Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
Gilt für:✅ Fabric Data Engineering and Data Science
Erfahren Sie, wie Sie Spark-Batchaufträge mithilfe der Livy-API für Fabric Data Engineering übermitteln. Die Livy-API unterstützt derzeit Azure Service Principal (SPN) nicht.
Voraussetzungen
Fabric Premium oder Testkapazität mit dem Lakehouse.
Ein Remoteclient wie Visual Studio Code mit Jupyter Notebooks, PySpark und dem Microsoft Authentication Library (MSAL) für Python.
Für den Zugriff auf die Fabric Rest-API ist ein Microsoft Entra App-Token erforderlich. Registern Sie eine Anwendung mit dem Microsoft identity platform.
Einige Daten in Ihrem Lakehouse. Dieses Beispiel verwendet NYC Taxi & Limousine Commission (Parquet-Datei „green_tripdata_2022_08“, die in Lakehouse geladen wurde).
Die Livy-API definiert einen einheitlichen Endpunkt für Vorgänge. Ersetzen Sie die Platzhalter {Entra_TenantID}, {Entra_ClientID}, {Fabric_WorkspaceID} und {Fabric_LakehouseID} durch die entsprechenden Werte, wenn Sie den Beispielen in diesem Artikel folgen.
Visual Studio Code für Ihre Livy-API-Batch-Konfiguration einrichten
Wählen Sie Lakehouse-Einstellungen in Ihrem Fabric Lakehouse aus.

Navigieren Sie zum Abschnitt Livy-Endpunkt.
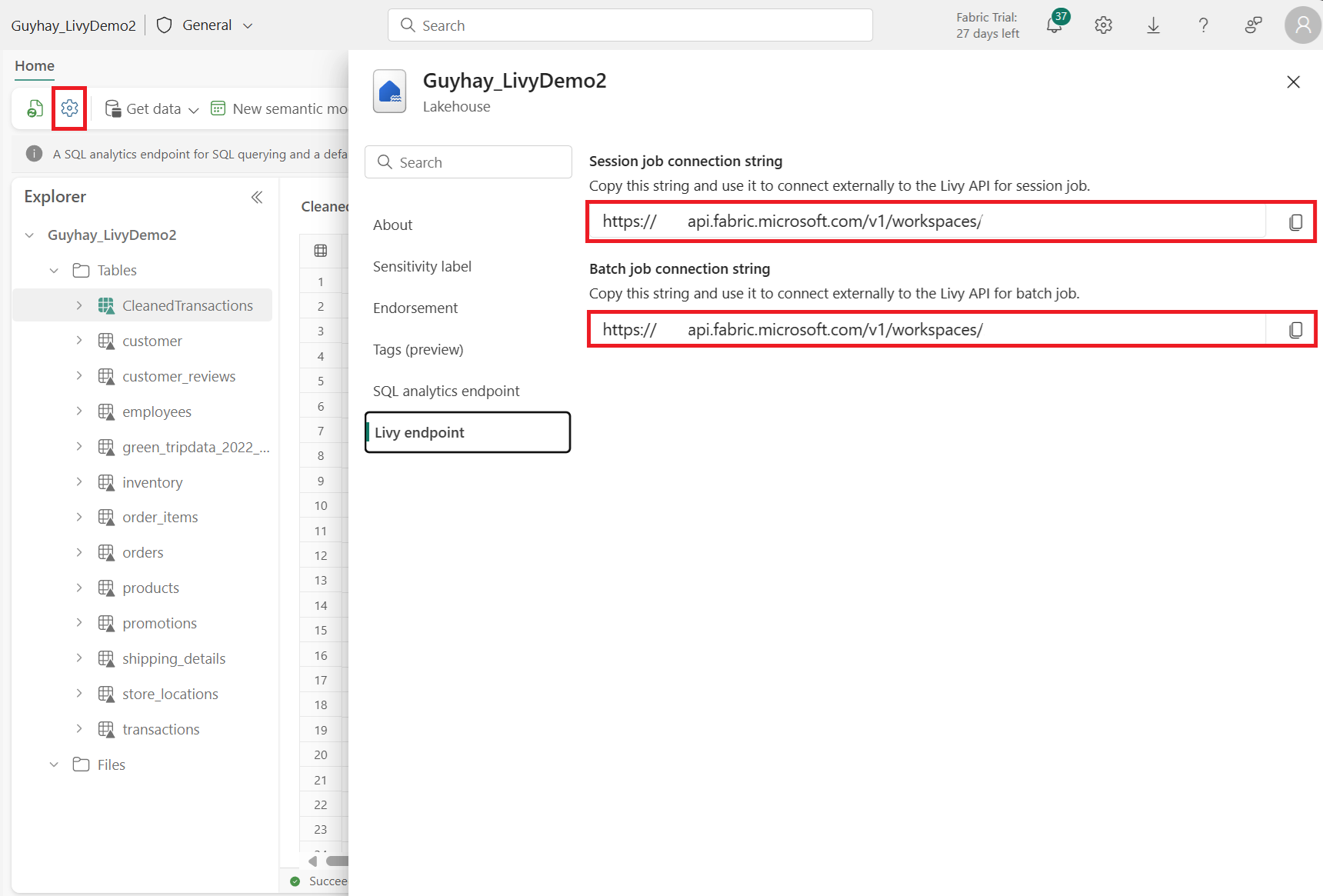
Kopieren Sie die Batch-Verbindungszeichenfolge aus dem zweiten roten Feld im Bild in Ihren Code.
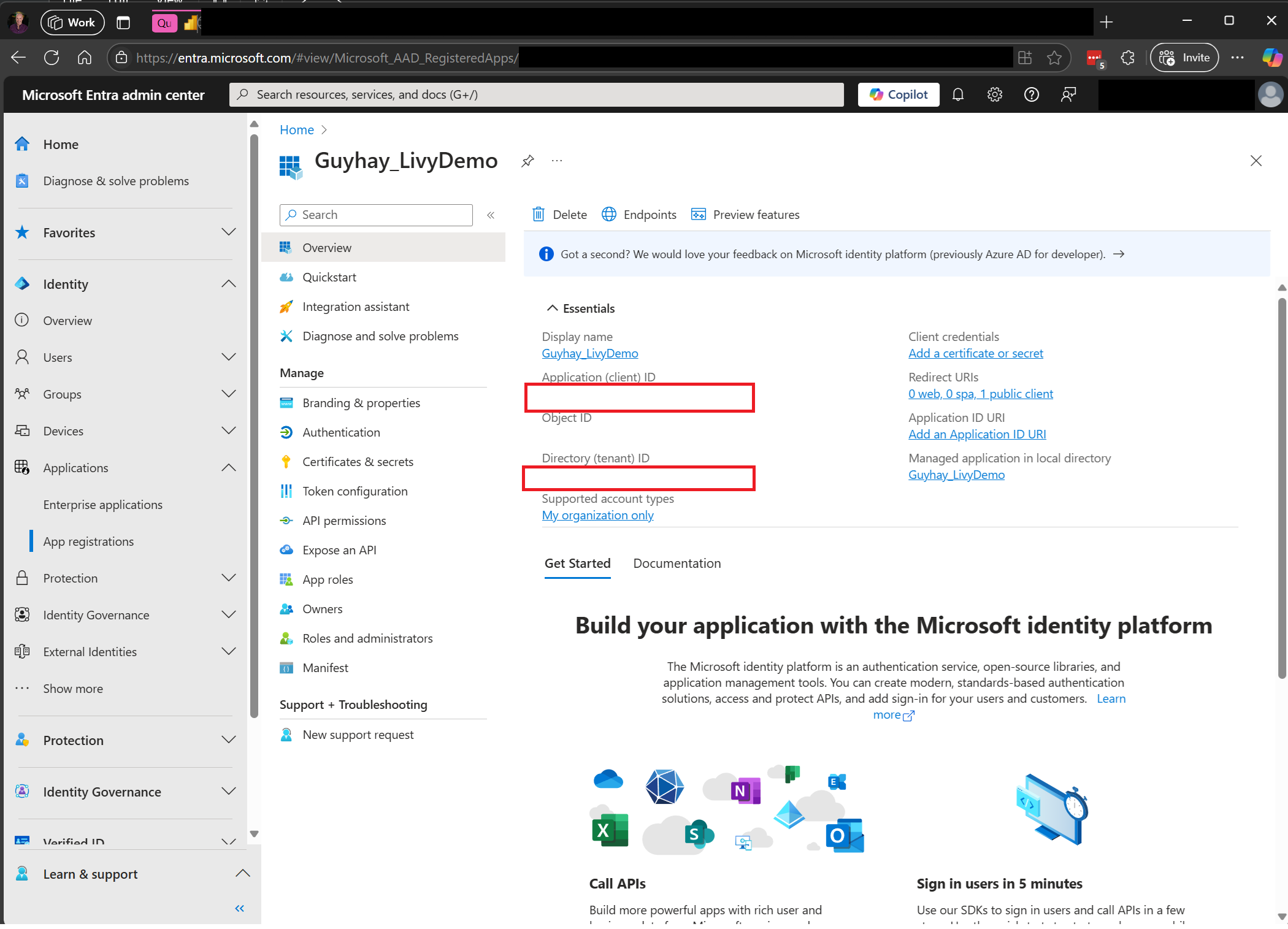
Navigieren Sie zu Microsoft Entra admin center, und kopieren Sie sowohl die Anwendungs-ID (Client-ID) als auch die Verzeichnis-ID (Mandant) in Ihren Code.



Erstellen Sie einen Spark Batch-Code und laden Sie es in das Lakehouse hoch.
Erstellen eines
.ipynb-Notizbuchs in Visual Studio Code und Einfügen des folgenden Codesimport sys import os from pyspark.sql import SparkSession from pyspark.conf import SparkConf from pyspark.sql.functions import col if __name__ == "__main__": #Spark session builder spark_session = (SparkSession .builder .appName("batch_demo") .getOrCreate()) spark_context = spark_session.sparkContext spark_context.setLogLevel("DEBUG") tableName = spark_context.getConf().get("spark.targetTable") if tableName is not None: print("tableName: " + str(tableName)) else: print("tableName is None") df_valid_totalPrice = spark_session.sql("SELECT * FROM green_tripdata_2022 where total_amount > 0") df_valid_totalPrice_plus_year = df_valid_totalPrice.withColumn("transaction_year", col("lpep_pickup_datetime").substr(1, 4)) deltaTablePath = f"Tables/{tableName}CleanedTransactions" df_valid_totalPrice_plus_year.write.mode('overwrite').format('delta').save(deltaTablePath)Speichern Sie die Python Datei lokal. Diese Python-Code-Payload enthält zwei Spark-Anweisungen, die Daten in einem Lakehouse bearbeiten und in Ihr Lakehouse hochgeladen werden müssen. Sie benötigen den Pfad des ABFS (Azure Blob File System) der Nutzlast, um darauf in Ihrem Livy-API-Batchauftrag in Visual Studio Code und in Ihrem Lakehouse-Tabellennamen in der SQL-Anweisung
SELECTzu verweisen.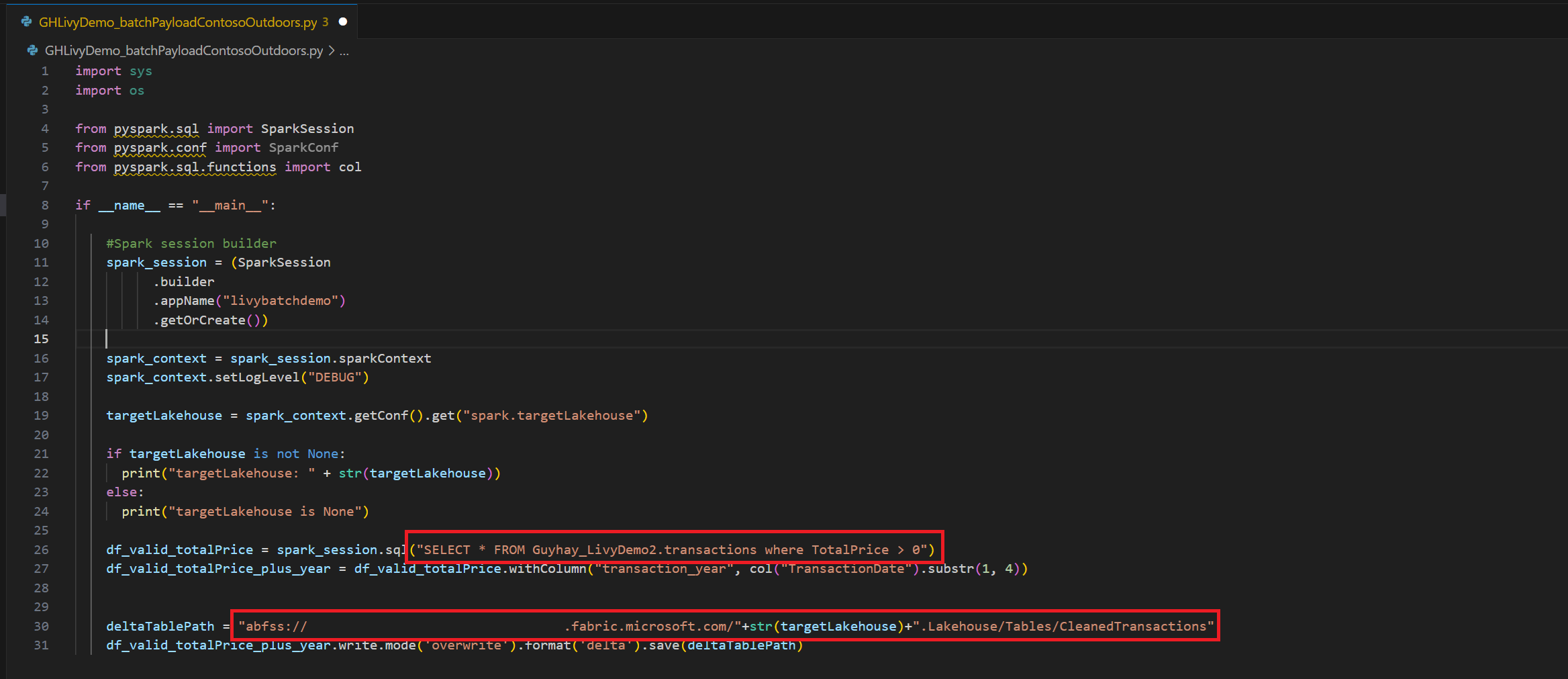
Laden Sie die Python-Payload in den Dateienbereich Ihres Lakehouse hoch. Wählen Sie im Lakehouse-Explorer "Dateien" aus. Wählen Sie >Data abrufen>Dateien hochladen aus. Wählen Sie Dateien über die Dateiauswahl aus.
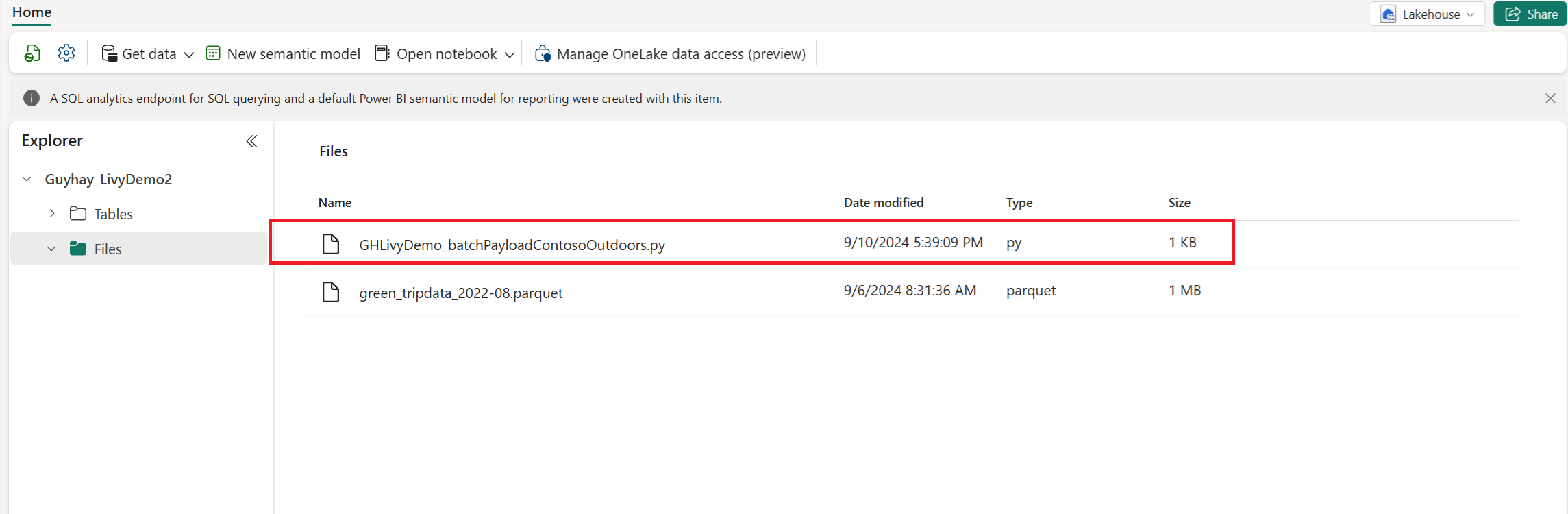
Nachdem sich die Datei im Abschnitt "Dateien" Ihres Lakehouse befindet, wählen Sie die drei Punkte (Auslassungspunkte) rechts neben dem Dateinamen der Nutzlast aus, und wählen Sie "Eigenschaften" aus.
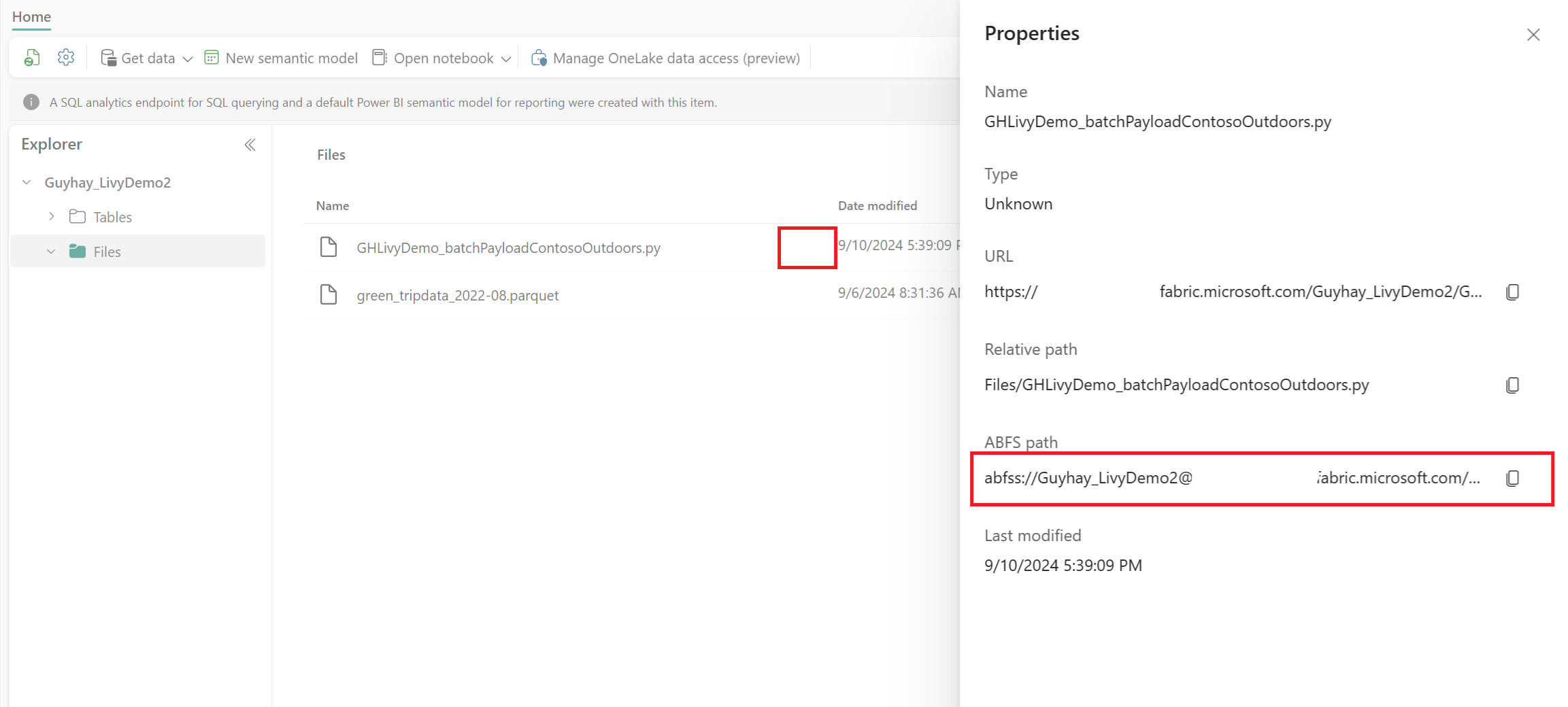
Kopieren Sie diesen ABFS-Pfad in Ihre Notebookzelle in Schritt 1.



Authentifizieren einer Spark-Batchsitzung der Livy-API mithilfe eines Microsoft Entra Benutzertokens oder eines Microsoft Entra SPN-Tokens
Authentifizieren einer Livy-API Spark-Batchsitzung mit einem Microsoft Entra SPN-Token
Erstellen Sie in Visual Studio Code ein
.ipynb-Notizbuch, und fügen Sie den folgenden Code ein.import sys from msal import ConfidentialClientApplication # Configuration - Replace with your actual values tenant_id = "Entra_TenantID" # Microsoft Entra tenant ID client_id = "Entra_ClientID" # Service Principal Application ID # Certificate paths - Update these paths to your certificate files certificate_path = "PATH_TO_YOUR_CERTIFICATE.pem" # Public certificate file private_key_path = "PATH_TO_YOUR_PRIVATE_KEY.pem" # Private key file certificate_thumbprint = "YOUR_CERTIFICATE_THUMBPRINT" # Certificate thumbprint # OAuth settings audience = "https://analysis.windows.net/powerbi/api/.default" authority = f"https://login.windows.net/{tenant_id}" def get_access_token(client_id, audience, authority, certificate_path, private_key_path, certificate_thumbprint=None): """ Get an app-only access token for a Service Principal using OAuth 2.0 client credentials flow. This function uses certificate-based authentication which is more secure than client secrets. Args: client_id (str): The Service Principal's client ID audience (str): The audience for the token (resource scope) authority (str): The OAuth authority URL certificate_path (str): Path to the certificate file (.pem format) private_key_path (str): Path to the private key file (.pem format) certificate_thumbprint (str): Certificate thumbprint (optional but recommended) Returns: str: The access token for API authentication Raises: Exception: If token acquisition fails """ try: # Read the certificate from PEM file with open(certificate_path, "r", encoding="utf-8") as f: certificate_pem = f.read() # Read the private key from PEM file with open(private_key_path, "r", encoding="utf-8") as f: private_key_pem = f.read() # Create the confidential client application app = ConfidentialClientApplication( client_id=client_id, authority=authority, client_credential={ "private_key": private_key_pem, "thumbprint": certificate_thumbprint, "certificate": certificate_pem } ) # Acquire token using client credentials flow token_response = app.acquire_token_for_client(scopes=[audience]) if "access_token" in token_response: print("Successfully acquired access token") return token_response["access_token"] else: raise Exception(f"Failed to retrieve token: {token_response.get('error_description', 'Unknown error')}") except FileNotFoundError as e: print(f"Certificate file not found: {e}") sys.exit(1) except Exception as e: print(f"Error retrieving token: {e}", file=sys.stderr) sys.exit(1) # Get the access token token = get_access_token(client_id, audience, authority, certificate_path, private_key_path, certificate_thumbprint)Führen Sie die Notizbuchzelle aus; wenn alles korrekt ist, sollte das Microsoft Entra-Token zurückgegeben werden.
Screenshot mit dem Microsoft Entra SPN-Token, das nach dem Ausführen von cell.
Authentifizieren einer Livy-API Spark-Sitzung mit einem Microsoft Entra Benutzertoken
Erstellen Sie in Visual Studio Code ein
.ipynb-Notizbuch, und fügen Sie den folgenden Code ein.from msal import PublicClientApplication import requests import time # Configuration - Replace with your actual values tenant_id = "Entra_TenantID" # Microsoft Entra tenant ID client_id = "Entra_ClientID" # Application ID (can be the same as above or different) # Required scopes for Livy API access scopes = [ "https://api.fabric.microsoft.com/Lakehouse.Execute.All", # Required — execute operations in lakehouses "https://api.fabric.microsoft.com/Lakehouse.Read.All", # Required — read lakehouse metadata "https://api.fabric.microsoft.com/Code.AccessFabric.All", # Required — general Fabric API access from Spark Runtime "https://api.fabric.microsoft.com/Code.AccessStorage.All", # Required — access OneLake and Azure storage from Spark Runtime ] # Optional scopes — add these only if your Spark jobs need access to the corresponding services: # "https://api.fabric.microsoft.com/Code.AccessAzureKeyvault.All" # Optional — access Azure Key Vault from Spark Runtime # "https://api.fabric.microsoft.com/Code.AccessAzureDataLake.All" # Optional — access Azure Data Lake Storage Gen1 from Spark Runtime # "https://api.fabric.microsoft.com/Code.AccessAzureDataExplorer.All" # Optional — access Azure Data Explorer from Spark Runtime # "https://api.fabric.microsoft.com/Code.AccessSQL.All" # Optional — access Azure SQL audience tokens from Spark Runtime def get_access_token(tenant_id, client_id, scopes): """ Get an access token using interactive authentication. This method will open a browser window for user authentication. Args: tenant_id (str): The Azure Active Directory tenant ID client_id (str): The application client ID scopes (list): List of required permission scopes Returns: str: The access token, or None if authentication fails """ app = PublicClientApplication( client_id, authority=f"https://login.microsoftonline.com/{tenant_id}" ) print("Opening browser for interactive authentication...") token_response = app.acquire_token_interactive(scopes=scopes) if "access_token" in token_response: print("Successfully authenticated") return token_response["access_token"] else: print(f"Authentication failed: {token_response.get('error_description', 'Unknown error')}") return None # Uncomment the lines below to use interactive authentication token = get_access_token(tenant_id, client_id, scopes) print("Access token acquired via interactive login")Führen Sie das Notebookfenster aus. In Ihrem Browser sollte ein Popupfenster erscheinen, in dem Sie die Identität auswählen können, mit der Sie sich anmelden möchten.
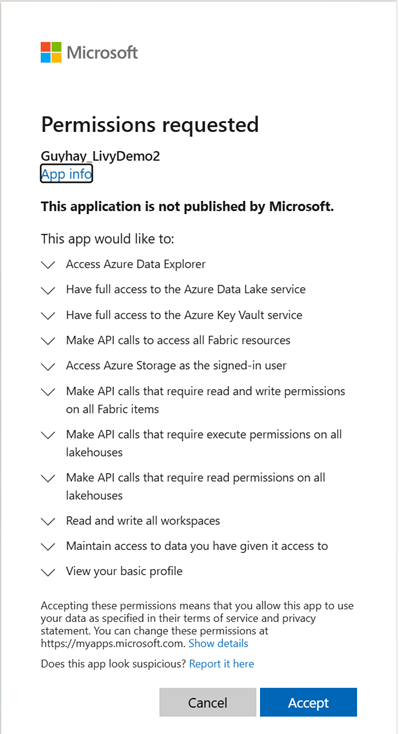
Nachdem Sie die Identität für die Anmeldung ausgewählt haben, müssen Sie die berechtigungen der Microsoft Entra App-Registrierungs-API genehmigen.
Schließen Sie das Browserfenster nach Abschluss der Authentifizierung.

In Visual Studio Code sollte das Microsoft Entra-Token angezeigt werden.
Screenshot, der das Microsoft Entra Token zeigt, das nach dem Ausführen der Zelle und der Anmeldung zurückgegeben wird.



Grundlegendes zu Code.* Bereichen für die Livy-API
Wenn Ihre Spark-Aufträge über die Livy-API ausgeführt werden, steuern die Code.* Bereiche, auf welche externen Dienste die Spark Runtime im Namen des authentifizierten Benutzers zugreifen kann. Zwei sind erforderlich; der Rest ist je nach Workload optional.
Erforderliche Code.* Umfänge
| Geltungsbereich | Beschreibung |
|---|---|
Code.AccessFabric.All |
Ermöglicht das Abrufen von Zugriffstoken für Microsoft Fabric. Erforderlich für alle Livy-API-Vorgänge. |
Code.AccessStorage.All |
Ermöglicht das Abrufen von Zugriffstoken für OneLake und Azure. Erforderlich für das Lesen und Schreiben von Daten in Seehäusern. |
Optionaler Code.* Gültigkeitsbereiche
Fügen Sie diese Bereiche nur hinzu, wenn Ihre Spark-Aufträge zur Laufzeit auf die entsprechenden Azure-Dienste zugreifen müssen.
| Geltungsbereich | Beschreibung | Wann verwenden? |
|---|---|---|
Code.AccessAzureKeyvault.All |
Ermöglicht das Abrufen von Zugriffstoken zum Azure Key Vault. | Ihr Spark-Code ruft geheime Schlüssel, Schlüssel oder Zertifikate aus Azure Key Vault ab. |
Code.AccessAzureDataLake.All |
Ermöglicht das Abrufen von Zugriffstoken zum Azure Data Lake Storage Gen1. | Ihr Spark-Code liest aus oder schreibt auf die Azure Data Lake Storage Gen1 Konten. |
Code.AccessAzureDataExplorer.All |
Ermöglicht das Abrufen von Zugangstoken für den Azure Data Explorer (Kusto). | Ihr Spark-Code führt Abfragen an Azure Data Explorer-Cluster durch oder erfasst Daten von diesen. |
Code.AccessSQL.All |
Ermöglicht das Abrufen von Zugriffstoken zum Azure SQL. | Ihr Spark-Code muss eine Verbindung mit Azure SQL Datenbanken herstellen. |
Hinweis
Die Lakehouse.Execute.All- und Lakehouse.Read.All-Bereiche sind ebenfalls erforderlich, jedoch nicht Teil der Code.*-Familie. Sie erteilen die Berechtigung zum Ausführen von Vorgängen in und lesen Metadaten aus Fabric Seehäusern.
Übermitteln Sie einen Livy-Stapel und überwachen Sie den Stapelauftrag.
Fügen Sie eine weitere Notebookzelle hinzu, und fügen Sie diesen Code ein.
# submit payload to existing batch session import requests import time import json api_base_url = "https://api.fabric.microsoft.com/v1" # Base URL for Fabric APIs # Fabric Resource IDs - Replace with your workspace and lakehouse IDs workspace_id = "Fabric_WorkspaceID" lakehouse_id = "Fabric_LakehouseID" # Construct the Livy Batch API URL # URL pattern: {base_url}/workspaces/{workspace_id}/lakehouses/{lakehouse_id}/livyApi/versions/{api_version}/batches livy_base_url = f"{api_base_url}/workspaces/{workspace_id}/lakehouses/{lakehouse_id}/livyApi/versions/2023-12-01/batches" # Set up authentication headers headers = {"Authorization": f"Bearer {token}"} print(f"Livy Batch API URL: {livy_base_url}") new_table_name = "TABLE_NAME" # Name for the new table # Configure the batch job print("Configuring batch job parameters...") # Batch job configuration - Modify these values for your use case payload_data = { # Job name - will appear in the Fabric UI "name": f"livy_batch_demo_{new_table_name}", # Path to your Python file in the lakehouse "file": "<ABFSS_PATH_TO_YOUR_PYTHON_FILE>", # Replace with your Python file path # Optional: Spark configuration parameters "conf": { "spark.targetTable": new_table_name, # Custom configuration for your application }, } print("Batch Job Configuration:") print(json.dumps(payload_data, indent=2)) try: # Submit the batch job print("\nSubmitting batch job...") post_batch = requests.post(livy_base_url, headers=headers, json=payload_data) if post_batch.status_code == 202: batch_info = post_batch.json() print("Livy batch job submitted successfully!") print(f"Batch Job Info: {json.dumps(batch_info, indent=2)}") # Extract batch ID for monitoring batch_id = batch_info['id'] livy_batch_get_url = f"{livy_base_url}/{batch_id}" print(f"\nBatch Job ID: {batch_id}") print(f"Monitoring URL: {livy_batch_get_url}") else: print(f"Failed to submit batch job. Status code: {post_batch.status_code}") print(f"Response: {post_batch.text}") except requests.exceptions.RequestException as e: print(f"Network error occurred: {e}") except json.JSONDecodeError as e: print(f"JSON decode error: {e}") print(f"Response text: {post_batch.text}") except Exception as e: print(f"Unexpected error: {e}")Führen Sie die Notebook-Zelle aus. Es sollten mehrere Zeilen ausgegeben werden, wenn der Livy Batch-Auftrag erstellt und ausgeführt wird.

Um alle Änderungen zu sehen, gehen Sie zurück zu Ihrem Lakehouse.

Integration in Fabric Umgebungen
Diese Livy-API-Sitzung wird standardmäßig für den Standardstartpool für den Arbeitsbereich ausgeführt. Alternativ können Sie Fabric Umgebungen Erstellen, Konfigurieren und Verwenden einer Umgebung in Microsoft Fabric zum Anpassen des Spark-Pools, den die Livy-API-Sitzung für diese Spark-Aufträge verwendet. Wenn Sie Ihre Fabric-Umgebung verwenden möchten, aktualisieren Sie die vorherige Notizbuchzelle mit dieser Änderung.
payload_data = {
"name":"livybatchdemo_with"+ newlakehouseName,
"file":"abfss://YourABFSPathToYourPayload.py",
"conf": {
"spark.targetLakehouse": "Fabric_LakehouseID",
"spark.fabric.environmentDetails" : "{\"id\" : \""EnvironmentID"\"}" # remove this line to use starter pools instead of an environment, replace "EnvironmentID" with your environment ID
}
}
Anzeigen Ihrer Aufträge im Überwachungshub
Sie können auf den Überwachungshub zugreifen, um verschiedene Apache Spark-Aktivitäten anzuzeigen, indem Sie in den Navigationslinks auf der linken Seite „Überwachen“ auswählen.
Wenn der Batchauftrag abgeschlossen ist, können Sie den Sitzungsstatus anzeigen, indem Sie zu Monitor navigieren.
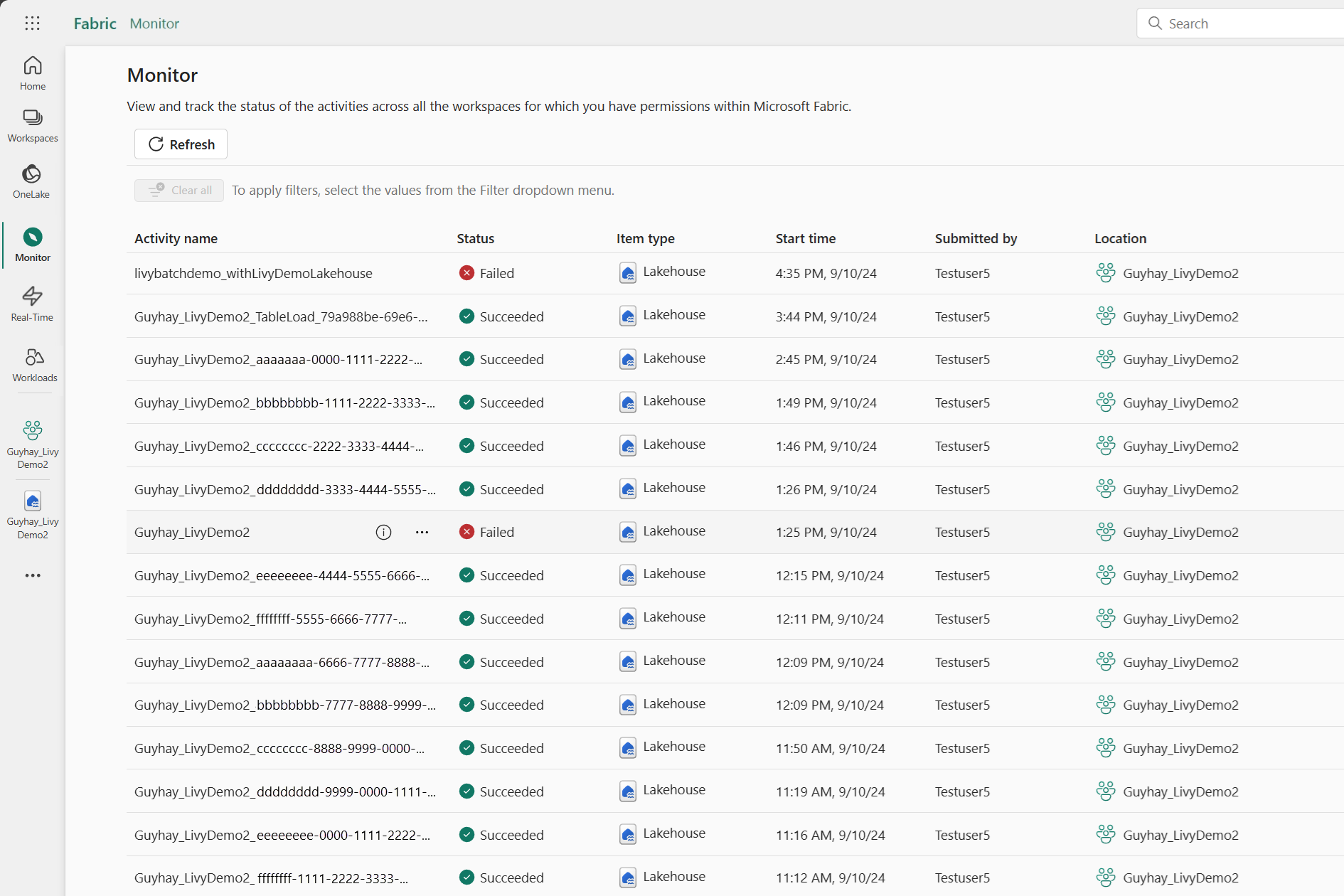
Wählen Sie den Namen der letzten Aktivität aus, und öffnen Sie sie.
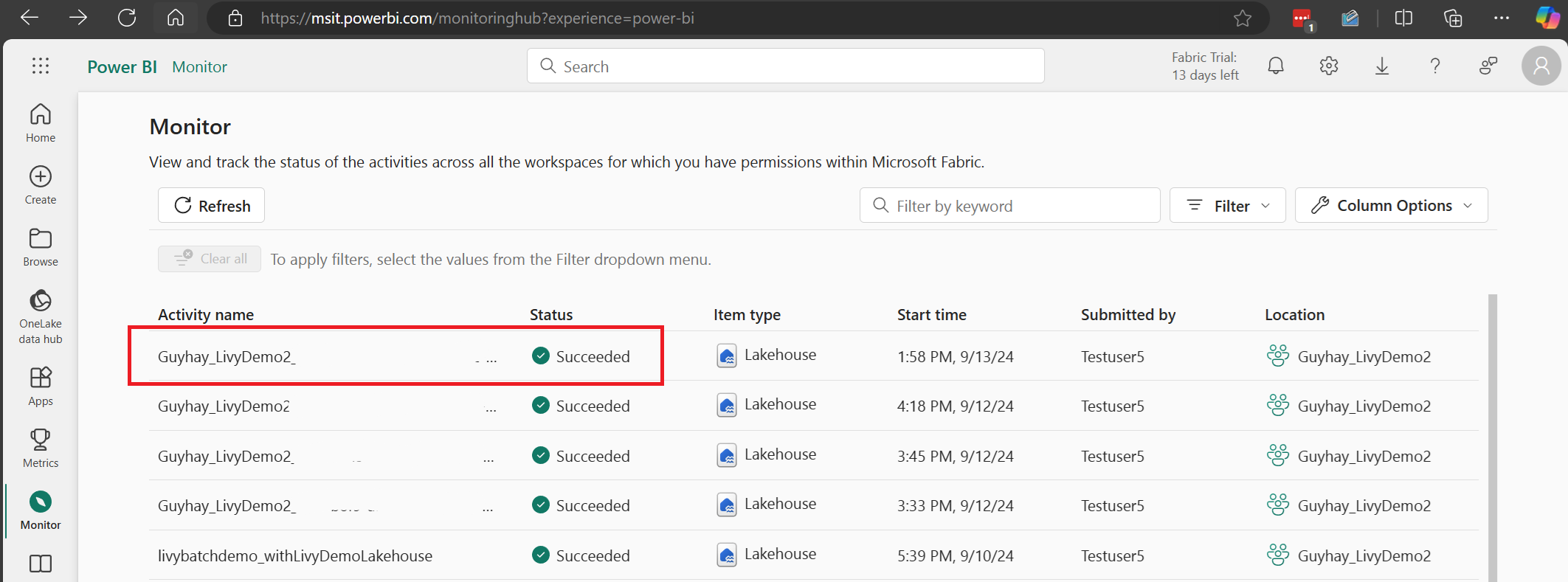
In diesem Livy-API-Sitzungsszenario können Sie Ihre vorherigen Batch-Einsendungen, Ausführungsdetails, Spark-Versionen und Konfigurationen einsehen. Beachten Sie den Status „Angehalten“ oben rechts.
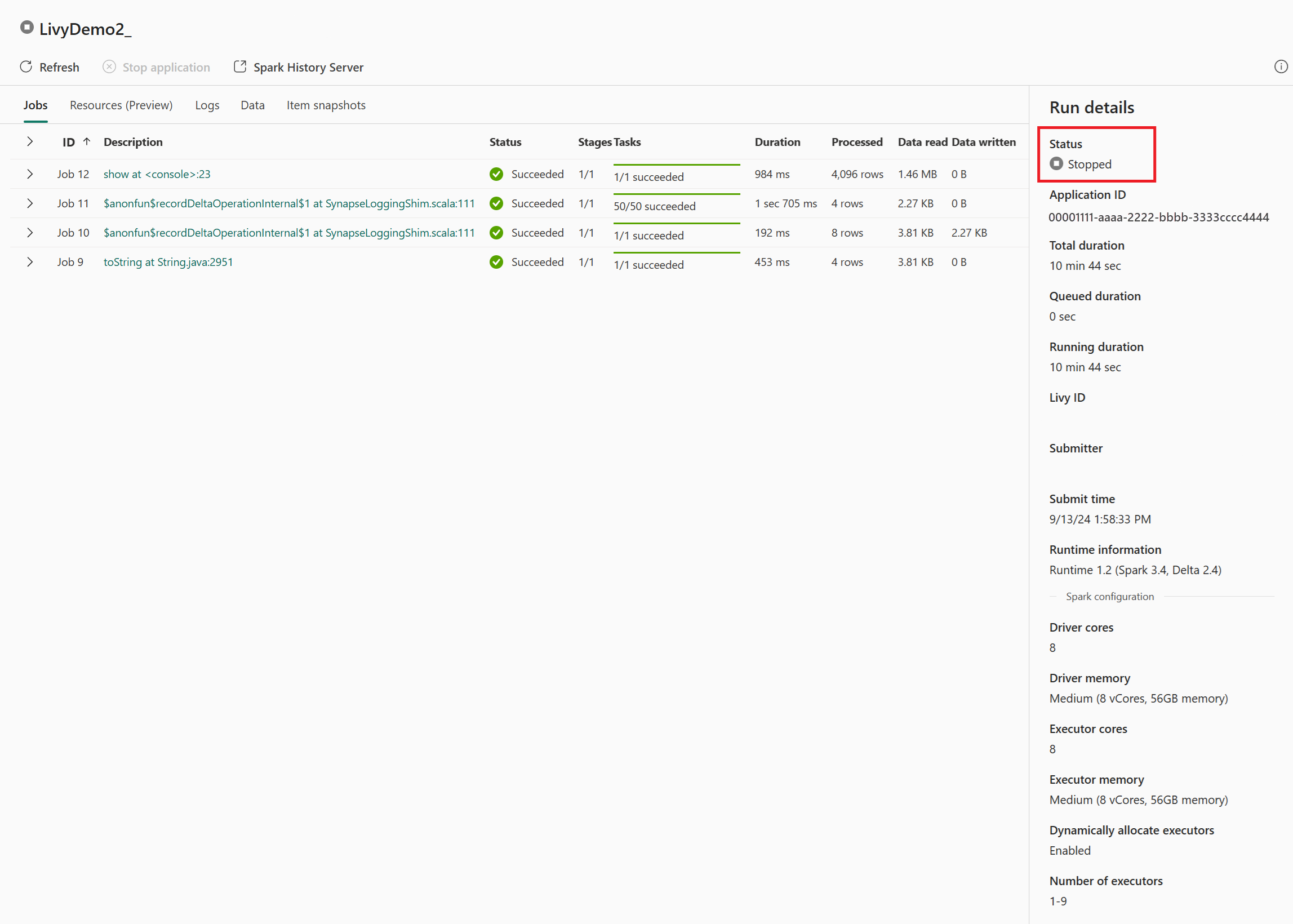



Um den gesamten Prozess zusammenzufassen, benötigen Sie einen Remote-Client wie Visual Studio Code, ein Microsoft Entra App-Token, die Livy-API-Endpunkt-URL, die Authentifizierung für Ihr Lakehouse, eine Spark-Nutzlast in Ihrem Lakehouse und schließlich eine Batch-Livy-API-Sitzung.