Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
Verknüpfungen in Microsoft OneLake vereinheitlichen Ihre Daten über Domänen, Clouds und Konten hinweg, indem OneLake als der einzelne virtuelle Datensee für Ihr gesamtes Unternehmen fungiert. Fabric-Funktionen und Analysemodule können eine Verbindung mit Ihren vorhandenen Datenquellen herstellen, darunter Azure, Amazon Web Services (AWS) und OneLake über einen gemeinsamen Namespace. OneLake verwaltet alle Berechtigungen und Anmeldeinformationen, daher müssen Sie nicht jede Fabric Workload separat konfigurieren, um eine Verbindung mit jeder Datenquelle herzustellen. Darüber hinaus können Sie Tastenkombinationen verwenden, um Randkopien von Daten zu vermeiden und die Prozesslatenz im Zusammenhang mit Datenkopien und Staging zu verringern.
Was sind Verknüpfungen?
Verknüpfungen sind Objekte in OneLake, die auf andere Speicherorte verweisen. Der Speicherort kann innerhalb oder außerhalb von OneLake sein. Die Position, auf die eine Verknüpfung verweist, ist der Zielpfad der Verknüpfung. Die Position, an der die Verknüpfung angezeigt wird, ist der Verknüpfungspfad.
Verknüpfungen werden in OneLake als Ordner angezeigt und können von allen Workloads oder Diensten verwendet werden, die Zugriff auf OneLake haben. Verknüpfungen verhalten sich wie symbolische Verknüpfungen. Sie sind ein vom Ziel unabhängiges Objekt. Wenn Sie eine Verknüpfung löschen, bleibt das Ziel davon unberührt. Wenn Sie einen Zielpfad verschieben, umbenennen oder löschen, kann die Verknüpfung unterbrochen werden.

Wo kann ich Verknüpfungen erstellen?
Sie können Verknüpfungen in Lakehouses und Kusto Query Language (KQL)-Datenbanken erstellen.
Sie können das Fabric Portal verwenden, um Verknüpfungen interaktiv zu erstellen, und Sie können die REST-API verwenden, um Verknüpfungen programmgesteuert zu erstellen.
Lakehouse
Beim Erstellen von Verknüpfungen in einem Lakehouse müssen Sie die Ordnerstruktur des Elements verstehen. Lakehouses haben zwei Ordner auf oberster Ebene: den Ordner "Tabellen " und den Ordner "Dateien ". Der Tabellenordner richtet sich an strukturierte Datasets. Der Ordner "Dateien" dient für unstrukturierte oder halbstrukturierte Daten.
Im Tabellenordner können Sie Verknüpfungen nur auf oberster Ebene erstellen. OneLake unterstützt keine Verknüpfungen in Unterverzeichnissen des Tabellenordners. Verknüpfungen im Tabellenabschnitt verweisen in der Regel auf interne Quellen in OneLake oder verknüpfen mit anderen Datenressourcen, die dem Delta-Tabellenformat entsprechen. Wenn das Ziel der Verknüpfung Daten im Delta-Parquet-Format enthält, synchronisiert das Lakehouse automatisch die Metadaten und erkennt den Ordner als Tabelle. Abkürzungen im Tabellenbereich können entweder auf eine einzelne Tabelle oder ein Schema verweisen, bei dem es sich um einen übergeordneten Ordner für mehrere Tabellen handelt.
Hinweis
Das Deltaformat unterstützt keine Tabellen mit Leerzeichen im Namen. OneLake erkennt keine Verknüpfung, die ein Leerzeichen im Namen als Delta-Tabelle im Seehaus enthält.
Im Ordner "Dateien" gibt es keine Einschränkungen, wo Sie Verknüpfungen erstellen können. Sie können Verknüpfungen auf jeder Ebene der Ordnerhierarchie erstellen. Im Ordner „Dateien“ findet keine Tabellenerkennung statt. Tastenkombinationen können hier entweder auf interne OneLake- und externe Speichersysteme mit Daten in jedem Beliebigen Format verweisen.
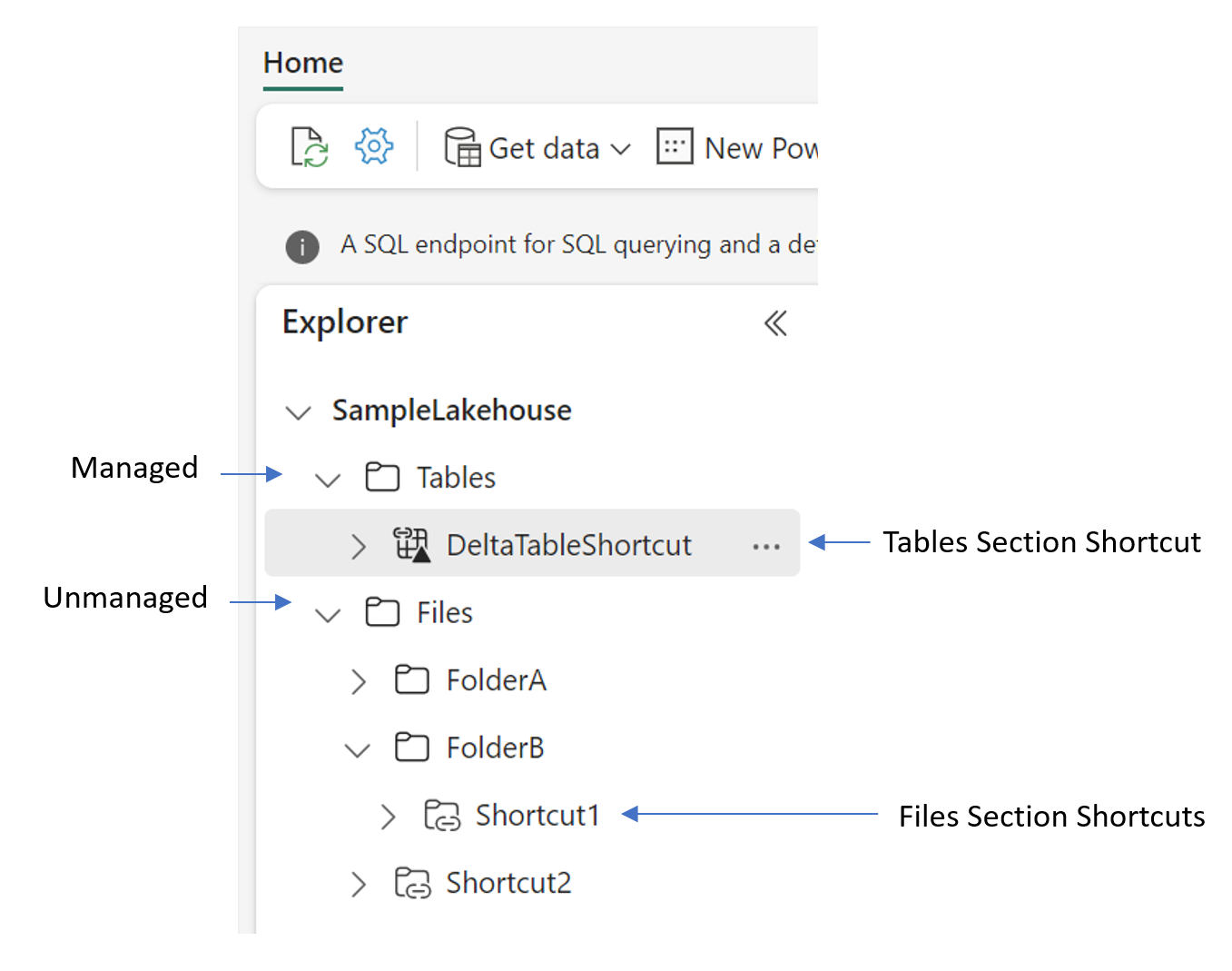
KQL-Datenbank
Wenn Sie eine Verknüpfung in einer KQL-Datenbank erstellen, wird sie im Ordner Shortcuts (Verknüpfungen) der Datenbank angezeigt. Die KQL-Datenbank behandelt Abkürzungen wie externe Tabellen. Um die Verknüpfung abzufragen, verwenden Sie die Funktion external_table der Kusto-Abfragesprache.
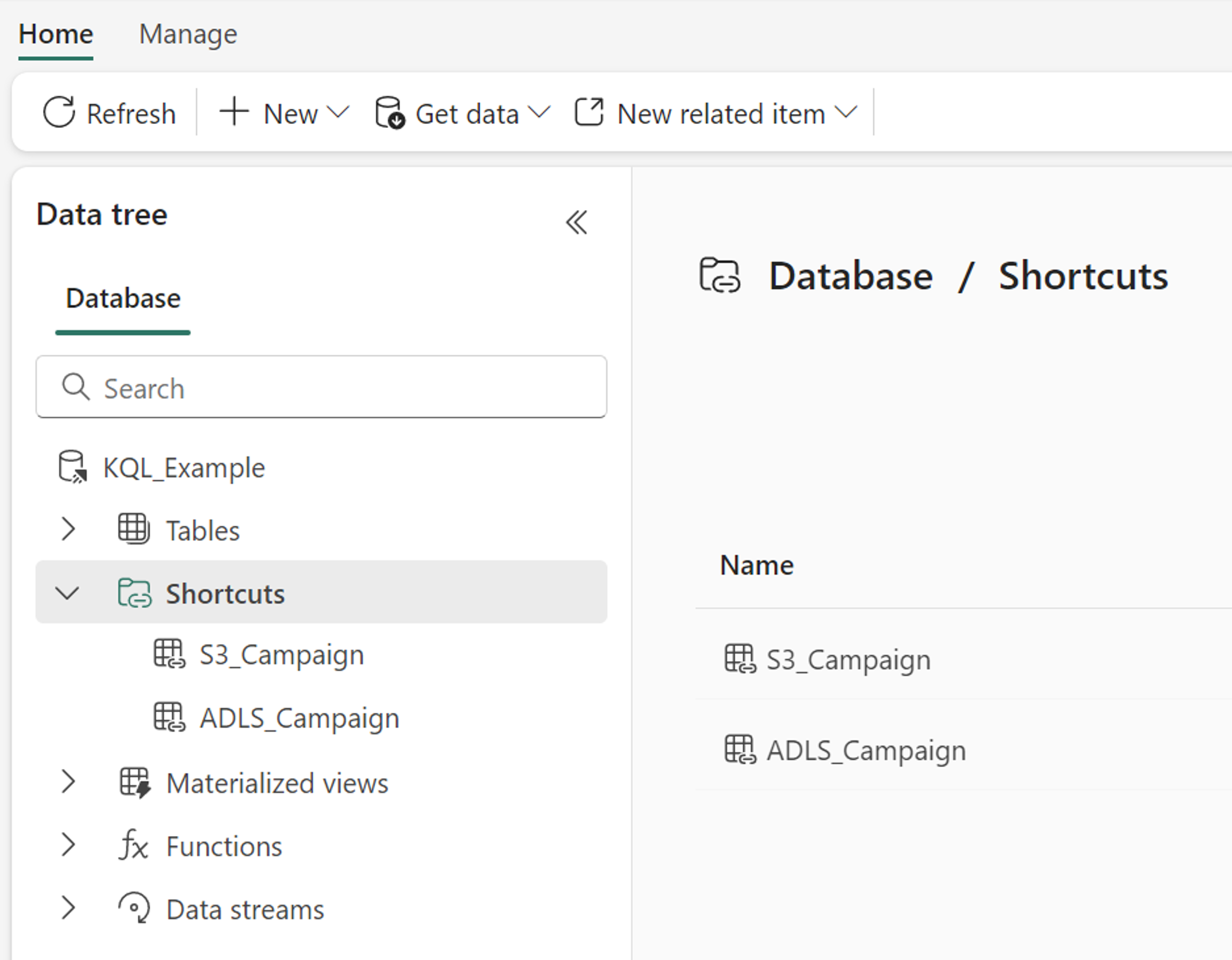
Wo kann ich auf meine Verknüpfungen zugreifen?
Jeder Fabric- oder Nicht-Fabric-Dienst, der auf Daten in OneLake zugreifen kann, kann Verknüpfungen verwenden. Verknüpfungen sind für jeden Dienst transparent, der über die OneLake-API auf Daten zugreift. Verknüpfungen werden schlicht wie ein anderer Ordner im Lake angezeigt. Apache Spark, SQL, Echtzeitintelligenz und Analysis Services können Abkürzungen beim Abfragen von Daten nutzen.
Apache Spark
Apache Spark-Notebooks und Apache Spark-Aufträge können Verknüpfungen nutzen, die Sie in OneLake erstellt haben. Verwenden Sie relative Dateipfade, um Daten direkt aus Verknüpfungen zu lesen. Wenn Sie eine Verknüpfung im Abschnitt Tabellen von Lakehouse erstellen und sie im Deltaformat vorliegt, können Sie sie auch als verwaltete Tabelle mithilfe der Apache Spark SQL-Syntax lesen.
df = spark.read.format("delta").load("Tables/MyShortcut")
display(df)
df = spark.sql("SELECT * FROM MyLakehouse.MyShortcut LIMIT 1000")
display(df)
SQL
Sie können Kurzbefehle im Abschnitt Tables (Tabellen) eines Lakehouses über den SQL-Analyseendpunkt des Lakehouses lesen. Sie können über die Modusauswahl des Lakehouses oder über SQL Server Management Studio (SSMS) auf den SQL-Analyseendpunkt zugreifen.
SELECT TOP (100) *
FROM [MyLakehouse].[dbo].[MyShortcut]
Echtzeit-Intelligenz
Abkürzungen in KQL-Datenbanken werden als externe Tabellen erkannt. Um die Verknüpfung abzufragen, verwenden Sie die Funktion external_table der Kusto-Abfragesprache.
external_table('MyShortcut')
| take 100
Analyse-Dienste
Sie können semantische Modelle für Lakehouses, die Verknüpfungen enthalten, im Abschnitt Tables (Tabellen) des Lakehouse erstellen. Wenn das semantische Modell im Direct Lake-Modus ausgeführt wird, kann Analysis Services Daten direkt aus der Verknüpfung lesen.
Nicht-Fabric-Dienste
Anwendungen und Dienste außerhalb des Fabric können auch über die OneLake-API auf Verknüpfungen zugreifen. OneLake unterstützt eine Teilmenge der ADLS Gen2- und Blob Storage-APIs. Weitere Informationen zur OneLake-API finden Sie unter OneLake-Zugriff mit APIs.
https://onelake.dfs.fabric.microsoft.com/MyWorkspace/MyLakhouse/Tables/MyShortcut/MyFile.csv
Typen von Verknüpfungen
OneLake-Abkürzungen unterstützen mehrere Datenquellen in Dateisystemen. Zu diesen Quellen gehören interne OneLake-Speicherorte und externe oder nicht-Microsoft-Quellen.
Sie können mithilfe des lokalen Fabric-Datengateways (OPDG) auch Verknüpfungen zu lokalen oder netzwerkbeschränkten Speicherorten erstellen.
Interne OneLake-Verknüpfungen
Verwenden Sie interne OneLake-Verknüpfungen, um auf Daten innerhalb vorhandener Fabric Elemente zu verweisen, einschließlich:
- KQL-Datenbanken
- Seehäuser
- Gespiegelte Azure Databricks-Kataloge
- Gespiegelte Datenbanken
- Semantikmodelle
- SQL-Datenbanken
- Lager
Anweisungen zum Erstellen einer internen Verknüpfung finden Sie unter Erstellen einer internen OneLake-Verknüpfung.
Die Verknüpfung kann auf einen Ordnerspeicherort innerhalb desselben Elements, zwischen Elementen innerhalb desselben Arbeitsbereichs oder sogar zwischen Elementen in verschiedenen Arbeitsbereichen verweisen. Wenn Sie eine Verknüpfung zwischen Elementen erstellen, müssen die Elementtypen nicht übereinstimmen. Sie können beispielsweise eine Verknüpfung in einem Lakehouse erstellen, die auf Daten in einem Data Warehouse verweist.
Wenn ein Benutzer über eine Verknüpfung auf Daten von einem anderen OneLake-Speicherort zugreift, verwendet OneLake die Identität des aufrufenden Benutzers, um den Zugriff auf die Daten zu autorisieren. Dieser Benutzer muss über Berechtigungen am Zielspeicherort verfügen, um die Daten lesen zu können.
Wichtig
Wenn Benutzer auf Power BI-Semantikmodelle mithilfe von DirectLake über SQL oder T-SQL-Engines im Modus der delegierten Identität zugreifen, wird die Identität des aufrufenden Benutzers nicht an die Zielverknüpfung übergeben. Stattdessen wird die Identität des Besitzers des aufrufenden Elements übergeben, wodurch der Zugriff auf den aufrufenden Benutzer delegiert wird. Um diese Einschränkung zu beheben, verwenden Sie Power BI semantischen Modelle in DirectLake über OneLake Modus oder T-SQL im Benutzeridentitätsmodus.
Externe OneLake-Tastenkombinationen
Detaillierte Anweisungen zum Erstellen eines bestimmten Verknüpfungstyps erhalten Sie, indem Sie einen Artikel aus dieser Liste der unterstützten externen Quellen auswählen.
- Amazon S3-Tastenkombinationen
- Mit Amazon S3 kompatible Tastenkombinationen
- Azure Data Lake Storage (ADLS) Gen 2-Tastenkombinationen
- Azure Blob Storage-Tastenkombinationen
- Dataverse-Verknüpfungen
- Google Cloud Storage-Tastenkombinationen
- Iceberg-Verknüpfungen
- OneDrive und SharePoint Tastenkombinationen
Zwischenspeicherung
Die Zwischenspeicherung von Tastenkombinationen kann die Kosten für den über cloudübergreifenden Datenzugriff verursachten Kosten reduzieren. Da OneLake Dateien über eine externe Verknüpfung liest, speichert der Dienst die Dateien im Cache für den Fabric Arbeitsbereich. OneLake antwortet auf nachfolgende Leseanforderungen aus dem Cache und nicht auf den Remotespeicheranbieter. Sie können den Aufbewahrungszeitraum für zwischengespeicherte Dateien zwischen 1 und 28 Tagen festlegen. Jedes Mal, wenn Sie auf die Datei zugreifen, wird der Aufbewahrungszeitraum zurückgesetzt. Wenn der Remotespeicher über eine neuere Version der Datei verfügt als die Version des Caches, liefert OneLake die Anforderung vom Remotespeicheranbieter und aktualisiert die Datei im Cache. Wenn Sie nicht innerhalb des ausgewählten Aufbewahrungszeitraums auf eine Datei zugreifen, wird sie aus dem Cache gelöscht. Einzelne Dateien, die größer als 1 GB sind, werden nicht zwischengespeichert.
Hinweis
Die Verknüpfungszwischenspeicherung unterstützt derzeit Google Cloud Storage (GCS), S3, S3-kompatible und auf lokalen Servern befindliche Datengateway-Verknüpfungen.
Das Zwischenspeichern wird auch für lokale Amazon S3-Verknüpfungen unterstützt, die Microsoft Entra Dienstprinzipalauthentifizierung verwenden.
Um die Zwischenspeicherung für Verknüpfungen zu aktivieren, öffnen Sie bitte den Bereich „Arbeitsbereichseinstellungen“. Wählen Sie die Registerkarte OneLake aus. Setzen Sie die Cacheeinstellung auf Ein, und wählen Sie den Aufbewahrungszeitraumaus.
Sie können den Cache jederzeit löschen. Wählen Sie auf derselben Einstellungsseite die Schaltfläche "Cache zurücksetzen" aus. Mit dieser Aktion werden alle Dateien aus dem Verknüpfungscache in diesem Arbeitsbereich entfernt.

So verwenden Verknüpfungen Cloudverbindungen
ADLS- und S3-Tastenkombinationen delegieren die Autorisierung mithilfe von Cloudverbindungen. Beim Erstellen einer neuen ADLS- oder S3-Verknüpfung erstellen Sie entweder eine neue Verbindung oder wählen eine vorhandene Verbindung für die Datenquelle aus. Das Festlegen einer Verbindung für eine Verknüpfung ist ein Bindungsvorgang. Nur Benutzer mit der Berechtigung für die Verbindung können den Bindungsvorgang ausführen. Wenn Sie nicht über die Berechtigung für die Verbindung verfügen, können Sie keine neuen Verknüpfungen mit dieser Verbindung erstellen.
Weitere Informationen zum Anzeigen und Aktualisieren von Cloud-Verbindungen finden Sie unter Verwalten von Verbindungen für Kurzbefehle.
Sicherheit mit Verknüpfungen
Verknüpfungen erfordern bestimmte Berechtigungen zum Verwalten und Verwenden. Die OneLake-Verknüpfungssicherheit erläutert die Berechtigungen, die Sie zum Erstellen von Verknüpfungen und zum Zugreifen auf Daten über sie benötigen.
Wie handhaben Verknüpfungen Löschungen?
Verknüpfungen unterstützen keine kaskadierenden Löschvorgänge. Wenn Sie eine Verknüpfung löschen, löschen Sie nur das Verknüpfungsobjekt. Die Daten im Verknüpfungsziel bleiben unverändert. Wenn Sie jedoch eine Datei oder einen Ordner in einer Verknüpfung löschen und über Berechtigungen im Verknüpfungsziel zum Ausführen des Löschvorgangs verfügen, löschen Sie auch die Datei oder den Ordner im Ziel.
Betrachten Sie zum Beispiel ein Seehaus mit dem folgenden Pfad darin: MyLakehouse\Files\MyShortcut\Foo\Bar.
MyShortcut ist eine Verknüpfung, die auf ein ADLS Gen2-Konto verweist, das die Verzeichnisse Foo\Bar enthält.
Wenn Sie MyLakehouse\Files\MyShortcut löschen, löschen Sie die Verknüpfung „MyShortcut“ aus dem Lakehouse. Die Dateien und Verzeichnisse im ADLS Gen2-Konto Foo\Bar bleiben jedoch unberührt.
Wenn Sie MyLakehouse\Files\MyShortcut\Foo\Bar löschen und über Schreibberechtigungen im ADLS Gen2-Konto verfügen, löschen Sie das Verzeichnis Bar aus dem ADLS Gen2-Konto.
Arbeitsbereichsherkunftsansicht
Wenn Sie Verknüpfungen zwischen mehreren Fabric Elementen in einem Arbeitsbereich erstellen, können Sie die Verknüpfungsbeziehungen über die Arbeitsbereichslinienansicht visualisieren. Wählen Sie in der oberen rechten Ecke des Arbeitsbereichs-Explorers die Schaltfläche Herkunftsansicht ( ) aus.
) aus.

Hinweis
Der Umfang der Herkunftsansicht ist auf einen einzelnen Arbeitsbereich beschränkt. Verknüpfungen zu Orten außerhalb des ausgewählten Arbeitsbereichs werden nicht angezeigt.
Einschränkungen und Aspekte
- Jedes Fabric Element unterstützt bis zu 100.000 Tastenkombinationen. In diesem Zusammenhang bezieht sich der Begriffsartikel auf Apps, Seehäuser, Lagerhäuser, Berichte und vieles mehr.
- Ein einzelner OneLake-Pfad unterstützt bis zu 10 Tastenkombinationen.
- Die maximale Anzahl direkter Verknüpfungen mit Verknüpfungslinks beträgt 5.
- OneLake-Verknüpfungsnamen, übergeordnete Pfade und Zielpfade dürfen keine „%“- oder „+“-Zeichen enthalten.
- Verknüpfungen unterstützen keine nicht lateinischen Zeichen.
- Die Herkunft für Verknüpfungen zu Data Warehouses und Semantikmodellen ist derzeit nicht verfügbar.
- Eine Fabric-Shortcut wird fast sofort mit der Quelle synchronisiert, die Fortpflanzungszeit kann jedoch aufgrund von Datenquellenleistung, Zwischenspeicheransichten oder Netzwerkkonnektivitätsproblemen variieren.
- Bis zu einer Minute kann es dauern, bis die Tabellen-API neue Verknüpfungen erkennt.