Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
Übersicht
Rebuffering ist die north-star von Microsoft eCDN, um die Qualität der Zuschauererfahrung zu beurteilen.
Definition
"Rebuffering" ist definiert als eine beliebige Zeitspanne, während der ein Zuschauer mit stillem oder keinem Video puffert. Sie wird pro Einzelperson als Prozentsatz der gesamten Sitzungszeit berechnet: Pufferzeit / (Wiedergabezeit + Pufferzeit). Das Aggregat der Zurückweisung aller Benutzer wird gemittelt und in den Analysedashboards pro Ereignis angezeigt und für den ausgewählten Zeitbereich im Rebuffering-Widget gemittelt.
Was ist eine schlechte Wiedergeburt?
Drei Prozent oder höher gelten als schlechte Erfahrung.
| Bereich | Farbcodierung | Bestimmung |
|---|---|---|
| >3% | Rot | Wir betrachten mehr als drei Prozent als schlechte Erfahrung, die eine Untersuchung rechtfertigen, wenn eine erhebliche Benutzerbasis vertreten ist. |
| <3% und >1% |
Gelb | Kann von herabgestuft zu beunruhigend betrachtet werden. Wir stellen fest, dass der gelbe Bereich in der Regel nur am höheren Ende des Bereichs und nur dann, wenn eine große oder konzentrierte Gruppe betroffen ist, ein Grund zur Sorge ist. |
| <1% | Grün | Wird als gute Erfahrung angesehen. Im Gesamten Kundenstamm von Microsoft eCDN wird häufig deutlich unter 1 % zurückgesetzt. |
Verwenden der Wiederzurückweisung für die Problembehandlung
Microsoft eCDN bietet detaillierte Benutzererfahrungsmetriken, z. B. "Wiedererkennen", die verwendet werden können, um Berichte über eine schlechte Benutzererfahrung zu bestätigen und den Umfang der betroffenen Zuschauer zu bestimmen. Es kann auch verwendet werden, um Schwachstellen in der Netzwerkumgebung hervorzuheben, insbesondere beim Ausführen von Auslastungstests mit unbeaufsichtigten Tests.
Im Folgenden finden Sie Szenarien, in denen die Wiedergeburt eine nützliche Metrik sein kann.
Ermitteln des Alters des Problems
Ein häufiger erster Schritt bei der Problembehandlung ist das Ermitteln des Alters eines Problems. Durch den Vergleich des Prozentsatzes der Zurückweisung des Ereignisses mit früheren Ereignissen kann ein unterschiedliches Muster in einem Zeitbereich erkannt werden. Fragen, die Sie stellen müssen, können...
- Wird diese Abfuhr auch bei früheren Ereignissen beobachtet oder ist sie nicht persistent?
- Ist dies ein neues Ereignis?
- Wenn dies der Fall ist, hat sich die Subnetzzuordnung oder Netzwerkkonfiguration seit dem letzten Ereignis mit guter Umgestaltung geändert. Wenn ja, was?
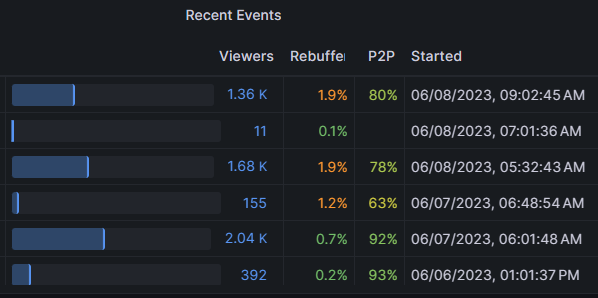
Beispiel für ein potenzielles persistentes Problem
In diesem Screenshot beobachten wir ein plausibles konsistentes Problem, das an einem bestimmten Datum mit größeren Ereignissen beginnt. Abgesehen von der Ereignisgröße empfiehlt es sich, andere mögliche gemeinsame Merkmale zu beobachten, z. B. ISP oder Subnetzgruppe.
Beispiel für ein einzelnes Ereignis mit hoher Wiedergeburt
In diesem Screenshot stellen wir fest, dass die hohe Zurückweisung für das größte Ereignis ein neues Problem ist, das in früheren Ereignissen nicht vorhanden war. Eine gute Frage, die sie hier stellen sollten, ist, ob schlechte Wiedergeburten in der Zuschauerbasis erlebt wurden oder sich irgendwo konzentrierten.
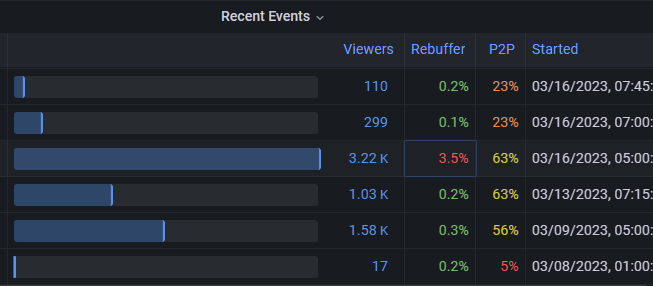
Wir stellen auch fest, dass nachfolgende kleinere Ereignisse in Ordnung sind, sodass es fair ist anzunehmen, dass die Ursache ein eindeutiges Merkmal des Ereignisses betrifft, z. B. seine Größe, das Timing oder eine andere Eigenschaft.
Ausschließen vorübergehender Netzwerkunregelmäßigkeiten
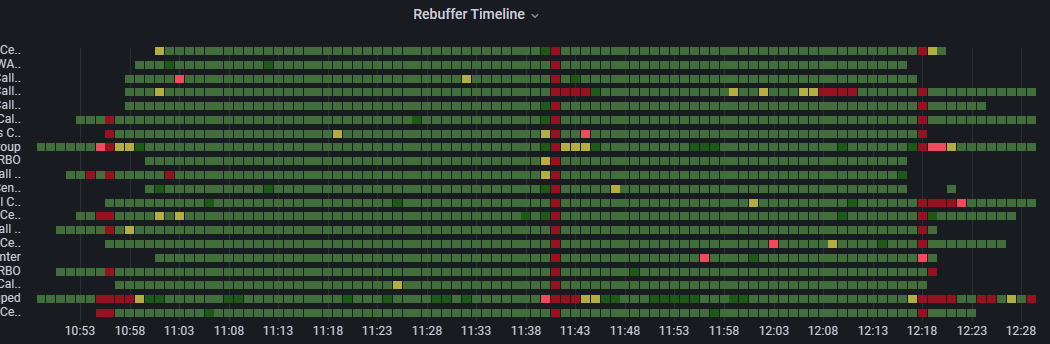
Eine Zurückweisung kann auf Netzwerkinkonsistenzen zurückzuführen sein, die außerhalb unserer unmittelbaren Kontrolle liegen, z. B. der ISP oder ein Content Delivery Network mit einer inkonsistenten Dienstinkonsistenz. Nach dem Filtern nach einem bestimmten Ereignis und der anschließenden Auswahl der Dimension "Gruppenaufschlüsselung" überprüfen wir im Drilldown-Dashboard das Diagramm "Zeitachsen neu formatieren" auf alle visuellen Muster, die gruppenübergreifend sind.
Beispiel für gruppenübergreifendes Wiederverteilen
In diesem Screenshot der Wiedererkennungszeitachse für die Dimension "Gruppen" beobachten wir drei Momente während dieses 90-minütigen Ereignisses, in denen in allen Gruppen dieser großen organization, am Anfang, an der Mitte und am Ende des Ereignisses eine hohe Wiedererkennung aufgetreten ist. Dieser organisationsübergreifende Effekt ist ein starker Indikator für die Ursache des Problems, die in diesem Fall das Content Delivery Network des organization war; ein CDN, nicht zu verwechseln mit Microsoft eCDN.
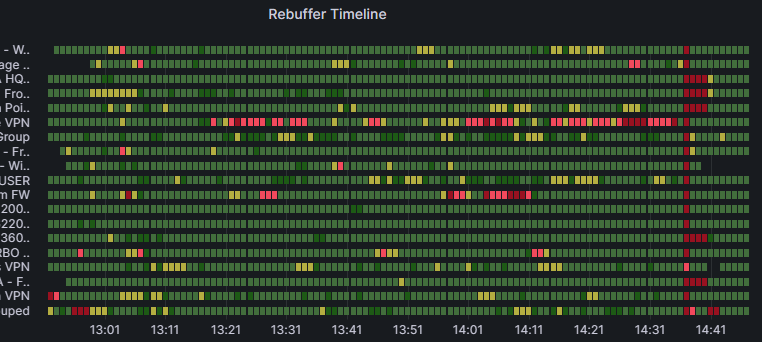
Beispiel für die Zurückweisung in einer einzelnen Gruppe
Ähnlich wie beim oben genannten Zeitleiste Screenshot beobachten wir in diesem Beispiel auch einen organization breiten Moment der Wiedergeburt in der Nähe des Endes. Darüber hinaus können wir auch beobachten, dass eine dieser ORGANIZATION VPN-Gruppen während des gesamten Ereignisses eine schlechte Wiedergeburt erlebt. Dies könnte ein deutliches Anzeichen für einen Mangel an Kapazität in der VPN-Leitung der Organisation sein. Wenn dies der Fall ist, wäre diese Gruppe ein guter Testfall, um die Auswirkungen des geteilten Tunnelings von Teams-Datenverkehr zur Verringerung der Last zu untersuchen.
Identifizieren eines slice mit Problemen
Wenn eine übergreifende Ursache nicht offensichtlich ist, fahren Sie mit der Problembehandlung fort, indem Sie die Daten zu den verschiedenen verfügbaren Aufschlüsselungen in den Analysedrilldowns Dashboard systematisch aufteilen. Die Aufschlüsselungsdimensionen umfassen Folgendes.
- Ereignis
- Gruppe
- App
- ISP
- Land
- Stadt/Ort
- Betriebssystem
Begrenzungen
Selbst wenn die Subnetzzuordnung hochgeladen wurde, können die hohen Wiedergeburtspunkte manchmal in einer der Standardgruppen gefunden werden. Um probleme mit schlechten Metriken für diese Gruppen zu beheben, verwenden Sie die automatisch aufgefüllten Aufschlüsselungskategorien wie die folgenden, um die Daten zu filtern und zu slicen.
- App
- ISP
- Land
- Stadt/Ort
Zusammenfassung
Wenn Sie das nächste Mal eine hohe Wiedergeburt erleben, suchen Sie nach Mustern, und stellen Sie sich Fragen wie die folgenden.
- Kommt es zu hohen Wiedergeburten unternehmensweit oder nur an bestimmten Standorten?
- Ist die Zurückweisung für bestimmte Betriebssysteme oder Anwendungen, die zum watch des Liveereignisses verwendet werden, höher?
- Gab es eine Erneuteinfuhr zu einer bestimmten Minute für jeden Benutzer und ging einige Zeit später weg?
- Gibt es eine Korrelation zwischen einem beobachteten Moment der Wiedergeburt und einem anderen potenziell auswirkungsbehafteten Ereignis im Netzwerk?
Rebuffering ist ein unerwünschtes Nebenprodukt, das in der Regel mit der Unzuverlässigkeit des Netzwerks verbunden ist. Mit den Dashboards von Microsoft eCDN können Sie mehr Einblick in die Quelle erhalten, um sie zu beheben.