Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
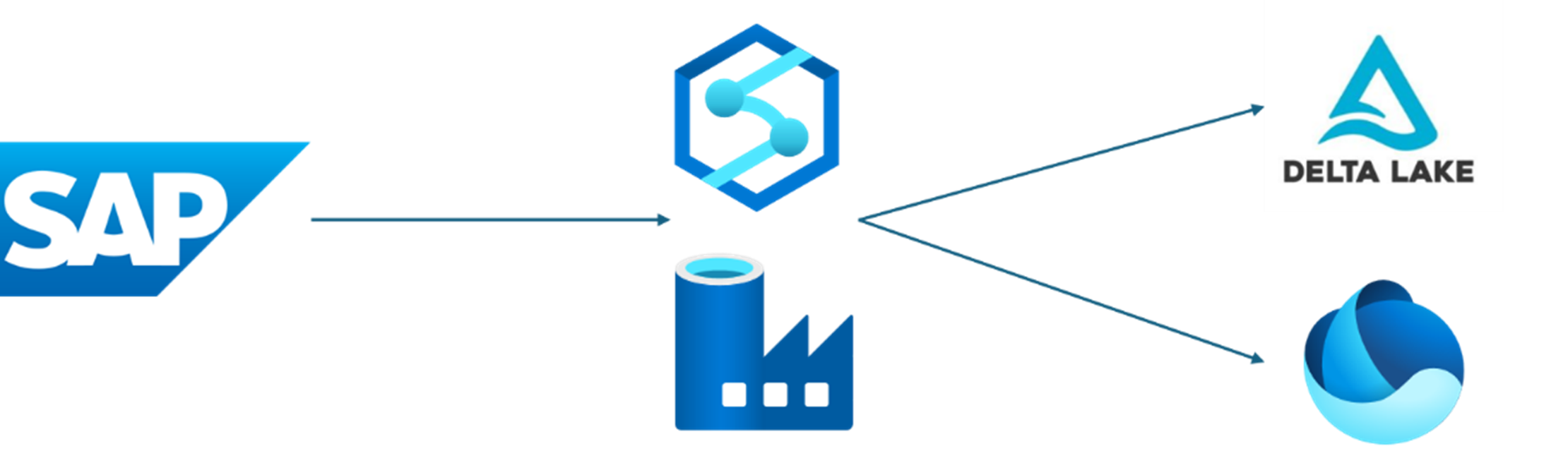
Azure Data Factory (ADF) und Azure Synapse Analytics verfügen über den SAP Change Data Capture (CDC)-Connector (eine Einführung finden Sie unter Übersicht und Architektur der SAP CDC-Funktionen oder Allgemeine Verfügbarkeit von SAP CDC-Funktionen für Azure Data Factory und Azure Synapse Analytics), der integrierte Funktionen für die Änderungsdatenerfassung bietet, die verschiedene SAP-Quellen abdecken. Viele Kunden verwenden diesen Connector, um einen Änderungsdatenfeed von SAP in Delta-Tabellen in ADLS Gen2 einzurichten, was eine großartige Speicheroption für die Eingangsebene (auch als Bronze bezeichnete) in einer Lakehouse-Architektur ist.
In diesem Artikel wird beschrieben, wie Sie den SAP CDC-Connector verwenden, um Ihre Eingangsebene mithilfe von ADF oder Synapse direkt in Microsoft Fabric OneLake zu erstellen.
Die beiden Szenarien sind bei der Einrichtung ähnlich, wobei der Hauptunterschied die Senkenkonfiguration ist. Wie im folgenden Diagramm dargestellt, können Sie einfach einen Datenfluss klonen, der in Delta-Tabellen in Azure Data Lake Storage (ADLS) Gen2 geschrieben wird, die Senkenkonfiguration gemäß diesem Dokument ändern und loslegen.
Wenn Sie beabsichtigen, Ihre SAP-Daten aus ADLS Gen2 in Microsoft Fabric zu migrieren, können Sie sogar einen vorhandenen CDC-Datenfluss von ADLS Gen2 zu OneLake umleiten, indem Sie die Senkenkonfiguration anpassen. Nachdem Sie die Senke geändert haben, können Sie den ursprünglichen CDC-Prozess fortsetzen, sodass Sie nahtlos zu Fabric migrieren können, ohne dass eine mühsame Neuinitialisierung erforderlich ist.
Erste Schritte
Um diesem Artikel Schritt für Schritt in Ihrer eigenen Umgebung zu folgen, benötigen Sie die folgenden Ressourcen:
- ETL mit Azure Data Factory und/oder Synapse Analytics
- Einen Microsoft Fabric-Arbeitsbereich mit einem Lakehouse.
- Ein SAP-System, das die hier angegebenen Anforderungen für den SAP CDC-Connector von ADF erfüllt. In unserem Szenario verwenden wir eine LOKALE SAP S/4HANA 2023 FPS00, aber alle aktuellen Versionen von SAP ECC, SAP BW, SAP BW/4HANA usw. werden ebenfalls unterstützt.
- Eine selbst gehostete Integrationslaufzeit (SHIR), auf der eine aktuelle Version des SAP .NET Connectors installiert ist
Um sich auf die Konnektivität zu konzentrieren, finden Sie hier eine Pipeline-Vorlage, die das einfachste Szenario der Extraktion von Änderungsdaten mit dem SAP CDC Connector und deren Zusammenführung mit einer Fabric Lakehouse-Tabelle ohne weitere Transformationen abdeckt: https://github.com/ukchrist/ADF-SAP-data-flows/blob/main/p_SAPtoFabric.zip. Wenn Sie mit ADF-Zuordnungsdatenflüssen und SAP CDC vertraut sind, können Sie ein Szenario von Grund auf neu einrichten und mit der folgenden Konfiguration des verknüpften Lakehouse-Diensts fortfahren.
Um die Vorlage zu verwenden, sind die folgenden Schritte erforderlich:
- Erstellen Sie drei verknüpfte Dienste, um eine Verbindung mit der SAP-Quelle, dem Stagingordner und dem Fabric Lakehouse herzustellen.
- Importieren Sie die Vorlage in Ihren ADF- oder Synapse-Arbeitsbereich.
- Konfigurieren Sie die Vorlage mit einem Quellobjekt aus Ihrem SAP-System und einer Senkentabelle.
Einrichten der Konnektivität mit dem SAP-Quellsystem
Um Ihr SAP-Quellsystem mit ADF oder Synapse mit dem SAP CDC-Connector zu verbinden, benötigen Sie eine selbst gehostete Integrationslaufzeit. Das Installationsverfahren wird hier beschrieben: Einrichten einer selbst gehosteten Integrationslaufzeit für den SAP CDC-Connector. Für die selbst gehostete Integrationslaufzeit zum Herstellen einer Verbindung mit dem SAP-Quellsystem über das RFC-Protokoll von SAP laden Sie den SAP .NET Connector herunter, und installieren Sie diesen, wie hier beschrieben: Herunterladen und Installieren des SAP .NET Connectors.
Als nächstes erstellen Sie einen mit SAP CDC verknüpften Dienst. Einrichten eines verknüpften Diensts und Datasets für den SAP CDC Connector. Dazu benötigen Sie die SAP-Systemverbindungsparameter (Anwendungs-/Nachrichtenserver, Instance-Nummer, Client-ID) und Benutzeranmeldeinformationen, um eine Verbindung mit dem SAP-System herzustellen. Ausführliche Informationen zur Konfiguration, die für diesen SAP-Benutzer erforderlich ist, finden Sie im Dokument: Einrichten des SAP-Benutzers.
Das Erstellen eines SAP CDC-Datasets wie im Dokument für die Konfiguration verknüpfter Dienste beschrieben ist optional – Zuordnungsdatenflüsse bieten eine schlankere Option zum Definieren der Dataseteigenschaften inline im Datenfluss selbst. Die hier bereitgestellte Pipelinevorlage verwendet eine solche Inline-Datasetdefinition.
Einrichten der ADLS Gen2-Konnektivität für Staging
Bevor Sie die Änderungsdaten aus dem SAP-Quellsystem in die Senke schreiben, werden sie in einen Ordner in ADLS Gen2 bereitgestellt. Von dort holt die Zuordnungsdatenfluss-Laufzeit die Daten ab und verarbeitet sie gemäß den im Datenfluss definierten Schritten. Der im Rahmen der Vorlage bereitgestellte Datenfluss führt die Änderungen mit den vorhandenen Daten in der Senkentabelle zusammen und gibt Ihnen somit eine aktuelle Kopie der Quelle.
Das Einrichten eines verknüpften ADLS Gen2-Diensts wird hier beschrieben: Erstellen eines verknüpften Azure Data Lake Storage Gen2-Diensts mithilfe der Benutzeroberfläche.
Abrufen der Fabric-Arbeitsbereich-ID und der Lakehouse-Objekt-ID
Führen Sie die folgenden Schritte aus, um die erforderliche Fabric-Arbeitsbereichs-ID und die Lakehouse-Objekt-ID in Microsoft Fabric zu erfassen:
Navigieren Sie in Ihrem Browser zu Microsoft Fabric.
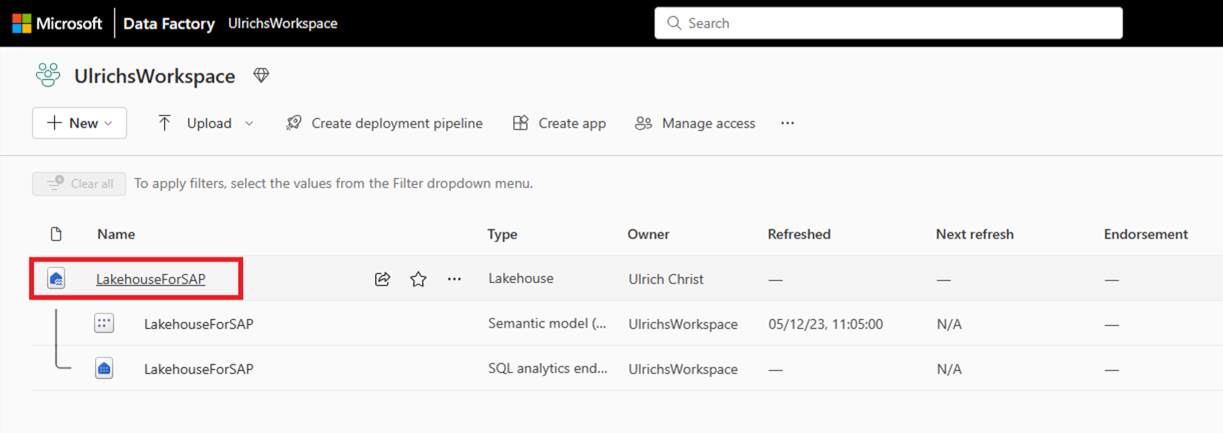
Sobald die Lakehouse-Umgebung im Browser geöffnet wird, kopieren Sie die Browser-URL. Diese hat folgendes Format:
https://xxxxxx.powerbi.com/groups/<Arbeitsbereichs-ID>/lakehouses/<Lakehouse-ID>Kopieren Sie die <Arbeitsbereichs-ID> und <die Lakehouse-ID> aus der URL.
Konfigurieren eines Dienstprinzipals
Das Konfigurieren des Dienstprinzipals erfordert zwei Schritte. Erstellen Sie zunächst einen Dienstprinzipal in Microsoft Entra ID. Fügen Sie dann den Dienstprinzipal als Mitglied zum Fabric-Arbeitsbereich hinzu.
Beginnen wir mit Microsoft Entra ID.
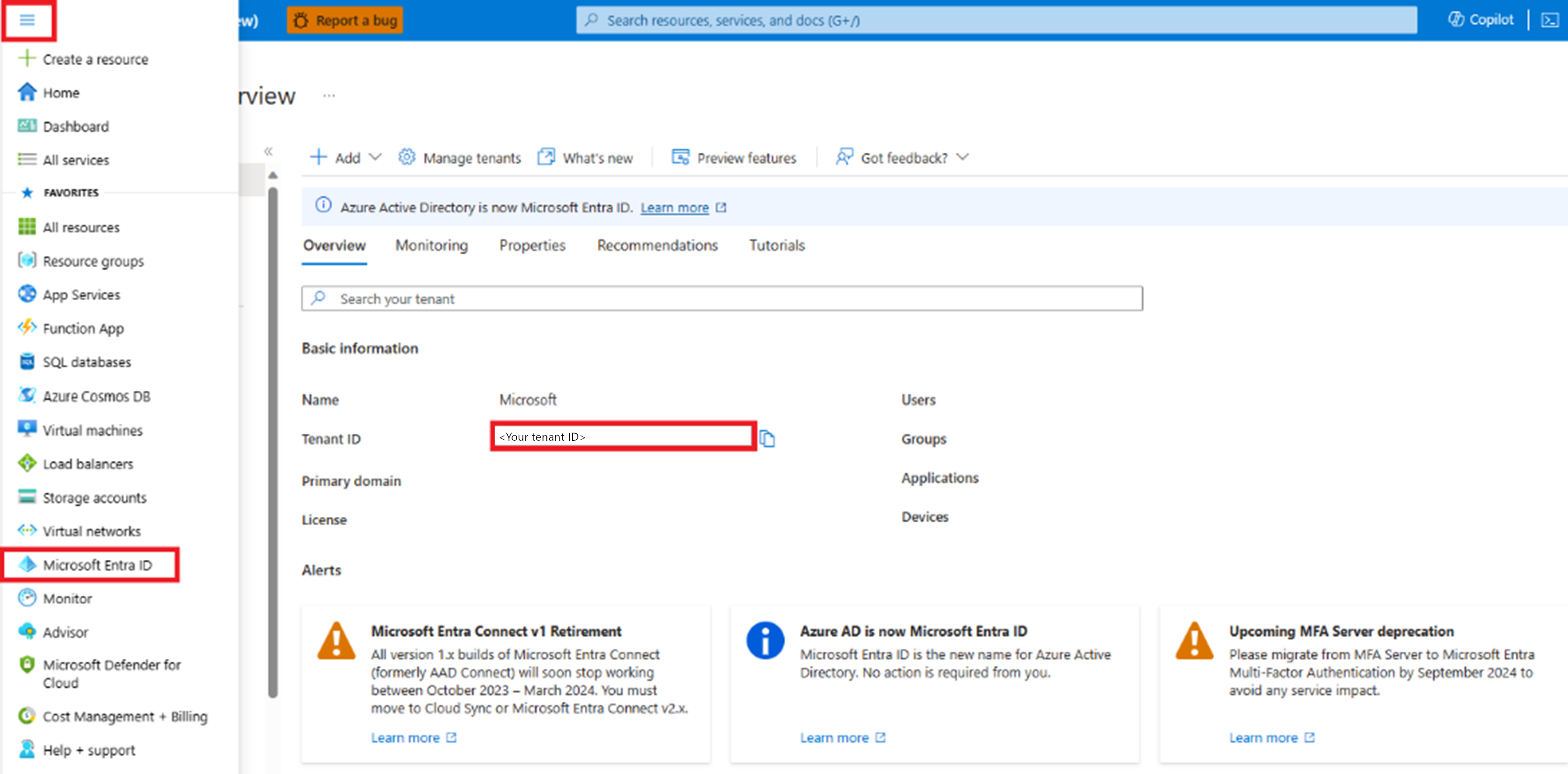
Navigieren Sie zu Azure-Portal, und wählen Sie im linken Menü die Microsoft Entra-ID aus. Kopieren Sie zur späteren Verwendung den Wert der Mandanten-ID.
Wählen Sie App-Registrierungen und + Neue Registrierung aus, um den Dienstprinzipal zu erstellen.
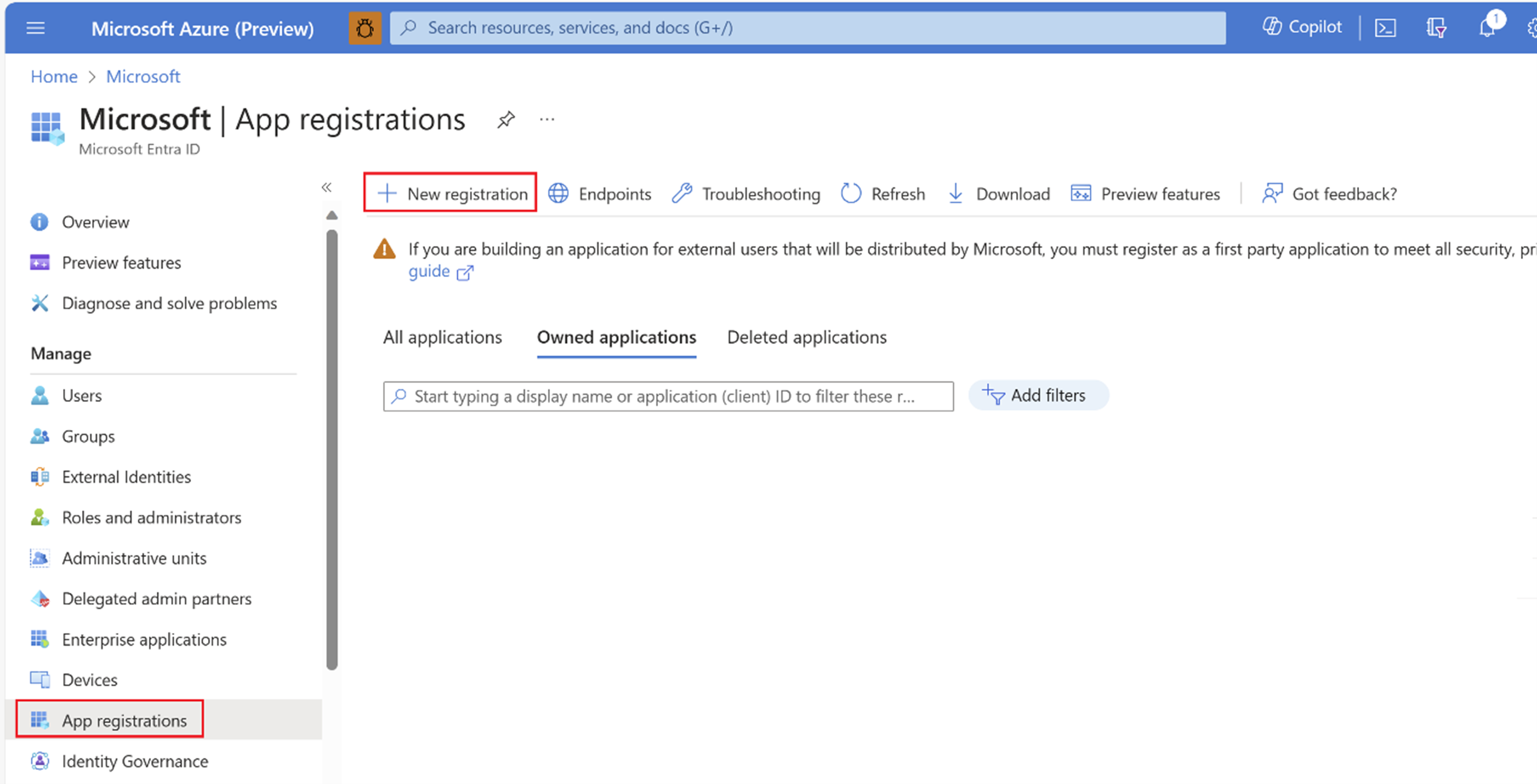
Geben Sie unter Name einen Namen für die Anwendung ein. Der Name ist identisch mit dem Dienstprinzipalnamen. Kopieren Sie ihn also zur späteren Verwendung.
Wählen Sie Nur Konten in diesem Organisationsverzeichnis aus.
Klicken Sie anschließend auf Registrieren.
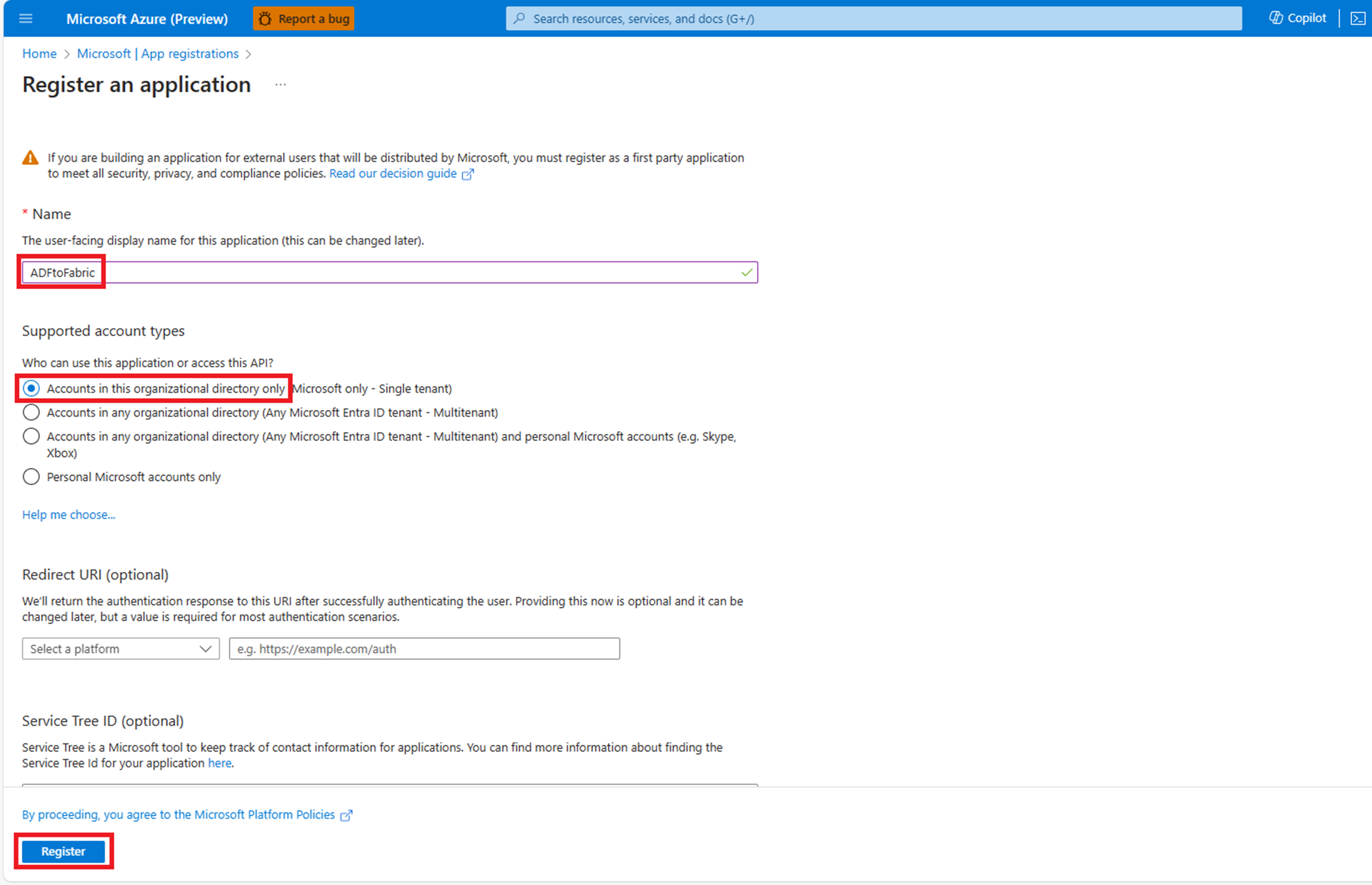
Kopieren Sie die Anwendungs- (Client-)ID. Dieser Schritt ist später in der verknüpften Dienstdefinition in ADF erforderlich. Wählen Sie dann Ein Zertifikat oder Geheimnis hinzufügen aus.
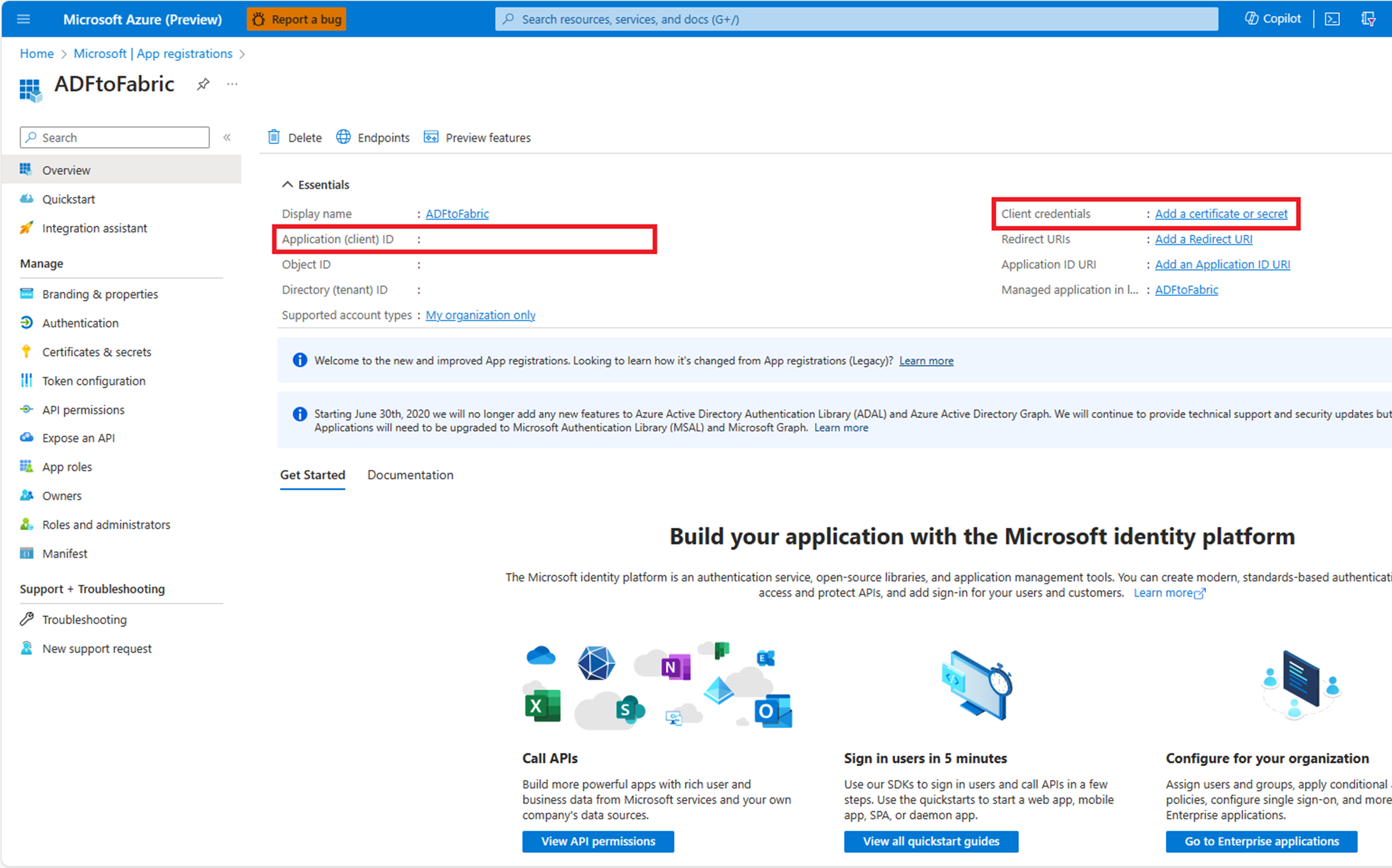
Wählen Sie + Neuer geheimer Clientschlüssel aus. Fügen Sie eine Beschreibung und Ablaufrichtlinie hinzu.
a
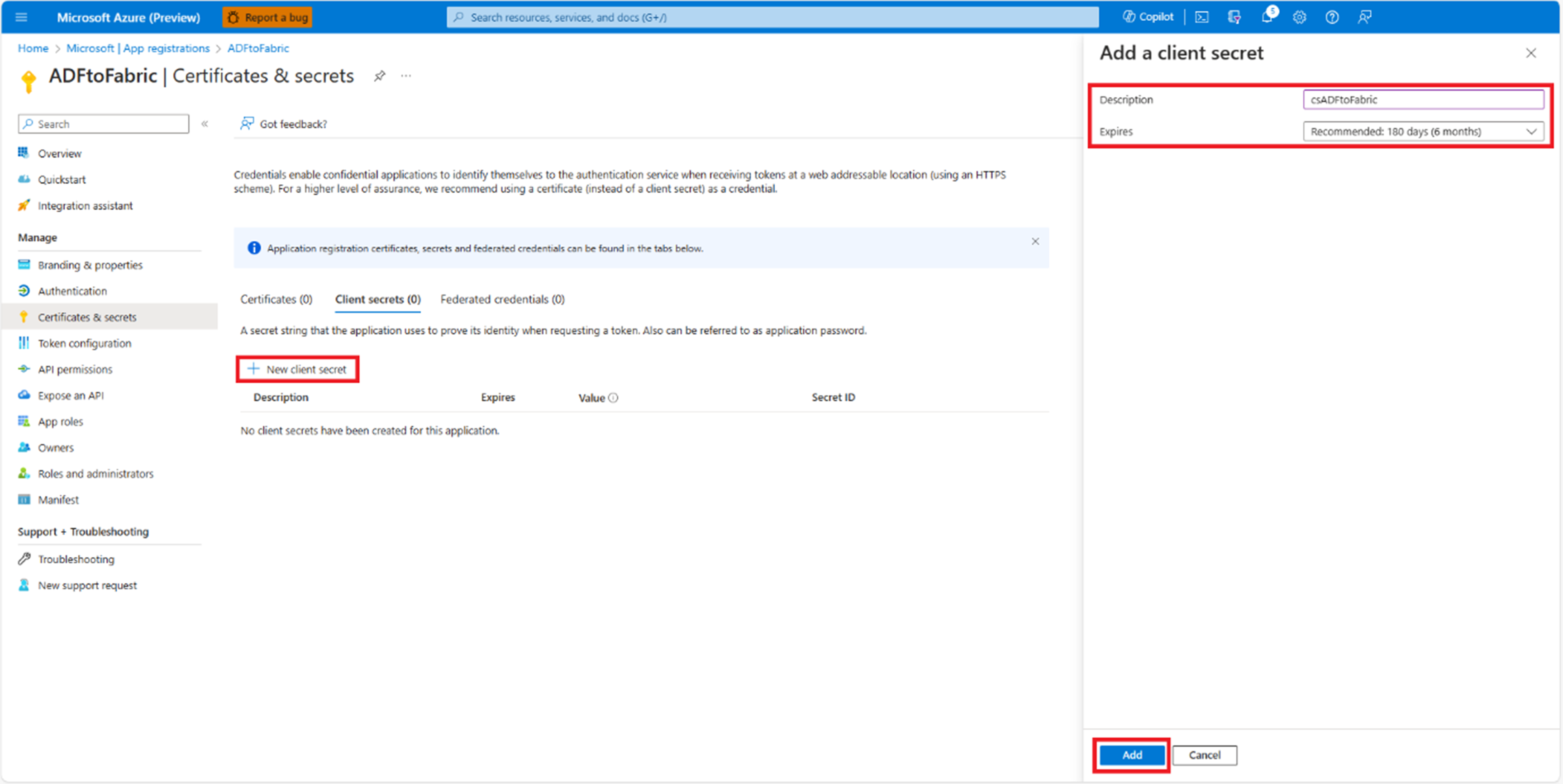
Kopieren Sie den Wert des geheimen Clientgeheimnisses. In diesem Schritt wird die Dienstprinzipalkonfiguration in der Microsoft Entra-ID abgeschlossen.






Als Nächstes fügen wir den Dienstprinzipal als Mitwirkender oder Administrator zu Ihrem Microsoft Fabric-Arbeitsbereich hinzu.
Navigieren Sie zu Ihrem Microsoft Fabric-Arbeitsbereich, und wählen Sie Zugriff verwalten aus:
Geben Sie den Namen des Dienstprinzipals ein, wählen Sie die Rolle Mitwirkender oder Administrator und dann Hinzufügen aus. Der Dienstprinzipal kann jetzt verwendet werden, um ADF mit Ihrem Arbeitsbereich zu verbinden.

Erstellen des verknüpften Lakehouse-Diensts in ADF oder Synapse
Jetzt können wir den verknüpften Lakehouse-Dienst in ADF oder Synapse konfigurieren.
Öffnen Sie Ihren ADF- oder Synapse-Arbeitsbereich, wählen Sie das Tool Verwalten und dann Verknüpfte Dienste aus. Wählen Sie dann + Neu aus.
Suchen Sie nach "Lakehouse", wählen Sie den verknüpften Diensttyp Microsoft Fabric Lakehouse, und wählen Sie Weiter.
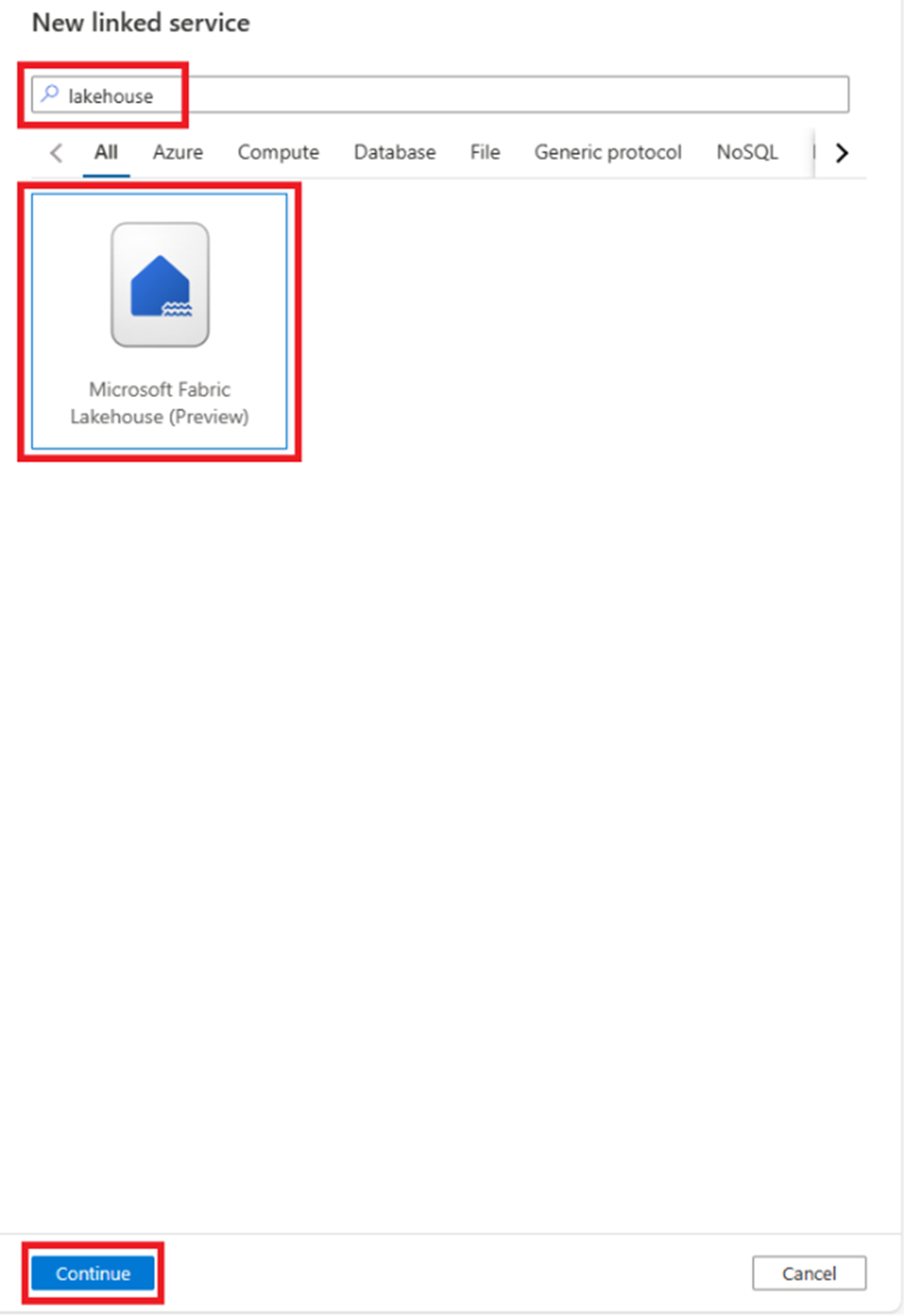
Weisen Sie dem verknüpften Dienst einen Namen zu, wählen Sie Manuell eingeben aus, und konfigurieren Sie die Werte Fabric-Arbeitsbereichs-ID und die Lakehouse-Objekt-ID, die zuvor aus der Fabric-URL kopiert wurden.
- Geben Sie in der Eigenschaft Mandant die Mandanten-ID an, die Sie in Schritt 1 der Dienstprinzipalkonfiguration in Microsoft Entra ID kopiert haben.
- Geben Sie für die Dienstprinzipal-ID die Anwendungs-ID (nicht den Dienstprinzipalnamen!) an, die Sie in Schritt 6 der Dienstprinzipalkonfiguration kopiert haben.
- Stellen Sie für den Dienstprinzipalschlüssel den geheimen Clientwert bereit, den Sie in Schritt 8 der Dienstprinzipalkonfiguration kopiert haben.
Stellen Sie sicher, dass die Verbindung erfolgreich hergestellt werden kann, und wählen Sie Erstellen aus.
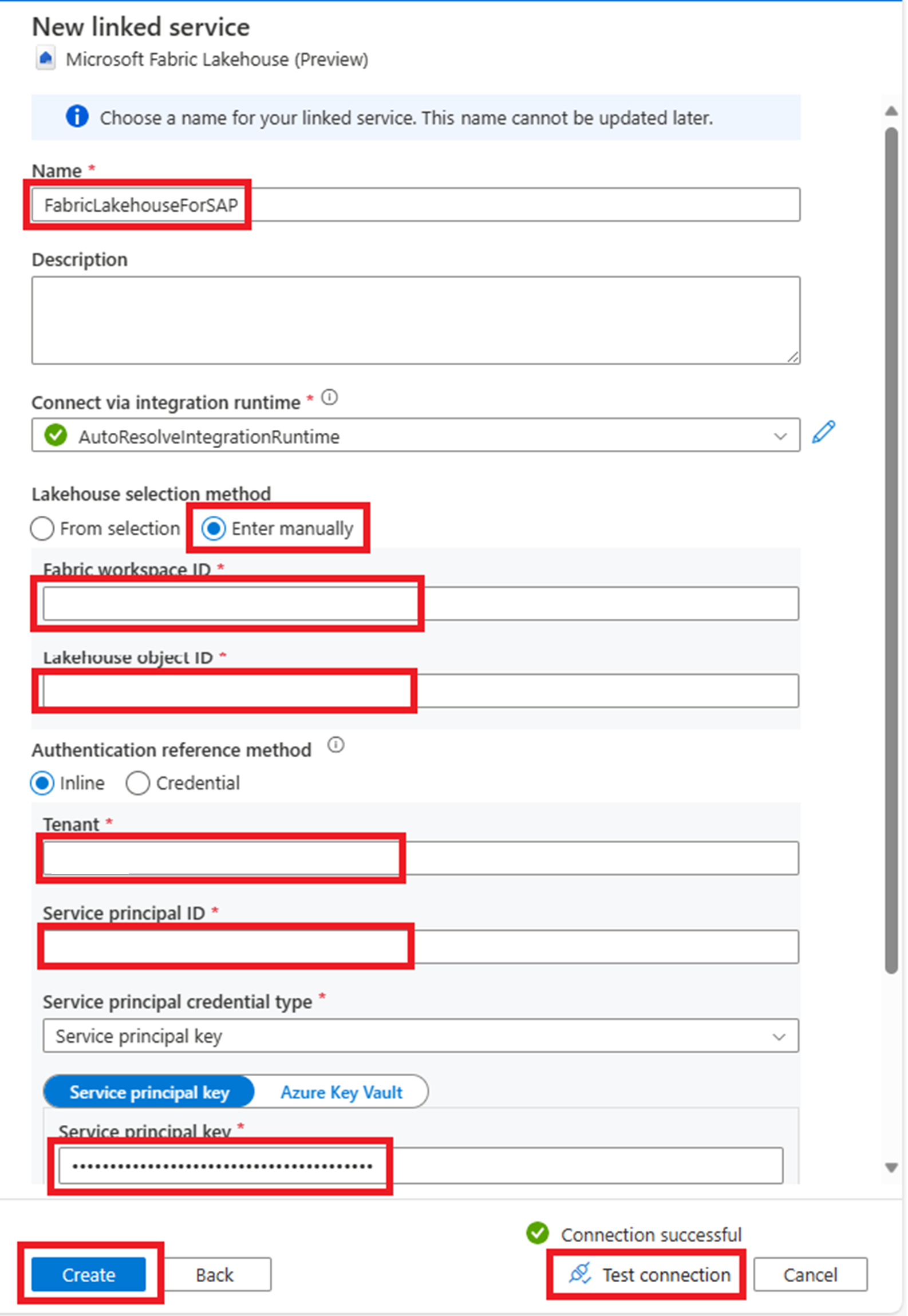

Konfigurieren der Pipelinevorlage
Nachdem die verknüpften Dienste eingerichtet wurden, können Sie die Vorlage importieren und für Ihr Quellobjekt anpassen.
Wählen Sie im Pipelinemenü + zum Hinzufügen einer neuen Ressource und dann Pipeline und Vorlagengalerie aus.
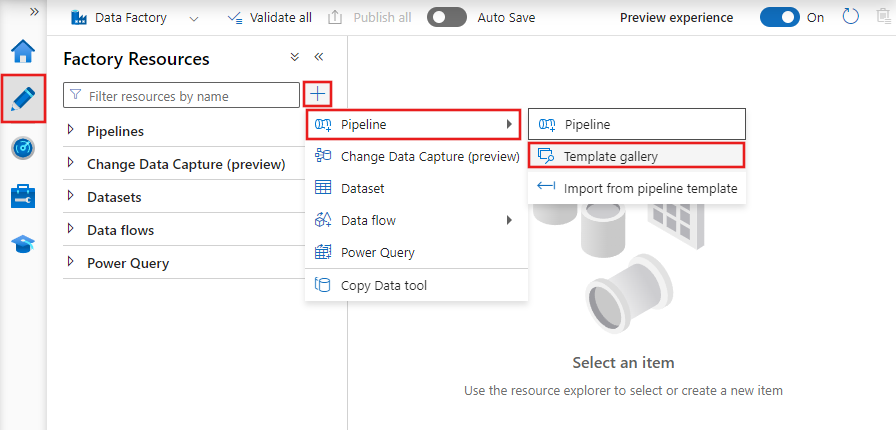
Das Dialogfeld Vorlagenkatalog wird angezeigt. Suchen Sie die Vorlage Änderungsänderungen aus SAP in Fabric Lakehouse-Tabelle kopieren, wählen Sie sie aus, und wählen Sie Weiter.
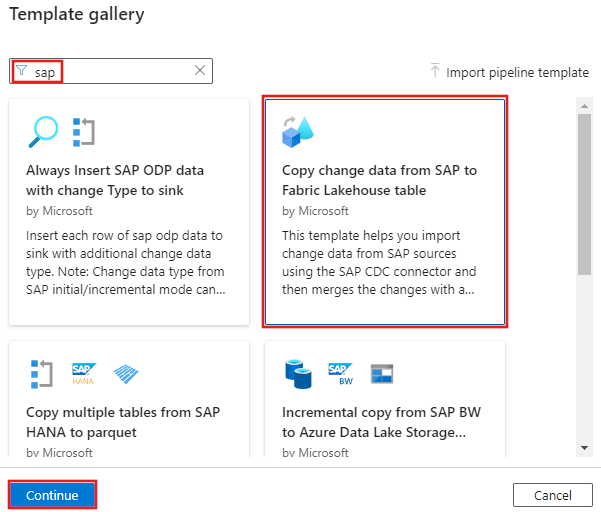
Der Konfigurationsbildschirm wird geöffnet, in dem Sie die verknüpften Dienste angeben, die zum Instanziieren der Vorlage verwendet werden sollen. Geben Sie die verknüpften Dienste ein, die in den vorherigen Abschnitten erstellt wurden. Der erste verknüpfte Dienst ist der erste, der für den Stagingordner in ADLS Gen2 erforderlich ist, der zweite ist eine Verbindung mit der SAP-Quelle und der dritte stellt eine Verbindung mit Microsoft Fabric Lakehouse her:
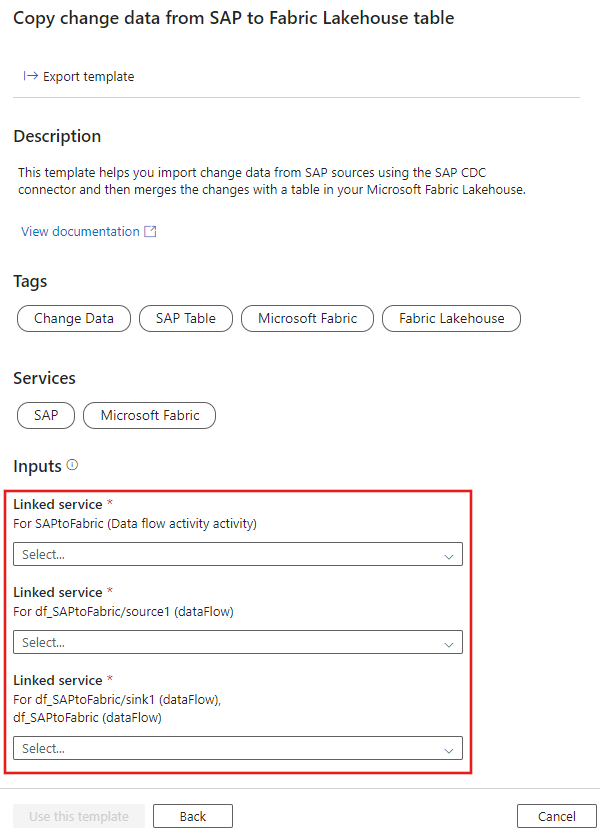
Nachdem Sie die Vorlage konfiguriert haben, erstellt ADF die neue Pipeline, und Sie können alle Anpassungen vornehmen, die Sie für Ihr spezifisches Setup benötigen. Konfigurieren Sie als ersten Schritt den Stagingordner so, dass die Änderungsdaten aus SAP zwischengespeichert werden, bevor sie mit Ihrer Delta-Tabelle in Fabric zusammengeführt werden. Wählen Sie in der Pipeline die Datenflussaktivität aus, und wählen Sie die Registerkarte Einstellungen aus. In den Stagingeigenschaften können Sie den im letzten Schritt konfigurierten verknüpften Staging-Dienst sehen. Geben Sie einen Stagingspeicherordner ein.
Doppelklicken Sie auf die Datenflussaktivität in der Pipeline, um den Zuordnungsdatenfluss zu öffnen und Ihre Quelle und Senke zu konfigurieren. Wählen Sie zuerst die SAP CDC-Quellübertragung und die Registerkarte Quelloptionen aus. Geben Sie die Detaileigenschaften Ihres Quellobjekts in ODP-Kontext, ODP-Name und Schlüsselspalten (als JSON-Array) an. Wählen Sie dann einen Ausführungsmodus aus. Ausführliche Informationen zu diesen Eigenschaften finden Sie in der Azure Data Factory-Dokumentation für SAP-Funktionen zur Änderungsdatenerfassung.
Wählen Sie die Senkentransformation des Datenflusses aus, wählen Sie dann die Registerkarte Einstellungen aus, und geben Sie den Tabellennamen für die Lakehouse-Tabelle in Ihren Fabric-Arbeitsbereich ein. Wählen Sie das Optionsfeld Benutzerdefinierter Ausdruck der Eigenschaft Schlüsselspalten aus, und geben Sie die Schlüsselspalten Ihrer Quelle als JSON-Array ein.
Veröffentlichen Sie Ihre Änderungen.
Abrufen der Daten
Navigieren Sie zurück zu der Pipeline, und starten Sie eine Pipelineausführung.
Wechseln Sie zur Überwachungsumgebung, und warten Sie, bis die Pipeline abgeschlossen ist:
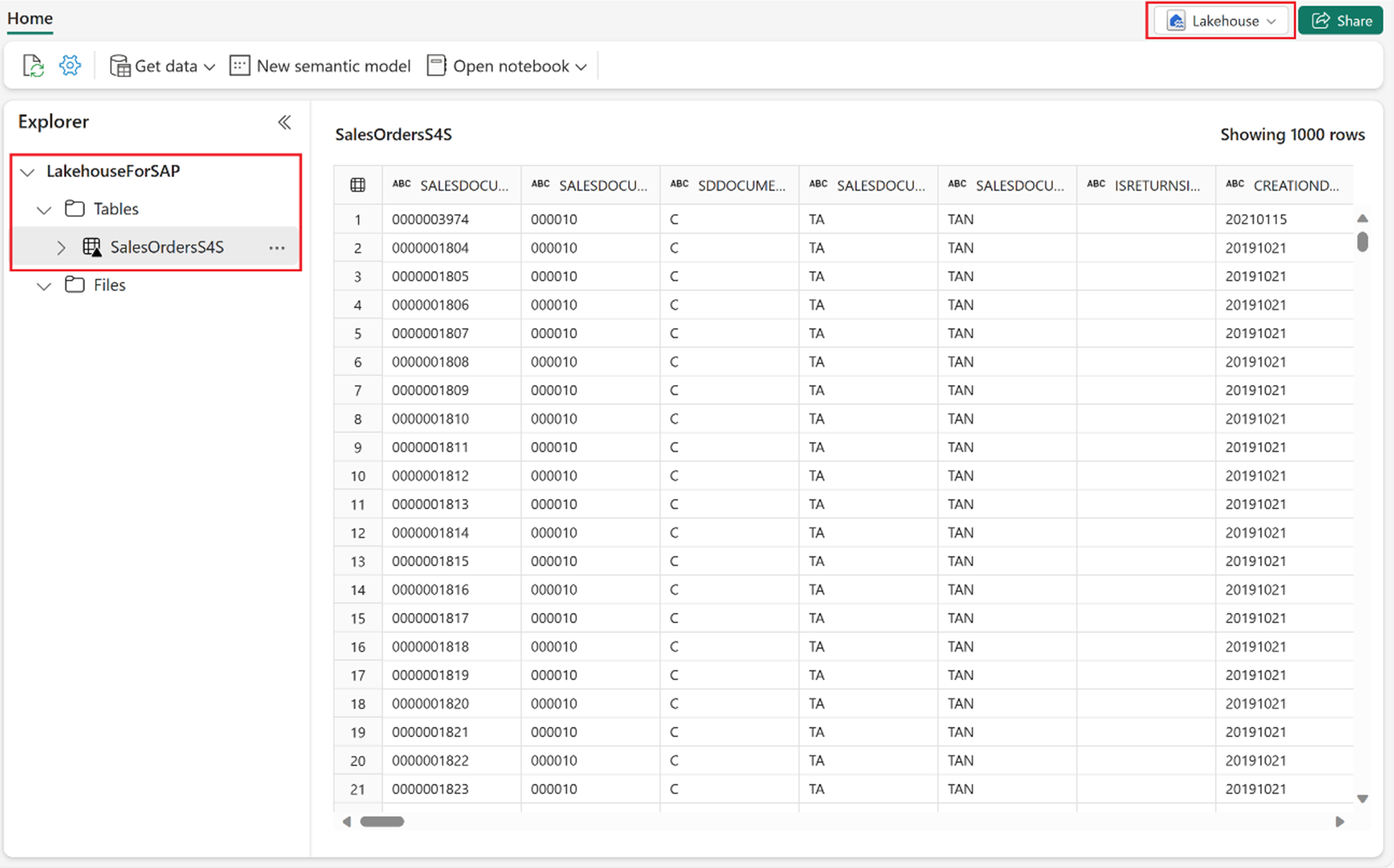
Öffnen Sie Ihr Lakehouse in Ihrem Fabric-Arbeitsbereich. Unter Tabellen wird die neu erstellte Lakehouse-Tabelle angezeigt. Rechts auf dem Bildschirm wird eine Vorschau der Daten angezeigt, die Sie aus SAP geladen haben.