Informationen zum Verbinden Sie gespiegelte Azure Cosmos DB-Daten mit anderen gespiegelten Datenbanken in Microsoft Fabric (Vorschau)
In dieser Anleitung verbinden Sie zwei Azure Cosmos DB for NoSQL-Container aus verschiedenen Datenbanken mit Hilfe einer Spiegelung in Fabric.
Sie können Daten aus Cosmos DB mit anderen gespiegelten Datenbanken, Warehouses oder Lakehouses im selben Fabric-Arbeitsbereich zusammenführen.
Wichtig
Die Spiegelung für Azure Cosmos DB befindet sich derzeit in der Vorschau. Produktionsworkloads werden in der Vorschauversion nicht unterstützt. Derzeit werden nur Azure Cosmos DB for NoSQL-Konten unterstützt.
Voraussetzungen
- Ein vorhandenes Azure Cosmos DB for NoSQL-Konto.
- Wenn Sie kein Azure-Abonnement besitzen, testen Sie Azure Cosmos DB for NoSQL kostenlos.
- Wenn Sie über ein Azure-Abonnement verfügen, erstellen Sie einen neuen Azure Cosmos DB for NoSQL-Cluster.
- Eine vorhandene Fabric-Kapazität. Wenn Sie noch keine Kapazität haben, starten Sie einen Fabric-Test.
- Aktivieren Sie die Spiegelung in Ihrem Fabric-Mandanten oder -Arbeitsbereich. Wenn das Feature nicht bereits aktiviert ist, aktivieren Sie die Spiegelung in Ihrem Fabric-Mandanten.
- Das Azure Cosmos DB for NoSQL-Konto muss für die Fabric-Spiegelung konfiguriert sein. Weitere Informationen finden Sie unter Kontoanforderungen.
Tipp
Es wird empfohlen, während der öffentlichen Vorschau eine Test- oder Entwicklungskopie Ihrer bestehenden Azure Cosmos DB-Daten zu verwenden, die schnell aus einem Backup wiederhergestellt werden kann.
Einrichten der Spiegelung und Voraussetzungen
Konfigurieren Sie die Spiegelung für die Azure Cosmos DB for NoSQL-Datenbank. Wenn Sie sich nicht sicher sind, wie Sie die Spiegelung konfigurieren, lesen Sie die Anleitung zur Konfiguration gespiegelter Datenbanken.
Navigieren Sie zum Fabric-Portal.
Erstellen Sie eine neue Verbindung mit den Anmeldedaten Ihres Azure Cosmos DB-Kontos.
Spiegeln Sie die erste Datenbank über die von Ihnen konfigurierte Verbindung.
Spiegeln Sie nun die zweite Datenbank.
Warten Sie, bis die Replikation den ersten Snapshot der Daten für beide Spiegel abgeschlossen hat.
Erstellen einer Abfrage, die Datenbanken verknüpft
Verwenden Sie nun den SQL-Analyseendpunkt, um eine Abfrage über zwei gespiegelte Datenbankelemente zu erstellen, ohne dass eine Datenbewegung erforderlich ist. Beide Elemente sollten sich im selben Arbeitsbereich befinden.
Navigieren Sie zu einer der gespiegelten Datenbanken im Fabric-Portal.
Wechseln Sie von Gespiegelte Azure Cosmos DB zum SQL-Analytics-Endpunkt.
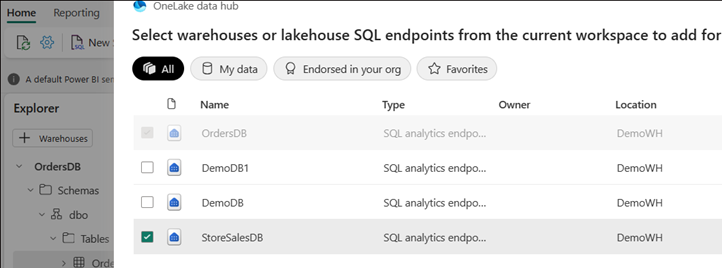
Wählen Sie im Menü i+ Warehouses aus. Wählen Sie das Element SQL-Analyse-Endpunkt für die andere gespiegelte Datenbank aus.
Öffnen Sie das Kontextmenü für die Tabelle, und wählen Sie Neue SQL-Abfrage aus. Schreiben Sie eine Beispielabfrage, die beide Datenbanken kombiniert.
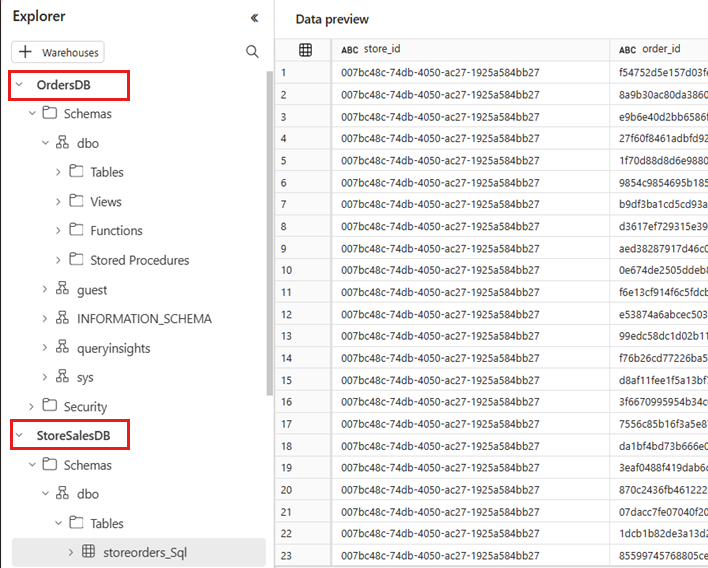
Diese Abfrage würde zum Beispiel in mehreren Containern und Datenbanken ausgeführt werden, ohne dass Daten verschoben werden. In diesem Beispiel wird der Name Ihrer Tabelle und Ihrer Spalten vorausgesetzt. Verwenden Sie beim Schreiben Ihrer SQL-Abfrage Ihre eigene Tabelle und Spalten.
SELECT product_category_count = COUNT (product_category), product_category FROM [StoreSalesDB].[dbo].[storeorders_Sql] as StoreSales INNER JOIN [dbo].[OrdersDB_order_status] as OrderStatus ON StoreSales.order_id = OrderStatus.order_id WHERE order_status='delivered' AND OrderStatus.order_month_year > '6/1/2022' GROUP BY product_category ORDER BY product_category_count descSie können Daten aus weiteren Quellen hinzufügen und sie nahtlos abfragen. Fabric vereinfacht und erleichtert das Zusammenführen von Organisationsdaten.

Zugehöriger Inhalt
Feedback
Bald verfügbar: Im Laufe des Jahres 2024 werden wir GitHub-Issues stufenweise als Feedbackmechanismus für Inhalte abbauen und durch ein neues Feedbacksystem ersetzen. Weitere Informationen finden Sie unter https://aka.ms/ContentUserFeedback.
Feedback senden und anzeigen für