Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
Von Bedeutung
Nicht englische Übersetzungen werden nur zur Bequemlichkeit bereitgestellt. Bitte wenden Sie sich an die EN-US Version dieses Dokuments für die Bindungsversion.
Viele der Azure OpenAI-Modelle sind generative KI-Modelle, die verbesserungen an erweiterten Funktionen wie z. B. Inhalts- und Codegenerierung, Zusammenfassung und Suche demonstriert haben. Mit vielen dieser Verbesserungen gehen auch erhöhte verantwortungsbewusste KI-Herausforderungen im Zusammenhang mit schädlichen Inhalten, Manipulation, menschlichem Verhalten, Datenschutz und mehr einher. Weitere Informationen zu den Funktionen, Einschränkungen und geeigneten Anwendungsfällen für diese Modelle finden Sie im Transparenzhinweis.
Zusätzlich zum Transparenzhinweis haben wir technische Empfehlungen und Ressourcen erstellt, die Kunden beim Entwerfen, Entwickeln, Bereitstellen und Verwenden von KI-Systemen unterstützen, die die Azure OpenAI-Modelle verantwortungsbewusst implementieren. Unsere Empfehlungen basieren auf dem Microsoft Responsible AI Standard, der Richtlinienanforderungen festlegt, die unsere eigenen Entwicklungsteams befolgen. Ein Großteil des Inhalts des Standards folgt einem Muster, das Teams auffordern, potenzielle Schäden zu identifizieren, zu messen und zu mindern und zu planen, wie das KI-System ebenfalls betrieben wird. In Übereinstimmung mit diesen Praktiken sind diese Empfehlungen in vier Stufen unterteilt:
- Identifizieren und priorisieren Sie potenzielle Schäden, die durch iteratives Red-Teaming, Stresstests und Analysen aus Ihrem KI-System resultieren könnten.
- Measure: Messen Sie die Häufigkeit und den Schweregrad dieser Schäden, indem Sie klare Metriken erstellen, Messtestsätze erstellen und iterative, systematische Tests (sowohl manuell als auch automatisiert) abschließen.
- Mindern Sie Schäden, indem Sie Tools und Strategien wie Prompt Engineering implementieren und unsere Inhaltsfilter verwenden. Wiederholen Sie die Messung, um die Effektivität nach der Implementierung von Entschärfungen zu testen.
- Operation : Definieren und Ausführen eines Bereitstellungs- und Betriebsbereitschaftsplans.
Neben ihrer Korrespondenz mit dem Microsoft Responsible AI Standard entsprechen diese Stufen den Funktionen im NIST AI Risk Management Framework genau.
Ermitteln
Die Identifizierung potenzieller Schäden, die in einem KI-System auftreten oder verursacht werden können, ist die erste Stufe des Verantwortlichen KI-Lebenszyklus. Je früher Sie mit der Identifizierung potenzieller Schäden beginnen, desto effektiver können Sie die Schäden mindern. Bei der Bewertung potenzieller Schäden ist es wichtig, ein Verständnis der Arten von Schäden zu entwickeln, die sich aus der Verwendung des Azure OpenAI-Diensts in Ihrem spezifischen Kontext ergeben könnten. In diesem Abschnitt bieten wir Empfehlungen und Ressourcen, die Sie verwenden können, um Schäden durch eine Folgenabschätzung, iterative rote Teamtests, Stresstests und Analysen zu identifizieren. Red-Teaming und Stresstests sind Ansätze, bei denen eine Gruppe von Testern zusammenkommen und absichtlich ein System untersuchen, um seine Einschränkungen, Risikooberfläche und Sicherheitsrisiken zu identifizieren.
Diese Schritte haben das Ziel, eine priorisierte Liste potenzieller Schäden für jedes bestimmte Szenario zu erstellen.
- Identifizieren Sie Schäden, die für Ihr spezifisches Modell, Ihre Anwendung und Ihr Bereitstellungsszenario relevant sind.
- Identifizieren Sie potenzielle Schäden im Zusammenhang mit den Modell- und Modellfunktionen (z. B. GPT-3-Modell und GPT-4-Modell), die Sie in Ihrem System verwenden. Dies ist wichtig zu berücksichtigen, da jedes Modell unterschiedliche Funktionen, Einschränkungen und Risiken aufweist, wie in den vorstehenden Abschnitten beschrieben.
- Identifizieren Sie andere Schäden oder einen erhöhten Schaden, der durch die beabsichtigte Verwendung Ihres Systems entstehen könnte. Erwägen Sie die Verwendung einer verantwortungsvollen KI-Folgenabschätzung , um potenzielle Schäden zu identifizieren.
- Betrachten wir beispielsweise ein KI-System, das Text zusammenfasst. Einige Verwendungsmöglichkeiten der Textgenerierung sind niedriger als andere. Wenn das System beispielsweise in einer Gesundheitsdomäne zum Zusammenfassen von Arztnotizen verwendet werden soll, ist das Risiko von Schäden, die sich aus Ungenauigkeiten ergeben, höher als wenn das System Onlineartikel zusammenfasst.
- Priorisieren Sie Schäden basierend auf Elementen des Risikos, z. B. Häufigkeit und Schweregrad. Bewerten Sie das Risikoniveau für jeden Schaden und die Wahrscheinlichkeit jedes Risikos, um die Liste der von Ihnen identifizierten Schäden zu priorisieren. Erwägen Sie, bei Bedarf mit Experten und Risikomanagern in Ihrer Organisation und mit relevanten externen Projektbeteiligten zusammenzuarbeiten.
- Führen Sie Red-Team-Tests und Stresstests durch, die mit den Risiken mit der höchsten Priorität beginnen, um ein besseres Verständnis dafür zu gewinnen, ob und wie die identifizierten Risiken tatsächlich in Ihrem Szenario auftreten, sowie um neue Risiken zu identifizieren, die Sie ursprünglich nicht vorhergesehen haben.
- Teilen Sie diese Informationen mithilfe der internen Complianceprozesse Ihrer Organisation mit relevanten Projektbeteiligten.
Am Ende dieser Identifizierungsphase sollten Sie eine dokumentierte, priorisierte Liste von Schäden haben. Wenn neue Schäden und neue Schadeninstanzen durch weitere Tests und Die Nutzung des Systems entstehen, können Sie diese Liste aktualisieren und verbessern, indem Sie den obigen Prozess erneut ausführen.
Maßnahme
Sobald eine Liste priorisierter Schäden identifiziert wurde, umfasst die nächste Phase die Entwicklung eines Ansatzes zur systematischen Messung der einzelnen Schäden und zur Durchführung von Bewertungen des KI-Systems. Es gibt manuelle und automatisierte Ansätze zur Messung. Wir empfehlen Ihnen, beides zu tun und mit der manuellen Messung zu beginnen.
Manuelle Messung ist nützlich für:
- Messen des Fortschritts bei einer kleinen Gruppe von Prioritätsproblemen. Bei der Eindämmung bestimmter Schäden ist es oft am produktivsten, den Fortschritt anhand eines kleinen Datasets manuell zu überprüfen, bis der Schaden nicht mehr zu beobachten ist, bevor man zur automatischen Messung übergeht.
- Definieren und Melden von Metriken, bis die automatisierte Messung zuverlässig genug ist, um sie selbst zu verwenden.
- Regelmäßige Stichprobenprüfungen zur Überprüfung der Qualität automatisierter Messungen.
Automatisierte Messung ist nützlich für:
- Automatisierte Messungen sind nützlich, wenn Sie in großem Maßstab und mit größerem Erfassungsbereich messen, um umfassendere Ergebnisse zu erhalten.
- Es ist auch hilfreich für die laufende Messung, um eventuelle Regressionen zu überwachen, wenn sich das System, die Nutzung und die Abhilfemaßnahmen weiterentwickeln.
Nachfolgend finden Sie spezifische Empfehlungen, um Ihr KI-System für potenzielle Schäden zu messen. Es wird empfohlen, diesen Vorgang zuerst manuell abzuschließen und dann einen Plan zur Automatisierung des Prozesses zu entwickeln:
Erstellen Sie Eingaben, die wahrscheinlich jeden priorisierten Schaden erzeugen: Erstellen Sie Maßsätze, indem Sie viele verschiedene Beispiele für gezielte Eingaben generieren, die wahrscheinlich jeden priorisierten Schaden erzeugen.
Systemausgaben generieren: Übergeben Sie die Beispiele aus den Messsätzen als Eingaben an das System, um Systemausgaben zu generieren. Dokumentieren Sie die Ausgaben.
Auswerten von Systemausgaben und Melden von Ergebnissen an relevante Projektbeteiligte
- Definieren Sie klare Metriken. Richten Sie für jede beabsichtigte Verwendung Ihres Systems Metriken ein, die die Häufigkeit und den Schweregrad jeder potenziell schädlichen Ausgabe messen. Erstellen Sie klare Definitionen, um Ausgaben zu klassifizieren, die im Kontext Ihres Systems und Szenarios als schädlich oder problematisch eingestuft werden, für jede Art von priorisiertem Schaden, den Sie identifiziert haben.
- Bewerten Sie die Ausgaben anhand der eindeutigen Metrikdefinitionen und -aufzeichnungen, und quantifizieren Sie die Vorkommen schädlicher Ausgaben. Wiederholen Sie die Messungen regelmäßig, um Entschärfungen zu bewerten und die Regression zu überwachen.
- Teilen Sie diese Informationen mithilfe der internen Complianceprozesse Ihrer Organisation mit relevanten Projektbeteiligten.
Am Ende dieser Messphase sollten Sie einen definierten Messansatz haben, um zu bewerten, wie Ihr System in Bezug auf jeden potenziellen Schaden abschneidet sowie über eine erste Reihe dokumentierter Ergebnisse verfügt. Wenn Sie weiterhin Entschärfungen implementieren und testen, sollten die Metriken und Messsätze weiterhin optimiert werden (z. B. um Metriken für neue Schäden hinzuzufügen, die ursprünglich nicht erwartet wurden) und die Ergebnisse aktualisiert werden.
Auswirkungen des Problems minimieren
Die Reduzierung von Schäden, die von großen Sprachmodellen (Large Language Models) wie den Azure OpenAI-Modellen präsentiert werden, erfordert einen iterativen, mehrstufigen Ansatz, der Experimentieren und kontinuierliche Messung umfasst. Es wird empfohlen, einen Entschärfungsplan zu entwickeln, der vier Ebenen von Gegenmaßnahmen für die in den früheren Phasen dieses Prozesses ermittelten Schäden umfasst:
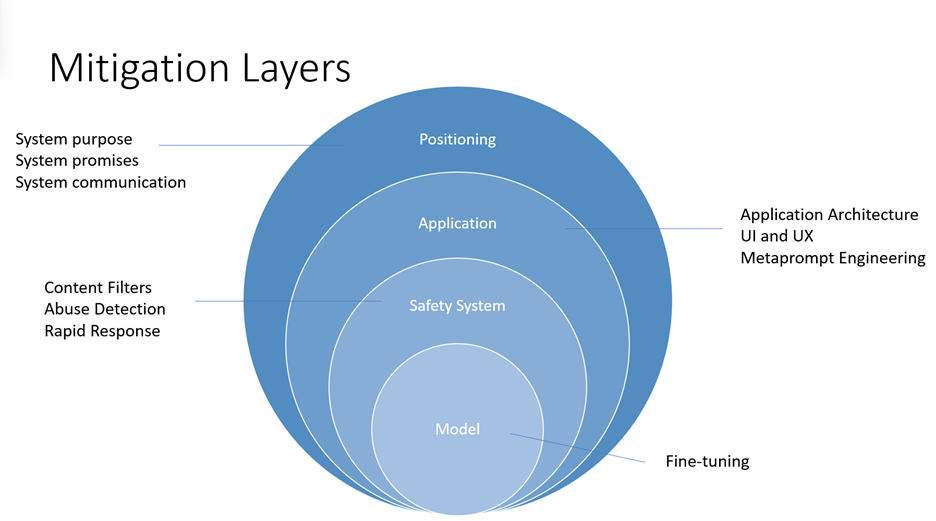
- Auf Modellebene ist es wichtig, die Modelle zu verstehen, die Sie verwenden werden, und welche Feinabstimmungsschritte möglicherweise von den Modellentwicklern unternommen wurden, um das Modell an die beabsichtigten Verwendungen auszurichten und das Risiko potenziell schädlicher Verwendungen und Ergebnisse zu verringern.
- Für GPT-4 konnten Modellentwickler beispielsweise Verstärkungslernmethoden als verantwortungsvolles KI-Tool verwenden, um das Modell besser an die beabsichtigten Ziele der Designer auszurichten.
- Auf Sicherheitssystemebene sollten Sie die implementierten Risikominderungen auf Plattformebene verstehen, z. B. die Azure OpenAI-Inhaltsfilter , die dazu beitragen, die Ausgabe schädlicher Inhalte zu blockieren.
- Auf Anwendungsebene können Anwendungsentwickler Metaprompt- und benutzerzentrierte Design- und Benutzeroberflächenminderungen implementieren. Metaprompts sind Anweisungen für das Modell, um sein Verhalten zu leiten; deren Verwendung kann entscheidend dazu führen, dass sich das System entsprechend Ihren Erwartungen verhält. Benutzerzentrierte Design- und UX-Interventionen (User Centered Design and User Experience, UX) sind auch wichtige Entschärfungstools, um Missbrauch und Überlastung auf KI zu verhindern.
- Auf der Positionierungsebene gibt es viele Möglichkeiten, die Personen zu schulen, die Ihr System nutzen oder davon betroffen sein werden, über dessen Funktionen und Einschränkungen.
Nachfolgend finden Sie spezifische Empfehlungen zur Implementierung von Gegenmaßnahmen auf den verschiedenen Ebenen. Nicht alle diese Gegenmaßnahmen sind für jedes Szenario geeignet, und umgekehrt sind diese Gegenmaßnahmen für einige Szenarien möglicherweise nicht ausreichend. Achten Sie sorgfältig auf Ihr Szenario und die priorisierten Schäden, die Sie identifiziert haben, und entwickeln Sie beim Implementieren von Entschärfungen einen Prozess zum Messen und Dokumentieren ihrer Effektivität für Ihr System und Ihr Szenario.
Risikominderungen auf Modellebene: Überprüfen und identifizieren Sie, welches Azure OpenAI-Basismodell am besten für das System geeignet ist, das Sie erstellen, und informieren Sie sich über seine Funktionen, Einschränkungen und alle Maßnahmen, die ergriffen werden, um das Risiko der potenziellen Schäden zu verringern, die Sie identifiziert haben. Wenn Sie z. B. GPT-4 verwenden, können Sie zusätzlich zum Lesen dieses Transparenzhinweiss die GPT-4-Systemkarte von OpenAI überprüfen, in der die sicherheitsrelevanten Herausforderungen des Modells und die Sicherheitsprozesse erläutert werden, die OpenAI zur Vorbereitung von GPT-4 für die Bereitstellung übernommen hat. Es kann sinnvoll sein, mit verschiedenen Versionen des Modells zu experimentieren (einschließlich durch Red Teaming und das Messen), um zu sehen, wie die Schäden unterschiedlich in Erscheinung treten.
Risikominderungen auf Sicherheitssystemebene: Identifizieren und bewerten Sie die Effektivität von Lösungen auf Plattformebene, z. B. die Azure OpenAI-Inhaltsfilter , um die potenziellen Schäden zu mindern, die Sie identifiziert haben.
Entschärfungen auf Anwendungsebene: Prompt Engineering, einschließlich Metaprompt-Optimierung, kann eine effektive Risikominderung für viele verschiedene Arten von Schäden sein. Überprüfen und implementieren Sie metaprompt (auch als "Systemnachricht" oder "Systemaufforderung" bezeichnet) Anleitungen und bewährte Methoden, die hier dokumentiert sind.
Es wird empfohlen, die folgenden benutzerzentrierten Design- und Benutzererfahrungs (User Experience, UX)-Interventionen, Anleitungen und bewährte Methoden zu implementieren, um Benutzer dazu zu führen, das System wie beabsichtigt zu verwenden und Überlastung auf dem KI-System zu verhindern:
- Überprüfen und Bearbeiten von Interventionen: Entwerfen Sie die Benutzeroberfläche (User Experience, UX), um Personen zu ermutigen, die das System verwenden, um die von KI generierten Ausgaben zu überprüfen und zu bearbeiten, bevor sie akzeptiert werden (siehe HAX G9: Effiziente Korrektur unterstützen).
- Heben Sie potenzielle Ungenauigkeiten in den KI-generierten Ausgaben hervor (siehe HAX G2: Machen Sie klar, wie gut das System tun kann, was es tun kann), sowohl wenn Benutzer das System zum ersten Mal verwenden, als auch zu geeigneten Zeiten während der laufenden Nutzung. Benachrichtigen Sie benutzer in der ersten Ausführungserfahrung (FRE), dass KI-generierte Ausgaben Ungenauigkeiten enthalten können und dass sie Informationen überprüfen sollten. Schließen Sie während der gesamten Erfahrung Erinnerungen ein, um die von KI generierte Ausgabe auf potenzielle Ungenauigkeiten zu überprüfen, sowohl insgesamt als auch in Bezug auf bestimmte Arten von Inhalten, die das System falsch generieren kann. Wenn Ihr Messvorgang beispielsweise festgestellt hat, dass Ihr System mit Zahlen eine niedrigere Genauigkeit aufweist, markieren Sie Zahlen in generierten Ausgaben, um den Benutzer zu benachrichtigen und ihn zu ermutigen, die Zahlen zu überprüfen oder externe Quellen zur Überprüfung zu suchen.
- Benutzerverantwortung. Erinnern Sie Personen daran, dass sie für den endgültigen Inhalt verantwortlich sind, wenn sie KI-generierte Inhalte überprüfen. Erinnern Sie den Entwickler beispielsweise beim Anbieten von Codevorschlägen daran, Vorschläge vor der Annahme zu überprüfen und zu testen.
- Geben Sie die Rolle der KI in der Interaktion offen. Machen Sie sich bewusst, dass sie mit einem KI-System interagieren (im Gegensatz zu einem anderen Menschen). Informieren Sie die Nutzer von Inhalten gegebenenfalls darüber, dass Inhalte teilweise oder vollständig durch ein KI-Modell generiert wurden; Solche Hinweise können gesetzlich vorgeschrieben oder durch anwendbare bewährte Methoden erforderlich sein und die unangemessene Abhängigkeit von KI-generierten Ausgaben verringern und den Nutzern helfen, ihr eigenes Urteil darüber zu verwenden, wie sie solche Inhalte interpretieren und darauf reagieren können.
- Verhindern Sie, dass das System anthropomorphisiert. KI-Modelle können Inhalte ausgeben, die Meinungen, gefühlsbetonte Aussagen oder andere Formulierungen enthalten, die den Eindruck vermitteln könnten, dass sie menschlich sind, die fälschlicherweise als menschliche Identität verstanden werden könnten, oder die Menschen dazu verleiten könnten zu glauben, dass ein System bestimmte Fähigkeiten hat, die es nicht besitzt. Implementieren Sie Mechanismen, die das Risiko solcher Ausgaben reduzieren oder Offenlegungen integrieren, um die Fehlinterpretation von Ausgaben zu verhindern.
- Zitieren Sie Verweise und Informationsquellen. Wenn Ihr System Inhalte auf der Grundlage von Verweisen generiert, die an das Modell gesendet werden, hilft das Zitieren von Informationsquellen den Menschen zu verstehen, woher die von der KI generierten Inhalte stammen.
- Beschränken Sie gegebenenfalls die Länge der Ein- und Ausgaben. Das Einschränken der Eingabe- und Ausgabelänge kann die Wahrscheinlichkeit verringern, unerwünschte Inhalte zu erzeugen, den Missbrauch des Systems über seine beabsichtigte Verwendung hinaus oder andere schädliche oder unbeabsichtigte Verwendungen zu vermeiden.
- Strukturieren Sie Eingaben und/oder Systemausgaben. Verwenden Sie eingabeaufforderungstechnische Techniken in Ihrer Anwendung, um Eingaben für das System zu strukturieren, um offene Antworten zu verhindern. Sie können Ausgaben auch einschränken, sodass sie in bestimmten Formaten oder Mustern strukturiert werden. Wenn Ihr System z. B. einen Dialog für einen fiktiven Charakter als Reaktion auf Abfragen generiert, beschränken Sie die Eingaben so, dass Personen nur nach einer vordefinierten Gruppe von Konzepten abfragen können.
- Bereiten Sie vorab festgelegte Antworten vor. Es gibt bestimmte Abfragen, für die ein Modell anstößige, unangemessene oder anderweitig schädliche Antworten generieren kann. Wenn schädliche oder anstößige Abfragen oder Antworten erkannt werden, können Sie Ihr System so entwerfen, dass eine vordefinierte Antwort an den Benutzer übermittelt wird. Vordefinierte Antworten sollten sorgfältig gestaltet werden. Beispielsweise kann die Anwendung vorgefertigte Antworten auf Fragen wie „Wer/was bist du?“ bereitstellen, um zu vermeiden, dass das System mit anthropomorphen Antworten reagiert. Sie können auch vordefinierte Antworten auf Fragen wie "Was sind Ihre Nutzungsbedingungen?" verwenden, um Personen zur richtigen Richtlinie zu leiten.
- Schränken Sie die automatische Veröffentlichung in sozialen Medien ein. Beschränken Sie, wie Personen Ihr Produkt oder Ihren Dienst automatisieren können. Sie können z. B. die automatisierte Veröffentlichung von KI-generierten Inhalten auf externen Websites (einschließlich sozialer Medien) verbieten oder die automatisierte Ausführung von generierten Code verbieten.
- Bot-Erkennung. Entwickeln und implementieren Sie einen Mechanismus, um zu verhindern, dass Benutzer eine API auf Grundlage Ihres Produkts erstellen.
Risikominderungen auf Positionierungsebene:
- Seien Sie angemessen transparent. Es ist wichtig, den Menschen, die das System nutzen, das richtige Maß an Transparenz zu bieten, damit sie fundierte Entscheidungen zur Nutzung des Systems treffen können.
- Bereitstellen einer Systemdokumentation. Erstellen und stellen Sie Schulungsmaterialien für Ihr System bereit, einschließlich Erläuterungen seiner Funktionen und Einschränkungen. Dies könnte z. B. in Form einer über das System zugänglichen Seite „Weitere Informationen“ erfolgen.
- Veröffentlichen Sie Benutzerrichtlinien und bewährte Methoden. Helfen Sie Benutzern und Projektbeteiligten, das System angemessen zu nutzen, indem Sie bewährte Methoden veröffentlichen, z. B. zum Erstellen von Aufforderungen, zum Überprüfen von Generationen, bevor sie akzeptiert werden usw. Solche Richtlinien können personen dabei helfen zu verstehen, wie das System funktioniert. Integrieren Sie nach Möglichkeit die Richtlinien und bewährten Methoden direkt in die UX.
Wenn Sie Gegenmaßnahmen implementieren, um potenzielle identifizierte Schäden zu beheben, ist es wichtig, einen Prozess zur kontinuierlichen Messung der Wirksamkeit solcher Gegenmaßnahmen zu entwickeln, Messergebnisse zu dokumentieren und diese Messergebnisse zu überprüfen, um das System kontinuierlich zu verbessern.
Betrieb
Sobald Mess- und Entschärfungssysteme vorhanden sind, empfehlen wir, einen Bereitstellungs- und Betriebsbereitschaftsplan zu definieren und auszuführen. Diese Phase umfasst die Durchführung geeigneter Überprüfungen Ihrer System- und Entschärfungspläne mit relevanten Projektbeteiligten, die Einrichtung von Pipelines zum Sammeln von Telemetrie und Feedback sowie die Entwicklung eines Vorfallreaktions- und Rollbackplans.
Einige Empfehlungen für das Bereitstellen und Betreiben eines Systems, das den Azure OpenAI-Dienst mit geeigneten, gezielten Schadensminderungen verwendet, sind:
Arbeiten Sie mit Complianceteams innerhalb Ihrer Organisation zusammen, um zu verstehen, welche Arten von Rezensionen für Ihr System erforderlich sind und wann sie erforderlich sind (z. B. rechtliche Überprüfung, Datenschutzüberprüfung, Sicherheitsüberprüfung, Barrierefreiheitsprüfung usw.).
Entwickeln und implementieren Sie Folgendes:
- Entwickeln Sie einen phasenweisen Lieferplan. Es wird empfohlen, Systeme mit dem Azure OpenAI-Dienst schrittweise mithilfe eines "phasenweisen Lieferansatzes" zu starten. Dies bietet eine begrenzte Anzahl von Personen die Möglichkeit, das System auszuprobieren, Feedback zu geben, Probleme und Bedenken zu melden und Verbesserungen vorzuschlagen, bevor das System breiter veröffentlicht wird. Außerdem hilft es, das Risiko unvorhergesehener Fehlermodi, unerwartetes Systemverhalten und unerwartete Bedenken zu verwalten.
- Entwickeln eines Plans für die Reaktion auf Sicherheitsvorfälle. Entwickeln Sie einen Plan zur Reaktion auf Vorfälle, und bewerten Sie die Zeit, die erforderlich ist, um auf einen Vorfall zu reagieren.
- Entwickeln eines Rollbackplans Stellen Sie sicher, dass Sie das System schnell und effizient zurücksetzen können, falls ein unerwarteter Vorfall auftritt.
- Bereiten Sie sich auf sofortige Maßnahmen für unerwartete Schäden vor. Erstellen Sie die erforderlichen Features und Prozesse, um problematische Eingabeaufforderungen und Antworten so zu blockieren, wie sie entdeckt und so nah wie möglich in Echtzeit sind. Wenn unerwartete Schäden auftreten, blockieren Sie die problematischen Eingabeaufforderungen und -antworten so schnell wie möglich, entwickeln und bereitstellen sie geeignete Gegenmaßnahmen, untersuchen Sie den Vorfall und implementieren Sie eine langfristige Lösung.
- Entwickeln Sie einen Mechanismus, um Personen zu blockieren, die Ihr System falsch verwenden. Entwickeln Sie einen Mechanismus, um Benutzer zu identifizieren, die gegen Ihre Inhaltsrichtlinien verstoßen (z. B. durch Generieren von Hassreden), oder verwenden Sie Ihr System anderweitig für unbeabsichtigte oder schädliche Zwecke, und ergreifen Sie Maßnahmen gegen weitere Missbrauch. Wenn ein Benutzer beispielsweise Ihr System häufig zum Generieren von Inhalten verwendet, die von Inhaltssicherheitssystemen blockiert oder gekennzeichnet werden, sollten Sie erwägen, ihm die weitere Verwendung Ihres Systems zu untersagen. Implementieren Sie gegebenenfalls einen Beschwerdemechanismus.
- Erstellen Sie effektive Benutzerfeedbackkanäle. Implementieren Sie Feedback-Kanäle, über die Stakeholder (und ggf. die breite Öffentlichkeit) Feedback abgeben oder Probleme mit generierten Inhalten oder Probleme melden können, die während der Nutzung des Systems anderweitig auftreten. Dokumentieren Sie, wie ein solches Feedback verarbeitet, berücksichtigt und adressiert wird. Bewerten Sie das Feedback und die Arbeit, um das System basierend auf Benutzerfeedback zu verbessern. Ein Ansatz könnte das Einschließen von Schaltflächen mit generierten Inhalten sein, mit denen Benutzer Inhalte als "ungenau", "schädlich" oder "unvollständig" identifizieren können. Dies könnte ein weit verbreitetes, strukturiertes und Feedbacksignal für die Analyse bieten.
- Telemetriedaten. Identifizieren und erfassen Sie (im Einklang mit geltenden Datenschutzgesetzen, -richtlinien und -verpflichtungen) Signale, die auf die Zufriedenheit der Benutzer oder ihre Fähigkeit hinweisen, das System wie vorgesehen zu verwenden. Verwenden Sie Telemetriedaten, um Lücken zu identifizieren und das System zu verbessern.
Dieses Dokument stellt keine rechtliche Beratung dar und darf auch nicht als solche ausgelegt werden. In der Gerichtsbarkeit, in der Sie agieren, können verschiedene behördliche oder rechtliche Anforderungen für Ihr KI-System gelten. Wenden Sie sich an einen Rechtsspezialisten, wenn Sie unsicher sind, welche Gesetze oder Vorschriften für Ihr System gelten könnten, insbesondere, wenn Sie der Meinung sind, dass sich dies auf diese Empfehlungen auswirken könnte. Beachten Sie, dass nicht alle hier bereitgestellten Empfehlungen und Ressourcen für jedes Szenario geeignet sind und dass die Empfehlungen und Ressourcen umgekehrt für einige Szenarien möglicherweise nicht ausreichen.
Erfahren Sie mehr über verantwortungsvolle KI
- KI-Prinzipien von Microsoft
- Ressourcen für verantwortungsbewusste KI von Microsoft
- Microsoft Azure Learning-Kurse zu verantwortungsvoller KI