Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
In diesem Lernprogramm führen Sie eine Abfrage an einer gespiegelten Fabric-Datenbank von einer bestehenden Cosmos DB innerhalb einer Fabric-Datenbank aus. Sie erfahren, wie Sie die Spiegelung in Ihrer Datenbank aktivieren, den Spiegelungsstatus überprüfen und dann sowohl die Quell- als auch die gespiegelten Daten für Analysen verwenden.
Voraussetzungen
Bestehende Fabric-Kapazität
- Wenn Sie über keine Fabric-Kapazität verfügen, starten Sie eine Fabric-Testversion.
Eine vorhandene Cosmos DB-Datenbank in Fabric
- Wenn Sie noch keine Datenbank besitzen, erstellen Sie eine neue Cosmos DB-Datenbank in Fabric.
Konfigurieren Sie Ihre Cosmos DB in der Fabric-Datenbank
Stellen Sie zunächst sicher, dass Ihre Cosmos DB in Fabric-Datenbank ordnungsgemäß konfiguriert ist und Daten für die Spiegelung enthält.
Öffnen Sie das Fabric-Portal (https://app.fabric.microsoft.com).
Navigieren Sie zu Ihrer vorhandenen Cosmos DB-Datenbank.
Von Bedeutung
Für dieses Lernprogramm sollte die vorhandene Cosmos DB-Datenbank den Beispieldatensatz bereits geladen haben. Bei den verbleibenden Schritten in diesem Lernprogramm wird davon ausgegangen, dass Sie denselben Datensatz für diese Datenbank verwenden.
Stellen Sie sicher, dass Ihre Datenbank mindestens einen Container mit Daten enthält. Führen Sie diese Überprüfung aus, indem Sie den Container im Navigationsbereich erweitern und beobachten, ob Elemente vorhanden sind.
Wählen Sie in der Menüleiste "Einstellungen" aus, um auf die Datenbankkonfiguration zuzugreifen.
Navigieren Sie im Dialogfeld "Einstellungen " zum Abschnitt " Spiegelung ", um zu überprüfen, ob die Spiegelung für diese Datenbank aktiviert ist.
Hinweis
Die Spiegelung wird automatisch für alle Cosmos DB-Datenbanken in Fabric aktiviert. Dieses Feature erfordert keine zusätzliche Konfiguration und stellt sicher, dass Ihre Daten immer in OneLake analysebereit sind.
Herstellen einer Verbindung mit der Quelldatenbank
Vergewissern Sie sich als Nächstes, dass Sie eine Direkte Verbindung mit der Cosmos DB-Quelldatenbank herstellen und abfragen können.
Navigieren Sie zurück zu Ihrer vorhandenen Cosmos DB-Datenbank im Fabric-Portal.
Wählen Sie ihren vorhandenen Container aus, und erweitern Sie diesen, um dessen Inhalt anzuzeigen.
Wählen Sie "Elemente" aus, um die Daten direkt in der Datenbank zu durchsuchen.
Stellen Sie sicher, dass die Elemente in Ihrem Container angezeigt werden können. Wenn Sie z. B. das Beispieldatenset verwenden, sollten Sie Elemente mit Eigenschaften wie
name,categoryundcountryOfOrigin.Wählen Sie im Menü "Neue Abfrage" aus, um den NoSQL-Abfrage-Editor zu öffnen.
Führen Sie eine Testabfrage aus, um die Konnektivität und Datenverfügbarkeit zu überprüfen:
SELECT COUNT(1) AS itemCount FROM containerDiese Abfrage sollte die Gesamtanzahl der Elemente in Ihrem Container zurückgeben.
Verbindung zur gespiegelten Datenbank herstellen
Greifen Sie nun über den SQL-Analyseendpunkt auf die gespiegelte Version Ihrer Datenbank zu, um dieselben Daten mit T-SQL abzufragen.
Wählen Sie in der Menüleiste die Cosmos DB-Liste und dann den SQL-Analyseendpunkt aus, um zur gespiegelten Datenbankansicht zu wechseln.
Überprüfen Sie, ob Ihr Container als Tabelle im SQL-Analyseendpunkt angezeigt wird. Die Tabelle sollte denselben Namen wie Ihr Container haben.
Wählen Sie im Menü neue SQL-Abfrage aus, um den T-SQL-Abfrage-Editor zu öffnen.
Führen Sie eine Testabfrage aus, um zu überprüfen, ob die Spiegelung ordnungsgemäß funktioniert:
SELECT COUNT(*) AS itemCount FROM [dbo].[SampleData]Hinweis
Ersetzen Sie
[SampleData]durch den Namen Ihres Containers, wenn Sie den Beispieldatensatz nicht verwenden.Die Abfrage sollte die gleiche Anzahl wie Ihre NoSQL-Abfrage zurückgeben und bestätigen, dass die Spiegelung ihre Daten erfolgreich repliziert.
Abfragen der Quelldatenbank aus Fabric
Verwenden Sie das Fabric-Portal, um die Daten zu untersuchen, die bereits in Ihrem Azure Cosmos DB-Konto vorhanden sind, und fragen Sie Ihre Cosmos DB-Quelldatenbank ab.
Navigieren Sie im Fabric-Portal zur gespiegelten Datenbank.
Wählen Sie "Ansicht" und dann " Quelldatenbank" aus. Diese Aktion öffnet den Azure Cosmos DB-Daten-Explorer mit einer schreibgeschützten Ansicht der Quelldatenbank.
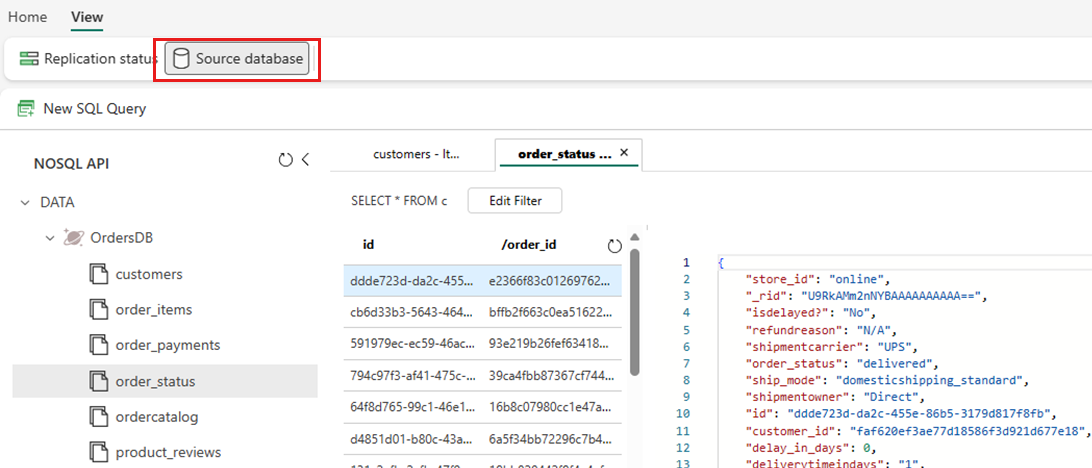
Wählen Sie einen Container aus, öffnen Sie dann das Kontextmenü, und wählen Sie "Neue SQL-Abfrage" aus.
Führen Sie eine beliebige Abfrage aus. Verwenden Sie
SELECT COUNT(1) FROM containerz. B. zum Zählen der Anzahl der Elemente im Container.Hinweis
Alle Lesevorgänge in der Quelldatenbank werden an Azure weitergeleitet und nutzen Anforderungseinheiten (Request Units, RUs), die dem Konto zugeordnet sind.

Analysieren der gespiegelten Zieldatenbank
Verwenden Sie nun T-SQL, um Ihre NoSQL-Daten abzufragen, die jetzt in Fabric OneLake gespeichert sind.
Navigieren Sie im Fabric-Portal zur gespiegelten Datenbank.
Wechseln Sie von Gespiegelter Azure Cosmos DB zu SQL-Analyseendpunkt.
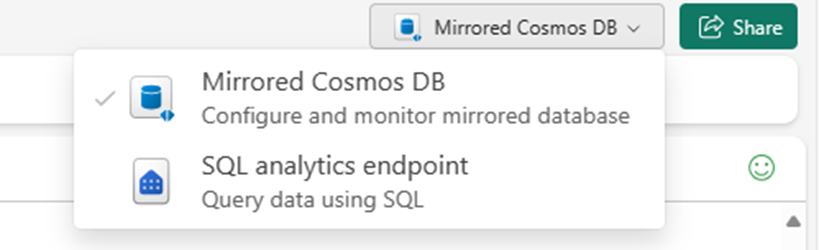
Jeder Container in der Quelldatenbank sollte im SQL-Analyseendpunkt als Lagertabelle dargestellt werden.
Wählen Sie eine beliebige Tabelle aus, öffnen Sie das Kontextmenü, wählen Sie dann "Neue SQL-Abfrage" und schließlich " Top 100" aus.
Die Abfrage wird ausgeführt und gibt 100 Datensätze in der ausgewählten Tabelle zurück.
Öffnen Sie das Kontextmenü für dieselbe Tabelle, und wählen Sie "Neue SQL-Abfrage" aus. Schreiben Sie eine Beispielabfrage, die Aggregate wie
SUM,COUNT,MINoderMAXverwendet. Verknüpfen Sie mehrere Tabellen im Lager, um die Abfrage über mehrere Container hinweg auszuführen.Hinweis
Diese Abfrage würde z. B. über mehrere Container hinweg ausgeführt:
SELECT d.[product_category_name], t.[order_status], c.[customer_country], s.[seller_state], p.[payment_type], sum(o.[price]) as price, sum(o.[freight_value]) freight_value FROM [dbo].[products] p INNER JOIN [dbo].[OrdersDB_order_payments] p on o.[order_id] = p.[order_id] INNER JOIN [dbo].[OrdersDB_order_status] t ON o.[order_id] = t.[order_id] INNER JOIN [dbo].[OrdersDB_customers] c on t.[customer_id] = c.[customer_id] INNER JOIN [dbo].[OrdersDB_productdirectory] d ON o.product_id = d.product_id INNER JOIN [dbo].[OrdersDB_sellers] s on o.seller_id = s.seller_id GROUP BY d.[product_category_name], t.[order_status], c.[customer_country], s.[seller_state], p.[payment_type]In diesem Beispiel wird der Name Ihrer Tabelle und Ihrer Spalten vorausgesetzt. Verwenden Sie beim Schreiben ihrer SQL-Abfrage Ihre eigene Tabelle und Spalten.
Wählen Sie die Abfrage und dann " Speichern unter" aus. Geben Sie der Ansicht einen eindeutigen Namen. Sie können jederzeit über das Fabric-Portal auf diese Ansicht zugreifen.
Kehren Sie zurück zur gespiegelten Datenbank im Fabric-Portal zurück.
Wählen Sie "Neue visuelle Abfrage" aus. Verwenden Sie den Abfrage-Editor, um komplexe Abfragen zu erstellen.
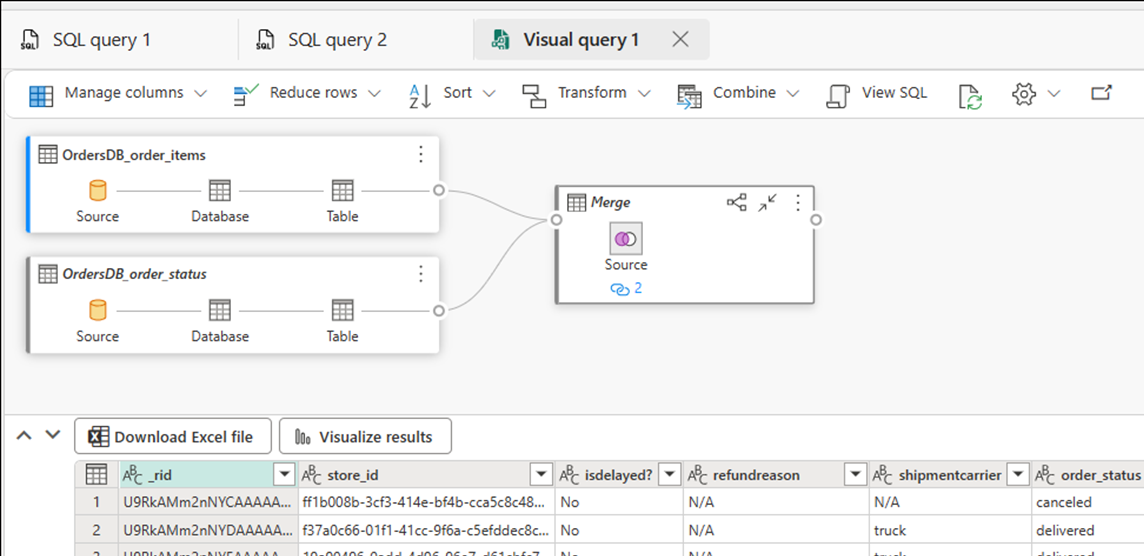


Erstellen von BI-Berichten für die SQL-Abfragen oder -Ansichten
- Wählen Sie die Abfrage oder Ansicht aus, und wählen Sie dann "Diese Daten durchsuchen" (Vorschau) aus. Diese Aktion untersucht die Abfrage in Power BI direkt mithilfe von Direct Lake auf OneLake gespiegelten Daten.
- Bearbeiten Sie die Diagramme nach Bedarf, und speichern Sie den Bericht.
Tipp
Sie können auch optional Copilot oder andere Verbesserungen verwenden, um Dashboards und Berichte ohne weitere Datenverschiebung zu erstellen.