Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
Tipp
Dieser Inhalt ist ein Auszug aus dem eBook .NET Microservices Architecture for Containerized .NET Applications, verfügbar auf .NET Docs oder als kostenlose herunterladbare PDF, die offline gelesen werden kann.

Wie bereits erwähnt, sollten Sie Fehler behandeln, die möglicherweise eine variable Zeit in Anspruch nehmen, um sich davon zu erholen. Dies kann passieren, wenn Sie versuchen, eine Verbindung zu einem Remotedienst oder einer Ressource herzustellen. Die Behandlung dieses Fehlertyps kann die Stabilität und Resilienz einer Anwendung verbessern.
In einer verteilten Umgebung können Anrufe an Remoteressourcen und -dienste aufgrund vorübergehender Fehler fehlschlagen, z. B. langsame Netzwerkverbindungen und Timeouts, oder wenn Ressourcen langsam reagieren oder vorübergehend nicht verfügbar sind. Diese Fehler korrigieren sich in der Regel nach kurzer Zeit, und eine robuste Cloudanwendung sollte darauf vorbereitet sein, sie mithilfe einer Strategie wie dem "Wiederholungsmuster" zu behandeln.
Es kann jedoch auch Situationen geben, in denen Fehler auf unerwartete Ereignisse zurückzuführen sind, die viel länger dauern können, um das Problem zu beheben. Zu unterscheiden sind unterschiedliche Schweregrade, die von einem Teilverlust der Konnektivität bis hin zum vollständigen Ausfall des Diensts reichen können. In diesen Situationen kann es sinnlos sein, dass eine Anwendung einen Vorgang, der nicht erfolgreich ist, kontinuierlich wiederholen kann.
Stattdessen sollte die Anwendung codiert werden, um zu akzeptieren, dass der Vorgang fehlgeschlagen ist, und den Fehler entsprechend behandeln.
Die sorglose Verwendung von HTTP-Anfragenwiederholungen kann dazu führen, dass innerhalb Ihrer eigenen Software ein Denial-of-Service (DoS)-Angriff entsteht. Da ein Microservice fehlschlägt oder langsam ausgeführt wird, können mehrere Clients wiederholt fehlgeschlagene Anforderungen wiederholen. Dadurch entsteht ein gefährliches Risiko, dass der Datenverkehr exponentiell erhöht wird, der auf den fehlerhaften Dienst abzielt.
Daher benötigen Sie eine Art Verteidigungsbarriere, damit übermäßige Anforderungen aufhören, wenn es sich nicht mehr lohnt, weiterzumachen. Diese Verteidigungsbarriere ist genau der Schaltkreisbrecher.
Das Circuit Breaker-Konzept verfolgt einen anderen Zweck als das "Retry-Konzept". Das "Wiederholungsmuster" ermöglicht es einer Anwendung, einen Vorgang erneut zu versuchen, in der Erwartung, dass der Vorgang letztendlich erfolgreich ist. Das Schaltkreistrennmuster verhindert, dass eine Anwendung einen Vorgang ausführt, der wahrscheinlich fehlschlägt. Eine Anwendung kann diese beiden Muster kombinieren. Die Wiederholungslogik sollte jedoch auf alle vom Schutzschalter zurückgegebenen Ausnahmen sensibel reagieren, und es sollten Wiederholungsversuche abgebrochen werden, wenn der Schutzschalter anzeigt, dass ein Fehler nicht vorübergehend ist.
Implementieren eines Circuit Breaker-Musters mit IHttpClientFactory und Polly
Ebenso wie für die Implementierung von Wiederholungen wird auch für Circuit Breakers empfohlen, auf bewährte .NET-Bibliotheken wie Polly und die native Integration in IHttpClientFactory zurückzugreifen.
Eine Circuit Breaker-Richtlinie kann zu Ihrer ausgehenden IHttpClientFactory-Middlewarepipeline hinzugefügt werden, indem Sie einfach einen einzelnen inkrementellen Codeabschnitt zu dem Code hinzufügen, der bei der Verwendung von IHttpClientFactory bereits vorhanden ist.
Die einzige Ergänzung zu dem Code, der für HTTP-Aufruf-Wiederholungen verwendet wird, ist der Code, in dem Sie die Richtlinie "Circuit Breaker" zur Liste der zu verwendenden Richtlinien hinzufügen, wie im folgenden inkrementellen Code gezeigt.
// Program.cs
var retryPolicy = GetRetryPolicy();
var circuitBreakerPolicy = GetCircuitBreakerPolicy();
builder.Services.AddHttpClient<IBasketService, BasketService>()
.SetHandlerLifetime(TimeSpan.FromMinutes(5)) // Sample: default lifetime is 2 minutes
.AddHttpMessageHandler<HttpClientAuthorizationDelegatingHandler>()
.AddPolicyHandler(retryPolicy)
.AddPolicyHandler(circuitBreakerPolicy);
Die AddPolicyHandler()-Methode ist dafür verantwortlich, Richtlinien zu den HttpClient-Objekten hinzuzufügen, die Sie verwenden. In diesem Fall wird eine Polly-Richtlinie für einen Circuit Breaker hinzugefügt.
Für einen modulareren Ansatz wird die Circuit Breaker-Richtlinie in einer separaten Methode namens GetCircuitBreakerPolicy() definiert, wie in folgendem Code veranschaulicht:
// also in Program.cs
static IAsyncPolicy<HttpResponseMessage> GetCircuitBreakerPolicy()
{
return HttpPolicyExtensions
.HandleTransientHttpError()
.CircuitBreakerAsync(5, TimeSpan.FromSeconds(30));
}
Im obigen Codebeispiel ist die Richtlinie für den Schaltkreistrennschalter so konfiguriert, dass sie den Schaltkreis einbricht oder öffnet, wenn beim Wiederholen der HTTP-Anforderungen fünf aufeinander folgende Fehler aufgetreten sind. In diesem Fall wird der Schaltkreis 30 Sekunden lang unterbrochen: In diesem Zeitraum schlagen Aufrufe durch den Circuit Breaker sofort fehl, statt tatsächlich durchgeführt zu werden. Die Richtlinie interpretiert automatisch relevante Ausnahmen und HTTP-Statuscodes als Fehler.
Schaltkreistrennzeichen sollten auch verwendet werden, um Anforderungen an eine Fallbackinfrastruktur umzuleiten, wenn Sie Probleme in einer bestimmten Ressource hatten, die in einer anderen Umgebung bereitgestellt wird als die Clientanwendung oder der Dienst, die den HTTP-Aufruf ausführt. Wenn im Rechenzentrum ein Ausfall vorhanden ist, der sich nur auf Ihre Back-End-Microservices, aber nicht auf Ihre Clientanwendungen auswirkt, können die Clientanwendungen zu den Fallbackdiensten umgeleitet werden. Für Polly wird aktuell eine Richtlinie zur Automatisierung dieses Failoverrichtlinienszenarios geplant.
Alle diese Funktionen sind für Fälle gedacht, in denen Sie das Failover aus dem .NET-Code heraus verwalten, anstatt es von Azure automatisch verwalten zu lassen, mit Ortsunabhängigkeit.
Aus Sicht der Verwendung muss bei Verwendung von HttpClient hier nichts Neues hinzugefügt werden, da der Code identisch ist als bei verwendung HttpClient mit IHttpClientFactory, wie in vorherigen Abschnitten gezeigt.
Testen von HTTP-Wiederholungen und Circuit Breakern in eShopOnContainers
Wenn Sie die eShopOnContainers-Lösung in einem Docker-Host starten, muss sie mehrere Container starten. Einige der Container sind langsamer zu starten und zu initialisieren, z. B. der SQL Server-Container. Dies gilt insbesondere beim ersten Bereitstellen der eShopOnContainers-Anwendung in Docker, da sie die Images und die Datenbank einrichten muss. Die Tatsache, dass einige Container langsamer beginnen als andere, können dazu führen, dass die restlichen Dienste anfänglich HTTP-Ausnahmen auslösen, auch wenn Sie Abhängigkeiten zwischen Containern auf docker-compose-Ebene festlegen, wie in früheren Abschnitten erläutert. Diese Docker-Compose-Abhängigkeiten zwischen Containern befinden sich nur auf Prozessebene. Der Einstiegspunktprozess des Containers kann gestartet werden, SQL Server ist jedoch möglicherweise nicht für Abfragen bereit. Das Ergebnis können zahlreiche Fehler sein. Außerdem wird in der Anwendung möglicherweise eine Ausnahme angezeigt, wenn sie versucht, den Container zu verwenden.
Möglicherweise wird dieser Fehlertyp beim Start auch angezeigt, wenn die Anwendung in der Cloud bereitgestellt wird. In diesem Fall können Orchestratoren Container von einem Knoten oder einer virtuellen Maschine auf einen anderen verschieben (d.h. neue Instanzen starten), während sie die Anzahl der Container über die Nodes im Cluster ausbalancieren.
eShopOnContainers behebt diese Probleme beim Starten aller Container, indem das zuvor veranschaulichte Wiederholungsmuster verwendet wird.
Testen des Schaltkreisschalters in eShopOnContainers
Es gibt einige Möglichkeiten, um den Schaltkreis zu unterbrechen/zu öffnen und mit eShopOnContainers zu testen.
Eine Option besteht darin, die zulässige Anzahl von Wiederholungen in der Circuit-Breaker-Richtlinie auf 1 zu reduzieren und die gesamte Lösung in Docker bereitzustellen. Bei einem einzelnen Wiederholungsvorgang besteht eine gute Chance, dass eine HTTP-Anforderung während der Bereitstellung fehlschlägt, der Schaltkreistrennschalter wird geöffnet, und Sie erhalten einen Fehler.
Eine weitere Option besteht darin, benutzerdefinierte Middleware zu verwenden, die im Basket microservice implementiert ist. Wenn diese Middleware aktiviert ist, fängt sie alle HTTP-Anforderungen ab und gibt Statuscode 500 zurück. Sie können die Middleware aktivieren, indem Sie eine GET-Anforderung an den fehlerhaften URI wie folgt vornehmen:
GET http://localhost:5103/failing
Diese Anforderung gibt den aktuellen Status der Middleware zurück. Wenn die Middleware aktiviert ist, gibt der Anforderungsrückgabestatuscode 500 zurück. Wenn die Middleware deaktiviert ist, gibt es keine Antwort.GET http://localhost:5103/failing?enable
Diese Anforderung aktiviert die Middleware.GET http://localhost:5103/failing?disable
Diese Anforderung deaktiviert die Middleware.
Wenn die Anwendung beispielsweise ausgeführt wird, können Sie die Middleware aktivieren, indem Sie eine Anforderung mit dem folgenden URI in einem beliebigen Browser durchführen. Beachten Sie, dass der Bestell microservice Port 5103 verwendet.
http://localhost:5103/failing?enable
Anschließend können Sie den Status mithilfe des URI http://localhost:5103/failingüberprüfen, wie in Abbildung 8-5 dargestellt.
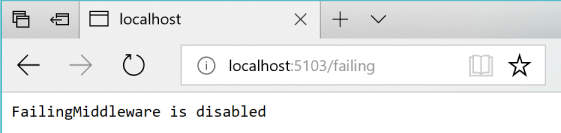
Abbildung 8-5. Überprüfung des Status der „fehlschlagenden“ ASP.NET-Middleware (hier deaktiviert)
An dieser Stelle antwortet der Basket microservice mit dem Statuscode 500, wenn Sie ihn aufrufen.
Sobald die Middleware ausgeführt wird, können Sie versuchen, eine Bestellung aus der MVC-Webanwendung zu erstellen. Da die Anforderungen fehlschlagen, wird die Kommunikation fortgesetzt.
Im folgenden Beispiel können Sie sehen, dass die MVC-Webanwendung einen Catch-Block in der Logik zum Platzieren einer Bestellung aufweist. Wenn der Code eine Open-Circuit-Ausnahme abfängt, wird dem Benutzer eine benutzerfreundliche Meldung angezeigt, die ihn darüber informiert, dass er warten soll.
public class CartController : Controller
{
//…
public async Task<IActionResult> Index()
{
try
{
var user = _appUserParser.Parse(HttpContext.User);
//Http requests using the Typed Client (Service Agent)
var vm = await _basketSvc.GetBasket(user);
return View(vm);
}
catch (BrokenCircuitException)
{
// Catches error when Basket.api is in circuit-opened mode
HandleBrokenCircuitException();
}
return View();
}
private void HandleBrokenCircuitException()
{
TempData["BasketInoperativeMsg"] = "Basket Service is inoperative, please try later on. (Business message due to Circuit-Breaker)";
}
}
Hier ist eine Zusammenfassung. Die Wiederholungsrichtlinie versucht mehrmals, die HTTP-Anfrage durchzuführen und stößt dabei auf HTTP-Fehler. Wenn die Anzahl der Wiederholungen die maximale Anzahl erreicht, die für die Richtlinie "Circuit Breaker" festgelegt ist (in diesem Fall 5), löst die Anwendung eine BrokenCircuitException aus. Das Ergebnis ist eine freundliche Nachricht, wie in Abbildung 8-6 dargestellt.
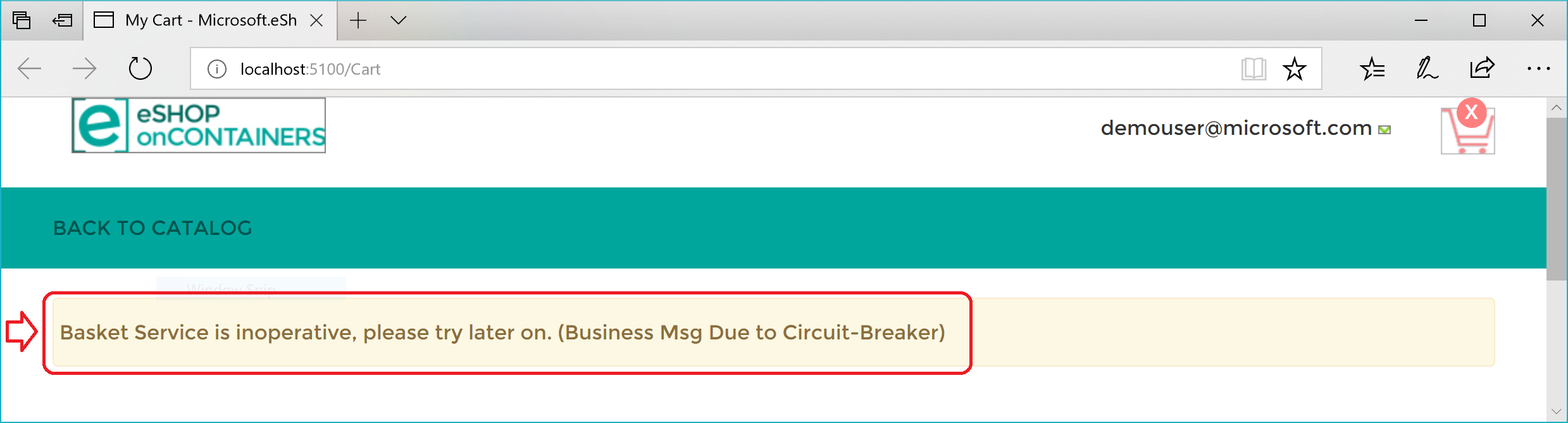
Abbildung 8-6. Schaltkreisbrecher, der einen Fehler an die Benutzeroberfläche zurückgibt
Sie können unterschiedliche Logik implementieren, um den Schaltkreis zu öffnen/zu unterbrechen. Sie können auch eine HTTP-Anforderung für einen anderen Back-End-Microservice ausprobieren, wenn ein Fallback-Rechenzentrum oder ein redundantes Back-End-System vorhanden ist.
Eine weitere Möglichkeit für CircuitBreakerPolicy ist die Verwendung von Isolate (dadurch wird das Fortsetzen der Kommunikation erzwungen und dafür gesorgt, dass diese bestehen bleibt) und Reset (dadurch wird die Kommunikation wieder unterbrochen). Diese können verwendet werden, um einen HTTP-Hilfsendpunkt zu erstellen, der Isolate und Reset direkt in der Richtlinie aufruft. Ein solcher HTTP-Endpunkt könnte auch in der Produktion verwendet werden, wenn er angemessen gesichert ist, um ein nachgeschaltetes System vorübergehend zu isolieren, z. B. wenn Sie es aktualisieren möchten. Alternativ könnte er den Trennschalter manuell auslösen, um ein Downstreamsystem zu schützen, das möglicherweise fehlerhaft ist.
Weitere Ressourcen
-
Trennschalter-Muster
https://learn.microsoft.com/azure/architecture/patterns/circuit-breaker
Zusammenarbeit auf GitHub
Die Quelle für diesen Inhalt finden Sie auf GitHub, wo Sie auch Issues und Pull Requests erstellen und überprüfen können. Weitere Informationen finden Sie in unserem Leitfaden für Mitwirkende.