Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
Zusammenarbeits- und Kommunikationsaktivitäten generieren eine riesige Menge an umfangreichen Daten in Microsoft 365. Sie können Microsoft Graph Data Connect verwenden, um Einblicke in Ihre organization zu erhalten. Die Data Connect-Vorlagen helfen Ihnen, die Zeit zu verkürzen, die erforderlich ist, um Datenerkenntnisse zu gewinnen und diese Erkenntnisse mit Ihren eigenen Daten anzureichern.
Die Microsoft Graph Data Connect-Vorlagen können Ihnen helfen, Möglichkeiten mit Ihren Microsoft 365-Daten zu realisieren und die Zeit bis zum Mehrwert zu beschleunigen. Jede Vorlage enthält Ressourcen, die für verschiedene Anwendungsfälle und Geschäftsszenarien spezifisch sind. Sie können diese Vorlagen für die ersten Schritte verwenden:
- Entitätsstimmungsanalyse
- Extrahieren von Entitäten aus Outlook- und Teams-Daten. Analysieren Sie dann, wie Sich Benutzer zu diesen Entitäten fühlen.
- Richtet synapse Workspace, Apache Spark Pool, Azure Data Lake Storage Account und Azure Cognitive Services-Ressourcen ein.
- Analyse des Organisationsnetzwerks
- Identifizieren Sie Zusammenarbeits- und Kommunikationsmuster, die für Organisationen entscheidend sind, um echte geschäftliche Agilität zu erreichen.
- Richtet Synapse-Arbeitsbereich, Apache Spark-Pool und Azure Data Lake Storage-Kontoressourcen ein.
- Überteilung von Informationen
- Schützen Sie Ihr Unternehmen, indem Sie Muster von Informationen über das Teilen und Betrug in Ihren Microsoft 365-Daten identifizieren.
- Richtet Synapse-Arbeitsbereich, Apache Spark-Pool und Azure Data Lake Storage-Kontoressourcen ein.
Die Vorlagen helfen Ihnen beim schnellen Bereitstellen von Azure-Ressourcen und stellen Datenpipelines und Beispiele bereit, mit denen Sie sofort einen Mehrwert erzielen können.
Weitere Informationen und erste Schritte mit den Microsoft Graph Data Connect-Vorlagen finden Sie im GitHub-Repository für Data Connect-Lösungen.
Schnellstartvorlagen
Schnellstartvorlagen helfen Ihnen beim einfachen Einrichten von Pipelines für die Extraktion von Microsoft Graph Data Connect-Datasets zusammen mit den Azure-Ressourcen, um sie bereitzustellen. Die Konfiguration von Datenpipelines wird schneller, da die Details der registrierten Anwendungen verwendet werden, um die Effizienz zu steigern. Derzeit unterstützen die Schnellstartvorlagen nur Azure Data Factory als Plattform und die Kopieraktivität als Aktivitätstyp.
Voraussetzungen
Um die Schnellstartvorlagen verwenden zu können, benötigen Sie die folgenden Voraussetzungen:
- Eine konfigurierte Microsoft Graph Data Connect-Anwendung. Ausführliche Informationen zum Erstellen einer Microsoft Graph Data Connect-Anwendung finden Sie unter Erstellen Ihrer ersten Data Connect-Anwendung.
- Das Anwendungsgeheimnis der Microsoft Entra Anwendung, die während der Registrierung der Microsoft Graph Data Connect-Anwendung verwendet wurde. Weitere Informationen finden Sie unter Einrichten Ihrer Microsoft Entra-Anwendung.
- Ein Azure Storage-Container, in den Daten geschrieben werden sollen. Weitere Informationen finden Sie unter Einrichten Ihrer Azure Storage-Ressource.
Einrichten einer Pipeline mit einer Schnellstartvorlage
So richten Sie eine Pipeline ein:
- Öffnen Sie Ihre Anwendung über die Startseite von Microsoft Graph Data Connect im Azure-Portal, und wechseln Sie zur Registerkarte Schnellstartvorlagen .
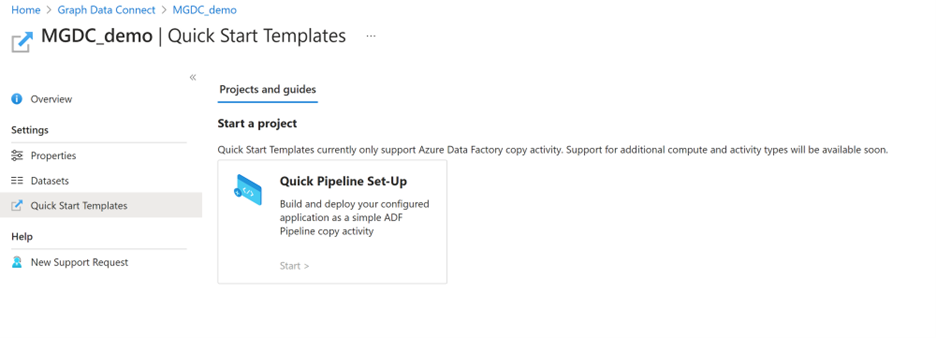
- Wählen Sie in der Vorlage Schnellpipeline einrichtendie Option Start aus.
- Füllen Sie die restlichen Werte im vorab aufgefüllten benutzerdefinierten Bereitstellungsformular aus.
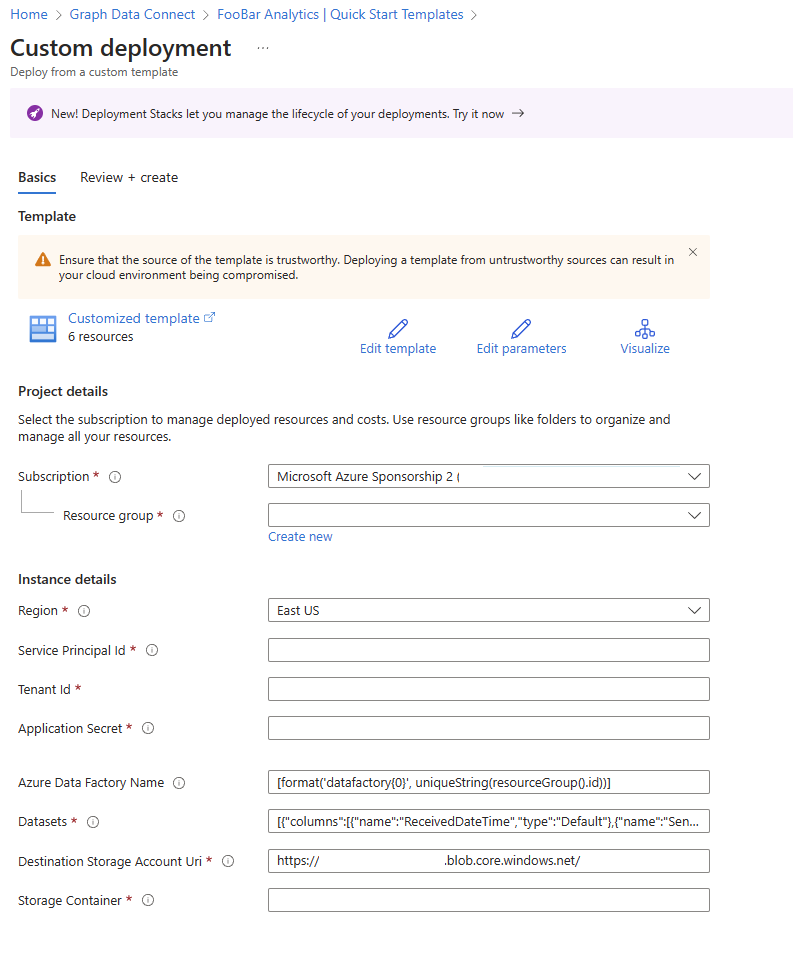
Das Formular enthält die folgenden Felder:
- Ressourcengruppe: Die Ressourcengruppe, in der sich Ihr Azure Storage-Konto befindet. Dieselbe Konfiguration gilt auch für den Speicherort des Azure Data Factory.
- Dienstprinzipal-ID: Ein vorab aufgefülltes Feld, das die Microsoft Entra Anwendungs-ID anzeigt, die zum Erstellen einer Anwendung mit Microsoft Graph Data Connect verwendet wird.
- Mandanten-ID: Ein vorab aufgefülltes Feld, das den Mandanten anzeigt, für den Daten extrahiert werden.
- Anwendungsgeheimnis: Der Geheimniswert der Microsoft Entra Anwendung, die während der Registrierung verwendet wurde.
- Azure Data Factory Name: Dieses Feld wird vorab ausgefüllt, indem die eindeutige Zeichenfolge, die der Ressourcengruppen-ID zugeordnet ist, mit datafactory verkettet wird. Sie können auch eine vorhandene Azure Data Factory Ressource angeben oder einen neuen eindeutigen Namen für eine neue Azure Data Factory-Ressource eingeben.
- Datasets: Ein vorab aufgefülltes Feld. Pro Dataset wird eine Pipeline generiert.
- Zielspeicherkonto-URI: Ein vorab aufgefülltes Feld. Der URI (Verteiltes Dateisystem (DFS) oder Blob), der basierend auf der registrierten Anwendung verwendet werden soll.
- Speichercontainer: Der Stammcontainer im Azure Storage-Ziel, in den die Daten geschrieben werden.
- Wählen Sie die Registerkarte Überprüfen + erstellen aus, um Ihre Einstellungen zu überprüfen. Nachdem Sie bestätigt haben, dass alle Details korrekt sind, wählen Sie die Schaltfläche Erstellen aus, um die Bereitstellung zu initiieren. Ein Bereitstellungsbildschirm status wird angezeigt, um die Erstellung der Ressourcen zu überwachen.
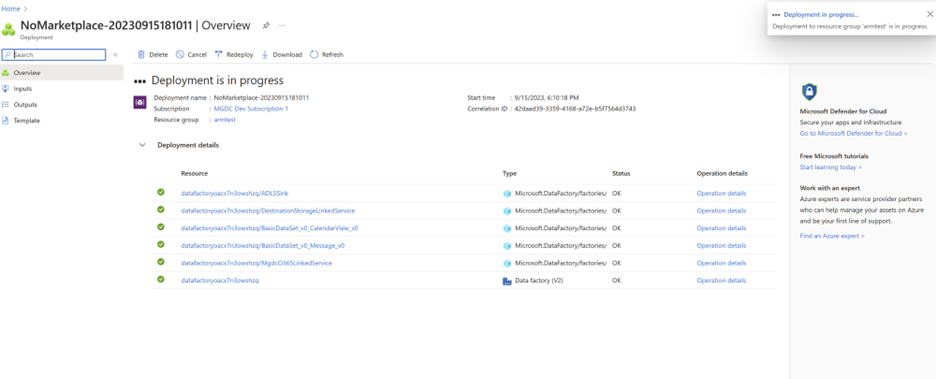
- Wechseln Sie zur Azure Data Factory Ressource in der ausgewählten Ressourcengruppe. Wenn während der Bereitstellung eine neue Azure Data Factory Ressource erstellt wurde, können Sie den Ressourcennamen im Abschnitt Bereitstellungsdetails auswählen.

- Wählen Sie ein Dataset in einer Kopieraktivität einer Pipeline aus, und konfigurieren Sie die Datenfilter für die Extraktion.
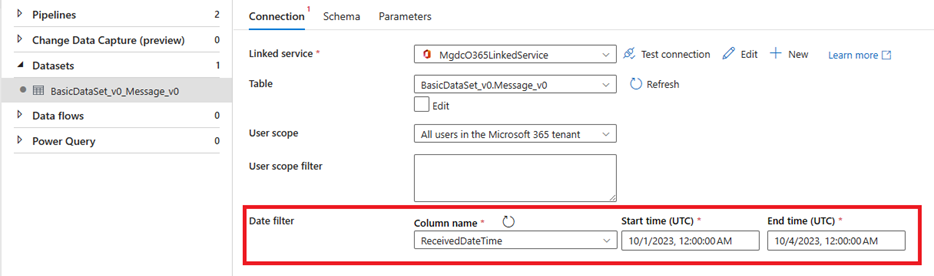
Bevor Sie die Pipeline auslösen, wählen Sie jede Kopieraktivität aus, um die anwendbaren Filter für jedes Dataset zu konfigurieren. Weitere Informationen zu Spaltenfiltern finden Sie unter Benutzerauswahl- und Filterfunktionen in Microsoft Graph Data Connect.
- Verwenden Sie die Schaltfläche Trigger hinzufügen , um die Pipeline auszulösen.
