Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
Gilt für:✅ Fabric Data Engineering und Data Science
Wenn Sie Microsoft Fabric aus dem Azure-Portal erstellen, wird sie automatisch dem Fabric-Mandanten hinzugefügt, der dem Abonnement zugeordnet ist, das zum Erstellen der Kapazität verwendet wird. Mit der vereinfachten Einrichtung in Microsoft Fabric müssen Sie die Kapazität nicht mit dem Fabric-Mandanten verknüpfen. Da die neu erstellte Kapazität im Bereich „Administratoreinstellungen“ aufgeführt wird. Mit dieser Konfiguration können Administratoren schneller mit der Einrichtung der Kapazität für ihre Unternehmensanalyseteams beginnen.
Um Änderungen an den Datentechnik/Data Science-Einstellungen in einer Kapazität vorzunehmen, müssen Sie über die Administratorrolle für diese Kapazität verfügen. Weitere Informationen zu den Rollen, die Sie Benutzern in einer Kapazität zuweisen können, finden Sie unter Rollen in Kapazitäten.
Führen Sie die folgenden Schritte aus, um die Data Engineering/Science-Einstellungen für Microsoft Fabric Kapazität zu verwalten:
Wählen Sie die Option Einstellungen aus, um den Einstellungsbereich für Ihr Fabric-Konto zu öffnen. Wählen Sie das Verwaltungsportal im Abschnitt "Governance und Einblicke" aus.
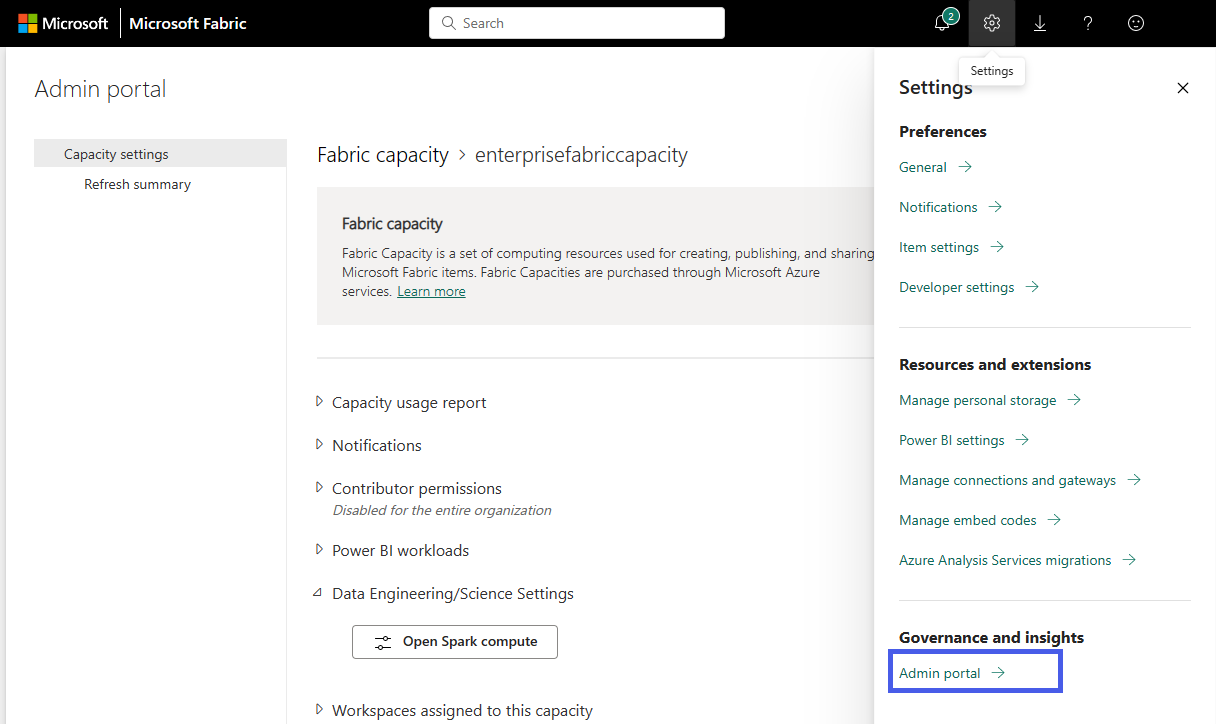
Wählen Sie die Option "Kapazitätseinstellungen" aus, um das Menü zu erweitern, und wählen Sie die Registerkarte "Fabric-Kapazität " aus. Hier sollten sie die Kapazitäten sehen, die Sie in Ihrem Mandanten erstellt haben. Wählen Sie die Kapazität aus, die Sie konfigurieren möchten.

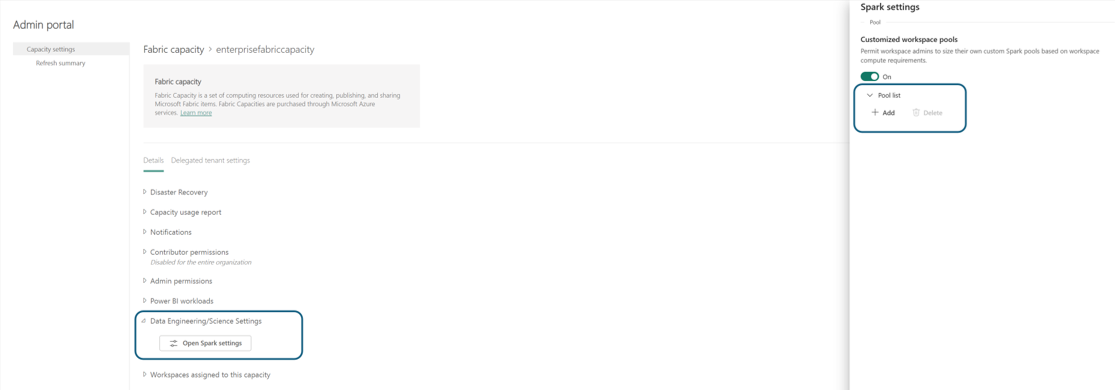
Sie werden zum Kapazitätsdetailbereich navigiert, in dem Sie die Nutzung und andere Administratorsteuerelemente für Ihre Kapazität anzeigen können. Navigieren Sie zum Abschnitt Datentechnik-/Data Science-Einstellungen, und wählen Sie Spark Compute öffnen aus. Konfigurieren Sie die folgenden Parameter:


Hinweis
Mindestens ein Arbeitsbereich sollte an die Fabric-Kapazität angefügt werden, um die Data Engineering/Science-Einstellungen aus dem Fabric Capacity Admin Portal zu erkunden.
Admin-Steuerung: Deaktivierung der Starter-Pool-Nutzung
Kapazitätsadministratoren können jetzt festlegen, dass die Startpoolnutzung in Arbeitsbereichen deaktiviert wird, die mit der Kapazität verbunden sind. Wenn diese Option deaktiviert ist, werden Benutzern und Arbeitsbereichsadministratoren der Starterpool nicht mehr als Computeoption angezeigt. Stattdessen müssen sie benutzerdefinierte Pools verwenden, die explizit vom Kapazitätsadministrator erstellt und verwaltet werden.
Dieses Feature bietet eine zentrale Governance für die Berechnungsnutzung und stellt eine engere Kontrolle über die Berechnungsgröße, die Kosten und das Planungsverhalten sicher.
Tipp
Diese Einstellung ist besonders in großen Organisationen hilfreich, die Berechnungsmuster standardisieren und willkürlichen Verbrauch über Standardstartpools vermeiden möchten.
Admin-Steuerung: Schaltfläche für Auftragsverteilung auf Auftragsebene
Microsoft Fabric unterstützt 3× bursting für Spark VCores, sodass ein einzelner Auftrag vorübergehend mehr Computekerne verwendet, als die Basiskapazität bereitstellt. Dies verbessert die Auftragsleistung während von Aktivitätsbrüchen, indem die volle Kapazitätsauslastung ermöglicht wird.
Als Kapazitätsadministrator können Sie dieses Verhalten jetzt steuern, indem Sie den im Admin-Portal verfügbaren Schalter "Deaktivierung von Job-Level Bursting" verwenden:
Ort:
Admin Portal → Capacity Settings → [Select Capacity] → Data Engineering/Science Settings → Spark ComputeVerhalten:
- Aktiviert (Standard): Ein einzelner Spark-Auftrag kann das vollständige Burst-Limit (bis zu 3× Spark VCores) nutzen.
- Deaktiviert: Einzelne Spark-Aufträge werden bei der Basiskapazitätszuweisung gedeckelt, wobei Parallelität erhalten bleibt und Monopolisierung vermieden wird.
Hinweis
Dieser Switch ist nur verfügbar , wenn Spark-Aufträge auf Fabric Capacity ausgeführt werden. Wenn die Option " Abrechnung automatisch skalieren " aktiviert ist, wird dieser Schalter automatisch deaktiviert, da:
- Autoscale Billing folgt einem reinen Pay-as-you-go-Modell.
- Es gibt kein Glättungsfenster , um Nutzungsbrüche zuzulassen und sie über 24 Stunden auszugleichen.
- "Bursting" ist eine Funktion der reservierten Kapazität, nicht des Bedarfsskalierungs-Computings.
Anwendungsfälle und Beispiele
| Szenario | Konfiguration | Verhalten |
|---|---|---|
| Hohe ETL-Arbeitsauslastung | Bursting aktiviert (Standard) | Job kann die gesamte Burst-Kapazität (z. B. 384 Spark VCores in F64) nutzen. |
| Interaktive Notizbücher mit mehreren Benutzern | Bersten deaktiviert | Die Auftragsnutzung ist begrenzt (z. B. 128 Spark VCores in F64), um die Parallelität zu verbessern. |
| Autoscale-Abrechnung ist aktiviert | Platzsteuerung nicht verfügbar | ** Alle Spark-Nutzung wird bei Bedarf in Rechnung gestellt; kein Burst aus der Basiskapazität. |
Tipp
Verwenden Sie diesen Switch, um den Durchsatz oder die Parallelität zu optimieren:
- Halten Sie große Aufträge und Pipelines im Bursting-Modus aktiviert.
- Deaktivieren Sie es für interaktive oder freigegebene Umgebungen mit vielen Benutzern.
Kapazitätspools für Data Engineering und Data Science in Microsoft Fabric
Klicken Sie im Abschnitt "Poolliste " der Spark-Einstellungen auf "Hinzufügen" , um einen benutzerdefinierten Pool für Ihre Fabric-Kapazität zu erstellen.
Sie werden zur Seite "Poolerstellung" navigiert, auf der Sie folgende Möglichkeiten haben:
- Geben Sie den Poolnamen an.
- Knotenfamilie und Knotengröße auswählen
- Festlegen von Min- und Max-Knoten
- Aktivieren/Deaktivieren der automatischen Skalierung und dynamischen Zuweisung von Executoren
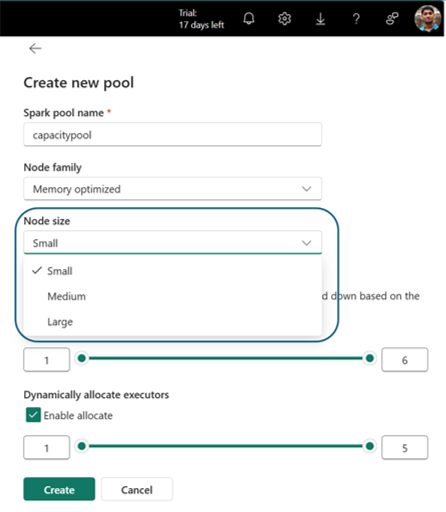
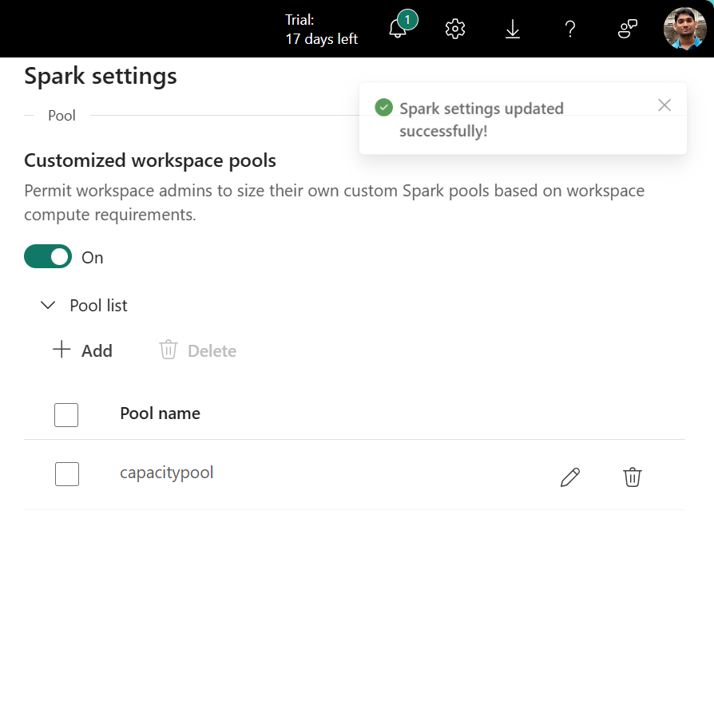
Wählen Sie "Erstellen" aus, um Ihre Einstellungen zu speichern.



Hinweis
Benutzerdefinierte Pools auf Kapazitätsebene weisen eine Startlatenz von 2 bis 3 Minuten auf. Verwenden Sie für den schnelleren Start der Spark-Sitzung (<5 Sekunden) Starterpools, wenn diese aktiviert sind.
Nach der Erstellung steht der Kapazitätspool zur Verfügung in:
- Das Dropdownmenü für die Poolauswahl in den Arbeitsbereichseinstellungen
- Die Seite "Einstellungen für Umgebungsrechner" im Arbeitsbereich
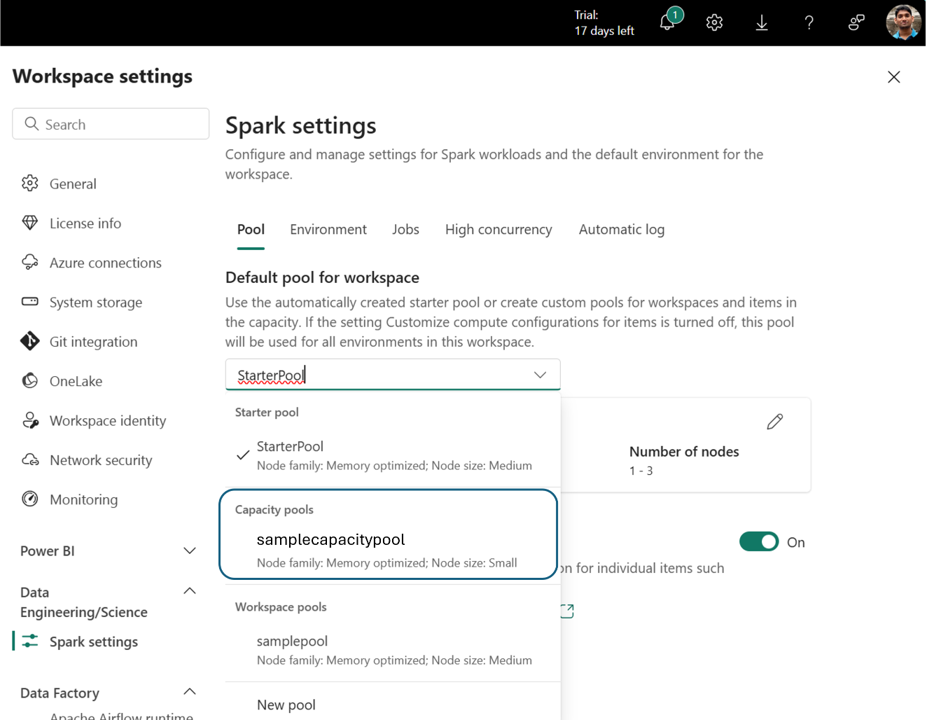

Dies ermöglicht eine zentrale Computerverwaltung. Administratoren können standardisierte Pools erstellen und optional anpassungen auf Arbeitsbereichsebene deaktivieren, administratoren in Arbeitsbereichen daran hindern, Pooleinstellungen zu ändern oder eigene zu erstellen.

