Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
In diesem Leitfaden werden Sie:
Erstellen einer Pipeline in einem Arbeitsbereich und Erfassen von Daten in OneLake im Delta-Format
Lesen und Ändern einer Delta-Tabelle in OneLake mit Azure Databricks
Voraussetzungen
Bevor Sie beginnen können, benötigen Sie Folgendes:
Ein Arbeitsbereich mit einem Lakehouse-Element.
Ein Azure Databricks-Premium-Arbeitsbereich. Nur Azure Databricks-Premium-Arbeitsbereiche unterstützen das Microsoft Entra Passthrough. Aktivieren Sie beim Erstellen Ihres Clusters unter Erweiterte Optionen das Passthrough für Anmeldeinformationen in Azure Data Lake Storage.
Ein Beispieldataset
Erfassen von Daten und Ändern der Delta-Tabelle
Navigieren Sie im Power BI-Dienst zu Ihrem Lakehouse. Wählen Sie Daten abrufen und anschließend Neue Datenpipeline aus.
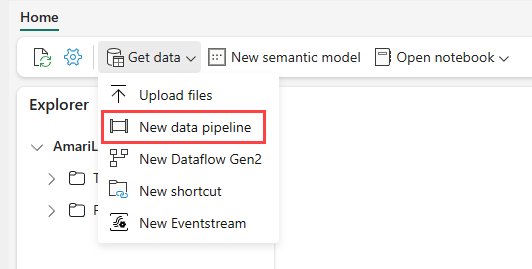
Geben Sie in der Eingabeaufforderung Neue Pipeline einen Namen für die neue Pipeline ein, und wählen Sie dann Erstellen aus.
Wählen Sie für diese Übung die Beispieldaten NYC Taxi – Green als Datenquelle aus.Wählen Sie dann Weiter aus.
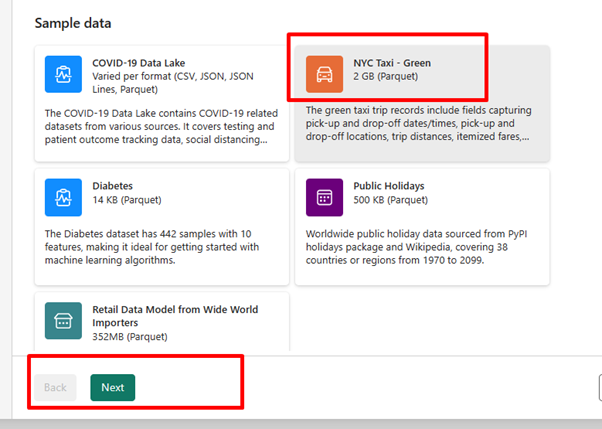
Wählen Sie auf dem Vorschaubildschirm erneut Weiter aus.
Wählen Sie als Datenziel den Namen des Lakehouse aus, das zum Speichern der OneLake-Delta-Tabellendaten verwendet werden soll. Sie können ein vorhandenes Lakehouse auswählen oder ein neues erstellen.
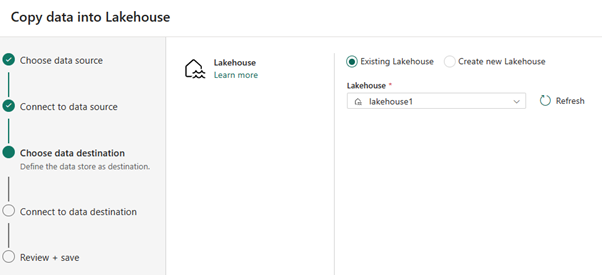
Wählen Sie aus, wo die Ausgabe gespeichert werden soll. Wählen Sie Tabellen als Stammordner aus, und geben Sie „nycsample“ als Tabellennamen ein.
Wählen Sie auf dem Bildschirm Überprüfen + Speichern die Option Datenübertragung sofort starten und dann Speichern + Ausführen aus.
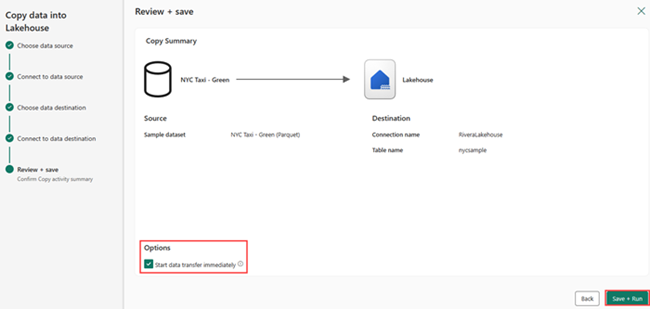
Wenn der Auftrag abgeschlossen ist, navigieren Sie zu Ihrem Lakehouse, und sehen Sie sich die Delta-Tabelle unter dem Ordner „/Tables“ an.
Klicken Sie mit der rechten Maustaste auf den Tabellennamen, wählen Sie Eigenschaften aus und kopieren Sie den Pfad für das Azure Blob Filesystem (ABFS).
Öffnen Sie Ihr Azure Databricks-Notebook. Lesen Sie die Delta-Tabelle in OneLake.
olsPath = "abfss://<replace with workspace name>@onelake.dfs.fabric.microsoft.com/<replace with item name>.Lakehouse/Tables/nycsample" df=spark.read.format('delta').option("inferSchema","true").load(olsPath) df.show(5)Aktualisieren Sie die Delta-Tabellendaten, indem Sie einen Feldwert ändern.
%sql update delta.`abfss://<replace with workspace name>@onelake.dfs.fabric.microsoft.com/<replace with item name>.Lakehouse/Tables/nycsample` set vendorID = 99999 where vendorID = 1;