Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
In diesem Artikel wird beschrieben, wie LLMs Ihre Datenquellen als Wissen behandeln können, ohne sie trainieren zu müssen.
LLMs verfügen durch Training über umfangreiche Wissensdatenbanken. Für die meisten Szenarien können Sie ein LLM auswählen, das für Ihre Anforderungen konzipiert ist, aber diese LLMs benötigen weiterhin zusätzliches Training, um Ihre spezifischen Daten zu verstehen. Mit Retrieval-Augmented Generation können Sie Ihre Daten für ein LLM verfügbar zu machen, ohne es zuvor trainieren zu müssen.
Funktionsweise von RAG
Um Retrieval-Augmented Generierung durchzuführen, erstellen Sie Einbettungen für Ihre Daten zusammen mit allgemeinen Fragen dazu. Sie können dies dynamisch tun, oder Sie können die Einbettungen mithilfe einer Vektordatenbanklösung erstellen und speichern.
Wenn ein Benutzer eine Frage stellt, verwendet das LLM Ihre Einbettungen, um die Frage des Benutzers mit Ihren Daten zu vergleichen und den relevantesten Kontext zu finden. Dieser Kontext und die Frage des Benutzers gehen dann in einer Eingabeaufforderung an das LLM, und das LLM stellt eine Antwort basierend auf Ihren Daten bereit.
Grundlegender RAG-Prozess
Zum Ausführen von RAG müssen Sie jede Datenquelle verarbeiten, die Sie für Abrufe verwenden möchten. Der Standardprozess verläuft wie folgt:
- Teilen Sie große Daten in verwaltbare Teile auf.
- Konvertieren Sie die Segmente in ein durchsuchbares Format.
- Speichern Sie die konvertierten Daten an einem Speicherort, der einen effizienten Zugriff ermöglicht. Darüber hinaus ist es wichtig, relevante Metadaten für Zitate oder Verweise zu speichern, wenn das LLM Antworten bereitstellt.
- Füttern Sie die LLMs mit Ihren umgewandelten Daten in Eingabeaufforderungen.
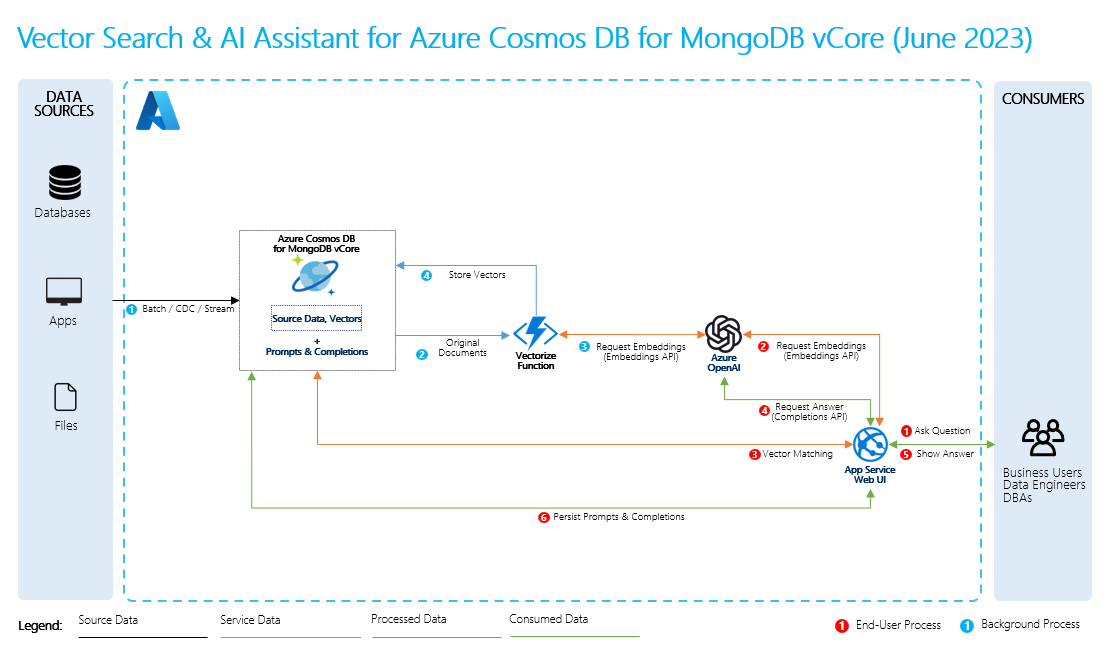
- Quelldaten: Hier befinden sich Ihre Daten. Dies kann eine Datei oder ein Ordner auf Ihrem Computer, eine Datei im Cloudspeicher, eine Azure Machine Learning-Datenressource, ein Git-Repository oder eine SQL-Datenbank sein.
- Datensegmentierung: Die Daten in Ihrer Quelle müssen in Nur-Text konvertiert werden. Beispielsweise müssen Word-Dokumente oder PDF-Dateien geöffnet und in Text konvertiert werden. Der Text wird dann in kleinere Teile unterteilt.
- Konvertieren des Texts in Vektoren: Dies sind Einbettungen. Vektoren sind numerische Darstellungen von Konzepten, die in Zahlensequenzen konvertiert werden, wodurch Computer die Beziehungen zwischen diesen Konzepten leichter verstehen können.
- Verknüpfungen zwischen Quelldaten und Einbettungen: Diese Informationen werden als Metadaten für die von Ihnen erstellten Segmente gespeichert, die dann verwendet werden, um die LLMs beim Generieren von Antworten zu unterstützen.
Siehe auch
Zusammenarbeit auf GitHub
Die Quelle für diesen Inhalt finden Sie auf GitHub, wo Sie auch Issues und Pull Requests erstellen und überprüfen können. Weitere Informationen finden Sie in unserem Leitfaden für Mitwirkende.