Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
Der ML.NET-Modell-Generator ist eine intuitive grafische Visual Studio-Erweiterung zum Erstellen, Trainieren und Bereitstellen von benutzerdefinierten Machine Learning-Modellen. Sie verwendet automatisiertes maschinelles Lernen (AutoML), um verschiedene Machine Learning-Algorithmen und -Einstellungen zu untersuchen, damit Sie den für Ihr Szenario am besten geeigneten Algorithmus ermitteln können.
Für die Verwendung des Modell-Generators sind keine Machine Learning-Kenntnisse erforderlich. Sie benötigen lediglich einige Daten und ein Problem, das Sie lösen möchten. Modell-Generator generiert den Code, um das Modell zur Ihrer .NET-Anwendung hinzuzufügen.

Erstellen eines Model Builder-Projekts
Wenn Sie Model Builder zum ersten Mal starten, werden Sie aufgefordert, das Projekt zu benennen. Dann wird eine mbconfig-Konfigurationsdatei innerhalb des Projekts erstellt. Die mbconfig-Datei verfolgt alles, was Sie in Model Builder tun, damit Sie die Sitzung erneut öffnen können.
Nach dem Training werden drei Dateien unter der Datei „*.mbconfig“ generiert:
- Model.consumption.cs: Diese Datei enthält die Schemas
ModelInputundModelOutputsowie diePredict-Funktion, die zur Nutzung des Modells generiert wurde. - Model.training.cs: Diese Datei enthält die Trainingspipeline (Datentransformationen, Algorithmus, Algorithmushyperparameter), die von Model Builder zum Trainieren des Modells ausgewählt wurde. Sie können diese Pipeline zum erneuten Trainieren Ihres Modells verwenden.
- Model.zip: Dies ist eine serialisierte ZIP-Datei, die Ihr trainiertes ML.NET-Modell darstellt.
Wenn Sie Ihre mbconfig-Datei erstellen, werden Sie zur Eingabe eines Namens aufgefordert. Dieser Name wird auf die Verbrauchs-, Trainings- und Modelldateien angewendet. In diesem Fall lautet der verwendete Name Model.
Szenario
Sie können viele verschiedene Szenarien in den Modell-Generator einbinden, um ein Machine Learning-Modell für Ihre Anwendung zu erstellen.
Ein Szenario ist eine Beschreibung der Art der Vorhersage, die Sie mit Ihren Daten treffen möchten. Zum Beispiel:
- Vorhersagen des zukünftigen Produktabsatzes auf der Grundlage früherer Verkaufsdaten
- Klassifizieren der Stimmungen als positiv oder negativ anhand von Kundenrezensionen
- Erkennen einer betrügerischen Banktransaktion
- Weiterleiten von Problemen beim Kundenfeedback an das richtige Team in Ihrem Unternehmen
Jedes Szenario ist einer anderen Machine-Learning-Aufgabe zugeordnet, darunter:
| Aufgabe | Szenario |
|---|---|
| Binäre Klassifizierung | Datenklassifizierung |
| Multiklassenklassifizierung | Datenklassifizierung |
| Bildklassifizierung | Bildklassifizierung |
| Textklassifizierung | Textklassifizierung |
| Regression | Wertvorhersage |
| Empfehlung | Empfehlung |
| Vorhersagen | Vorhersagen |
Beispielsweise würde das Szenario zum Klassifizieren von Stimmungen als positiv oder negativ unter die binäre Klassifizierungsaufgabe fallen.
Weitere Informationen zu den verschiedenen von ML.NET unterstützten ML-Aufgaben finden Sie unter Machine Learning-Aufgaben in ML.NET.
Welches Machine Learning-Szenario ist für mich geeignet?
Im Modell-Generator müssen Sie ein Szenario auswählen. Die Art des Szenarios hängt davon ab, welche Art von Vorhersage Sie treffen möchten.
Tabellarisch
Datenklassifizierung
Die Klassifizierung dient der Unterteilung von Daten in Kategorien.
Beispieleingabe
Beispielausgabe
| SepalLength | SepalWidth | Blütenblattlänge | Blütenblattbreite | Tierart |
|---|---|---|---|---|
| 5,1 | 3,5 | 1.4 | 0.2 | setosa |
| Vorhergesagte Arten |
|---|
| setosa |
Wertvorhersage
Die Wertvorhersage, die unter die Regressionsaufgabe fällt, wird verwendet, um Zahlen vorherzusagen.
Beispieleingabe
Beispielausgabe
| vendor_id | rate_code | passenger_count | trip_time_in_secs | trip_distance | payment_type | fare_amount |
|---|---|---|---|---|---|---|
| CMT | 1 | 1 | 1271 | 3.8 | CRD | 17,5 |
| Vorhergesagter Fahrpreis |
|---|
| 4,5 |
Empfehlung
Mit dem Empfehlungsszenario wird eine Liste vorgeschlagener Elemente für einen bestimmten Benutzer vorhergesagt. Die Vorhersage basiert darauf, wie stark ihre „Gefällt mir“- und „Gefällt nicht“-Angaben denen anderer Benutzer ähneln.
Sie können das Empfehlungsszenario verwenden, wenn Sie über einen Satz mit Benutzern und einen Satz mit „Produkten“ – z. B. Kaufartikel, Filme, Bücher oder TV-Sendungen – sowie über einen Satz mit Benutzerbewertungen dieser Produkte verfügen.
Beispieleingabe
Beispielausgabe
| UserId | ProductId | Rating |
|---|---|---|
| 1 | 2 | 4,2 |
| Vorhergesagte Bewertung |
|---|
| 4,5 |
Vorhersagen
Das Prognoseszenario verwendet Verlaufsdaten mit einer Zeitreihen- oder saisonalen Komponente.
Sie können das Prognoseszenario verwenden, um die Nachfrage oder den Verkauf eines Produkts vorherzusagen.
Beispieleingabe
Beispielausgabe
| Date | SaleQty |
|---|---|
| 01.01.1970 | 1000 |
| 3-Tage-Prognose |
|---|
| [1000,1001,1002] |
Maschinelles Sehen
Bildklassifizierung
Die Bildklassifizierung wird verwendet, um Bilder unterschiedlicher Kategorien zu identifizieren. Beispiele hierfür sind unterschiedliche Arten von Gelände, Tieren oder Fertigungsfehlern.
Sie können das Szenario für die Bildklassifizierung verwenden, wenn Sie über einen Satz von Bildern verfügen und die Bilder in verschiedene Kategorien klassifizieren möchten.
Beispieleingabe
Beispielausgabe

| Vorhergesagte Bezeichnung |
|---|
| Hund |
Objekterkennung
Die Objekterkennung dient dem Suchen und Kategorisieren von Entitäten auf Bildern. Beispiele hierfür sind das Suchen und Identifizieren von Autos und Personen auf einem Bild.
Sie können die Objekterkennung verwenden, wenn Bilder mehrere Objekte verschiedener Typen enthalten.
Beispieleingabe
Beispielausgabe

Verarbeitung natürlicher Sprache
Textklassifizierung
Die Textklassifizierung kategorisiert unformatierte Texteingaben.
Sie können das Textklassifizierungsszenario verwenden, wenn Sie über einen Satz von Dokumenten oder Kommentaren verfügen und sie in verschiedene Kategorien klassifizieren möchten.
Beispieleingabe
Beispielausgabe
| Überprüfung |
|---|
| Ich mag dieses Steak wirklich! |
| Stimmung |
|---|
| Positiv |
Umgebung
Sie können Ihr Machine Learning-Modell je nach Szenario lokal auf Ihrem Computer oder in der Cloud in Azure trainieren.
Wenn Sie ein lokales Training durchführen, arbeiten Sie innerhalb der Grenzen Ihrer Computerressourcen (CPU, Arbeitsspeicher und Datenträger). Wenn Sie das Training in der Cloud durchführen, können Sie Ihre Ressourcen in Abstimmung auf die Anforderungen Ihres Szenarios hochskalieren, insbesondere für große Datasets.
| Szenario | Lokale CPU | Lokale GPU | Azure |
|---|---|---|---|
| Datenklassifizierung | ✔️ | ❌ | ❌ |
| Wertvorhersage | ✔️ | ❌ | ❌ |
| Empfehlung | ✔️ | ❌ | ❌ |
| Vorhersagen | ✔️ | ❌ | ❌ |
| Bildklassifizierung | ✔️ | ✔️ | ✔️ |
| Objekterkennung | ❌ | ❌ | ✔️ |
| Textklassifizierung | ✔️ | ✔️ | ❌ |
Daten
Sobald Sie Ihr Szenario ausgewählt haben, fordert Model Builder Sie auf, ein Dataset bereitzustellen. Die Daten werden verwendet, um das beste Modell für Ihr Szenario zu trainieren, zu evaluieren und auszuwählen.
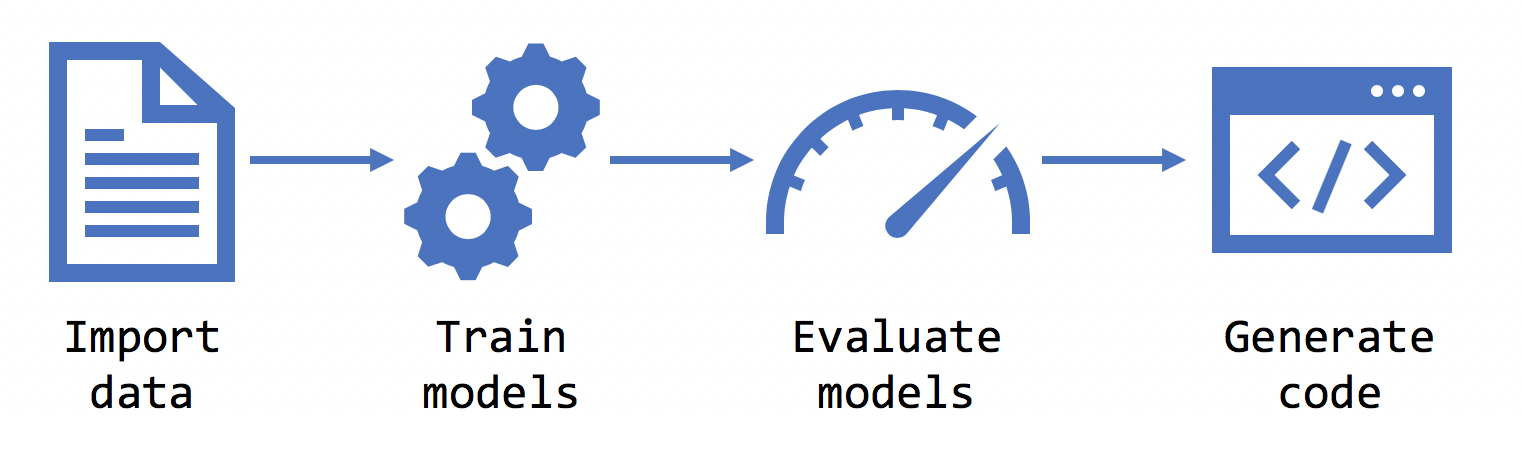
Model Builder unterstützt Datasets im TSV-, CSV- und TXT-Format sowie im SQL-Datenbank-Format. Wenn Sie über eine TXT-Datei verfügen, sollten Spalten durch ,, ; oder \t getrennt werden.
Wenn das Dataset aus Bildern besteht, sind die unterstützten Dateitypen .jpg und .png.
Weitere Informationen finden Sie unter Laden von Trainingsdaten in den Modell-Generator.
Auswählen der Ausgabe für die Vorhersage (Bezeichnung)
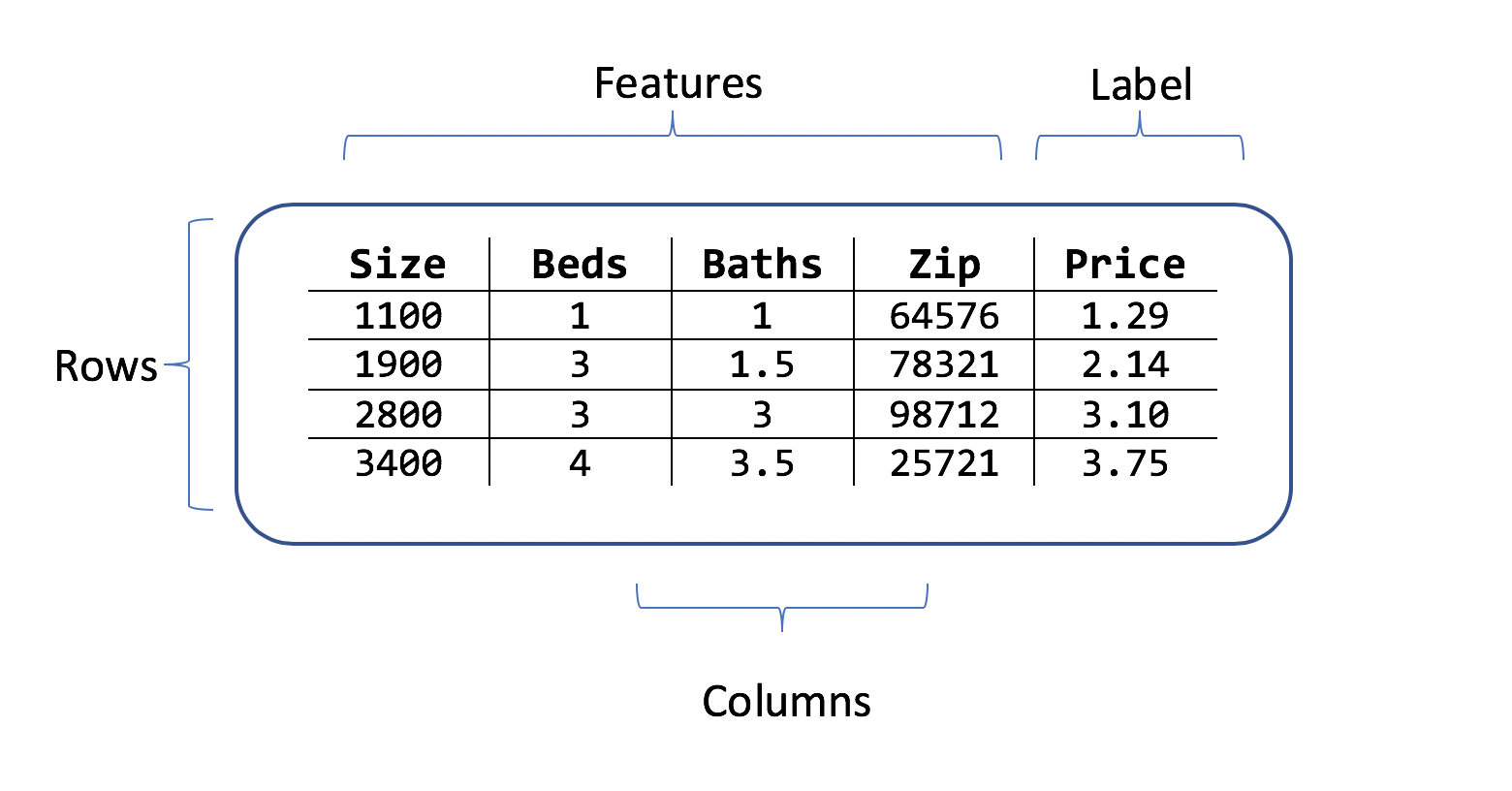
Ein Dataset ist eine Tabelle mit Zeilen mit Trainingsbeispielen und Spalten mit Attributen. Jede Zeile enthält:
- eine Bezeichnung (das Attribut, das Sie vorhersagen möchten)
- Features (Attribute, die als Eingaben verwendet werden, um die Bezeichnung vorherzusagen)
Für das Szenario der Hauspreisvorhersage könnten folgende Features verwendet werden:
- die Quadratmeterzahl des Hauses
- die Anzahl an Schlafzimmern und Badezimmern
- die Postleitzahl
Die Bezeichnung ist der historische Hauspreis für diese Zeile mit den Werten für die Quadratmeterzahl, Schlafzimmer- und Badezimmeranzahl und Postleitzahl.
Beispieldatasets
Wenn Sie noch keine eigenen Daten haben, probieren Sie eines dieser Datasets aus:
| Szenario | Beispiel | Daten | Bezeichnung | Features |
|---|---|---|---|---|
| Klassifizierung | Vorhersage von Umsatzanomalien | product sales data | Produktverkäufe | Monat |
| Stimmungsvorhersage für Websitekommentare | website comment data | Bezeichnung (1 bei negativer Stimmung, 0 bei positiver Stimmung) | Kommentar, Jahr | |
| Vorhersage betrügerischer Kreditkartentransaktionen | credit card data | Klasse (1, wenn betrügerisch, andernfalls 0) | Betrag, V1-V28 (anonymisierte Features) | |
| Vorhersage des Issuetyps in einem GitHub-Repository | GitHub issue data | Bereich | Titel, Beschreibung | |
| Wertvorhersage | Vorhersage des Preises für eine Taxifahrt | taxi fare data | Preis | Fahrtzeit, Strecke |
| Bildklassifizierung | Vorhersage der Kategorie einer Blume | flower images | Der Typ Blume: Gänseblümchen, Löwenzahn, Rosen, Sonnenblumen, Tulpen | Die Bilddaten selbst |
| Empfehlung | Vorhersage von Filmen, die einer Person gefallen | movie ratings | Benutzer, Filme | Altersfreigabe |
Training
Sobald Sie Ihr Szenario, Ihre Umgebung, Ihre Daten und Ihre Bezeichnung ausgewählt haben, trainiert der Modell-Generator das Modell.
Was bedeutet Training?
Das Training ist ein automatischer Prozess, bei dem der Modellgenerator dem Modell beibringt, wie es Fragen für Ihr Szenario beantworten kann. Nach dem Training kann Ihr Modell Vorhersagen mit ihm bisher unbekannten Eingabedaten treffen. Wenn Sie zum Beispiel die Hauspreise vorhersagen und ein neues Haus auf den Markt kommt, können Sie seinen Verkaufspreis vorhersagen.
Da der Modell-Generator automatisiertes maschinelles Lernen (AutoML) verwendet, ist während des Trainings keine Eingabe oder Anpassung durch Sie erforderlich.
Wie lange sollte ich das Modell trainieren?
Der Modell-Generator verwendet AutoML zum Untersuchen mehrerer Modelle, um das Modell mit der besten Leistung zu ermitteln.
Längere Trainingszeiträume ermöglichen es AutoML, mehr Modelle mit einer breiteren Palette von Einstellungen zu untersuchen.
In der folgenden Tabelle wird die durchschnittliche Zeit zusammengefasst, die benötigt wird, um eine gute Leistung für eine Suite von Beispieldatasets auf einem lokalen Computer zu erzielen.
| Datasetgröße | Durchschnittliche Trainingszeit |
|---|---|
| 0 bis 10 MB | 10 Sek. |
| 10 bis 100 MB | 10 Min. |
| 100 bis 500 MB | 30 Min. |
| 500 MB bis 1 GB | 60 Min. |
| Mehr als 1 GB | Mehr als 3 Stunden |
Diese Zahlen sind nur eine Richtlinie. Die genaue Trainingsdauer ist abhängig von:
- die Anzahl der Features (Spalten), die als Eingabe für das Modell verwendet werden
- Art der Spalten
- die ML-Aufgabe
- die CPU-, Datenträger- und Arbeitsspeicherleistung des zum Training verwendeten Computers
Generell wird empfohlen, dass Sie mehr als 100 Zeilen verwenden, da Datasets mit weniger Zeilen möglicherweise keine Ergebnisse erzielen.
Auswerten
Auswertung ist der Prozess, bei dem gemessen wird, wie gut das Modell ist. Der Modell-Generator verwendet das trainierte Modell, um Vorhersagen mit neuen Testdaten zu treffen und anschließend zu messen, wie gut die Vorhersagen sind.
Der Modell-Generator unterteilt die Trainingsdaten in einen Trainingssatz und einen Testsatz. Die Trainingsdaten (80 %) werden zum Trainieren Ihres Modells verwendet, und die Testdaten (20 %) zur Evaluierung Ihres Modells zurückgehalten.
Wie gewinne ich ein Verständnis für die Modellleistung?
Ein Szenario wird einer Machine Learning-Aufgabe zugeordnet. Jede ML-Aufgabe verfügt über einen eigenen Satz von Auswertungsmetriken.
Wertvorhersage
Die Standardmetrik für Wertvorhersageprobleme ist RSquared. Der Wert von RSquared liegt zwischen 0 und 1. 1 ist der bestmögliche Wert, d. h. je näher der Wert von RSquared bei 1 liegt, desto besser ist die Leistung Ihres Modells.
Andere erfasste Metriken wie „absolute-loss“, „squared-loss“ und „RMS-loss“ sind zusätzliche Metriken, die verwendet werden können, um die Leistung Ihres Modells zu verstehen und es mit anderen Wertvorhersagemodellen zu vergleichen.
Klassifizierung (2 Kategorien)
Die Standardmetrik für binäre Klassifizierungsprobleme ist „accuracy“ (Genauigkeit). Sie definiert den Anteil an genauen Vorhersagen, die Ihr Modell anhand des Testdatasets trifft. Je näher der Wert bei 100 % oder 1,0 liegt, desto besser ist das Modell.
Andere gemeldete Metriken wie AUC (Area under the curve, Fläche unter der Kurve), die den Anteil der tatsächlich positiven Ergebnisse mit dem Anteil der falsch positiven Ergebnisse abgleicht, sollten größer als 0,50 sein, damit Modelle akzeptabel sind.
Zusätzliche Metriken wie die F1-Bewertung können verwendet werden, um das Gleichgewicht zwischen Genauigkeit und Rückruf zu steuern.
Klassifizierung (3 Kategorien und mehr)
Die Standardmetrik für mehrklassige Klassifizierung ist „Micro Accuracy“. Je näher „Mico Accuracy“ bei 100 % oder 1,0 liegt, desto besser ist das Modell.
Eine weitere wichtige Metrik für die mehrklassige Klassifizierung ist „Macro-accuracy“. Ähnlich wie bei „Micro-accuracy“ ist das Modell umso besser, je näher der Wert bei 1,0 liegt. Eine gute Möglichkeit, diese beiden Genauigkeitstypen zu unterscheiden:
- Micro-accuracy: Wie oft wird ein eingehendes Ticket dem richtigen Team zugeordnet?
- Macro-accuracy: Wie oft ist für ein durchschnittliches Team ein eingehendes Ticket das richtige Ticket für das Team?
Weitere Informationen zu Auswertungsmetriken
Weitere Informationen finden Sie unter Metriken für die Modellevaluierung.
Verbessern
Wenn Ihr Modellleistungswert nicht so gut ist, wie Sie es sich wünschen, haben Sie die folgenden Möglichkeit:
Längeres Trainieren. Je mehr Zeit einer automatisierten Machine Learning-Engine zum Trainieren zur Verfügung steht, desto mehr Algorithmen und Einstellungen kann sie ausprobieren.
Weitere Daten hinzufügen. Manchmal reicht die Datenmenge nicht aus, um ein hochwertiges Machine Learning-Modell zu trainieren. Dies gilt besonders für Datasets mit einer kleinen Anzahl von Beispielen.
Ihre Daten ausgleichen. Achten Sie bei Klassifizierungsaufgaben darauf, dass der Trainingssatz über die Kategorien hinweg gleichmäßig verteilt ist. Wenn Sie beispielsweise vier Klassen für 100 Trainingsbeispiele haben und die beiden ersten Klassen (tag1 und tag2) für 90 Datensätze verwendet werden, die anderen beiden (tag3 und tag4) aber nur für die restlichen 10 Datensätze, kann das dazu führen, dass Ihr Modell Schwierigkeiten hat, tag3 oder tag4 korrekt vorherzusagen, da die Daten nicht gleichmäßig verteilt sind.
Nutzen
Nach der Evaluierungsphase gibt der Modell-Generator eine Modelldatei und einen Code aus, mit dem Sie das Modell zur Ihrer Anwendung hinzufügen können. ML.NET-Modelle werden als Zip-Datei gespeichert. Der Code zum Laden und Verwenden Ihres Modells wird als neues Projekt in Ihrer Projektmappe hinzugefügt. Der Modell-Generator fügt auch eine Beispiel-Konsolen-App hinzu, die Sie ausführen können, um Ihr Modell in Aktion zu sehen.
Darüber hinaus bietet Model Builder Ihnen die Möglichkeit, Projekte zu erstellen, die Ihr Modell nutzen. Derzeit erstellt Model Builder die folgenden Projekte:
- Konsolen-App: Erstellt eine .NET-Konsolenanwendung, um Vorhersagen auf Grundlage Ihres Modells zu treffen
- Web-API: Erstellt eine ASP.NET Core-Web-API, mit der Sie Ihr Modell über das Internet nutzen können
Wie geht es weiter?
Installieren Sie die Model Builder-Erweiterung für Visual Studio.
Probieren Sie ein Szenario für die Preisvorhersage oder Regression aus.
Zusammenarbeit auf GitHub
Die Quelle für diesen Inhalt finden Sie auf GitHub, wo Sie auch Issues und Pull Requests erstellen und überprüfen können. Weitere Informationen finden Sie in unserem Leitfaden für Mitwirkende.