt werden. |
MV2_CPU_BINDING_LEVEL |
Hier wird angegeben, wo Prozesse angeheftet werden sollen. In diesem Fall wurde numanode festgelegt. Dies bedeutet, dass Prozesse an NUMA-Domäneneinheiten angeheftet werden. |
MV2_SHOW_CPU_BINDING |
Hier wird angegeben, ob Debuginformationen dazu abgerufen werden sollen, wo die Prozesse angeheftet sind. |
MV2_SHOW_HCA_BINDING |
Hier wird angegeben, ob Debuginformationen dazu abgerufen werden sollen, welchen Hostkanaladapter die einzelnen Prozesse verwenden. |
Plattform-MPI
Installieren Sie die erforderlichen Pakete für die Community-Edition von Platform MPI.
sudo yum install libstdc++.i686
sudo yum install glibc.i686
Download platform MPI at https://www.ibm.com/developerworks/downloads/im/mpi/index.html
sudo ./platform_mpi-09.01.04.03r-ce.bin
Führen Sie die Schritte des Installationsprozesses aus.
MPICH
Installieren Sie UCX, wie oben beschrieben. Erstellen Sie MPICH.
wget https://www.mpich.org/static/downloads/3.3/mpich-3.3.tar.gz
tar -xvf mpich-3.3.tar.gz
cd mpich-3.3
./configure --with-ucx=${UCX_PATH} --prefix=${INSTALL_PREFIX} --with-device=ch4:ucx
make -j 8 && make install
Führen Sie MPICH aus.
${INSTALL_PREFIX}/bin/mpiexec -n 2 -hostfile ~/hostfile -env UCX_IB_PKEY=0x0003 -bind-to hwthread ./osu_latency
Überprüfen Sie Ihren Partitionsschlüssel, wie weiter oben erwähnt.
OSU-MPI-Benchmarks
Laden Sie die OSU-MPI-Benchmarks herunter, und entpacken Sie sie.
wget http://mvapich.cse.ohio-state.edu/download/mvapich/osu-micro-benchmarks-5.5.tar.gz
tar –xvf osu-micro-benchmarks-5.5.tar.gz
cd osu-micro-benchmarks-5.5
Erstellen Sie Benchmarks unter Verwendung einer bestimmten MPI-Bibliothek:
CC=<mpi-install-path/bin/mpicc>CXX=<mpi-install-path/bin/mpicxx> ./configure
make
MPI-Benchmarks befinden sich im Ordner mpi/.
Ermitteln von Partitionsschlüsseln
Ermitteln Sie Partitionsschlüssel für die Kommunikation mit anderen VMs im selben Mandanten (Verfügbarkeitsgruppe oder VM-Skalierungsgruppe).
/sys/class/infiniband/mlx5_0/ports/1/pkeys/0
/sys/class/infiniband/mlx5_0/ports/1/pkeys/1
Der größere der beiden ist der Mandantenschlüssel, der mit MPI verwendet werden muss. Beispiel: Von den folgenden Partitionsschlüsseln muss „0x800b“ mit MPI verwendet werden:
cat /sys/class/infiniband/mlx5_0/ports/1/pkeys/0
0x800b
cat /sys/class/infiniband/mlx5_0/ports/1/pkeys/1
0x7fff
Beachten Sie, dass die Schnittstellen innerhalb der HPC-VM-Images als mlx5_ib* bezeichnet werden.
Beachten Sie außerdem, dass die Partitionsschlüssel unverändert bleiben, solange der Mandant (Verfügbarkeitsgruppe oder VM-Skalierungsgruppe) vorhanden ist. Dies gilt auch, wenn Knoten hinzugefügt oder gelöscht werden. Neue Mandanten erhalten unterschiedliche Partitionsschlüssel.
Einrichten von Benutzergrenzwerten für MPI
Richten Sie Benutzergrenzwerte für MPI ein.
cat << EOF | sudo tee -a /etc/security/limits.conf
* hard memlock unlimited
* soft memlock unlimited
* hard nofile 65535
* soft nofile 65535
EOF
Einrichten von SSH-Schlüsseln für MPI
Richten Sie SSH-Schlüssel für MPI-Typen ein, bei denen dies erforderlich ist.
ssh-keygen -f /home/$USER/.ssh/id_rsa -t rsa -N ''
cat << EOF > /home/$USER/.ssh/config
Host *
StrictHostKeyChecking no
EOF
cat /home/$USER/.ssh/id_rsa.pub >> /home/$USER/.ssh/authorized_keys
chmod 600 /home/$USER/.ssh/authorized_keys
chmod 644 /home/$USER/.ssh/config
Die obige Syntax setzt ein gemeinsames Home-Verzeichnis voraus, ansonsten muss das .ssh-Verzeichnis auf jeden Knoten kopiert werden.
Nächste Schritte
- Informieren Sie sich über die InfiniBand-fähigen VMs der HB-Serie und N-Serie.
- Weitere Informationen finden Sie in der Übersicht über virtuelle Computer der HBv3-Serie und in der Übersicht über virtuelle Computer der HC-Serie.
- Weitere Informationen finden Sie unter Optimale MPI-Prozessplatzierung für VMs der HB-Serie.
- Informieren Sie sich über die neuesten Ankündigungen, HPC-Workloadbeispiele und Leistungsergebnisse in den Tech Community-Blogs zu Azure Compute.
- Eine allgemeinere Übersicht über die Architektur für die Ausführung von HPC-Workloads finden Sie unter High Performance Computing (HPC) in Azure.