Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
Die Datenaufnahme ist der Prozess des Sammelns, Lesens und Vorbereitens von Daten aus verschiedenen Quellen wie Dateien, Datenbanken, APIs oder Clouddiensten, damit sie in downstream-Anwendungen verwendet werden kann. In der Praxis folgt dieser Prozess dem Extract-Transform-Load(ETL)-Workflow:
- Extrahieren Sie Daten aus der ursprünglichen Quelle, unabhängig davon, ob es sich um eine PDF-, Word-Dokument-, Audiodatei- oder Web-API handelt.
- Transformieren Sie die Daten durch Bereinigen, Aufteilen, Anreichern mit zusätzlichen Informationen oder Konvertieren von Formaten.
- Laden Sie die Daten in ein Ziel, z. B. eine Datenbank, einen Vektorspeicher oder ein KI-Modell zum Abrufen und Analysieren.
Bei KI- und Machine Learning-Szenarien, insbesondere Retrieval-Augmented Generation (RAG), geht es bei der Datenaufnahme nicht nur darum, Daten aus einem Format in ein anderes zu konvertieren. Es geht darum, Daten für intelligente Anwendungen nutzbar zu machen. Dies bedeutet, Dass Dokumente auf eine Weise dargestellt werden, die ihre Struktur und Bedeutung bewahrt, sie in verwaltbare Blöcke aufteilen, mit Metadaten oder Einbettungen bereichern und speichern, damit sie schnell und präzise abgerufen werden können.
Warum die Datenaufnahme für KI-Anwendungen wichtig ist
Stellen Sie sich vor, Sie erstellen einen RAG-basierten Chatbot, um Mitarbeitern dabei zu helfen, Informationen in der großen Sammlung von Dokumenten Ihres Unternehmens zu finden. Diese Dokumente können PDF-Dateien, Word-Dateien, PowerPoint-Präsentationen und Webseiten enthalten, die über verschiedene Systeme verteilt sind.
Ihr Chatbot muss Tausende von Dokumenten verstehen und durchsuchen, um genaue, kontextbezogene Antworten bereitzustellen. Rohdokumente eignen sich jedoch nicht für KI-Systeme. Sie müssen sie in ein Format umwandeln, in dem Sie die Bedeutung bewahren und dabei durchsuchbar und abrufbar machen.
An dieser Stelle wird die Erfassung von Daten kritisch. Sie müssen Text aus verschiedenen Dateiformaten extrahieren, große Dokumente in kleinere Abschnitte unterteilen, die in AI-Modellgrenzen passen, den Inhalt mit Metadaten bereichern, Einbettungen für die semantische Suche generieren und alles so speichern, dass schnelles Abrufen ermöglicht wird. Jeder Schritt erfordert sorgfältige Überlegungen zur Erhaltung der ursprünglichen Bedeutung und des Ursprünglichen Kontexts.
Die Microsoft.Extensions.DataIngestion-Bibliothek
Das 📦 Microsoft.Extensions.DataIngestion-Paket stellt grundlegende .NET-Bausteine für die Datenaufnahme bereit. Es ermöglicht Entwicklern das Lesen, Verarbeiten und Vorbereiten von Dokumenten für KI- und Machine Learning-Workflows, insbesondere Retrieval-Augmented Generation (RAG)-Szenarien.
Mit diesen Bausteinen können Sie robuste, flexible und intelligente Datenaufnahmepipelines erstellen, die auf Ihre Anwendungsanforderungen zugeschnitten sind:
- Einheitliche Dokumentdarstellung: Stellen Sie einen beliebigen Dateityp (z. B. PDF, Bild oder Microsoft Word) in einem konsistenten Format dar, das gut mit großen Sprachmodellen funktioniert.
- Flexible Datenintegration: Lesen Sie Dokumente sowohl aus Clouddiensten als auch aus lokalen Quellen mit mehreren integrierten Lesern, sodass Sie Daten problemlos von überall beziehen können.
- Integrierte KI-Verbesserungen: Inhalte automatisch mit Zusammenfassungen, Stimmungsanalyse, Stichwortextraktion und Klassifizierung anreichern, Ihre Daten für intelligente Workflows vorbereiten.
- Anpassbare Chunking-Strategien: Teilen Sie Dokumente mithilfe von tokenbasierten, abschnittsbasierten oder semantisch-basierten Ansätzen in Chunks auf, sodass Sie Ihre Abruf- und Analyseanforderungen optimieren können.
- Produktionsfertiger Speicher: Speichern Sie verarbeitete Blöcke in beliebten Vektordatenbanken und Dokumentspeichern, mit Unterstützung für die Generierung von Einbettungen, wodurch Ihre Pipelines für reale Szenarien bereit sind.
- End-to-End-Pipelinekomposition: Verkettung von Lesern, Prozessoren, Chunkern und Writern mit der IngestionPipeline<T> API, was Gerüstcode reduziert und es einfach macht, vollständige Workflows zu erstellen, anzupassen und zu erweitern.
- Leistung und Skalierbarkeit: Diese Komponenten sind für die skalierbare Datenverarbeitung konzipiert und können große Datenmengen effizient verarbeiten, sodass sie für Anwendungen auf Unternehmensniveau geeignet sind.
Alle diese Komponenten sind offen und erweiterbar. Sie können benutzerdefinierte Logik und neue Connectors hinzufügen und das System erweitern, um neue KI-Szenarien zu unterstützen. Durch die Standardisierung, wie Dokumente dargestellt, verarbeitet und gespeichert werden, können .NET-Entwickler zuverlässige, skalierbare und wartungsfähige Datenpipelinen erstellen, ohne das Rad für jedes Projekt neu zu erfinden.
Gebaut auf stabilen Fundamenten
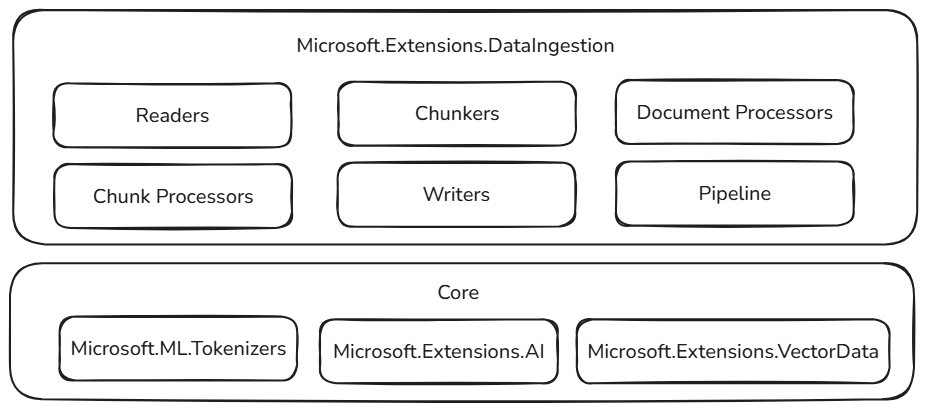
Diese Datenaufnahmebausteine basieren auf bewährten und erweiterbaren Komponenten im .NET-Ökosystem, sorgen für Zuverlässigkeit, Interoperabilität und nahtlose Integration mit vorhandenen KI-Workflows:
- Microsoft.ML.Tokenizers: Tokenizer stellen die Grundlage für die Segmentierung von Dokumenten basierend auf Tokens bereit. Dies ermöglicht eine präzise Aufteilung von Inhalten, die für die Vorbereitung von Daten für große Sprachmodelle und die Optimierung von Abrufstrategien unerlässlich sind.
- Microsoft.Extensions.AI: Dieser Satz von Bibliotheken treibt Anreicherungstransformationen mithilfe großer Sprachmodelle in Kraft. Es ermöglicht Features wie Zusammenfassung, Stimmungsanalyse, Stichwortextraktion und Einbettungsgenerierung, wodurch Ihre Daten mit intelligenten Erkenntnissen leicht verbessert werden können.
- Microsoft.Extensions.VectorData: Dieser Satz von Bibliotheken bietet eine konsistente Schnittstelle zum Speichern verarbeiteter Blöcke in einer Vielzahl von Vektorspeichern, einschließlich Qdrant, Azure SQL, CosmosDB, MongoDB, ElasticSearch und vielem mehr. Dadurch wird sichergestellt, dass Ihre Datenpipelines für die Produktion bereit sind und über verschiedene Speicher-Back-Ends skaliert werden können.
Zusätzlich zu vertrauten Mustern und Tools bauen diese Abstraktionen auf bereits erweiterbaren Komponenten auf. Plug-In-Fähigkeiten und Interoperabilität sind von größter Bedeutung. Während das restliche .NET KI-Ökosystem wächst, nehmen auch die Fähigkeiten der Datenaufnahmekomponenten zu. Mit diesem Ansatz können Entwickler neue Connectors, Anreicherungen und Speicheroptionen problemlos integrieren, ihre Pipelines zukunftsfähig halten und an sich entwickelnde KI-Szenarien anpassen.
Datenaufnahmebausteine
Die Microsoft.Extensions.DataIngestion-Bibliothek basiert auf mehreren wichtigen Komponenten, die zusammenarbeiten, um eine vollständige Datenverarbeitungspipeline zu erstellen. In diesem Abschnitt werden die einzelnen Komponenten und deren Zusammenpassen erläutert.
Dokumente und Dokumentleser
Bei der Grundlage der Bibliothek handelt es sich um den IngestionDocument Typ, der eine einheitliche Möglichkeit zum Darstellen eines Dateiformats bietet, ohne wichtige Informationen zu verlieren.
IngestionDocument ist Markdown-zentrisch, da große Sprachmodelle am besten mit Markdown-Formatierung funktionieren.
Die IngestionDocumentReader Abstraktion behandelt das Laden von Dokumenten aus verschiedenen Quellen, unabhängig davon, ob lokale Dateien oder Datenströme. Einige Leser sind verfügbar:
Weitere Leser (einschließlich LlamaParse und Azure Document Intelligence) werden in Zukunft hinzugefügt.
Dieses Design bedeutet, dass Sie mit Dokumenten aus verschiedenen Quellen mit derselben konsistenten API arbeiten können, wodurch Ihr Code besser verwaltet und flexibler wird.
Dokumentenverarbeitung
Dokumentverarbeiter wenden Transformationen auf Dokumentebene an, um Inhalte zu verbessern und vorzubereiten. Die Bibliothek stellt die ImageAlternativeTextEnricher Klasse als integrierten Prozessor bereit, der große Sprachmodelle verwendet, um beschreibenden Alternativtext für Bilder in Dokumenten zu generieren.
Blöcke und Blockierungsstrategien
Nachdem Sie ein Dokument geladen haben, müssen Sie es in der Regel in kleinere Teile unterteilen, die als Blöcke bezeichnet werden. Blöcke stellen Unterabschnitte eines Dokuments dar, die von KI-Systemen effizient verarbeitet, gespeichert und abgerufen werden können. Dieser Chunking-Prozess ist für Szenarien der rückrufverstärkten Generierung unerlässlich, in denen Sie die relevantesten Informationen schnell finden müssen.
Die Bibliothek bietet mehrere Chunking-Strategien für verschiedene Einsatzmöglichkeiten:
- Kopfzeilenbasiertes Chunking zum Aufteilen anhand von Kopfzeilen.
- Abschnittsbasiertes Aufteilen zum Aufteilen in Abschnitte (z. B. Seiten).
- Semantisches Chunking, um vollständige Gedanken zu bewahren.
Diese Chunking-Strategien bauen auf der Microsoft.ML.Tokenizers-Bibliothek auf, um Text intelligent in passend dimensionierte Teile aufzuteilen, die gut mit größeren Sprachmodellen funktionieren. Die richtige Chunking-Strategie hängt von den Dokumenttypen und davon ab, wie Sie Informationen abrufen möchten.
Tokenizer tokenizer = TiktokenTokenizer.CreateForModel("gpt-4");
IngestionChunkerOptions options = new(tokenizer)
{
MaxTokensPerChunk = 2000,
OverlapTokens = 0
};
IngestionChunker<string> chunker = new HeaderChunker(options);
Blockverarbeitung und -anreicherung
Nachdem Dokumente in Blöcke aufgeteilt wurden, können Sie Prozessoren anwenden, um den Inhalt zu verbessern und zu bereichern. Blockverarbeiter arbeiten an einzelnen Stücken und können folgendes ausführen:
-
Inhaltsanreicherung einschließlich automatischer Zusammenfassungen (
SummaryEnricher), Stimmungsanalyse (SentimentEnricher) und Stichwortextraktion (KeywordEnricher). -
Klassifizierung für automatisierte Inhaltskategorisierung basierend auf vordefinierten Kategorien (
ClassificationEnricher).
Diese Prozessoren verwenden Microsoft.Extensions.AI.Abstractions , um große Sprachmodelle für die intelligente Inhaltstransformation zu nutzen, wodurch Ihre Blöcke für nachgeschaltete KI-Anwendungen nützlicher sind.
Dokumentschreiber und Speicher
IngestionChunkWriter<T> speichert verarbeitete Datenblöcke in einem Datenspeicher zum späteren Abruf. Mithilfe von Microsoft.Extensions.AI und Microsoft.Extensions.VectorData.Abstractions stellt die Bibliothek die Klasse bereit, die VectorStoreWriter<T> das Speichern von Blöcken in jedem von Microsoft.Extensions.VectorData unterstützten Vektorspeicher unterstützt.
Vektorspeicher enthalten beliebte Optionen wie Qdrant, SQL Server, CosmosDB, MongoDB, ElasticSearch und viele mehr. Der Writer kann auch automatisch Einbettungen für Ihre Blöcke mithilfe von Microsoft.Extensions.AI generieren und sie für semantische Such- und Abrufszenarien vorbereiten.
OpenAIClient openAIClient = new(
new ApiKeyCredential(Environment.GetEnvironmentVariable("GITHUB_TOKEN")!),
new OpenAIClientOptions { Endpoint = new Uri("https://models.github.ai/inference") });
IEmbeddingGenerator<string, Embedding<float>> embeddingGenerator =
openAIClient.GetEmbeddingClient("text-embedding-3-small").AsIEmbeddingGenerator();
using SqliteVectorStore vectorStore = new(
"Data Source=vectors.db;Pooling=false",
new()
{
EmbeddingGenerator = embeddingGenerator
});
// The writer requires the embedding dimension count to be specified.
// For OpenAI's `text-embedding-3-small`, the dimension count is 1536.
using VectorStoreWriter<string> writer = new(vectorStore, dimensionCount: 1536);
Dokumentverarbeitungspipeline
Mit der IngestionPipeline<T> API können Sie die verschiedenen Datenaufnahmekomponenten in einen vollständigen Workflow verketten. Sie können Folgendes kombinieren:
- Leser zum Laden von Dokumenten aus verschiedenen Quellen.
- Prozessoren zum Transformieren und Anreichern von Dokumentinhalten.
- Chunker, um Dokumente in verwaltbare Teile aufzuteilen.
- Schreibprozesse , um die endgültigen Ergebnisse in Ihrem ausgewählten Datenspeicher zu speichern.
Dieser Pipelineansatz reduziert Codebausteine und erleichtert das Erstellen, Testen und Verwalten komplexer Datenaufnahmeworkflows.
using IngestionPipeline<string> pipeline = new(reader, chunker, writer, loggerFactory: loggerFactory)
{
DocumentProcessors = { imageAlternativeTextEnricher },
ChunkProcessors = { summaryEnricher }
};
await foreach (var result in pipeline.ProcessAsync(new DirectoryInfo("."), searchPattern: "*.md"))
{
Console.WriteLine($"Completed processing '{result.DocumentId}'. Succeeded: '{result.Succeeded}'.");
}
Ein einzelner Fehler bei der Aufnahme von Dokumenten sollte die gesamte Pipeline nicht fehlschlagen. Aus diesem Grund wird IngestionPipeline<T>.ProcessAsync durch die Rückgabe von IAsyncEnumerable<IngestionResult> teilweiser Erfolg implementiert. Der Aufrufer ist für die Behandlung von Fehlern verantwortlich (z. B. durch Wiederholen fehlgeschlagener Dokumente oder Beenden des ersten Fehlers).
Zusammenarbeit auf GitHub
Die Quelle für diesen Inhalt finden Sie auf GitHub, wo Sie auch Issues und Pull Requests erstellen und überprüfen können. Weitere Informationen finden Sie in unserem Leitfaden für Mitwirkende.