Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
Gilt für:✅ Warehouse in Microsoft Fabric
In diesem Artikel werden die Features und Innovationen in der Architektur von Fabric Data Warehouse erläutert, die ihre Leistung, Skalierbarkeit und Kosteneffizienz steigern.
Fabric Data Warehouse wird auf einer zukunftsfähigen Architektur in einer zusammengeführten Datenplattform ausgeführt. Mit einem offenen Delta-Speicherformat und oneLake-Integration können Ihre Daten in Fabric Data Warehouse analysiert werden.
Allgemeine Architektur

Fabric Data Warehouse ist speziell für Analysen im großen Maßstab mit den folgenden Bausteinen konstruiert:
| Baustein | Beschreibung |
|---|---|
| Einheitlicher Abfrageoptimierer | Generiert einen optimalen Ausführungsplan für verteilte Cloudumgebungen, unabhängig von der Qualität von vom Benutzer erstellten SQL-Abfragen. |
| Verteilte Abfrageverarbeitung | Unterstützt massive parallele Abfrageausführung mit schneller automatischer Skalierung der Cloudinfrastruktur und stellt sofort erforderliche Computeressourcen für Abfragen bereit. Separate SELECT- und DML-Workloads verwenden unterschiedliche Pools für eine effiziente und isolierte Ausführung. |
| Abfrageausführungsmodul | Ein SQL-basiertes Modul zum Ausführen von Analyseabfragen für große Datenmengen mit schneller Leistung und hoher Parallelität. |
| Metadaten- und Transaktionsverwaltung | Metadaten befinden sich im Frontend, Back-End und sowohl im lokalen SSD-Cache als auch im Remotespeicher von OneLake. Unterstützt gleichzeitige Transaktionen und stellt die ACID-Compliance sicher. |
| Speicher in OneLake | Protokollstrukturierte Tabellen, implementiert mit dem open Delta table format, ein Lakehouse-Modell mit sicherem offenem Speicher. |
| Fabric-Plattform | Die Fabric-Plattform bietet ein einheitliches Authentifizierungs- und Sicherheitsmodell, überwachung und Überwachung. Ihr Fabric Data Warehouse ist automatisch für andere Fabric-Plattformdienste verfügbar, um geschäftliche Anforderungen zu erfüllen, einschließlich Power BI, Datenpipelinen in Data Factory, Real-Time Intelligence und mehr. |
Einheitliches Abfrageoptimierermodul
Der einheitliche Abfrageoptimierer in Fabric Data Warehouse ist das Modul, das die intelligenteste Methode zum Ausführen Ihrer SQL-Abfragen entscheidet.
Wenn Sie eine Abfrage übermitteln, untersucht der einheitliche Abfrageoptimierer mögliche Möglichkeiten zum Ausführen: Verknüpfen von Tabellen, Verschieben von Daten und Verwenden von Ressourcen wie CPU, Arbeitsspeicher und Netzwerk. Der einheitliche Abfrageoptimierer wählt nicht nur die erste Option aus, er wählt den optimalen Plan innerhalb der zulässigen Zeit aus, indem die Kosten für diese Faktoren und verfügbare Metadaten und Statistiken ausgewertet werden.
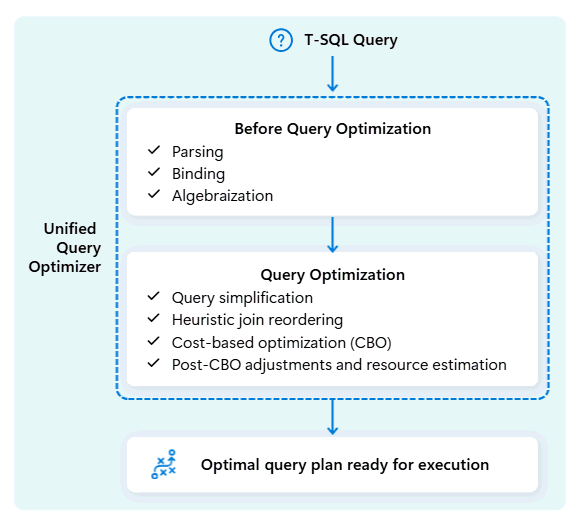
Bei der Optimierung des Ausführungsplans einer Abfrage berücksichtigt der einheitliche Abfrageoptimierer alles in einem Einzigen: das Shape Ihrer Abfrage, die Datenverteilung Ihrer Tabellen und die Kosten für das Verschieben von Daten im Vergleich zur lokalen Verarbeitung. Der einheitliche Abfrageoptimierer kann intelligente Kompromisse machen, z. B. entscheiden, ob das Übertragen einer kleinen Tabelle günstiger ist als das Mischen einer großen Tabelle. Dies bedeutet weniger unnötige Daten shuffles, eine bessere Berechnung und schnellere Leistung, auch für komplexe oder schlecht geschriebene T-SQL-Abfragen.
Eine konsistente Leistung erfordert keine Zeit für die manuelle T-SQL-Abfrageoptimierung. Beispielsweise müssen Sie die beste JOIN Reihenfolge in Abfragen nicht manuell ermitteln. Wenn Ihre SQL zuerst die große Tabelle und eine kleinere, hoch selektive Datentabelle an erster Stelle auflistet, kann der Optimierer ihre Positionen automatisch ändern, um eine bessere Leistung zu erzielen. Es verwendet die kleinere Tabelle als Ausgangspunkt für den Abgleich von Zeilen (die "Build"-Seite) und die größere Tabelle als die zu durchsuchende Tabelle (die "Probe"-Seite, die auf Übereinstimmungen überprüft wird). Bei diesem Ansatz wird die Speicherauslastung minimiert, die Datenverschiebung reduziert und parallelität verbessert, während dennoch genaue Ergebnisse erzielt werden.
Der einheitliche Abfrageoptimierer lernt kontinuierlich aus früheren Abfrageausführungen, während Workloads weiterentwickelt werden, und optimiert seinen Optimierungsalgorithmus, um die bestmögliche Leistung zu erzielen. Benutzer profitieren von der schnellen Abfrageausführung automatisch, unabhängig von der Komplexität und ohne Eingreifen.
Verteiltes Abfrageverarbeitungsmodul
In Fabric Data Warehouse weist das verteilte Abfrageverarbeitungsmodul Computerressourcen Vorgängen in Abfrageplänen zu. Das verteilte Abfrageverarbeitungsmodul kann Aufgaben über Computeknoten hinweg planen, sodass jeder Knoten Einen Teil eines Abfrageplans ausführt und eine parallele Ausführung für eine schnellere Leistung ermöglicht. Komplexe Berichte zu großen Datasets können von der verteilten Abfrageverarbeitung profitieren.
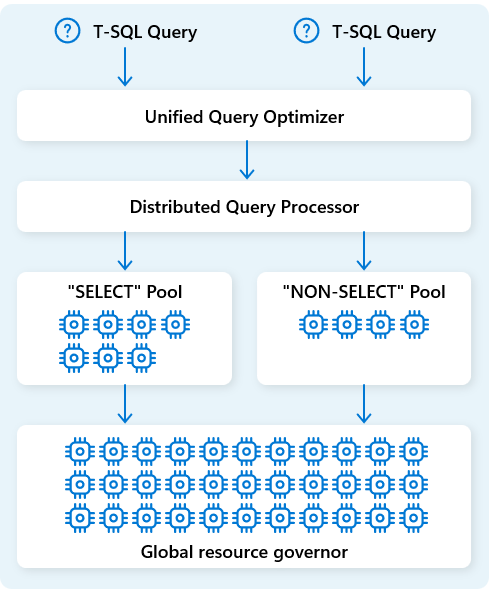
Um Ressourcen weiter zu optimieren, trennt das verteilte Abfrageverarbeitungsmodul Computeressourcen in zwei Pools: für SELECT Abfragen und für Datenaufnahmeaufgaben (NON-SELECT Abfragen). Jede Workload erhält bei Bedarf dedizierte Ressourcen. Dies bedeutet beispielsweise, dass Ihre nächtlichen ETL-Aufträge die Dashboards am Morgen nicht verzögern werden.
Mit der schnellen Bereitstellung von Knoten in der Cloud skaliert das verteilte Abfrageverarbeitungsmodul automatisch Computeressourcen nach oben oder unten als Reaktion auf Änderungen des Abfragevolumes, der Datengröße und der Abfragekomplexität. Fabric Data Warehouse verfügt über parallele Verarbeitungsfunktionen für kleine Datasets oder Daten im Multi-Petabyte-Maßstab.
Abfrageausführungs-Engine
Das Abfrageausführungsmodul ist ein Prozess, der Teile des verteilten Ausführungsplans ausführt, der den einzelnen Computeknoten zugewiesen ist. Das Abfrageausführungsmodul basiert auf demselben Modul, das von SQL Server und Azure SQL-Datenbank verwendet wird, um die Ausführung im Batchmodus und spaltenbasierte Datenformate für eine effiziente Analyse von Big Data zu optimalen Kosten zu verwenden.
Das Abfrageausführungsmodul liest Daten direkt aus Delta-Parkettdateien, die in Fabric OneLake gespeichert sind, und nutzt mehrere Cacheebenen (Speicher und SSD), um die Abfrageleistung zu beschleunigen und sicherzustellen, dass Abfragen mit optimaler Geschwindigkeit ausgeführt werden. Das Abfrageausführungsmodul verarbeitet Daten im Arbeitsspeicher und ruft bei Bedarf zusätzliche Daten aus dem SSD-Cache oder OneLake-Speicher ab.
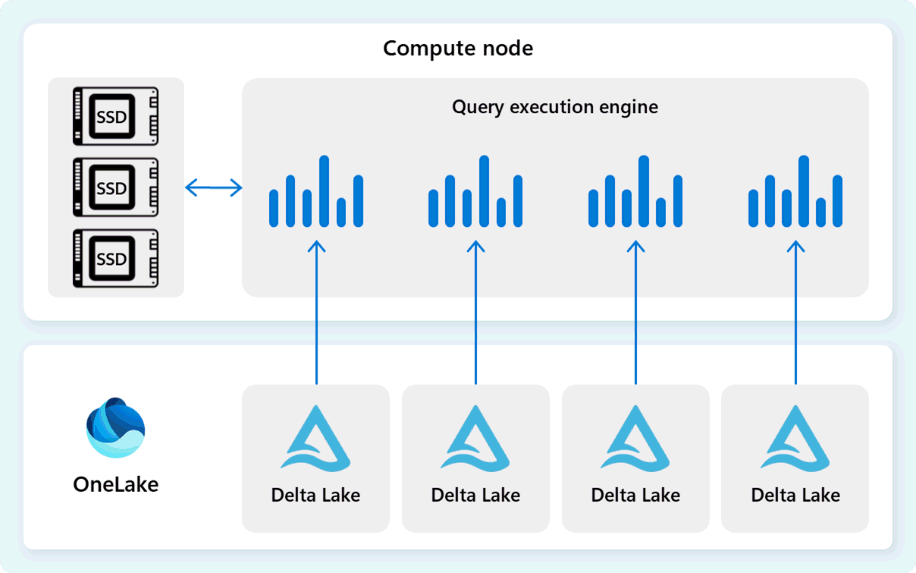
Beim Verarbeiten von Daten führt die Abfrageausführungs-Engine eine Spalten- und Zeilengruppen-Eliminierung durch, um Segmente zu überspringen, die für die Abfrage nicht relevant sind. Diese Optimierung reduziert die Datenmenge, die aus den Dateien und dem Speichercache gescannt wurde, um die Ressourcenauslastung zu minimieren und die Gesamtausführungszeit zu verbessern.
Das Abfrageausführungsmodul zeichnet sich durch das Filtern und Aggregieren von Milliarden von Zeilen aus und unterstützt die generischen Datenanalysemuster, die in modernen Data Warehouse-Lösungen verwendet werden. Die Batchmodusausführung nutzt die moderne CPU-Fähigkeit, mehrere Zeilen parallel zu verarbeiten, wodurch der Mehraufwand erheblich reduziert wird und Abfragen im Vergleich zur herkömmlichen Zeilenausführung bis zu Hunderten schneller ausgeführt werden.
Metadaten- und Transaktionsverwaltung
Das Warehouse-Modul verwendet Metadaten, um Tabellenschema, Dateiorganisation, Versionsverlauf und Transaktionszustände zu beschreiben. Diese Metadaten ermöglichen es dem Warehouse-Modul, Daten effizient zu verwalten und abzufragen. Fabric Data Warehouse bietet eine robuste und umfassende Metadaten- und Transaktionsverwaltungsarchitektur, erweitert einen OLTP-Transaktions-Manager, um hoch gleichzeitige Metadatenvorgänge zu koordinieren und die ACID-Compliance sicherzustellen.
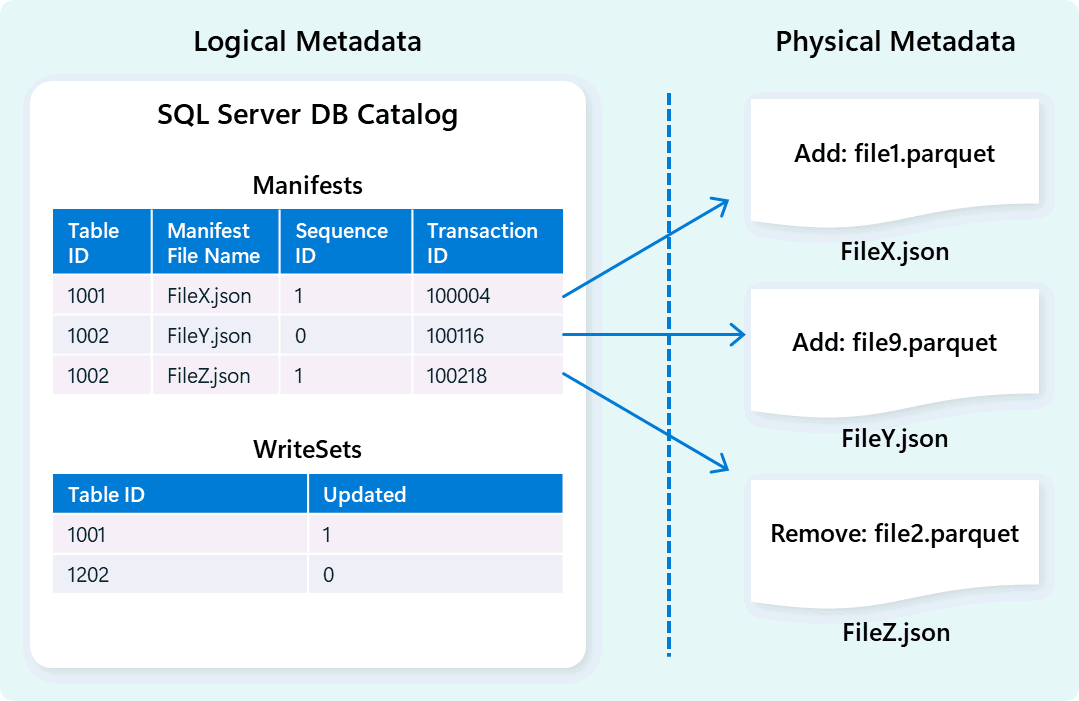
Dieses Design ermöglicht eine schnelle, zuverlässige Navigation von Transaktionszuständen, die Workloads mit hoher Parallelität unterstützen und gleichzeitig Konsistenz gewährleisten.
Speichern und Datenaufnahme
Fabric Data Warehouse verwendet eine Lakehouse-Architektur mit dem Open-Source-Delta-Format für skalierbaren, sicheren und leistungsstarken Speicher. Das Delta-Tabellenformat unterstützt die Datenversionsverwaltung und ermöglicht den sofortigen Zugriff auf historische Momentaufnahmen über Zeitreisen und Das Klonen von Nullkopien für sichere Tests und Rollbackvorgänge. Benutzerdaten werden in OneLake gespeichert, sodass alle Fabric-Engines ohne Redundanz effizient auf freigegebene Daten zugreifen können.
Basierend auf dieser Grundlage ist Fabric Data Warehouse so konzipiert, dass optimale Datenaufnahmeleistung mit dem Fokus auf Einfachheit und Flexibilität erzielt wird. Das Modul verwaltet die Tabellendatenspeicherung effizient durch automatische Datenkomprimierung, wodurch fragmentierte Dateien im Hintergrund konsolidiert werden, um unnötige Datenüberprüfungen zu reduzieren. Die intelligente Datenverteilungsmethode unterteilt und organisiert Daten in mikropartitionierte Zellen, um die parallele Verarbeitung zu steigern und Abfrageergebnisse zu verbessern. Diese Funktionen funktionieren eigenständig, ohne dass manuelle Anpassungen erforderlich sind.