Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
Graph-Semanitcs unterstützt zwei primäre Ansätze für die Arbeit mit Diagrammen: vorübergehende Diagramme, die für jede Abfrage im Arbeitsspeicher erstellt wurden, und persistente Diagramme, die als Diagrammmodelle und Momentaufnahmen innerhalb der Datenbank definiert sind. Dieser Artikel enthält bewährte Methoden für beide Methoden, sodass Sie den optimalen Ansatz auswählen und die KQL-Graph-Semantik effizient verwenden können.
Diese Anleitung umfasst:
- Graph-Erstellungs- und Optimierungsstrategien
- Abfragetechniken und Leistungsgesichtspunkte
- Schemaentwurf für persistente Diagramme
- Integration mit anderen KQL-Funktionen
- Häufige Fallstricke, die vermieden werden sollen
Diagrammmodellierungsansätze
Es gibt zwei Ansätze für die Arbeit mit Diagrammen: vorübergehend und persistent.
Temporäre Graphen
Dynamisch mit dem make-graph Operator erstellt. Diese Diagramme sind nur während der Abfrageausführung vorhanden und eignen sich optimal für ad-hoc- oder explorative Analysen für kleine bis mittlere Datasets.
Persistente Diagramme
Definiert mithilfe von Graphmodellen und Graph-Schnappschüssen. Diese Diagramme werden in der Datenbank gespeichert, unterstützen Schema- und Versionsverwaltung und sind für wiederholte, umfangreiche oder kollaborative Analysen optimiert.
Bewährte Methoden für vorübergehende Diagramme
Vorübergehende Diagramme, die mithilfe des make-graph Operators erstellt wurden, eignen sich ideal für Ad-hoc-Analysen, Prototypen und Szenarien, in denen sich die Diagrammstruktur häufig ändert oder nur eine Teilmenge der verfügbaren Daten erfordert.
Optimieren der Diagrammgröße für die Leistung
Die make-graph erzeugt eine In-Memory-Darstellung, die sowohl Struktur als auch Eigenschaften umfasst. Optimieren Sie die Leistung durch:
- Frühzeitiges Anwenden von Filtern – Wählen Sie vor der Diagrammerstellung nur relevante Knoten, Kanten und Eigenschaften aus.
- Verwenden von Projektionen – Entfernen Sie unnötige Spalten, um den Arbeitsspeicherverbrauch zu minimieren.
- Anwenden von Aggregationen – Zusammenfassen von Daten, falls zutreffend, um die Diagrammkomplexität zu reduzieren
Beispiel: Reduzieren der Diagrammgröße durch Filtern und Projektion
In diesem Szenario änderte Bob Manager von Alice zu Eve. So zeigen Sie nur den aktuellen Organisationsstatus an, während Die Diagrammgröße minimiert wird:
let allEmployees = datatable(organization: string, name:string, age:long)
[
"R&D", "Alice", 32,
"R&D","Bob", 31,
"R&D","Eve", 27,
"R&D","Mallory", 29,
"Marketing", "Alex", 35
];
let allReports = datatable(employee:string, manager:string, modificationDate: datetime)
[
"Bob", "Alice", datetime(2022-05-23),
"Bob", "Eve", datetime(2023-01-01),
"Eve", "Mallory", datetime(2022-05-23),
"Alice", "Dave", datetime(2022-05-23)
];
let filteredEmployees =
allEmployees
| where organization == "R&D"
| project-away age, organization;
let filteredReports =
allReports
| summarize arg_max(modificationDate, *) by employee
| project-away modificationDate;
filteredReports
| make-graph employee --> manager with filteredEmployees on name
| graph-match (employee)-[hasManager*2..5]-(manager)
where employee.name == "Bob"
project employee = employee.name, topManager = manager.name
Ausgabe:
| Arbeitnehmer | topManager |
|---|---|
| Bubikopf | Mallory |
Beibehalten des aktuellen Zustands mit materialisierten Ansichten
Im vorherigen Beispiel wurde gezeigt, wie Sie den letzten bekannten Zustand mithilfe von summarize und arg_max erhalten können. Dieser Vorgang kann rechenintensiv sein, daher sollten Sie materialisierte Ansichten für eine verbesserte Leistung verwenden.
Schritt 1: Erstellen von Tabellen mit Versionsverwaltung
Erstellen von Tabellen mit einem Versionsverwaltungsmechanismus für Diagrammzeitreihen:
.create table employees (organization: string, name:string, stateOfEmployment:string, properties:dynamic, modificationDate:datetime)
.create table reportsTo (employee:string, manager:string, modificationDate: datetime)
Schritt 2: Erstellen materialisierter Ansichten
Verwenden Sie die arg_max Aggregationsfunktion , um den neuesten Zustand zu ermitteln:
.create materialized-view employees_MV on table employees
{
employees
| summarize arg_max(modificationDate, *) by name
}
.create materialized-view reportsTo_MV on table reportsTo
{
reportsTo
| summarize arg_max(modificationDate, *) by employee
}
Schritt 3: Erstellen von Hilfsfunktionen
Stellen Sie sicher, dass nur die materialisierte Komponente verwendet wird, und wenden Sie zusätzliche Filter an:
.create function currentEmployees () {
materialized_view('employees_MV')
| where stateOfEmployment == "employed"
}
.create function reportsTo_lastKnownState () {
materialized_view('reportsTo_MV')
| project-away modificationDate
}
Dieser Ansatz bietet schnellere Abfragen, höhere Parallelität und niedrigere Latenz für die aktuelle Zustandsanalyse, während der Zugriff auf historische Daten erhalten bleibt.
let filteredEmployees =
currentEmployees
| where organization == "R&D"
| project-away organization;
reportsTo_lastKnownState
| make-graph employee --> manager with filteredEmployees on name
| graph-match (employee)-[hasManager*2..5]-(manager)
where employee.name == "Bob"
project employee = employee.name, reportingPath = hasManager.manager
Implementieren von Graph-Zeitreisen
Das Analysieren von Daten basierend auf historischen Diagrammzuständen bietet wertvollen zeitlichen Kontext. Implementieren Sie diese "Zeitreise"-Fähigkeit, indem Sie Zeitfilter mit summarize und arg_max kombinieren.
.create function graph_time_travel (interestingPointInTime:datetime ) {
let filteredEmployees =
employees
| where modificationDate < interestingPointInTime
| summarize arg_max(modificationDate, *) by name;
let filteredReports =
reportsTo
| where modificationDate < interestingPointInTime
| summarize arg_max(modificationDate, *) by employee
| project-away modificationDate;
filteredReports
| make-graph employee --> manager with filteredEmployees on name
}
Verwendungsbeispiel:
Abfrage Bobs Top-Manager basierend auf dem Diagrammstatus vom Juni 2022:
graph_time_travel(datetime(2022-06-01))
| graph-match (employee)-[hasManager*2..5]-(manager)
where employee.name == "Bob"
project employee = employee.name, reportingPath = hasManager.manager
Ausgabe:
| Arbeitnehmer | topManager |
|---|---|
| Bubikopf | David |
Verarbeiten mehrerer Knoten- und Kantentypen
Verwenden Sie beim Arbeiten mit komplexen Diagrammen, die mehrere Knotentypen enthalten, ein kanonisches Eigenschaftendiagrammmodell. Definieren Sie Knoten mit Attributen wie nodeId (Zeichenfolge), label (Zeichenfolge) und properties (dynamisch), während Kanten Felder wie source (Zeichenfolge), destination (Zeichenfolge), label (Zeichenfolge) und properties (dynamisch) enthalten.
Beispiel: Analyse der Werkswartung
Erwägen Sie einen Werksleiter, der Geräteprobleme untersucht und verantwortliche Mitarbeiter. Das Szenario kombiniert Bestandsdiagramme von Produktionsanlagen mit der Hierarchie der Wartungsmitarbeiter:
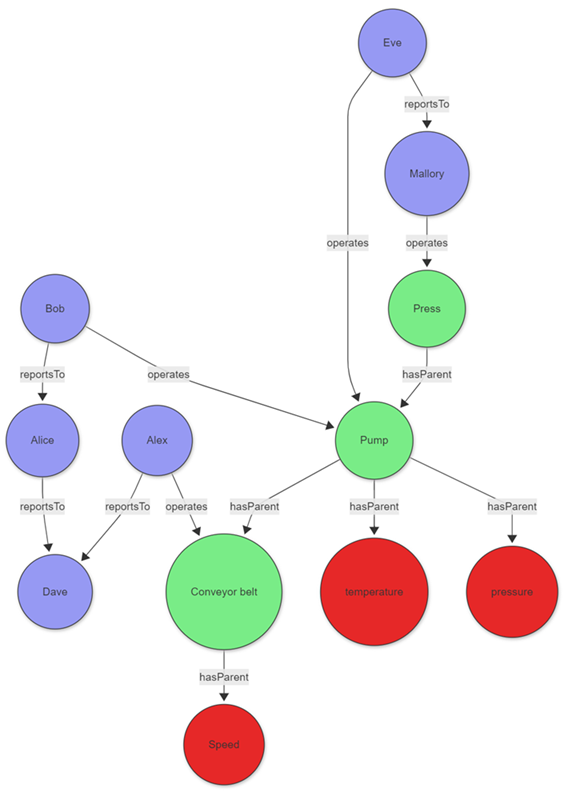
Die Daten für diese Entitäten können direkt in Ihrem Cluster gespeichert oder mithilfe des Abfrageverbunds zu einem anderen Dienst erworben werden. Zur Veranschaulichung des Beispiels werden die folgenden tabellarischen Daten als Teil der Abfrage erstellt:
let sensors = datatable(sensorId:string, tagName:string, unitOfMeasure:string)
[
"1", "temperature", "°C",
"2", "pressure", "Pa",
"3", "speed", "m/s"
];
let timeseriesData = datatable(sensorId:string, timestamp:string, value:double, anomaly: bool )
[
"1", datetime(2023-01-23 10:00:00), 32, false,
"1", datetime(2023-01-24 10:00:00), 400, true,
"3", datetime(2023-01-24 09:00:00), 9, false
];
let employees = datatable(name:string, age:long)
[
"Alice", 32,
"Bob", 31,
"Eve", 27,
"Mallory", 29,
"Alex", 35,
"Dave", 45
];
let allReports = datatable(employee:string, manager:string)
[
"Bob", "Alice",
"Alice", "Dave",
"Eve", "Mallory",
"Alex", "Dave"
];
let operates = datatable(employee:string, machine:string, timestamp:datetime)
[
"Bob", "Pump", datetime(2023-01-23),
"Eve", "Pump", datetime(2023-01-24),
"Mallory", "Press", datetime(2023-01-24),
"Alex", "Conveyor belt", datetime(2023-01-24),
];
let assetHierarchy = datatable(source:string, destination:string)
[
"1", "Pump",
"2", "Pump",
"Pump", "Press",
"3", "Conveyor belt"
];
Mitarbeiter, Sensoren und andere Entitäten und Beziehungen teilen kein kanonisches Datenmodell. Der Union-Operator kann verwendet werden, um die Daten zu kombinieren und zu standardisieren.
Die folgende Abfrage verknüpft die Sensordaten mit den Zeitreihendaten, um Sensoren mit abnormen Messwerten zu identifizieren, und verwendet dann eine Projektion, um ein gemeinsames Modell für die Diagrammknoten zu erstellen.
let nodes =
union
(
sensors
| join kind=leftouter
(
timeseriesData
| summarize hasAnomaly=max(anomaly) by sensorId
) on sensorId
| project nodeId = sensorId, label = "tag", properties = pack_all(true)
),
( employees | project nodeId = name, label = "employee", properties = pack_all(true));
Die Kanten werden auf ähnliche Weise transformiert.
let edges =
union
( assetHierarchy | extend label = "hasParent" ),
( allReports | project source = employee, destination = manager, label = "reportsTo" ),
( operates | project source = employee, destination = machine, properties = pack_all(true), label = "operates" );
Mit den standardisierten Knoten- und Kantendaten können Sie mithilfe des Make-Graph-Operators ein Diagramm erstellen.
let graph = edges
| make-graph source --> destination with nodes on nodeId;
Nachdem das Diagramm erstellt wurde, definieren Sie das Pfadmuster, und projizieren Sie die erforderlichen Informationen. Das Muster beginnt bei einem Tagknoten, gefolgt von einer Kante mit variabler Länge zu einem Asset. Dieses Asset wird von einem Bediener betrieben, der über eine variable Kantenlänge namens reportsTo an einen Top-Manager berichtet. Der Einschränkungsbereich des Diagrammvergleichsoperators, in diesem Fall die Where-Klausel , filtert die Tags auf diejenigen mit Anomalien, die an einem bestimmten Tag betrieben wurden.
graph
| graph-match (tag)-[hasParent*1..5]->(asset)<-[operates]-(operator)-[reportsTo*1..5]->(topManager)
where tag.label=="tag" and tobool(tag.properties.hasAnomaly) and
startofday(todatetime(operates.properties.timestamp)) == datetime(2023-01-24)
and topManager.label=="employee"
project
tagWithAnomaly = tostring(tag.properties.tagName),
impactedAsset = asset.nodeId,
operatorName = operator.nodeId,
responsibleManager = tostring(topManager.nodeId)
Ausgabe
| TagMitAnomalie | betroffenes Asset | operatorName | verantwortlicher Manager |
|---|---|---|---|
| Temperatur | Pumpe | Abend | Mallory |
Die Projektion graph-match zeigt, dass der Temperatursensor am angegebenen Tag eine Anomalie aufweist. Der Sensor wurde von Eve betrieben, der schließlich an Mallory berichtet. Mit diesen Informationen kann der Fabrikleiter Eve kontaktieren und ggf. Mallory kontaktieren, um die Anomalie besser zu verstehen.
Bewährte Methoden für persistente Diagramme
Dauerhafte Diagramme, die mithilfe von Diagrammmodellen und Diagrammmomentaufnahmen definiert sind, bieten robuste Lösungen für fortgeschrittene Graph-Analyseanforderungen. Diese Diagramme zeichnen sich in Szenarien aus, die eine wiederholte Analyse großer, komplexer oder sich entwickelnder Datenbeziehungen erfordern und die Zusammenarbeit vereinfachen, indem Teams standardisierte Diagrammdefinitionen und konsistente Analyseergebnisse gemeinsam nutzen können. Durch das Beibehalten von Diagrammstrukturen in der Datenbank verbessert dieser Ansatz die Leistung für wiederkehrende Abfragen erheblich und unterstützt anspruchsvolle Versionsverwaltungsfunktionen.
Verwenden von Schema und Definition für Konsistenz und Leistung
Ein klares Schema für Ihr Diagrammmodell ist unerlässlich, da es Knoten- und Randtypen zusammen mit ihren Eigenschaften angibt. Mit diesem Ansatz wird die Datenkonsistenz sichergestellt und eine effiziente Abfrage ermöglicht. Verwenden Sie den Definition Abschnitt, um anzugeben, wie Knoten und Kanten aus Ihren tabellarischen Daten durch AddNodes und AddEdges Schritte erstellt werden.
Nutzen statischer und dynamischer Bezeichnungen für flexible Modellierung
Beim Modellieren ihres Diagramms können Sie sowohl statische als auch dynamische Bezeichnungsansätze für optimale Flexibilität nutzen. Statische Beschriftungen eignen sich ideal für gut definierte Knoten- und Randtypen, die sich selten ändern – definieren Sie diese im Schema Abschnitt, und verweisen Sie auf sie im Labels Array Ihrer Schritte. Verwenden Sie für Fälle, in denen Knoten- oder Edgetypen durch Datenwerte bestimmt werden (z. B. wenn der Typ in einer Spalte gespeichert wird), dynamische Bezeichnungen, indem Sie einen LabelsColumn in Ihrem Schritt angeben, um Bezeichnungen zur Laufzeit zuzuweisen. Dieser Ansatz ist besonders nützlich für Diagramme mit heterogenen oder sich entwickelnden Schemas. Beide Mechanismen können effektiv kombiniert werden– Sie können ein Labels Array für statische Beschriftungen definieren und auch angeben LabelsColumn , dass zusätzliche Beschriftungen aus Ihren Daten integriert werden sollen. Dies bietet maximale Flexibilität beim Modellieren komplexer Diagramme mit fester und datengesteuerter Kategorisierung.
Beispiel: Verwenden dynamischer Bezeichnungen für mehrere Knoten- und Edgetypen
Das folgende Beispiel zeigt eine effektive Implementierung dynamischer Bezeichnungen in einem Diagramm, das professionelle Beziehungen darstellt. In diesem Szenario enthält das Diagramm Personen und Unternehmen als Knoten, wobei Arbeitsbeziehungen die Ränder zwischen ihnen bilden. Die Flexibilität dieses Modells kommt aus der Bestimmung von Knoten- und Edgetypen direkt aus Spalten in den Quelldaten, sodass die Diagrammstruktur organisch an die zugrunde liegenden Informationen angepasst werden kann.
.create-or-alter graph_model ProfessionalNetwork ```
{
"Schema": {
"Nodes": {
"Person": {"Name": "string", "Age": "long"},
"Company": {"Name": "string", "Industry": "string"}
},
"Edges": {
"WORKS_AT": {"StartDate": "datetime", "Position": "string"}
}
},
"Definition": {
"Steps": [
{
"Kind": "AddNodes",
"Query": "Employees | project Id, Name, Age, NodeType",
"NodeIdColumn": "Id",
"Labels": ["Person"],
"LabelsColumn": "NodeType"
},
{
"Kind": "AddEdges",
"Query": "EmploymentRecords | project EmployeeId, CompanyId, StartDate, Position, RelationType",
"SourceColumn": "EmployeeId",
"TargetColumn": "CompanyId",
"Labels": ["WORKS_AT"],
"LabelsColumn": "RelationType"
}
]
}
}
```
Dieser ansatz für dynamische Bezeichnungen bietet außergewöhnliche Flexibilität beim Modellieren von Diagrammen mit zahlreichen Knoten- und Edgetypen, sodass das Schema bei jeder Anzeige eines neuen Entitätstyps in Ihren Daten nicht mehr geändert werden muss. Durch Entkoppeln des logischen Modells von der physischen Implementierung kann sich Ihr Diagramm kontinuierlich weiterentwickeln, um neue Beziehungen darzustellen, ohne strukturelle Änderungen am zugrunde liegenden Schema zu erfordern.
Mehrinstanzenfähige Partitionierungsstrategien für groß angelegte ISV-Szenarien
In großen Organisationen, insbesondere ISV-Szenarien, können Diagramme aus mehreren Milliarden Knoten und Kanten bestehen. Dieser Maßstab stellt einzigartige Herausforderungen dar, die strategische Partitionierungsansätze erfordern, um die Leistung zu gewährleisten und gleichzeitig Kosten und Komplexität zu verwalten.
Grundlegendes zur Herausforderung
Große Mehrinstanzenumgebungen weisen häufig die folgenden Merkmale auf:
- Milliarden von Knoten und Kanten – Unternehmensmaßstab-Graphen, die die Fähigkeiten herkömmlicher Graphdatenbanken überschreiten
- Verteilung der Mandantengröße – folgt in der Regel einem Potenzgesetz, bei dem 99,9 %% der Mandanten kleine bis mittlere Graphen aufweisen, während 0,1 %% massive Graphen haben
- Leistungsanforderungen – Bedarf sowohl für Echtzeitanalysen (aktuelle Daten) als auch für historische Analysefunktionen
- Kostenüberlegungen – Balance zwischen Infrastrukturkosten und analytischen Fähigkeiten
Partitionierung durch natürliche Grenzen
Der effektivste Ansatz für die Verwaltung großer Diagramme ist die Partitionierung durch natürliche Grenzen, in der Regel Mandanten-IDs oder Organisationseinheiten:
Schlüsselpartitionierungsstrategien:
- Mandantenbasierte Partitionierung – Separate Diagramme nach Kunden, Organisation oder Geschäftseinheit
- Geografische Partitionierung – Dividieren nach Region, Land oder Rechenzentrumsstandort
- Zeitliche Partitionierung - Getrennt nach Zeiträumen für die historische Analyse
- Funktionale Partitionierung – Aufgeteilt nach Geschäftsdomäne oder Anwendungsbereich
Beispiel: Mehrinstanzenfähige Organisationsstruktur
// Partition employees and reports by tenant
let tenantEmployees =
allEmployees
| where tenantId == "tenant_123"
| project-away tenantId;
let tenantReports =
allReports
| where tenantId == "tenant_123"
| summarize arg_max(modificationDate, *) by employee
| project-away modificationDate, tenantId;
tenantReports
| make-graph employee --> manager with tenantEmployees on name
| graph-match (employee)-[hasManager*1..5]-(manager)
where employee.name == "Bob"
project employee = employee.name, reportingChain = hasManager.manager
Hybridansatz: Vorübergehende und persistente Diagramme nach Mandantengröße
Die kostengünstigste Strategie kombiniert vorübergehende und persistente Diagramme basierend auf Mandantenmerkmalen:
Kleine bis mittlere Mandanten (99,9% von Mandanten)
Verwenden Sie transiente Diagramme für die meisten Mandanten.
Vorteile:
- Always up-to-date data - Keine Snapshot-Wartung erforderlich
- Geringerer Betriebsaufwand – Keine Diagrammmodell- oder Momentaufnahmeverwaltung
- Kosteneffizient - Keine zusätzlichen Speicherkosten für Graphstrukturen
- Sofortige Verfügbarkeit – Keine Vorverarbeitungsverzögerungen
Implementierungsmuster:
.create function getTenantGraph(tenantId: string) {
let tenantEmployees =
employees
| where tenant == tenantId and stateOfEmployment == "employed"
| project-away tenant, stateOfEmployment;
let tenantReports =
reportsTo
| where tenant == tenantId
| summarize arg_max(modificationDate, *) by employee
| project-away modificationDate, tenant;
tenantReports
| make-graph employee --> manager with tenantEmployees on name
}
// Usage for small tenant
getTenantGraph("small_tenant_456")
| graph-match (employee)-[reports*1..3]-(manager)
where employee.name == "Alice"
project employee = employee.name, managerChain = reports.manager
Große Mandanten (0.1% von Mandanten)
Verwenden Sie persistente Diagramme für die größten Mandanten.
Vorteile:
- Skalierbarkeit – Behandeln von Diagrammen, die Speicherbeschränkungen überschreiten
- Leistungsoptimierung – Vermeiden der Baulatenz für komplexe Abfragen
- Erweiterte Analysen – Unterstützung anspruchsvoller Graphalgorithmen und Analysen
- Historische Analyse – Mehrere Momentaufnahmen für einen zeitlichen Vergleich
Implementierungsmuster:
// Create graph model for large tenant (example: Contoso)
.create-or-alter graph_model ContosoOrgChart ```
{
"Schema": {
"Nodes": {
"Employee": {
"Name": "string",
"Department": "string",
"Level": "int",
"JoinDate": "datetime"
}
},
"Edges": {
"ReportsTo": {
"Since": "datetime",
"Relationship": "string"
}
}
},
"Definition": {
"Steps": [
{
"Kind": "AddNodes",
"Query": "employees | where tenant == 'Contoso' and stateOfEmployment == 'employed' | project Name, Department, Level, JoinDate",
"NodeIdColumn": "Name",
"Labels": ["Employee"]
},
{
"Kind": "AddEdges",
"Query": "reportsTo | where tenant == 'Contoso' | summarize arg_max(modificationDate, *) by employee | project employee, manager, modificationDate as Since | extend Relationship = 'DirectReport'",
"SourceColumn": "employee",
"TargetColumn": "manager",
"Labels": ["ReportsTo"]
}
]
}
}
```
// Create snapshot for Contoso
.create graph snapshot ContosoSnapshot from ContosoOrgChart
// Query Contoso's organizational graph
graph("ContosoOrgChart")
| graph-match (employee)-[reports*1..10]-(executive)
where employee.Department == "Engineering"
project employee = employee.Name, executive = executive.Name, pathLength = array_length(reports)
Bewährte Methoden für ISV-Szenarien
- Starten Sie mit vorübergehenden Diagrammen - Alle neuen Mandanten sollten mit vorübergehenden Diagrammen beginnen, um es einfach zu halten
- Überwachen von Wachstumsmustern – Implementieren der automatischen Erkennung von Mandanten, die dauerhafte Diagramme erfordern
- Erstellung von Batchmomentaufnahmen – Planen von Momentaufnahmeaktualisierungen in Zeiträumen mit geringer Nutzung
- Mandantenisolation – Sicherstellen, dass Diagrammmodelle und Momentaufnahmen ordnungsgemäß zwischen Mandanten isoliert sind
- Ressourcenverwaltung – Verwenden von Workloadgruppen, um zu verhindern, dass sich große Mandantenabfragen auf kleinere Mandanten auswirken
- Kostenoptimierung – Regelmäßige Überprüfung und Optimierung des persistenten/vorübergehenden Schwellenwerts basierend auf tatsächlichen Nutzungsmustern
Mit diesem Hybridansatz können Organisationen immer aktuelle Datenanalysen für die mehrzahl der Mandanten bereitstellen und gleichzeitig Unternehmensanalysen für die größten Mandanten bereitstellen, wodurch Kosten und Leistung in der gesamten Kundenbasis optimiert werden.