Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
Microsoft-Rechenzentren sind darauf ausgelegt, eine Strategie der tiefgehenden Verteidigung zu implementieren und mehrere Ebenen von Sicherheitsmaßnahmen zu nutzen, um unsere Cloudarchitektur und unterstützende Infrastruktur zuverlässig zu schützen. Redundanz ist in allen Systemen auf mehreren Ebenen integriert, um die Verfügbarkeit des Rechenzentrums zu unterstützen.
Microsoft verfügt über hoch gesicherte Rechenzentrumseinrichtungen, die weltweit verteilt sind und eine verteilte Rechenzentrumsinfrastruktur schaffen, die Tausende von Onlinedienste unterstützt. Diese global verteilte Infrastruktur ist darauf ausgelegt, Anwendungen näher an Benutzer heranzuführen, die Datenresidenz zu erhalten und umfassende Compliance- und Resilienzoptionen für Kunden zu bieten.
Regionen sind Sätze von Rechenzentren, die über ein massives und resilientes Netzwerk miteinander verbunden sind. Regionen sind in geografien organisiert, sodass Kunden mit bestimmten Datenresidenz- und Complianceanforderungen die Möglichkeit haben, ihre Daten und Anwendungen in der Nähe zu halten. Die integrierte Fehlertoleranz ermöglicht es Geografischen Regionen, durch ihre Verbindung mit der dedizierten Netzwerkinfrastruktur mit hoher Kapazität vollständigen Regionsausfällen standzuhalten.
Physisch getrennte Standorte innerhalb einer Region werden als Verfügbarkeitszonen bezeichnet, die jeweils aus einem oder mehreren Rechenzentren bestehen, die mit unabhängiger Stromversorgung, Kühlung und Netzwerk ausgestattet sind. Verfügbarkeitszonen ermöglichen die Ausführung unternehmenskritischer Anwendungen mit Hochverfügbarkeit und Replikation mit geringer Latenz.
Die folgende Abbildung zeigt, wie die globale Infrastruktur Region und Verfügbarkeitszonen innerhalb derselben Datenresidenzgrenze für Hochverfügbarkeit, Notfallwiederherstellung und Sicherung kombiniert.
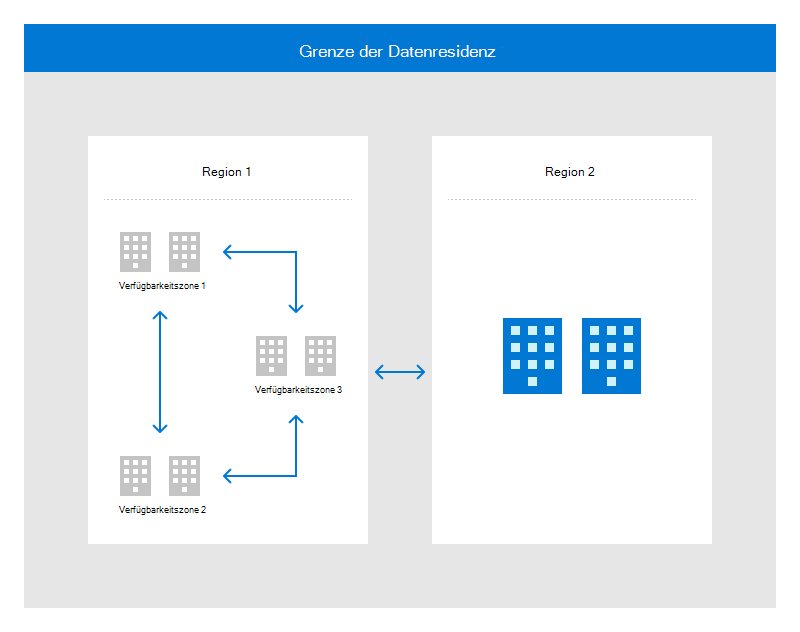
Geografisch verteilte Rechenzentren ermöglichen es Microsoft, Dienste näher an kundennäher zu bringen, die Netzwerklatenz zu reduzieren und georedundante Sicherungen und Failover zu ermöglichen.
Verfügbarkeit
Microsoft-Rechenzentren sind so entwickelt, dass sie eine Verfügbarkeit von 99,999 % bieten, um die SlAs und Serviceanforderungen von Kunden zu erfüllen. Microsoft investiert erheblich in den globalen Betrieb, das Management, die Netzwerke und die Nachhaltigkeit von Einrichtungen, die 24x7x365-Dienste bereitstellen.
Compliancestandards und -anforderungen
Microsoft hat mehr als 15 Milliarden US-Dollar in den Aufbau unserer globalen Infrastruktur und über 9 Milliarden US-Dollar in Forschung und Entwicklung investiert, um die Effizienz zu steigern und Innovationen voranzutreiben. Daher entwickeln sich die Rechenzentren von Microsoft schneller als viele Einrichtungen in der Branche und entsprechen daher nicht den in herkömmlichen Rechenzentrumsstandards festgelegten Anforderungen. Zusätzlich zu den umfangreichen betrieblichen Erkenntnissen, die mit der Ausführung eines der weltweit größten Rechenzentrumsportfolios einfing, verwendet Microsoft IEEE Gold Book-Daten und Software für die Zuverlässigkeitssimulation von Drittanbietern, um unsere Rechenzentrumsentwurfsstandards kontinuierlich zu verbessern. Microsoft-Rechenzentren werden im Rahmen mehrerer behördlicher Audits umfassend überprüft, wie im Complianceportfolio angegeben. Der Reifegrad in Microsoft-Rechenzentren kann über das Complianceportfolio und insbesondere die ISO 22301-Zertifizierung bewertet werden.
Während Microsoft Programme im Einklang mit dem Geist der ANSI/TIA-942-Telekommunikationsinfrastruktur von Rechenzentren Standard betreibt, gelten Teile dieses Standards nicht für Microsoft oder stehen in Konflikt mit anderen gesetzlichen und/oder länder-/regionsspezifischen Anforderungen. Darüber hinaus hat Sich Microsoft für einen leistungsorientierten Ansatz entschieden, um den Kundenanforderungen gerecht zu werden.
Daten- und Netzwerkredundanz
Kritische Rechenzentrumseinrichtungen verwenden mehrere Ebenen redundanter Systeme, um Fehler zu beheben und Dienstunterbrechungen zu minimieren. Lokal redundanter Speicher auf Festplattenebene schützt Daten in einer Region, während georedundanter Speicher die regionsübergreifende Redundanz bereitstellt. Um eine zuverlässige Netzwerkkommunikation sicherzustellen, setzt Microsoft unterschiedliche Fibre-Routes und redundante Hardware ein, um wichtige Komponenten vor Fehlern oder Dienstunterbrechungen zu schützen.
Die Georeplikation wird verwendet, um Redundanz für alternative geografische Standorte bereitzustellen. Die Dauerhaftigkeit der Daten wird durch synchrone Replikation von Daten über mehrere Datenbanken in verschiedenen Rechenzentren hinweg erreicht. Wiederherstellungstests werden für alle Sicherungsdaten durchgeführt, die sich im Besitz der Cloud befinden. Die Notfallwiederherstellung wird durch asynchrone Replikation in einem Rechenzentrum in einer anderen geografischen Region erreicht.
Kapazität
Cloud Operations ist ein dediziertes Kapazitätsteam, das zukünftige Anforderungen prognostiziert, um sicherzustellen, dass die erforderliche Kapazität strukturiert und für kunden- und interne Zwecke verfügbar ist. Systeme werden überwacht, um eine akzeptable Dienstleistung, Verfügbarkeit, Dienstauslastung, Speicherauslastung, Netzwerklatenz und Überwachungsprotokollkapazität sicherzustellen. Darüber hinaus schützt Microsoft Rechenzentren vor den Auswirkungen von Denial-of-Service-Angriffen auf Bandbreite, Transaktionskapazität und Speicherkapazität.
Alle Serviceteams schließen die Kapazitätsplanung als ein wichtiges Feature ihrer Rechenzentrumsmodelle und Datenreplikationspläne ein, um sicherzustellen, dass die erforderliche Kapazität für die Informationsverarbeitung, Telekommunikation und Umgebungsunterstützung vorhanden ist.
Potenz
Die Rechenzentren von Microsoft verfügen über dedizierte unterbrechungsfreie 24x7-Netzteile (UPSs) und Notstromunterstützung, die vor Ort Generatoren umfasst, die Sicherungsenergie bereitstellen. Sowohl für die unterbrechungsfreien Stromversorgungen als auch für die Generatoren werden regelmäßige Wartungen und Tests durchgeführt, und die Teams haben Vertragsvereinbarungen mit lokalen Anbietern im Hinblick auf die Versorgung mit Notstrom. In Rechenzentren gibt es auch ein dediziertes Facility Operations Center zur Überwachung von Stromsystemen, einschließlich kritischer elektrischer Komponenten.
Microsoft-Rechenzentren sind mit Schutzräumen und entsprechenden Bezeichnungen für Kabel ausgestattet. Die Ausrüstung der Energieinfrastruktur wird in Umgebungen platziert, die zum Schutz vor Umweltrisiken entwickelt wurden. Alle tragbaren Onlinedienste müssen gesperrt oder befestigt sein, um Schutz vor Diebstahl oder Bewegungsschäden zu bieten. Stromkabel werden unter den Böden, in Kabelschalen und in Schränken zum Schutz vor beweglichen Teilen und versehentlichen Beschädigungen geführt. Alle elektrischen Räume befinden sich nach Bedarf hinter Karte Lesern oder zusätzlichen Tastenschlössern. Zugangsgänge, Außeneingänge und Gerätehöfe werden alle per Videoüberwachung überwacht. Stromversorgungssysteme nutzen auch Redundanz als Eine Form des Schutzes, mit mehreren Strom-/Versorgungseinspeisungen in die Anlage und Generatoren und USV-Systeme.
Für das Informationssystem wird eine langfristige alternative Stromversorgung implementiert, die in der Lage ist, die Leistung in einer minimal erforderlichen Betriebsfähigkeit aufrechtzuerhalten. Wenn die Stromversorgung ausfällt oder auf ein inakzeptables Spannungsniveau fällt, werden USV-Systeme sofort online geschaltet. Dadurch wird genügend Strom für die Ausführung der Server bereitgestellt, bis die Generatoren die Macht übernehmen können. Notstromgeneratoren liefern Sicherungsenergie für längere Ausfälle, geplante Wartungen und können das Rechenzentrum im Fall einer Naturkatastrophe mit Vor-Ort-Kraftstoffreserven betreiben.
Microsoft-Rechenzentren (sowohl geleaste als auch vollständig verwaltete) implementieren Notbeleuchtung in Form von Overhead-Notbeleuchtung auf dedizierten Schaltungen, die durch USV- und Generatorsysteme gesichert werden. Die automatische Notbeleuchtung wird in Übereinstimmung mit dem Lebenssicherheitskodex der National Fire and Protection Association (NFPA) oder dem anwendbaren lokalen Code/Gesetz implementiert. Wenn die Stromversorgung verloren geht, wechselt die Notbeleuchtung automatisch auf die Stromversorgung der USV- und Generatorsysteme. Die Notbeleuchtungssysteme in den Rechenzentren werden routinemäßig gewartet, um sicherzustellen, dass sie ordnungsgemäß funktionieren.
Wartung
Die Systemwartungsrichtlinien und -verfahren sind in Übereinstimmung mit den online services physical and environmental security Standard von Microsoft eingerichtet. Alle Microsoft-Geräte und -Systeme werden regelmäßig gewartet, um die betriebliche Effizienz zu gewährleisten. Die Wartung von Geräten oder Systemen muss gemäß den Empfehlungen des Herstellers durchgeführt, von autorisiertem Personal durchgeführt und in einem Wartungsticket aufgezeichnet werden.
Es gibt zwei Ressourcenteams, die verschiedene Arten von Systemen verwalten:
Kritische Umgebung (CE) -Team:
- CE ist das Team, das Das Facility Management für elektrische, mechanische und physische Systeme bereitstellt, die die Betriebsinfrastruktur der Anlage bilden. Das CE-Team plant, führt, dokumentiert und überprüft alle Wartungsaktivitäten, die für CE-Komponenten ausgeführt werden. Microsoft-Rechenzentren basieren auf einem computergesteuerten System zum Verwalten von Wartungsplänen und Arbeitsaufträgen.
- Datacenter Management (DCM) ist für alle CE-Wartungen verantwortlich, die entweder vor Ort oder remote durchgeführt werden. Die CE-Wartung wird in erforderlichen Schritt-für-Schritt-Dokumenten vorgeschrieben, die als Methoden der Prozedur (MOP) bezeichnet werden. MOPs werden vor Beginn der Arbeit von der Rechenzentrumsverwaltung überprüft/genehmigt.
Site Services-Team :
- Site Services ist das Team, das die Wartung von Microsoft-Onlinedienstressourcen im Microsoft-Rechenzentrum bereitstellt. Das DC Site Services-Team stellt einen Smart Hands/Break Fix-Dienst für Ressourcen bereit, die zu Eigenschaften gehören, die Dienste aus dem Rechenzentrum bereitstellen. Beispielsweise können Ressourcen, die physische Wartung erfordern, einen Smart Hands-Service vom DC Site Services-Team anfordern. Alle Websitedienste für Microsoft-Ressourcen werden im Workflowtickettool in Arbeitstickets geplant, ausgeführt, dokumentiert und überprüft, und ohne ein genehmigtes Arbeitsticket kann keine Arbeit ausgeführt werden.
- Der Technical Program Manager (TPM) und das DCM-Team sind für alle Site Services-Aufgaben verantwortlich, die im Rechenzentrum ausgeführt werden, und für Die Arbeit, bei der die Ressource außerhalb des Standorts übertragen werden muss. Die Wartung von Site Services erfolgt in Bereichen des Rechenzentrums, die durch physische Sicherheitsmechanismen gesteuert und geschützt werden.
Wenn CE-Komponenten aus der Anlage entfernt werden müssen, wird die Handhabung der Ausrüstung von DCM genehmigt. In den meisten Fällen werden CE-Komponenten vor Ort gewartet und nicht aus der Einrichtung entfernt. Eigenschaftenobjekte (z. B. Netzwerkgeräte oder Server), die eine Übertragung außerhalb des Standorts erfordern, müssen über eine explizite Genehmigung des Ressourcenbesitzers verfügen.
Digitale Medien innerhalb der Cloud dürfen nicht aus dem Colocation-Raum transportiert werden, es sei denn, sie werden zur Zerstörung verschoben. Wenn diese Ressourcen zerstört werden sollen, werden sie in gesperrten Speicherbehältern gespeichert, die sich unter CCTV-Kameraabdeckung befinden. Wenn die Ressourcen zur Zerstörung bereit sind, müssen ein Physischer Sicherheitsbeauftragter und ein Vollzeitmitarbeiter von Microsoft von Asset Management den gesperrten Behälter aus dem Colocation-Raum in den Ort begleiten, an dem die Zerkleinerung vor Ort erfolgen soll. Da das Zerkleinern im Rechenzentrum und unter Microsoft-Aufsicht erfolgt, verlassen Microsoft-Ressourcen nicht die kontrollierten Bereiche des Rechenzentrums.
Alle Wartungsarbeiten müssen vor Beginn der Arbeit genehmigt werden, einschließlich des Zugriffs auf Systemwartungstools. Microsoft Infrastructure hat die Steuerung der Wartungstools implementiert, indem eine Zugriffsebene im Datacenter Access Tool (DCAT) erstellt wurde. Jede Einrichtung enthält einen eingeschränkten physischen Schließkasten oder einen zugangsgesteuerten Raum für die Lagerung von speziellen Wartungswerkzeugen. Der Zugriff auf die Schließfach oder den Lagerraum wird im DCAT-Tool gesteuert, um unbefugten Zugriff auf die Wartungswerkzeuge zu verhindern. Dieses Programm stellt sicher, dass nur Mitarbeiter mit genehmigtem Zugriff auf die Tools zugreifen können. Das Site Services-Team führt routinemäßige Bestandsprüfungen durch, um die status aller Tools zu überprüfen. Vierteljährlich führen das Rechenzentrumsverwaltungsteam und die physischen Sicherheitsteams Überwachungen der DCAT-Zugriffsliste durch, um die Zugriffsliste des Wartungspersonals auf dem neuesten Stand zu halten. Kündigungen oder Versetzungen von Mitarbeitern werden sofort durch eine manuelle Aktualisierung der Zugriffsliste widerspiegelt. Der Zugriff auf das Schlossfach oder den Wartungsspeicherraum wird in den Zugriffs-Badge-Leserprotokollen nachverfolgt, die für alle Untersuchungen verfügbar sind.
Das Site Services-Team verwaltet ein Inventar der genehmigten Wartungstools für die Verwendung innerhalb des Rechenzentrums. Das Wartungspersonal wird angewiesen, die bereitgestellten Wartungswerkzeuge zu verwenden. Datacenter Management (DCM)-Genehmigung ist erforderlich, um Tools verwenden zu können, die nicht vom Rechenzentrum bereitgestellt werden. Physische Handwerkzeuge sind von dieser Art der Steuerung ausgenommen.
In Microsoft-Rechenzentren wird ein mitarbeiterresidentes Wartungspersonal zur Unterstützung kritischer Infrastruktursysteme des Rechenzentrums (das Kritische Umgebungsteam) und Rechenzentrumsvorgänge (das Site Services-Team) verwaltet. Die Teams für kritische Umgebungen und Standortdienste haben wichtige Sicherheits- und Technologiesystemkomponenten identifiziert, für die sie Vor-Ort-Reserven beibehalten. Kritische Informationssystemdienste werden von mehr als einem Rechenzentrum bereitgestellt, um eine Unterbrechung des Diensts aufgrund eines Incidents in einem der Rechenzentren zu verhindern.