Duplikate in jeder Tabelle entfernen, um die Daten zu vereinheitlichen
Der Schritt „Deduplizierungsregeln“ der Vereinheitlichung sucht und entfernt doppelte Datensätze für einen Kunden aus einer Quelltabelle, sodass die einzelnen Kunden bzw. Kundinnen in jeder Tabelle durch eine einzelne Zeile dargestellt werden. Jede Tabelle wird mithilfe von Regeln separat dedupliziert, um die Datensätze für einen bestimmten Kunden bzw. eine bestimmte Kundin zu identifizieren.
Die Regeln werden der Reihe nach verarbeitet. Nachdem alle Regeln für alle Datensätze in einer Tabelle ausgeführt wurden, werden Übereinstimmungsgruppen, die eine gemeinsame Zeile haben, zu einer einzigen Übereinstimmungsgruppe zusammengefasst.
Definieren von Deduplizierungsregeln
Eine gute Regel identifiziert einen eindeutigen Kunden bzw. eine eindeutige Kundin. Betrachten Sie Ihre Daten. Es kann ausreichen, die Kundschaft anhand eines Felds wie „E-Mail“ zu identifizieren. Wenn Sie jedoch einzelne Kunden bzw. Kundinnen unterscheiden möchten, die eine E-Mail-Adresse teilen, können Sie sich für eine Regel mit zwei Bedingungen entscheiden, nämlich für den Abgleich von „E-Mail“ + „FirstName“. Weitere Informationen finden Sie unter Deduplizierungskonzepte und -szenarien.
Wählen Sie auf der Seite Deduplizierungsregeln eine Tabelle aus und wählen Sie Regel hinzufügen, um die Deduplizierungsregeln zu definieren.
Tipp
Wenn Sie Tabellen auf der Ebene der Datenquelle angereichert haben, um Ihre Vereinheitlichungsergebnisse zu verbessern, wählen Sie oben auf der Seite Angereicherte Tabellen verwenden aus. Weitere Informationen finden Sie unter Anreicherungen für Datenquellen.
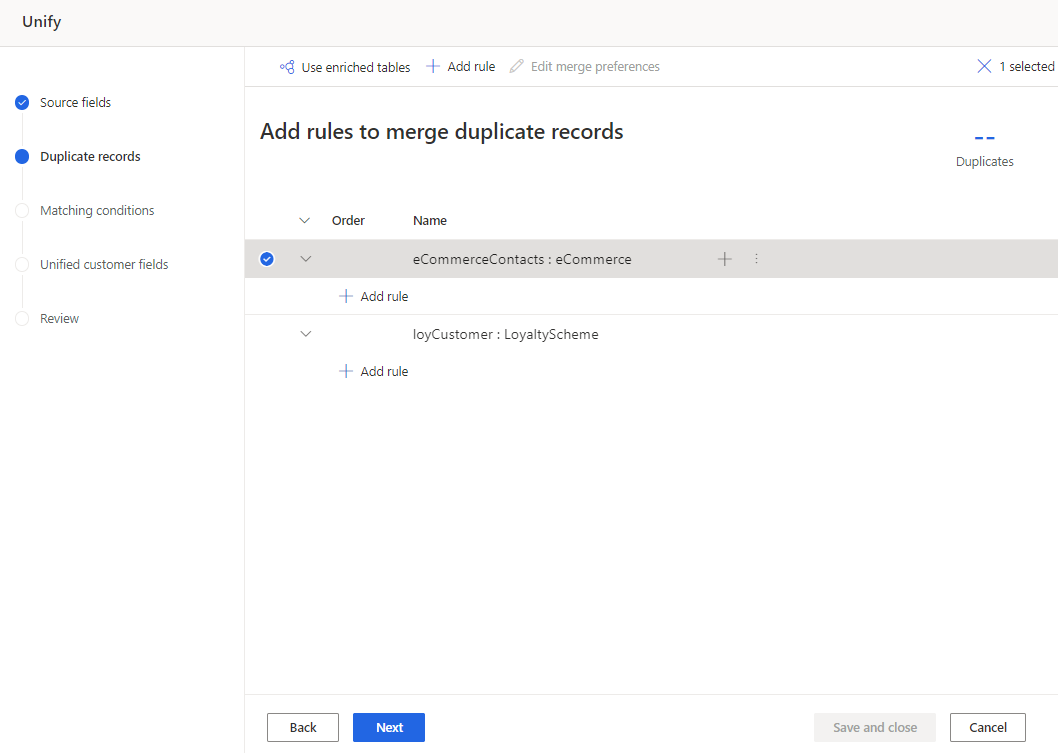
Geben Sie im Bereich Regel hinzufügen die folgenden Informationen ein:
- Feld auswählen: Wählen Sie aus der Liste der verfügbaren Felder der Tabelle aus, die Sie auf Duplikate prüfen möchten. Wählen Sie Felder aus, die wahrscheinlich für jeden einzelnen Kunden eindeutig sind. Zum Beispiel eine E-Mail-Adresse oder die Kombination aus Name, Stadt und Telefonnummer.
- Normalisieren: Wählen Sie aus den Normalisierungsoptionen für die Spalte aus. Die Normalisierung wirkt sich nur auf den Abgleichsschritt aus und verändert die Daten nicht.
- Ziffern: Konvertiert viele Unicode-Symbole, die Zahlen darstellen, in einfache Zahlen.
- Symbole: Entfernt viele gängige Symbole wie !„“#$%&‚‘()*+,-./:;<=>?@[]^_`{|}~. Zum Beispiel wird Head&Shoulder zu HeadShoulder.
- Text in Kleinbuchstaben: Konvertiert alle Zeichen in Kleinbuchstaben. „ALL CAPS und Erster Buchstabe groß“ wird zu „all caps und erster buchstabe groß.“
- Typ (Telefon, Name, Adresse, Organisation): Standardisiert Namen, Titel, Telefonnummern, Adressen usw.
- Unicode in ASCII: Konvertiert die Unicode-Zeichen in ihr ASCII-Äquivalent. Beispielsweise wird das akzentuierte „ề“ in das Zeichen „e“ umgewandelt.
- Leerzeichen: Entfernt alle Leerzeichen. Hallo Welt wird HalloWelt.
- Präzision: Hier können Sie die Ebene der Präzision festlegen. Präzision wird bei der Fuzzyübereinstimmung verwendet und bestimmt, wie nahe zwei Zeichenfolgen beieinander liegen müssen, um als Übereinstimmung zu gelten.
- Basic: Wählen Sie Niedrig (30 %%), Mittel (60 %%), Hoch (80 %%) und Genau (100 %%). Wählen Sie Genau, um nur Datensätze abzugleichen, die zu 100 Prozent übereinstimmen.
- Benutzerdefiniert: Legen Sie einen Prozentsatz fest, mit dem Datensätze übereinstimmen müssen. Das System stimmt nur mit Datensätzen überein, die diesen Schwellenwert überschreiten.
- Name: Der Name für die Regel.
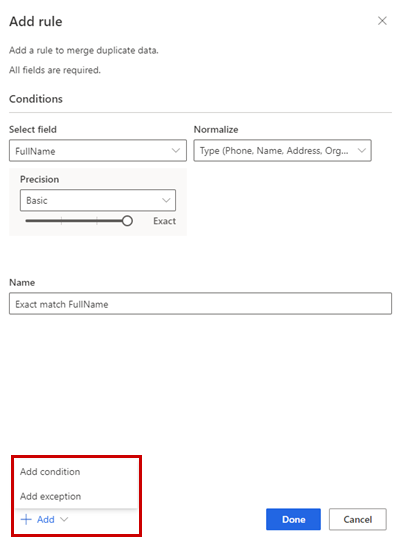
Wählen Sie optional Hinzufügen>Bedingung hinzufügen aus, um der Regel weitere Bedingungen hinzuzufügen. Bedingungen sind mit einem logischen UND-Operator verbunden und werden daher nur ausgeführt, wenn alle Bedingungen erfüllt sind.
Wählen Sie optional Hinzufügen>Ausnahme hinzufügen, um Ausnahmen zur Regel hinzuzufügen. Ausnahmen werden verwendet, um seltene Fälle von falsch positiven und falsch negativen Ergebnissen zu behandeln.
Wählen Sie Fertig, um die Regel zu erstellen.
Optional weitere Regeln hinzufügen.
Wählen Sie eine Tabelle und dann Einstellungen für die Zusammenführung bearbeiten.
Im Bereich Einstellungen für die Zusammenführunng:
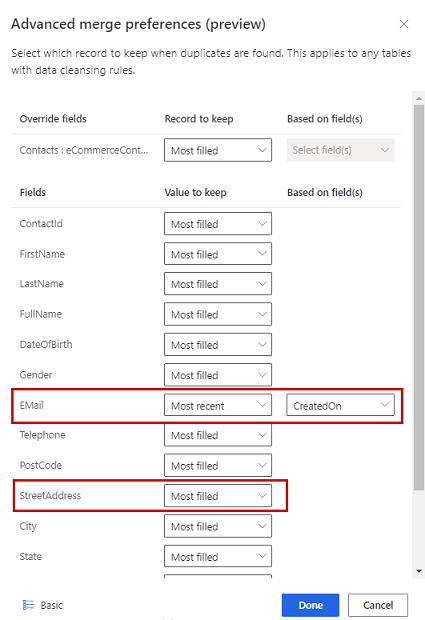
Wählen Sie eine von drei Optionen aus, um zu bestimmen, welcher Datensatz aufbewahrt werden soll, wenn ein Duplikat gefunden wird:
- Am häufigsten: Identifiziert den Datensatz mit den meisten ausgefüllten Spalten als Gewinner-Datensatz. Dies ist die standardmäßige Zusammenführungsoption.
- Aktuell: Identifiziert den Gewinner-Datensatz auf der Basis der größten Aktualität. Erfordert ein Datum oder ein numerisches Feld, um die Aktualität zu definieren.
- Letzer: Identifiziert den Gewinner-Datensatz basierend auf der besten Aktualität. Erfordert ein Datum oder ein numerisches Feld, um die Aktualität zu definieren.
Im Falle eines Unentschiedens ist der Gewinnerdatensatz derjenige mit dem MAX(PK)-Wert oder dem größeren Primärschlüsselwert.
Um optional Zusammenführungseinstellungen für einzelne Spalten einer Tabelle zu definieren, wählen Sie Erweitert am unteren Rand des Bereichs. Sie können beispielsweise wählen, ob Sie die neueste E-Mail UND die vollständigste Adresse aus verschiedenen Datensätzen behalten möchten. Erweitern Sie die Tabelle, um alle ihre Spalten anzuzeigen, und definieren Sie, welche Option für einzelne Spalten verwendet werden soll. Wenn Sie eine auf Aktualität basierende Option wählen, müssen Sie auch ein Datums-/Uhrzeitfeld angeben, das die Aktualität definiert.
Wählen Sie Fertig aus, um Ihre Einstellungen zusammenzuführen.
Nachdem Sie die Deduplizierungsregeln und Zusammenführungseinstellungen definiert haben, wählen Sie Weiter.
