Optionen für Geschäftskontinuität und Notfallwiederherstellung für FSLogix
Hinweis
Alle Diagramme sind Beispiele, die auf Azure Virtual Desktop basieren und auch auf andere virtuelle Desktopplattformen anwendbar sind.
Ein effektiver Plan für Geschäftskontinuität und Notfallwiederherstellung (BCDR) konzentriert sich auf die Prozesse und Ressourcen, die eine Organisation benötigt, um im Fall einer Katastrophe oder eines anderen maßgeblichen Ausfalls weiterarbeiten zu können. Roamingbenutzerprofile werden in der Regel nicht als geschäfts- oder unternehmenskritische Komponente einer BCDR-Strategie beschrieben. In einer virtuellen Desktopumgebung wissen Benutzerinnen und Benutzer nicht, dass sie ein Roamingprofil haben. Das Profil wird übertragen, um den Benutzerinnen und Benutzer unabhängig von der virtuellen Maschine ein einheitliches Erlebnis zu bieten. Geschäfts- oder unternehmenskritische Daten sollten wenn möglich nicht im Profil eines Benutzers gespeichert werden. Die Verwendung von OneDrive, SharePoint oder anderen Lösungen ist ein effektives Mittel, Daten während eines BCDR-Ereignisses zu schützen, ohne sich auf das Datenroaming in Verbindung mit dem Benutzerprofil zu verlassen. Dieser Prozess lässt sich am besten in einer Übung mit Wiederherstellungszeitzielen (RTO) und Wiederherstellungspunktzielen (RPO) skizzieren, bei der die Kosten-Nutzen- und Risiko-Analyse auf der Grundlage der Unternehmens- und Geschäftsziele abgewogen werden.
Option 1: Keine Profilwiederherstellung
Obwohl diese Option nicht wie ein BCDR-Design aussieht, ist sie jedoch darauf ausgerichtet, sicherzustellen, dass geschäfts- und unternehmenskritische Daten nicht im Benutzerprofil enthalten sind. Im Katastrophenfall würden die Benutzer neue Profile entweder an einem neuen Standort oder bei einem neuen Speicheranbieter erstellen (beides kann zutreffen). Diese Option ist im Bezug auf die Infrastrukturkosten die kostengünstigste, hat jedoch einen Nachteil, da sie sich auf die Benutzerfreundlichkeit auswirken kann.
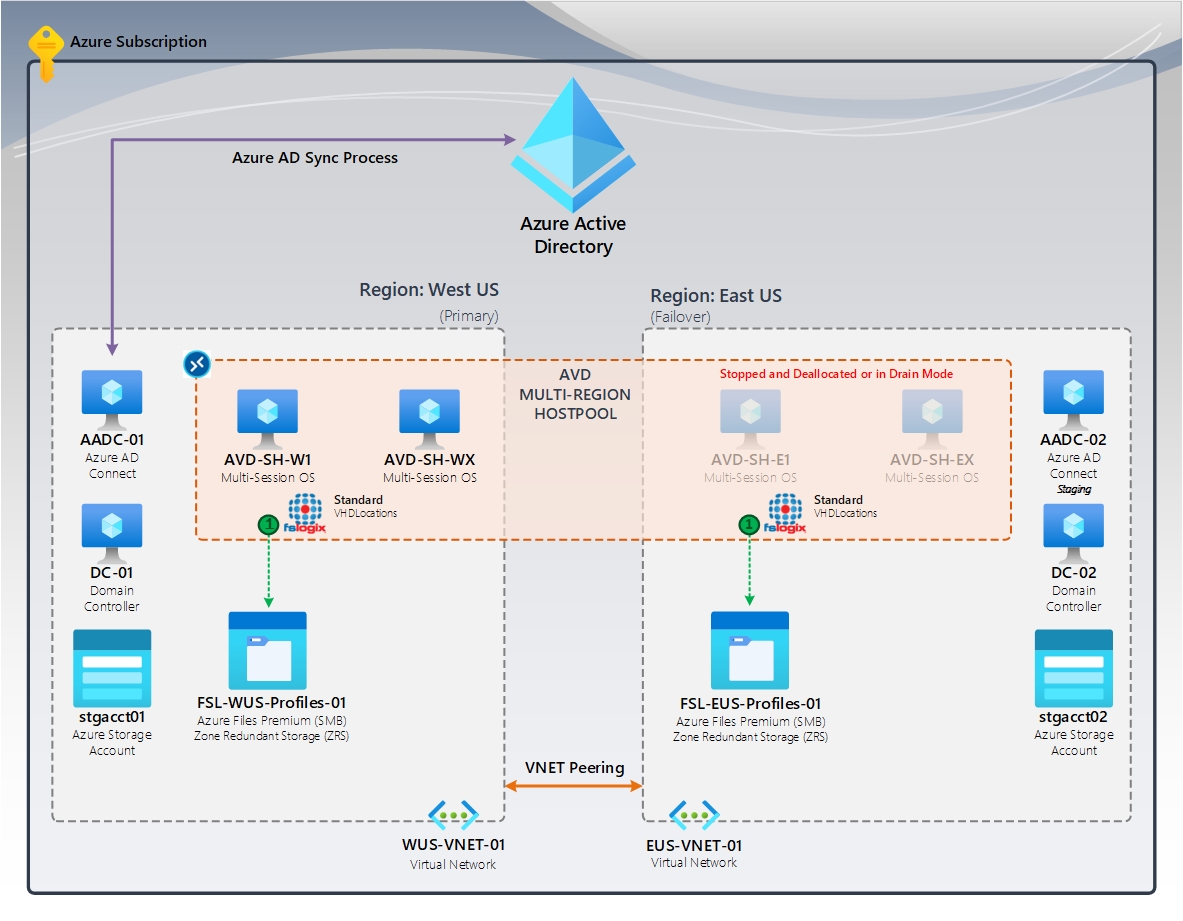
Abbildung 1: Keine Profilwiederherstellung | FSLogix-Standardcontainer (VHDLocations)
Das Diagramm zeigt einen Hostpool mit mehreren Regionen, der Azure Virtual Desktop verwendet. Sowohl die primäre Region als auch die Failoverregion verfügen über eine dedizierte Azure Files-Freigabe mit zonenredundantem Speicher (ZRS), die für hohe Verfügbarkeit innerhalb der Region sorgt. Die Failoverregion verfügt über Sitzungshosts, die angehalten oder freigegeben werden. Im Katastrophenfall wird die Failoverregion zur primären Region, und die Benutzerinnen und Benutzer melden sich bei diesen Sitzungshosts an und erstellen neue Profile auf der Azure Files-Freigabe in dieser Region.
Option 2: Cloudcache (primär/Failover)
- Überprüfung:Cloudcache im Überblick
- Beispiel:Erweitert + Notfallwiederherstellung (primär/Failover)
Ein Failoverdesign ist eine gängige Strategie, um die Verfügbarkeit und Zuverlässigkeit Ihrer Infrastruktur im Fall einer Katastrophe oder eines Ausfalls zu gewährleisten. Cloudcache erlaubt Ihnen, FSLogix mit diesem Typ von Failoverdesign zu verwenden. Mit Cloudcache können Sie Ihre Geräte so konfigurieren, dass sie zwei (2) Speicheranbieter verwenden, die Ihre Profildaten an unterschiedlichen Orten speichern. Der Cloudcache synchronisiert Ihre Profildaten asynchron mit jedem der beiden Speicheranbieter, sodass Sie immer über die aktuelle Version Ihrer Daten verfügen. Einige Ihrer Geräte befinden sich am primären Standort, und die anderen Geräte befinden sich am Failoverstandort. Cloudcache priorisiert den ersten Speicheranbieter (der Ihrem Gerät am nächsten ist) und verwendet den anderen Speicheranbieter als Backup. Wenn sich Ihr primäres Gerät beispielsweise in der Region „USA, Westen“ und Ihr Failovergerät in der Region „USA, Osten“ befindet, können Sie den Cloudcache wie folgt konfigurieren:
- Das primäre Gerät verwendet einen Speicheranbieter in der Region „USA, Westen“ als erste Option und einen Speicheranbieter in der Region „USA, Osten“ als zweite Option.
- Das Failovergerät verwendet einen Speicheranbieter in der Region „USA, Osten“ als erste Option und einen Speicheranbieter in der Region „USA, Westen“ als zweite Option.
- Wenn das primäre Gerät oder der nächstgelegene Speicheranbieter ausfällt, können Sie zum Failovergerät oder zum Sicherungsspeicheranbieter wechseln und Ihre Arbeit fortsetzen, ohne Ihre Profildaten zu verlieren.
Die Verwendung eines Failoverdesigns mit Cloudcache hat jedoch einige Nachteile. Zunächst müssen Sie für das Speichern Ihrer Profildaten an zwei (2) Standorten extra bezahlen. Zweitens müssen Sie den Failoverprozess manuell initiieren, wozu möglicherweise die Zustimmung der Beteiligten aus dem Geschäftsbereich und eine Prozessvalidierung erforderlich sind. Drittens kann es aufgrund der asynchronen Synchronisierung mit den beiden Speicheranbietern zu Wartezeiten oder Inkonsistenzen bei Ihren Profildaten kommen.
Tipp
- Vergewissern Sie sich, dass sich alle Benutzer und Benutzerinnen erfolgreich vom Failoverstandort abgemeldet haben, um sicherzustellen, dass der primäre Standort über ein aktuelles Replikat der Profildaten des Benutzers bzw. der Benutzerin verfügt, bevor Sie Benutzern und Benutzerinnen ein Failback zu Profilen am primären Standort gestatten.
- Cloudcache ist ein E/A-intensives System. Es kann zu Netzwerk- und/oder Speicherengpässen am wiederhergestellten Standort führen.
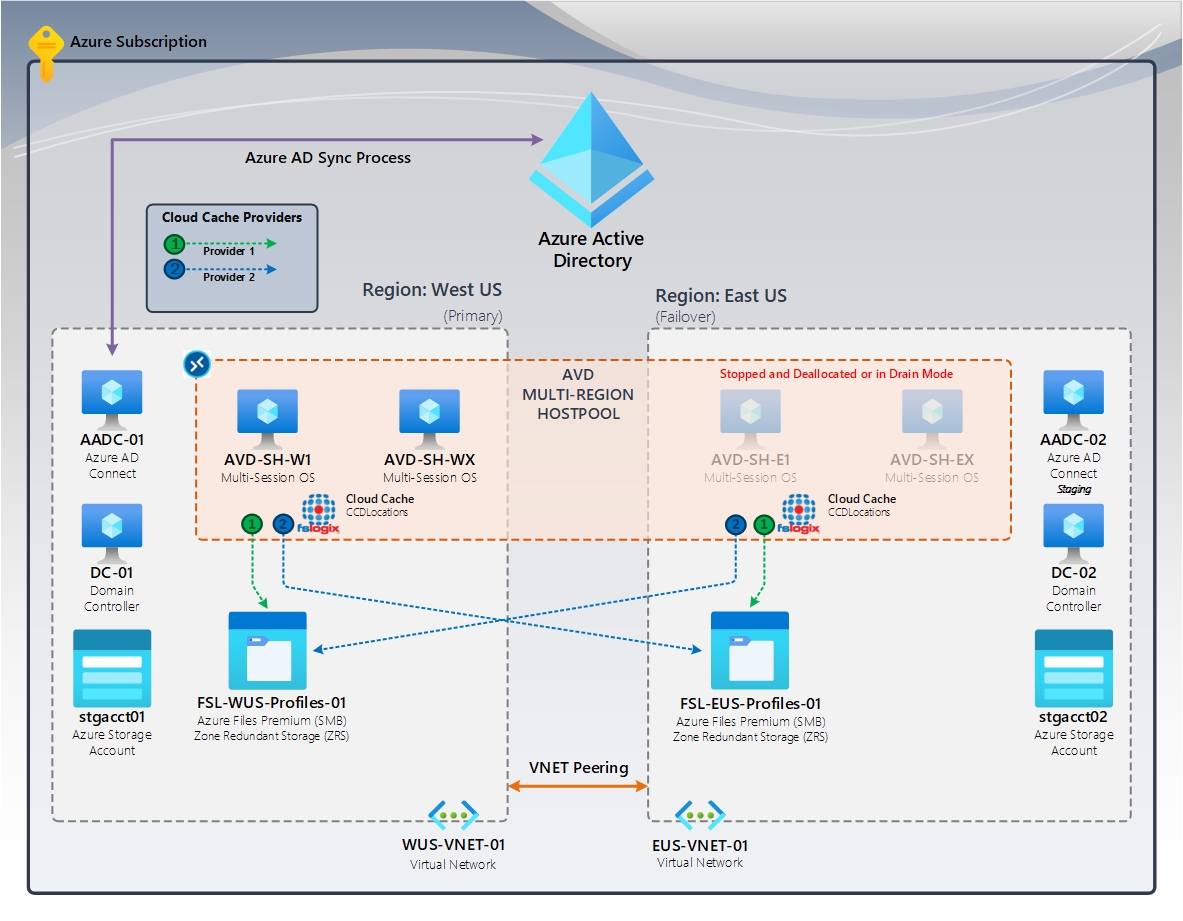
Abbildung 2: Cloudcache (primär/Failover) | FSLogix Cloud Cache (CCDLocations)
Im Diagramm ist Hostpool mit mehreren Regionen unter Verwendung von Azure Virtual Desktop dargestellt. Sowohl die primären Regionen als auch die Failoverregionen sind Teil dieses Setups. Sie verfügen jeweils über eine dedizierte Azure Files-Freigabe mit zonenredundantem Speicher (ZRS), wodurch Hochverfügbarkeit innerhalb der Region sichergestellt wird. Die Failoverregion enthält Sitzungshosts, die entweder angehalten werden oder deren Zuordnung aufgehoben wird. Im Katastrophenfall wird die Failoverregion zur primären Region. Benutzer und Benutzerinnen melden sich bei diesen Sitzungshosts an und laden ihr repliziertes Profil aus der Failoverregion.
Es ist jedoch wichtig, Folgendes zu berücksichtigen:
- BCDR-Ereignisse (Geschäftskontinuität und Notfallwiederherstellung) verlaufen selten glimpflich. Je nach den Umständen kann die Unversehrtheit der Benutzerprofildaten nicht gewährleistet werden.
- Bei Benutzern und Benutzerinnen, die sich bei Sitzungshosts in der Failoverregion anmelden, können Datenverluste oder in schlimmeren Fällen Containerbeschädigungen auftreten.
In dieser Situation ist es wichtig, Speicherplattformen wie OneDrive oder SharePoint für wichtige Daten zu nutzen. Diese Plattformen bieten zusätzliche Redundanz und Schutz vor Datenverlust. Denken Sie daran, dass die Planung für die Notfallwiederherstellung von entscheidender Bedeutung ist und dass die richtige Speicherstrategie die Risiken mindern und die Geschäftskontinuität gewährleisten kann.
Option 3: Cloudcache (aktiv/aktiv)
- Überprüfung:Cloudcache im Überblick
- Beispiel:Erweitert + Notfallwiederherstellung (primär/Failover)
In Infrastrukturdiskussionen werden häufig Aktiv/Aktiv-Konzepte verwendet, die auch auf eine FSLogix-Profillösung angewendet werden können. Bei dieser Option wird der Cloudcache mit zwei Speicheranbietern eingerichtet, die asynchron aktualisiert werden, um alle am lokalen Cache vorgenommenen Änderungen widerzuspiegeln. Der Speicheranbieter, der dem aktiven Standort am nächsten liegt, wird an erster Stelle aufgeführt, während der am weitesten entfernte Anbieter an zweiter Stelle aufgeführt wird. Am anderen Standort wird die Reihenfolge umgekehrt. Diese Option verursacht zusätzliche Kosten für das Speichern von Anbieterdaten an zwei Standorten und erfordert eine manuelle Entscheidung der Beteiligten aus dem Geschäftsbereich, bevor ein Failover initiiert wird.
Tipp
- Wenn die ausgefallene Region betriebsbereit ist, kann es sehr lange dauern, bis die Profildaten vollständig repliziert sind.
- Cloudcache ist ein E/A-intensives System. Es kann zu Netzwerk- und/oder Speicherengpässen am wiederhergestellten Standort führen.
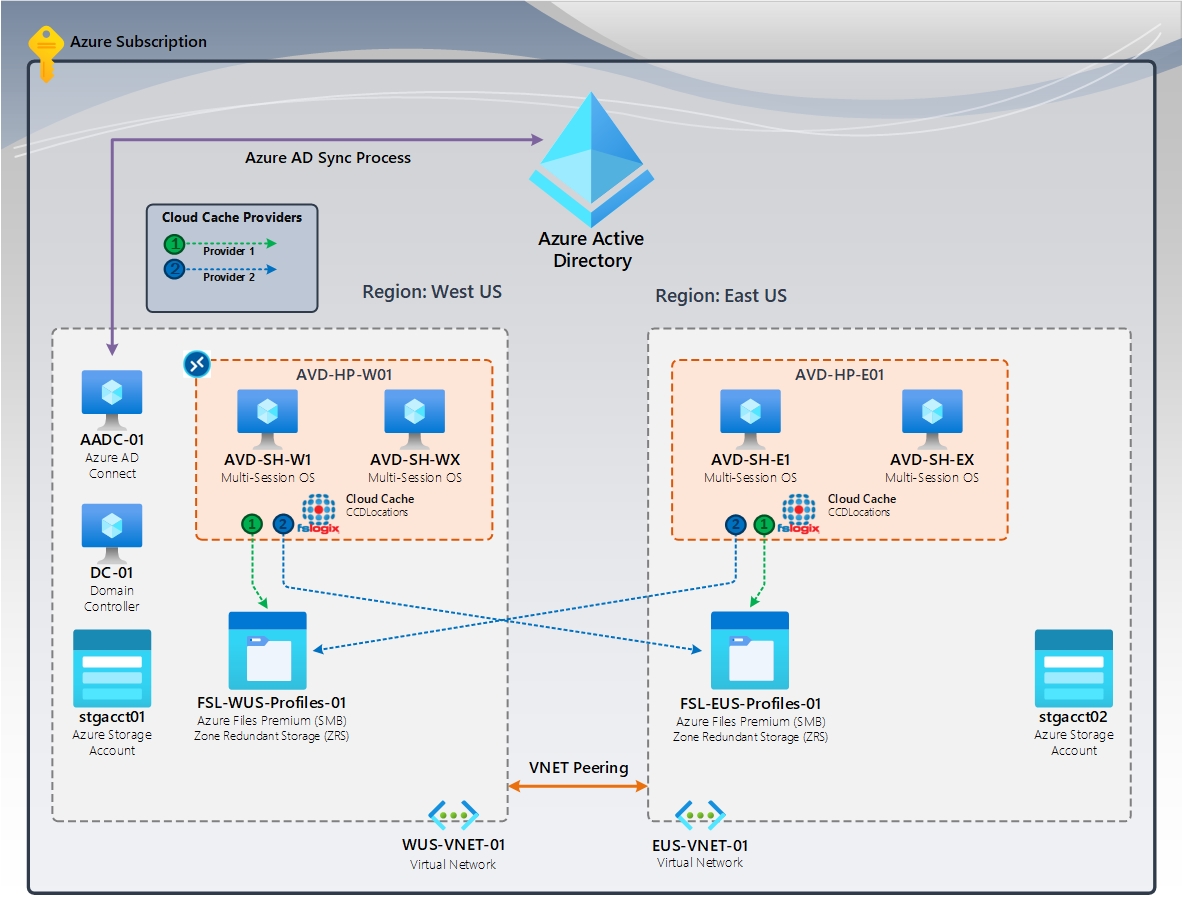
Abbildung 3: Cloudcache (aktiv/aktiv) | FSLogix-Cloudcache (CCDLocations)
Das Diagramm zeigt zwei (2) AVD-Hostpools und Sitzungshosts, die sich in bestimmten Azure-Regionen befinden. Benutzerinnen und Benutzer, die der Region USA, Westen zugewiesen sind, greifen auf diese virtuellen Maschinen zu. Benutzer aus der Region USA, Osten greifen nur auf diese virtuellen Maschinen zu und sind diesen zugewiesen. Im Katastrophenfall muss die überlebende Region über genügend Kapazität verfügen, um alle Benutzer zu unterstützen. Außerdem müssen die Benutzer aus der ausgefallenen Region Zugriff auf die virtuellen Maschinen in der überlebenden Region erhalten.
BCDR-Ereignisse verlaufen nie glimpflich, und je nach den Umständen des Ereignisses kann die Unversehrtheit der Benutzerprofildaten nicht gewährleistet werden. Bei Benutzerinnen und Benutzern, die sich an Sitzungshosts in der überlebenden Region anmelden, kann es zu Datenverlusten oder im schlimmsten Fall zur Beschädigung von Containern kommen. Diese Situation verstärkt die Notwendigkeit, Speicherplattformen wie OneDrive oder SharePoint für kritische Benutzerdaten zu nutzen.