Überblick über Datenimportaufträgen und Datenexportaufträgen
Um Datenimport- und Datenexporteinzelvorgänge zu erstellen und zu verwalten, verwenden Sie den Arbeitsbereich Datenverwaltung. Standardmäßig der Datenimport und der Exportvorgang eine für jede Stagingtabelle Entität in der Zieldatenbank erstellt. Mit Stagingtabellen können Sie Daten prüfen, bereinigen oder konvertieren, bevor Sie diese verschieben.
Notiz
Für diesen Artikel wird vorausgesetzt, dass Sie sich mit dem Thema Datenentitäten vertraut gemacht haben.
Prozess für Datenimport und -export
Nachfolgend sind die Schritte dargestellt, um Daten zu importieren oder zu exportieren.
Erstellen eines Import- oder Exportvorgangs, wo Sie die folgenden Aufgaben durchführen können:
- Projektkategorie definieren.
- Geben Sie die Entitäten an, um Daten zu importieren oder exportieren.
- Legen Sie das Datenformat für den Stapelverarbeitungsauftrag fest.
- Entitäten nummerieren, damit sie in logischen Gruppen sowie in einen Auftrag verarbeitet werden, der logisch ist.
- Hier legen Sie fest, ob Tabellen verwendet werden.
Überprüfen Sie, ob die Daten und die Zieldaten korrekt zugeordnet werden.
Überprüfen Sie die Sicherheit für den Export- oder Importvorgang.
Führt den Import- oder Exportvorgang aus.
Überprüfen Sie, ob der Einzelvorgang z erwartet ausgeführt wurde, da die Einzelvorgangshistorie hat.
Bereinigen der Tabellen.
Die verbleibenden Abschnitte dieses Artikels enthalten zusätzliche Informationen für jeden Schritt des Prozesses.
Schein
Um das Exportformular Datenimport/export zu aktualisieren um den aktuellen Status anzuzeigen, verwenden Sie das Formularaktualisierungssymbol. Die Aktualisierung des Browsers wird nicht empfohlen, da alle Import-/Exportaufträge unterbrochen werden, die nicht als Batch ausgeführt werden.
Erstellen eines Import- oder Exportvorgangs
Ein Datenimport- oder Exportvorgang kann einmal oder mehrmals ausgeführt werden.
Projektkategorie definieren
Es wird empfohlen, Zeit zu nehmen, um eine entsprechende Projektkategorie für den Import- oder Exportvorgang zu wählen. Projektkategorien können helfen, zugehörige Einzelvorgänge zu verwalten.
Geben Sie die Entitäten an, um Daten zu importieren oder zu exportieren.
Sie können bestimmte Entitäten einem Import- oder Exportvorgang hinzufügen oder eine Vorlage auswählen, die übernommen werden soll. Vorlagen füllen einen Einzelvorgang mit einer Liste von Entitäten aus. Die Option Vorlage anwenden ist verfügbar, wenn Sie dem Einzelvorgang einen Namen geben und den Einzelvorgang speichern.
Legen Sie das Datenformat für den Stapelverarbeitungsauftrag fest.
Wenn Sie eine Einheit auswählen, müssen Sie die Verpackungseinheiten das Format der Daten auswählen, die exportiert oder importiert werden. Sie legen Formate fest, indem Sie die Kachel Datenquelleneinstellung verwenden. Ein Quelldatenformat ist eine Kombination aus Typ, Dateiformat, Zeilentrennzeichen und Spaltentrennzeichen. Es gibt noch andere Attribute, aber diese sind die wichtigsten, die man verstehen sollte. In der folgenden Tabelle werden die gültigen Kombinationen aufgeführt.
| Dateiformat | Zeilen-/Spaltentrennzeichen | XML-Stil |
|---|---|---|
| Excel | Excel | -NA- |
| XML | -NA- | XML-Element XML-Attribut |
| Mit Trennzeichen, fest mit | Komma, Semikolon, Registerkarte, senkrechter Strich, Doppelpunkt | -NA- |
Schein
Es ist aber wichtig, den richtigen Wert für Zeilentrennzeichen, Spaltentrennzeichen und Textqualifizierer auszuwählen, wenn die Datei Format-Option auf Getrennt eingestellt ist. Stellen Sie sicher, dass Ihre Daten nicht das als Trennzeichen oder Qualifizierer verwendete Zeichen enthalten, da dies beim Import und Export zu Fehlern führen kann.
Notiz
Achten Sie bei XML-basierten Dateiformaten darauf, nur zulässige Zeichen zu verwenden. Weitere Informationen zu gültigen Zeichen finden Sie unter Gültige Zeichen in XML 1.0. XML 1.0 erlaubt keine Steuerzeichen mit Ausnahme von Tabulatoren, Wagenrückläufen und Zeilenvorschüben. Beispiele für unzulässige Zeichen sind eckige Klammern, geschweifte Klammern und umgekehrte Schrägstriche.
Um Daten zu importieren oder zu exportieren, verwenden Sie Unicode anstelle einer bestimmten Codepage. Dies trägt mit dazu bei, die konsistentesten Ergebnisse zu liefern, und verhindert, dass Datenverwaltungsaufträge fehlschlagen, weil sie Unicode-Zeichen enthalten. Die systemdefinierten Quelldatenformate, die Unicode verwenden, haben alle Unicode im Quellennamen. Das Unicode-Format wird angewendet, indem Sie eine Unicode-Codierung für ANSI-Codepage als Codepage in der Registerkarte Regionale Einstellungen auswählen. Wählen Sie eine der folgenden Codepages für Unicode:
| Codeseite | Anzeigename |
|---|---|
| 1200 | Unicode |
| 12000 | Unicode (UTF-32) |
| 12001 | Unicode (UTF-32 Big-Endian) |
| 1201 | Unicode (Big-Endian) |
| 65000 | Unicode (UTF-7) |
| 65001 | Unicode (UTF-8) |
Weitere Informatione zu Codepages finden Sie unter Codepage-Bezeichner.
Sequenz der Entitäten
Entitäten können in einer Datenvorlage in den Serverkonfigurationsdateien oder im Import- und Exporteinzelvorgang sequenziert werden. Wenn Sie einen Einzelvorgang ausführen, der mehr als eine Datenentität enthält, müssen Sie prüfen, ob die Datenentitäten ordnungsgemäß geordnet werden. Sie ordnen die Entitäten hauptsächlich so, dass Sie beliebige funktionalen Abhängigkeiten unter den Entitäten adressieren können. Wenn Entitäten keine funktionalen Abhängigkeiten haben, können Sie diese für Parallelimport oder Export planen.
Ausführungseinheiten, Ebenen und Nummernkreise
Die Ausführungseinheit, die Ebene in der Ausführungseinheit und die Sequenz der Entität helfen, die Reihenfolge der Daten zu steuern, die importiert oder exportiert werden.
- In jeder Ausführungseinheit werden Entitäten parallel verarbeitet.
- In jeder Ausführungseinheit werde Entitäten parallel verarbeitet, wenn sie dieselbe Ebene haben.
- Auf ejder Stufe werden Entitäten entsprechend der Sequenznummer in dieser Ebene verarbeitet.
- Nachdem eine Ebene verarbeitet wurde, wird die nächste verarbeitet.
Neue Reihenfolge
Möglicherweise empfiehlt es sich, die Entitäten in den folgenden Situationen neu zu ordnen:
- Wenn nur ein Datenenvorgang für alle Änderungen verwendet wird, können Sie die Optionen neu verwenden, um die Ausführungszeit des vollständigen Einzelvorgang zu optimieren. In diesen Fällen kann die Ausführungseinheit verwendet werden, um das Modul darzustellen, die Schichten im Funktionsbereich im Modul anzugeben und den Nummernkreis der zu zeigen. Wenn Sie diesen Ansatz verwenden, können Sie in allen Modulen parallel arbeiten, aber trotzdem in der Sequenz in einem Modul arbeiten. Zur Sicherstellung einer korrekten Erfassung , dass parallele Arbeitsgänge erfolgreich sind, müssen Sie alle Abhängigkeiten berücksichtigt.
- Wenn mehrere Dateneneinzelvorgänge, (beispielsweise ein Einzelvorgang für jedes Modul) verwendet werden, können Sie Abfolgen verenden, um die Ebene und den Nummernkreis von Entitäten für optimale Ausführung zu gewährleisten.
- Wenn es keine vorhanden Abhängigkeiten gibt, können Sie Nummernkreisentitäten an verschiedenen Ausführungseinheiten für maximale Optimierungsaufgaben definieren.
Das Menü Neu Sequenzen ist nur verfügbar, wenn mehrere Entitäten ausgewählt werden. Sie können neue Sequenzen basierend auf Grundlage der Ausführungseinheit, der Ebene oder der Nummernkreisoptionen definieren. Sie können ein Inkrement zur neuen Sequenzierung der Entität festlegen, die ausgewählt wurden. Die Einheit, die Ebene und/oder eine laufende Nummer, die für jede Entität ausgewählt ist, wird durch das angegebene Inkrement aktualisiert.
Sortieren
Sie können die Option Sortieren nach verwenden, um die Entitätsliste in sequenzieller Reihenfolge anzuzeigen.
Kürzen
Bei Importprojekten können Sie Datensätze in den Entitäten vor dem Import kürzen. Kürzen ist nützlich, wenn Ihre Datensätze in einen leeren Satz Tabellen importiert werden müssen. Diese Einstellung ist standardmäßig ausgeschaltet.
Überprüfen Sie, ob die Daten und die Zieldaten korrekt zugeordnet werden.
Zuordnung ist eine Funktion, die Importe und Exporteinzelvorgänge gilt.
- Im Kontext eines Importeinzelvorgangs beschreibt die Zuordnung, welche Spalten in der Quelldatei zu den Spalten in der Stagingtabelle werden. Daher kann das System bestimmen, welche Spaltendaten in der Quelldatei in welche Spalte Stagingtabelle kopiert werden müssen.
- Im Kontext eines Importeinzelvorgangs beschreibt die Zuordnung, welche Spalten in der Quelldatei zu den Spalten in der Stagingtabelle werden.
Wenn die Spaltennamen in der Stagingtabelle und die Datei übereinstimmen, erstellt das System automatisch die Zuordnung basierend auf den Namen. Wenn die Namen unterschiedlich sind, werden die Spalten nicht automatisch zugeordnet. In diesem Fall müssen Sie die Verknüpfung abschließen, indem Sie die Option Ansichtszuordnung für die Entität im Dateneneinzelvorgang auswählen.
Es gibt zwei zuzuordnende Ansichten: Zuordnungsvisualisierung, das die Standardansicht ist, und Zuordnungsdetails. Ein rotes Sternchen (*) kennzeichnet alle Pflichtfelder in der Entität. Diese Felder müssen zugeordnet werden, damit die Entität arbeiten können. Sie können andere Felder nach Bedarf trennen, wenn Sie mit Entitäten arbeiten. Wenn Sie Felder trennen, wählen Sie entweder die Spalte Entität oder die Spalte Quelle aus und anschließend Auswahl löschen. Klicken Sie auf Speichern um die Änderungen zu speichern und zur Listenseite Projekte zurückzukehren. Sie können den gleichen Prozess verwenden, um Feldzuordnung von der Quelle zum Bereitstellen zu bearbeiten, nachdem Sie Ihren Import ausgeführt haben.
Sie können auf der Seite eine Zuordnung generieren, indem Sie Generieren Sie Quellzuordnung auswählen. Eine generierte Zuordnung verhält sich wie eine automatische Zuordnung. Daher müssen Sie alle nicht zugeordneten Felder manuell zuordnen.
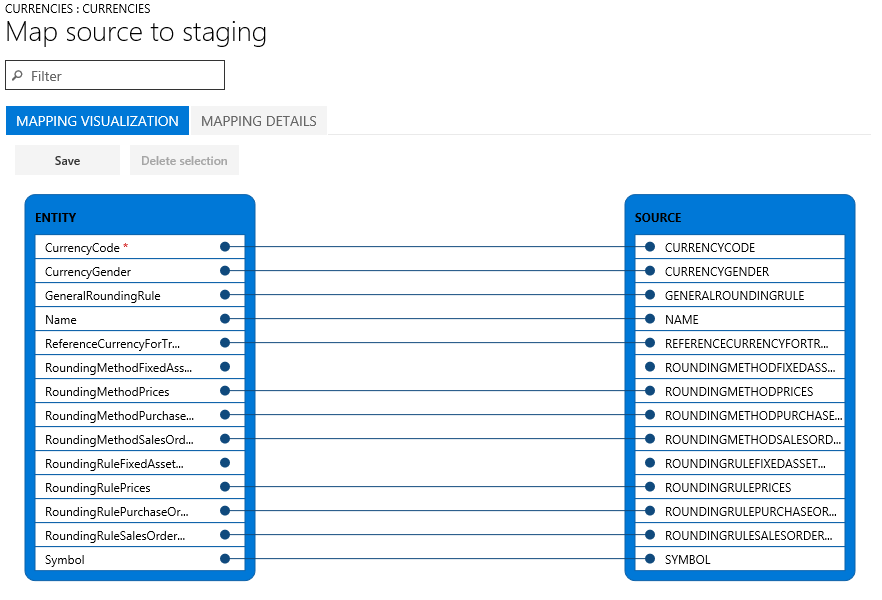
Überprüfen Sie die Sicherheit für den Export- oder Importvorgang.
Der Zugriff auf den Arbeitsbereich Datenverwaltung kann eingeschränkt werden, damit Benutzer nur auf Benutzer ohne Administratorroollen zugreifen können. Der Zugriff auf einen Dateneneinzelvorgang bedeutet Zugriff auf die Ausführungshistorie dieses Einzelvorgangs und Zugriff auf die Tabellen. Daher müssen Sie prüfen, ob übereinstimmende Zugriffssteuerungen vorhanden sind, wenn Sie einen Dateneneinzelvorgang erstellen.
Sichern Sie einen Einzelvorgang nach Rollen und Benutzer
Verwenden Sie das Menü Anwendbare Rollen, um den Einzelvorgang für mindestens eine Sicherheitsrolle einzuschränken. Nur Benutzer mit diesen Rollen haben Zugriff auf den Einzelvorgang.
Darüber hinaus können Sie einen Auftrag für bestimmte Benutzer einschränken. Wenn Sie einen Einzelvorgang nach Benutzer und nicht nach Rollen speichern, gibt es weitere Steuerelemente, falls mehrere Benutzer einer Rolle zugewiesen sind.
Einen Einzelvorgang nach juristischer Person schützen
Dateneneinzelvorgänge sind global. Wenn ein Dateneneinzelvorgang erstellt wurde und in einer juristischen Person ist, wird der Einzelvorgang in anderen juristischen Personen im System angezeigt. Dieses Standardverhalten kann in einigen Anwendungsszenarien bevorzugt werden. So kann eine Organisation, die Rechnungen importiert, indem Sie Datenentitäten verwendet, ein zentralisiertes Fakturierungsteam bereitstellen, das zur Verwaltung von Rechnungsfehlern für alle Geschäftsbereiche in der Organisation verantwortlich ist. In diesem Szenario ist es hilfreich für das zentralisierte Fakturierungsteam, den Zugriff auf die Rechnungsimporteinzelvorgängen von allen juristischen Personen verwendet werden. Daher entspricht das Standardverhalten der Bedingung aus einer Perspektive der juristischen Person.
Allerdings sollte eine Organisation Fakturierungsteams pro juristische Personen enthalten. In diesem Fall sollte ein Team in einer juristischen Personen nur Zugriff auf Rechnungsimporteinzelvorgang in der eigenen juristischen Personen enthalten. Um dieser Bedingung zu entsprechen, können Sie Entität-basierte gültige Zugriffssteuerung auf den Dateneneinzelvorgängen konfigurieren indem Sie Anwendbare juristische Personen im Dateneneinzelvorgangs verwenden. Nachdem die Konfiguration erfolgt ist, können Benutzer nur Stellen anzeigen, die für die juristische Person verfügbar sind, bei dem sie derzeit angemeldet sind. Um Einzelvorgänge einer anderen juristischen Person zu finden, müssen Benutzer diese juristische Person verwendet.
Einer Stelle kann durch Rollen, Benutzer und juristischen Person gleichzeitig geschützt werden.
Führt den Import- oder Exportvorgang aus
Sie können einen Einzelvorgang gleichzeitig aktivieren, indem Sie Importieren Exportieren auswählen, nachdem Sie den Einzelvorgang definiert haben. Um einen sich wiederholenden Auftrag einzurichten, wählen Sie Erstellen eines sich wiederholenden Dateneneinzelvorgangs aus.
Notiz
Ein Import- oder Exportvorgang kann ausgeführt werden, indem Sie die Schalfläche Importieren bzw. Exportieren auswählen. Diese Aktion plant einen Batchauftrag so, dass er nur einmal ausgeführt wird. Der Einzelvorgang wird möglicherweise nicht sofort ausgeführt, wenn der Batchservice aufgrund der Belastung des Batchservice gedrosselt wird. Die Einzelvorgänge können durch Auswahl von Jetzt importieren oder Jetzt exportieren synchron ausgeführt werden. Dadurch wird der Einzelvorgang sofort gestartet. Das ist hilfreich, wenn der Batchauftrag aufgrund einer Drosselung nicht startet. Die Einzelvorgänge können auch so geplant werden, dass sie zu einem späteren Zeitpunkt ausgeführt werden. Dies kann durch Auswahl der Option Im Batch ausführen erfolgen. Stapelressoucen sind von Drosselung betroffen. Der Einzelvorgang zur Stapelverarbeitung startet also möglicherweise nicht sofort. Die Verwendung eines Batch wird empfohlen, da dies auch bei großen Datenmengen hilfreich ist, die importiert oder exportiert werden müssen. Chargensaufträge können geplant wurden, sodass sie in einer bestimmte Chargengruppe ausgeführt werden. Dies bietet von einer Lastenausgleichsperspektive aus betrachtet eine bessere Steuerung.
Überprüfen Sie, ob der Einzelvorgang wie erwartet ausgeführt wurde
Die Einzelvorgangshistorie ist zur Problembehebung und Untersuchung auf Import- und Exporteinzelvorgängen verfügbar. Historische Einzelvorgangsausführungen werden nach Perioden sortiert.
Jede Einzelvorgangsausführung enthält die folgenden Details:
- Ausführungsdetails
- Ausführungsprotokoll
Ausführungsdetails zeigt den Status der einzelnen Datenentitäten an, die den Einzelvorgang verarbeitet. Daher können Sie die folgenden Informationen schnell suchen:
- Die Entitäten, die verarbeitet wurden.
- Für eine Entität, wie viele Datensätze erfolgreich verarbeitet wurden und wie viele nicht erfolgreich waren
- Die Stagingdatensätze für jede Entität
Sie können die Stagingdaten in Einzelvorgängen einer Datei für den Export herunterladen, oder Sie können sie als Paket für Import- und Exporteinzelvorgänge herunterladen.
Aus den Ausführungsdetails können Sie auch das Ausführungsprotokoll öffnen.
Parallelimporte
Um den Import von Daten zu beschleunigen, kann die parallele Verarbeitung des Imports einer Datei aktiviert werden, wenn die Entität parallele Importe unterstützt. Um den Parallelimport für eine Entität zu konfigurieren, müssen die folgenden Schritte ausgeführt werden.
Wechseln Sie zu Systemverwaltung > Arbeitsbereiche > Datenverwaltung.
Im Abschnitt Import/Export wählen Sie die Kachel Frameworkparameter zum Öffnen der Seite Rahmenparameter für Datenimport/-export.
Auf der Registerkarte Entitätseinstellungen wählen Sie Entitätsausführungsparameter konfigurieren, um die Seite Ausführungsparameter für den Entitätsimport zu öffnen.
Legen Sie die folgenden Felder fest, um den Parallelimport für eine Entität zu konfigurieren:
- Wählen Sie im Feld Entität aus, die Entität aus. Wenn das Entitätsfeld leer ist, wird der leere Wert als Standardeinstellung für alle nachfolgenden Importe verwendet, sofern die Entität den Parallelimport unterstützt.
- Geben Sie im Feld Importschwellenwert für Datensatzanzahl die Anzahl der Schwellenwerte für den Import ein. Dies bestimmt die Anzahl der Datensätze, die von einem Thread verarbeitet werden sollen. Wenn eine Datei 10 KB an Datensätzen enthält, bedeutet eine Datensatzanzahl von 2.500 mit einer Aufgabenanzahl von vier, dass jede Diskussion 2.500 Datensätze verarbeitet.
- Im Feld Aufgabenanzahl importieren geben Sie die Anzahl der Importaufgaben ein. Diese Zählung darf die maximale Anzahl von Batch-Threads nicht überschreiten, die für die Chargenverarbeitung in Systemadministration >Serverkonfiguration zugewiesen sind.
Hinweis
Werden zu viele parallele Aufgaben hinzufügt, führt dies dazu, dass die zugrunde liegende Infrastruktur die Ressourcenkapazität zu 100 % nutzt und die Leistung der Umgebung und anderen Vorgänge beeinträchtigt. Es wird empfohlen, dass Sie die Ressourcenkapazität der Umgebung und den Verbrauch basierend auf den konfigurierten parallelen Importvorgängen verstehen und die Anzahl der Aufgaben begrenzen.
Bereinigung des Auftragsverlaufs
Standardmäßig werden Auftragsverlaufseinträge und zugehörige Staging-Tabellendaten, die älter als 90 Tage sind, automatisch gelöscht. Mithilfe der Funktion zur Bereinigung des Einzelvorgangsverlaufs in der Datenverwaltung kann eine regelmäßige Bereinigung des Ausführungsverlaufs mit einer kürzeren Aufbewahrungsfrist als dieser Standardeinstellung konfiguriert werden. Diese Funktion ersetzt die vorherige Bereinigungsfunktion für Stagingtabellen, die ab sofort nicht mehr bereitgestellt wird. Die folgenden Tabellen werden durch den Bereinigungsprozess bereinigt.
Alle Stagingtabellen
DMFSTAGINGVALIDATIONLOG
DMFSTAGINGEXECUTIONERRORS
DMFSTAGINGLOGDETAIL
DMFSTAGINGLOG
DMFDEFINITIONGROUPEXECUTIONHISTORY
DMFEXECUTION
DMFDEFINITIONGROUPEXECUTION
Der Zugriff auf die Funktion Bereinigung des Ausführungsverlaufs erfolgt über Datenverwaltung > Bereinigung des Einzelauftragsverlaufs.
Planungsparameter
Wenn Sie den Bereinigungsprozess planen, müssen die folgenden Parameter angegeben werden, um die Bereinigungskriterien zu definieren.
Anzahl der Tage zur Beibehaltung des Verlaufs – Diese Einstellung wird verwendet, um den Umfang des beizubehaltenden Ausführungsverlaufs zu steuern. Der Verlauf vird in Anzahl Tagen angegeben. Wenn der Bereinigungsauftrag als wiederkehrender Batchauftrag geplant wird, funktioniert diese Einstellung wie ein sich fortlaufend bewegendes Fenster. Das heißt, der Verlauf bleibt für die angegebene Anzahl von Tagen unverändert, während der Rest gelöscht wird. Der Standardwert ist sieben Tage.
Anzahl der Stunden für die Ausführung des Auftrags: Je nach Umfang des zu bereinigenden Verlaufs kann die gesamte Ausführungszeit für den Bereinigungsauftrag von wenigen Minuten bis zu ein paar Stunden variieren. Dieser Parameter muss auf die Anzahl der Stunden eingestellt werden, die der Auftrag ausführt. Nachdem der Bereinigungsauftrag für die angegebene Anzahl von Stunden ausgeführt wurde, wird der Auftrag beendet und bei der nächsten Ausführung auf der Grundlage des Wiederholungszeitplans wieder aufgenommen.
Eine maximale Ausführungszeit kann durch Festlegen eines Höchstlimits für die Anzahl der Stunden angegeben werden, die der Auftrag unter Verwendung dieser Einstellung ausgeführt werden muss. Die Bereinigungslogik geht chronologisch eine Auftragsausführungskennung nach der anderen durch. Dabei wird die älteste bei der Bereinigung des entsprechenden Ausführungsverlaufs zuerst berücksichtigt. Sie endet dann mit der Verarbeitung neuer Ausführungskennungen für die Bereinigung, wenn die verbleibende Ausführungsdauer innerhalb der letzten 10 % des angegebenen Zeitraums liegt. In einigen Fällen wird der Bereinigungsauftrag über die angegebene Höchstzeit fortgesetzt. Diese Dauer hängt weitgehend von der Anzahl der Datensätze ab, die für die aktuelle Ausführungskennung gelöscht werden müssen, die gestartet wurde, bevor der Schwellenwert von 10 % erreicht wurde. Die Bereinigung, die gestartet wurde, muss abgeschlossen werden, um die Datenintegrität sicherzustellen. Dies bedeutet dann, dass die Bereinigung auch dann fortgesetzt wird, denn das angegebene Limit überschritten wurde. Wenn der Vorgang abgeschlossen ist, werden keine neuen Ausführungskennungen verarbeitet und der Bereinigungsauftrag wird danach abgeschlossen. Der verbleibende Ausführungsverlauf, der aufgrund unzureichender Ausführungszeit nicht bereinigt wurde, wird das nächste Mal verarbeitet, wenn der Bereinigungsauftrag eingeplant ist. Der Standard- und Mindestwert für diese Einstellung ist 2 Stunden.
Wiederkehrender Batch: Der Bereinigungsauftrag kann als einmalige, manuelle Ausführung ausgeführt oder für eine wiederkehrende Ausführung im Batch eingeplant werden. Der Stapel kann mithilfe der Einstellungen Im Hintergrund ausführen geplant werden. Dabei handelt es sich um die Standardstapeleinstellung.
Schein
Wenn die Funktion zum Bereinigen des Jobverlaufs nicht verwendet wird, wird der Ausführungsverlauf, der älter als 90 Tage ist, weiterhin automatisch gelöscht. Zusätzlich zu dieser automatischen Löschung kann eine Bereinigung des Auftragsverlaufs ausgeführt werden. Stellen Sie sicher, dass der Bereinigungsauftrag so geplant ist, dass er wiederholt ausgeführt wird. Wie oben erläutert, bereinigt der Auftrag bei jeder Bereinigungsausführung nur so viele Ausführungskennungen, wie in den vorgegebenen maximalen Stunden möglich.
Bereinigung und Archivierung des Einzelvorgangsverlaufs
Die Funktionen zum Bereinigen und Archivieren des Einzelvorgangsverlaufs ersetzen die vorherigen Versionen der Bereinigungsfunktion. In diesem Abschnitt werden diese neuen Funktionen erklärt.
Eine der wichtigsten Änderungen an der Bereinigungsfunktion ist die Verwendung des System-Batchauftrags zum Bereinigen des Verlaufs. Die Verwendung des System Batch-Auftrags lässt zu, dass die Finanz- und Betriebs-App den Batch-Auftrag für die Bereinigung automatisch planen und ausführen lässt, sobald das System bereit ist. Es ist nicht mehr erforderlich, den Batchauftrag manuell zu planen. In diesem Standardausführungsmodus wird der Batchauftrag ab Mitternacht jede Stunde ausgeführt und der Ausführungsverlauf für die letzten sieben Tage beibehalten. Der gelöschte Verlauf wird für den zukünftigen Abruf archiviert. Ab Version 10.0.20 ist diese Funktion immer aktiviert.
Die zweite Änderung am Bereinigungsprozess ist die Archivierung des gelöschten Ausführungsverlaufs. Der Bereinigungsauftrag archiviert die gelöschten Datensätze im Blob Storage, den DIXF für regelmäßige Integrationen verwendet. Die archivierte Datei liegt im DIXF-Paketformat vor und ist sieben Tage lang im Blob verfügbar. Während dieser Zeit kann sie heruntergeladen werden. Die Standardlebensdauer von sieben Tagen für die archivierte Datei kann in den Parametern auf maximal 90 Tage geändert werden.
Standardeinstellungen ändern
Diese Funktion ist derzeit in der Vorschau verfügbar und muss explizit aktiviert werden, indem der Flight DMFEnableExecutionHistoryCleanupSystemJob aktiviert wird. Die Funktion zur Stagingbereinigung muss ebenfalls in der Funktionsverwaltung aktiviert sein.
Um die Standardeinstellung für die Langlebigkeit der archivierten Datei zu ändern, wechseln Sie zum Datenverwaltungsarbeitsbereich und wählen Sie Bereinigung des Auftragsverlaufs aus. Legen Sie Tage zur Beibehaltung des Pakets im Blob auf einen Wert zwischen 7 und 90 (inklusive) fest. Diese Änderung tritt für die Archive in Kraft, die nach dieser Änderung erstellt werden.
Archiviertes Paket herunterladen
Diese Funktion ist derzeit in der Vorschau verfügbar und muss explizit aktiviert werden, indem der Flight DMFEnableExecutionHistoryCleanupSystemJob aktiviert wird. Die Funktion zur Stagingbereinigung muss ebenfalls in der Funktionsverwaltung aktiviert sein.
Um den archivierten Ausführungsverlauf herunterzuladen, wechseln Sie zum Datenverwaltungsarbeitsbereich und wählen Sie Bereinigung des Auftragsverlaufs aus. Wählen Sie Verlauf Paketsicherung aus, um das Verlaufsformular zu öffnen. Dieses Formular zeigt die Liste aller archivierten Pakete an. Ein Archiv kann durch Auswahl von Paket herunterladen ausgewählt und heruntergeladen werden. Das heruntergeladene Paket liegt im DIXF-Paketformat vor und enthält die folgenden Dateien:
- Die Stagingtabellendatei der Entität
- DMFDEFINITIONGROUPEXECUTION
- DMFDEFINITIONGROUPEXECUTIONHISTORY
- DMFEXECUTION
- DMFSTAGINGEXECUTIONERRORS
- DMFSTAGINGLOG
- DMFSTAGINGLOGDETAILS
- DMFSTAGINGVALIDATIONLOG
Zusammengesetzte Entitätsdaten mit XSLT sortieren
Mit dieser Funktion können Sie eine zusammengesetzte Entität exportieren und eine XSLT-Datei anwenden, um die Daten in der XML-Datei zu sortieren.
Um zusammengesetzte Entitätsdaten mit XSLT zu sortieren, gehen Sie wie folgt vor.
- Erstellen Sie eine XSLT-Datei, um die Daten im XML-Format zu sortieren. Wenn Sie beispielsweise eine XSLT-Datei für die sofort einsatzbereite Entität „Zusammengesetzte Bestellungen V3“ haben, können Sie die Daten im XML-Attributformat für PURCHPURCHASEORDERHEADERV2ENTITY nach INVOICEVENDORACCOUNTNUMBER und für PURCHPURCHASEORDERLINEV2ENTITY nach LINENUMBER sortieren.
<xsl:stylesheet version='1.0' xmlns:xsl="http://www.w3.org/1999/XSL/Transform">
<xsl:template match="/*">
<xsl:copy>
<xsl:apply-templates select="@*" />
<xsl:apply-templates>
<xsl:sort select="@INVOICEVENDORACCOUNTNUMBER" data-type="text" order="ascending" />
</xsl:apply-templates>
</xsl:copy>
</xsl:template>
<xsl:template match="PURCHPURCHASEORDERHEADERV2ENTITY">
<xsl:copy>
<xsl:apply-templates select="@*"/>
<xsl:apply-templates select="*">
<xsl:sort select="@LINENUMBER" data-type="number" order="descending"/>
</xsl:apply-templates>
</xsl:copy>
</xsl:template>
<xsl:template match="@*|node()">
<xsl:copy>
<xsl:apply-templates select="@*|node()"/>
</xsl:copy>
</xsl:template>
</xsl:stylesheet>
- Gehen Sie zum Arbeitsbereich Datenverwaltung.
- Wählen Sie aus der Liste der Datenexportprojekte ein Projekt mit XML-Datenquelle und dann Zuordnung anzeigen aus.
- Wählen Sie Zuordnung anzeigen für jede Entität aus.
- Gehen Sie zur Registerkarte Transformationen
- Wählen Sie Neu aus und laden Sie die in Schritt 1 erstellte XSLT-Datei hoch.