Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
In Projekten mit moderner Business Intelligence (BI) kann es eine Herausforderung sein, den Datenfluss von der Datenquelle bis zum Ziel zu verstehen. Die Herausforderung ist sogar noch größer, wenn Sie erweiterte analytische Projekte erstellen, die mehrere Datenquellen, Elemente und Abhängigkeiten umfassen.
Fragen wie „Was passiert, wenn ich diese Daten ändere?“ oder „Warum ist dieser Bericht nicht auf dem neuesten Stand?“ sind nicht immer einfach zu beantworten. Solche Fragen benötigen möglicherweise ein Team von Experten oder eine umfassende Untersuchung, um das zu verstehen. Die Datenherkunftsansicht von Microsoft Fabric hilft Ihnen beim Beantworten dieser Fragen.
Datenherkunft und maschinelles Lernen
Es gibt mehrere Gründe, warum die Datenherkunft in Ihrem Machine Learning-Workflow wichtig ist:
- Reproduzierbarkeit: Wenn Sie die Datenherkunft eines Modells kennen, können Sie das Modell und dessen Ergebnisse leichter reproduzieren. Wenn jemand anderes das Modell replizieren möchte, kann er die gleichen Schritte ausführen, die Sie zum Erstellen des Modells verwendet haben, sowie dieselben Daten und Parameter verwenden.
- Transparenz: Das Verständnis der Datenherkunft eines Modells trägt dazu bei, seine Transparenz zu erhöhen. Beteiligte, z. B. aufsichtsführende Personen oder Benutzer, können verstehen, wie das Modell erstellt wurde und wie es funktioniert. Dieser Faktor kann wichtig sein, um Fairness, Verantwortlichkeit und ethische Überlegungen sicherzustellen.
- Debugging: Wenn ein Modell nicht wie erwartet funktioniert, kann die Kenntnis der Datenherkunft hilfreich sein, um die Ursache des Problems zu ermitteln. Durch die Untersuchung der Trainingsdaten, der Parameter und der während des Trainingsprozesses getroffenen Entscheidungen können die Benutzer möglicherweise Probleme erkennen, die die Leistung des Modells beeinträchtigen.
- Verbesserung: Die Kenntnis der Datenherkunft eines Modells kann auch dazu beitragen, es zu verbessern. Wenn Sie verstehen, wie das Modell erstellt und trainiert wurde, können Benutzer ggf. Änderungen an den Trainingsdaten, Parametern oder Prozessen vornehmen, um die Genauigkeit des Modells oder andere Leistungsmetriken zu verbessern.
Data Science-Elementtypen
Microsoft Fabric integriert Machine Learning-Modelle und -Experimente in eine einheitliche Plattform. Im Rahmen dieses Ansatzes können Benutzer die Beziehung zwischen Fabric Data Science-Elementen und anderen Fabric-Elementen durchsuchen.

Machine Learning-Modelle
In Fabric können Benutzer Machine Learning-Modelle erstellen und verwalten. Ein Machine Learning-Modellelement stellt eine versionierte Liste von Modellen dar, die es Benutzern ermöglicht, die verschiedenen Iterationen des Modells zu durchsuchen.
In der Datenherkunftsansicht können Benutzer die Beziehung zwischen einem Machine Learning-Modell und anderen Fabric-Elementen durchsuchen, um die folgenden Fragen zu beantworten:
- Welche Beziehung besteht zwischen Machine Learning-Modellen und -Experimenten in meinem Arbeitsbereich?
- Welche Machine Learning-Modelle sind in meinem Arbeitsbereich vorhanden?
- Wie kann ich die Datenherkunft zurückverfolgen, um festzustellen, welche Lakehouse-Elemente mit diesem Modell zusammenhängen?
Machine Learning-Experimente
Ein Machine Learning-Experiment ist die primäre Einheit für die Organisation und Steuerung aller zugehörigen Machine Learning-Ausführungen.
In der Datenherkunftsansicht können Benutzer die Beziehung zwischen einem Machine Learning-Experiment und anderen Fabric-Elementen durchsuchen, um die folgenden Fragen zu beantworten:
- Welche Beziehung besteht zwischen Experimenten zum maschinellen Lernen und Code-Elementen in meinem Arbeitsbereich? Was ist beispielsweise die Beziehung zwischen Notebooks und Spark Job Definitions?
- Welche Machine Learning-Experimente sind in meinem Arbeitsbereich vorhanden?
- Wie kann ich die Datenherkunft zurückverfolgen, um festzustellen, welche Lakehouse-Elemente mit diesem Experiment zusammenhängen?
Erkunden der Herkunftsansicht
Jeder Fabric-Arbeitsbereich verfügt über eine integrierte Herkunftsansicht. Um auf diese Ansicht zugreifen zu können, müssen Sie mindestens über die Rolle Mitwirkender im Arbeitsbereich verfügen. Um mehr über Berechtigungen in Fabric zu erfahren, siehe Data Science Rollen und Berechtigungen.
So greifen Sie auf die Datenherkunftsansicht zu:
Wählen Sie Ihren Fabric-Arbeitsbereich aus, und navigieren Sie dann zur Liste der Arbeite.
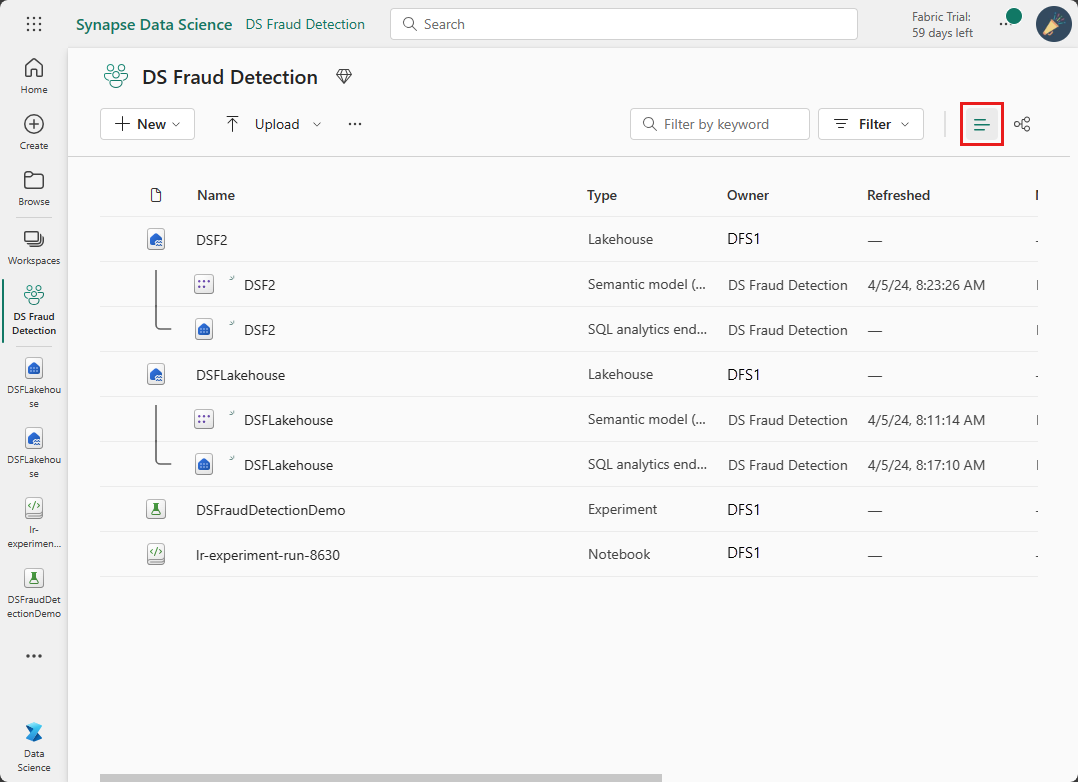
Wechseln Sie von der Listenansicht für den Arbeitsbereich zur Datenherkunftsansicht des Arbeitsbereichs.
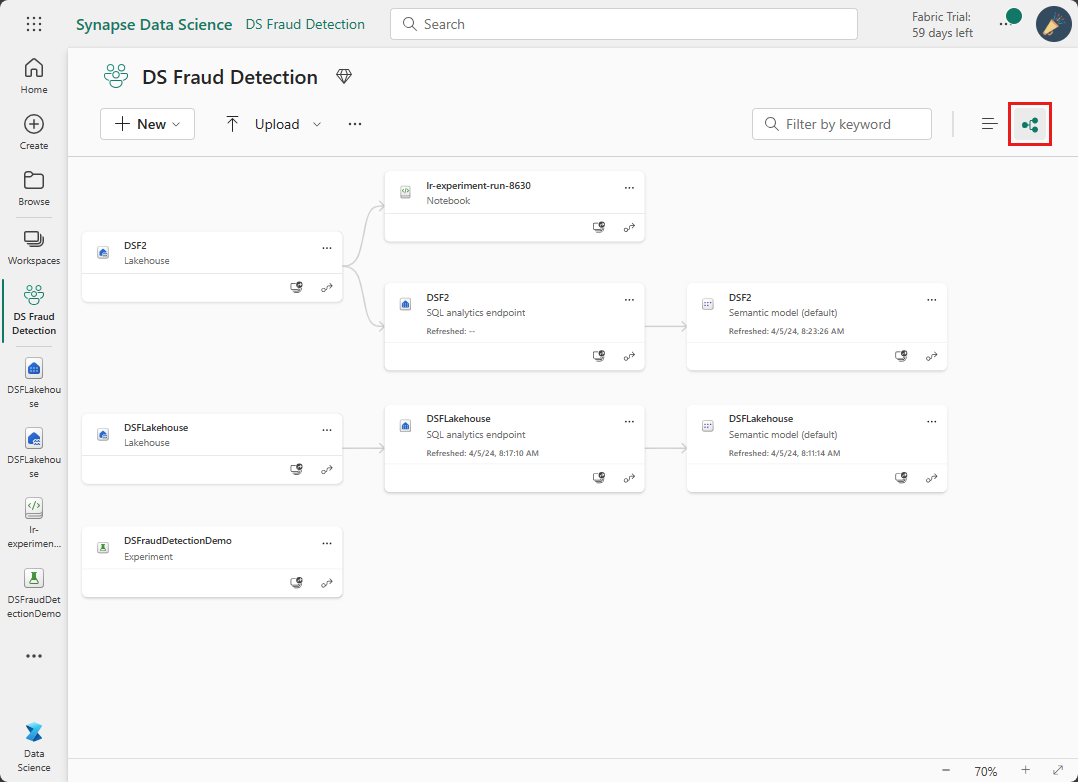
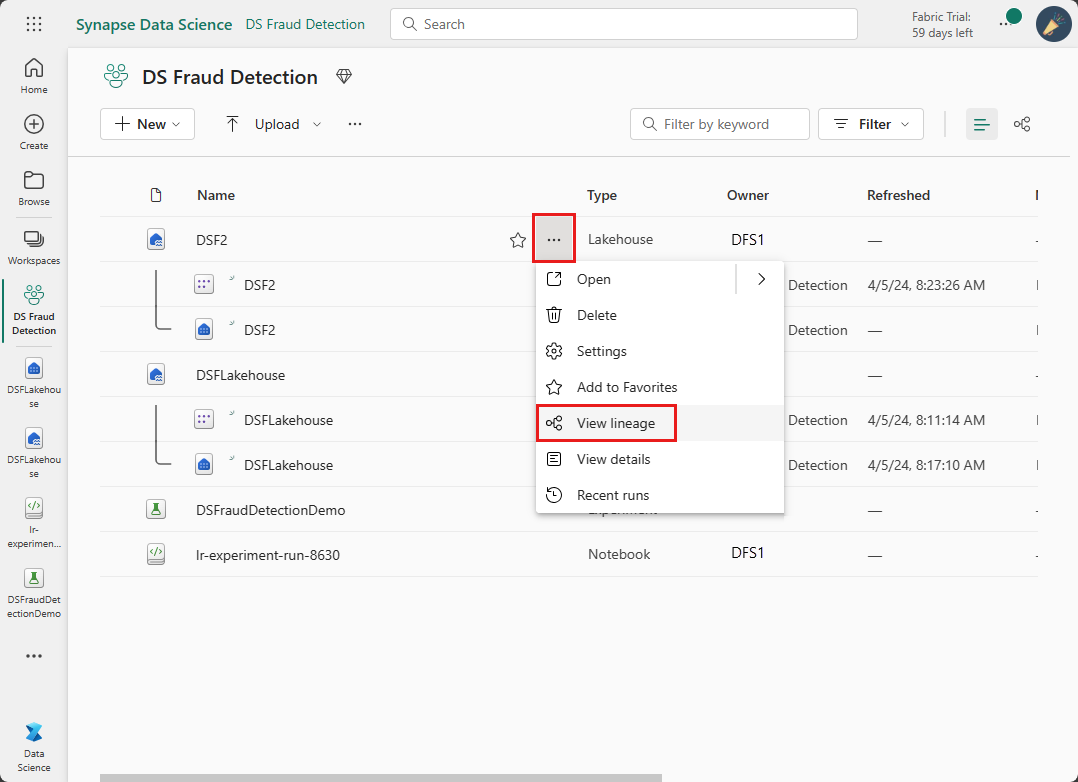
Sie können auch zur Datenherkunftsansicht für ein bestimmtes Element navigieren, indem Sie das Kontextmenü öffnen.



Zugehöriger Inhalt
- Informationen zu Machine Learning-Modellen: Machine Learning-Modelle
- Informationen zu Machine Learning-Experimenten: Machine Learning-Experimente