Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
In diesem Artikel wird das Azure Log Analytics Ziel für Fabric Apache Spark Diagnostic Emitter mithilfe der Log Ingestion-API beschrieben.
Fabric Apache Spark Diagnostic Emitter bietet ein gemeinsames Konfigurationsmodell für Spark-Diagnostik über verschiedene Ziele hinweg. Für Azure Log Analytics ist die Protokollaufnahme-API das empfohlene Aufnahmemodell.
In diesem Artikel wird erläutert, wie Sie Emittereigenschaften konfigurieren, Apache Spark-Protokolle, Ereignisprotokolle und Metriken an Log Analytics weiterleiten und die erfassten Daten zur Überwachung und Problembehandlung abfragen.
Architektur und Zielauswahl über den Fabric Apache Spark Diagnostic Emitter finden Sie unter Fabric Apache Spark Diagnostic Emitter overview.
Migrieren von der Datensammler-API
Wenn Sie derzeit die HTTP-Datensammler-API verwenden, migrieren Sie zur Log Ingestion-API, um sich an das aktuelle Azure Monitor-Aufnahmemuster anzupassen.
Wichtige Änderungen im neuen Modell:
- Schemadefinitionen sind durch Datensammlungsregeln (Data Collection Rules, DCRs) explizit, wodurch Sie vorhersagbare Schemaüberprüfung und konsistentere Abfrageergebnisse als der ältere Freiform-Nutzlastansatz erhalten.
- Die Erfassung erfolgt über Datensammlungsendpunkte (DCEs) und DCR-Zuordnungen, die einen kontrollierteren Erfassungspfad bereitstellen, als direkt an den Datensammler-API-Endpunkt zu senden.
- Die Authentifizierung unterstützt sowohl den geheimen Clientschlüssel des Dienstprinzipals als auch zertifikatbasierte Optionen.
- Der Emittertyp ändert sich von
AzureLogAnalyticszuAzureLogIngestion.
Die Migration umfasst in der Regel das Erstellen von DCR- und DCE-Ressourcen, das Aktualisieren der Spark-Eigenschaften der Fabric Umgebung und das Überprüfen der Datenintegration in benutzerdefinierte Log Analytics-Tabellen.
Übersicht über die Protokollaufnahme-API
Für die Apache Spark-Diagnose in Microsoft Fabric stellt die Log Ingestion-API ein strukturiertes Aufnahmemodell für Authentifizierung, Schemadefinition, Routing und Tabellenübermittlung in Azure Log Analytics bereit.
Wichtigste Komponenten
| Bestandteil | Purpose |
|---|---|
| Anmeldeinformationen für die App-Registrierung | Stellt Microsoft Entra App-Identität bereit, die zum Authentifizieren von Protokollaufnahme-API-Anforderungen mit einem geheimen Clientschlüssel oder Zertifikat verwendet wird. |
| Log Analytics Tabelle | Stellt die benutzerdefinierte Zieltabelle bereit, in der die erfasste Spark-Diagnose für Abfragen und Überwachung gespeichert wird. |
| Datensammlungsregel (Data Collection Rule, DCR) | Definiert Eingabedatenströme, Schemazuordnung und optionale Transformationen für die Aufnahme. |
| Datensammlungsendpunkt (Data Collection Endpoint, DCE) | Stellt den Aufnahmeendpunkt-URI (dceUri) bereit, der von Clients zum Senden von Daten über DCR-basiertes Routing verwendet wird. |
Nur vom Benutzer erstellte DCRs, die für die Log Ingestion-API konfiguriert sind, können für die programmgesteuerte Erfassung verwendet werden.
Schrittweise Konfiguration
Schritt 1. Vorbereiten des Arbeitsbereichs für Log Analytics
Zum Empfangen der Spark-Diagnose ist ein Log Analytics Arbeitsbereich erforderlich. Es ist die grundlegende Speicher- und Abfrageeinheit für Azure Monitor Logs.
Wenn Sie noch keinen haben, erstellen Sie einen Log Analytics-Arbeitsbereich im Azure-Portal.
Von Bedeutung
Erstellen Sie beim Ausführen der folgenden Schritte die Ressourcen Data Collection Endpoint (DCE) und Data Collection Rule (DCR) in derselben Region wie der Log Analytics-Arbeitsbereich.
Schritt 2. Erstellen eines Datensammlungsendpunkts (DATA Collection Endpoint, DCE)
Erstellen Sie einen Datensammlungsendpunkt (Data Collection Endpoint, DCE) im Azure-Portal. Der DCE stellt den Endpunkt-URI bereit, den Sie in Spark-Eigenschaften für die Log Ingestion-API konfigurieren. Die Region des DCE muss mit der Region Ihres Log Analytics Arbeitsbereichs übereinstimmen.
Wechseln Sie im portal Azure portal zum Monitor im linken Navigationsbereich.
Wählen Sie unter "Einstellungen"die Option "Datensammlungsendpunkte" und dann " Erstellen" aus.
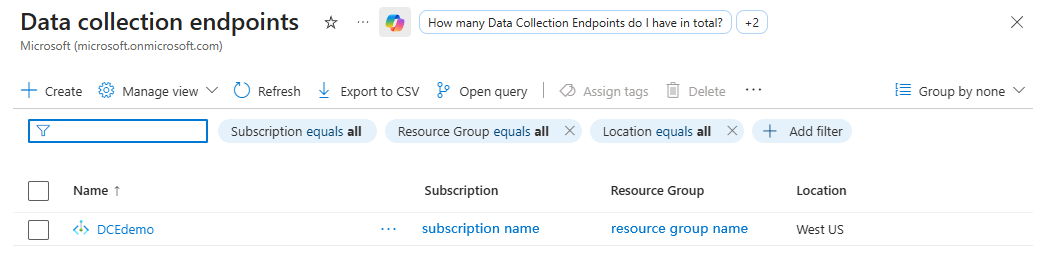
Erstellen Sie den Endpunkt, und notieren Sie sich dann den DCE-Namen (z. B
DCEdemo. ).

Schritt 3. Vorbereiten des JSON-Beispielschemas
Beim Erstellen benutzerdefinierter Protokolltabellen müssen Sie eine Datensammlungsregel (Data Collection Rule, DCR) konfigurieren. Basierend auf den im DCR angegebenen Datenstromdefinitionen generiert das System automatisch das entsprechende Tabellenschema in Ihrem Log Analytics Arbeitsbereich.
Folgende vordefinierte JSON-Schemabeispiele sind jeweils einem bestimmten Datentyp zugeordnet. Laden Sie das Beispiel herunter, das Ihrem Szenario entspricht, und laden Sie es hoch, wenn Sie die zugeordnete benutzerdefinierte Tabelle und DCR erstellen.
- Spark-Ereignisprotokolle – JSON-Schemabeispiel für Ereignistabellen
- Spark-Treiber- und Executorprotokolle – Beispiel für das JSON-Schema der Protokolltabelle
- Spark-Metriken – JSON-Schemabeispiel für metrische Tabellen
- Plattformmetadaten – JSON-Schemabeispiel für die Plattformmetadatentabelle
Hier ist ein Beispiel für ein JSON-Schemabeispiel für die Protokolltabelle für Spark-Treiber- und Executorprotokolle in Azure Log Analytics. Verwenden Sie dieses Schema als Verweis, wenn Sie ihre benutzerdefinierten Tabellen und DCRs für die Protokollaufnahme erstellen.
[
{
"applicationId_s": "<APPLICATION_ID>",
"applicationName_s": "<NOTEBOOK_NAME>",
"artifactId_g": "<ARTIFACT_GUID>",
"artifactType_s": "SynapseNotebook",
"capacityId_g": "<CAPACITY_GUID>",
"Category": "Log",
"executorId_s": "driver",
"executorMax_s": 9,
"executorMin_s": 1,
"ExtraFields": {
"Category": "Log",
"JobId": "1"
},
"fabricEnvId_g": "<FABRIC_ENV_GUID>",
"fabricLivyId_g": "<FABRIC_LIVY_GUID>",
"fabricTenantId_g": "<FABRIC_TENANT_GUID>",
"fabricWorkspaceId_g": "<FABRIC_WORKSPACE_GUID>",
"isHighConcurrencyEnabled_s": false,
"Level": "INFO",
"logger_name_s": "org.apache.spark.scheduler.dynalloc.ExecutorMonitor",
"Message": "Executor 1 is removed.",
"thread_name_s": "spark-listener-group-executorManagement",
"TimeGenerated": "<TIME_GENERATED>",
"userId_g": "<USER_ID>"
}
]
Schritt 4. Erstellen einer benutzerdefinierten Tabelle (Direct Ingest)
Erstellen Sie eine benutzerdefinierte Tabelle in Ihrem Log Analytics Arbeitsbereich mit der Option Log Ingestion API, und laden Sie das JSON-Schemabeispiel in den zugehörigen DCR hoch. Dieser Schritt ist erforderlich, um das Ziel für die Spark-Diagnose einzurichten und sicherzustellen, dass die erfassten Daten dem erwarteten Schema entsprechen. Die Region des Log Analytics-Arbeitsbereichs, DCE und DCR muss für eine erfolgreiche Datenaufnahme identisch sein.
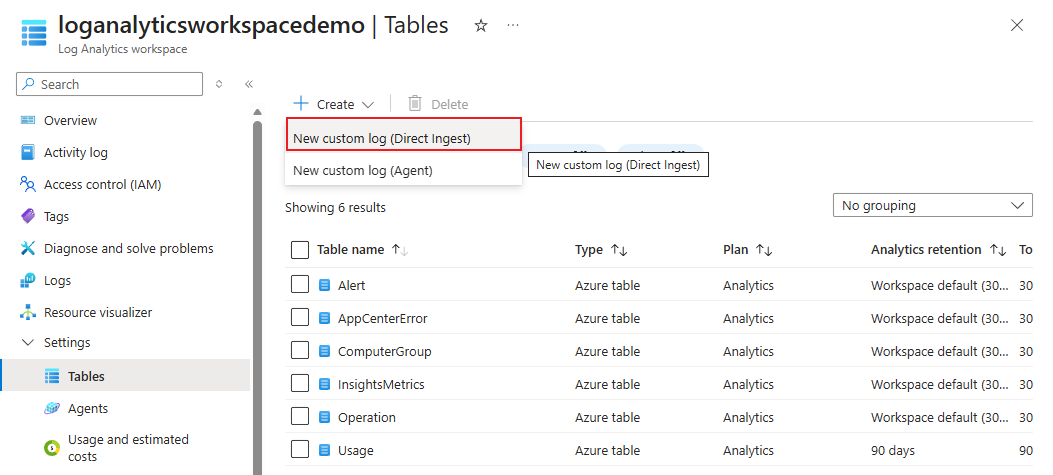
Öffnen Sie im portal Azure Ihren Log Analytics Arbeitsbereich (z. B. loganalyticsworkspacedemo).
Wählen Sie Tabelle>Erstellen>Neues benutzerdefiniertes Protokoll (Direkte Erfassung) aus.
Geben Sie die Tabelleneinstellungen ein:
- Tabellenname: Zum Beispiel SparkLogTest (Suffix "_CL" wird automatisch hinzugefügt).
- Tabellenplan: Analyse
- Datensammlungsregel: Erstellen eines neuen DCR (z. B. SparkLogTestrule).
- Datensammlungsendpunkt: Wählen Sie den DCE aus dem Schritt "Datensammlungsendpunkt erstellen" ( z. B. DCEdemo) aus.
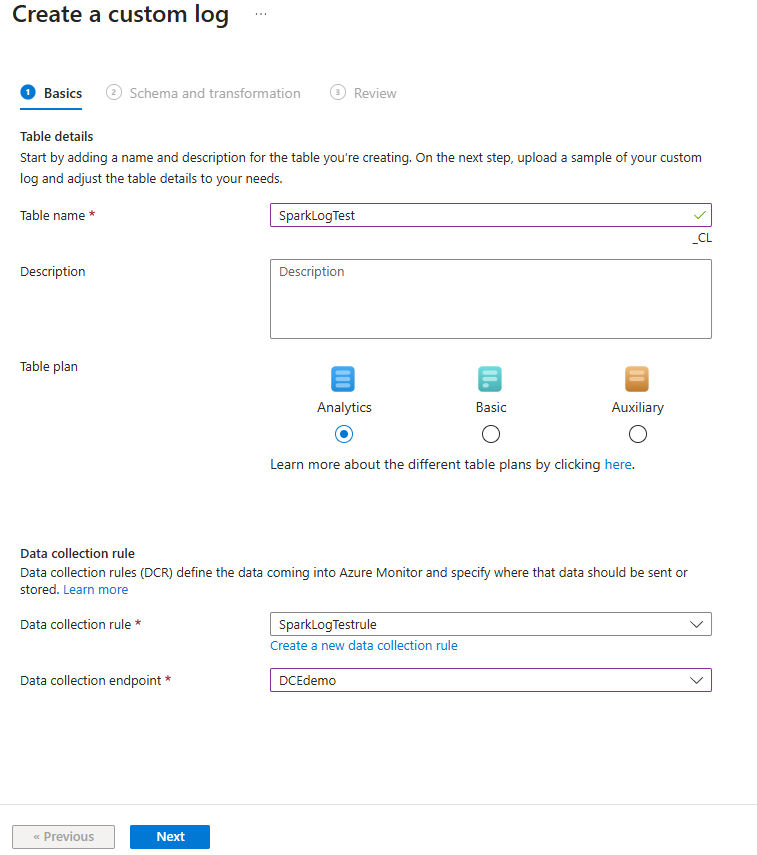
Wählen Sie Weiteraus.
Laden Sie im Schema- undTransformationsbeispiel das JSON-Schemabeispiel hoch. Sie müssen die DCR-Transformation nicht konfigurieren, da das Schema vollständig auf der Clientseite stabilisiert ist.


Schritt 5. Vorbereiten des Dienstprinzipals für die Authentifizierung
Registrieren Sie eine App in Microsoft Entra ID.

Notieren Sie die TenantId, ClientId und ClientSecret (wenn Sie die geheime Clientschlüsselauthentifizierung verwenden). Sie verwenden diese Werte in der Spark-Konfiguration in Schritt 6.
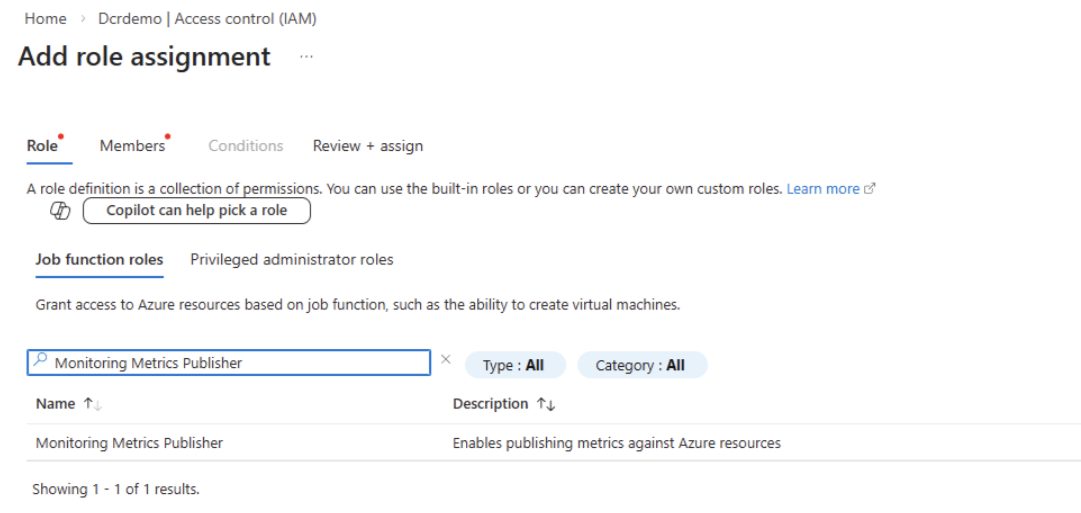
Gewähren Sie der App die Rolle Monitoring Metrics Publisher für die DCR-Ressource jeder Tabelle. Schritte zur Rollenzuweisung finden Sie unter Assign Azure Rollen mithilfe des Azure Portals.


Schritt 6: Spark-Eigenschaften konfigurieren
Um Spark zu konfigurieren, erstellen Sie eine Umgebung in Fabric, und wählen Sie eine der folgenden Authentifizierungsoptionen aus. Verwenden Sie nur eine Option für einen bestimmten Emitter.
Eine Umgebung in Fabric speichert Spark-Einstellungen und Bibliotheken, die von Notizbüchern und Spark-Auftragsdefinitionen während der Laufzeit verwendet werden. Schritte zum Erstellen einer Umgebung finden Sie unter Create, configure, and use an environment in Fabric.
- Wählen Sie Option 1 aus, wenn Sie ein einfacheres Setup mithilfe eines geheimen Clientschlüssels wünschen.
- Wählen Sie Option 2 aus, wenn Ihre Organisation zertifikatbasierte Authentifizierung und zentrale Zertifikatverwaltung in Azure Key Vault erfordert.
In beiden Optionen können Sie Aus .yml hinzufügen in der Umgebung auswählen, um eine .yml Konfigurationsdatei zu importieren.
Option 1: Konfigurieren mit Dienstprinzipal und Client-Geheimnis
Verwenden Sie diese Option zum schnellen Einrichten mit Dienstprinzipal-Anmeldeinformationen und einem geheimen Clientschlüssel.
Erstellen Sie eine Umgebung in Fabric.
Fügen Sie die folgenden Spark-Eigenschaften mit den entsprechenden Werten zur Umgebung hinzu, oder wählen Sie im Menüband "Aus .yml hinzufügen " aus, um eine
.ymlKonfigurationsdatei zu importieren.spark.synapse.diagnostic.emitters: <EMITTER_NAME> spark.synapse.diagnostic.emitter.<EMITTER_NAME>.type: AzureLogIngestion spark.synapse.diagnostic.emitter.<EMITTER_NAME>.categories: DriverLog,ExecutorLog,EventLog,Metrics spark.synapse.diagnostic.emitter.<EMITTER_NAME>.dceUri: https://<DCE_NAME>.<REGION>.ingest.monitor.azure.com spark.synapse.diagnostic.emitter.<EMITTER_NAME>.logDcr: <LOG_DCR_ID> spark.synapse.diagnostic.emitter.<EMITTER_NAME>.logStream: <LOG_STREAM_NAME> spark.synapse.diagnostic.emitter.<EMITTER_NAME>.eventDcr: <EVENT_DCR_ID> spark.synapse.diagnostic.emitter.<EMITTER_NAME>.eventStream: <EVENT_STREAM_NAME> spark.synapse.diagnostic.emitter.<EMITTER_NAME>.metricDcr: <METRIC_DCR_ID> spark.synapse.diagnostic.emitter.<EMITTER_NAME>.metricStream: <METRIC_STREAM_NAME> spark.synapse.diagnostic.emitter.<EMITTER_NAME>.metaDcr: <META_DCR_ID> spark.synapse.diagnostic.emitter.<EMITTER_NAME>.metaStream: <META_STREAM_NAME> spark.synapse.diagnostic.emitter.<EMITTER_NAME>.secret: <SP_CLIENT_SECRET> spark.synapse.diagnostic.emitter.<EMITTER_NAME>.tenantId: <SP_TENANT_ID> spark.synapse.diagnostic.emitter.<EMITTER_NAME>.clientId: <SP_CLIENT_ID> spark.fabric.pools.skipStarterPools: 'true'Speichern und veröffentlichen Sie die Änderungen.
Option 2: Konfigurieren mit dienstprinzipaler Zertifikatauthentifizierung
Verwenden Sie diese Option, wenn Ihre Organisation eine zertifikatbasierte Authentifizierung erfordert.
Bevor Sie beginnen, stellen Sie sicher, dass Ihr Dienstprinzipal mit einem Zertifikat erstellt wird. Weitere Informationen finden Sie unter Erstellen eines Dienstprinzipals mit einem Zertifikat mithilfe der Azure CLI.
Erstellen Sie eine Umgebung in Fabric.
Fügen Sie die folgenden Spark-Eigenschaften mit den entsprechenden Werten zur Umgebung hinzu, oder wählen Sie im Menüband "Aus .yml hinzufügen " aus, um eine
.ymlKonfigurationsdatei zu importieren.spark.synapse.diagnostic.emitters: <EMITTER_NAME> spark.synapse.diagnostic.emitter.<EMITTER_NAME>.type: AzureLogIngestion spark.synapse.diagnostic.emitter.<EMITTER_NAME>.categories: DriverLog,ExecutorLog,EventLog,Metrics spark.synapse.diagnostic.emitter.<EMITTER_NAME>.dceUri: https://<DCE_NAME>.<REGION>.ingest.monitor.azure.com spark.synapse.diagnostic.emitter.<EMITTER_NAME>.logDcr: <LOG_DCR_ID> spark.synapse.diagnostic.emitter.<EMITTER_NAME>.logStream: <LOG_STREAM_NAME> spark.synapse.diagnostic.emitter.<EMITTER_NAME>.eventDcr: <EVENT_DCR_ID> spark.synapse.diagnostic.emitter.<EMITTER_NAME>.eventStream: <EVENT_STREAM_NAME> spark.synapse.diagnostic.emitter.<EMITTER_NAME>.metricDcr: <METRIC_DCR_ID> spark.synapse.diagnostic.emitter.<EMITTER_NAME>.metricStream: <METRIC_STREAM_NAME> spark.synapse.diagnostic.emitter.<EMITTER_NAME>.metaDcr: <META_DCR_ID> spark.synapse.diagnostic.emitter.<EMITTER_NAME>.metaStream: <META_STREAM_NAME> spark.synapse.diagnostic.emitter.<EMITTER_NAME>.certificate.keyVault.certificateName: <SP_CERT-NAME> spark.synapse.diagnostic.emitter.<EMITTER_NAME>.certificate.keyVault: https://<KEYVAULT_NAME>.vault.azure.net/ spark.synapse.diagnostic.emitter.<EMITTER_NAME>.tenantId: <SP_TENANT_ID> spark.synapse.diagnostic.emitter.<EMITTER_NAME>.clientId: <SP_CLIENT_ID> spark.fabric.pools.skipStarterPools: 'true'Speichern und veröffentlichen Sie die Änderungen.
Schritt 7. Fügen Sie die Umgebung an Notizbücher oder Spark-Auftragsdefinitionen an, oder legen Sie sie als Arbeitsbereichstandard fest.
Verwenden Sie einen der folgenden Ansätze, die auf Ihrem Umfang basieren:
- Befestigen Sie die Umgebung an bestimmte Notizbücher oder Spark-Auftragsdefinitionen, wenn Sie ein gezieltes Rollout, Tests oder Kontrolle pro Element möchten.
- Legen Sie die Umgebung als Standardeinstellung für den Arbeitsbereich fest, wenn Sie konsistente Spark-Diagnoseeinstellungen für den gesamten Arbeitsbereich verwenden möchten.
So fügen Sie die Umgebung an Notizbücher oder Spark-Auftragsdefinitionen an:
- Navigieren Sie in Fabric zu Ihrer Notizbuch- oder Spark-Auftragsdefinition.
- Wählen Sie auf der Registerkarte „Start“ das Menü Umgebung und dann die konfigurierte Umgebung aus.
- Die Konfiguration wird nach dem Starten einer Spark-Sitzung angewendet.
So legen Sie die Umgebung als Standard für den Arbeitsbereich fest:
- Navigieren Sie in Fabric zu den Arbeitsbereichseinstellungen.
- Suchen Sie Spark-Einstellungen in Arbeitsbereichseinstellungen (Arbeitsbereichseinstellung>Data Engineering/Science>Spark-Einstellungen).
- Wählen Sie die Registerkarte "Umgebung" und die Umgebung mit konfigurierten Diagnose-Spark-Eigenschaften aus, und wählen Sie "Speichern".
Schritt 8: Ausführen von Spark-Workloads und Überprüfen von Protokollen und Metriken
Verwenden Sie die Umgebung, die Sie im vorherigen Abschnitt erstellt und angefügt haben, und führen Sie dann Spark-Workloads aus, und überprüfen Sie die Aufnahme in Log Analytics.
- Führen Sie Spark-Workloads mithilfe der im vorherigen Abschnitt konfigurierten Umgebung aus. Sie können eine der folgenden Methoden verwenden:
- Führen Sie ein Notizbuch in Fabric aus.
- Übermitteln eines Spark-Batchauftrags über eine Spark-Auftragsdefinition.
- Ausführen von Spark-Aktivitäten in einer Pipeline.
- Öffnen Sie den Ziel-Log Analytics Arbeitsbereich, und überprüfen Sie, ob Protokolle und Metriken für die ausgeführte Workload aufgenommen werden.
- Verwenden Sie zur Validierung der Erfassung und Überprüfung von Datensätzen die Kusto-Beispiele in Abfragen von Daten mit Kusto.
Schreiben von benutzerdefinierten Anwendungsprotokollen
Verwenden Sie benutzerdefinierte Anwendungsprotokolle, wenn Sie zusätzlich zur Plattformdiagnose geschäftsspezifische Oder App-spezifische Ereignisse benötigen. Diese Protokolle werden über dieselbe Diagnosepipeline ausgegeben und in Log Analytics zusammen mit Spark-Protokollen, Ereignisprotokollen und Metriken angezeigt.
Verwenden Sie Apache Log4j in Ihrem Spark-Code, um benutzerdefinierte Protokollnachrichten auszustrahlen. Die folgenden Beispiele zeigen ein minimales Muster für Scala und PySpark.
Scala-Beispiel:
%%spark
val logger = org.apache.log4j.LogManager.getLogger("com.contoso.LoggerExample")
logger.info("info message")
logger.warn("warn message")
logger.error("error message")
//log exception
try {
1/0
} catch {
case e:Exception =>logger.warn("Exception", e)
}
// run job for task level metrics
val data = sc.parallelize(Seq(1,2,3,4)).toDF().count()
PySpark-Beispiel:
%%pyspark
logger = sc._jvm.org.apache.log4j.LogManager.getLogger("com.contoso.PythonLoggerExample")
logger.info("info message")
logger.warn("warn message")
logger.error("error message")
Abfragen von Daten mit Kusto
Verwenden Sie Kusto-Abfragen, um zu überprüfen, ob die Aufnahme funktioniert, und um das Verhalten der Spark-Ausführung zu untersuchen. Ersetzen Sie Platzhalterwerte wie {FabricWorkspaceId}, {ArtifactId} und {LivyId} durch Werte aus Ihrer eigenen Ausführung.
Beginnen Sie mit Ereignis- und Protokollabfragen, um die Ankunft von Daten zu bestätigen, und verwenden Sie dann Metrikabfragen für die Leistungsanalyse.
So fragen Sie Apache Spark-Ereignisse ab
SparkEventTest_CL
| where fabricWorkspaceId_g == "{FabricWorkspaceId}" and artifactId_g == "{ArtifactId}" and fabricLivyId_g == "{LivyId}"
| order by TimeGenerated desc
| limit 100
Um Protokolle von Spark-Anwendungstreiber und -Executor abzufragen:
SparkLogTest_CL
| where fabricWorkspaceId_g == "{FabricWorkspaceId}" and artifactId_g == "{ArtifactId}" and fabricLivyId_g == "{LivyId}"
| order by TimeGenerated desc
| limit 100
So fragen Sie Apache Spark-Metriken ab
SparkMetricsTest_CL
| where fabricWorkspaceId_g == "{FabricWorkspaceId}" and artifactId_g == "{ArtifactId}" and fabricLivyId_g == "{LivyId}"
| where name_s endswith "jvm.total.used"
| summarize max(value_d) by bin(TimeGenerated, 30s), executorId_s
| order by TimeGenerated asc
So fragen Sie Plattformmetadaten ab:
SparkMetadataTest_CL
| where fabricWorkspaceId_g == "{FabricWorkspaceId}" and artifactId_g == "{ArtifactId}" and fabricLivyId_g == "{LivyId}"
| order by TimeGenerated desc
| limit 100
Fabric Arbeitsbereiche mit verwaltetem virtuellen Netzwerk
Fabric-Unterstützung zur Ermöglichung des Datenexfiltrationsschutzes für Arbeitsbereiche. Bei Exfiltrationsschutz können die Protokolle und Metriken nicht direkt an die Zielendpunkte gesendet werden. Sie können entsprechende verwaltete private Endpunkte für verschiedene Zielendpunkte in diesem Szenario erstellen.
Verfügbare Apache Spark-Konfigurationen
In der folgenden Tabelle sind Spark-Konfigurationen zum Senden von Protokollen und Metriken an Azure Log Analytics mithilfe der Log Ingestion-API aufgeführt.
Von Bedeutung
Legen Sie für Azure Log Analytics spark.synapse.diagnostic.emitter.<EMITTER_NAME>.type auf AzureLogIngestion fest.
AzureLogAnalytics ist der ältere HTTP-Datensammler-API-Typ. Anleitungen zu älteren Versionen finden Sie unter Überwachen von Apache Spark-Anwendungen mit Azure Log Analytics.
| Konfiguration | Beschreibung |
|---|---|
spark.synapse.diagnostic.emitters |
Kommagetrennte Liste der Zielnamen von Diagnoseemittern. Beispiel: MyDest1,MyDest2. |
spark.synapse.diagnostic.emitter.<EMITTER_NAME>.type |
Integrierter Zieltyp Um Azure Log Analytics über die Log Ingestion-API zu aktivieren, legen Sie diesen Wert auf AzureLogIngestion fest. |
spark.synapse.diagnostic.emitter.<EMITTER_NAME>.categories |
Kommagetrennte Liste der ausgewählten Protokollkategorien. Verfügbare Werte: DriverLog, ExecutorLog, EventLog, Metrics. Wenn nicht festgelegt, ist der Standardwert alle Kategorien. |
spark.synapse.diagnostic.emitter.<EMITTER_NAME>.dceUri |
Der Datensammlungsendpunkt (DCE)-URI, der zum Erfassen beim Weiterleiten von Daten über Datensammlungsregeln (DCRs) verwendet wird. |
spark.synapse.diagnostic.emitter.<EMITTER_NAME>.logDcr |
Die Ressourcen-ID der Datensammlungsregel (Data Collection Rule, DCR), die zum Weiterleiten von Spark-Logdateien an das Ziel verwendet wird. |
spark.synapse.diagnostic.emitter.<EMITTER_NAME>.logStream |
Der Datenstromname, der in der Datensammlungsregel (DATA Collection Rule, DCR) für Spark-Protokolle definiert ist. |
spark.synapse.diagnostic.emitter.<EMITTER_NAME>.eventDcr |
Die Ressourcen-ID der Datensammlungsregel (Data Collection Rule, DCR), die zum Weiterleiten von Spark-Ereignisprotokollen verwendet wird. |
spark.synapse.diagnostic.emitter.<EMITTER_NAME>.eventStream |
Der Datenstromname, der in der Datensammlungsregel (DATA Collection Rule, DCR) für Spark-Ereignisprotokolle definiert ist. |
spark.synapse.diagnostic.emitter.<EMITTER_NAME>.metricDcr |
Die Ressourcen-ID der Datensammlungsregel (Data Collection Rule, DCR), die zum Weiterleiten von Spark-Metriken verwendet wird. |
spark.synapse.diagnostic.emitter.<EMITTER_NAME>.metricStream |
Der datenstromname, der in der Datensammlungsregel (Data Collection Rule, DCR) für Spark-Metriken definiert ist. |
spark.synapse.diagnostic.emitter.<EMITTER_NAME>.metaDcr |
Die Ressourcen-ID der Datensammlungsregel (Data Collection Rule, DCR), die zum Weiterleiten von Spark-Metadaten verwendet wird. |
spark.synapse.diagnostic.emitter.<EMITTER_NAME>.metaStream |
Der Datenstromname, der in der Datensammlungsregel (DATA Collection Rule, DCR) für Spark-Metadaten definiert ist. |
spark.synapse.diagnostic.emitter.<EMITTER_NAME>.certificate.keyVault.certificateName |
Der Name des in Azure Key Vault gespeicherten Zertifikats, das für die Authentifizierung verwendet wird. |
spark.synapse.diagnostic.emitter.<EMITTER_NAME>.certificate.keyVault |
Der Azure Key Vault-URI, der das Authentifizierungszertifikat speichert. |
spark.synapse.diagnostic.emitter.<EMITTER_NAME>.tenantId |
Die Microsoft Entra Mandanten-ID, die für die Authentifizierung verwendet wird. |
spark.synapse.diagnostic.emitter.<EMITTER_NAME>.clientId |
Die in Microsoft Entra ID registrierte Client-ID (Anwendungs-ID). |
spark.fabric.pools.skipStarterPools |
Diese Spark-Eigenschaft wird verwendet, um eine Spark-Sitzung bei Bedarf zu erzwingen. Setzen Sie den Wert auf true, wenn Sie den Standardpool verwenden, um die Bibliotheken zum Ausgeben von Protokollen und Metriken auszulösen. |
spark.synapse.diagnostic.emitter.<EMITTER_NAME>.secret |
Der geheime Clientschlüssel, der der Microsoft Entra ID-Anwendung (Azure AD) zugeordnet ist, wird zusammen mit der Mandanten-ID und der Client-ID verwendet, um den Emitter beim Senden von Diagnosedaten zu authentifizieren. Diese Einstellung schließt sich gegenseitig mit der zertifikatbasierten Authentifizierung aus– konfigurieren Sie entweder den geheimen Clientschlüssel oder das Zertifikat, aber nicht beides. |
Verwandte Inhalte
- Erstellen einer Apache Spark-Auftragsdefinition
- Erstellen, konfigurieren und verwenden Sie eine Umgebung in Microsoft Fabric
- Entwickeln, Ausführen und Verwalten von Microsoft Fabric Notizbüchern
- Überwachen von Spark-Anwendungen
- Apache Spark-Diagnosen mit Azure Event Hubs erfassen
- Sammeln Sie Apache-Spark-Diagnosedaten über ein Azure Storage-Konto