Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
In diesem Artikel wird die grundlegende Anwendungsbinärschnittstelle (Application Binary Interface, ABI) für x64, die 64-Bit-Erweiterung für die x86-Architektur, erläutert. Es werden Themen wie die beispielsweise die Aufrufkonvention, das Typlayout sowie die Stapel- und Registernutzung behandelt.
x64-Aufrufkonventionen
Die zwei wichtigen Unterschiede zwischen x86 und x64 sind:
- 64-Bit-Adressierungsfunktion
- Sechzehn 64-Bit-Register für die allgemeine Verwendung.
Aufgrund des erweiterten Registersatzes verwendet x64 die __fastcall Aufrufkonvention und ein RISC-basiertes Ausnahmebehandlungsmodell.
Die __fastcall-Konvention verwendet Register für die ersten vier Argumente und den Stapelrahmen zur Übergabe weiterer Argumente. Weitere Informationen zur x64-Aufrufkonvention, einschließlich Registerverwendung, Stapelparametern, Rückgabewerten und Stapelentladung, finden Sie unter x64 calling convention (x64-Aufrufkonvention).
Weitere Informationen zur __vectorcall-Aufrufkonvention finden Sie unter __vectorcall.
Aktivieren der x64-Compileroptimierung
Die folgende Compileroption hilft Ihnen, Ihre Anwendung für x64 zu optimieren:
x64-Typ- und Speicherlayout
In diesem Abschnitt wird die Speicherung von Datentypen für die x64-Architektur beschrieben.
Skalare Typen
Obwohl es möglich ist, auf Daten unabhängig von ihrer Ausrichtung zuzugreifen, richten Sie Daten an ihrer natürlichen Grenze oder an einem Vielfachen ihrer natürlichen Grenze aus, um Leistungsverluste zu vermeiden. Enumerationen sind konstante Ganzzahlen und werden wie 32-Bit-Ganzzahlen behandelt. Die folgende Tabelle enthält eine Beschreibung der Typdefinition und der empfohlenen Speicherung von Daten hinsichtlich der Ausrichtung mithilfe der folgenden Ausrichtungswerte:
- Byte: 8 Bit
- Word (Wort): 16 Bit
- Doubleword (Doppelwort): 32 Bit
- Quadword (Quadwort): 64 Bit
- Octaword (Oktawort): 128 Bit
| Skalarer Type | C-Datentyp | Speichergröße (in Byte) | Empfohlene Ausrichtung |
|---|---|---|---|
INT8 |
char |
1 | Byte |
UINT8 |
unsigned char |
1 | Byte |
INT16 |
short |
2 | Word |
UINT16 |
unsigned short |
2 | Word |
INT32 |
int, long |
4 | Doubleword |
UINT32 |
unsigned int, unsigned long |
4 | Doubleword |
INT64 |
__int64 |
8 | Quadword |
UINT64 |
unsigned __int64 |
8 | Quadword |
FP32 (einfache Genauigkeit) |
float |
4 | Doubleword |
FP64 (doppelte Genauigkeit) |
double |
8 | Quadword |
POINTER |
* | 8 | Quadword |
__m64 |
struct __m64 |
8 | Quadword |
__m128 |
struct __m128 |
16 | Octaword |
x64-Aggregat und Unionlayout
Andere Typen, wie z. B. Arrays, Strukturen und Unions, haben strengere Ausrichtungsanforderungen, die eine konsistente Speicherung und einen Datenabruf von Aggregaten und Unions gewährleisten. Im Folgenden sind die Definitionen für Array, Struktur und Union aufgeführt:
Array
Enthält eine geordnete Gruppe von angrenzenden Datenobjekten. Jedes Objekt wird als Element bezeichnet. Alle Elemente in einem Array weisen dieselbe Größe und denselben Datentyp auf.
Struktur
Enthält eine geordnete Gruppe von Datenobjekten. Im Gegensatz zu den Elementen eines Arrays können die Member einer Struktur unterschiedliche Datentypen und Größen aufweisen.
Union
Ein Objekt, das eine Gruppe von benannten Membern enthält. Die Member der benannten Gruppe können von einem beliebigen Typ sein. Der für eine Union zugewiesene Speicherplatz entspricht dem Speicherplatz, der für das umfangreichste Member dieser Union erforderlich ist, zuzüglich der für die Ausrichtung erforderlichen Auffüllung.
Die folgende Tabelle zeigt die dringend empfohlene Ausrichtung für die skalaren Member von Unions und Strukturen.
| Skalarer Type | Datentyp in C | Erforderliche Ausrichtung |
|---|---|---|
INT8 |
char |
Byte |
UINT8 |
unsigned char |
Byte |
INT16 |
short |
Word |
UINT16 |
unsigned short |
Word |
INT32 |
int, long |
Doubleword |
UINT32 |
unsigned int, unsigned long |
Doubleword |
INT64 |
__int64 |
Quadword |
UINT64 |
unsigned __int64 |
Quadword |
FP32 (einfache Genauigkeit) |
float |
Doubleword |
FP64 (doppelte Genauigkeit) |
double |
Quadword |
POINTER |
* | Quadword |
__m64 |
struct __m64 |
Quadword |
__m128 |
struct __m128 |
Octaword |
Es gelten die folgenden aggregierten Ausrichtungsregeln:
Die Ausrichtung eines Arrays entspricht der Ausrichtung eines der Elemente des Arrays.
Die Ausrichtung am Anfang einer Struktur oder einer Union ist die maximale Ausrichtung eines einzelnen Mitglieds. Jedes Member innerhalb der Struktur oder Union muss in der richtigen Ausrichtung, wie in der vorherigen Tabelle definiert, platziert werden. Abhängig vom vorherigen Member kann dies eine implizite interne Auffüllung erfordern.
Die Größe der Struktur muss ein ganzzahliges Vielfaches ihrer Ausrichtung sein, was eine Auffüllung nach dem letzten Member erforderlich machen kann. Da Strukturen und Unions in Arrays gruppiert werden können, muss jedes Arrayelement einer Struktur oder Union an der zuvor festgelegten richtigen Ausrichtung beginnen und enden.
Es ist möglich, Daten so auszurichten, dass sie die Ausrichtungsanforderungen übersteigen, solange die vorherigen Regeln beibehalten werden.
Ein einzelner Compiler kann die Zusammenstellung einer Struktur aufgrund der Größe anpassen. Zum Beispiel erlaubt /Zp (Strukturmemberausrichtung), das Packen von Strukturen anzupassen.
Beispiele zur Ausrichtung der x64-Architektur
Die folgenden vier Beispiele deklarieren jeweils eine ausgerichtete Struktur oder Union, und die entsprechenden Abbildungen veranschaulichen das Layout dieser Struktur bzw. Union im Speicher. Jede Spalte in einer Abbildung stellt ein Byte des Speichers dar, und die Zahl in der Spalte zeigt die Verschiebung dieses Byte an. Der Name in der zweiten Zeile jeder Abbildung entspricht dem Namen einer Variablen in der Deklaration. Die schattierten Spalten zeigen die Polsterung, die erforderlich ist, um die angegebene Ausrichtung zu erreichen.
Beispiel 1
// Total size = 2 bytes, alignment = 2 bytes (word).
_declspec(align(2)) struct {
short a; // +0; size = 2 bytes
}

Beispiel 2
// Total size = 24 bytes, alignment = 8 bytes (quadword).
_declspec(align(8)) struct {
int a; // +0; size = 4 bytes
double b; // +8; size = 8 bytes
short c; // +16; size = 2 bytes
}

Das Diagramm zeigt 24 Bytes Arbeitsspeicher. Member a, ein Int, belegt Bytes 0 bis 3. Das Diagramm zeigt den Abstand für Bytes 4 bis 7. Member b, ein Double, belegt Bytes 8 bis 15. Mitglied c, ein Short, belegt die Bytes 16 bis 17. Bytes 18 bis 23 sind nicht verwendet.
Beispiel 3
// Total size = 12 bytes, alignment = 4 bytes (doubleword).
_declspec(align(4)) struct {
char a; // +0; size = 1 byte
short b; // +2; size = 2 bytes
char c; // +4; size = 1 byte
int d; // +8; size = 4 bytes
}
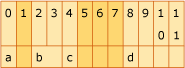
Das Diagramm zeigt 12 Bytes Arbeitsspeicher. Das Member a, ein char, belegt Byte 0. Byte 1 ist ein Füllbyte. Das Member b, ein short, belegt Byte 2 bis 4. Element c, ein Charakter, belegt Byte 4. Byte 5 bis 7 sind Füllbytes. Member d, ein Int, belegt Bytes 8 bis 11.
Beispiel 4
// Total size = 8 bytes, alignment = 8 bytes (quadword).
_declspec(align(8)) union {
char *p; // +0; size = 8 bytes
short s; // +0; size = 2 bytes
long l; // +0; size = 4 bytes
}

Das Diagramm zeigt 8 Bytes Arbeitsspeicher. Mitglied p, ein Zeichen, belegt Byte 0. Das Member s, ein short, belegt Byte 0 bis 1. Das Member l, ein long, belegt Bytes 0 bis 3. Byte 4 bis 7 sind Füllbytes.
Bitfelder
Strukturbitfelder sind auf 64 Bit begrenzt und können vom Typ „signed int“, „unsigned int“, „int64“ oder „unsigned int64“ sein. Bei Bitfeldern, die die Typgrenze überschreiten, werden Bits übersprungen, um das Bitfeld an der nächsten Typausrichtung auszurichten. Ganzzahlige Bitfelder können z. B. keinen 32-Bit-Grenzwert überschreiten.
Konflikt mit dem x86-Compiler
Datentypen mit mehr als 4 Bytes werden nicht automatisch auf dem Stapel ausgerichtet, wenn Sie den x86-Compiler zum Kompilieren einer Anwendung verwenden. Da die Architektur für den x86-Compiler ein an 4 Bytes ausgerichteter Stapel ist, wird nicht alles, was größer als 4 Bytes ist, z. B. eine 64-Bit-Ganzzahl, automatisch an einer 8-Byte-Adresse ausgerichtet.
Das Arbeiten mit nicht ausgerichteten Daten hat zwei Auswirkungen.
Der Zugriff auf nicht ausgerichtete Positionen kann länger dauern als der Zugriff auf ausgerichtete Positionen.
Nicht ausgerichtete Positionen können nicht in Interlocked-Vorgängen verwendet werden.
Wenn Sie eine strengere Ausrichtung benötigen, verwenden Sie __declspec(align(N)) für die variablen Deklarationen. Dies bewirkt, dass der Compiler den Stapel dynamisch entsprechend Ihren Spezifikationen ausrichtet. Das dynamische Ausrichten des Stapels zur Laufzeit kann jedoch zu einer langsameren Ausführung der Anwendung führen.
x64-Registerverwendung
Die x64-Architektur ermöglicht den Einsatz von 16 allgemeinen Registern (im Folgenden als Ganzzahlregister bezeichnet) sowie von 16 XMM/YMM-Registern für die Gleitkommanutzung. Volatile Register sind Scratch-Register, von denen der Aufrufer voraussetzt, dass sie während eines Aufrufs zerstört werden. Nicht volatile Register müssen ihre Werte über einen Funktionsaufruf hinweg bewahren und, sofern sie verwendet werden, vom Aufgerufenen gespeichert werden.
Volatilität und Erhaltung des Registers
Die folgende Tabelle beschreibt, wie jedes Register bei Funktionsaufrufen verwendet wird:
| Registrieren | Der Status | Verwendung |
|---|---|---|
| RAX | Flüchtig | Rückgabewert-Register |
| RCX | Flüchtig | Erstes Ganzzahl-Argument |
| RDX | Flüchtig | Zweites Ganzzahl-Argument |
| R8 | Flüchtig | Drittes Ganzzahl-Argument |
| R9 | Flüchtig | Viertes Ganzzahl-Argument |
| R10:R11 | Flüchtig | Muss je nach Anforderung des Aufrufers bewahrt werden. Wird in syscall-/sysret-Instruktionen verwendet. |
| R12:R15 | Nicht volatil | Muss vom Aufgerufenen bewahrt werden |
| RDI | Nicht volatil | Muss vom Aufgerufenen bewahrt werden |
| RSI | Nicht volatil | Muss vom Aufgerufenen bewahrt werden |
| RBX | Nicht volatil | Muss vom Aufgerufenen bewahrt werden |
| RBP | Nicht volatil | Kann als Frame-Pointer verwendet werden; muss vom Aufgerufenen bewahrt werden |
| RSP | Nicht volatil | Stack-Pointer |
| XMM0, YMM0 | Flüchtig | Erstes FP-Argument; erstes Argument vom Typ Vektor, wenn __vectorcall verwendet wird |
| XMM1, YMM1 | Flüchtig | Zweites FP-Argument; zweites Argument vom Typ Vektor, wenn __vectorcall verwendet wird |
| XMM2, YMM2 | Flüchtig | Drittes FP-Argument; drittes Argument vom Typ Vektor, wenn __vectorcall verwendet wird |
| XMM3, YMM3 | Flüchtig | Viertes FP-Argument; viertes Argument vom Typ Vektor, wenn __vectorcall verwendet wird |
| XMM4, YMM4 | Flüchtig | Muss je nach Bedarf vom Aufrufer beibehalten werden; fünftes Argument vom Typ Vektor, wenn __vectorcall verwendet wird |
| XMM5, YMM5 | Flüchtig | Muss je nach Bedarf vom Aufrufer beibehalten werden; sechstes Argument vom Typ Vektor, wenn __vectorcall verwendet wird |
| XMM6:XMM15, YMM6:YMM15 | Nicht volatil (XMM), Volatil (obere Hälfte von YMM) | Muss vom Aufgerufenen bewahrt werden. YMM-Register müssen je nach Bedarf vom Aufrufer bewahrt werden. |
Bei Funktionsende und beim Funktionseinstieg in C-Laufzeitbibliotheksaufrufen und Windows-Systemaufrufen wird erwartet, dass das Richtungsflag im CPU-Flagsregister gelöscht wird.
Stapelverwendung
Ausführliche Informationen zur Stapelzuweisung, Ausrichtung, Funktionstypen und Stapelframes auf x64 finden Sie unter x64-Stapelverwendung.
Prolog und Epilog
Jede Funktion, die Stapelspeicherplatz zuweist, andere Funktionen aufruft, nichtflüchtige Register speichert oder die Ausnahmebehandlung verwendet, muss über einen Prolog verfügen, dessen Adressgrenzen in den Entladedaten beschrieben sind, die mit dem jeweiligen Funktionstabelleneintrag verbunden sind, sowie über Epiloge bei jedem Beenden einer Funktion. Ausführliche Informationen zum erforderlichen Prolog- und Epilogcode für x64 finden Sie unter x64 prolog and epilog (Prolog- und Epilogcode bei x64-Systemen).
Ausnahmebehandlung bei x64-Systemen
Informationen zu den Konventionen und Datenstrukturen, die verwendet werden, um die strukturierte C++-Ausnahmebehandlung und das Verhalten der Ausnahmebehandlung bei x64-Systemen zu implementieren, finden Sie unter x64 exception handling (Ausnahmebehandlung bei x64-Systemen).
Intrinsische Funktionen und Inlineassemblys
Eine der Einschränkungen für den x64-Compiler besteht darin, dass keine Unterstützung für den Inlineassembler vorhanden ist. Dies bedeutet, dass Funktionen, die nicht in C oder C++ geschrieben werden können, entweder als Unterroutinen oder als intrinsische Funktionen geschrieben werden müssen, die vom Compiler unterstützt werden. Bestimmte Funktionen sind leistungsabhängig, andere hingegen nicht. Leistungsabhängige Funktionen sollten als intrinsische Funktionen implementiert werden.
Die intrinsischen Funktionen, die vom Compiler unterstützt werden, werden in intrinsischen Compilerfunktionen beschrieben.
x64-Bildformat
Das ausführbare x64-Imageformat ist das Format PE32+. Ausführbare Images (sowohl DLLs als auch EXE-Dateien) sind auf eine maximale Größe von 2 Gigabyte beschränkt, sodass eine relative Adressierung mit einer 32-Bit-Verschiebung verwendet werden kann, um statische Imagedaten zu adressieren. Diese Daten umfassen die Importadresstabelle, Zeichenfolgenkonstanten, statische globale Daten usw.