Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
Tipp
Dieser Inhalt ist ein Auszug aus dem eBook .NET Microservices Architecture for Containerized .NET Applications, verfügbar auf .NET Docs oder als kostenlose herunterladbare PDF, die offline gelesen werden kann.

Datenpersistenzkomponenten bieten Zugriff auf die Daten, die innerhalb der Grenzen eines Microservice gehostet werden (d. a. die Datenbank eines Microservice). Sie enthalten die tatsächliche Implementierung von Komponenten wie Repositorys und Arbeitseinheitenklassen , z. B. benutzerdefinierte Entity Framework (EF)- DbContext Objekte. EF DbContext implementiert die beiden Muster „Repository“ und „Arbeitseinheit“.
Das Repositorymuster
Das Repositorymuster ist ein Domain-Driven Entwurfsmuster, das darauf abzielt, Persistenzbedenken außerhalb des Domänenmodells des Systems beizubehalten. Mindestens eine Persistenzabstraktion – Schnittstellen – werden im Domänenmodell definiert, und diese Abstraktionen verfügen über Implementierungen in Form von Persistenz-spezifischen Adaptern, die an anderer Stelle in der Anwendung definiert sind.
Repositoryimplementierungen sind Klassen, die die für den Zugriff auf Datenquellen erforderliche Logik kapseln. Sie zentralisieren allgemeine Datenzugriffsfunktionen, wodurch die Infrastruktur oder Technologie, die für den Zugriff auf Datenbanken aus dem Domänenmodell verwendet wird, besser verwaltet und entkoppelt wird. Wenn Sie einen ORM (objektrelationaler Mapper) wie Entity Framework verwenden, wird der zu implementierende Code dank LINQ und starker Typisierung vereinfacht. Auf diese Weise können Sie sich auf die Datenpersistenzlogik konzentrieren und nicht auf die Datenzugriffsmechanismen.
Das Repositorymuster ist eine gut dokumentierte Methode zum Arbeiten mit einer Datenquelle. Im Buch Patterns of Enterprise Application Architecture beschreibt Martin Fowler ein Repository wie folgt:
Ein Repository fungiert als Vermittler zwischen den Ebenen des Domänenmodells und der Datenzuordnung, ähnlich wie eine Gruppe von Domänenobjekten im Speicher. Clientobjekte erstellen deklarativ Abfragen und senden sie an die Repositorys, um Antworten zu erhalten. Konzeptionell kapselt ein Repository eine Gruppe von Objekten, die in der Datenbank gespeichert sind, und Vorgänge, die für sie ausgeführt werden können, und bietet eine Möglichkeit, die näher an der Persistenzebene liegt. Repositorys unterstützen auch den Zweck, die Abhängigkeit zwischen der Arbeitsdomäne und der Datenzuweisung oder Zuordnung eindeutig und in eine Richtung zu trennen.
Definieren eines Repositorys pro Aggregat
Für jeden Aggregat- oder Aggregatstamm sollten Sie eine Repositoryklasse erstellen. Möglicherweise können Sie C#-Generika nutzen, um die Gesamtanzahl konkreter Klassen zu reduzieren, die Sie verwalten müssen (wie weiter unten in diesem Kapitel gezeigt). In einem Mikroservice, der auf Domain-Driven Designmustern (DDD) basiert, sollte der einzige Kanal, den Sie zum Aktualisieren der Datenbank verwenden sollten, die Repositorys sein. Dies liegt daran, dass sie über eine 1:1-Beziehung mit dem Aggregatstamm verfügen, die die Invarianten und transaktionsbezogene Konsistenz des Aggregats steuert. Es ist in Ordnung, die Datenbank über andere Kanäle abzufragen (wie Sie einem CQRS-Ansatz folgen können), da Abfragen den Status der Datenbank nicht ändern. Der Transaktionsbereich (d. h. die Aktualisierungen) muss jedoch immer von den Repositorys und den Aggregatwurzeln gesteuert werden.
Im Grunde können Sie mit einem Repository Daten im Arbeitsspeicher auffüllen, die aus der Datenbank in Form der Domänenentitäten stammen. Sobald sich die Entitäten im Arbeitsspeicher befinden, können sie geändert und dann über Transaktionen wieder in der Datenbank gespeichert werden.
Wie bereits erwähnt, werden bei Verwendung des CQS/CQRS-Architekturmusters die anfänglichen Abfragen von Nebenabfragen aus dem Domänenmodell ausgeführt, die mittels einfacher SQL-Anweisungen mit Dapper durchgeführt werden. Dieser Ansatz ist viel flexibler als Repositorys, da Sie alle benötigten Tabellen abfragen und verknüpfen können, und diese Abfragen sind nicht durch Regeln aus den Aggregaten eingeschränkt. Diese Daten werden auf die Präsentationsebene oder die Client-App umgeschaltet.
Wenn der Benutzer Änderungen vor nimmt, stammen die zu aktualisierenden Daten aus der Client-App- oder Präsentationsebene auf die Anwendungsebene (z. B. einen Web-API-Dienst). Wenn Sie einen Befehl in einem Befehlshandler erhalten, verwenden Sie Repositorys, um die Daten abzurufen, die Sie aus der Datenbank aktualisieren möchten. Sie aktualisieren sie im Arbeitsspeicher mit den Daten, die mit den Befehlen übergeben werden, und fügen sie dann die Daten (Domänenentitäten) über eine Transaktion in der Datenbank hinzu oder aktualisieren sie.
Es ist wichtig, erneut hervorzuheben, dass Sie nur ein Repository für jeden Aggregatstamm definieren sollten, wie in Abbildung 7-17 dargestellt. Um das Ziel des Aggregatstamms zu erreichen, um die Transaktionskonsistenz zwischen allen Objekten innerhalb des Aggregats aufrechtzuerhalten, sollten Sie niemals ein Repository für jede Tabelle in der Datenbank erstellen.
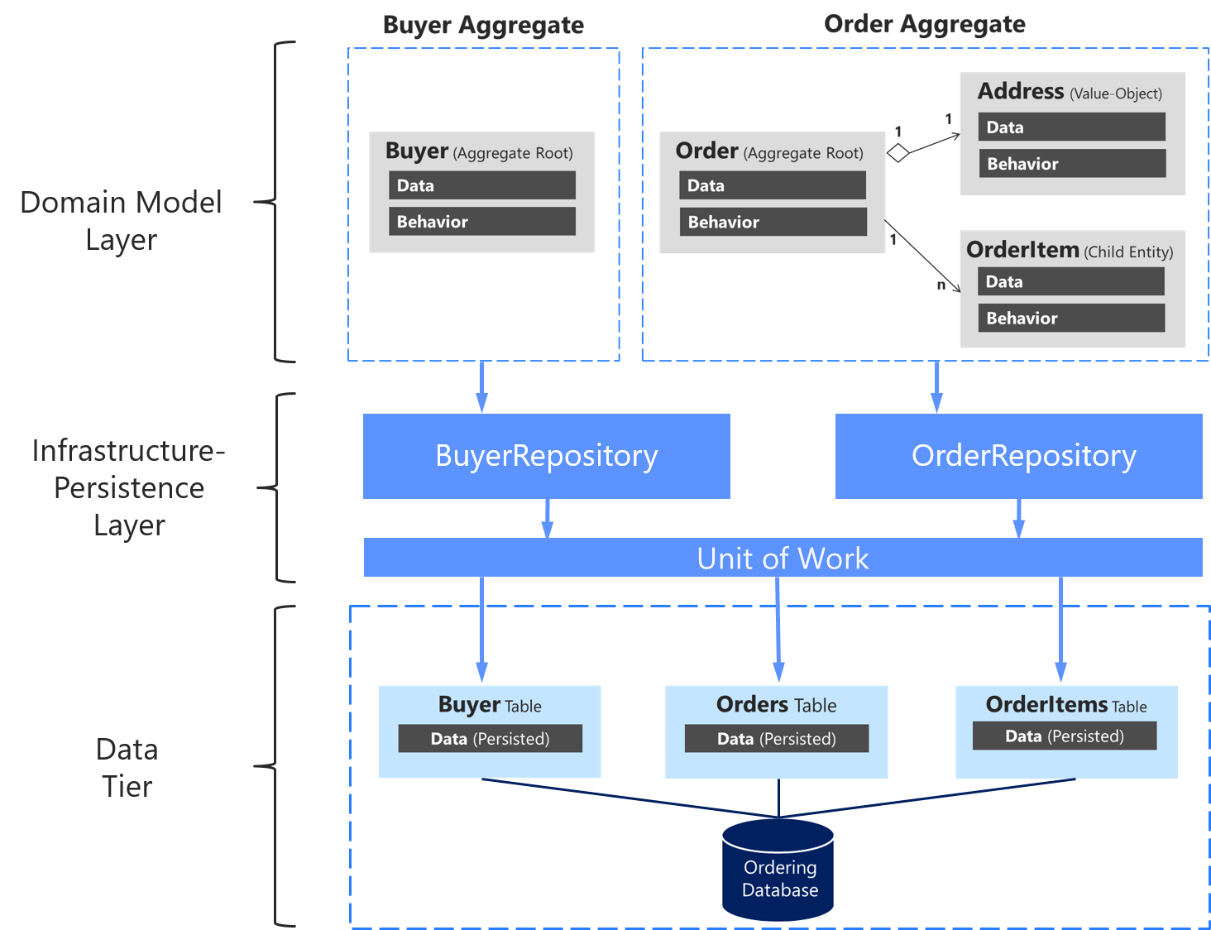
Abbildung 7-17. Die Beziehung zwischen Repositorys, Aggregaten und Datenbanktabellen
Das obige Diagramm zeigt die Beziehungen zwischen den Domänen- und Infrastruktur-Ebenen: Das Käuferaggregat hängt von der IBuyerRepository-Schnittstelle ab und das Order-Aggregat von der IOrderRepository-Schnittstelle. Diese Schnittstellen werden in der Infrastrukturebene von den entsprechenden Repositories implementiert, die von der UnitOfWork abhängen, die ebenfalls dort implementiert ist und auf die Tabellen der Datenebene zugreift.
Erzwingen eines Aggregatstamms pro Repository
Es kann hilfreich sein, Ihr Repositorydesign so zu implementieren, dass es die Regel erzwingt, dass nur aggregierte Wurzeln Über Repositorys verfügen sollten. Sie können einen generischen oder Basis-Repositorytyp erstellen, der den Typ der Entitäten einschränkt, mit denen er arbeitet, um sicherzustellen, dass sie über die IAggregateRoot-Markerschnittstelle verfügen.
Daher implementiert jede auf der Infrastrukturebene implementierte Repositoryklasse einen eigenen Vertrag oder eine eigene Schnittstelle, wie im folgenden Code gezeigt:
namespace Microsoft.eShopOnContainers.Services.Ordering.Infrastructure.Repositories
{
public class OrderRepository : IOrderRepository
{
// ...
}
}
Jede spezifische Repositoryschnittstelle implementiert die generische IRepository-Schnittstelle:
public interface IOrderRepository : IRepository<Order>
{
Order Add(Order order);
// ...
}
Eine bessere Möglichkeit, dass der Code die Konvention erzwingt, die jedes Repository mit einem einzelnen Aggregat verknüpft ist, besteht jedoch darin, einen generischen Repositorytyp zu implementieren. Auf diese Weise ist es explizit, dass Sie ein Repository für ein bestimmtes Aggregat verwenden. Dies kann einfach durch die Implementierung einer generischen IRepository Basisschnittstelle erfolgen, wie im folgenden Code:
public interface IRepository<T> where T : IAggregateRoot
{
//....
}
Das Repositorymuster erleichtert das Testen der Anwendungslogik.
Mit dem Repositorymuster können Sie Ihre Anwendung ganz einfach mit Komponententests testen. Denken Sie daran, dass Komponententests nur Ihren Code und nicht Ihre Infrastruktur testen, sodass die Repositoryabstraktionen das Erreichen dieses Ziels vereinfachen.
Wie in einem früheren Abschnitt erwähnt, empfiehlt es sich, die Repositoryschnittstellen in der Domänenmodellebene zu definieren und zu platzieren, damit die Anwendungsschicht, z. B. Ihr Web-API-Microservice, nicht direkt von der Infrastrukturebene abhängt, auf der Sie die tatsächlichen Repositoryklassen implementiert haben. Indem Sie dies tun und Dependency Injection in den Controllern Ihrer Web-API verwenden, können Sie Pseudorepositorys implementieren, die gefälschte Daten anstelle von Daten aus der Datenbank zurückgeben. Mit diesem entkoppelten Ansatz können Sie Komponententests erstellen und ausführen, die sich auf die Logik Ihrer Anwendung konzentrieren, ohne dass eine Verbindung mit der Datenbank erforderlich ist.
Verbindungen mit Datenbanken können fehlschlagen, und das Ausführen von Hunderten von Tests für eine Datenbank ist aus zwei Gründen schlecht. Erstens kann es aufgrund der großen Anzahl von Tests eine lange Zeit dauern. Zweitens können sich die Datenbankeinträge ändern und sich auf die Ergebnisse Ihrer Tests auswirken, insbesondere, wenn Ihre Tests parallel ausgeführt werden, sodass sie möglicherweise nicht konsistent sind. Komponententests können in der Regel parallel ausgeführt werden; Integrationstests unterstützen je nach Implementierung möglicherweise nicht die parallele Ausführung. Tests für die Datenbank sind kein Komponententest, sondern ein Integrationstest. Sie sollten viele Komponententests schnell ausführen, aber weniger Integrationstests für die Datenbanken.
Im Hinblick auf die Trennung von Bedenken für Komponententests arbeitet Ihre Logik auf Domänenentitäten im Arbeitsspeicher. Es wird davon ausgegangen, dass die Repositoryklasse diese bereitgestellt hat. Sobald Ihre Logik die Domänenentitäten ändert, wird davon ausgegangen, dass die Repositoryklasse sie ordnungsgemäß speichert. Der wichtigste Punkt hier ist die Erstellung von Komponententests für Ihr Domänenmodell und die Zugehörige Domänenlogik. Aggregatwurzeln sind die wichtigsten Konsistenzgrenzen in DDD.
Die in eShopOnContainers implementierten Repositorys basieren auf der DbContext-Implementierung von EF Core, die die Muster "Repository" und "Unit of Work" mit ihrem Änderungsverfolgungsmechanismus nutzt, sodass diese Funktionalität nicht dupliziert wird.
Der Unterschied zwischen dem Repositorymuster und dem älteren Datenzugriffsklassenmuster (DAL-Klasse)
Ein typisches DAL-Objekt führt direkt Datenzugriffs- und Persistenzvorgänge gegen den Speicher aus, häufig auf ebene einer einzelnen Tabelle und Zeile. Einfache CRUD-Vorgänge, die mit einer Reihe von DAL-Klassen implementiert wurden, unterstützen häufig keine Transaktionen (obwohl dies nicht immer der Fall ist). Die meisten DAL-Klassenansätze nutzen nur minimale Abstraktionen, was zu einer engen Kopplung zwischen Anwendungs- oder BLL-Klassen (Business Logic Layer) führt, die die DAL-Objekte aufrufen.
Bei Verwendung des Repositorys werden die Implementierungsdetails der Persistenz vom Domänenmodell entfernt gekapselt. Die Verwendung einer Abstraktion bietet eine einfache Erweiterung des Verhaltens durch Muster wie Dekoratoren oder Proxys. Beispielsweise können querschnittliche Belange wie Zwischenspeicherung, Protokollierung und Fehlerbehandlung mithilfe dieser Muster angewendet werden, anstatt sie direkt im Code für den Datenzugriff fest zu verankern. Es ist ebenfalls einfach, mehrere Repositoryadapter zu unterstützen, die in verschiedenen Umgebungen verwendet werden können, von der lokalen Entwicklung bis hin zu gemeinsamen Staging-Umgebungen bis zur Produktion.
Implementieren der „Arbeitseinheit“
Eine Arbeitseinheit bezieht sich auf eine einzelne Transaktion, die mehrere Einfüge-, Aktualisierungs- oder Löschvorgänge umfasst. In einfachen Worten bedeutet dies, dass für eine bestimmte Benutzeraktion, z. B. eine Registrierung auf einer Website, alle Einfüge-, Aktualisierungs- und Löschvorgänge in einer einzigen Transaktion behandelt werden. Dies ist effizienter als die Abwicklung mehrerer Datenbankvorgänge auf umständliche Weise.
Mehrere Persistenzvorgänge werden später in einer einzigen Aktion ausgeführt, wenn Ihr Code vom Anwendungslayer dies anfordert. Die Entscheidung über das Anwenden der In-Memory-Änderungen auf den tatsächlichen Datenbankspeicher basiert in der Regel auf dem Arbeitseinheitsmuster. In EF wird das Muster „Arbeitseinheit“ von einem DbContext implementiert und ausgeführt, wenn SaveChanges aufgerufen wird.
In vielen Fällen kann dieses Muster oder die Art der Anwendung von Vorgängen gegen den Speicher die Anwendungsleistung erhöhen und die Möglichkeit von Inkonsistenzen verringern. Zudem können Transaktionsblockierungen in den Datenbanktabellen verringert werden, da alle vorgesehenen Vorgänge im Rahmen einer Transaktion zugesichert werden. Dies ist im Vergleich zur Ausführung vieler isolierter Vorgänge für die Datenbank effizienter. Daher kann das ausgewählte ORM die Ausführung für die Datenbank optimieren, indem mehrere Aktualisierungsaktionen innerhalb derselben Transaktion gruppiert werden, im Gegensatz zu vielen kleinen und separaten Transaktionsausführungen.
Das Muster „Arbeitseinheit“ kann mit dem oder ohne das Repository-Muster implementiert werden.
Repositorys sollten nicht obligatorisch sein
Benutzerdefinierte Repositorys sind aus den zuvor genannten Gründen nützlich, und dies ist der Ansatz für den Bestell-Microservice in eShopOnContainers. Es ist jedoch kein wesentliches Muster für die Implementierung in einem DDD-Design oder sogar in der allgemeinen .NET-Entwicklung.
Beispielsweise sagte Jimmy Bogard, als er direktes Feedback für diesen Leitfaden gab, Folgendes:
Dies wird wahrscheinlich mein größtes Feedback sein. Ich bin wirklich kein Fan von Repositorys, hauptsächlich weil sie die wichtigen Details des zugrunde liegenden Persistenzmechanismus ausblenden. Deshalb entscheide ich mich auch für MediatR bei Befehlen. Ich kann die volle Leistungsfähigkeit der Persistenzschicht verwenden und das gesamte Domänenverhalten in meine Aggregatwurzeln verschieben. Normalerweise möchte ich meine Repositorys nicht modellieren – ich muss noch diesen Integrationstest mit dem echten Ding haben. Wenn wir CQRS verwenden, bedeutete das, dass wir nicht mehr überhaupt einen Bedarf an Repositorys haben.
Repositories können nützlich sein, aber sie sind für Ihr DDD-Design nicht entscheidend, wie es das Aggregatmuster und ein reichhaltiges Domänenmodell sind. Verwenden Sie daher das Repository-Muster oder auch nicht, wie Sie es für richtig halten.
Weitere Ressourcen
Repositorymuster
Edward Hieatt und Rob me. Repositorymuster.
https://martinfowler.com/eaaCatalog/repository.htmlDas Repositorymuster
https://learn.microsoft.com/previous-versions/msp-n-p/ff649690(v=pandp.10)Eric Evans. Domain-Driven Design: Komplexität im Herzen der Software anzugehen. (Buch; enthält eine Diskussion über das Repository-Muster)
https://www.amazon.com/Domain-Driven-Design-Tackling-Complexity-Software/dp/0321125215/
Muster der Arbeitseinheit
Martin Fowler. Arbeitseinheitsmuster.
https://martinfowler.com/eaaCatalog/unitOfWork.htmlImplementieren des Repositorys und der Arbeitsmustereinheit in einer ASP.NET MVC-Anwendung
https://learn.microsoft.com/aspnet/mvc/overview/older-versions/getting-started-with-ef-5-using-mvc-4/implementing-the-repository-and-unit-of-work-patterns-in-an-asp-net-mvc-application
Zusammenarbeit auf GitHub
Die Quelle für diesen Inhalt finden Sie auf GitHub, wo Sie auch Issues und Pull Requests erstellen und überprüfen können. Weitere Informationen finden Sie in unserem Leitfaden für Mitwirkende.