Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
In diesem Artikel erfahren Sie, wie Sie mithilfe von Azure Open Datasets und Apache Spark eine explorative Datenanalyse durchführen. In diesem Artikel wird das Dataset der Taxis in New York City analysiert. Die Daten sind über Azure Open Datasets verfügbar. Diese Teilmenge des Datasets enthält Informationen zu Taxifahrten von Yellow Cabs: Informationen zu den einzelnen Fahrten, Start- und Endzeiten, Abfahrtsorte und Ziele, die Kosten sowie weitere interessante Attribute.
In diesem Artikel führen Sie folgende Schritte aus:
- Herunterladen und Vorbereiten von Daten
- Daten analysieren
- Visualisieren von Daten
Voraussetzungen
Erwerben Sie ein Microsoft Fabric-Abonnement. Registrieren Sie sich alternativ für eine kostenlose Microsoft Fabric-Testversion.
Melden Sie sich bei Microsoft Fabric an.
Wechseln Sie zu Fabric, indem Sie den Benutzeroberflächenschalter auf der unteren linken Seite Ihrer Startseite verwenden.

Herunterladen und Vorbereiten der Daten
Laden Sie zunächst das Dataset der Taxis in New York City (NYC) herunter, und bereiten Sie die Daten vor.
Erstellen Sie ein Notebook unter Verwendung von PySpark. Eine entsprechende Anleitung finden Sie unter Erstellen eines Notebooks.
Hinweis
Durch den PySpark-Kernel müssen Sie keine Kontexte explizit erstellen. Der Spark-Kontext wird automatisch für Sie erstellt, wenn Sie die erste Codezelle ausführen.
In diesem Artikel verwenden Sie verschiedene Bibliotheken, um das Dataset zu visualisieren. Für die Analyse müssen die folgenden Bibliotheken importiert werden:
import matplotlib.pyplot as plt import seaborn as sns import pandas as pdDa die Rohdaten im Parquet-Format vorliegen, können Sie den Spark-Kontext verwenden, um die Datei direkt als DataFrame in den Arbeitsspeicher zu lesen. Verwenden Sie die Open Datasets-API, um die Daten abzurufen und einen Spark DataFrame zu erstellen. Um die Datentypen und das Schema abzuleiten, verwenden wir die Schema beim Lesen-Eigenschaften des Spark-DataFrame.
from azureml.opendatasets import NycTlcYellow end_date = parser.parse('2018-06-06') start_date = parser.parse('2018-05-01') nyc_tlc = NycTlcYellow(start_date=start_date, end_date=end_date) nyc_tlc_pd = nyc_tlc.to_pandas_dataframe() df = spark.createDataFrame(nyc_tlc_pd)Nachdem die Daten gelesen wurden, führen Sie eine erste Filterung durch, um das Dataset zu bereinigen. Sie können nicht benötigte Spalten entfernen und Spalten hinzufügen, die wichtige Informationen extrahieren. Darüber hinaus können Sie auch Anomalien aus dem Dataset herausfiltern.
# Filter the dataset from pyspark.sql.functions import * filtered_df = df.select('vendorID', 'passengerCount', 'tripDistance','paymentType', 'fareAmount', 'tipAmount'\ , date_format('tpepPickupDateTime', 'hh').alias('hour_of_day')\ , dayofweek('tpepPickupDateTime').alias('day_of_week')\ , dayofmonth(col('tpepPickupDateTime')).alias('day_of_month'))\ .filter((df.passengerCount > 0)\ & (df.tipAmount >= 0)\ & (df.fareAmount >= 1) & (df.fareAmount <= 250)\ & (df.tripDistance > 0) & (df.tripDistance <= 200)) filtered_df.createOrReplaceTempView("taxi_dataset")
Daten analysieren
Als Datenanalyst steht Ihnen eine Vielzahl von Tools zur Verfügung, die Ihnen beim Extrahieren von Erkenntnissen aus Daten helfen. In diesem Teil des Artikels werden Sie einige nützliche Tools kennen lernen, die in Microsoft Fabric-Notebooks verfügbar sind. In dieser Analyse möchten Sie die Faktoren verstehen, die im ausgewählten Zeitraum zu höheren Trinkgeldern führen.
Apache Spark SQL-Magic-Befehl
Als Erstes führen Sie eine explorative Datenanalyse mithilfe von Apache Spark SQL und Magic-Befehlen mit dem Microsoft Fabric-Notebook aus. Sobald Sie die Abfrage durchgerführt haben, visualisieren Sie die Ergebnisse mithilfe der integrierten chart options-Funktion.
Erstellen Sie eine neue Zelle im Notebook, und kopieren Sie den folgenden Code. Mit dieser Abfrage können Sie herausfinden, wie sich die durchschnittlichen Trinkgeldbeträge im ausgewählten Zeitraum verändert haben. Mit dieser Abfrage können Sie auch andere nützliche Erkenntnisse erzielen, beispielsweise den minimalen und den maximalen Trinkgeldbetrag pro Tag sowie den durchschnittlichen Fahrpreis.
%%sql SELECT day_of_month , MIN(tipAmount) AS minTipAmount , MAX(tipAmount) AS maxTipAmount , AVG(tipAmount) AS avgTipAmount , AVG(fareAmount) as fareAmount FROM taxi_dataset GROUP BY day_of_month ORDER BY day_of_month ASCNach dem Ausführen der Abfrage können Sie die Ergebnisse visualisieren, indem wir zur Diagrammansicht wechseln. In diesem Beispiel wird ein Liniendiagramm erstellt, indem wir das Feld
day_of_monthals Schlüssel undavgTipAmountals Wert angeben. Nachdem Sie eine Auswahl getroffen haben, wählen Sie Anwenden aus, um das Diagramm zu aktualisieren.
Visualisieren von Daten
Zusätzlich zu den integrierten Diagrammoptionen im Notebook können Sie auch beliebte Open-Source-Bibliotheken verwenden, um eigene Visualisierungen zu erstellen. In den folgenden Beispielen verwenden Sie Seaborn und Matplotlib – zwei häufig genutzte Python-Bibliotheken für die Datenvisualisierung.
Um die Entwicklung einfacher und kostengünstiger zu gestalten, führen Sie ein Downsampling des Datasets aus. Dabei verwenden Sie die integrierte Samplingfunktion von Apache Spark. Darüber hinaus benötigen sowohl Seaborn als auch Matplotlib einen Pandas-Datenrahmen oder ein NumPy-Array. Um einen Pandas-Datenrahmen zu erhalten, verwenden wir den Befehl
toPandas()zum Konvertieren des Datenrahmens.# To make development easier, faster, and less expensive, downsample for now sampled_taxi_df = filtered_df.sample(True, 0.001, seed=1234) # The charting package needs a Pandas DataFrame or NumPy array to do the conversion sampled_taxi_pd_df = sampled_taxi_df.toPandas()Zunächst können Sie sich die Verteilung der Trinkgelder im Dataset ansehen. Sie verwenden Matplotlib, um ein Histogramm zu erstellen, das die Verteilung der Beträge und die Anzahl zeigt. Anhand der Verteilung können Sie erkennen, dass Trinkgelder tendenziell nicht mehr als 10 USD betragen.
# Look at a histogram of tips by count by using Matplotlib ax1 = sampled_taxi_pd_df['tipAmount'].plot(kind='hist', bins=25, facecolor='lightblue') ax1.set_title('Tip amount distribution') ax1.set_xlabel('Tip Amount ($)') ax1.set_ylabel('Counts') plt.suptitle('') plt.show()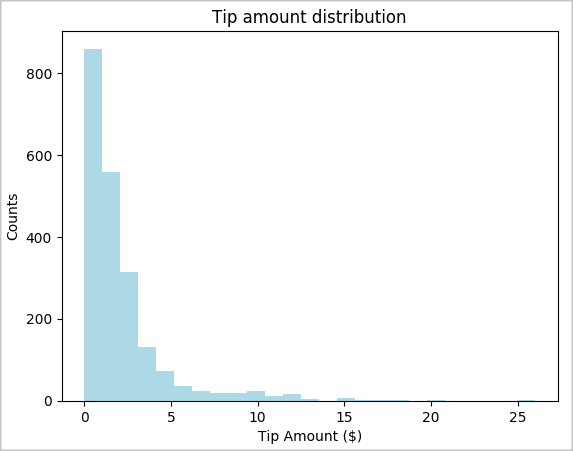
Als Nächstes versuchen Sie die Beziehung zwischen Trinkgeld pro Fahrt und Wochentag zu verstehen. Wir verwenden Seaborn, um ein Boxplotdiagramm zu erstellen, das die Trends für jeden Wochentag zusammenfasst.
# View the distribution of tips by day of week using Seaborn ax = sns.boxplot(x="day_of_week", y="tipAmount",data=sampled_taxi_pd_df, showfliers = False) ax.set_title('Tip amount distribution per day') ax.set_xlabel('Day of Week') ax.set_ylabel('Tip Amount ($)') plt.show()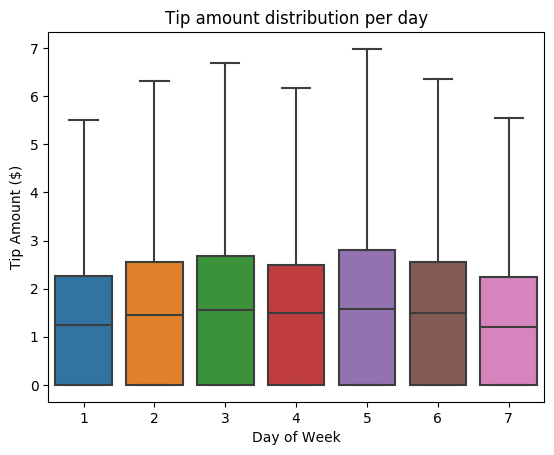
Nun möchten Sie eine weitere Hypothese untersuchen, derzufolge möglicherweise ein positiver Zusammenhang zwischen der Anzahl von Fahrgästen und dem gesamten Trinkgeldbetrag besteht. Um diesen Zusammenhang zu überprüfen, führen wir den folgenden Code aus, um ein Boxplotdiagramm zu generieren, das die Verteilung von Trinkgeldern für die jeweilige Anzahl von Fahrgästen zeigt.
# How many passengers tipped by various amounts ax2 = sampled_taxi_pd_df.boxplot(column=['tipAmount'], by=['passengerCount']) ax2.set_title('Tip amount by Passenger count') ax2.set_xlabel('Passenger count') ax2.set_ylabel('Tip Amount ($)') ax2.set_ylim(0,30) plt.suptitle('') plt.show()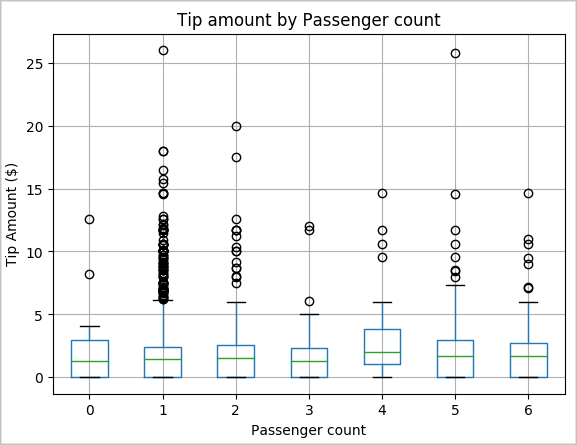
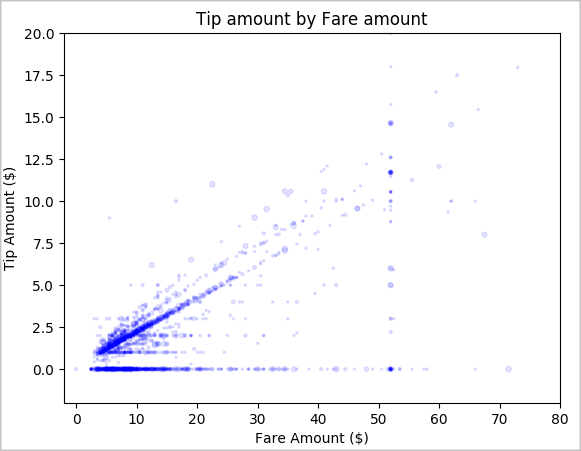
Zum Schluss erkunden Sie den Zusammenhang zwischen Fahrpreis und Trinkgeldbetrag. Anhand der Ergebnisse können Sie feststellen, dass es mehrere Fahrten gab, bei denen die Fahrgäste gar kein Trinkgeld gegeben haben. Sie sehen jedoch auch einen positiven Zusammenhang zwischen Gesamtfahrpreis und Trinkgeldbetrag.
# Look at the relationship between fare and tip amounts ax = sampled_taxi_pd_df.plot(kind='scatter', x= 'fareAmount', y = 'tipAmount', c='blue', alpha = 0.10, s=2.5*(sampled_taxi_pd_df['passengerCount'])) ax.set_title('Tip amount by Fare amount') ax.set_xlabel('Fare Amount ($)') ax.set_ylabel('Tip Amount ($)') plt.axis([-2, 80, -2, 20]) plt.suptitle('') plt.show()