Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
Mit dem Fabric-Daten-Agent können Organisationen Unterhaltungssysteme mithilfe von generativer KI erstellen. Durch die Verbindung von Power BI-Semantikmodellen als Datenquellen können Teams Fragen in natürlicher Sprache stellen und präzise, kontextreiche Antworten erhalten, ohne komplexe DAX- oder SQL-Abfragen zu schreiben.
Die Qualität der KI-Antworten hängt jedoch stark davon ab, wie gut Sie Ihre Datenquellen vorbereiten. Während Fabric-Daten-Agent mehrere Datenquellentypen unterstützt, einschließlich Lakehouses, Warehouses, Eventhouses und Ontologien, konzentriert sich dieser Leitfaden speziell auf Power BI-Semantikmodelle und durchläuft bewährte Methoden für die Konfiguration, um Genauigkeit und Relevanz zu maximieren.
Funktionsweise des Fabric-Datenagents
Der Daten-Agent verwendet eine mehrschichtige Architektur, in der Benutzerfragen durch einen Orchestrator fließen. Der Orchestrator bestimmt die entsprechende Datenquelle und ruft spezielle Tools auf, einschließlich des DAX-Generierungstools für Power BI-Semantikmodelle zum Generieren, Überprüfen und Ausführen von Abfragen.
Der Abfrageverarbeitungsfluss
Frageanalyse: Der Agent verarbeitet Benutzerfragen über Azure OpenAI, gewährleistung der Einhaltung von Sicherheitsprotokollen und Berechtigungen und einhaltung der Microsoft Responsible AI-Prinzipien.
Datenquellenauswahl: Das System bewertet die Frage mithilfe von Schemainformationen und KI-Anweisungen, die Sie bereitstellen, gegenüber den verfügbaren Quellen.
Abfragegenerierung: Für semantische Modelle generiert das DAX-Generierungstool DAX-Abfragen basierend auf dem Schema, den Metadaten (Synonyme, Min- und Max-Werte numerischer Spalten, grafische Berichtsmetadaten und mehr), dem Kontext, welcher in Daten für KI vorbereiten konfiguriert ist, und dem Unterhaltungsverlauf.
Antwortformatierung: Der Agent formatiert Ergebnisse in lesbare Antworten mit Tabellen, Zusammenfassungen oder Erkenntnissen basierend auf den Agentanweisungen.

Vorbereitung für KI: Machen Sie das semantische Modell KI bereit.
Das Feature "Prep for AI" von Power BI bietet drei Konfigurationskomponenten, die sich direkt darauf auswirken, wie Fabric-Daten-Agent Ihr Semantikmodell interpretiert. Sie können auf diese Komponenten sowohl in Power BI Desktop als auch im Power BI-Dienst zugreifen. Power BI Copilot verwendet auch Prep für KI-Konfigurationen. Wenn Sie Zeit in die Konfiguration investieren, profitieren sowohl der Copilot als auch die Daten-Agent-Antworten davon.
Von Bedeutung
Beim Abfragen von Semantikmodellen basiert das vom Daten-Agent verwendete DAX-Generierungstool ausschließlich auf den Metadaten des Semantikmodells und der Vorbereitung für KI-Konfigurationen. Das DAX-Generierungstool ignoriert alle Anweisungen, die Sie auf Daten-Agent-Ebene für die DAX-Abfragegenerierung hinzufügen. Die richtige Vorbereitung für die KI-Konfiguration ist für genaue Ergebnisse unerlässlich.
KI-Datenschemas
MIT KI-Datenschemas können Sie eine fokussierte Teilmenge Ihres Modells für die KI-Priorisierung definieren. Der Daten-Agent verfügt zwar auch über eine eigene Tabellenauswahl beim Hinzufügen eines semantischen Modells als Datenquelle, konfigurieren Sie ihr Schema jedoch zuerst in Prep für KI. Das DAX-Generierungstool verwendet dieses Schema zum Erstellen von DAX-Abfragen.
Sie können dieses Schema in Power BI Desktop oder dem Power BI-Dienst konfigurieren, indem Sie im Menüband "Start" die Option "Vorbereiten von Daten für KI " auswählen. Navigieren Sie dann zur Registerkarte " Datenschema vereinfachen ". Wählen Sie dort aus, welche Tabellen, Spalten und Measures die KI beim Generieren von Antworten verwenden soll. Ausführliche Einrichtungsanweisungen finden Sie unter Festlegen eines KI-Datenschemas.

Wenn Sie das Semantikmodell zum Daten-Agent hinzufügen, wählen Sie die gleichen Tabellen aus, die Sie in Prep für KI definiert haben, um ein konsistentes Verhalten sicherzustellen. Definieren Sie zunächst den Umfang Ihres Datenagenten (die Arten von Fragen, die er beantworten sollte). Wählen Sie dann nur die relevanten Objekte aus. Dieser Ansatz reduziert Mehrdeutigkeit, verbessert die Genauigkeit und verringert die Antwortlatenz.
Das DAX-Generierungstool basiert auf den Metadaten Ihres Modells, um Fragen zu interpretieren. Verwenden Sie klare, unternehmensfreundliche Namen für Tabellen, Spalten und Measures, die widerspiegeln, wie Benutzer natürlich auf die Daten verweisen. Verwenden Sie z. B. "Gesamtumsatz" anstelle von "TR_AMT" oder "Vertriebsregion" anstelle von "DIM_GEO_01". Diese Anleitung ist besonders wichtig für große Modelle mit überlappenden oder ähnlich benannten Feldern, bei denen mehrdeutige Namen zu einer falschen Abfragegenerierung führen können.
Beispiel: Auflösen der Mehrdeutigkeit des Felds
| Ohne AI-Datenschema | Mit AI-Datenschema |
|---|---|
Ein Benutzer fragt: "What were our sales last quarter?" Das semantische Modell enthält mehrere umsatzbezogene Measures: Gesamtumsatz, Bruttoumsatz, Nettoumsatz und Umsatz nach Rückgaben. Die KI gibt den Bruttoumsatz zurück, aber Ihr Team verwendet in der Regel den Nettoumsatz für die Quartalsberichterstattung. |
Nachdem Sie das KI-Datenschema so konfiguriert haben, dass nur Nettoumsatz einbezogen und die anderen nicht relevanten Measures ausgeschlossen werden, gibt die gleiche Frage jetzt die erwartete Metrik zurück. Die KI muss nicht mehr erraten, welches "Umsatz"-Measure der Benutzer beabsichtigt hat. |
Tipps für KI-Datenschemas
Stellen Sie für konsistente und genaue Ergebnisse sicher, dass Sie dieselben Tabellen im Fabric-Daten-Agent auswählen, die auch über KI-Datenschemas in Prep für KI definiert sind.
Schließen Sie beim Auswählen des Schemas auch abhängige Objekte ein. Wenn beispielsweise ein Maß "Gesamtumsatz" auf zwei weitere Maße verweist, die von zusätzlichen Spalten abhängen, schließen Sie alle diese abhängigen Objekte in Ihr Schema ein. Verwenden Sie zum Identifizieren von Abhängigkeiten die get_measure_dependencies-Funktion aus der Bibliothek "Semantische Verknüpfungslabore ".
Wenn Sie über ein großes Semantikmodell verfügen, kann das manuelle Umbenennen aller Objekte mühsam sein. Verwenden Sie den Power BI Modeling MCP-Server, um geschäftsfreundliche Namen für Ihre Tabellen, Spalten und Maße mithilfe eines LLM zu generieren. Überprüfen und validieren Sie die Änderungen vor dem Speichern, um sicherzustellen, dass sie keine DAX-Ausdrücke, Beziehungen oder andere abhängige Objekte unterbrechen.
Überprüfte Antworten
Überprüfte Antworten sind vom Benutzer genehmigte visuelle Antworten, die bestimmte Fragen auslösen. Sie bieten konsistente, zuverlässige Antworten auf häufig gestellte oder komplexe Fragen, die andernfalls falsch interpretiert werden könnten. Da Sie die überprüften Antworten auf der semantischen Modellebene (nicht auf der Berichtsebene) speichern, funktionieren sie für alle Daten-Agenten, die dasselbe Modell verwenden. Weitere Informationen finden Sie unter "Vorbereiten Ihrer Daten für KI – Überprüfte Antworten".
Wenn Sie überprüfte Antworten mit dem Daten-Agent verwenden, gibt das System das Power BI-Visuelle selbst nicht zurück. Stattdessen werden die Fragen des Benutzers und die Eigenschaften des visuellen Elements (Spalten, Measures, Filter) verwendet, um die DAX-Abfragegenerierung zu beeinflussen. Dieser Ansatz bedeutet, dass überprüfte Antworten die Antwortgenauigkeit verbessern, indem das DAX-Generierungstool zur richtigen Abfragestruktur geleitet wird. Wenn ein Benutzer dem Daten-Agent eine Frage stellt, sucht das System zunächst nach einer genauen oder semantischen Übereinstimmung mit ihrer in der überprüften Antwort definierten Eingabeaufforderung, bevor eine neue Antwort generiert wird.

Beispiel: Behandeln regionaler Terminologie
| Ohne überprüfte Antwort | Mit bestätigter Antwort |
|---|---|
Ein Benutzer fragt: "Show me performance by territory" Die KI interpretiert "Gebiet" als Produktkategorie, da in der Tabelle "Produkte" eine Spalte "Gebiet" vorhanden ist. Der Benutzer meinte tatsächlich Vertriebsregionen. |
Sie erstellen eine überprüfte Antwort mithilfe eines regionalen Verkaufsvisuals mit Triggerfragen wie "What is the sales performance by territory?""Nach Gebiet aufgeschlüsselte Verkäufe anzeigen" und "Wie werden Verkäufe über Regionen verteilt?" Wenn Benutzer nun nach Gebietsleistung fragen, erhalten sie auf der Grundlage der Objekte, die in der visuellen Region verwendet werden, konsistente Antworten. |
Konfigurationstipps für überprüfte Antworten
- Verwenden Sie fünf bis sieben Triggerfragen pro überprüfter Antwort, um natürliche Variationen abzudecken.
- Umfassen Sie sowohl formale als auch umgangssprachliche Ausdrücke, die Benutzer möglicherweise ausprobieren.
- Konfigurieren Sie bis zu drei Filter für flexibles Slicing, ohne mehrere überprüfte Antworten zu erstellen.
- Wenn Sie Tabellen, Spalten oder Measures umbenennen, auf die in einer überprüften Antwort verwiesen wird, aktualisieren Sie die überprüfte Antwort, und speichern Sie sie erneut, damit die Änderungen wirksam werden.
KI-Anweisungen
KI-Anweisungen in Prep für KI bieten Kontext, Geschäftslogik und Anleitungen direkt zum semantischen Modell. Sie helfen dabei, Terminologie zu klären, Analyseansätze zu leiten und kritischen Geschäfts- und semantischen Kontext bereitzustellen, den die KI sonst nicht verstehen würde.
Sie können diese Anweisungen in Power BI Desktop oder im Power BI-Dienst konfigurieren, indem Sie im Menüband "Start" Daten für KI vorbereiten auswählen und zur Registerkarte KI-Anweisungen hinzufügen navigieren. Ausführliche Einrichtungsanweisungen finden Sie in der KI-Anweisungsdokumentation.

KI-Anweisungen sind unstrukturierte Anleitungen, die der LLM interpretiert, aber es gibt keine Garantie dafür, dass sie genau befolgt werden. Klare, spezifische Anweisungen sind effektiver als komplexe oder widersprüchliche.
Wie bereits erwähnt, bezieht sich das DAX-Generierungstool nur auf die KI-Anweisungen, die in Prep für KI des semantischen Modells konfiguriert sind. Daten-Agent-Anweisungen werden nicht an das Tool übergeben und werden beim Abfragen von semantischen Modellen ignoriert. Fügen Sie aus diesem Grund keine spezifischen Semantikmodellanweisungen auf Daten-Agent-Ebene hinzu. Behalten Sie stattdessen alle Semantikmodellanweisungen in dem Bereich Prep für KI bei, sodass das DAX-Generierungstool sie nutzen kann. Anweisungen zum Daten-Agent sollten nur Anleitungen enthalten, die für alle im Agent konfigurierten Datenquellen gelten, z. B. allgemeine Einstellungen für die Formatierung von Antworten, Quellweiterleitungsregeln, allgemeine Abkürzungen, Ton usw. Beachten Sie außerdem, dass der Daten-Agent im Gegensatz zu anderen Datenquellen keine Datenquellenanweisungen oder Beschreibungen für semantische Modelle unterstützt.
Beispiel: Definieren der Geschäftsterminologie
| Ohne KI-Anweisungen | Mit KI-Anweisungen |
|---|---|
| Ein Benutzer fragt: "Wer waren die Top-Performer im letzten Monat?" Die KI versteht nicht, was "Top-Performer" in Ihrer Organisation bedeutet und gibt einen Fehler zurück oder fordert eine Klarstellung. | Sie fügen eine Anweisung hinzu: "Ein Top-Performer ist ein Vertriebsmitarbeiter, der 110% oder mehr seines monatlichen Kontingents erreicht. Verwenden Sie die Rep_Performance Tabelle und filtern Sie dort, wo Quota_Attainment >= 1,1" Jetzt interpretiert die KI die Frage richtig und gibt die richtigen Ergebnisse zurück. |
Effektive Anweisungsmuster
- Zeitraumdefinitionen: "Spitzensaison läuft von November bis Januar. Die Offsaison ist Februar bis April."
- Metrikeinstellungen: "Wenn Benutzer nach Rentabilität fragen, verwenden Sie das Contribution_Margin Measure, nicht Gross_Profit."
- Datenquellenrouting: "Bei Bestandsfragen priorisieren Sie die Warehouse_Inventory Tabelle über Sales_Orders.".
- Standardgruppierungen: "Sofern nicht anders angegeben, analysieren Sie den Umsatz nach Geschäftsquartal anstelle des Kalendermonats."
Zusätzlich zu Prep für KI verwendet das DAX-Abfragegenerierungstool auch Metadaten aus berichtsvisualen Elementen wie visuellem Titel, Spalten, Measures, Filtern usw. zur Verbesserung der Abfragegenauigkeit.
Empfohlener Implementierungsworkflow
Optimieren Des semantischen Modells: Optimieren Sie zunächst Ihr semantisches Modell für die Leistung. Schlechte Daten-Agent-Leistung kommt häufig aus einem schlecht gestalteten Semantikmodell, ineffizienten DAX-Measures oder einer Mischung aus den beiden. Wenn ein Benutzer eine Frage stellt, generiert der Daten-Agent eine DAX-Abfrage und führt sie anhand Ihres Modells aus. Ein gut optimiertes Modell verwendet weniger Ressourcen und erzielt eine schnellere Abfrageausführung. In einer konversationsbasierten Benutzeroberfläche erwarten Benutzer schnelle Antworten, sodass sich eine langsame Leistung direkt auf das Benutzererlebnis und die Akzeptanz auswirkt.
Darüber hinaus erzeugt ein aufgeblähtes Modell mit unnötigen Spalten, Tabellen und Measures mehr Rauschen, was die Genauigkeit der Antworten verringern kann, wenn das DAX-Generierungstool versucht, diese zu parsen. Indem Sie Ihr Modell frühzeitig optimieren, verhindern Sie auch Leistungsprobleme, wenn Ihre Daten wachsen und das Modell komplexer wird. Weitere Informationen finden Sie im Power BI-Kurs "Optimieren eines Modells zur Leistungsoptimierung ".
Verwenden Sie Best Practice Analyzer und Semantic Model Memory Analyzer in einem Fabric-Notizbuch, um Probleme wie falsche Datentypen, unnötige Spalten, Spalten mit hoher Kardinalität und ineffiziente DAX-Muster zu identifizieren. Fügen Sie Beschreibungen für Tabellen, Spalten und Maße hinzu, um dem LLM zu helfen, den Zweck jedes Objekts zu verstehen, das im KI-Datenschema enthalten ist.
Definieren der Vorbereitung für KI > AI-Datenschema: Konfigurieren Sie basierend auf dem Umfang Ihres Daten-Agents das KI-Datenschema in Prep für KI, indem Sie nur die Tabellen, Spalten und Measures auswählen, die für die Fragen relevant sind, die Ihr Agent beantworten sollte.
Erstellen einer Vorbereitung für KI > Überprüfte Antworten: Identifizieren Sie Ihre am häufigsten verwendeten Fragen und konfigurieren Sie überprüfte Antworten in Prep für KI mithilfe geeigneter visueller Elemente. Verwenden Sie vollständige, robuste Fragen als Trigger (keine Teilausdrücke), um die Übereinstimmungsgenauigkeit zu verbessern.
Hinzufügen des semantischen Modells zum Daten-Agent: Bevor Sie KI-Anweisungen in Prep für KI hinzufügen, testen und überprüfen Sie Antworten vom Daten-Agent. Dieser Schritt hilft Ihnen zu verstehen, wo KI-Anweisungen erforderlich sind, um die DAX-Abfragegenerierung zu verbessern.
Hinzufügen von Prep für KI > KI-Anweisungen: Basierend auf Ihren Validierungsergebnissen definieren Sie Geschäftsterminologie, Analysepräferenzen und Datenquellenprioritäten in Prep für KI-Anweisungen (nicht in den Daten-Agent-Anweisungen).
Vorbereiten visueller Berichte: Überprüfen Sie Berichte, die mit dem semantischen Modell verbunden sind, einschließlich ausgeblendeter visueller Elemente und Seiten, um sicherzustellen, dass visuelle Elemente beschreibende Titel aufweisen. Gut strukturierte visuelle Elemente helfen der KI, die Antworten mithilfe der visuellen Metadaten wie visuellem Titel, Tabelle, Spalte, verwendeten Maßeinheiten, angewendeten Filtern und vielem mehr herzuleiten.
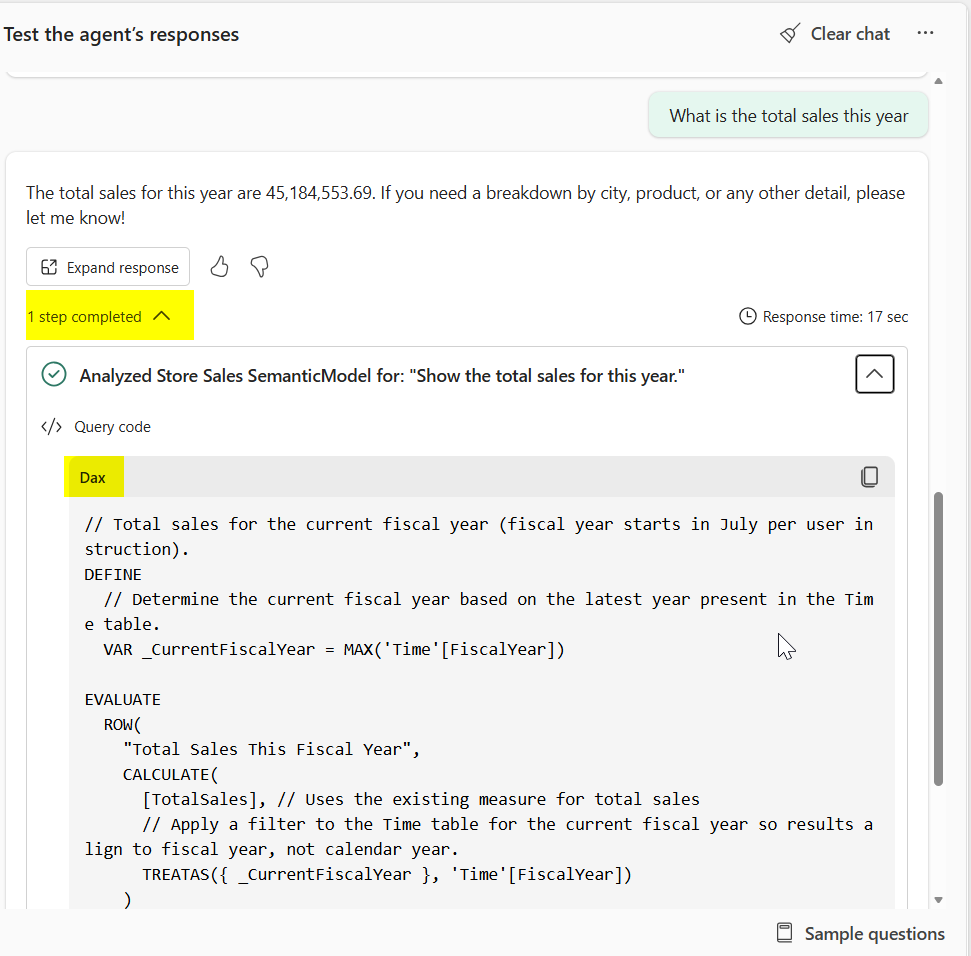
Überprüfen und Testen von DAX: Die Antwortgenauigkeit hängt von der generierten DAX-Abfrage ab. Überprüfen Sie beim Testen Ihres Daten-Agents die DAX-Abfrage in jeder Antwort, um zu überprüfen, ob sie gültig ist und die Frage richtig beantwortet. Wenn die Ergebnisse falsch sind, analysieren Sie den DAX, um zu ermitteln, welche Konfigurationen (semantisches Modell, AI-Datenschema, überprüfte Antworten oder KI-Anweisungen) Anpassungen benötigen.
Konfigurieren von Daten-Agent-Anweisungen: Fügen Sie Anweisungen nur auf Daten-Agent-Ebene hinzu, um Anleitungen zu erhalten, die für alle im Agent konfigurierten Datenquellen gelten. Dieser Leitfaden umfasst allgemeine Einstellungen für die Formatierung von Antworten, quellübergreifende Routingregeln, allgemeine Abkürzungen und Ton. Fügen Sie hier keine spezifischen Anweisungen für das Semantikmodell hinzu, da sie nicht an das DAX-Generierungstool übergeben werden. Anleitungen zum Konfigurieren von Agentanweisungen finden Sie in den Konfigurationsrichtlinien.
Validieren und Iterieren: LLMs können falsche Ergebnisse ohne richtigen Kontext erzeugen. Durchlaufen Sie kontinuierlich Ihre Konfiguration und überprüfen Sie Antworten, um Vertrauen in Ihren Daten-Agent zu schaffen. Um Antworten programmgesteuert auszuwerten, können Sie das Fabric-Datenagent Python-SDK verwenden, um automatisierte Auswertungen gegen Referenz-Fragen-Antwort-Paare auszuführen und Genauigkeitsmetriken zu analysieren. Beachten Sie, dass das SDK nur in diesem Fall für die Auswertung vorgesehen ist und die Vorbereitung des Semantikmodells nicht für KI-Konfigurationen ändern kann. Ausführliche Informationen finden Sie unter "Auswerten Ihres Daten-Agents". Binden Sie darüber hinaus Projektbeteiligte und Endbenutzer in den Evaluierungsprozess ein. Ihr Feedback stellt sicher, dass Antworten den erwartungen und der Benutzerfreundlichkeit in der Praxis entsprechen und Ihnen dabei helfen, Lücken zu erkennen, die automatisierte Prüfungen möglicherweise verpassen.
Implementieren von Quellcodeverwaltungs- und Bereitstellungspipelines: Verwenden Sie Git-Integrations- und Bereitstellungspipelinen, um Ihre Daten-Agent-Konfigurationen über Entwicklungs-, Test- und Produktionsarbeitsbereiche hinweg zu verwalten. Diese Übung stellt sicher, dass Konfigurationsänderungen getestet und überprüft werden, bevor sie in die Produktion höhergestuft werden, wo Endbenutzer darauf zugreifen. Ausführliche Informationen finden Sie unter Quellcodeverwaltung, CI/CD und ALM für Fabric-Daten-Agent.


Tipp
Sie können Ressourcen im Fabric-Toolbox-Repository als Referenz verwenden, um Sie durch diesen Workflow zu unterstützen. Dieses Repository enthält:
- Prüfliste zum Vorbereiten und Konfigurieren des semantischen Modells als Datenquelle
- Daten-Agent-Dienstprogramme-Notizbuch mit nützlichen Codeausschnitten und Hilfsfunktionen
Häufige Fallstricke, die vermieden werden sollen
Sternschema nicht verwenden: Semantische Modelle, die flache, denormalisierte Tabellen oder pivotierte Datenstrukturen verwenden, machen DAX weniger effizient und schwieriger, richtig zu schreiben. DAX ist für Sternschemas mit klaren Fakten- und Dimensionstabellen optimiert. Drehen Sie breite Tabellen in normalisierte Strukturen zurück, in denen jede Zeile eine einzelne Beobachtung darstellt.
Vertrauen auf ausgeblendete Felder: Überprüfte Antworten funktionieren nicht, wenn sie auf ausgeblendete Spalten im Modell verweisen.
Einschließlich unnötiger Maßnahmen: Semantische Modelle enthalten häufig Hilfsmaße und Zwischenobjekte, die zur Verbesserung der Berichtsinteraktivität verwendet werden. Schließen Sie beim Konfigurieren Ihres KI-Datenschemas nur die Measures ein, die tatsächliche Geschäftsmetriken berechnen. Das Ausschließen von Hilfsmaßnahmen reduziert das Rauschen und hilft dem DAX-Generierungstool, genauere Abfragen zu generieren.
Doppelte oder überlappende Measures: Mehrere Measures, die ähnliche Metriken berechnen (z. B. Total Sales, Sales Amount, Revenue) erzeugen Mehrdeutigkeit. Konsolidieren Sie Messgrößen oder unterscheiden Sie diese deutlich, und schließen Sie Duplikate aus Ihrem KI-Datenschema aus.
Nicht beschreibende Benennung: Objektnamen wie TR_AMT, F_SLS oder DIM_GEO_01 bieten keinen Kontext für das DAX-Generierungstool. Verwenden Sie klare, unternehmensfreundliche Namen wie "Gesamtumsatz", "Umsatz" oder "Kundengeografie". Wenn Sie Objekte nicht umbenennen können, stellen Sie sicher, dass Beschreibungen und Synonyme den erforderlichen Kontext für die KI bereitstellen, um ihren Zweck zu verstehen.
Vertrauen auf implizite Maßnahmen: Implizite Maßnahmen können zu unvorhersehbaren Ergebnissen führen. Erstellen Sie explizite DAX-Measures für Berechnungen, die Von Benutzern abgefragt werden sollen, und legen Sie die richtige Standardzusammenfassung (Summe, Mittelwert, Keine usw.) für numerische Spalten fest, um unbeabsichtigte Aggregationen zu verhindern.
Mehrdeutige Datumsfelder: Mehrere Datumsspalten (Bestelldatum, Lieferdatum, Fälligkeitsdatum, Kalenderquartal/Geschäftsjahrquartal usw.) ohne klare Richtlinien verwirren die KI. Verwenden Sie überprüfte Antworten und KI-Anweisungen in Prep für KI, um anzugeben, welches Datumsfeld standardmäßig oder für bestimmte Fragetypen verwendet werden soll.
Widersprüchliche Anweisungen: KI-Anweisungen, die überprüften Antwortkonfigurationen widersprechen, erzeugen unvorhersehbares Verhalten.
Schema-Verfeinerung wird übersprungen: Große Modelle mit vielen ähnlich benannten Feldern benötigen fokussierte KI-Datenschemas.
Übermäßig komplexe Anweisungen: Halten Sie Anweisungen fokussiert und spezifisch. Die KI interpretiert, gewährleistet jedoch nicht die Einhaltung komplexer, widersprüchlicher Hinweise. Komplexe Anweisungen können auch zur Latenz hinzugefügt werden.
Tools
Um diese Richtlinien zu befolgen, können Sie die folgenden Tools aus dem Fabric-Toolbox-GitHub-Repository verwenden:
- Checkliste mit Empfehlungen. Dies sind Richtlinien und nicht alle Elemente in der Checkliste können für Ihr Szenario gelten.
- Notizbuch mit Sammlung von Dienstprogrammen an einer zentralen Stelle.
- Power BI MCP Server zur Beschleunigung der Entwicklung und Tests in VS Code
- Bibliothek für semantische Verknüpfungslabore zum programmgesteuerten Aktualisieren des Semantikmodells im Fabric-Notizbuch.
Weitere Ressourcen
- Dokumentation zu Fabric-Daten-Agent-Konzepten
- Fabric-Toolbox mit Checkliste und Notizbüchern
- Hinzufügen eines semantischen Modells als Datenquelle zum Daten-Agent
- Vorbereiten Ihrer Daten für KI in Power BI
- Optimieren Des semantischen Modells für Copilot
- Optimieren eines Modells für die Leistung in Power BI – Schulung
- Häufig gestellte Fragen zur Vorbereitung für KI