Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
Tipp
Dieser Inhalt ist ein Auszug aus dem eBook, Architect Modern Web Applications mit ASP.NET Core und Azure, verfügbar auf .NET Docs oder als kostenloses herunterladbares PDF, das offline gelesen werden kann.

"Wenn Bauarbeiter Gebäude gebaut haben, wie Programmierer Programme geschrieben haben, dann würde der erste Holzpecker, der kam, die Zivilisation zerstören."
- Gerald Weinberg
Sie sollten Softwarelösungen mit Blick auf die Wartbarkeit gestalten. Die in diesem Abschnitt beschriebenen Prinzipien können Sie bei architekturlichen Entscheidungen unterstützen, die zu sauberen, wartungsfähigen Anwendungen führen. Im Allgemeinen führen Sie diese Prinzipien dazu, Anwendungen aus separaten Komponenten zu erstellen, die nicht eng mit anderen Teilen Ihrer Anwendung gekoppelt sind, sondern über explizite Schnittstellen oder Messagingsysteme kommunizieren.
Allgemeine Designprinzipien
Trennung von Zuständigkeiten
Ein Leitprinzip bei der Entwicklung ist Trennung von Bedenken. Dieses Prinzip behauptet, dass Software auf der Grundlage der Art der von ihr durchgeführten Arbeit getrennt werden sollte. Betrachten Sie beispielsweise eine Anwendung, die Logik zum Identifizieren von würdigen Elementen enthält, die dem Benutzer angezeigt werden sollen, und welche Elemente auf eine bestimmte Weise formatiert werden, um sie spürbarer zu machen. Das Verhalten, das für die Auswahl der zu formatierenden Elemente verantwortlich ist, sollte vom Verhalten getrennt bleiben, das für die Formatierung der Elemente verantwortlich ist, da diese Verhaltensweisen separate Bedenken sind, die nur zufällig miteinander zusammenhängen.
Architekturell können Anwendungen logisch erstellt werden, um diesem Prinzip zu folgen, indem kernwirtschaftliches Verhalten von Infrastruktur und Benutzeroberflächenlogik getrennt wird. Im Idealfall sollten Sich Geschäftsregeln und Logik in einem separaten Projekt befinden, das nicht von anderen Projekten in der Anwendung abhängig sein sollte. Diese Trennung trägt dazu bei, dass das Geschäftsmodell einfach zu testen ist und sich weiterentwickeln kann, ohne eng mit Details zur Implementierung auf niedriger Ebene gekoppelt zu sein (es hilft auch, wenn Infrastrukturbedenken von in der Geschäftsebene definierten Abstraktionen abhängen). Die Trennung von Bedenken ist ein wichtiger Aspekt bei der Verwendung von Ebenen in Anwendungsarchitekturen.
Kapselung
Verschiedene Teile einer Anwendung sollten Kapselung verwenden, um sie von anderen Teilen der Anwendung zu isolieren . Anwendungskomponenten und Ebenen sollten ihre interne Implementierung anpassen können, ohne ihre Mitarbeiter zu unterbrechen, solange externe Verträge nicht verletzt werden. Die ordnungsgemäße Verwendung der Kapselung trägt dazu bei, lose Kopplung und Modularität in Anwendungsdesigns zu erreichen, da Objekte und Pakete durch alternative Implementierungen ersetzt werden können, solange dieselbe Schnittstelle beibehalten wird.
In Klassen wird die Kapselung erreicht, indem der externe Zugriff auf den internen Zustand der Klasse beschränkt wird. Wenn ein externer Akteur den Status des Objekts bearbeiten möchte, sollte dies über eine gut definierte Funktion (oder einen Eigenschaftensatzer) ausgeführt werden, anstatt direkten Zugriff auf den privaten Zustand des Objekts zu haben. Anwendungskomponenten und Anwendungen selbst müssen ebenso klar definierte Schnittstellen für die Verwendung durch ihre Komponenten vorweisen und nicht zulassen, dass ihr Zustand direkt geändert werden kann. Durch diesen Ansatz kann das interne Design der Anwendung über einen Zeitraum weiterentwickelt werden, ohne dass die Sorge besteht, dass durch diese Aktion Komponentenfehler auftreten, solange die öffentlichen Verträge bestehen.
Der mutierbare globale Zustand ist antithetisch für die Kapselung. Ein wert, der aus dem mutierbaren globalen Zustand in einer Funktion abgerufen wird, kann nicht darauf vertrauen, dass er denselben Wert in einer anderen Funktion hat (oder sogar weiter in derselben Funktion). Das Verständnis von Problemen mit dem veränderbaren globalen Zustand ist einer der Gründe, warum Programmiersprachen wie C# Unterstützung für unterschiedliche Bereichsregeln haben, die überall von Anweisungen bis hin zu Methoden zu Klassen verwendet werden. Es lohnt sich zu beachten, dass datengesteuerte Architekturen, die auf einer zentralen Datenbank für die Integration innerhalb und zwischen Anwendungen basieren, selbst entscheiden, von dem veränderbaren globalen Zustand abhängig zu sein, der durch die Datenbank dargestellt wird. Ein wichtiger Aspekt des domänengesteuerten Entwurfs und der sauberen Architektur besteht darin, den Zugriff auf Daten zu kapseln und sicherzustellen, dass der Anwendungsstatus nicht durch direkten Zugriff auf das Persistenzformat ungültig wird.
Abhängigkeitsumkehr
Die Richtung der Abhängigkeit innerhalb der Anwendung sollte in Richtung Abstraktion und nicht in Implementierungsdetails erfolgen. Die meisten Anwendungen werden so geschrieben, dass die Kompilierungszeitabhängigkeit in Richtung der Laufzeitausführung fließt und ein direktes Abhängigkeitsdiagramm erzeugt. Das heißt, wenn Klasse A eine Methode der Klasse B aufruft und Klasse B eine Methode von Klasse C aufruft, hängt die Klasse A zur Kompilierungszeit von Klasse B ab, und Klasse B hängt von Klasse C ab, wie in Abbildung 4-1 dargestellt.
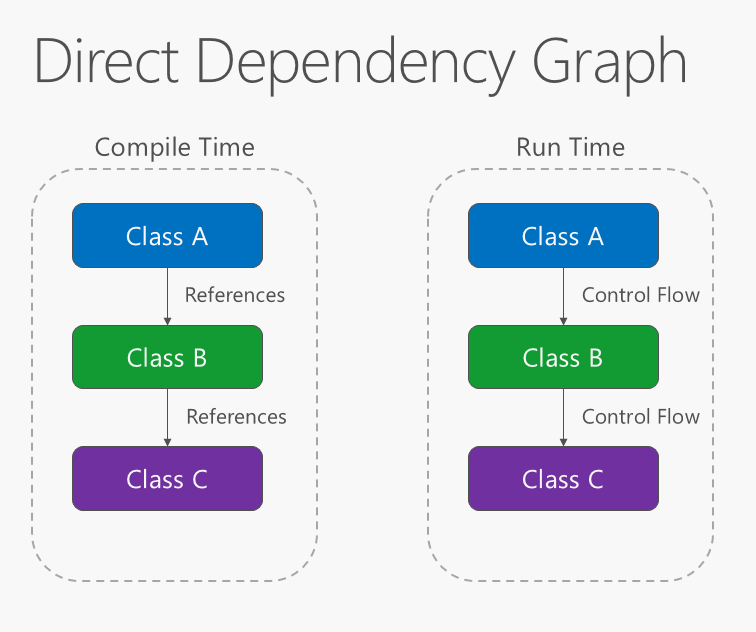
Abbildung 4-1. Direktes Abhängigkeitsdiagramm.
Das Anwenden des Abhängigkeitsinversionsprinzips ermöglicht es A, Methoden einer Abstraktion aufzurufen, die von B implementiert wurde, sodass A zur Laufzeit B aufrufen kann, während B zur Kompilierungszeit von einer Schnittstelle abhängt, die von A kontrolliert wird (wodurch die typische Kompilierungszeitabhängigkeit umgekehrt wird). Zur Laufzeit bleibt der Programmablauf unverändert, aber die Einführung von Schnittstellen bedeutet, dass unterschiedliche Implementierungen dieser Schnittstellen problemlos angeschlossen werden können.
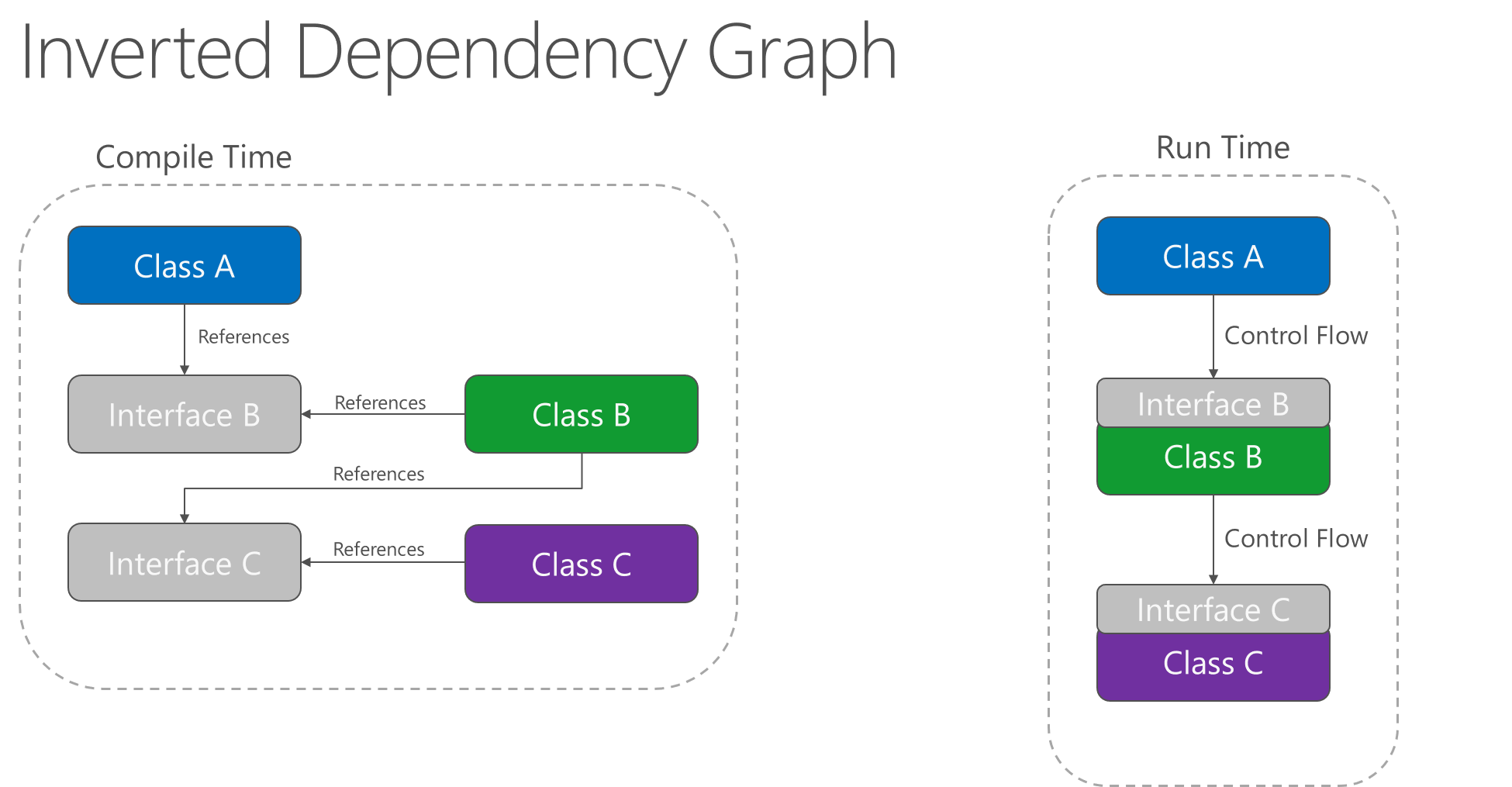
Abbildung 4-2. Invertiertes Abhängigkeitsdiagramm.
Abhängigkeitsinversion ist ein wesentlicher Bestandteil beim Erstellen lose gekoppelter Anwendungen, da Implementierungsdetails so geschrieben werden können, dass sie auf übergeordnete Abstraktionen angewiesen sind und diese implementieren, anstatt andersherum. Die resultierenden Anwendungen sind beprüfbarer, modularer und wartungsfähiger als Ergebnis. Die Praxis der Abhängigkeitsinjektion wird durch das Befolgen des Abhängigkeitsinversionsprinzips ermöglicht.
Explizite Abhängigkeiten
Methoden und Klassen sollten explizit alle benötigten Zusammenarbeitsobjekte erfordern, um ordnungsgemäß funktionieren zu können. Es wird als explizites Abhängigkeitsprinzip bezeichnet. Klassenkonstruktoren bieten die Möglichkeit, die benötigten Elemente zu identifizieren, um in einem gültigen Zustand zu sein und ordnungsgemäß zu funktionieren. Wenn Sie Klassen definieren, die erstellt und aufgerufen werden können, die jedoch nur ordnungsgemäß funktionieren, wenn bestimmte globale oder Infrastrukturkomponenten vorhanden sind, sind diese Klassen mit ihren Clients unehrlich . Der Konstruktorvertrag teilt dem Client mit, dass er nur die angegebenen Dinge benötigt (möglicherweise nichts, wenn die Klasse nur einen parameterlosen Konstruktor verwendet), aber zur Laufzeit stellt es heraus, dass das Objekt wirklich etwas anderes benötigt.
Indem Sie dem expliziten Abhängigkeitsprinzip folgen, sind Ihre Klassen und Methoden mit ihren Kunden ehrlich darüber, was sie benötigen, um funktionieren zu können. Indem Sie diesem Prinzip folgen, wird Ihr Code zu besser dokumentiertem Code und Ihre Codierungsverträge benutzerfreundlicher. Die Benutzer können darauf vertrauen, dass sich die Objekte, mit denen sie arbeiten, bei korrekter Angabe der erforderlichen Methoden- oder Konstruktorparameter zur Laufzeit ordnungsgemäß verhalten.
Einzelverantwortung
Das Prinzip der einzelverantwortlichen Verantwortung gilt für objektorientiertes Design, kann aber auch als architektonisches Prinzip betrachtet werden, das der Trennung von Anliegen ähnelt. Es gibt an, dass Objekte nur eine Verantwortung haben sollten und dass sie nur einen Grund haben sollten, sich zu ändern. Insbesondere ist die einzige Situation, in der sich das Objekt ändern sollte, wenn die Art und Weise, in der es seine Verantwortung ausführt, aktualisiert werden muss. Nach diesem Prinzip können mehr lose gekoppelte und modulare Systeme erzeugt werden, da viele Arten von neuem Verhalten als neue Klassen implementiert werden können, anstatt vorhandenen Klassen zusätzliche Verantwortung hinzuzufügen. Das Hinzufügen neuer Klassen ist immer sicherer als das Ändern vorhandener Klassen, da noch kein Code von den neuen Klassen abhängt.
In einer monolithischen Anwendung können wir das Prinzip der einzelverantwortlichen Verantwortung auf hoher Ebene auf die Schichten in der Anwendung anwenden. Die Präsentationsverantwortung sollte im UI-Projekt verbleiben, während die Datenzugriffsverantwortung innerhalb eines Infrastrukturprojekts beibehalten werden sollte. Geschäftslogik sollte im Anwendungskernprojekt beibehalten werden, wo sie einfach getestet werden kann und unabhängig von anderen Verantwortlichkeiten weiterentwickelt werden kann.
Wenn dieses Prinzip auf die Anwendungsarchitektur angewendet und auf den logischen Endpunkt angewendet wird, erhalten Sie Microservices. Ein gegebener Mikroservice sollte eine einzige Verantwortung haben. Wenn Sie das Verhalten eines Systems erweitern müssen, ist es in der Regel besser, indem Sie zusätzliche Microservices hinzufügen, anstatt die Verantwortung zu einem vorhandenen hinzuzufügen.
Weitere Informationen zur Microservices-Architektur
Wiederhole dich nicht (DRY)
Die Anwendung sollte vermeiden, verhalten im Zusammenhang mit einem bestimmten Konzept an mehreren Stellen anzugeben, da diese Übung eine häufige Fehlerquelle ist. Zu einem bestimmten Zeitpunkt erfordert eine Änderung der Anforderungen eine Änderung dieses Verhaltens. Es ist wahrscheinlich, dass mindestens eine Instanz des Verhaltens nicht aktualisiert wird, und das System verhält sich inkonsistent.
Anstatt Logik zu duplizieren, kapseln Sie sie in einem Programmierkonstrukt. Machen Sie dieses Konstrukt zur einzigen Autorität über dieses Verhalten, und lassen Sie jeden anderen Teil der Anwendung, der dieses Verhalten erfordert, das neue Konstrukt verwenden.
Hinweis
Vermeiden Sie das Zusammenführen von Verhaltensweisen, die sich nur zufällig wiederholen. Beispielsweise, weil zwei verschiedene Konstanten denselben Wert haben, bedeutet dies nicht, dass Sie nur eine Konstante haben sollten, wenn sie konzeptionell auf verschiedene Dinge verweisen. Duplizierung ist immer vorzuziehen gegenüber der Kopplung an die falsche Abstraktion.
Ignorieren der Persistenz
Persistenz-Unwissenheit (PI) bezieht sich auf Typen, die beibehalten werden müssen, deren Code jedoch von der Wahl der Persistenztechnologie nicht betroffen ist. Solche Typen in .NET werden manchmal als einfache alte CLR-Objekte (POCOs) bezeichnet, da sie nicht von einer bestimmten Basisklasse erben oder eine bestimmte Schnittstelle implementieren müssen. Persistenz-Unwissenheit ist wertvoll, da dasselbe Geschäftsmodell auf mehrere Arten beibehalten werden kann, was zusätzliche Flexibilität für die Anwendung bietet. Persistenzmöglichkeiten können sich im Laufe der Zeit ändern, von einer Datenbanktechnologie in eine andere oder zusätzliche Formen der Persistenz können zusätzlich zu dem benötigt werden, mit dem die Anwendung begonnen hat (z. B. die Verwendung eines Redis-Caches oder Azure Cosmos DB zusätzlich zu einer relationalen Datenbank).
Einige Beispiele für Verstöße gegen diesen Grundsatz sind:
Eine erforderliche Basisklasse.
Eine erforderliche Schnittstellenimplementierung.
Klassen, die für das Speichern selbst verantwortlich sind (z. B. das Active Record-Muster).
Erforderlicher parameterloser Konstruktor.
Eigenschaften, die ein virtuelles Schlüsselwort erfordern.
Persistenzspezifische erforderliche Attribute.
Die Anforderung, dass Klassen über eine der oben genannten Features oder Verhaltensweisen verfügen, fügt die Kopplung zwischen den zu speichernden Typen und der Wahl der Persistenztechnologie hinzu, wodurch es schwieriger wird, neue Datenzugriffsstrategien in zukunft einzuführen.
Gebundene Kontexte
Gebundene Kontexte sind ein zentrales Muster im Domain-Driven Design. Sie bieten eine Möglichkeit, die Komplexität in großen Anwendungen oder Organisationen zu bewältigen, indem sie sie in separate konzeptionelle Module aufteilen. Jedes konzeptionelle Modul stellt dann einen Kontext dar, der von anderen Kontexten (daher gebunden) getrennt ist und unabhängig voneinander weiterentwickelt werden kann. Jeder gebundene Kontext sollte idealerweise frei sein, eigene Namen für darin enthaltene Konzepte auszuwählen und exklusiven Zugriff auf seinen eigenen Persistenzspeicher zu haben.
Zumindest sollten einzelne Webanwendungen ihren eigenen abgegrenzten Kontext mit einem eigenen persistenten Speicher für ihr Geschäftsmodell haben, anstatt eine Datenbank gemeinsam mit anderen Anwendungen zu nutzen. Die Kommunikation zwischen gebundenen Kontexten erfolgt über programmgesteuerte Schnittstellen und nicht über eine freigegebene Datenbank, wodurch Geschäftslogik und Ereignisse als Reaktion auf änderungen stattfinden können. Gebundene Kontexte sind eng mit Mikroservices verbunden, die auch idealerweise als eigene, gebundene Kontexte implementiert werden.
Weitere Ressourcen
Zusammenarbeit auf GitHub
Die Quelle für diesen Inhalt finden Sie auf GitHub, wo Sie auch Issues und Pull Requests erstellen und überprüfen können. Weitere Informationen finden Sie in unserem Leitfaden für Mitwirkende.