Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
Dieses Lernprogramm zeigt ein End-to-End-Beispiel für einen Synapse Data Science-Workflow in Microsoft Fabric. Es verwendet sowohl die nycflights13-Datenressource als auch R, um vorherzusagen, ob ein Flugzeug mehr als 30 Minuten spät eintrifft. Anschließend werden die Vorhersageergebnisse verwendet, um ein interaktives Power BI-Dashboard zu erstellen.
In diesem Lernprogramm erfahren Sie, wie Sie:
Verwenden Sie tidymodels-Pakete
Schreiben der Ausgabedaten als Deltatabelle in Lakehouse
Erstellen Sie einen visuellen Power BI-Bericht, um direkt auf Daten in diesem Lakehouse zuzugreifen
Voraussetzungen
Erhalten Sie ein Microsoft Fabric-Abonnement. Oder registrieren Sie sich für eine kostenlose Microsoft Fabric-Testversion.
Melden Sie sich bei Microsoft Fabrican.
Wechseln Sie zu Fabric, indem Sie den Benutzeroberflächenschalter auf der unteren linken Seite Ihrer Startseite verwenden.

Öffnen oder Erstellen eines Notizbuchs Informationen dazu finden Sie unter Verwenden von Microsoft Fabric-Notizbüchern.
Legen Sie die Sprachoption auf SparkR (R)- fest, um die primäre Sprache zu ändern.
Fügen Sie Ihr Notizbuch an ein Seehaus an. Wählen Sie auf der linken Seite Hinzufügen aus, um ein vorhandenes Seehaus hinzuzufügen oder ein Seehaus zu erstellen.
Installieren von Paketen
Installieren Sie das nycflights13-Paket, um den Code in diesem Lernprogramm zu verwenden.
install.packages("nycflights13")
# Load the packages
library(tidymodels) # For tidymodels packages
library(nycflights13) # For flight data
Erkunden der Daten
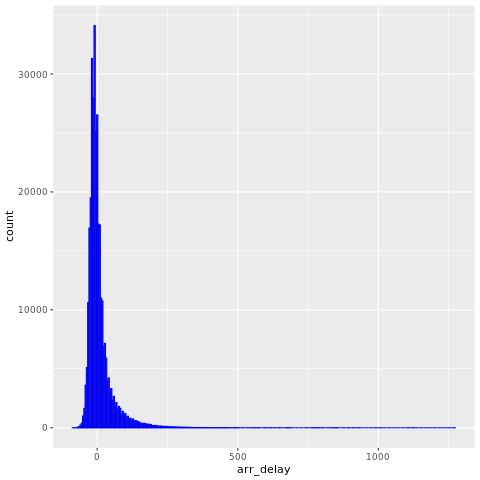
Die nycflights13 Daten enthalten Informationen zu 325.819 Flügen, die 2013 in der Nähe von New York City angekommen sind. Untersuchen Sie zunächst die Verteilung von Flugverzögerungen. Die folgende Codezelle generiert ein Diagramm, das zeigt, dass die Verteilung der Ankunftsverzögerung rechtsschief ist.
ggplot(flights, aes(arr_delay)) + geom_histogram(color="blue", bins = 300)
Er weist einen langen Schwanz in den hohen Werten auf, wie in der folgenden Abbildung dargestellt:
Laden Sie die Daten, und nehmen Sie einige Änderungen an den Variablen vor:
set.seed(123)
flight_data <-
flights %>%
mutate(
# Convert the arrival delay to a factor
arr_delay = ifelse(arr_delay >= 30, "late", "on_time"),
arr_delay = factor(arr_delay),
# You'll use the date (not date-time) for the recipe that you'll create
date = lubridate::as_date(time_hour)
) %>%
# Include weather data
inner_join(weather, by = c("origin", "time_hour")) %>%
# Retain only the specific columns that you'll use
select(dep_time, flight, origin, dest, air_time, distance,
carrier, date, arr_delay, time_hour) %>%
# Exclude missing data
na.omit() %>%
# For creating models, it's better to have qualitative columns
# encoded as factors (instead of character strings)
mutate_if(is.character, as.factor)
Bevor wir das Modell erstellen, sollten Sie einige bestimmte Variablen berücksichtigen, die sowohl für die Vorverarbeitung als auch für die Modellierung von Bedeutung sind.
Die arr_delay Variable ist eine Faktorvariable. Für die Schulung des Logistischen Regressionsmodells ist es wichtig, dass die Ergebnisvariable eine Faktorvariable ist.
glimpse(flight_data)
Etwa 16% der Flüge in diesem Dataset kamen mehr als 30 Minuten spät an:
flight_data %>%
count(arr_delay) %>%
mutate(prop = n/sum(n))
Das dest Feature verfügt über 104 Flugziele:
unique(flight_data$dest)
Es gibt 16 verschiedene Träger:
unique(flight_data$carrier)
Teilen der Daten
Teilen Sie dieses einzelne Dataset in zwei auf: einen Trainingssatz und einen Testsatz. Behalten Sie die meisten Zeilen im ursprünglichen Dataset (als zufällig ausgewählte Teilmenge) im Schulungsdatensatz bei. Verwenden Sie das Schulungsdatenset, um das Modell anzupassen, und verwenden Sie das Testdatenset, um die Modellleistung zu messen.
Verwenden Sie das rsample-Paket, um ein Objekt zu erstellen, das Informationen zum Teilen der Daten enthält. Verwenden Sie dann zwei weitere rsample Funktionen, um DataFrames für die Schulungs- und Testsätze zu erstellen:
set.seed(123)
# Keep most of the data in the training set
data_split <- initial_split(flight_data, prop = 0.75)
# Create DataFrames for the two sets:
train_data <- training(data_split)
test_data <- testing(data_split)
Erstellen eines Rezepts und einer Rolle
Erstellen Sie ein Rezept für ein einfaches logistisches Regressionsmodell. Bevor Sie das Modell trainieren, verwenden Sie ein Rezept zum Erstellen neuer Vorhersager, und führen Sie die Vorverarbeitung durch, die das Modell erfordert.
Verwenden Sie die update_role() Funktion mit einer benutzerdefinierten Rolle namens ID, damit die Rezepte wissen, dass flight und time_hour variablen sind. Eine Rolle kann einen beliebigen Zeichenwert aufweisen. Die Formel enthält alle Variablen im Schulungssatz als Prädiktoren, mit Ausnahme von arr_delay. Das Rezept behält diese beiden ID-Variablen bei, verwendet sie jedoch nicht als Ergebnisse oder Prädiktoren:
flights_rec <-
recipe(arr_delay ~ ., data = train_data) %>%
update_role(flight, time_hour, new_role = "ID")
Verwenden Sie die summary()-Funktion, um den aktuellen Satz von Variablen und Rollen anzuzeigen:
summary(flights_rec)
Features erstellen
Feature engineering kann Ihr Modell verbessern. Das Flugdatum kann eine angemessene Auswirkung auf die Wahrscheinlichkeit einer verspäteten Ankunft haben:
flight_data %>%
distinct(date) %>%
mutate(numeric_date = as.numeric(date))
Es kann hilfreich sein, Modellbegriffe hinzuzufügen, die vom Datum abgeleitet sind, die potenzielle Bedeutung für das Modell haben. Leiten Sie die folgenden aussagekräftigen Features von der einzelnen Datumsvariable ab:
- Wochentag
- Monat
- Gibt an, ob das Datum einem Feiertag entspricht.
Fügen Sie Ihrem Rezept die drei Schritte hinzu:
flights_rec <-
recipe(arr_delay ~ ., data = train_data) %>%
update_role(flight, time_hour, new_role = "ID") %>%
step_date(date, features = c("dow", "month")) %>%
step_holiday(date,
holidays = timeDate::listHolidays("US"),
keep_original_cols = FALSE) %>%
step_dummy(all_nominal_predictors()) %>%
step_zv(all_predictors())
Anpassen eines Modells mit einem Rezept
Verwenden Sie die logistische Regression, um die Flugdaten zu modellieren. Erstellen Sie zunächst eine Modellspezifikation mit dem parsnip-Paket:
lr_mod <-
logistic_reg() %>%
set_engine("glm")
Verwenden Sie das workflows Paket, um Ihr parsnip Modell (lr_mod) mit Ihrem Rezept zu bündeln (flights_rec):
flights_wflow <-
workflow() %>%
add_model(lr_mod) %>%
add_recipe(flights_rec)
flights_wflow
Trainieren des Modells
Diese Funktion kann das Rezept vorbereiten und das Modell aus den resultierenden Prädiktoren trainieren:
flights_fit <-
flights_wflow %>%
fit(data = train_data)
Verwenden Sie die Hilfsfunktionen xtract_fit_parsnip() und extract_recipe(), um das Modell oder rezeptobjekte aus dem Workflow zu extrahieren. Ziehen Sie in diesem Beispiel das angepasste Modellobjekt, und verwenden Sie dann die broom::tidy() Funktion, um ein aufgeräumtes Tibble von Modellkoeffizienten zu erhalten:
flights_fit %>%
extract_fit_parsnip() %>%
tidy()
Vorhersagen von Ergebnissen
Ein einzelner Aufruf von predict() verwendet den trainierten Workflow (flights_fit), um Vorhersagen mit den nicht angezeigten Testdaten zu erstellen. Die predict() Methode wendet das Rezept auf die neuen Daten an und übergibt dann die Ergebnisse an das passende Modell.
predict(flights_fit, test_data)
Rufen Sie die Ausgabe von predict() ab, um die vorhergesagte Klasse zurückzugeben: late im Vergleich zu on_time. Verwenden Sie jedoch augment() mit dem Modell, in Kombination mit den Testdaten, um die vorhergesagten Klassenwahrscheinlichkeiten für jeden Flug zusammen zu speichern.
flights_aug <-
augment(flights_fit, test_data)
Überprüfen Sie die Daten:
glimpse(flights_aug)
Auswerten des Modells
Wir haben jetzt ein Tibble mit den vorhergesagten Klassenwahrscheinlichkeiten. In den ersten paar Zeilen hat das Modell ordnungsgemäß fünf pünktliche Flüge vorhergesagt (Werte von .pred_on_time sind p > 0.50). Wir benötigen jedoch Vorhersagen für insgesamt 81.455 Zeilen.
Wir benötigen eine Metrik, die angibt, wie gut das Modell späte Ankunft im Vergleich zum tatsächlichen Status der arr_delay Ergebnisvariable vorhergesagt hat.
Verwenden Sie den Bereich unter der ROC-Kurve (Receiver Operating Characteristic Curve) (AUC-ROC). Berechnen Sie sie mit roc_curve() und roc_auc()aus dem yardstick-Paket:
flights_aug %>%
roc_curve(truth = arr_delay, .pred_late) %>%
autoplot()
Erstellen eines Power BI-Berichts
Das Modellergebnis sieht gut aus. Verwenden Sie die Ergebnisse der Flugverzögerungsvorhersage, um ein interaktives Power BI-Dashboard zu erstellen. Das Dashboard zeigt die Anzahl der Flüge nach Fluggesellschaft und die Anzahl der Flüge nach Ziel an. Das Dashboard kann nach den Ergebnissen der Verzögerungsvorhersage filtern.

Fügen Sie den Namen des Netzbetreibers und den Flughafennamen in das Vorhersageergebnis-Dataset ein:
flights_clean <- flights_aug %>%
# Include the airline data
left_join(airlines, c("carrier"="carrier"))%>%
rename("carrier_name"="name") %>%
# Include the airport data for origin
left_join(airports, c("origin"="faa")) %>%
rename("origin_name"="name") %>%
# Include the airport data for destination
left_join(airports, c("dest"="faa")) %>%
rename("dest_name"="name") %>%
# Retain only the specific columns you'll use
select(flight, origin, origin_name, dest,dest_name, air_time,distance, carrier, carrier_name, date, arr_delay, time_hour, .pred_class, .pred_late, .pred_on_time)
Überprüfen Sie die Daten:
glimpse(flights_clean)
Konvertieren sie die Daten in einen Spark DataFrame:
sparkdf <- as.DataFrame(flights_clean)
display(sparkdf)
Schreiben Sie die Daten in eine Delta-Tabelle in Ihrem Seehaus:
# Write data into a delta table
temp_delta<-"Tables/nycflight13"
write.df(sparkdf, temp_delta ,source="delta", mode = "overwrite", header = "true")
Verwenden Sie die Delta-Tabelle, um ein Semantikmodell zu erstellen.
Wählen Sie im linken Navigationsbereich Ihren Arbeitsbereich aus, und geben Sie im textfeld oben rechts den Namen des Seehauses ein, das Sie an Ihr Notizbuch angefügt haben. Der folgende Screenshot zeigt, dass wir "Mein Arbeitsbereich" ausgewählt haben:
Geben Sie den Namen des Seehauses ein, das Sie an Ihr Notizbuch angefügt haben. Wir geben test_lakehouse1 ein, wie im folgenden Screenshot gezeigt:
Wählen Sie im gefilterten Ergebnisbereich das Seehaus aus, wie im folgenden Screenshot gezeigt:
Wählen Sie "Neues semantisches Modell" aus, wie im folgenden Screenshot gezeigt:
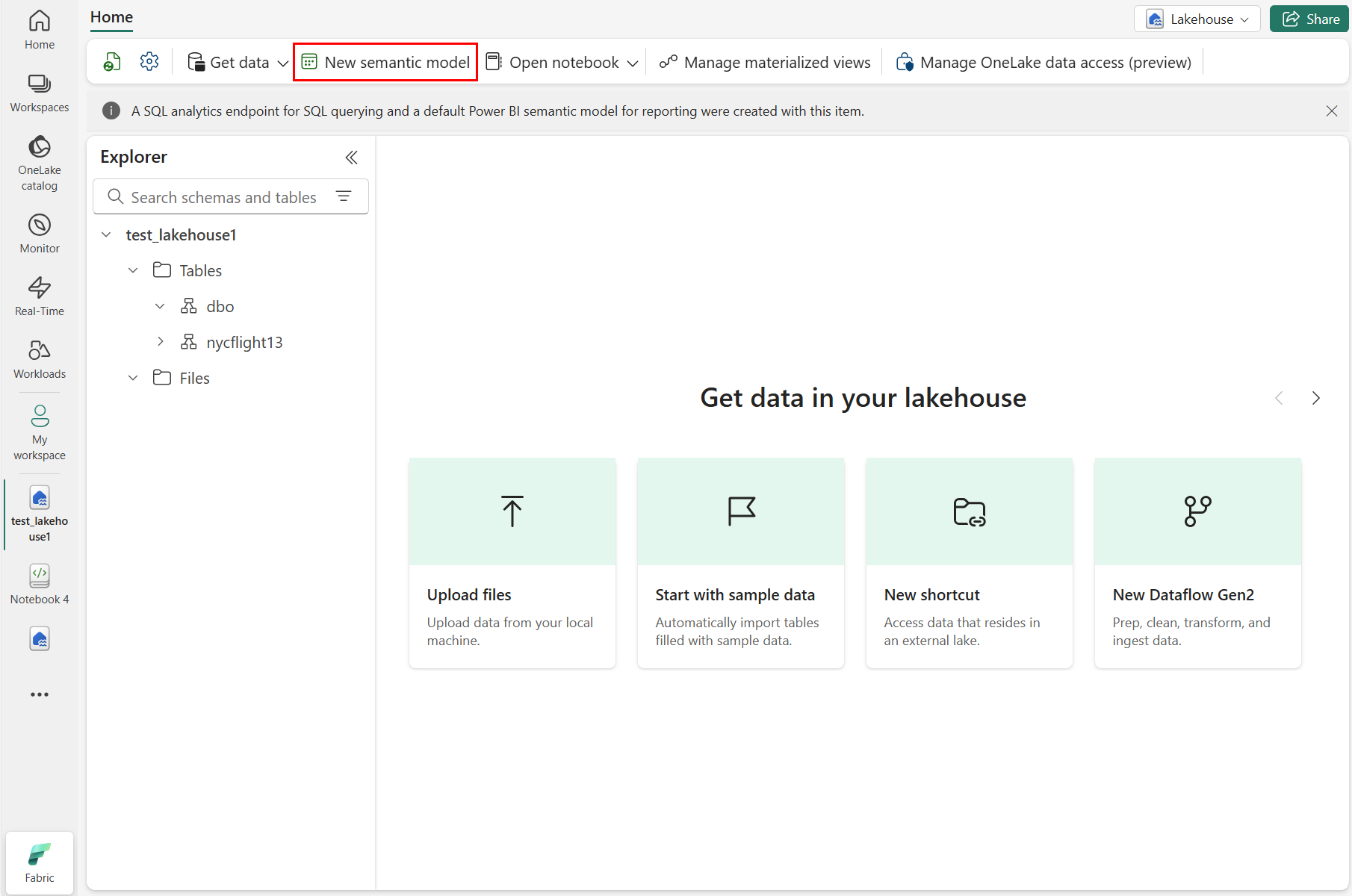
Geben Sie im Bereich "Neues Semantikmodell" einen Namen für das neue Semantikmodell ein, wählen Sie einen Arbeitsbereich aus, und wählen Sie die Tabellen aus, die für dieses neue Modell verwendet werden sollen, und wählen Sie dann "Bestätigen" aus, wie im folgenden Screenshot gezeigt:
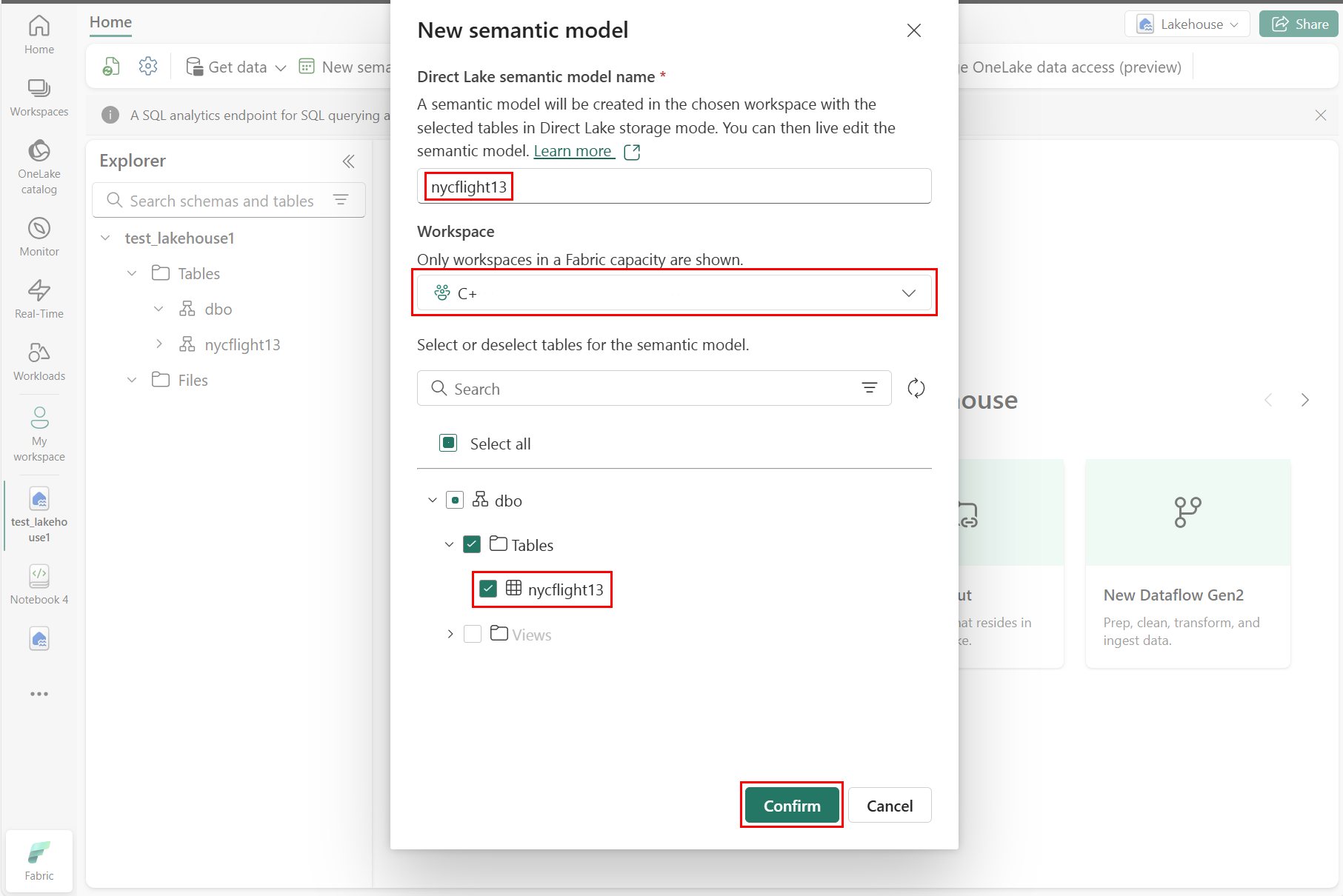
Um einen neuen Bericht zu erstellen, wählen Sie " Neuen Bericht erstellen" aus, wie im folgenden Screenshot gezeigt:
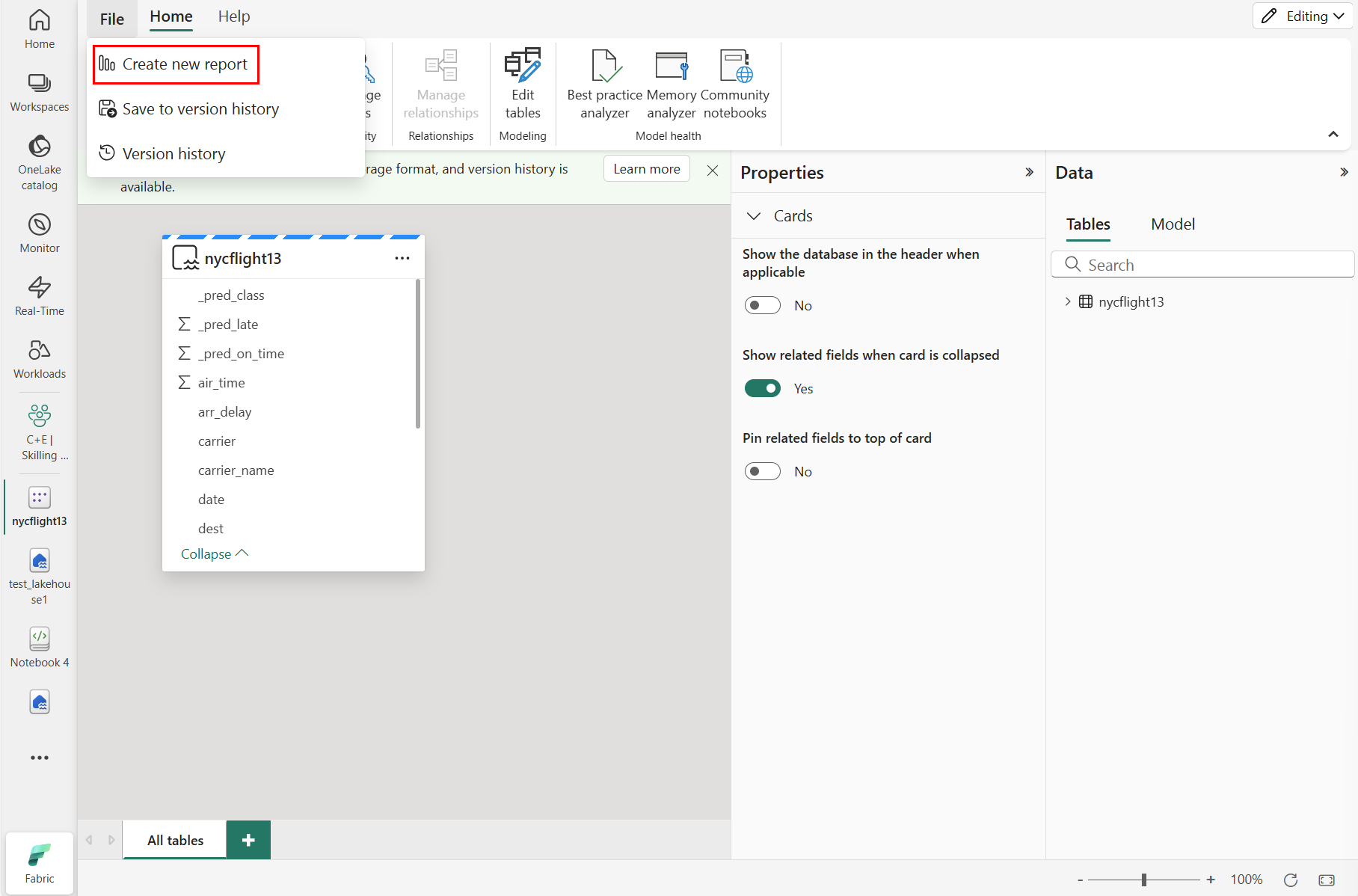
Wählen oder ziehen Sie Felder aus den Daten- und Visualisierungsbereichen in die Berichtscanvas, um den Bericht zu erstellen
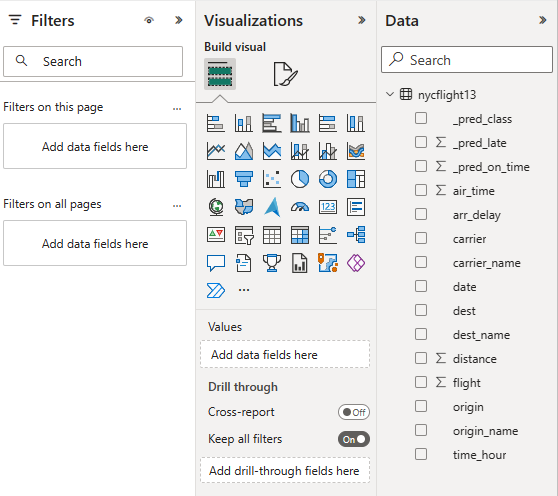






Verwenden Sie die folgenden Visualisierungen und Daten, um den am Anfang dieses Abschnitts angezeigten Bericht zu erstellen:
-
 Ein gestapeltes Balkendiagramm mit:
Ein gestapeltes Balkendiagramm mit: - y-Achse: carrier_name
- X-Achse: Flug. Wählen Sie Anzahl für die Aggregation aus.
- Legende: origin_name
-
Ein gestapeltes Balkendiagramm mit:
- Y-Achse: dest_name
- X-Achse: Flug. Wählen Sie Anzahl für die Aggregation aus.
- Legende: origin_name
-
 Datenschnitt mit:
Datenschnitt mit:- Feld: _pred_class
-
Datenschnitt mit:
- Feld: _pred_late