Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
Wenn Sie Spark-Auftragsdefinitionen (Spark Job Definitions, SJDs) von Azure Synapse zu Fabric migrieren möchten, haben Sie zwei Optionen:
- Option 1: Manuelles Erstellen einer Spark-Auftragsdefinition in Fabric.
- Option 2: Sie können ein Skript verwenden, um Spark-Auftragsdefinitionen aus Azure Synapse zu exportieren und mithilfe der API in Fabric zu importieren.
Überlegungen zu Spark-Auftragsdefinitionen finden Sie unter Unterschiede zwischen Azure Synapse Spark und Fabric.
Voraussetzungen
Erstellen Sie einen Fabric-Arbeitsbereich in Ihrem Mandanten, falls noch keiner vorhanden ist.
Option 1: Manuelles Erstellen einer Spark-Auftragsdefinition
So exportieren Sie eine Spark-Auftragsdefinition aus Azure Synapse
- Öffnen Sie Synapse Studio: Melden Sie sich bei Azure an. Navigieren Sie zu Ihrem Azure Synapse-Arbeitsbereich, und öffnen Sie Synapse Studio.
- Suchen Sie den Python/Scala/R Spark-Auftrag: Identifizieren Sie die Python-/Scala-/R Spark-Auftragsdefinition, die Sie migrieren möchten.
- Exportieren Sie die Konfiguration der Auftragsdefinition:
- Öffnen Sie die Apache Spark-Auftragsdefinition in Synapse Studio.
- Exportieren Sie die Konfigurationseinstellungen (einschließlich Skriptdateispeicherort, Abhängigkeiten, Parametern und anderen relevanten Details), oder notieren Sie sie sich.
So erstellen Sie eine neue Spark-Auftragsdefinition (Spark Job Definition, SJD) auf der Grundlage der exportierten SJD-Informationen in Fabric:
- Auf den Fabric-Arbeitsbereich zugreifen: Melden Sie sich bei Fabric an, und greifen Sie auf Ihren Arbeitsbereich zu.
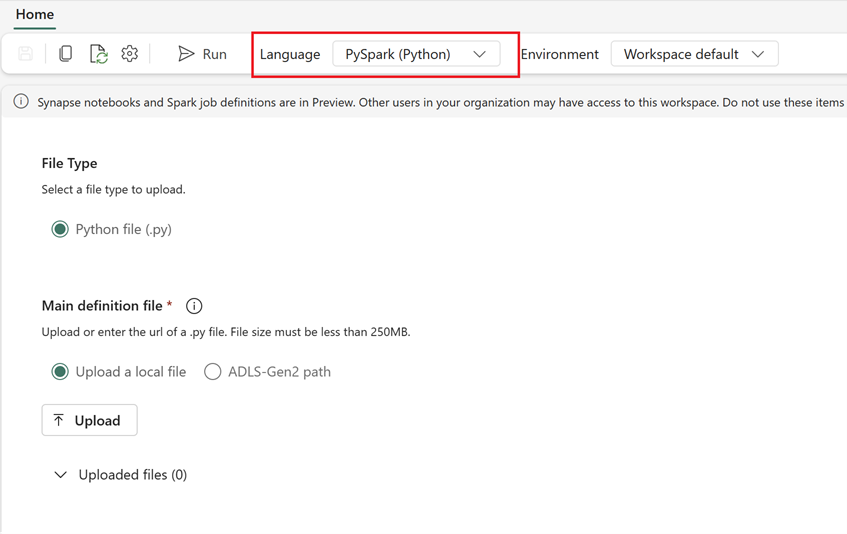
- Erstellen Sie eine neue Spark-Auftragsdefinition in Fabric:
- Navigieren Sie in Fabric zur Datentechnik-Homepage.
- Wählen Sie Spark-Auftragsdefinition aus.
- Konfigurieren Sie den Auftrag mit den Informationen, die Sie aus Synapse exportiert haben (einschließlich Skriptspeicherort, Abhängigkeiten, Parametern und Clustereinstellungen).
- Anpassen und testen: Nehmen Sie alle für die Fabric-Umgebung erforderlichen Anpassungen am Skript oder an der Konfiguration vor. Testen Sie den Auftrag in Fabric, um sicherzustellen, dass er ordnungsgemäß ausgeführt wird.
Überprüfen nach der Erstellung der Spark-Auftragsdefinition die Abhängigkeiten:
- Stellen Sie sicher, dass Sie die gleiche Spark-Version verwenden.
- Überprüfen Sie das Vorhandensein der Hauptdefinitionsdatei.
- Überprüfen Sie das Vorhandensein der referenzierten Dateien, Abhängigkeiten und Ressourcen.
- Verknüpfte Dienste, Datenquellenverbindungen und Bereitstellungspunkte.
Weitere Informationen zum Erstellen einer Apache Spark-Auftragsdefinition in Fabric finden Sie hier.
Option 2: Verwenden der Fabric-API
Führen Sie die folgenden wichtigen Schritte für die Migration aus:
- Voraussetzungen
- Schritt 1: Exportieren Sie die Spark-Auftragsdefinition von Azure Synapse zu OneLake (JSON).
- Schritt 2: Importieren Sie die Spark-Auftragsdefinition mithilfe der Fabric-API automatisch in Fabric.
Voraussetzungen
Zu den Voraussetzungen gehören Aktionen, die Sie berücksichtigen müssen, bevor Sie die Migration der Spark-Auftragsdefinition zu Fabric starten.
- Ein Fabric-Arbeitsbereich.
- Erstellen Sie ein Fabric Lakehouse in Ihrem Arbeitsbereich, falls noch keins vorhanden ist.
Schritt 1: Exportieren der Spark-Auftragsdefinition aus dem Azure Synapse-Arbeitsbereich
Der Fokus von Schritt 1 liegt auf dem Exportieren der Spark-Auftragsdefinition aus dem Azure Synapse-Arbeitsbereich in OneLake im JSON-Format. Dieser Prozess läuft wie folgt ab:
- 1.1) Importieren Sie das SJD-Migrations-Notebook in den Arbeitsbereich Fabric. Dieses Notebook exportiert alle Spark-Auftragsdefinitionen aus einem bestimmten Azure Synapse-Arbeitsbereich in ein Zwischenverzeichnis in OneLake. Die Synapse-API wird zum Exportieren von SJDs verwendet.
- 1.2) Konfigurieren Sie die Parameter im ersten Befehl zum Exportieren der Spark-Auftragsdefinition in einen Zwischenspeicher (OneLake). Dadurch wird nur die JSON-Metadatendatei exportiert. Der folgende Codeschnipsel wird verwendet, um die Quell- und Zielparameter zu konfigurieren. Diese müssen durch Ihre eigenen Werte ersetzt werden.
# Azure config
azure_client_id = "<client_id>"
azure_tenant_id = "<tenant_id>"
azure_client_secret = "<client_secret>"
# Azure Synapse workspace config
synapse_workspace_name = "<synapse_workspace_name>"
# Fabric config
workspace_id = "<workspace_id>"
lakehouse_id = "<lakehouse_id>"
export_folder_name = f"export/{synapse_workspace_name}"
prefix = "" # this prefix is used during import {prefix}{sjd_name}
output_folder = f"abfss://{workspace_id}@onelake.dfs.fabric.microsoft.com/{lakehouse_id}/Files/{export_folder_name}"
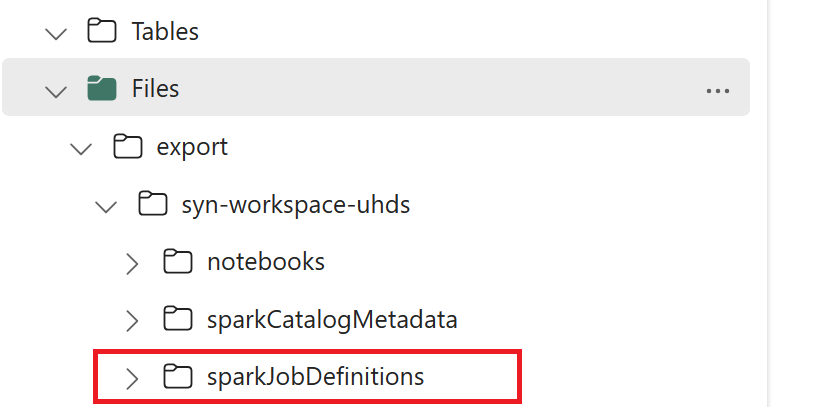
- 1.3) Führen Sie die ersten beiden Zellen des Export-/Import-Notebooks aus, um die Metadaten der Spark-Auftragsdefinition nach OneLake zu exportieren. Nach Abschluss der Zellen wird diese Ordnerstruktur unter dem Zwischenausgabeverzeichnis erstellt.
Schritt 2: Importieren der Spark-Auftragsdefinition in Fabric
Schritt 2 erfolgt, wenn Spark-Auftragsdefinitionen aus dem Zwischenspeicher in den Fabric-Arbeitsbereich importiert werden. Dieser Prozess läuft wie folgt ab:
- 2.1) Überprüfen Sie die Konfigurationen in Schritt 1.2, um sicherzustellen, dass der richtige Arbeitsbereich und das richtige Präfix angegeben sind, um die Spark-Auftragsdefinitionen zu importieren.
- 2.2) Führen Sie die dritte Zelle des Export-/Import-Notebooks aus, um alle Spark-Auftragsdefinitionen aus dem Zwischenspeicherort zu importieren.
Hinweis
Die Exportoption gibt eine JSON-Metadatendatei aus. Stellen Sie sicher, dass ausführbare Dateien, Referenzdateien und Argumente der Spark-Auftragsdefinition über Fabric zugänglich sind.