Smart Store Analytics erweitern
Fortgeschrittene Benutzer von Smart Store Analytics können auf relevante Daten und Analysen aus ihrem eigenen Data Lake-Speicher zugreifen. Der Zugriff kann über beliebige andere Dienste oder Anwendungen erfolgen, die Definitionen für Microsoft Azure Data Lake Storage und Common Data Model unterstützen, z. B. Microsoft Azure Synapse Analytics, Microsoft Azure Data Factory oder Microsoft Power BI.
Wichtig
Sie müssen Microsoft Azure Data Lake Storage Gen2 verwenden, da Microsoft Azure Data Lake Storage Gen1 nicht kompatibel ist.
Das Datenmodell von Smart Store Analytics entspricht den Azure Synapse Datenbankvorlagen für den Einzelhandel, wurde um Besonderheiten von Smart Store Analytics erweitert und vereinfacht die Verbindung anderer Anwendungen mit den Daten aus dem Lake.
Data Lake-Struktur von Smart Store Analytics
Smart Store Analytics Data Lake folgt der Definition des Common Data Model (Common Data Model Metadaten).

Der Stammordner heißt smartstores/. Unter dem Stammordner befinden sich zwei Datenmomentaufnahmen:
Vom Smart-Store-Anbieter transformierte Daten (Smart-Store-Rohdaten)
Das Stammmanifest des Common Data Model für die Rohdaten ist root.manifest.cdm.json. Die Manifestdatei bezieht sich auf die Schemadateien und eigentlichen Datendateien in den Unterordnern (benannt nach den Tabellen), z. B. smartstores/Order/.
Der Unterordner jeder Tabelle enthält:
Schemadatei, die die Tabellenmetadaten, -spalten und -typen im Format table-name.cdm.json festlegt, z. B. Order.cdm.json
Datendateien, auch Datenpartitionen oder Tabellendatensätze genannt, im Parquet-Format, z. B. Order-cec9368060a849b8aab7583b62b506eb-00001.parquet
Daten, die von den Einzelhandelsanalyse- und KI-Modulen aus den Smart-Store-Rohdaten generiert werden
Alle generierten Daten befinden sich in einem als GUID benannten Ordner, z. B. smartstores/14a7334b-7176-ed11-9985-00224804e0d0/. Das Stammmanifest des Common Data Model für diese Daten ist kpi.manifest.cdm.json. Die Manifestdatei bezieht sich auf die Schemadateien und eigentlichen Datendateien, im Ordner mit dem Namen GUID.
Der Ordners namens GUID enthält:
Schemadateien für alle Tabellen, welche die Tabellenmetadaten, -spalten und -typen im Format table-name.cdm.json festlegen, z. B. OrderMetrics.cdm.json
Datendateien, auch Datenpartitionen oder Tabellendatensätze genannt, im Parquet-Format, z. B. part-00000-1e110bf0-6474-400b-b40a-086fce9f8e2a-c000.snappy.parquet
Wichtig
Gemäß dem Metadatenvertrag des Common Data Models benötigen Benutzer nur Daten aus den manifest.cdm.json-Dateien. Sie müssen die Ordnerstruktur oder andere im Data Lake vorhandene interne Dateien nicht interpretieren.
Verwendung des Data Lake von Smart Store Analytics
Hier sind einige Beispiele für Daten, die in von Microsoft Cloud for Retail generierte Analyse-/KI-Erkenntnisse synchronisiert wurden.
Datenpipeline mit Microsoft Azure Data Factory
Erstellen Sie eine Datenpipeline wie folgt:
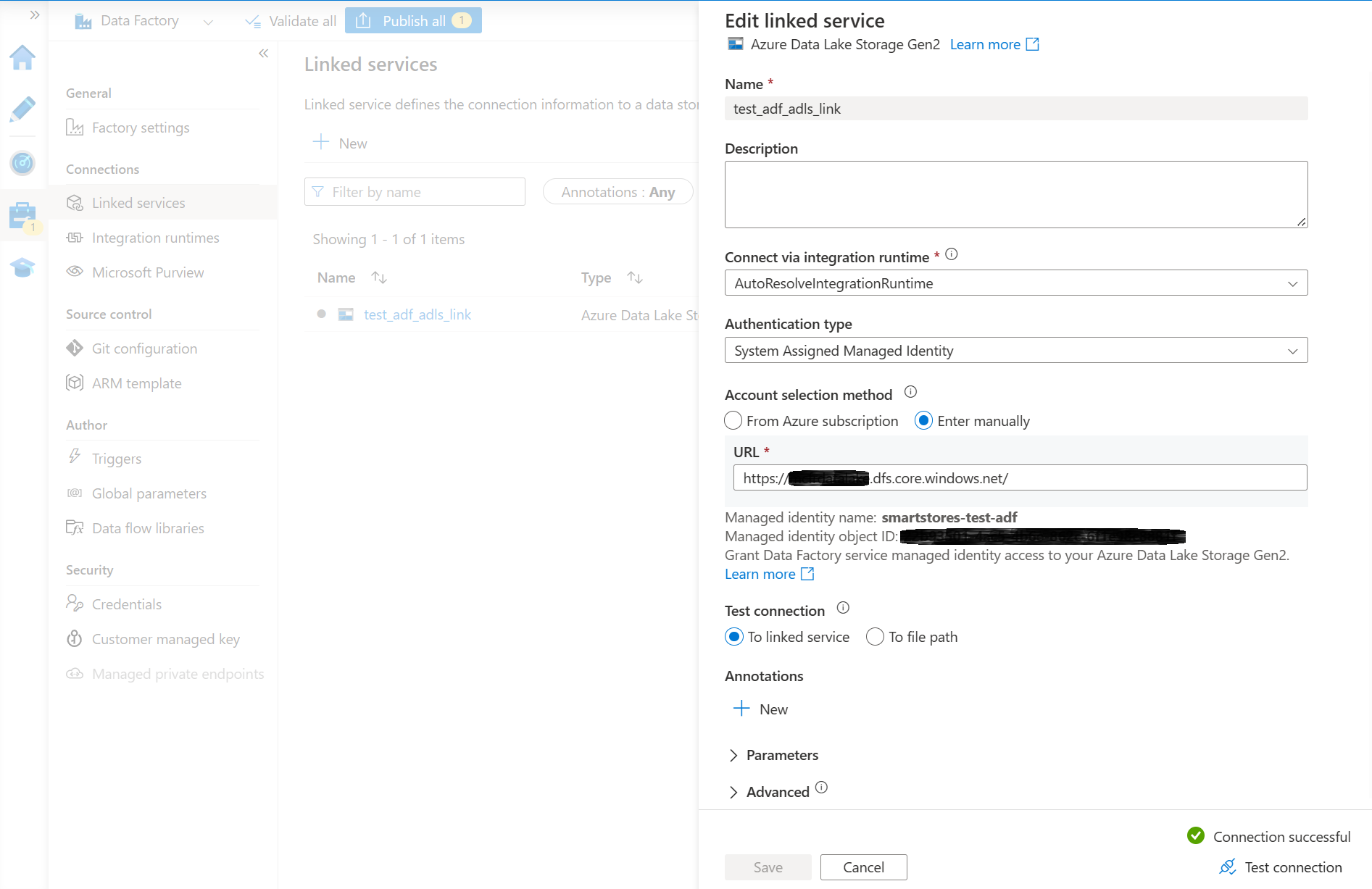
- Erstellen Sie eine Azure Data Factory-Instanz und verknüpfen Sie sie mit dem Data Lake-Speicher von Smart Store Analytics. Sie sollten einen verknüpften Dienst mit einer erfolgreich getesteten Verbindung haben.
Anmerkung
Am einfachsten lässt sich die Azure Data Factory-Instanz mit Azure Data Lake Storage verbinden, indem Sie einer von Azure Data Factory verwalteten Identität im Azure Data Lake Storage Konto eine Teilnehmerrolle zuweisen. Weitere Details finden Sie in der Azure Data Factory Dokumentation.
- Wählen Sie Alle veröffentlichen aus, um den neuen Link zu veröffentlichen.
Eine Datenpipeline mit Microsoft Azure Data Factory erstellen
Um eine Kopie der Pipeline für den smartstores/-Ordner als Quelle zu erstellen, führen Sie die folgenden Schritte aus:
- Wählen Sie im Abschnitt „Autor“ Neuer Datenfluss aus, um einen neuen Datenfluss zu erstellen.
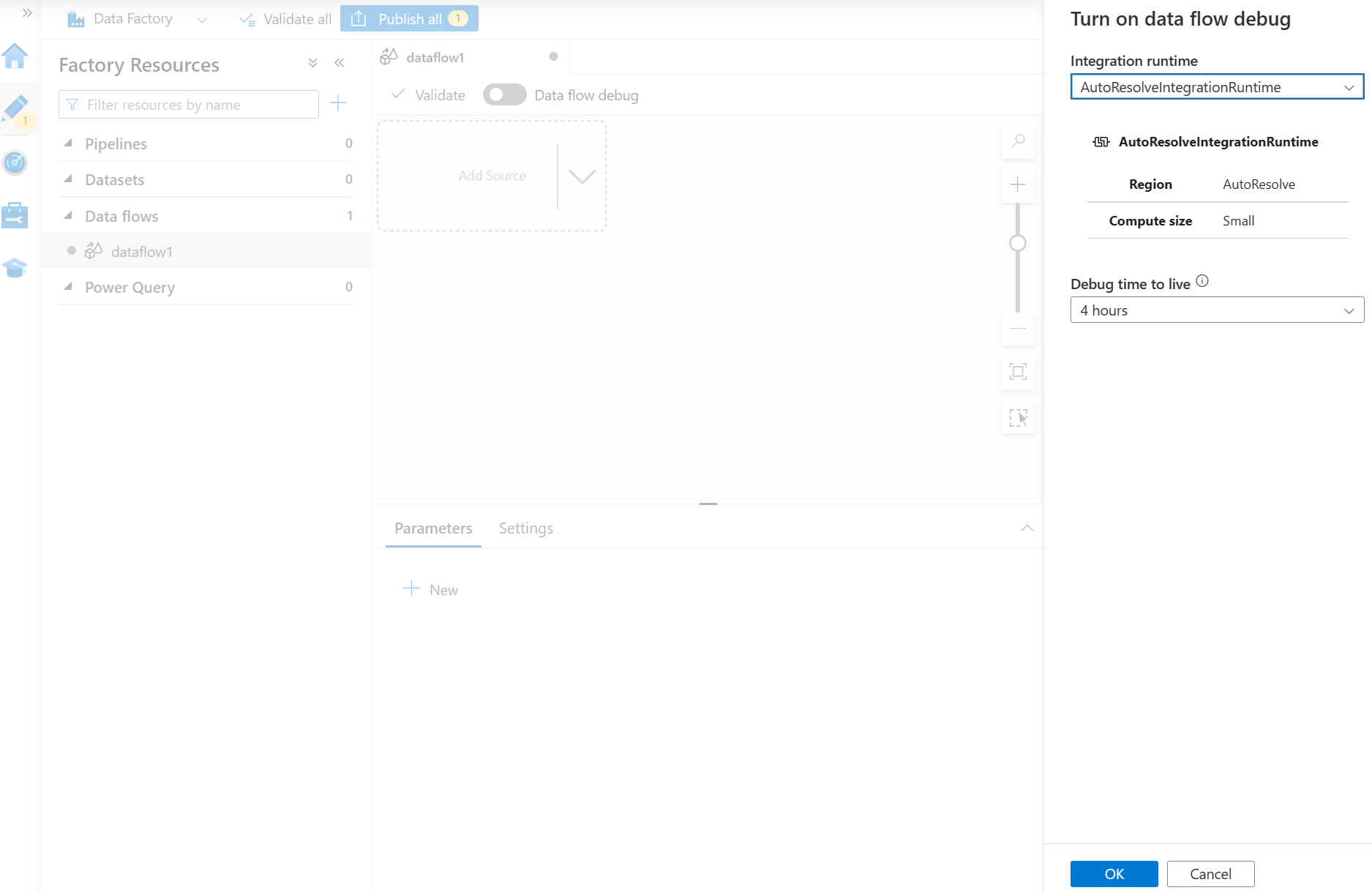
- Beginnen Sie mit dem Debuggen, um die Einrichtung der Pipeline schneller zu überprüfen.
- Konfigurieren Sie die Quelleinstellungen wie folgt:
- Wählen Sie für den Quellentyp Inline aus
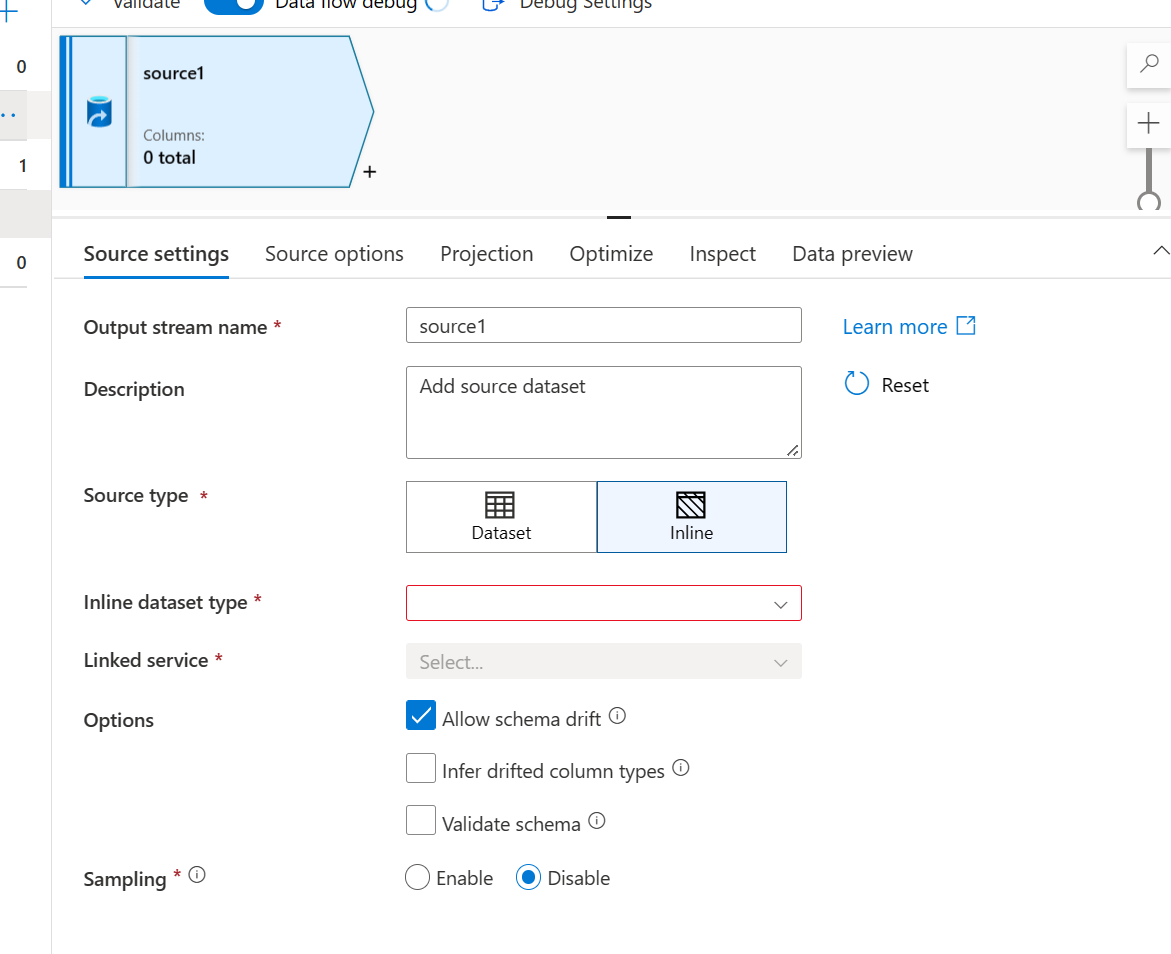
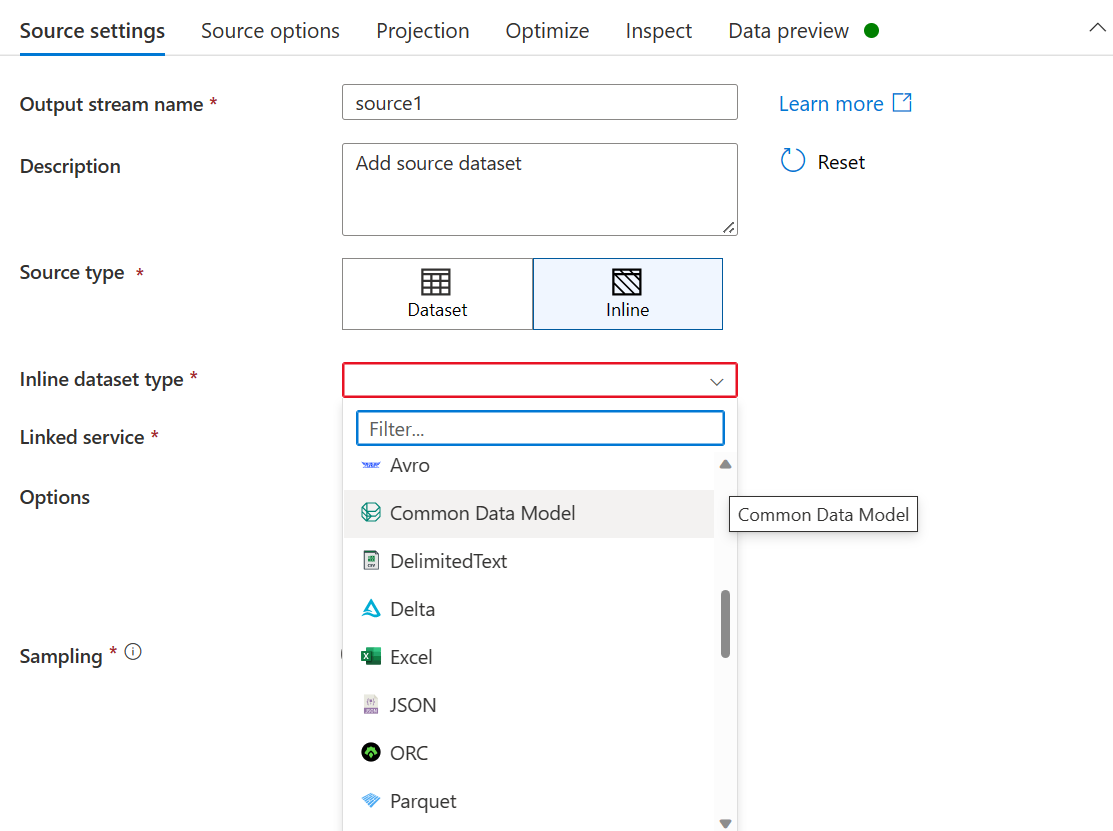
- Wählen Sie als Inline-DataSet-Typ Common Data Model aus
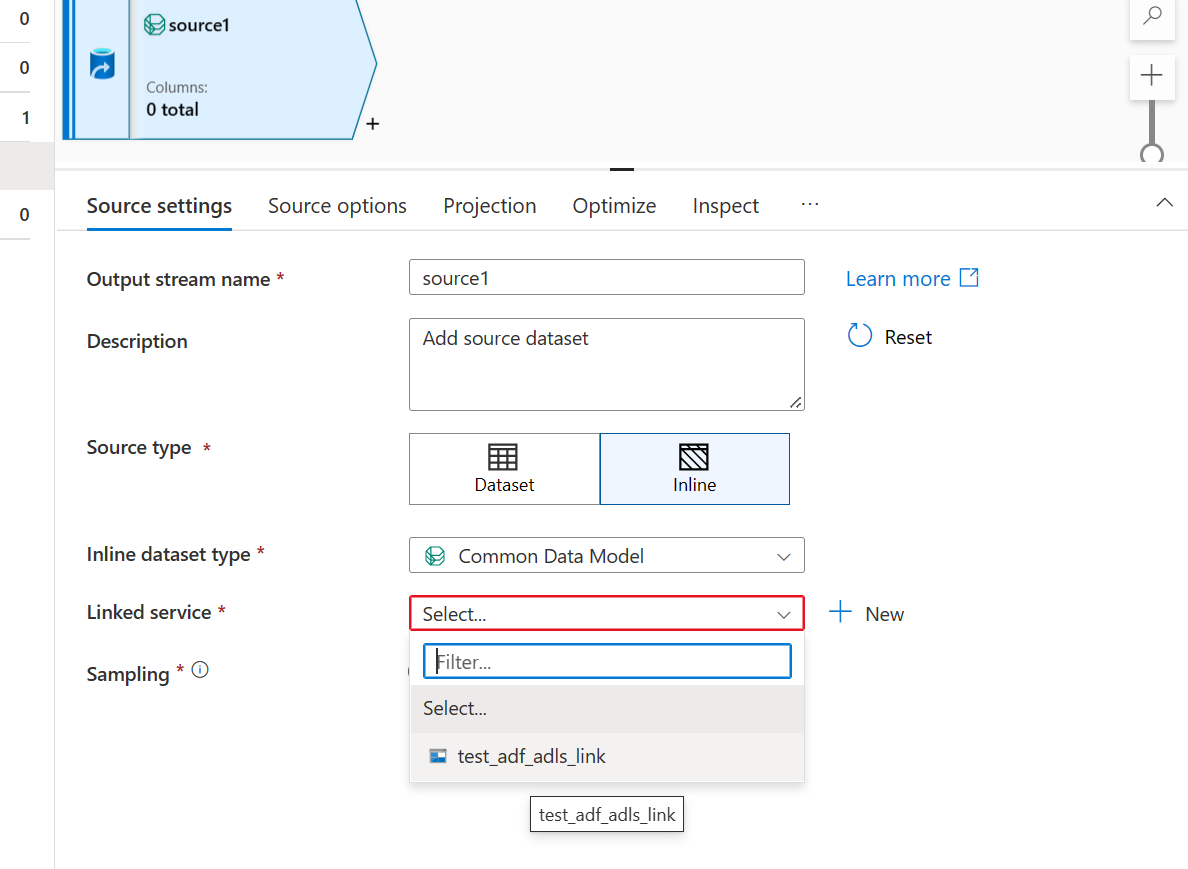
- Verwenden Sie den für den Smart Stores Data Link erstellten Azure Data Lake Storage-Link aus.
- Richten Sie im Abschnitt Quelloptionen die Common Data Model-Schemaquelle wie folgt ein:
- Wählen Sie als Metadatenformat Manifest aus.
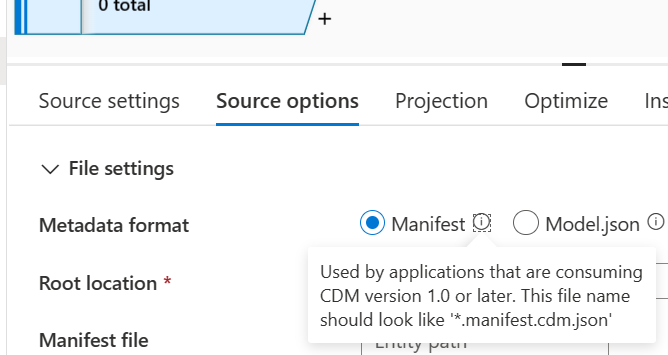
Suchen Sie im Stammverzeichnis nach dem smartstores-Ordner und wählen Sie ihn aus.
Navigieren Sie im Abschnitt „Manifestdatei“ zum gewünschten Stammmanifest, um es auszuwählen. Wählen Sie die Stammdatei kpi.manifest.cdm.json für die Analyse- und KI-Erkenntnisdaten aus.
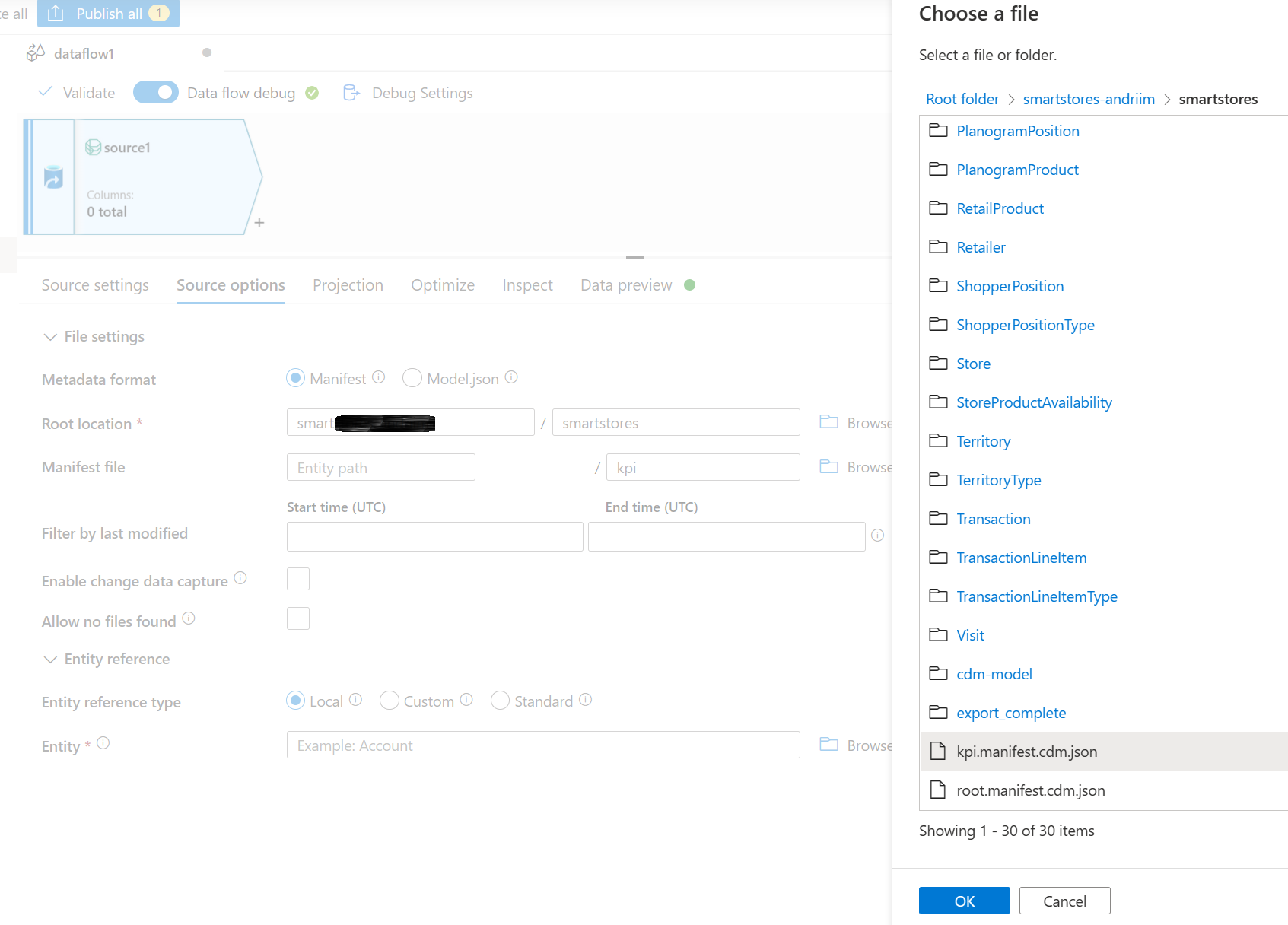
Wählen Sie im Abschnitt „Entität“ die Entität (Tabelle) aus, die Sie kopieren/umwandeln müssen, z. B. FBTProductAssociationsUI aus dem Paket „Häufig zusammen gekauft“.
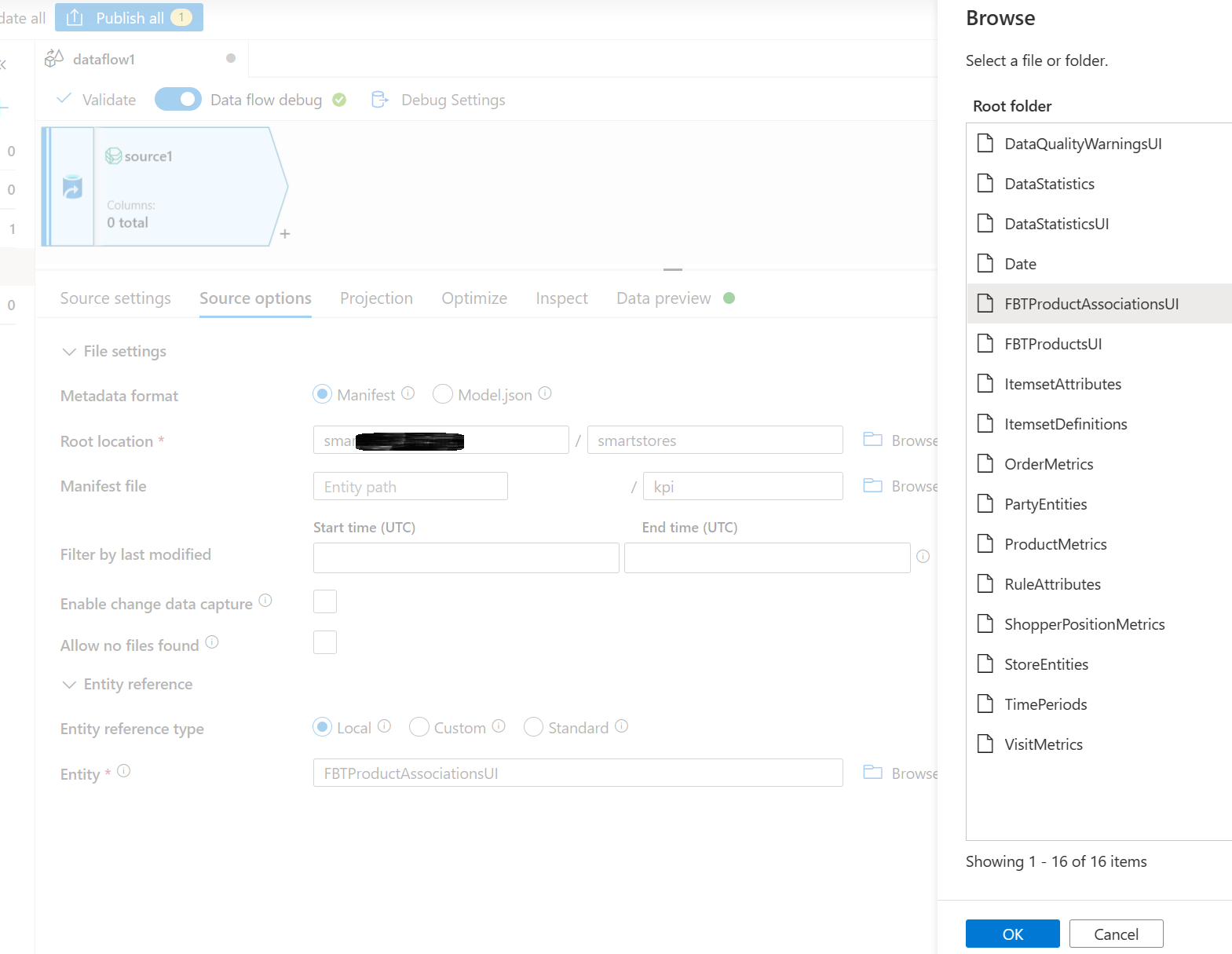
- Wählen Sie auf der Registerkarte „Projektion“ Schemaabweichung zulassen. Diese Auswahl stellt sicher, dass das Schema nicht an der Quelle validiert wird, sondern zu anderen Transformations-/Senkenschritten abweicht.
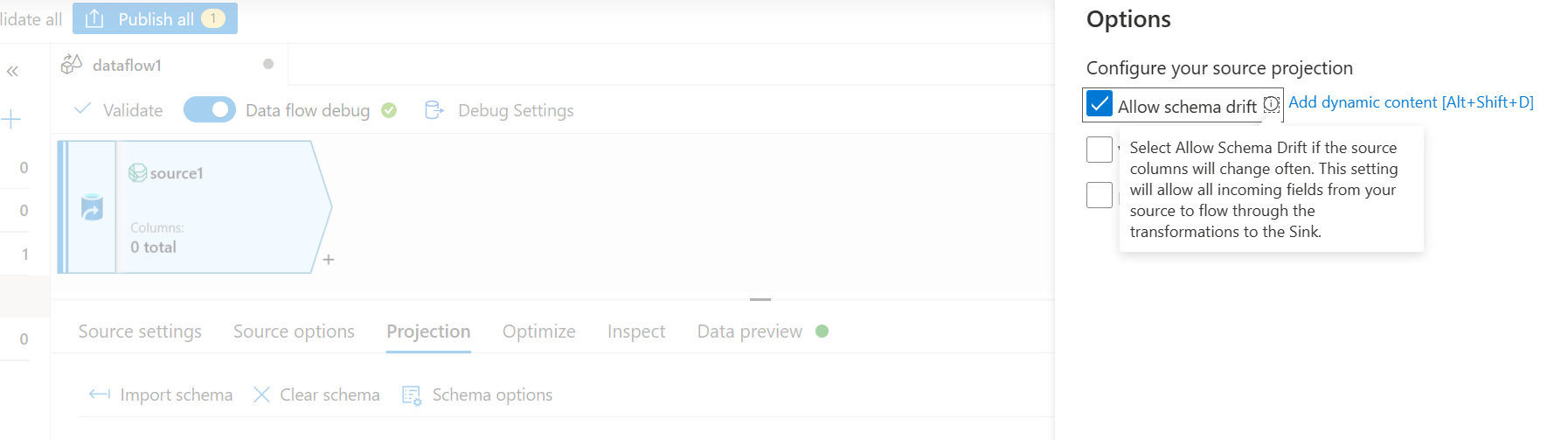
- Wählen Sie auf der Registerkarte „Datenvorschau“ Neu laden aus, um die Datenquelle-Einstellungen zu validieren.
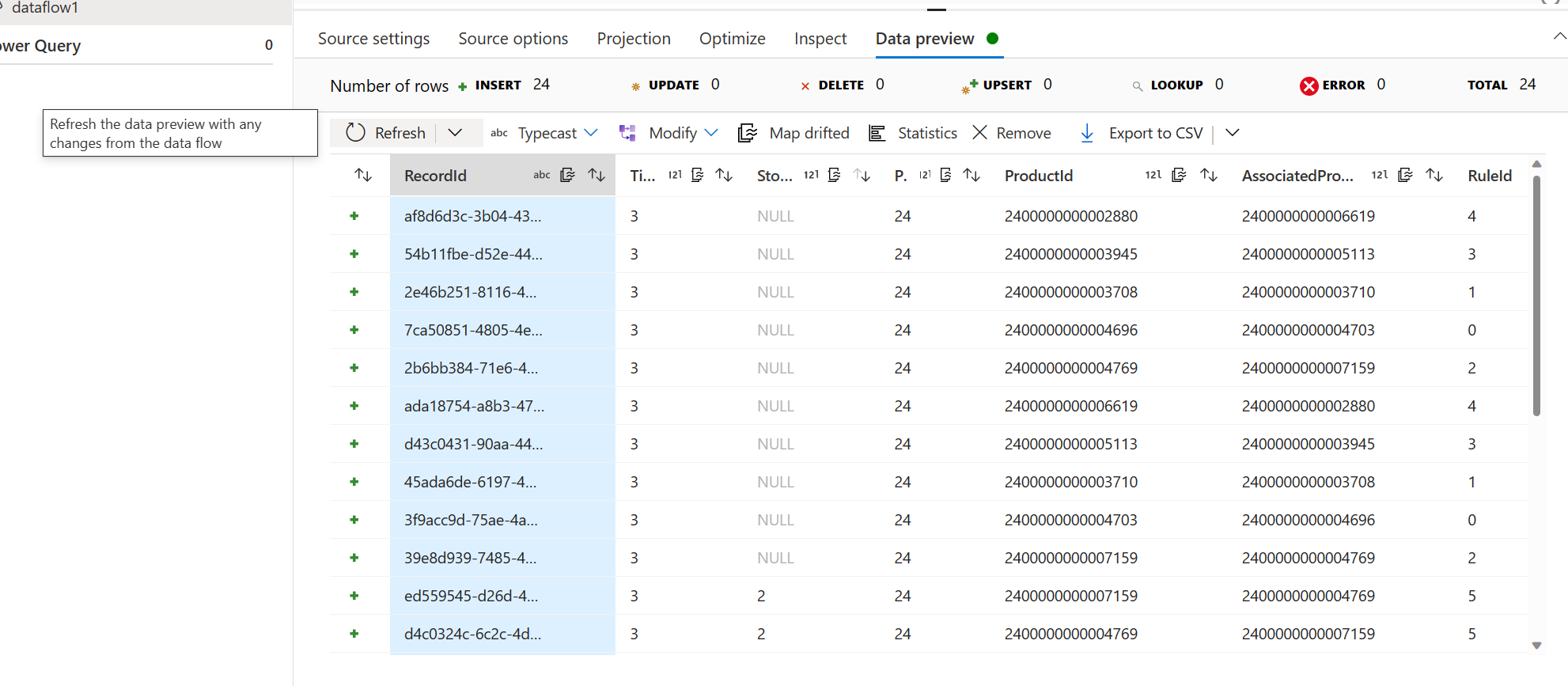
Fügen Sie einen Senkenschritt hinzu. Legen Sie die Parameter und die Datenzuordnung für Ihr Szenario nach Bedarf fest.
Wählen Sie Veröffentlichen, um die Änderungen zu veröffentlichen.