Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
Mit der Spark Job Definition-Aktivität in Data Factory für Microsoft Fabric können Sie Verbindungen zu Ihren Spark Job Definitions erstellen und sie aus einer Datenpipeline ausführen.
Voraussetzungen
Um zu beginnen, müssen Sie die folgenden Voraussetzungen erfüllen:
- Ein Mandantenkonto mit einem aktiven Abonnement. Erstellen Sie ein kostenloses Konto.
- Ein Arbeitsbereich wird erstellt.
Hinzufügen einer SparkAuftragsdefinitionsaktivität zu einer Pipeline mit Benutzeroberfläche
Erstellen Sie eine neue Datenpipeline in Ihrem Arbeitsbereich.
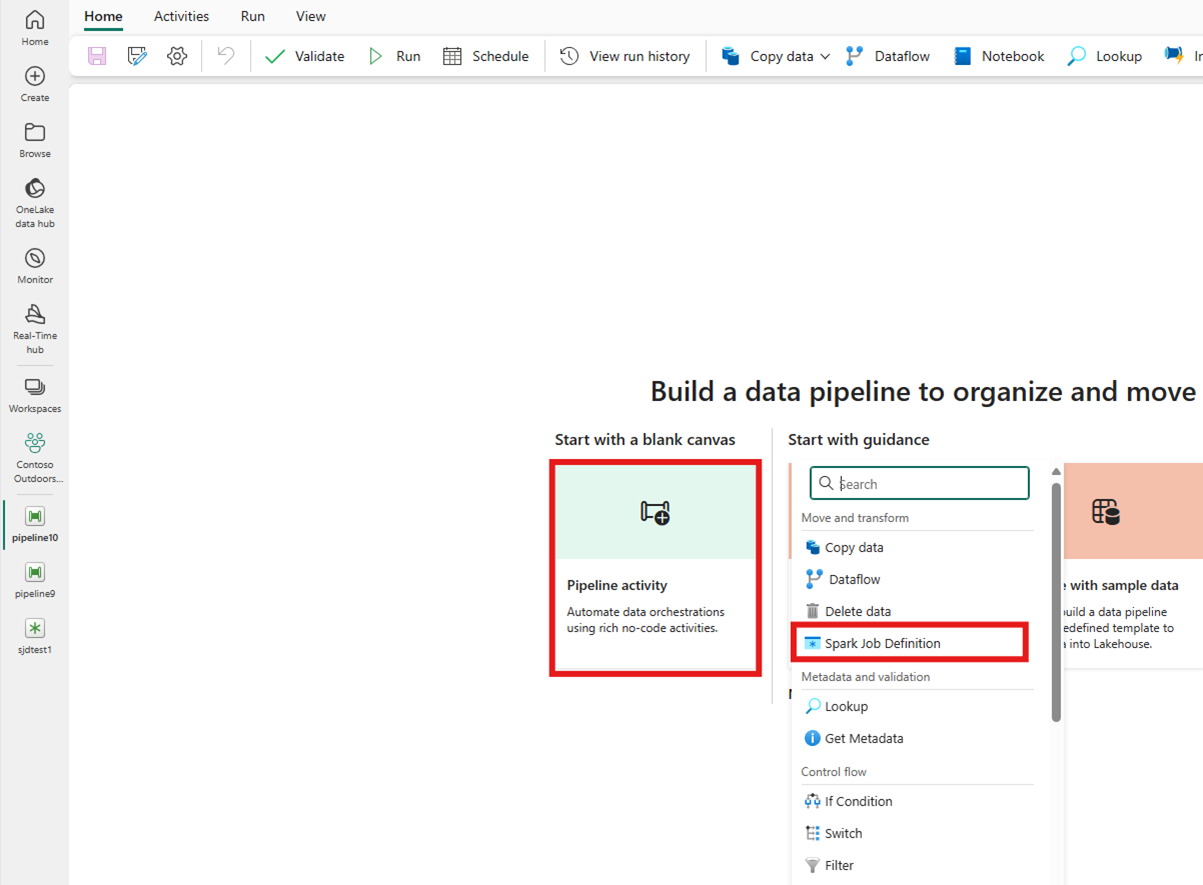
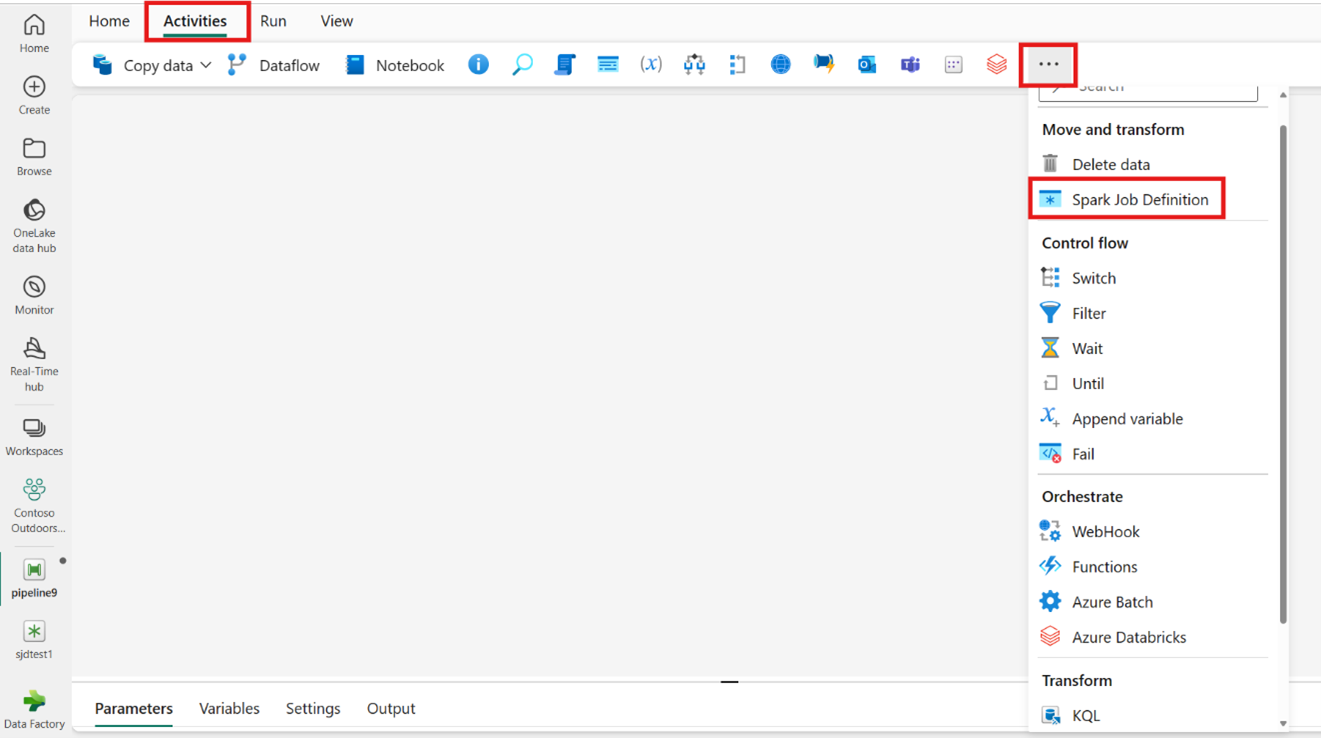
Suchen Sie auf der Startseitenkarte nach „Spark Job Definition“, und wählen Sie die Komponente aus. Alternativ können Sie die Aktivität auf der Leiste „Aktivitäten“ auswählen, um die Komponente zur Pipelinecanvas hinzuzufügen.
Die Aktivität von der Startseitenkarte aus erstellen:
Erstellen der Aktivität über die Aktivitätsleiste:
Wählen Sie die neue Spark Job Definition-Aktivität im Pipeline-Editor-Canvas aus, wenn sie noch nicht ausgewählt ist.

Beachten Sie die Anleitung zu den allgemeinen Einstellungen, um die Optionen auf der Registerkarte Allgemeine Einstellungen zu konfigurieren.



Spark Job Definition-Aktivitätseinstellungen
Wählen Sie im Bereich der Aktivitätseigenschaften die Registerkarte Einstellungen aus, und wählen Sie dann den Fabric-Arbeitsbereich aus, der die Spark-Auftragsdefinition enthält, die Sie ausführen möchten.

Auf der Registerkarte "Einstellungen " können Sie ihre Verbindungs-, Arbeitsbereichs- und Spark-Auftragsdefinition konfigurieren. Wenn noch keine Spark iob-Definition vorhanden ist, können Sie im Pipeline-Editor eine neue Spark-Auftragsdefinition erstellen, indem Sie neben der Spark-Auftragsdefinition die Schaltfläche "+Neu" auswählen.

Nachdem Sie einen Namen festgelegt und "Erstellen" ausgewählt haben, werden Sie zur Spark-Auftragsdefinition weitergeleitet, um Ihre Konfigurationen festzulegen.


Auf der Registerkarte "Einstellungen " können Sie unter "Erweiterte Einstellungen" weitere Einstellungen konfigurieren.

Sie können diese Einstellungsfelder auch parametrisieren, um Ihr Spark-Auftragsdefinitionselement zu koordinieren. Die übergebenen Werte überschreiben die ursprünglichen Konfigurationen der Spark-Auftragsdefinition.


Bekannte Einschränkungen
Die aktuellen Einschränkungen in der Spark Job Definition-Aktivität für Fabric Data Factory sind hier aufgeführt. Dieser Abschnitt kann geändert werden.
- Obwohl wir die Überwachung der Aktivität über den Ausgabetab unterstützen, können Sie die Spark Job Definition noch nicht auf einer detaillierteren Ebene überwachen. Links zur Überwachungsseite, zum Status, zur Dauer und vorherigen Spark Job Definition-Ausführungen sind beispielsweise nicht direkt in Data Factory verfügbar. Auf der Spark Job Definition Monitoring-Seitekönnen Sie jedoch genauere Details sehen.
Speichern und Ausführen oder Planen der Pipeline
Nachdem Sie alle anderen aktivitäten konfiguriert haben, die für Ihre Pipeline erforderlich sind, wechseln Sie oben im Pipeline-Editor zur Registerkarte "Start", und wählen Sie die Schaltfläche "Speichern" aus, um Die Pipeline zu speichern. Wählen Sie Ausführen aus, um sie direkt auszuführen, oder Planen, um sie zu planen. Sie können den Ausführungsverlauf auch hier anzeigen oder andere Einstellungen konfigurieren.
