Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
Die Fabric-Runtime bietet eine nahtlose Integration in Azure. Sie bietet eine fortschrittliche Umgebung für Datentechnik- und Data Science-Projekte, bei denen Apache Spark zum Einsatz kommt. Dieser Artikel enthält eine Übersicht über die wesentlichen Features und Komponenten von Fabric Runtime 1.3.
Microsoft Fabric Runtime 1.3 ist eine GA-Laufzeitversion, die die folgenden Komponenten und Upgrades enthält, die entwickelt wurden, um Ihre Datenverarbeitungsfunktionen zu verbessern:
- Apache Spark 3.5
- Betriebssystem: Mariner 2.0 (Azure Linux 2.0)
- Java: 11
- Skala: 2.12.17
- Python: 3.11
- Delta Lake: 3.2
- R: 4.4.1
Important
Der Early Access-Kanal von Runtime 1.3 umfasst ein aktualisiertes Betriebssystem von Mariner 2.0 (Azure Linux 2.0) auf Mariner 3.0 (Azure Linux 3.0). Verwenden Sie den Frühzugriffs-Releasekanal, um Ihre Workloads im Hinblick auf diese Änderung zu testen, bevor sie zur Standardeinstellung wird. Diese Überprüfung ist wichtig, insbesondere, wenn Ihre Workloads Abhängigkeiten von Paketen auf Betriebssystemebene haben.
Tipp
Fabric Runtime 1.3 enthält Unterstützung für das native Ausführungsmodul, das die Leistung ohne mehr Kosten erheblich verbessern kann. Um das Native Execution Engine für alle Aufträge und Notebooks in Ihrer Umgebung zu aktivieren, navigieren Sie zu Ihren Umgebungseinstellungen, wählen Sie Spark-Compute aus, wechseln Sie zur Registerkarte „Beschleunigung“ und aktivieren Sie das Native Execution Engine. Nachdem Sie diese Einstellung gespeichert und veröffentlicht haben, wird diese Einstellung in der gesamten Umgebung angewendet, sodass alle neuen Aufträge und Notizbücher automatisch erben und von den erweiterten Leistungsfunktionen profitieren.
Integrieren von Runtime 1.3
Hinweis
Informationen zu allen verfügbaren Fabric-Runtimes und ihrem aktuellen Status finden Sie unter Apache Spark Runtimes in Fabric.
Halten Sie sich an die folgenden Anweisungen, um die Runtime 1.3 in Ihren Arbeitsbereich zu integrieren und die neuen Features zu verwenden:
Navigieren Sie im Fabric-Arbeitsbereich zur Registerkarte Arbeitsbereichseinstellungen.
Wechseln Sie zur Registerkarte Datentechnik/Data Science, und wählen Sie Spark-Einstellungen aus.
Wählen Sie die Registerkarte Umgebung aus.
Erweitern Sie unter den Runtime-Versionen das Dropdownmenü.
Wählen Sie 1.3 (Spark 3.5, Delta 3.2) aus und speichern Sie Ihre Änderungen. Hiermit wird 1.3 als Standard-Runtime für Ihren Arbeitsbereich festgelegt.
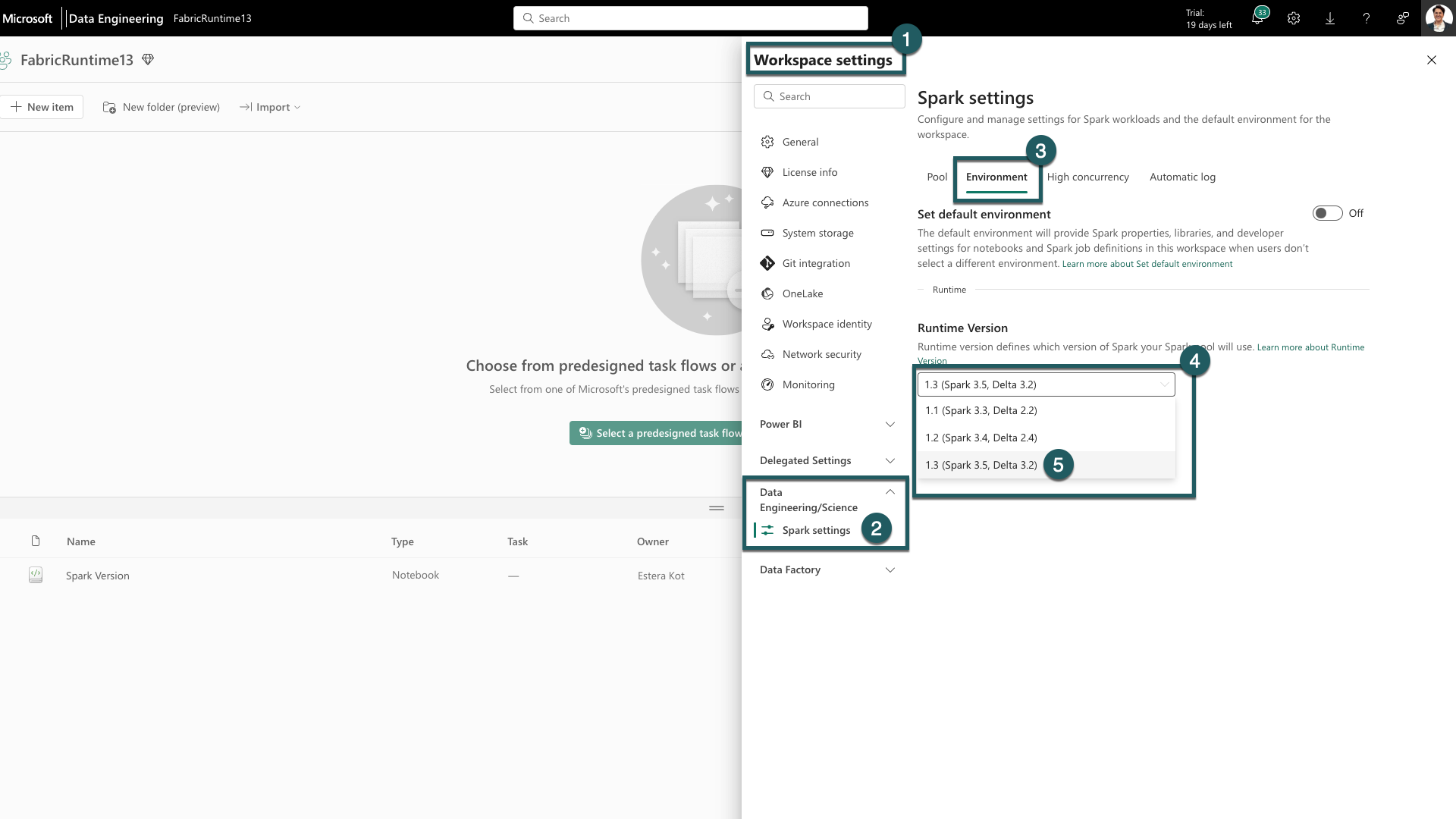

Sie können jetzt mit den neuesten Verbesserungen und Funktionen arbeiten, die in Fabric Runtime 1.3 (Spark 3.5 und Delta Lake 3.2) eingeführt wurden.
Erfahren Sie mehr über Apache Spark 3.5
Apache Spark 3.5.0 ist die sechste Version der 3.x-Reihe. Diese Version ist das Ergebnis einer umfassenden Zusammenarbeit in der Open-Source-Community. Dabei wurden mehr als 1.300 Probleme behoben, wie in Jira aufgezeichnet.
In dieser Version gibt es ein Upgrade in der Kompatibilität für strukturiertes Streaming. Darüber hinaus erweitert diese Version die Funktionalität in PySpark und SQL. Es kommen Features wie die SQL-Bezeichnerklausel, benannte Argumente in SQL-Funktionsaufrufen und die Einbeziehung von SQL-Funktionen für ungefähre HyperLogLog-Aggregationen hinzu.
Zu den weiteren neuen Funktionen gehören benutzerdefinierte Python-Tabellenfunktionen, die Vereinfachung des verteilten Trainings über DeepSpeed und neue Funktionen für strukturiertes Streaming wie die Grenzwertverteilung und der Vorgang DropDuplicatesWithinWatermark.
Hier finden Sie die vollständige Liste und detaillierte Änderungen: Spark Release 3.5.0.
Informationen zu Delta Spark
Delta Lake 3.2 markiert ein gemeinsames Bestreben, Delta Lake übergreifend kompatibel zu machen, die Arbeit damit zu erleichtern und die Leistung zu verbessern. Delta Spark 3.2 basiert auf Apache Spark™ 3.5. Das Delta Spark Maven-Artefakt wird von Delta-Core in Delta-Spark umbenannt.
Die vollständige Liste und detaillierte Änderungen finden Sie hier: https://docs.delta.io/index.html.
Komponenten und Bibliotheken
Um aktuelle Informationen, eine ausführliche Liste der Änderungen und spezifische Versionshinweise für Fabric-Runtimes zu erhalten, sollten Sie Spark-Runtimes – Versionen und Updates lesen und abonnieren.
Hinweis
EventHubConnector ist in Fabric Runtime 1.3 (Spark 3.5) veraltet und wird aus zukünftigen Fabric-Runtime-Versionen entfernt. Kunden werden ermutigt, stattdessen Kafka Spark Connector zu verwenden, da Event Hubs bereits kafka kompatibel sind. Weitere Informationen zur Verwendung von Kafka Spark Connector mit Event Hubs finden Sie hier: Event Hubs Kafka Spark Tutorial
Zugehöriger Inhalt
- Lesen Sie mehr über Apache Spark Runtimes in Fabric – Übersicht, Versionsverwaltung, Unterstützung für mehrere Runtimes und Upgrade des Delta Lake Protocol
- Anleitung zur Migration von Spark Core
- Anleitung zur Migration von SQL, DataSets und DataFrame
- Anleitung zur Migration von strukturiertem Streaming
- Anleitung zur Migration von MLlib (Maschinelles Lernen)
- Anleitung zur Migration von PySpark (Python in Spark)
- Anleitung zur Migration von SparkR (R in Spark)