Anleitung: Azure KI Services – Erkennung von multivariaten Anomalien
In dieser Anleitung wird beschrieben, wie Sie SynapseML und Azure KI Services in Apache Spark für die Erkennung von multivariaten Anomalien verwenden können. Die Erkennung von multivariaten Anomalien ermöglicht die Erkennung von Anomalien unter vielen Variablen oder Zeitreihen unter Berücksichtigung aller Interkorrelationen und Abhängigkeiten zwischen den verschiedenen Variablen. In diesem Szenario verwenden Sie SynapseML, um ein Modell für die Erkennung von multivariaten Anomalien mit Azure KI Services zu trainieren. Anschließend verwenden Sie das trainierte Modell, um multivariate Anomalien in einem Dataset abzuleiten, das synthetische Messungen von drei IoT-Sensoren enthält.
Wichtig
Ab dem 20. September 2023 können Sie keine neuen Ressourcen für die Anomalieerkennung mehr erstellen. Der Anomalieerkennungsdienst wird am 1. Oktober 2026 eingestellt.
Weitere Informationen zum Azure KI Anomalie Detektor finden Sie auf dieser Dokumentationsseite.
Voraussetzungen
- Azure-Abonnement: Kostenloses Azure-Konto
- Fügen Sie Ihr Notebook an ein Lakehouse an. Wählen Sie auf der linken Seite Hinzufügen aus, um ein vorhandenes Lakehouse hinzuzufügen oder ein Lakehouse zu erstellen.
Setup
Befolgen Sie die Anweisungen zum Erstellen einer Anomaly Detector-Ressource mit dem Azure-Portal. Alternativ können Sie auch die Azure CLI verwenden, um diese Ressource zu erstellen.
Nachdem Sie eine Anomaly Detector eingerichtet haben, können Sie Methoden zur Verarbeitung von Daten verschiedener Formen erkunden. Der Katalog der Dienste in Azure AI bietet mehrere Optionen: Vision, Sprache, Sprache, Websuche, Entscheidung, Übersetzung und Dokumentintelligenz.
Erstellen einer Anomalieerkennungsressource
- Wählen Sie im Azure-Portal in Ihrer Ressourcengruppe die Option Erstellen und geben Sie dann Anomalie-Detektor ein. Wählen Sie die Ressource Anomalie-Detektor.
- Geben Sie der Ressource einen Namen. Verwenden Sie idealerweise dieselbe Region wie der Rest Ihrer Ressourcengruppe. Verwenden Sie für den Rest die Standardoptionen, und wählen Sie dann Überprüfen + Erstellen und anschließend Erstellen.
- Sobald die Ressource Anomalieerkennung erstellt ist, öffnen Sie sie und wählen Sie im linken Navigationsbereich
Keys and Endpointsaus. Kopieren Sie den Schlüssel für die Anomaly Detector-Ressource in dieANOMALY_API_KEY-Umgebungsvariable, oder speichern Sie ihn in deranomalyKey-Variablen.
Erstellen einer Speicherkontoressource
Um Zwischendaten zu speichern, müssen Sie ein Azure Blob Storage-Konto erstellen. Erstellen Sie in diesem Speicherkonto einen Container zum Speichern der Zwischendaten. Notieren Sie sich den Containernamen, und kopieren Sie die Verbindungszeichenfolge in den betreffenden Container. Sie benötigen diese später für die containerName-Variable und die BLOB_CONNECTION_STRING-Umgebungsvariable.
Eingeben Ihrer Dienstschlüssel
Richten Sie zuerst die Umgebungsvariablen für unsere Dienstschlüssel ein. In der nächsten Zelle werden die Umgebungsvariablen ANOMALY_API_KEY und BLOB_CONNECTION_STRING basierend auf den Werten festgelegt, die in unserem Azure Key Vault gespeichert sind. Wenn Sie dieses Tutorial in Ihrer eigenen Umgebung ausführen, müssen Sie diese Umgebungsvariablen festlegen, bevor Sie fortfahren.
import os
from pyspark.sql import SparkSession
from synapse.ml.core.platform import find_secret
# Bootstrap Spark Session
spark = SparkSession.builder.getOrCreate()
Lesen Sie nun die Umgebungsvariablen ANOMALY_API_KEY und BLOB_CONNECTION_STRING, und legen Sie die Variablen containerName und location fest.
# An Anomaly Dectector subscription key
anomalyKey = find_secret("anomaly-api-key") # use your own anomaly api key
# Your storage account name
storageName = "anomalydetectiontest" # use your own storage account name
# A connection string to your blob storage account
storageKey = find_secret("madtest-storage-key") # use your own storage key
# A place to save intermediate MVAD results
intermediateSaveDir = (
"wasbs://madtest@anomalydetectiontest.blob.core.windows.net/intermediateData"
)
# The location of the anomaly detector resource that you created
location = "westus2"
Zuerst stellen wir eine Verbindung mit unserem Speicherkonto her, damit die Anomalieerkennung dort Zwischenergebnisse speichern kann:
spark.sparkContext._jsc.hadoopConfiguration().set(
f"fs.azure.account.key.{storageName}.blob.core.windows.net", storageKey
)
Importieren Sie alle erforderlichen Module.
import numpy as np
import pandas as pd
import pyspark
from pyspark.sql.functions import col
from pyspark.sql.functions import lit
from pyspark.sql.types import DoubleType
import matplotlib.pyplot as plt
import synapse.ml
from synapse.ml.cognitive import *
Lesen Sie nun unsere Beispieldaten in einen Spark-DataFrame ein.
df = (
spark.read.format("csv")
.option("header", "true")
.load("wasbs://publicwasb@mmlspark.blob.core.windows.net/MVAD/sample.csv")
)
df = (
df.withColumn("sensor_1", col("sensor_1").cast(DoubleType()))
.withColumn("sensor_2", col("sensor_2").cast(DoubleType()))
.withColumn("sensor_3", col("sensor_3").cast(DoubleType()))
)
# Let's inspect the dataframe:
df.show(5)
Jetzt können Sie ein estimator-Objekt erstellen, das zum Trainieren unseres Modells verwendet wird. Geben Sie die Start- und Endzeiten für die Trainingsdaten an. Geben Sie außerdem die zu verwendenden Eingabespalten und den Namen der Spalte an, die die Zeitstempel enthält. Geben Sie schließlich die Anzahl der Datenpunkte an, die im gleitenden Fenster für die Anomalieerkennung verwendet werden sollen, und legen Sie die Verbindungszeichenfolge auf das Azure Blob Storage-Konto fest.
trainingStartTime = "2020-06-01T12:00:00Z"
trainingEndTime = "2020-07-02T17:55:00Z"
timestampColumn = "timestamp"
inputColumns = ["sensor_1", "sensor_2", "sensor_3"]
estimator = (
FitMultivariateAnomaly()
.setSubscriptionKey(anomalyKey)
.setLocation(location)
.setStartTime(trainingStartTime)
.setEndTime(trainingEndTime)
.setIntermediateSaveDir(intermediateSaveDir)
.setTimestampCol(timestampColumn)
.setInputCols(inputColumns)
.setSlidingWindow(200)
)
Nachdem wir nun das estimator-Objekt erstellt haben, kann es an die Daten angepasst werden:
model = estimator.fit(df)
```parameter
Once the training is done, we can now use the model for inference. The code in the next cell specifies the start and end times for the data we would like to detect the anomalies in.
```python
inferenceStartTime = "2020-07-02T18:00:00Z"
inferenceEndTime = "2020-07-06T05:15:00Z"
result = (
model.setStartTime(inferenceStartTime)
.setEndTime(inferenceEndTime)
.setOutputCol("results")
.setErrorCol("errors")
.setInputCols(inputColumns)
.setTimestampCol(timestampColumn)
.transform(df)
)
result.show(5)
Beim Aufruf von .show(5) der vorherigen Zelle wurden die ersten fünf Zeilen im Datenframe angezeigt. Die Ergebnisse waren alle null, weil sie sich außerhalb des Rückschlussfensters befanden.
Wählen Sie die benötigten Spalten aus, um nur für die abgeleiteten Daten Ergebnisse anzuzeigen. Anschließend können Sie die Zeilen im Dataframe nach aufsteigender Reihenfolge sortieren und das Ergebnis so filtern, dass nur die Zeilen angezeigt werden, die sich im Bereich des Rückschlussfensters befinden. In diesem Fall stimmt inferenceEndTime mit der letzten Zeile im Dataframe überein, sodass der Wert ignoriert werden kann.
Um die Ergebnisse besser darstellen zu können, wird der Spark-Dataframe schließlich in einen Pandas-Dataframe konvertiert.
rdf = (
result.select(
"timestamp",
*inputColumns,
"results.contributors",
"results.isAnomaly",
"results.severity"
)
.orderBy("timestamp", ascending=True)
.filter(col("timestamp") >= lit(inferenceStartTime))
.toPandas()
)
rdf
Formatieren Sie die contributors-Spalte, in der die Beitragsbewertung der einzelnen Sensoren für die erkannten Anomalien gespeichert wird. In der nächsten Zelle werden diese Daten formatiert und Beitragsbewertungen der einzelnen Sensoren in eigene Spalten aufgeteilt.
def parse(x):
if type(x) is list:
return dict([item[::-1] for item in x])
else:
return {"series_0": 0, "series_1": 0, "series_2": 0}
rdf["contributors"] = rdf["contributors"].apply(parse)
rdf = pd.concat(
[rdf.drop(["contributors"], axis=1), pd.json_normalize(rdf["contributors"])], axis=1
)
rdf
Sehr gut! Die Beitragsbewertungen der Sensoren 1, 2 und 3 befinden sich jetzt in den Spalten series_0, series_1 und series_2.
Führen Sie die nächste Zelle aus, um die Ergebnisse darzustellen. Der minSeverity-Parameter gibt den minimalen Schweregrad der Anomalien an, die dargestellt werden sollen.
minSeverity = 0.1
####### Main Figure #######
plt.figure(figsize=(23, 8))
plt.plot(
rdf["timestamp"],
rdf["sensor_1"],
color="tab:orange",
linestyle="solid",
linewidth=2,
label="sensor_1",
)
plt.plot(
rdf["timestamp"],
rdf["sensor_2"],
color="tab:green",
linestyle="solid",
linewidth=2,
label="sensor_2",
)
plt.plot(
rdf["timestamp"],
rdf["sensor_3"],
color="tab:blue",
linestyle="solid",
linewidth=2,
label="sensor_3",
)
plt.grid(axis="y")
plt.tick_params(axis="x", which="both", bottom=False, labelbottom=False)
plt.legend()
anoms = list(rdf["severity"] >= minSeverity)
_, _, ymin, ymax = plt.axis()
plt.vlines(np.where(anoms), ymin=ymin, ymax=ymax, color="r", alpha=0.8)
plt.legend()
plt.title(
"A plot of the values from the three sensors with the detected anomalies highlighted in red."
)
plt.show()
####### Severity Figure #######
plt.figure(figsize=(23, 1))
plt.tick_params(axis="x", which="both", bottom=False, labelbottom=False)
plt.plot(
rdf["timestamp"],
rdf["severity"],
color="black",
linestyle="solid",
linewidth=2,
label="Severity score",
)
plt.plot(
rdf["timestamp"],
[minSeverity] * len(rdf["severity"]),
color="red",
linestyle="dotted",
linewidth=1,
label="minSeverity",
)
plt.grid(axis="y")
plt.legend()
plt.ylim([0, 1])
plt.title("Severity of the detected anomalies")
plt.show()
####### Contributors Figure #######
plt.figure(figsize=(23, 1))
plt.tick_params(axis="x", which="both", bottom=False, labelbottom=False)
plt.bar(
rdf["timestamp"], rdf["series_0"], width=2, color="tab:orange", label="sensor_1"
)
plt.bar(
rdf["timestamp"],
rdf["series_1"],
width=2,
color="tab:green",
label="sensor_2",
bottom=rdf["series_0"],
)
plt.bar(
rdf["timestamp"],
rdf["series_2"],
width=2,
color="tab:blue",
label="sensor_3",
bottom=rdf["series_0"] + rdf["series_1"],
)
plt.grid(axis="y")
plt.legend()
plt.ylim([0, 1])
plt.title("The contribution of each sensor to the detected anomaly")
plt.show()
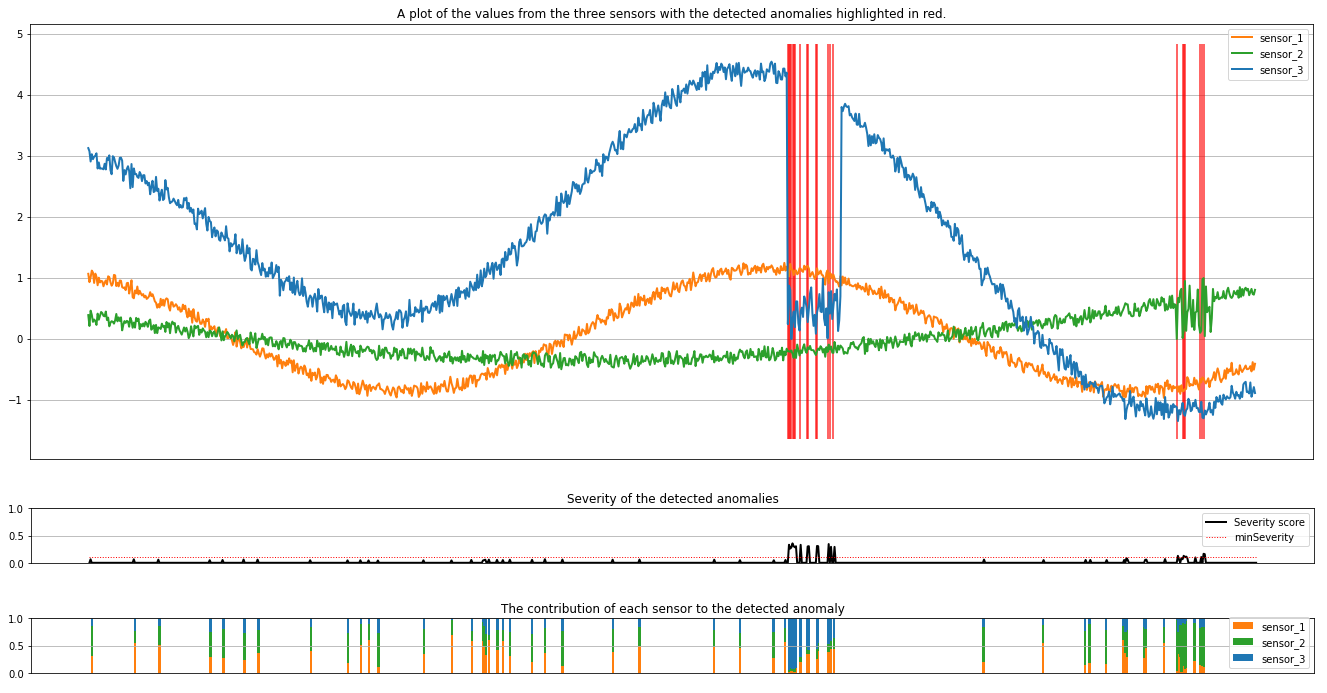
Die Diagramme zeigen die Rohdaten der Sensoren (innerhalb des Rückschlussfensters) in Orange, Grün und Blau an. Die roten vertikalen Linien in der ersten Abbildung veranschaulichen die erkannten Anomalien, deren Schweregrad größer oder gleich minSeverity ist.
Das zweite Diagramm veranschaulicht den Schweregrad aller erkannten Anomalien, wobei der minSeverity-Schwellenwert als gestrichelte rote Linie angezeigt wird.
Schließlich veranschaulicht das letzte Diagramm den Beitrag der Daten der einzelnen Sensoren zu den erkannten Anomalien. Dies ist hilfreich, um die wahrscheinlichste Ursache der einzelnen Anomalien zu diagnostizieren und zu verstehen.
Zugehöriger Inhalt
Feedback
Bald verfügbar: Im Laufe des Jahres 2024 werden wir GitHub-Issues stufenweise als Feedbackmechanismus für Inhalte abbauen und durch ein neues Feedbacksystem ersetzen. Weitere Informationen finden Sie unter https://aka.ms/ContentUserFeedback.
Feedback senden und anzeigen für