Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
Die Domäne für die betriebsbezogene Sicherheit stellt sicher, dass ISVs eine reihe von Sicherheitsminderungstechniken gegen eine Vielzahl von Bedrohungen implementieren, denen Bedrohungsakteure gegenüberstehen. Dies ist darauf ausgelegt, die Betriebsumgebung und Softwareentwicklungsprozesse zu schützen, um sichere Umgebungen zu erstellen.
Bewusstseinsschulung
Sicherheitsbewusstseinsschulungen sind für Organisationen wichtig, da sie dazu beiträgt, die Risiken zu minimieren, die sich aus menschlichen Fehlern ergeben, die an mehr als 90 % der Sicherheitsverletzungen beteiligt sind. Es hilft Mitarbeitern, die Bedeutung von Sicherheitsmaßnahmen und -verfahren zu verstehen. Wenn Schulungen zum Sicherheitsbewusstsein angeboten werden, verstärkt dies die Bedeutung einer sicherheitsbewussten Kultur, in der Benutzer wissen, wie sie potenzielle Bedrohungen erkennen und darauf reagieren können. Ein effektives Schulungsprogramm für Sicherheitsbewusstsein sollte Inhalte umfassen, die eine Vielzahl von Themen und Bedrohungen umfassen, mit denen Benutzer konfrontiert sein könnten, z. B. Social Engineering, Kennwortverwaltung, Datenschutz und physische Sicherheit.
Steuerelement Nr. 1
Weisen Sie folgendes nach:
Die organization legt Schulungsrichtlinien und -prozesse für das Sicherheitsbewusstsein fest, die erfordern, dass alle Benutzer der In-Scope-Systeme (einschließlich Auftragnehmern) eine Schulung durchlaufen:
Im Rahmen der Erstschulung für neue Benutzer oder bei Bedarf durch Informationssystem/organization Veränderungen oder Branchentrends.
Mindestens jährlich.
Sie dokumentieren und überwachen Das Sicherheitsbewusstsein des Informationssystems und bewahren einzelne Trainingsdatensätze inLine mit Punkt A auf.
Absicht: Schulung für neue Benutzer
Dieser Unterpunkt konzentriert sich auf die Einrichtung eines obligatorischen Sicherheitsbewusstseins-Schulungsprogramms für alle Mitarbeiter und für neue Mitarbeiter, die der organization beitreten, unabhängig von ihrer Rolle. Dies schließt Manager, Leitende Führungskräfte und Auftragnehmer ein. Das Sicherheitsbewusstseinsprogramm sollte einen umfassenden Lehrplan umfassen, der grundlegendes Wissen über die Informationssicherheitsprotokolle, Richtlinien und bewährten Methoden der organization vermittelt, um sicherzustellen, dass alle Mitglieder der organization an einem einheitlichen Satz von Sicherheitsstandards ausgerichtet sind und eine robuste Informationssicherheitsumgebung schaffen.
Richtlinien: Schulung für neue Benutzer
Die meisten Organisationen nutzen eine Kombination aus plattformbasierten Schulungen zum Sicherheitsbewusstsein und administrativer Dokumentation wie Richtliniendokumentation und -aufzeichnungen, um den Abschluss der Schulung für alle Mitarbeiter in der organization nachzuverfolgen. Die vorgelegten Nachweise müssen zeigen, dass die Mitarbeiter die Schulung abgeschlossen haben, und dies sollte durch unterstützende Richtlinien/Verfahren gesichert werden, die die Anforderung des Sicherheitsbewusstseins darstellen.
Beispielbeweis: Schulung für neue Benutzer
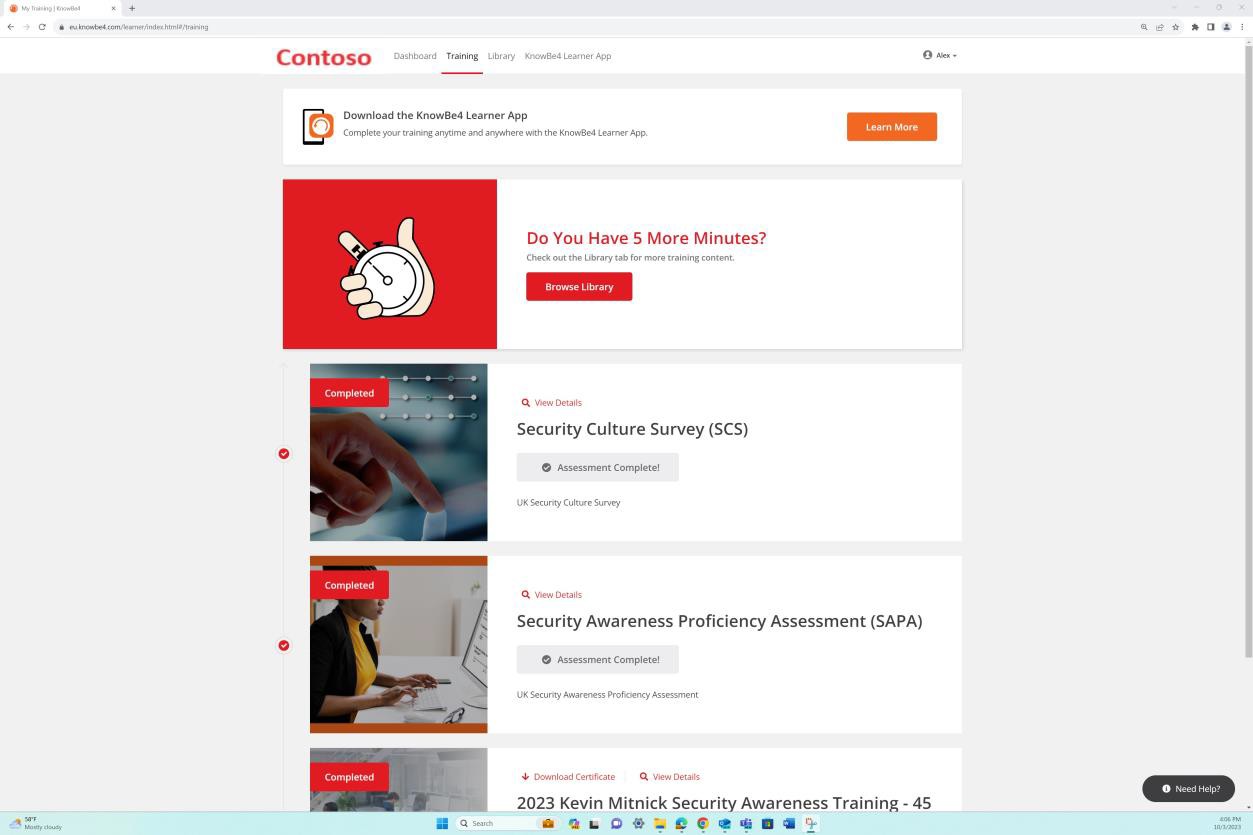
Der folgende Screenshot zeigt die Confluence-Plattform, die verwendet wird, um das Onboarding neuer Mitarbeiter nachzuverfolgen. Für den neuen Mitarbeiter wurde ein JIRA-Ticket mit seiner Zuweisung, Rolle, Abteilung usw. erhoben. Mit dem neuen Starterprozess wurde die Security Awareness-Schulung ausgewählt und dem Mitarbeiter zugewiesen, das bis zum Fälligkeitsdatum des 28. Februar 2023 abgeschlossen werden muss.

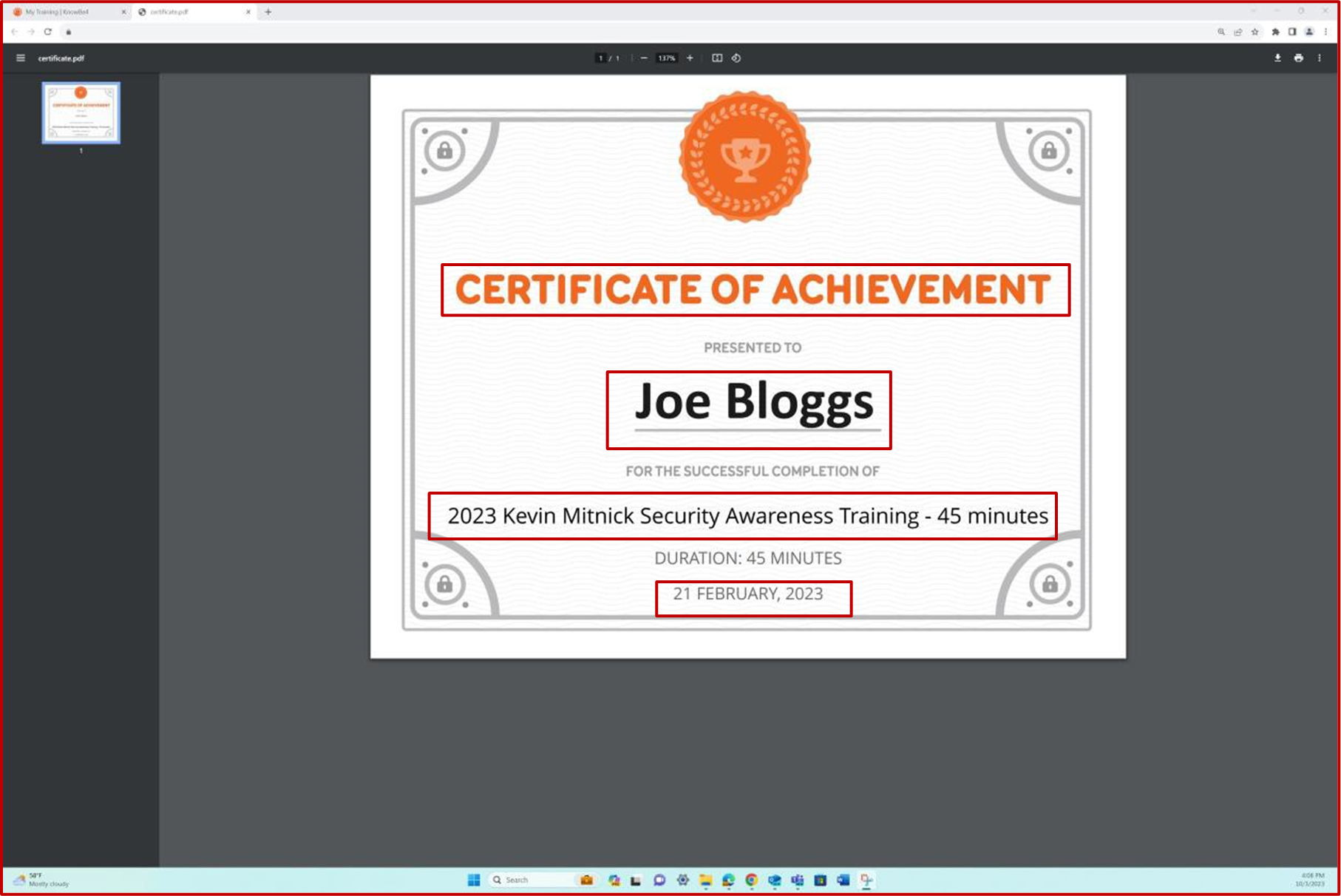
Der Screenshot zeigt das Von Knowb4 generierte Abschlusszertifikat nach erfolgreichem Abschluss der Schulung zum Sicherheitsbewusstsein durch den Mitarbeiter. Das Fertigstellungsdatum ist der 21. Februar 2023, der innerhalb des zugewiesenen Zeitraums liegt.
Absicht: Änderungen am Informationssystem.
Ziel dieses Unterpunkts ist es, sicherzustellen, dass adaptives Sicherheitsbewusstseinstraining immer dann eingeleitet wird, wenn wesentliche Änderungen an den Informationssystemen der organization auftreten. Die Änderungen können aufgrund von Softwareupdates, Architekturänderungen oder neuen gesetzlichen Anforderungen auftreten. Die aktualisierte Schulung stellt sicher, dass alle Mitarbeiter über die neuen Änderungen und die daraus resultierenden Auswirkungen auf Sicherheitsmaßnahmen informiert werden, sodass sie ihre Handlungen und Entscheidungen entsprechend anpassen können. Dieser proaktive Ansatz ist wichtig, um die digitalen Ressourcen der organization vor Sicherheitsrisiken zu schützen, die durch Systemänderungen entstehen können.
Richtlinien: Änderungen am Informationssystem.
Die meisten Organisationen nutzen eine Kombination aus plattformbasierten Schulungen zum Sicherheitsbewusstsein und administrativer Dokumentation wie Richtliniendokumentation und Datensätzen, um den Abschluss der Schulung für alle Mitarbeiter nachzuverfolgen. Die vorgelegten Nachweise müssen belegen, dass verschiedene Mitarbeiter die Schulung auf der Grundlage verschiedener Änderungen der systeme der organization abgeschlossen haben.
Beispielbeweis: Änderungen des Informationssystems.
Die nächsten Screenshots zeigen die Zuweisung von Security Awareness-Schulungen zu verschiedenen Mitarbeitern und zeigen, dass Phishing-Simulationen stattfinden.
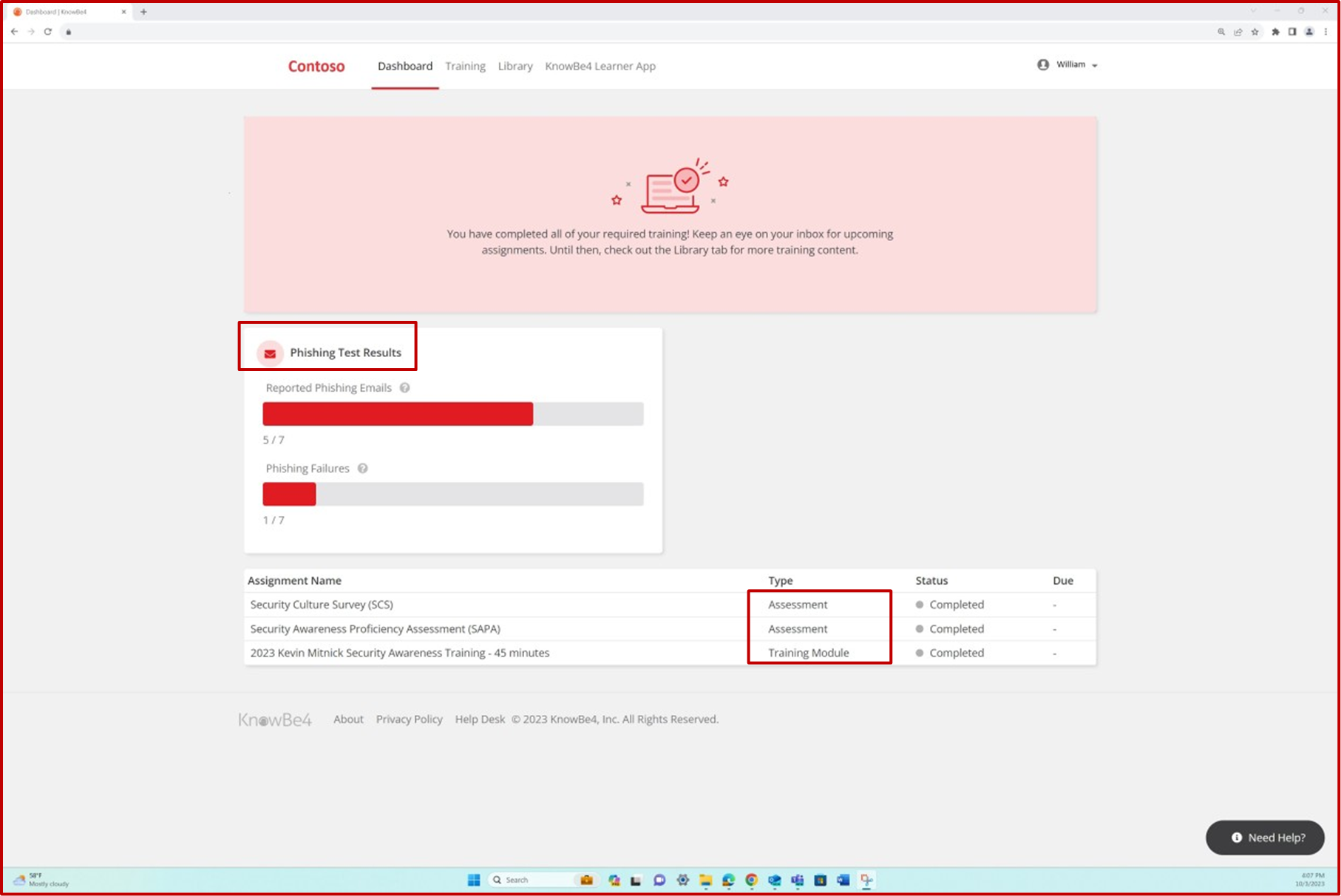
Die Plattform wird verwendet, um neues Training zuzuweisen, wenn eine Systemänderung eintritt oder ein Test fehlgeschlagen ist.
Absicht: Häufigkeit des Bewusstseinstrainings.
Ziel dieses Unterpunkts ist es, eine organization-spezifische Häufigkeit für regelmäßige Sicherheitsschulungen zu definieren. Dies kann jährlich, halbjährlicher oder in einem anderen vom organization festgelegten Intervall geplant werden. Durch die Festlegung einer Häufigkeit stellt die organization sicher, dass die Benutzer regelmäßig über die sich entwickelnde Bedrohungslandschaft sowie über neue Schutzmaßnahmen und Richtlinien informiert werden. Dieser Ansatz kann dazu beitragen, ein hohes Maß an Sicherheitsbewusstsein bei allen Benutzern aufrechtzuerhalten und frühere Schulungskomponenten zu stärken.
Richtlinien: Häufigkeit des Bewusstseinstrainings.
Die meisten Organisationen verfügen über eine administrative Dokumentation und/oder eine technische Lösung, um die Anforderung und das Verfahren für Schulungen zum Sicherheitsbewusstsein zu skizzieren/umzusetzen sowie die Häufigkeit der Schulung zu definieren. Die vorgelegten Nachweise sollten zeigen, dass verschiedene Bewusstseinsschulungen innerhalb des definierten Zeitraums abgeschlossen wurden und dass ein von Ihrer organization definierter Zeitraum vorhanden ist.
Beispielbeweis: Häufigkeit des Bewusstseinstrainings.
Die folgenden Screenshots zeigen Momentaufnahmen der Dokumentation zur Sicherheitsbewusstseinsrichtlinie, die vorhanden ist und verwaltet wird. Die Richtlinie erfordert, dass alle Mitarbeiter der organization eine Schulung zum Sicherheitsbewusstsein erhalten, wie im Bereichsbereich der Richtlinie beschrieben. Die Ausbildung muss jährlich von der zuständigen Abteilung zugewiesen und absolviert werden.
Laut Richtliniendokument müssen alle Mitarbeiter der organization drei Kurse (eine Schulung und zwei Bewertungen) jährlich und innerhalb von zwanzig Tagen nach dem Einsatz absolvieren. Die Kurse müssen per E-Mail versendet und über KnowBe4 zugewiesen werden.
Das bereitgestellte Beispiel zeigt nur Momentaufnahmen der Richtlinie. Beachten Sie, dass erwartet wird, dass das vollständige Richtliniendokument übermittelt wird.

Der zweite Screenshot zeigt die Fortsetzung der Richtlinie und zeigt den Abschnitt des Dokuments, der die jährliche Schulungsanforderung vorschreibt, und zeigt, dass die organization definierten Häufigkeit von Sensibilisierungsschulungen auf jährlich festgelegt wird.

Die nächsten beiden Screenshots zeigen den erfolgreichen Abschluss der zuvor erwähnten Trainingsbewertungen. Die Screenshots stammen von zwei verschiedenen Mitarbeitern.
Absicht: Dokumentation und Überwachung.
Das Ziel dieses Unterpunkts besteht darin, sorgfältige Aufzeichnungen über die Teilnahme jedes Benutzers an Schulungen für Sicherheitsbewusstsein zu erstellen, zu verwalten und zu überwachen. Diese Datensätze sollten über einen organization definierten Zeitraum aufbewahrt werden. Diese Dokumentation dient als überprüfbarer Pfad für die Einhaltung von Vorschriften und internen Richtlinien. Die Überwachungskomponente ermöglicht es dem organization, die Wirksamkeit der
Schulung, Identifizieren von Verbesserungsbereichen und Verständnis der Benutzerbindungsebenen. Durch die Aufbewahrung dieser Datensätze über einen definierten Zeitraum kann die organization die langfristige Effektivität und Compliance nachverfolgen.
Richtlinien: Dokumentation und Überwachung.
Die Nachweise, die für das Sicherheitsbewusstseinstraining bereitgestellt werden können, hängen davon ab, wie die Schulung auf organization Ebene durchgeführt wird. Dies kann umfassen, ob das Training über eine Plattform oder intern auf der Grundlage eines internen Prozesses durchgeführt wird. Die vorgelegten Nachweise müssen zeigen, dass historische Aufzeichnungen von Schulungen, die für alle Benutzer über einen Bestimmten Zeitraum abgeschlossen wurden, vorhanden sind und wie dies nachverfolgt wird.
Beispielbeweis: Dokumentation und Überwachung.
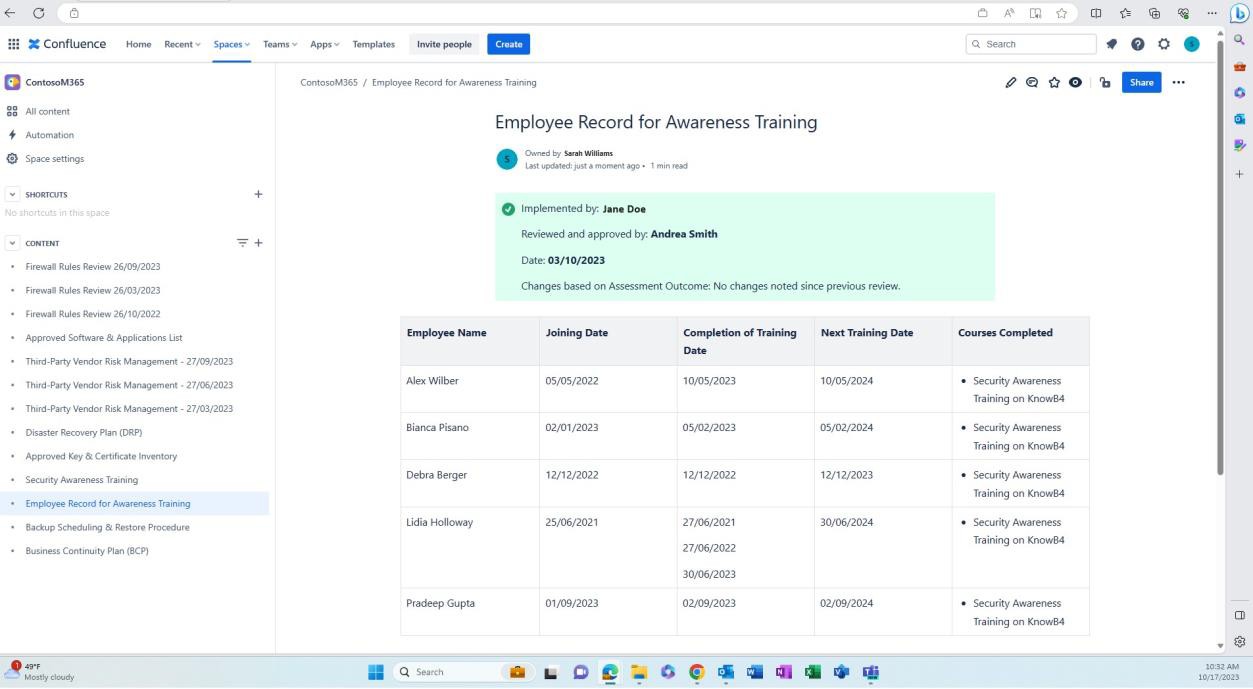
Der nächste Screenshot zeigt den verlaufsbezogenen Trainingsdatensatz für jeden Benutzer, einschließlich des Beitrittsdatums, des Abschlusses der Schulung und des Zeitpunkts, an dem die nächste Schulung geplant ist. Die Bewertung dieses Dokuments wird in regelmäßigen Abständen und mindestens einmal im Jahr durchgeführt, um sicherzustellen, dass Schulungsdatensätze zum Sicherheitsbewusstsein für jeden Mitarbeiter auf dem neuesten Stand gehalten werden.
Schutz vor Schadsoftware/Antischadsoftware
Schadsoftware stellt ein erhebliches Risiko für Organisationen dar, die je nach Den Merkmalen der Schadsoftware die Auswirkungen auf die Sicherheit der Betriebsumgebung variieren können. Bedrohungsakteure haben erkannt, dass Schadsoftware erfolgreich monetarisiert werden kann, was durch das Wachstum von Malware-Angriffen im Ransomware-Stil realisiert wurde. Malware kann auch verwendet werden, um einen Eingangspunkt für einen Bedrohungsakteur bereitzustellen, um eine Umgebung zu kompromittieren, um vertrauliche Daten zu stehlen, d. h. Remotezugriff Trojaner/Rootkits. Organisationen müssen daher geeignete Mechanismen zum Schutz vor diesen Bedrohungen implementieren. Schutzmaßnahmen, die verwendet werden können, sind Virenschutz(AV)/Endpoint Detection and Response (EDR)/Endpoint Detection and Protection Response (EDPR)/heuristisches Scannen mit künstlicher Intelligenz (KI). Wenn Sie eine andere Technik zur Minderung des Risikos von Schadsoftware bereitgestellt haben, teilen Sie dem Zertifizierungsanalysten mit, wer gerne untersuchen kann, ob dies der Absicht entspricht oder nicht.
Steuerelement Nr. 2
HARTER FEHLER
Stellen Sie Beweise für Folgendes bereit:
Die Antischadsoftwarelösung der Organisationen ist aktiv und für alle Systemkomponenten der Stichprobe aktiviert.
Wenn Sie eine herkömmliche Antivirenlösung verwenden, MUSS diese konfiguriert werden:
Die Überprüfung bei Zugriff ist aktiviert, und Signaturen sind innerhalb von 1 Tag auf dem neuesten Stand.
Blockiert automatisch Schadsoftware oder Warnungen zur sofortigen Selektierung, wenn Schadsoftware erkannt wird.
ODER Wenn Sie NGAV (Endpoint Detection and Response/Next-Generation Antivirus) verwenden, dann:
MUSS konfiguriert werden:
um regelmäßige Überprüfungen durchzuführen,
, um Überwachungsprotokolle zu generieren, und
ständig auf dem neuesten Stand zu halten und über Selbstlernfähigkeiten zu verfügen.
MUSS konfiguriert werden:
, um bekannte Schadsoftware zu blockieren, und
um neue Malware-Varianten basierend auf Makroverhalten zu identifizieren und zu blockieren sowie über vollständige Safelist-Funktionen zu verfügen.
Absicht: Überprüfung bei Zugriff
Dieser Unterpunkt soll überprüfen, ob die Antischadsoftware in allen Systemkomponenten der Stichprobe installiert ist und aktiv Zugriffsüberprüfungen ausführt. Das Steuerelement schreibt außerdem vor, dass die Signaturdatenbank der Antischadsoftware-Lösung innerhalb eines Tageszeitrahmens auf dem neuesten Stand ist. Eine aktuelle Signaturdatenbank ist entscheidend, um die neuesten Schadsoftwarebedrohungen zu identifizieren und zu mindern und so sicherzustellen, dass die Systemkomponenten angemessen geschützt sind.
Richtlinien: Überprüfung bei Zugriff**.**
Um zu zeigen, dass eine aktive instance von AV in der bewerteten Umgebung ausgeführt wird, stellen Sie einen Screenshot für jedes Gerät in dem mit Ihrem Analysten vereinbarten Beispielsatz bereit, der die Verwendung von Antischadsoftware unterstützt. Der Screenshot sollte zeigen, dass die Antischadsoftware ausgeführt wird und dass die Antischadsoftware aktiv ist. Wenn es eine zentralisierte Verwaltungskonsole für Antischadsoftware gibt, können Beweise aus dem Verwaltungskonsole bereitgestellt werden. Stellen Sie außerdem sicher, dass Sie einen Screenshot bereitstellen, der zeigt, dass die erfassten Geräte verbunden sind und funktionieren.
Beispielbeweis: Überprüfung bei Zugriff**.**
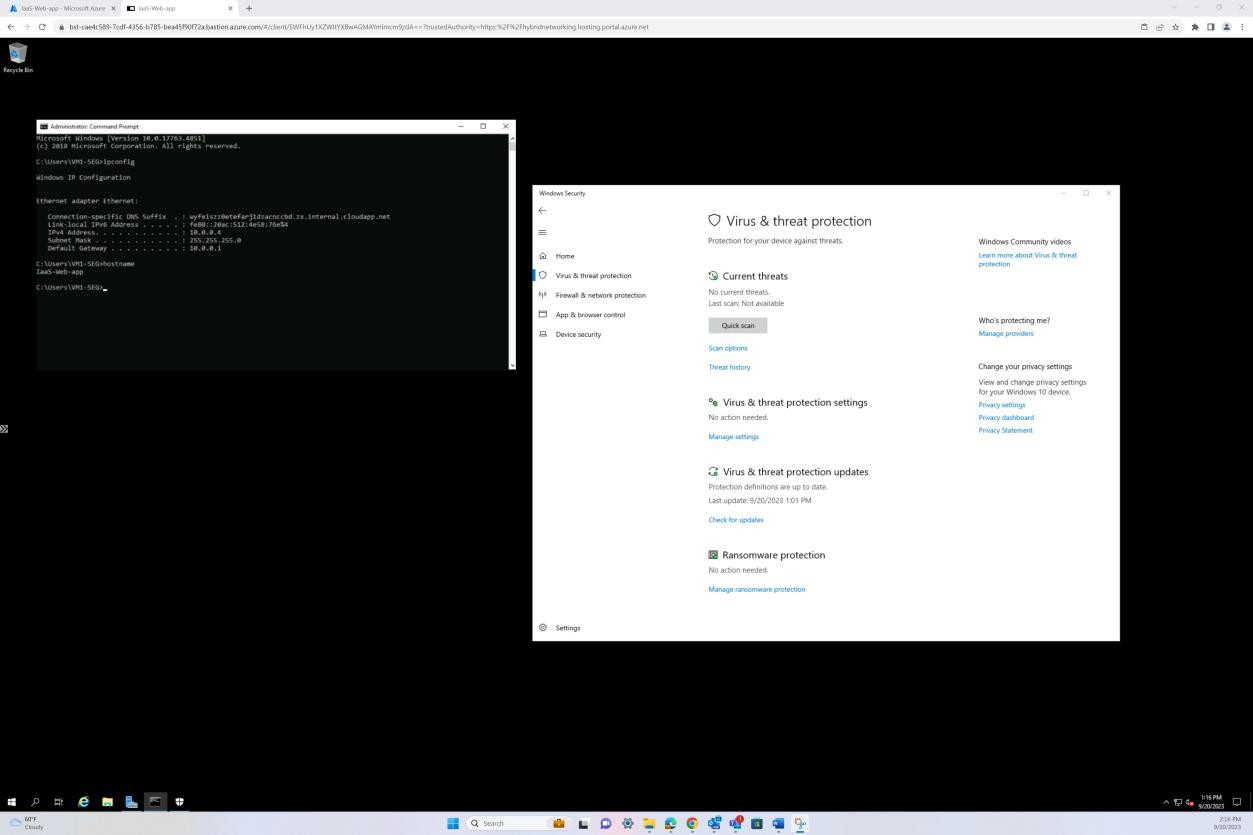
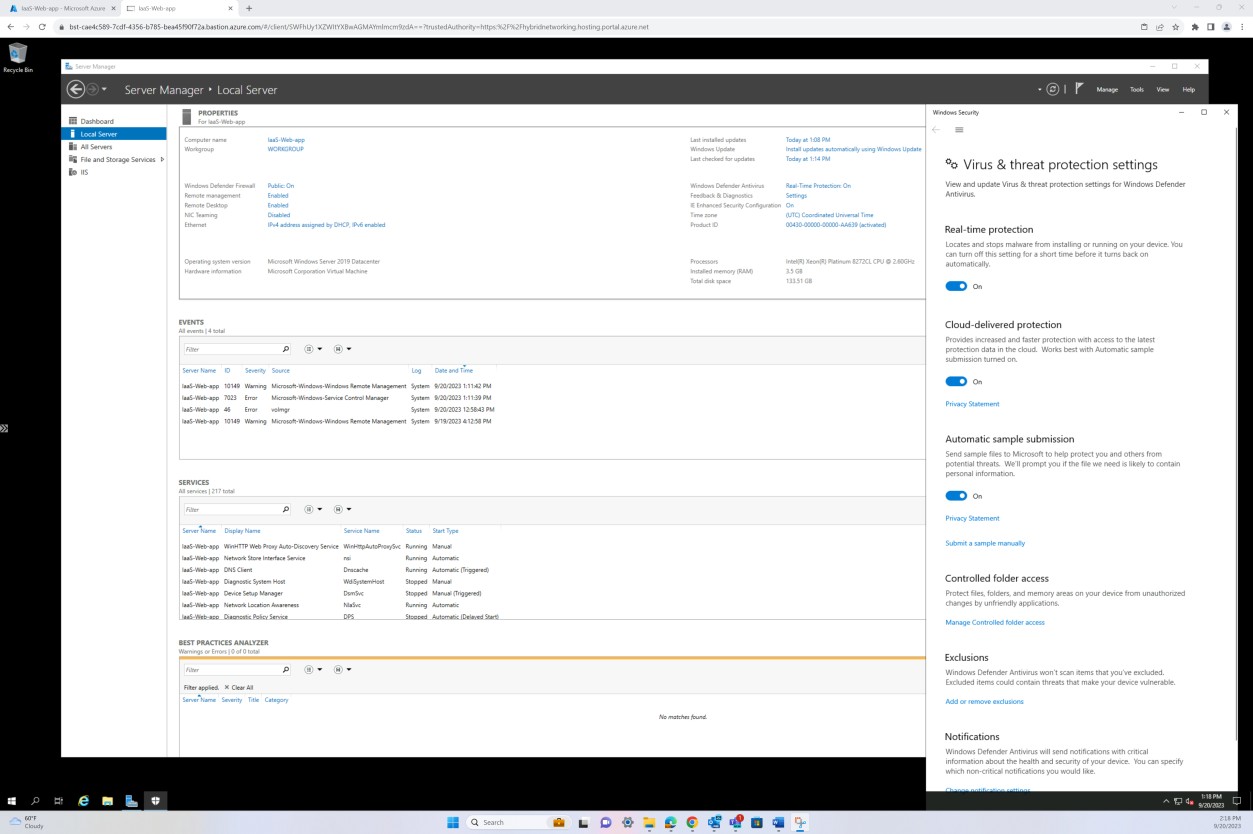
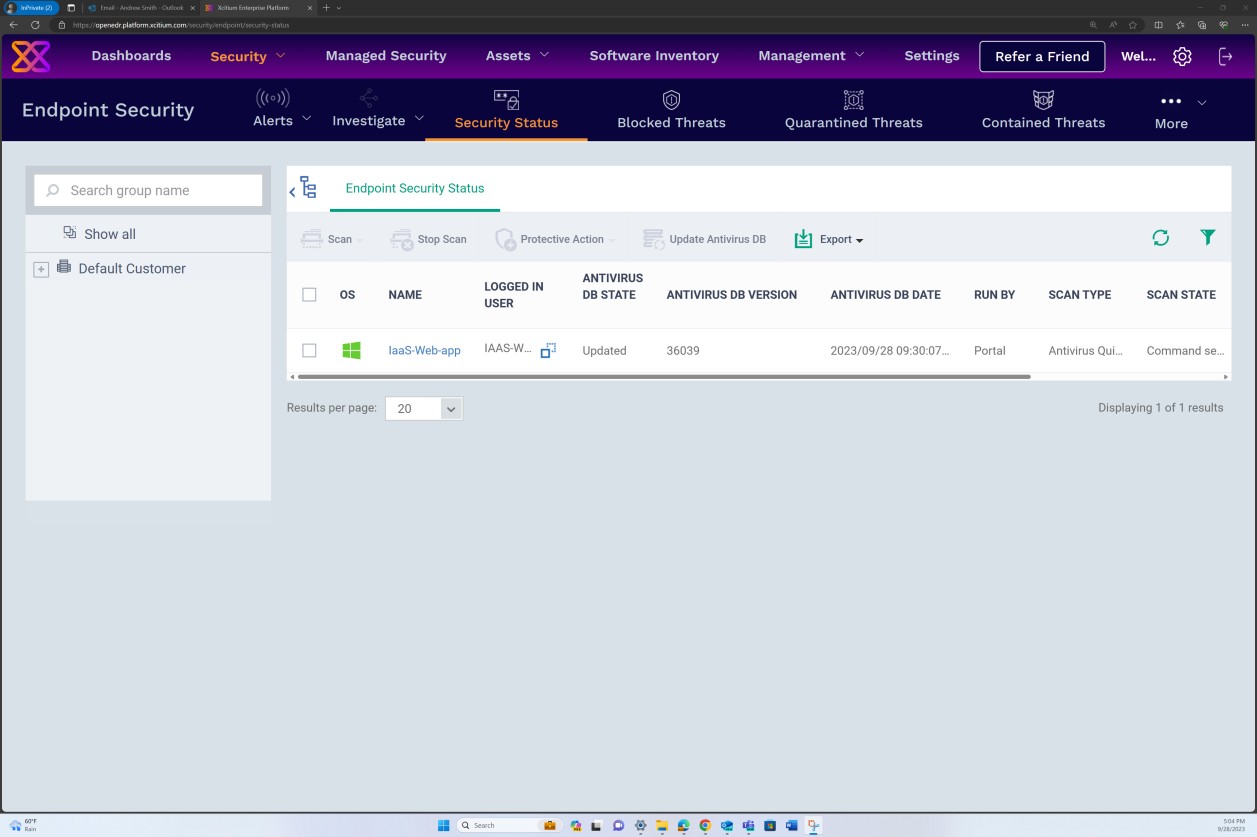
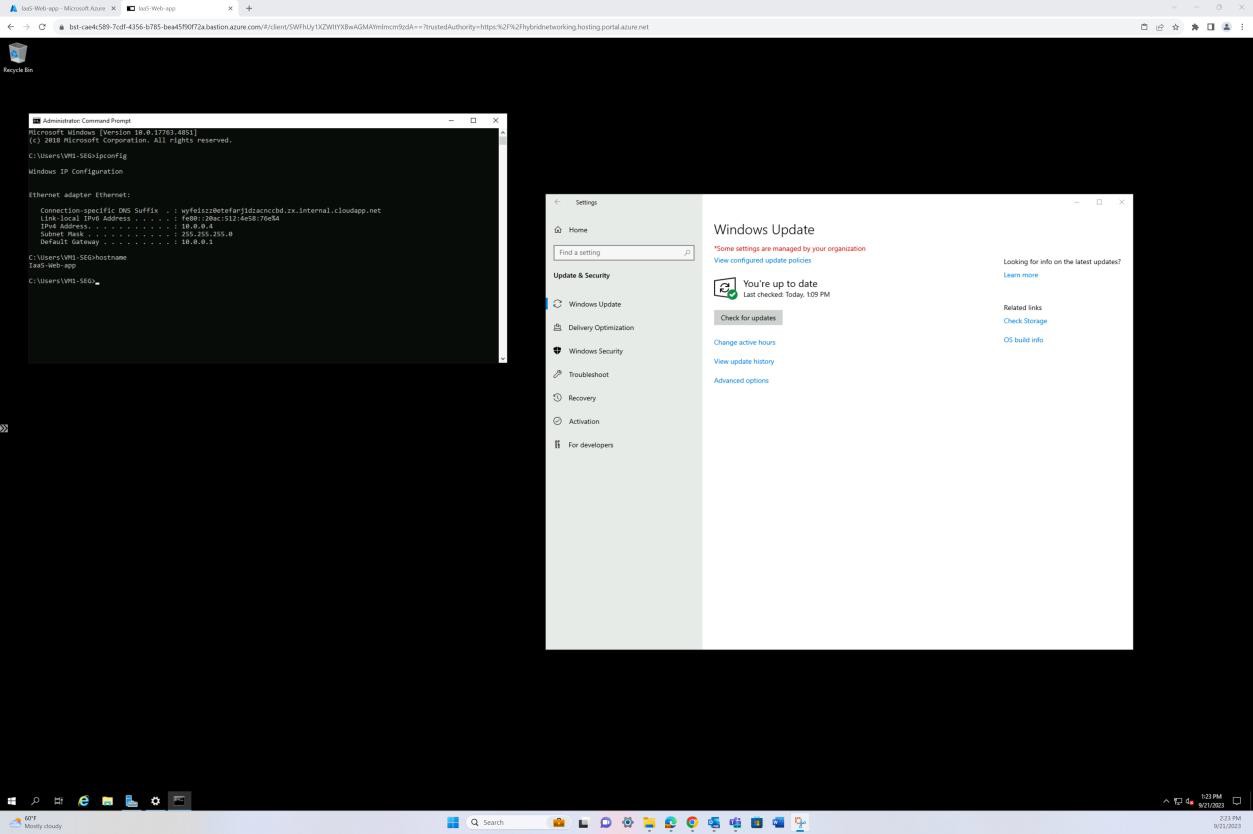
Der folgende Screenshot wurde von einem Windows Server Gerät erstellt und zeigt, dass "Microsoft Defender" für den Hostnamen "IaaS-Web-app" aktiviert ist.
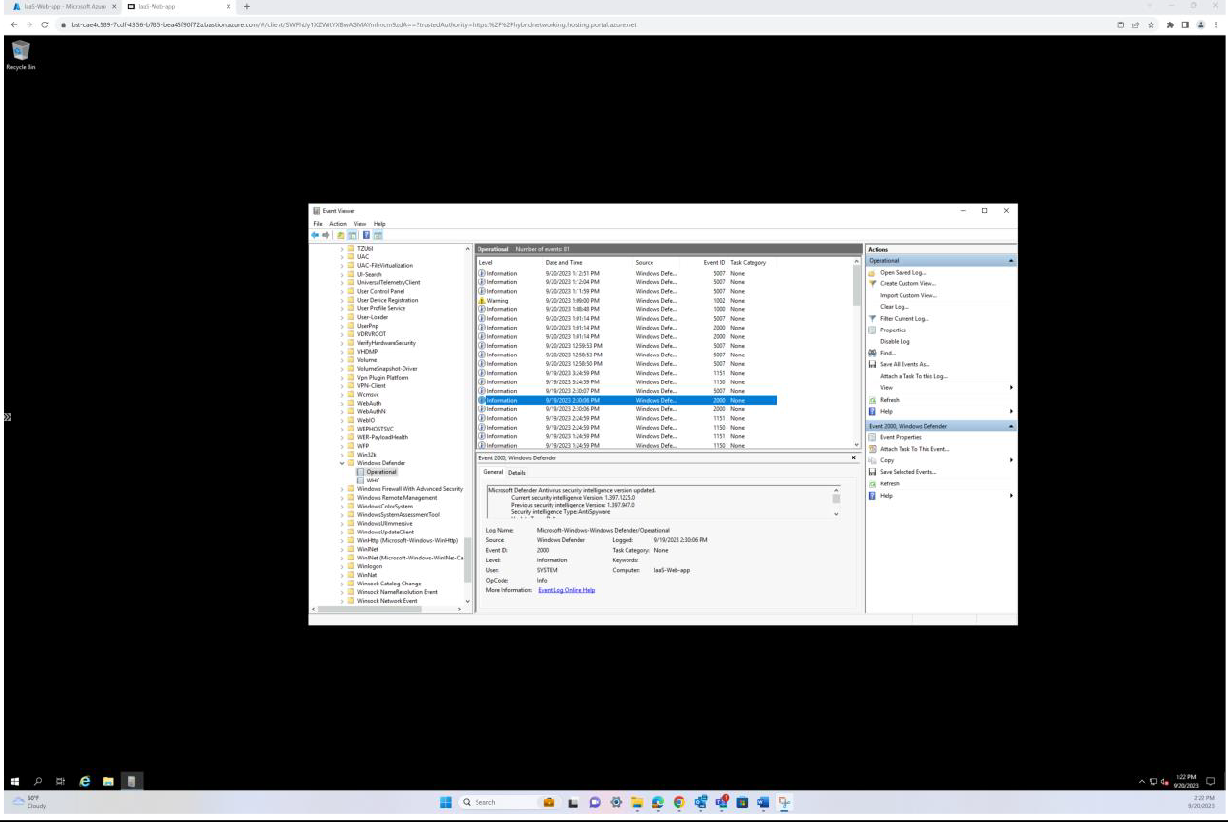
Der nächste Screenshot wurde von einem Windows Server Gerät erstellt und zeigt, Microsoft Defender Version der Sicherheitsintelligenz von Antimalware das Protokoll aus der Windows-Ereignisanzeige aktualisiert hat. Dies zeigt die neuesten Signaturen für den Hostnamen "IaaS-Web-app".
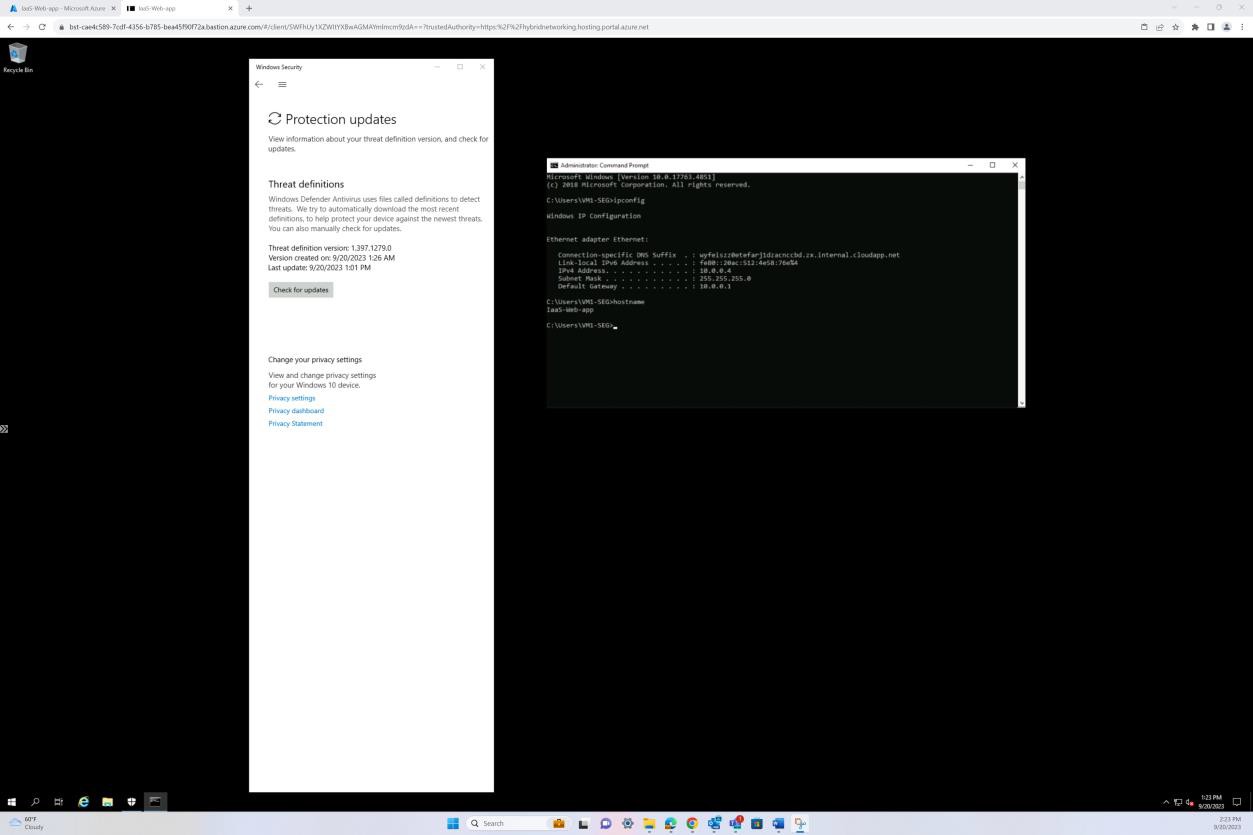
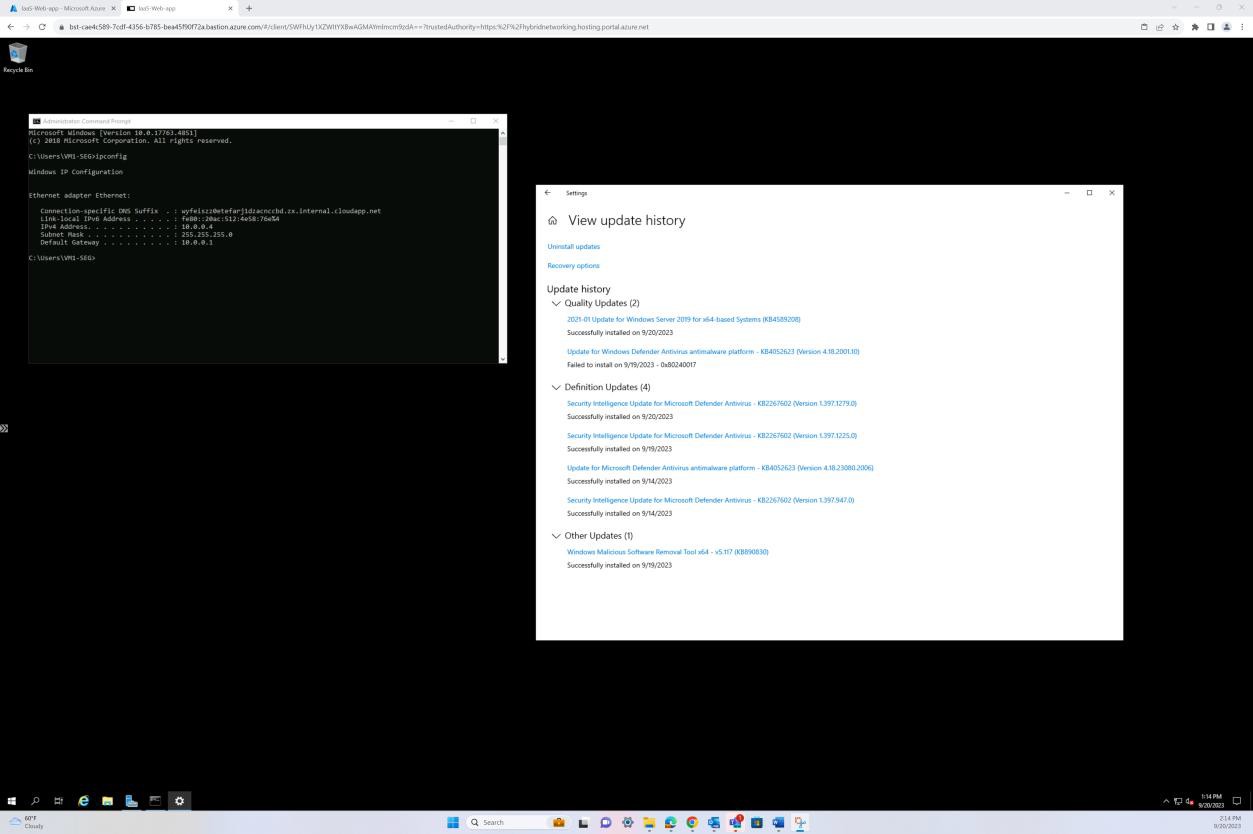
Dieser Screenshot wurde von einem Windows Server Gerät mit Microsoft Defender Updates für den Antischadsoftwareschutz erstellt. Dies zeigt deutlich die Versionen der Bedrohungsdefinition, die version erstellt unter und das letzte Update, um zu veranschaulichen, dass Schadsoftwaredefinitionen für den Hostnamen "IaaS-Web-app" auf dem neuesten Stand sind.
Absicht: Anti-Malware-Blöcke.
Der Zweck dieses Unterpunkts besteht darin, zu bestätigen, dass die Antischadsoftware so konfiguriert ist, dass sie Bei der Erkennung automatisch Schadsoftware blockiert oder Warnungen generiert und erkannte Schadsoftware in einen sicheren Quarantänebereich verschoben wird. Dadurch kann sichergestellt werden, dass sofortige Maßnahmen ergriffen werden, wenn eine Bedrohung erkannt wird, das Sicherheitsrisikofenster reduziert und ein starker Sicherheitsstatus des Systems beibehalten wird.
Richtlinien: Anti-Malware-Blöcke.
Stellen Sie einen Screenshot für jedes Gerät im Beispiel bereit, das die Verwendung von Antischadsoftware unterstützt. Der Screenshot sollte zeigen, dass Antischadsoftware ausgeführt wird und so konfiguriert ist, dass Schadsoftware automatisch blockiert, warnungen oder isoliert und warnungen werden.
Beispielbeweis: Anti-Malware-Blöcke.
Der nächste Screenshot zeigt, dass der Host "IaaS-Web-app" mit Echtzeitschutz als ON für Microsoft Defender Antimalware konfiguriert ist. Wie die Einstellung sagt, wird dadurch die Installation oder Ausführung der Schadsoftware auf dem Gerät verhindert.
Absicht: EDR/NGAV
Dieser Unterpunkt zielt darauf ab, zu überprüfen, ob Endpoint Detection and Response (EDR) oder Antivirus der nächsten Generation (NGAV) aktiv regelmäßige Überprüfungen für alle erfassten Systemkomponenten durchführen; Überwachungsprotokolle werden zum Nachverfolgen von Scanaktivitäten und -ergebnissen generiert. die Scanlösung wird kontinuierlich aktualisiert und verfügt über selbstlernfähige Funktionen, um sich an neue Bedrohungslandschaften anzupassen.
Richtlinien: EDR/NGAV
Stellen Sie einen Screenshot ihrer EDR/NGAV-Lösung bereit, der zeigt, dass alle Agents aus den stichprobenierten Systemen berichte und zeigen, dass ihre status aktiv sind.
Beispielbeweis: EDR/NGAV
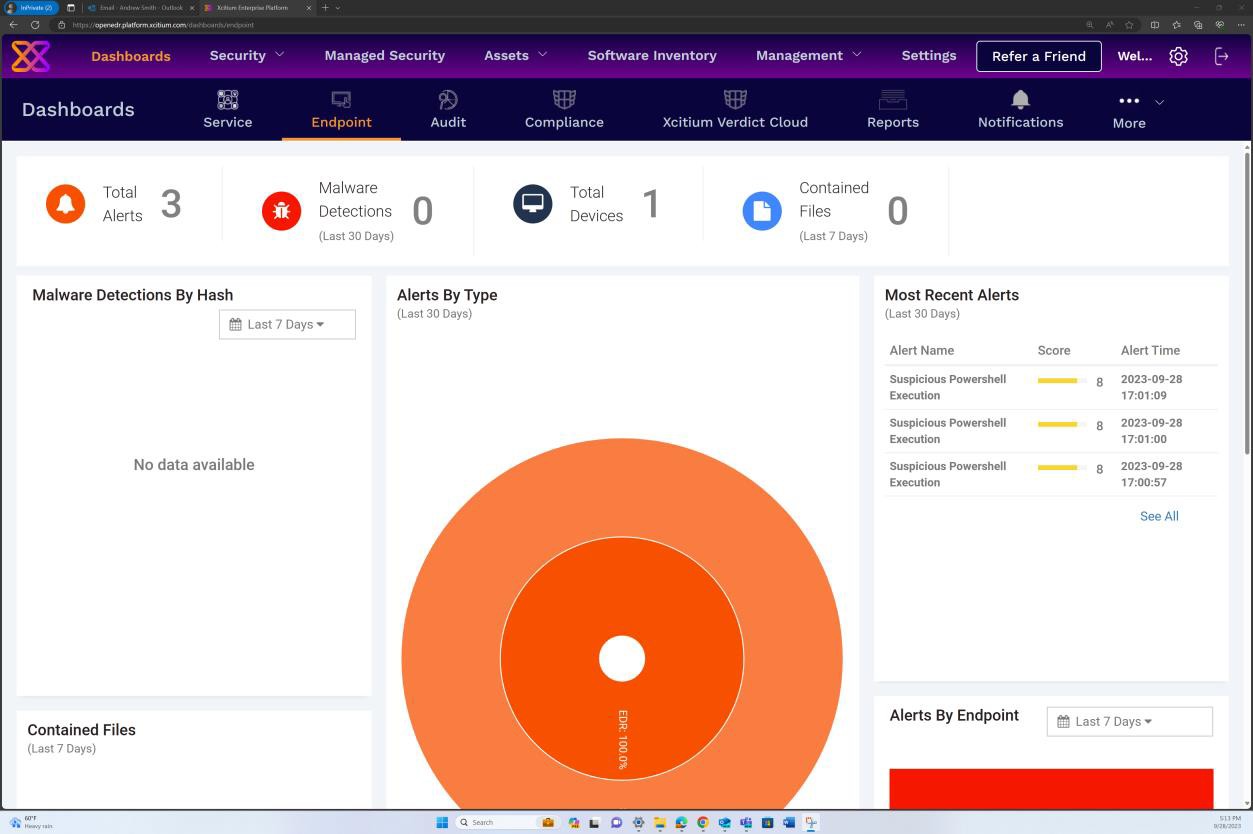
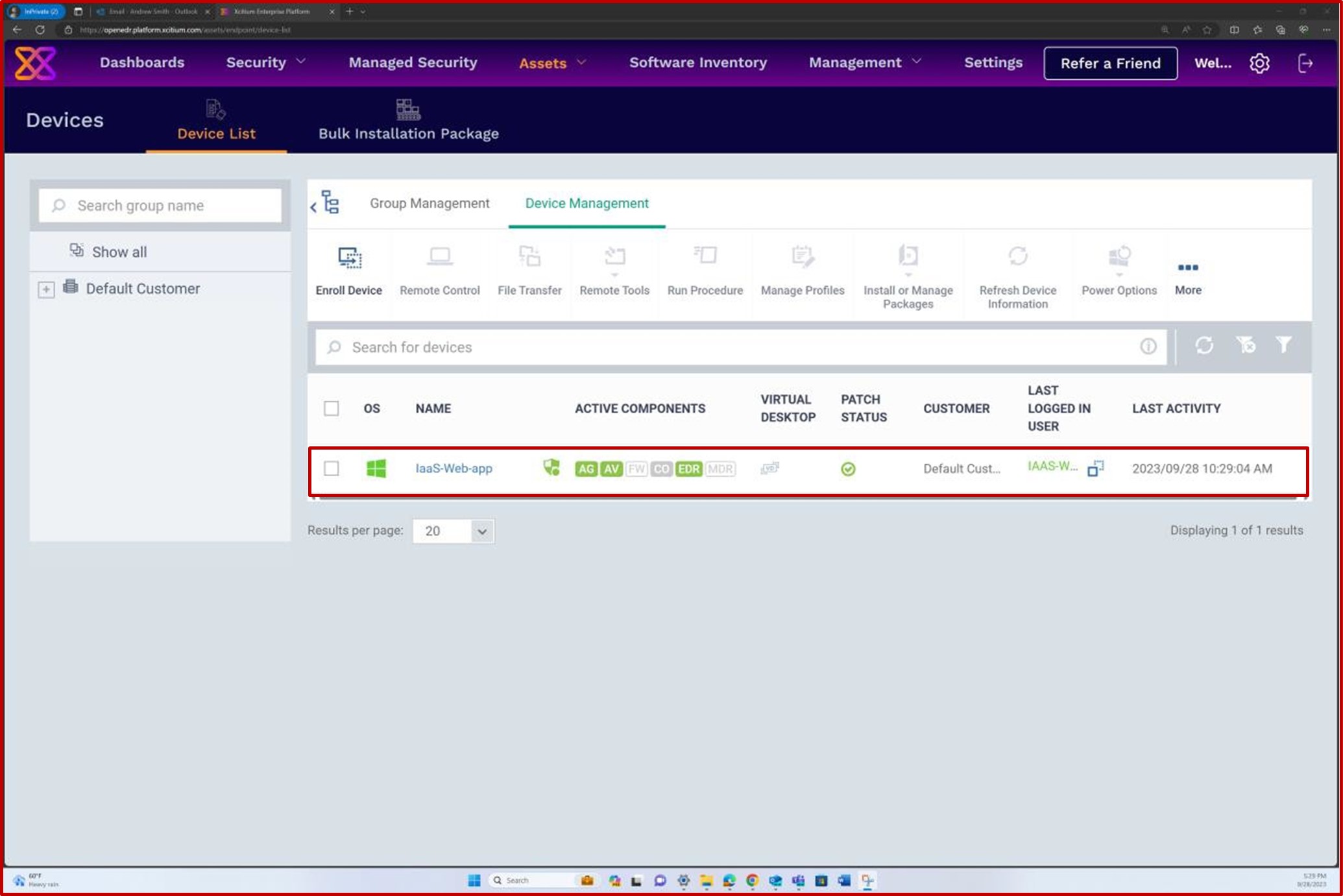
Der nächste Screenshot der OpenEDR-Lösung zeigt, dass ein Agent für den Host "IaaS-Web-app" aktiv ist und berichte.
Der nächste Screenshot der OpenEDR-Lösung zeigt, dass die Echtzeitüberprüfung aktiviert ist.
Der nächste Screenshot zeigt, dass Warnungen basierend auf Verhaltensmetriken generiert werden, die in Echtzeit vom auf Systemebene installierten Agent abgerufen wurden.
Die nächsten Screenshots der OpenEDR-Lösung veranschaulichen die Konfiguration und Generierung von Überwachungsprotokollen und Warnungen. Die zweite Abbildung zeigt, dass die Richtlinie aktiviert ist und die Ereignisse konfiguriert sind.
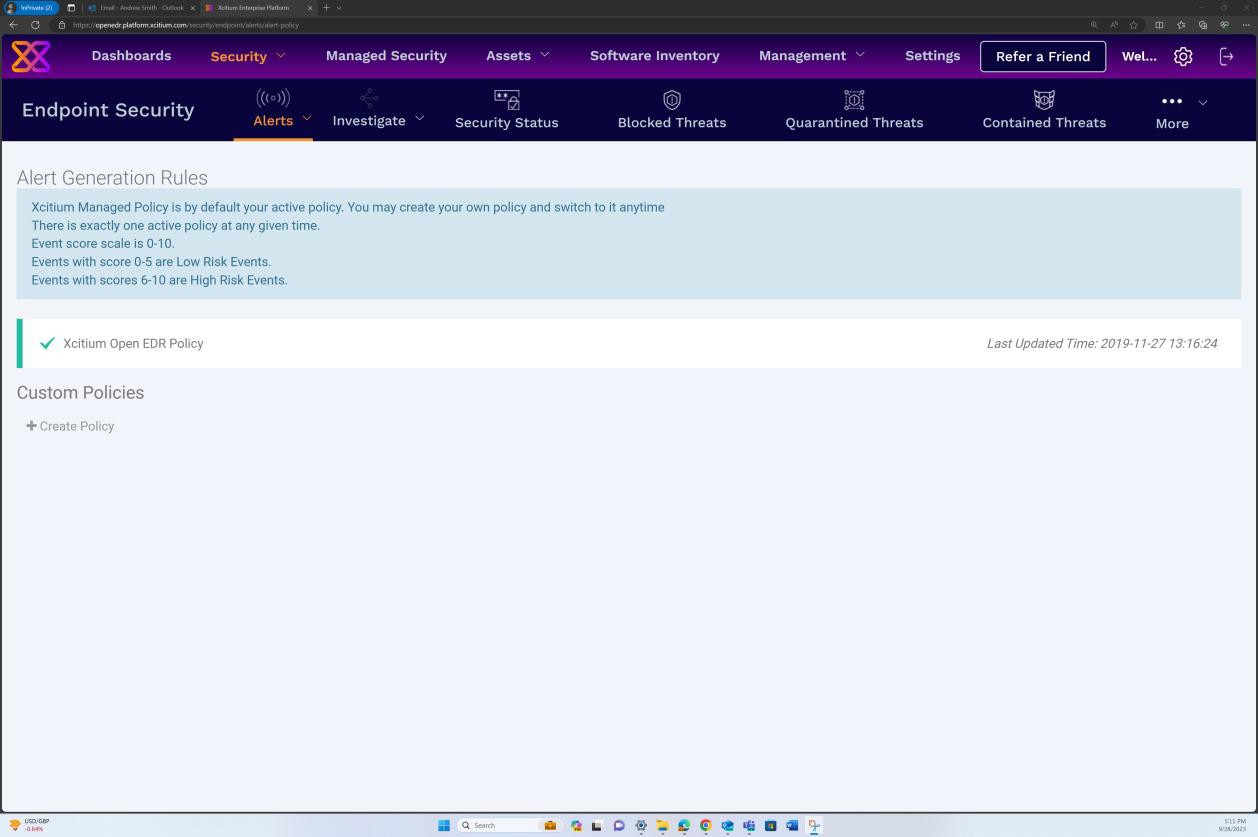
Der nächste Screenshot der OpenEDR-Lösung zeigt, dass die Lösung ständig auf dem neuesten Stand gehalten wird.
Absicht: EDR/NGAV
Der Schwerpunkt dieses Unterpunkts besteht darin, sicherzustellen, dass EDR/NGAV die Möglichkeit hat, bekannte Schadsoftware automatisch zu blockieren und neue Schadsoftwarevarianten basierend auf Makroverhalten zu identifizieren und zu blockieren. Außerdem wird sichergestellt, dass die Lösung über vollständige Genehmigungsfunktionen verfügt, sodass der organization vertrauenswürdige Software zulassen kann, während alle anderen Blockiert werden, wodurch eine zusätzliche Sicherheitsebene hinzugefügt wird.
Richtlinien: EDR/NGAV
Abhängig von der Art der verwendeten Lösung können Beweise bereitgestellt werden, die die Konfigurationseinstellungen der Lösung zeigen und dass die Lösung über Machine Learning-/Heuristik-Funktionen verfügt und so konfiguriert ist, dass Schadsoftware bei der Erkennung blockiert wird. Wenn die Konfiguration standardmäßig für die Lösung implementiert ist, muss dies von der Herstellerdokumentation überprüft werden.
Beispielbeweis: EDR/NGAV
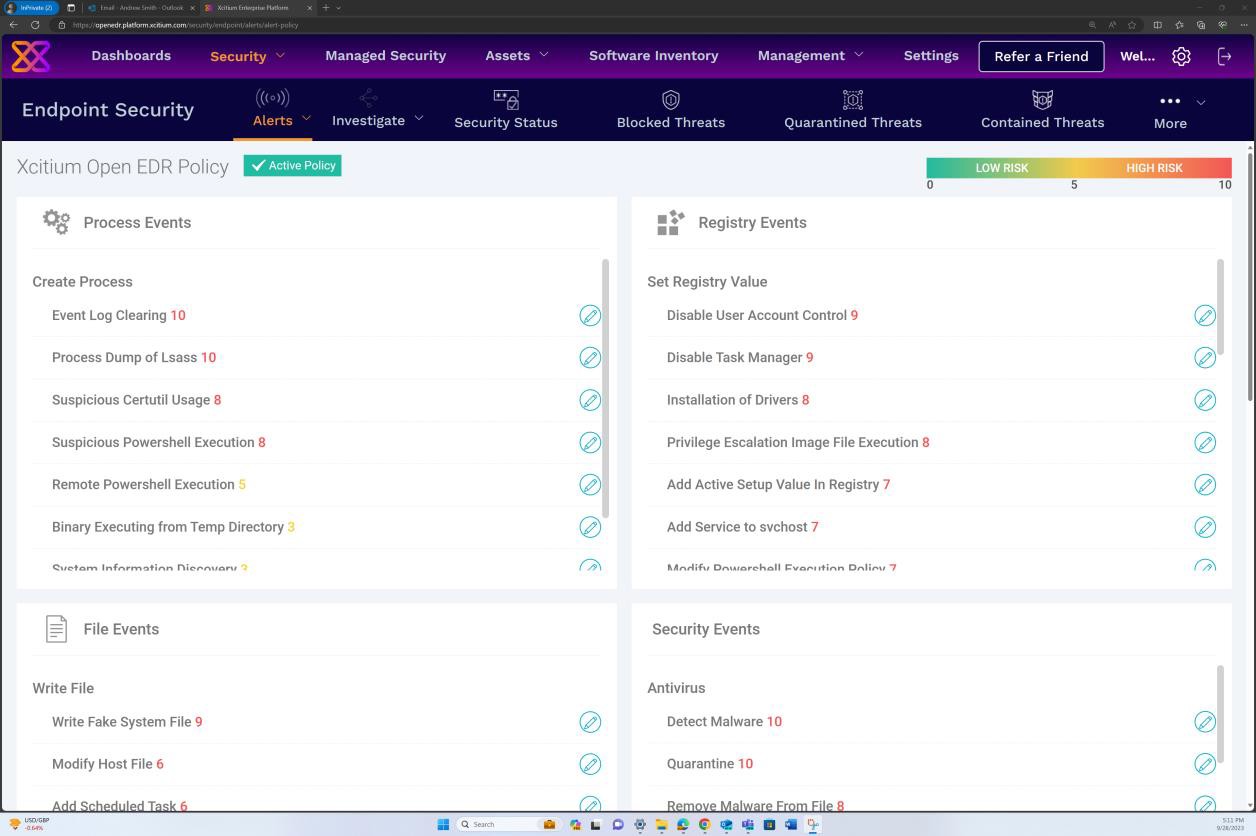
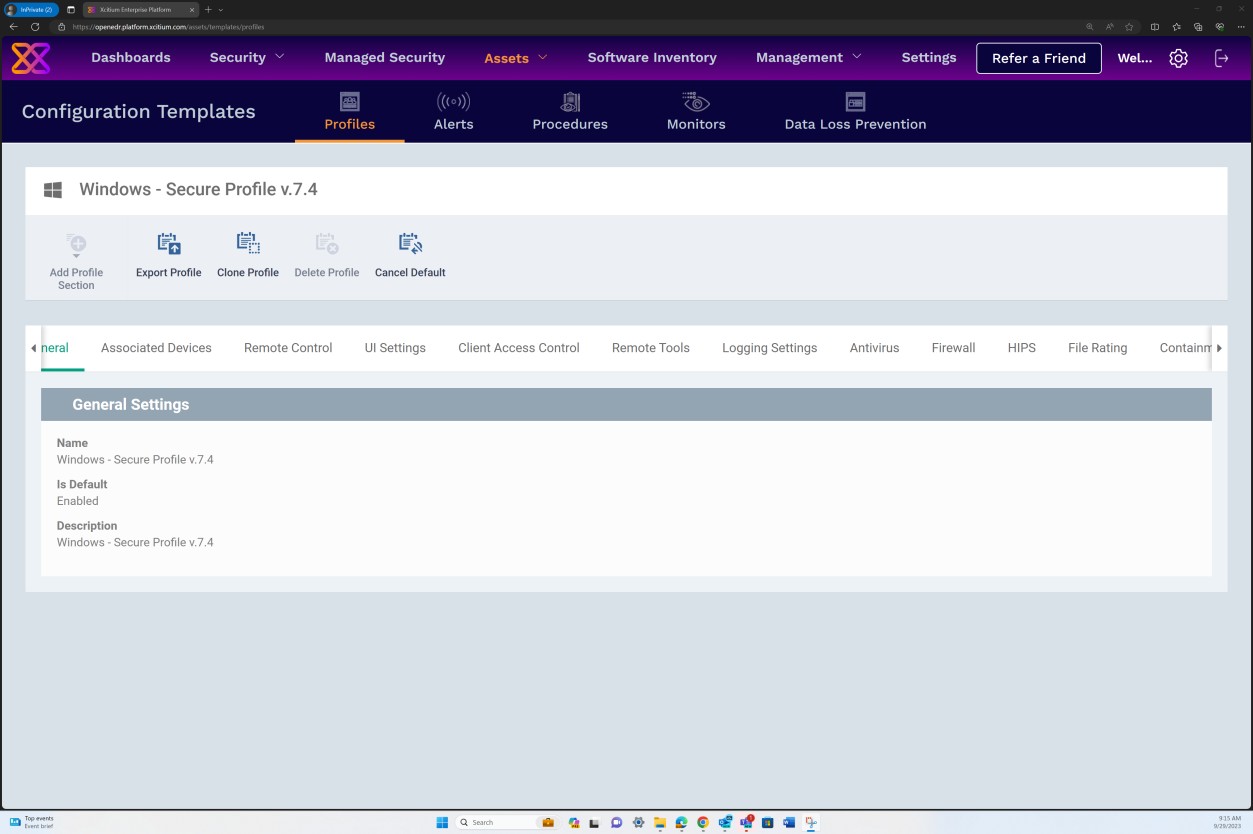
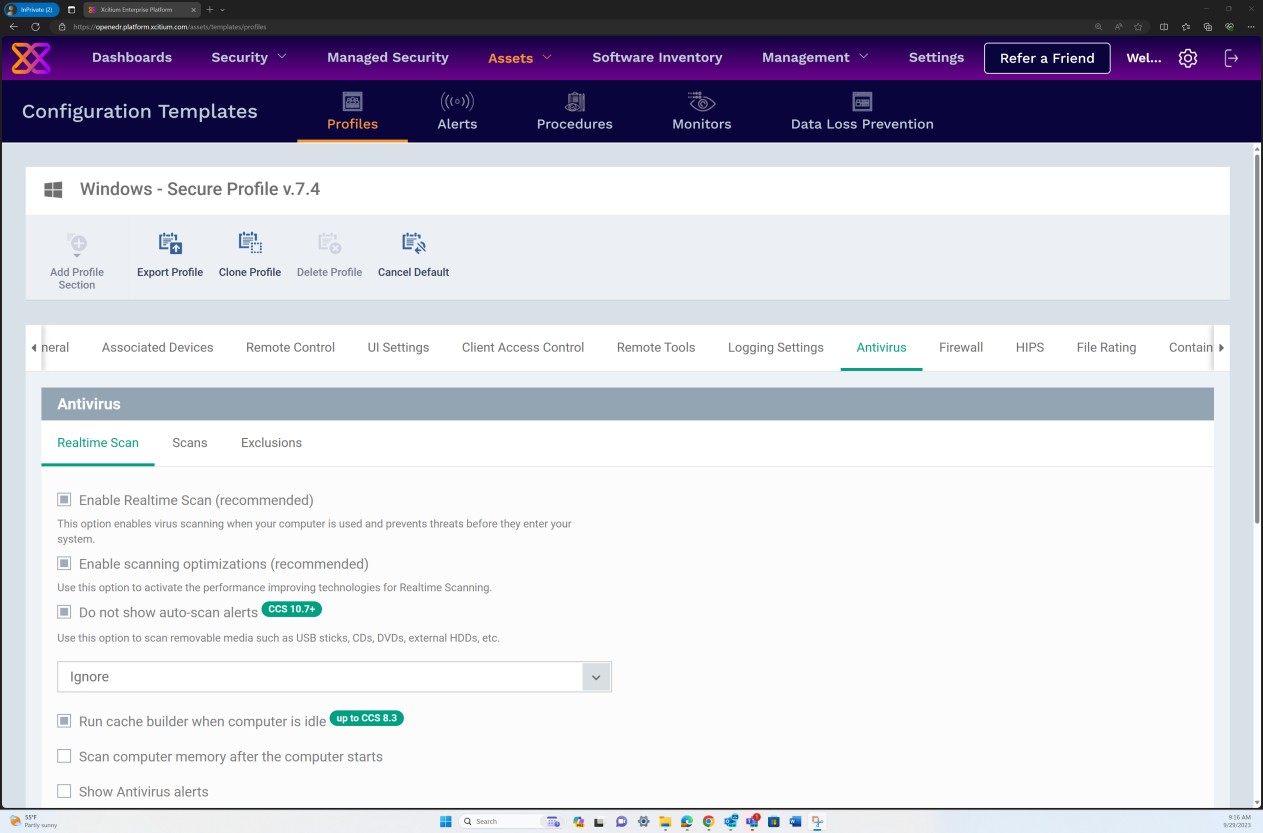
Die nächsten Screenshots der OpenEDR-Lösung zeigen, dass ein sicheres Profil v7.4 konfiguriert ist, um Echtzeitscans zu erzwingen, Schadsoftware zu blockieren und quarantänen.
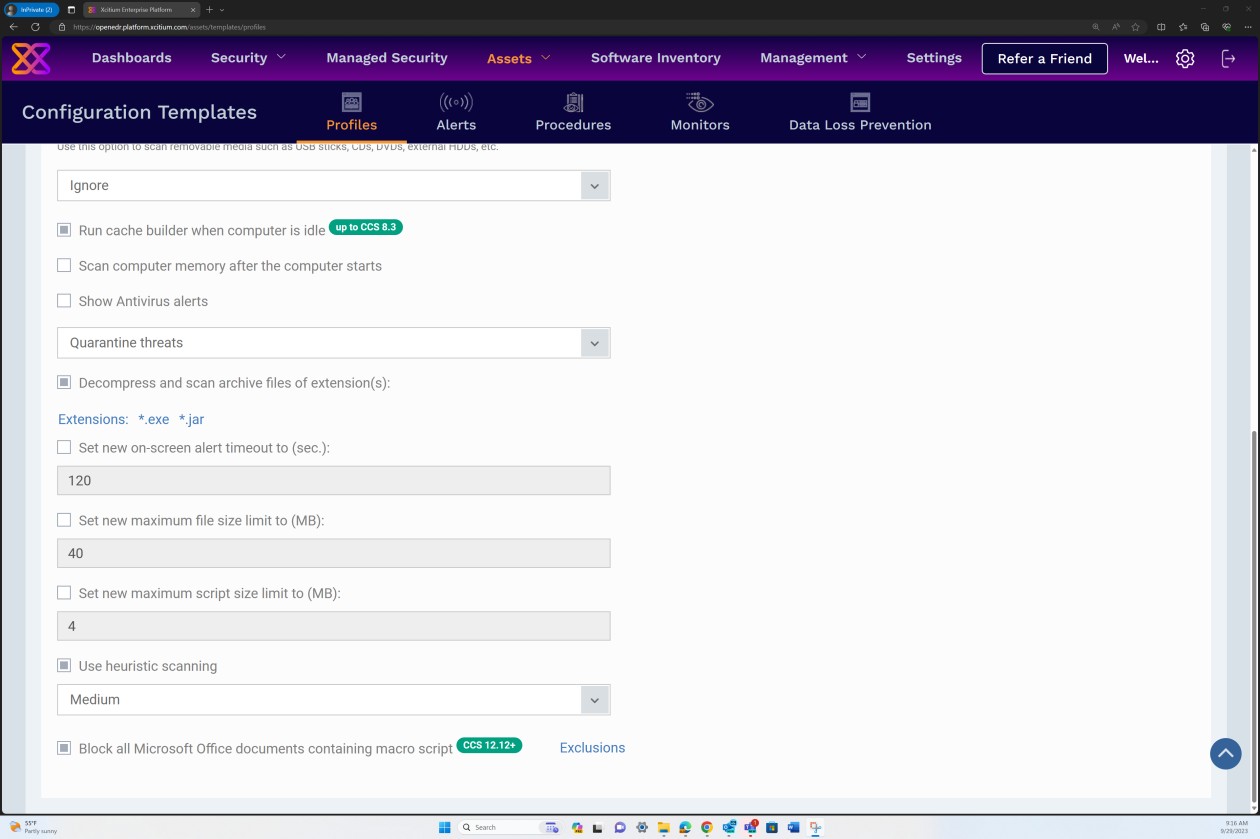
Die nächsten Screenshots der Konfiguration des sicheren Profils v7.4 zeigen, dass die Lösung sowohl die "Echtzeitüberprüfung" basierend auf einem herkömmlichen Antischadsoftware-Ansatz implementiert, bei dem nach bekannten Schadsoftwaresignaturen gesucht wird, als auch die "Heuristik"-Überprüfung auf mittlerer Ebene. Die Lösung erkennt und entfernt Schadsoftware, indem die Dateien und der Code überprüft werden, die sich auf verdächtige/unerwartete oder böswillige Weise verhalten.
Der Scanner ist so konfiguriert, dass Archive dekomprimiert und die Darin befindlichen Dateien überprüft werden, um potenzielle Schadsoftware zu erkennen, die sich möglicherweise unter dem Archiv maskiert. Darüber hinaus ist der Scanner so konfiguriert, dass Mikroskripts in Microsoft Office-Dateien blockiert werden.
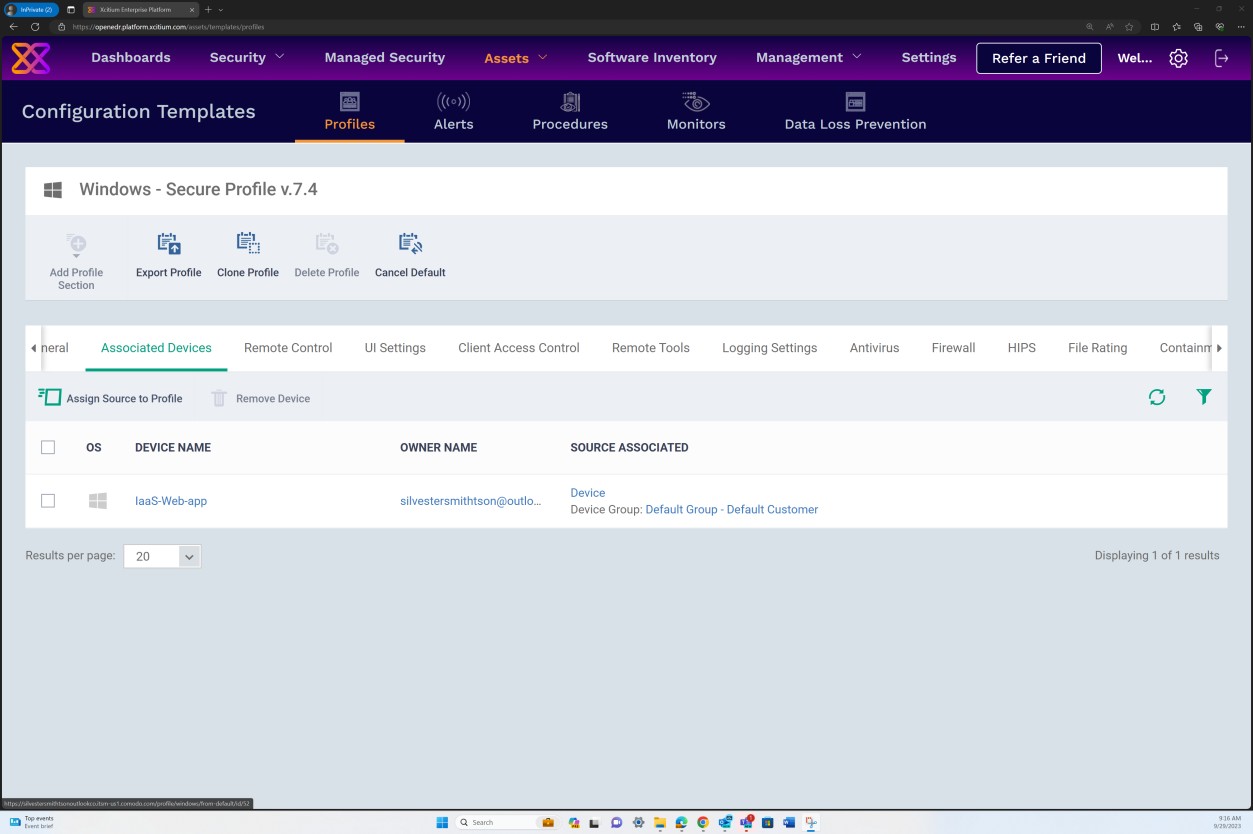
 Die nächsten Screenshots zeigen, dass Secure Profile v.7.4 unserem Windows Server Gerät "IaaS-Web-app"-Host zugewiesen wurde.
Die nächsten Screenshots zeigen, dass Secure Profile v.7.4 unserem Windows Server Gerät "IaaS-Web-app"-Host zugewiesen wurde.
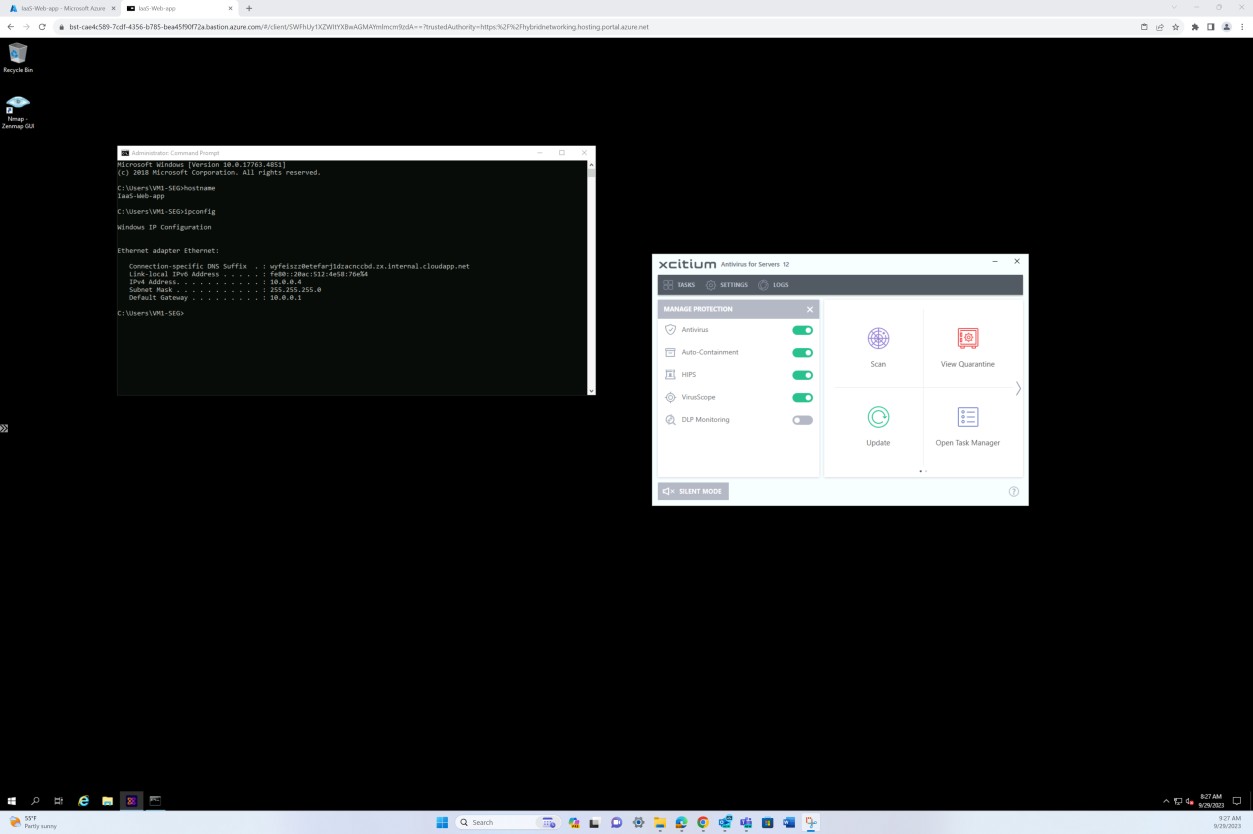
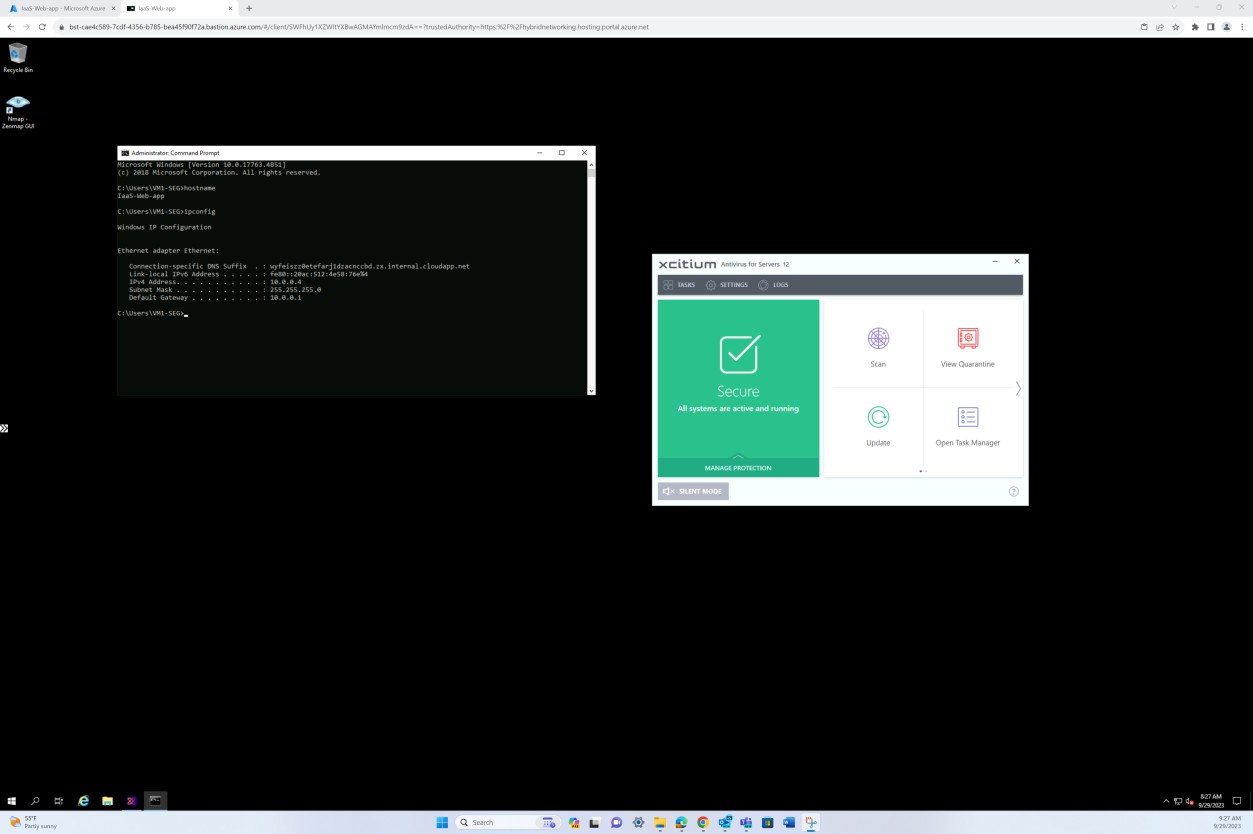
Der nächste Screenshot stammt aus dem Windows Server Gerät "IaaS-Web-app", das zeigt, dass der OpenEDR-Agent aktiviert ist und auf dem Host ausgeführt wird.
Schutz vor Schadsoftware/Anwendungssteuerung
Die Anwendungssteuerung ist eine Sicherheitsmethode, die die Ausführung nicht autorisierter Anwendungen auf eine Weise verhindert oder einschränkt, die Daten gefährdet. Anwendungssteuerungen sind ein wichtiger Bestandteil eines Unternehmenssicherheitsprogramms und können verhindern, dass böswillige Akteure Sicherheitsrisiken für Anwendungen ausnutzen und das Risiko einer Sicherheitsverletzung verringern. Durch die Implementierung der Anwendungssteuerung können Unternehmen und Organisationen die Risiken und Bedrohungen im Zusammenhang mit der Anwendungsnutzung erheblich reduzieren, da Anwendungen daran gehindert werden, ausgeführt zu werden, wenn sie das Netzwerk oder vertrauliche Daten gefährden. Anwendungssteuerungen bieten Betriebs- und Sicherheitsteams einen zuverlässigen, standardisierten und systematischen Ansatz zur Minderung von Cyberrisiken. Sie geben Organisationen auch ein vollständiges Bild von den Anwendungen in ihrer Umgebung, was IT- und Sicherheitsorganisationen dabei helfen kann, Cyberrisiken effektiv zu verwalten.
Regelung Nr. 3
HARTER FEHLER
Stellen Sie Beweise für Folgendes bereit:
Sie verfügen über eine genehmigte Liste von Software/Anwendungen mit geschäftlicher Begründung, die:
existiert und wird auf dem neuesten Stand gehalten.
Jede Anwendung wird einem Genehmigungsprozess unterzogen und vor der Bereitstellung abgemeldet.
Diese Anwendungssteuerungstechnologie ist aktiv, aktiviert und inline mit der Genehmigungsliste für die erfassten Systemkomponenten konfiguriert.
Absicht: Softwareliste
Mit diesem Unterpunkt soll sichergestellt werden, dass innerhalb der organization eine genehmigte Liste von Software und Anwendungen vorhanden ist und ständig auf dem neuesten Stand gehalten wird. Stellen Sie sicher, dass jede Software oder Anwendung in der Liste über eine dokumentierte geschäftliche Begründung verfügt, um ihre Notwendigkeit zu überprüfen. Diese Liste dient als maßgeblicher Verweis für die Regulierung der Bereitstellung von Software und Anwendungen und hilft so bei der Beseitigung nicht autorisierter oder redundanter Software, die ein Sicherheitsrisiko darstellen könnte.
Richtlinien: Softwareliste
Ein Dokument, das die genehmigte Liste von Software und Anwendungen enthält, wenn es als digitales Dokument (Word, PDF usw.) verwaltet wird. Wenn die genehmigte Liste der Software und Anwendungen über eine Plattform verwaltet wird, müssen Screenshots der Liste der Plattform bereitgestellt werden.
Beispielbeweis: Softwareliste
Die nächsten Screenshots zeigen, dass eine Liste der genehmigten Software und Anwendungen auf der Confluence Cloud-Plattform verwaltet wird.
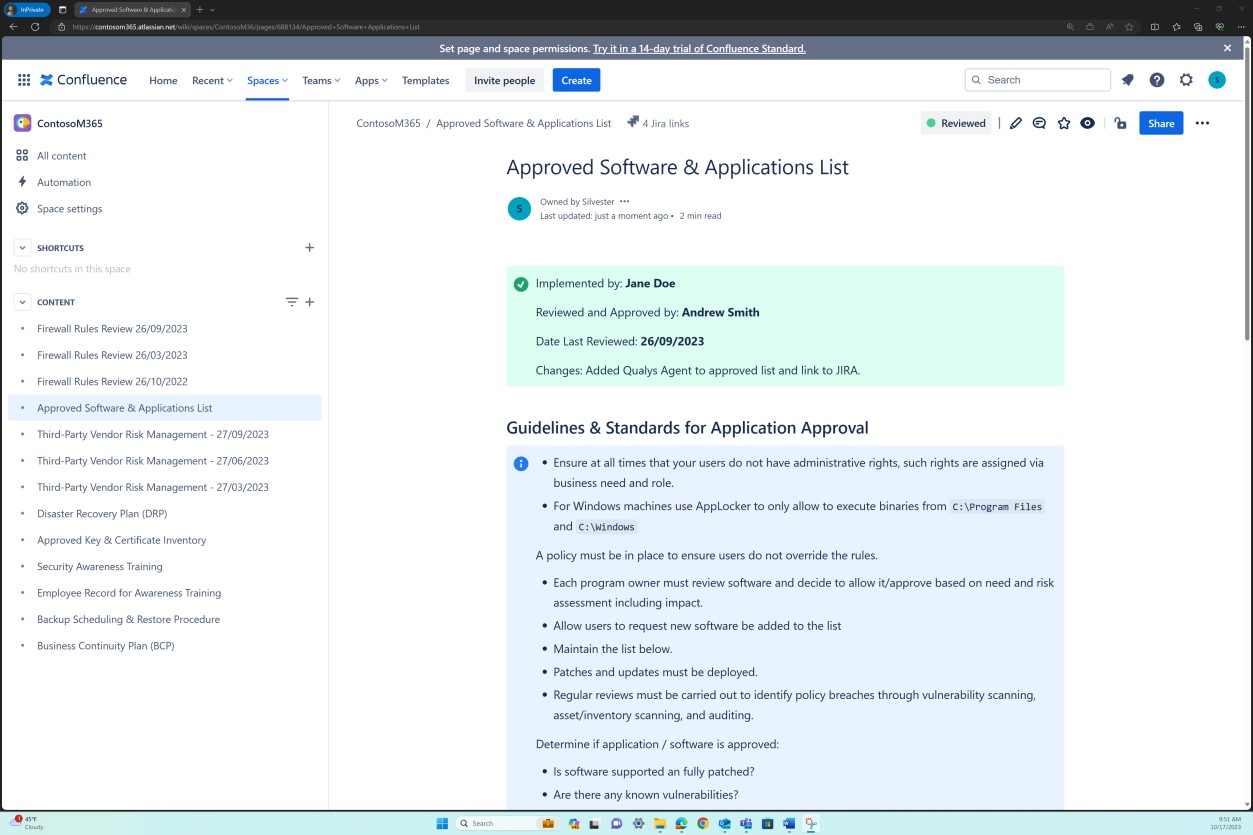
Die nächsten Screenshots zeigen, dass die Liste der genehmigten Software und Anwendungen, einschließlich des Anforderers, des Datums der Anforderung, der genehmigenden Person, des Datums der Genehmigung, des Kontrollmechanismus, des JIRA-Tickets, des Systems/der Ressource, verwaltet wird.
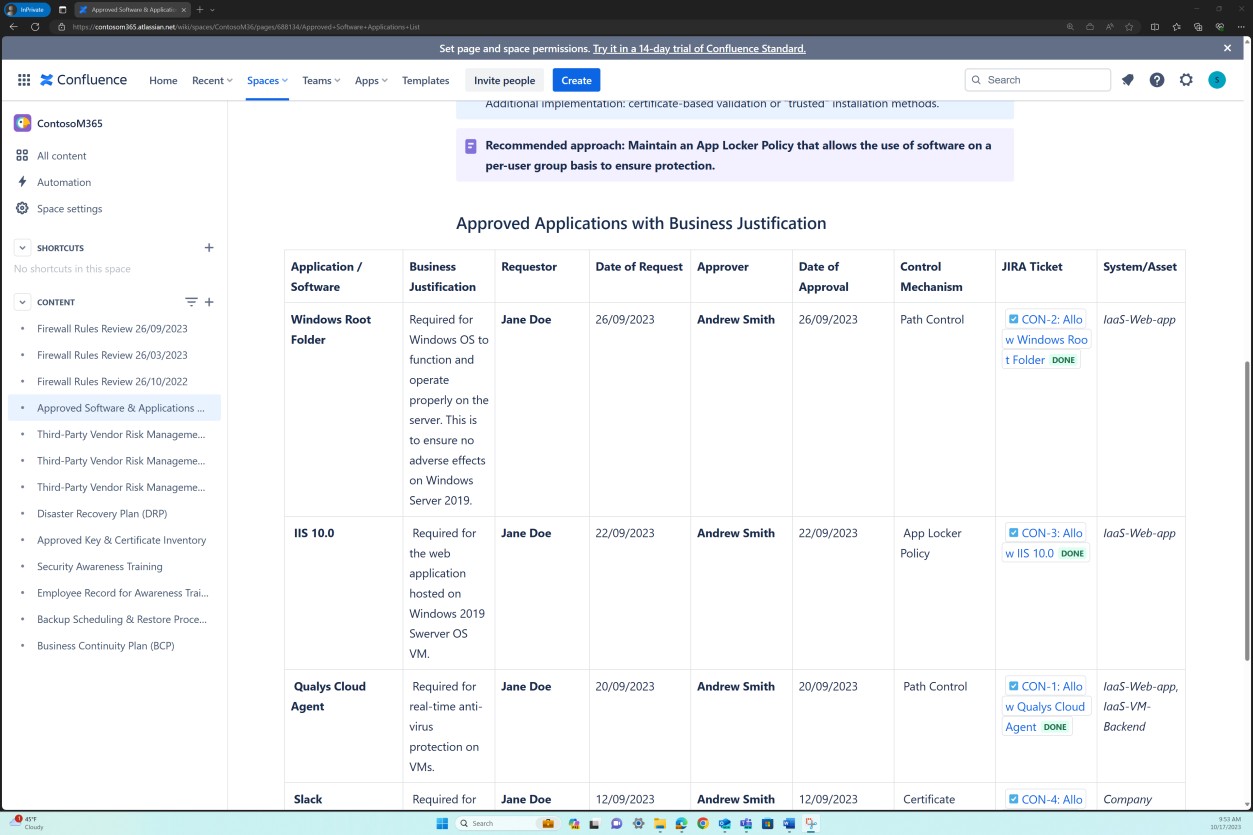
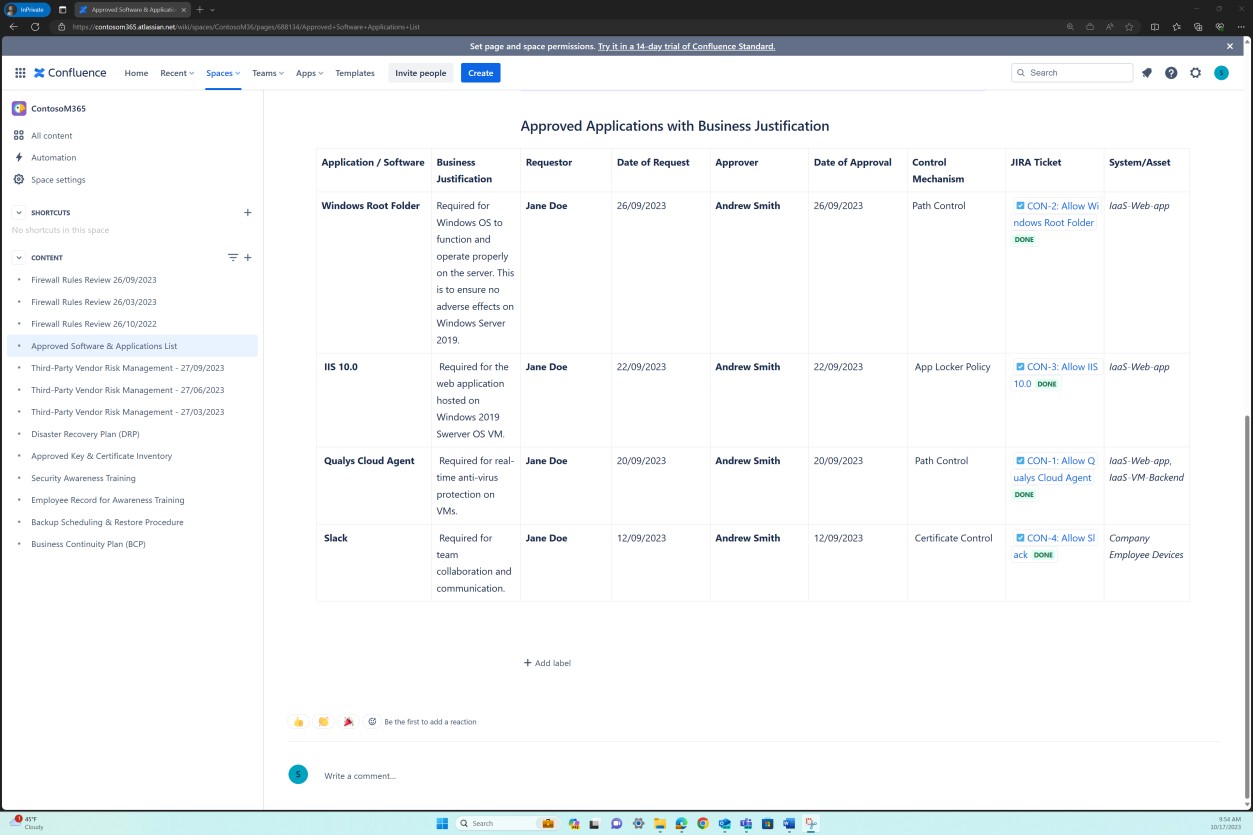
Absicht: Softwaregenehmigung
Der Zweck dieses Unterpunkts besteht darin, zu bestätigen, dass jede Software/Anwendung vor ihrer Bereitstellung innerhalb der organization einem formalen Genehmigungsprozess unterzogen wird. Der Genehmigungsprozess sollte eine technische Bewertung und eine Genehmigung durch die Geschäftsleitung umfassen, um sicherzustellen, dass sowohl operative als auch strategische Perspektiven berücksichtigt wurden. Durch die Einführung dieses strengen Prozesses stellt die organization sicher, dass nur geprüfte und erforderliche Software bereitgestellt wird, wodurch Sicherheitsrisiken minimiert und die Ausrichtung auf die Geschäftsziele sichergestellt wird.
Richtlinien
Es kann nachgewiesen werden, dass der Genehmigungsprozess befolgt wird. Dies kann durch signierte Dokumente, die Nachverfolgung innerhalb der Änderungskontrollsysteme oder die Verwendung von Azure DevOps/JIRA bereitgestellt werden, um die Änderungsanforderungen und die Autorisierung nachzuverfolgen.
Beispielbeweis
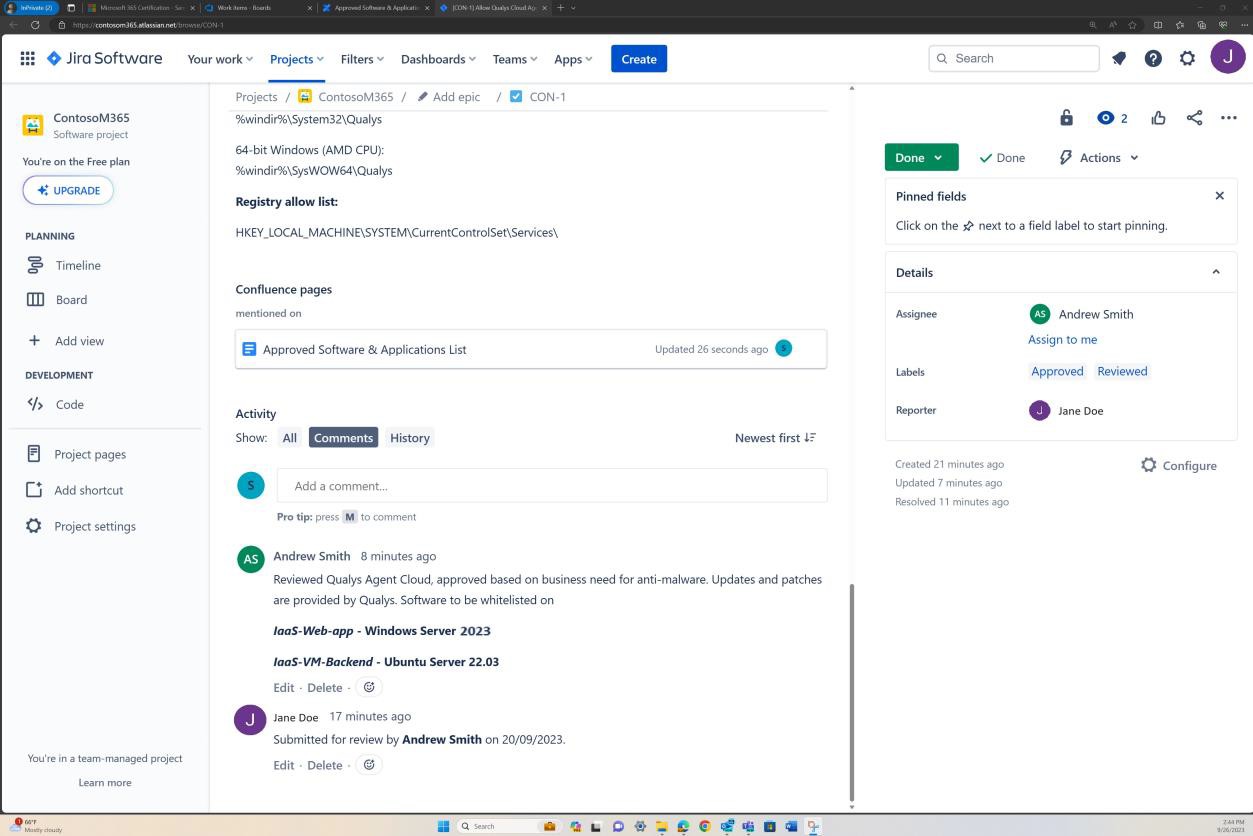
Die nächsten Screenshots zeigen einen vollständigen Genehmigungsprozess in JIRA Software. Ein Benutzer "Jane Doe" hat eine Anforderung für die Installation von "Qualys Cloud Agent" auf servern "IaaS-Web-app" und "IaaS-VM- Back-End" ausgelöst. "Andrew Smith" hat die Anforderung überprüft und mit dem Kommentar "genehmigt basierend auf geschäftlichem Bedarf an Antischadsoftware. Updates und Patches, die von Qualys bereitgestellt werden. Zu genehmigende Software."
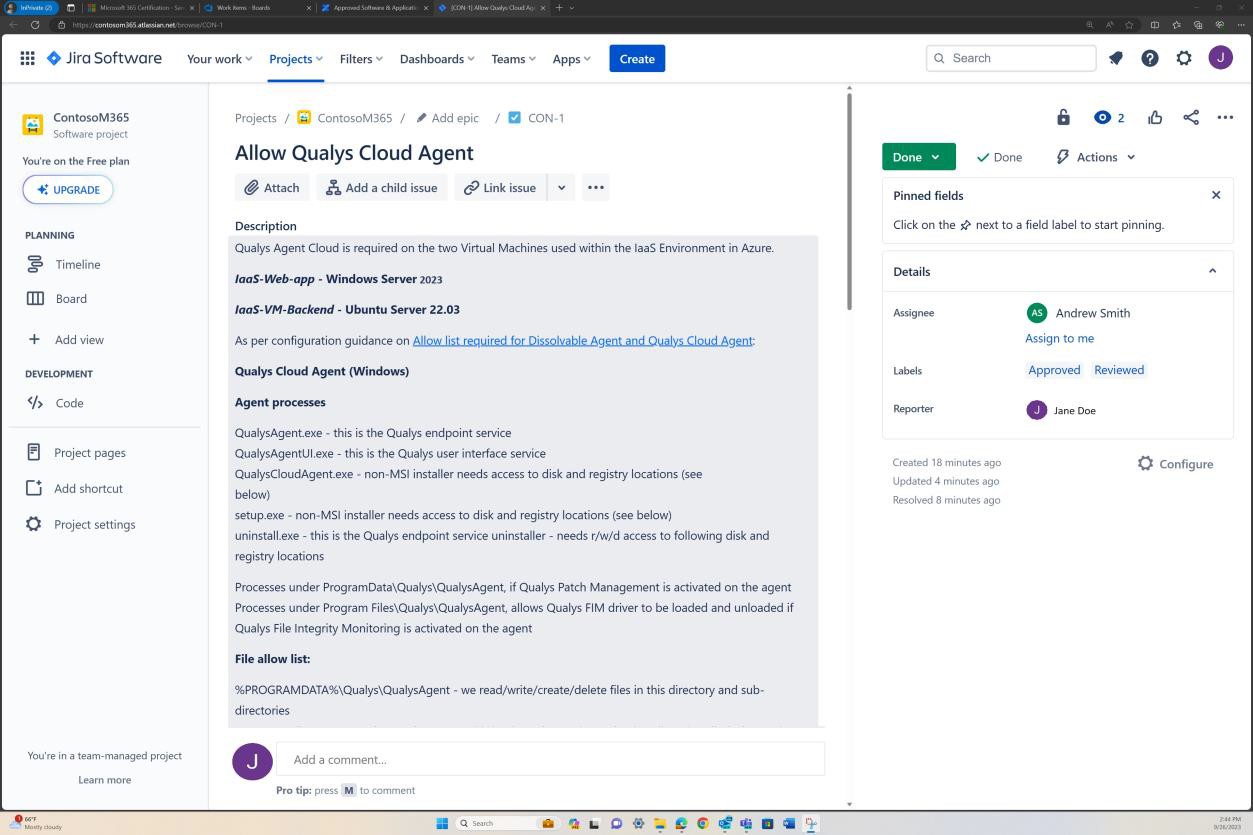
Der nächste Screenshot zeigt die Genehmigung, die über das Auf der Confluence-Plattform ausgelöste Ticket erteilt wird, bevor die Anwendung auf dem Produktionsserver ausgeführt werden kann.
Absicht: App-Steuerungstechnologie
Dieser Unterpunkt konzentriert sich auf die Überprüfung, ob die Anwendungssteuerungstechnologie aktiv, aktiviert und ordnungsgemäß für alle erfassten Systemkomponenten konfiguriert ist. Stellen Sie sicher, dass die Technologie in Übereinstimmung mit dokumentierten Richtlinien und Verfahren arbeitet, die als Richtlinien für ihre Implementierung und Wartung dienen. Durch eine aktive, aktivierte und gut konfigurierte Anwendungssteuerungstechnologie kann die organization dazu beitragen, die Ausführung von nicht autorisierter oder bösartiger Software zu verhindern und den allgemeinen Sicherheitsstatus des Systems zu verbessern.
Richtlinien: App-Steuerungstechnologie
Stellen Sie eine Dokumentation bereit, in der die Einrichtung der Anwendungssteuerung beschrieben wird, sowie Nachweise aus der anwendbaren Technologie, die zeigen, wie die einzelnen Anwendungen/Prozesse konfiguriert wurden.
Beispielbeweis: App-Steuerungstechnologie
Die nächsten Screenshots zeigen, dass Windows-Gruppenrichtlinien (GPO) so konfiguriert sind, dass nur genehmigte Software und Anwendungen erzwungen werden.
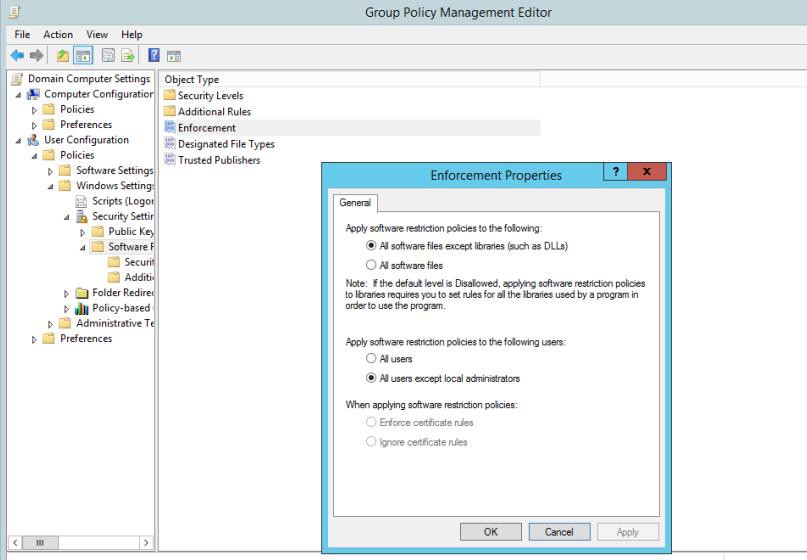
Der nächste Screenshot zeigt die Software/Anwendungen, die über die Pfadsteuerung ausgeführt werden dürfen.
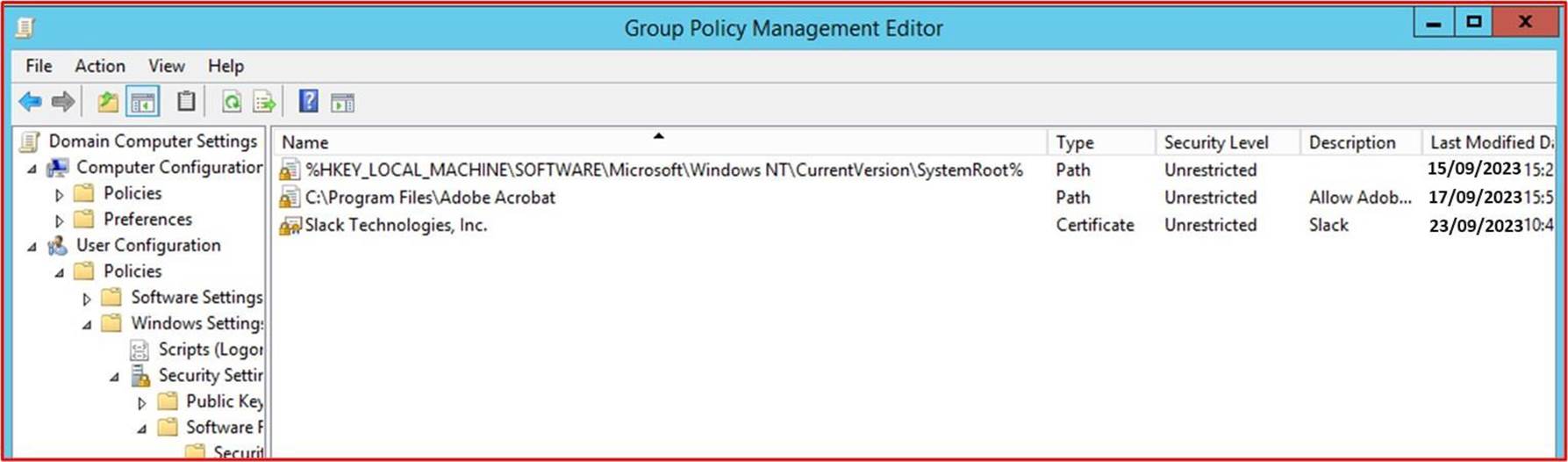
Hinweis: In diesen Beispielen wurden keine vollständigen Screenshots verwendet, aber ALLE von ISV übermittelten Nachweise Screenshots müssen Vollbildscreenshots sein, die eine URL, den angemeldeten Benutzer und die Systemzeit und das Systemdatum zeigen.
Patchverwaltung/Patching und Risikorangfolge
Die Patchverwaltung, die häufig als Patchen bezeichnet wird, ist eine wichtige Komponente jeder robusten Cybersicherheitsstrategie. Es umfasst den systematischen Prozess zum Identifizieren, Testen und Anwenden von Patches oder Updates für Software, Betriebssysteme und Anwendungen. Das primäre Ziel der Patchverwaltung besteht darin, Sicherheitsrisiken zu minimieren und sicherzustellen, dass Systeme und Software resilient gegen potenzielle Bedrohungen bleiben. Darüber hinaus umfasst die Patchverwaltung die Risikoeinstufung, die ein wichtiges Element bei der Priorisierung von Patches ist. Dies umfasst die Bewertung von Sicherheitsrisiken basierend auf ihrem Schweregrad und den potenziellen Auswirkungen auf den Sicherheitsstatus eines organization. Durch die Zuweisung von Risikobewertungen zu Sicherheitsrisiken können Organisationen Ressourcen effizient zuordnen und sich darauf konzentrieren, kritische und risikoreiche Sicherheitsrisiken umgehend zu beheben und gleichzeitig eine proaktive Haltung gegenüber neuen Bedrohungen beizubehalten. Eine effektive Strategie für patch management und risk ranking erhöht nicht nur die Sicherheit, sondern trägt auch zur allgemeinen Stabilität und Leistung der IT-Infrastruktur bei, sodass Organisationen in der sich ständig entwickelnden Landschaft der Cybersicherheitsbedrohungen resilient bleiben.
Um eine sichere Betriebsumgebung zu gewährleisten, müssen Anwendungen/Add-Ons und unterstützende Systeme entsprechend gepatcht werden. Es muss ein geeigneter Zeitrahmen zwischen Der Identifizierung (oder der öffentlichen Veröffentlichung) und dem Patchen verwaltet werden, um das Zeitfenster für die Ausnutzung eines Sicherheitsrisikos durch einen Bedrohungsakteur zu verringern. Die Microsoft 365-Zertifizierung sieht kein "Patchfenster" vor. Zertifizierungsanalysten werden jedoch Zeitrahmen ablehnen, die nicht angemessen sind oder den bewährten Methoden der Branche entsprechen. Diese Sicherheitskontrollgruppe ist auch für PaaS-Hostingumgebungen (Platform-as-a-Service) vorgesehen, da die Anwendung/Add-In-Softwarebibliotheken und Codebasis von Drittanbietern basierend auf der Risikobewertung gepatcht werden müssen.
Steuerung Nr. 4
Stellen Sie Beweise für Folgendes bereit:
Eine Dokumentation zur Patchverwaltungsrichtlinie und -prozedur definiert Folgendes:
geeignetes minimales Patchingfenster für Sicherheitsrisiken mit kritischem/hohem und mittlerem Risiko ab dem Zeitpunkt der Veröffentlichung des Herstellerpatches oder ab dem Zeitpunkt, an dem maßgeschneiderte Codierungsrisiken identifiziert werden
Außerbetriebnahme von nicht unterstützten Betriebssystemen und Anwendungssoftware, einschließlich Codeabhängigkeiten von Drittanbietern
Details dazu, wie sicherheitsrelevante Sicherheitsrisiken durch einen neuen Anbieter identifiziert und einer Risikobewertung zugewiesen werden
Der Prozess zur Identifizierung neuer Benachrichtigungen zu Sicherheitsrisiken des Anbieters und zum Zuweisen einer Risikobewertung wird durchgeführt.
Absicht: Patchverwaltung
Patchverwaltung ist für viele Sicherheitscompliance-Frameworks erforderlich, z. B. PCI-DSS, ISO 27001, NIST (SP) 800-53, FedRAMP und SOC 2. Die Bedeutung einer guten Patchverwaltung kann nicht übermäßig betont werden
da es Sicherheits- und Funktionsprobleme in Software, Firmware und Sicherheitslücken beheben kann, was dazu beiträgt, die Möglichkeiten zur Nutzung zu verringern. Die Absicht dieses Steuerelements besteht darin, das Zeitfenster zu minimieren, das ein Bedrohungsakteur hat, um Sicherheitsrisiken auszunutzen, die möglicherweise in der umgebung des Bereichs vorhanden sind.
In der Dokumentation zur Patchverwaltungsrichtlinie und -prozedur des organization muss Folgendes klar definiert werden:
Ein geeignetes minimales Patchfenster für Sicherheitsrisiken, die als kritische, hohe und mittlere Risiken kategorisiert sind.
Die Patchzeitrahmen sollten auf dem Veröffentlichungsdatum des Anbieters basieren, nicht auf dem Zeitpunkt, zu dem der organization das Sicherheitsrisiko identifiziert. Durch die explizite Definition dieser Zeitrahmen kann der organization seinen Ansatz für die Patchverwaltung standardisieren und so das Risiko für nicht gepatchte Sicherheitsrisiken verringern.
Außerbetriebnahme nicht unterstützter Betriebssysteme und Software.
Die Patchverwaltungsrichtlinie enthält Bestimmungen für die Außerbetriebnahme nicht unterstützter Betriebssysteme und Software. Betriebssysteme und Software, die keine Sicherheitsupdates mehr erhalten, stellen ein erhebliches Risiko für den Sicherheitsstatus eines organization dar. Daher stellt diese Kontrolle sicher, dass solche Systeme rechtzeitig identifiziert und entfernt oder ersetzt werden, wie in der Richtliniendokumentation definiert.
- Ein dokumentiertes Verfahren, das beschreibt, wie neue Sicherheitsrisiken identifiziert und einer Risikobewertung zugewiesen werden.
Das Patchen muss auf dem Risiko basieren, je riskanter das Sicherheitsrisiko ist, desto schneller muss es behoben werden. Die Risikoeinstufung identifizierter Sicherheitsrisiken ist ein integraler Bestandteil dieses Prozesses. Mit dieser Kontrolle soll sichergestellt werden, dass es einen dokumentierten Risikorangfolgeprozess gibt, der befolgt wird, um sicherzustellen, dass alle identifizierten Sicherheitsrisiken entsprechend dem Risiko bewertet werden. Organisationen verwenden in der Regel die CVSS-Bewertung (Common Vulnerability Scoring System), die von Anbietern oder Sicherheitsexperten bereitgestellt wird. Wenn Organisationen sich auf CVSS verlassen, wird empfohlen, dass ein Mechanismus zur Neubewertung in den Prozess einbezogen wird, damit die organization die Rangfolge basierend auf einer internen Risikobewertung ändern können. Manchmal ist die Sicherheitsanfälligkeit aufgrund der Art und Weise, wie die Anwendung in der Umgebung bereitgestellt wurde, möglicherweise nicht anwendbar. Beispielsweise kann eine Java-Sicherheitsanfälligkeit freigegeben werden, die sich auf eine bestimmte Bibliothek auswirkt, die nicht vom organization verwendet wird.
Hinweis: Auch wenn Sie in einer reinen PaaS/Serverless-Umgebung von Platform-as-a-Service ausgeführt werden, sind Sie dennoch dafür verantwortlich, Sicherheitsrisiken in Ihrer Codebasis zu identifizieren, d. h. Bibliotheken von Drittanbietern.
Richtlinien: Patchverwaltung
Geben Sie das Richtliniendokument an. Administrative Nachweise wie Richtlinien- und Verfahrensdokumentationen, die die im organization definierten Prozesse detailliert beschreiben, die alle Elemente für die jeweilige Kontrolle abdecken, sind vorzulegen.
Hinweis: Diese logischen Beweise können als unterstützende Beweise bereitgestellt werden, die einen weiteren Einblick in das Vulnerability Management Program (VMP) Ihres organization bieten, aber diese Kontrolle wird nicht von selbst erfüllt.
Beispielbeweis: Patchverwaltung
Der nächste Screenshot zeigt einen Codeausschnitt einer Patchverwaltungs-/Risikobewertungsrichtlinie sowie die verschiedenen Risikokategorienebenen. Danach folgen die Zeitrahmen für Klassifizierung und Korrektur. Hinweis: Es wird erwartet, dass ISVs die tatsächliche Dokumentation zu unterstützenden Richtlinien/Verfahren freigeben und nicht einfach einen Screenshot bereitstellen.


Beispiel für (optional) zusätzliche technische Beweise, die das Richtliniendokument unterstützen
Logische Beweise, z. B. Tabellen für die Nachverfolgung von Sicherheitsrisiken, Berichte zur technischen Bewertung von Sicherheitsrisiken oder Screenshots von Tickets, die über Onlineverwaltungsplattformen ausgelöst wurden, um die status und den Fortschritt von Sicherheitsrisiken nachzuverfolgen, die zur Unterstützung der Implementierung des prozesses verwendet werden, der in der zu erstellenden Richtliniendokumentation beschrieben ist. Der nächste Screenshot zeigt, dass Snyk, ein Tool zur Analyse der Softwarezusammensetzung (Software Composition Analysis, SCA), verwendet wird, um die Codebasis auf Sicherheitsrisiken zu überprüfen. Darauf folgt eine Benachrichtigung per E-Mail.
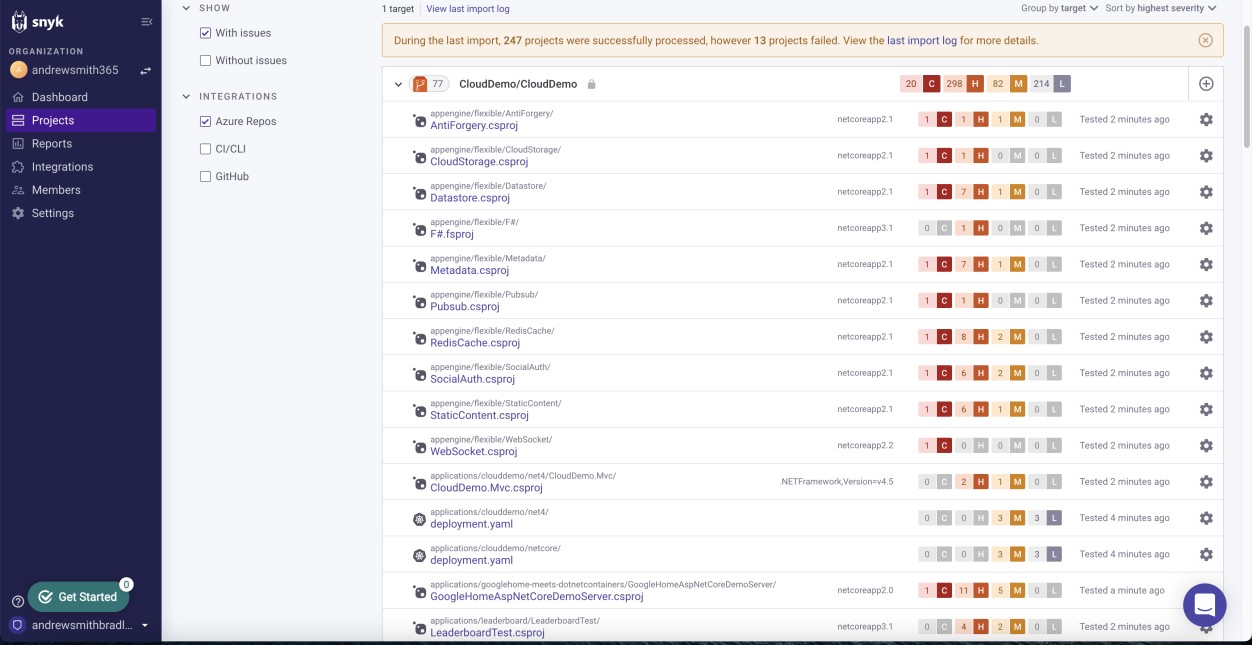
Bitte beachten Sie: In diesem Beispiel wurde kein vollständiger Screenshot verwendet, aber ALLE von ISV übermittelten Nachweise Screenshots müssen vollständige Screenshots sein, die eine URL, den angemeldeten Benutzer und die Systemzeit und das Systemdatum zeigen.
Die nächsten beiden Screenshots zeigen ein Beispiel für die E-Mail-Benachrichtigung, die empfangen wird, wenn neue Sicherheitsrisiken von Snyk gekennzeichnet werden. Wir können sehen, dass die E-Mail das betroffene Projekt und den zugewiesenen Benutzer für den Empfang der Warnungen enthält.
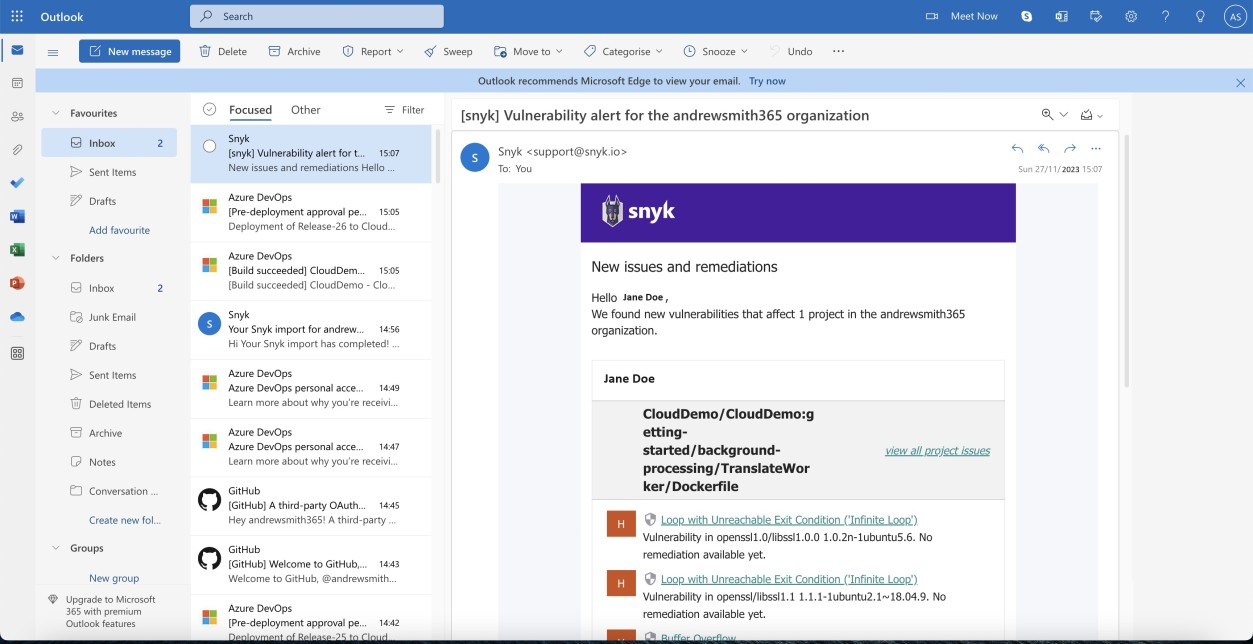
Der folgende Screenshot zeigt die identifizierten Sicherheitsrisiken.
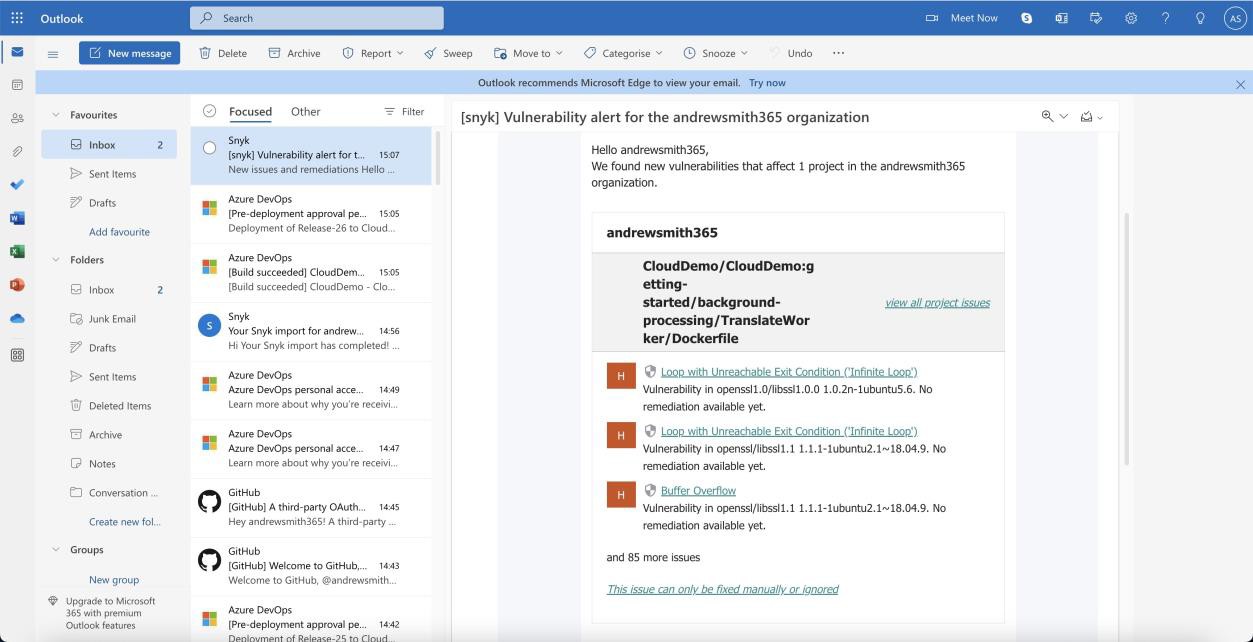
Bitte beachten Sie: In den vorherigen Beispielen wurden keine vollständigen Screenshots verwendet, jedoch müssen ALLE von ISV übermittelten Beweisscreenshots vollständige Screenshots mit der URL, allen angemeldeten Benutzern und Systemzeit und -datum sein.
Beispielbeweis
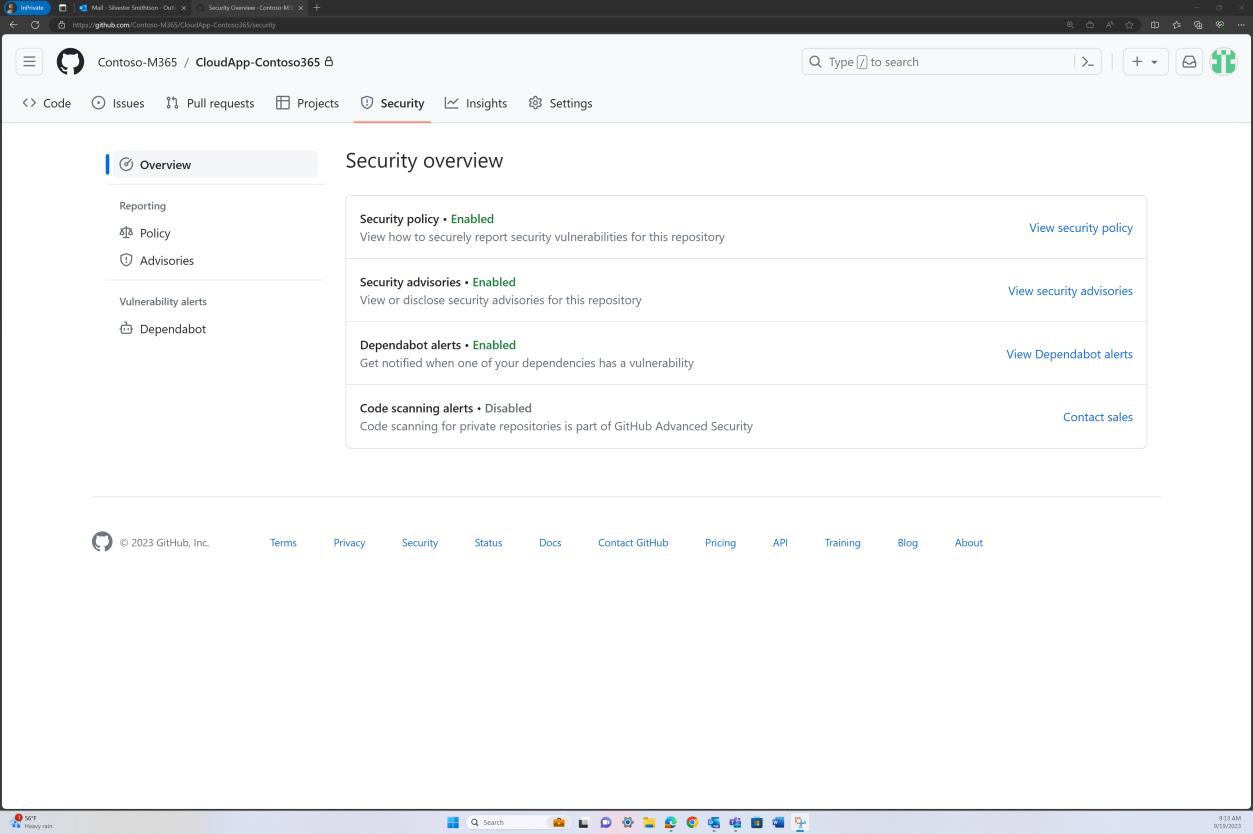
Die nächsten Screenshots zeigen GitHub-Sicherheitstools, die konfiguriert und aktiviert sind, um in der Codebasis nach Sicherheitsrisiken zu suchen, und Warnungen werden per E-Mail gesendet.
Die als Nächstes angezeigte E-Mail-Benachrichtigung ist eine Bestätigung, dass die gekennzeichneten Probleme automatisch durch einen Pull Request behoben werden.
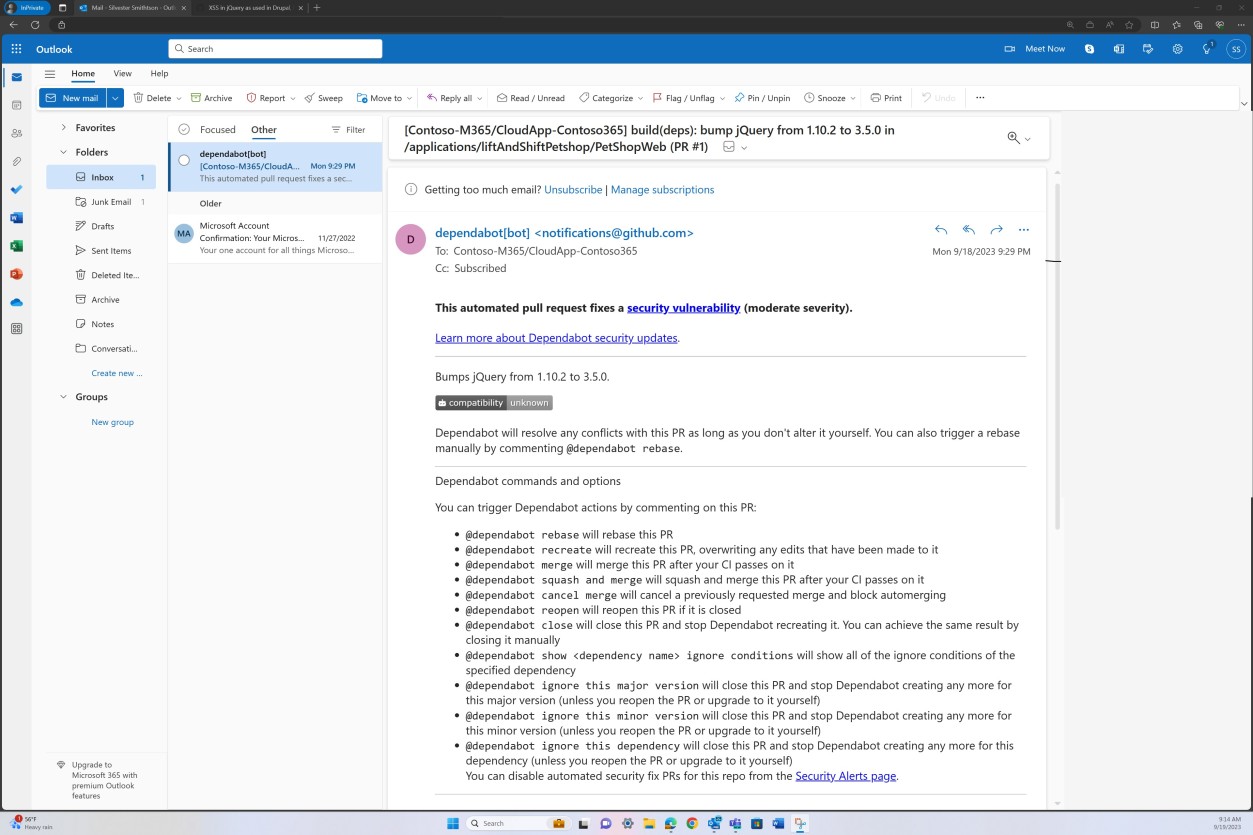
Beispielbeweis
Der nächste Screenshot zeigt die interne technische Bewertung und Rangfolge von Sicherheitsrisiken über ein Arbeitsblatt.
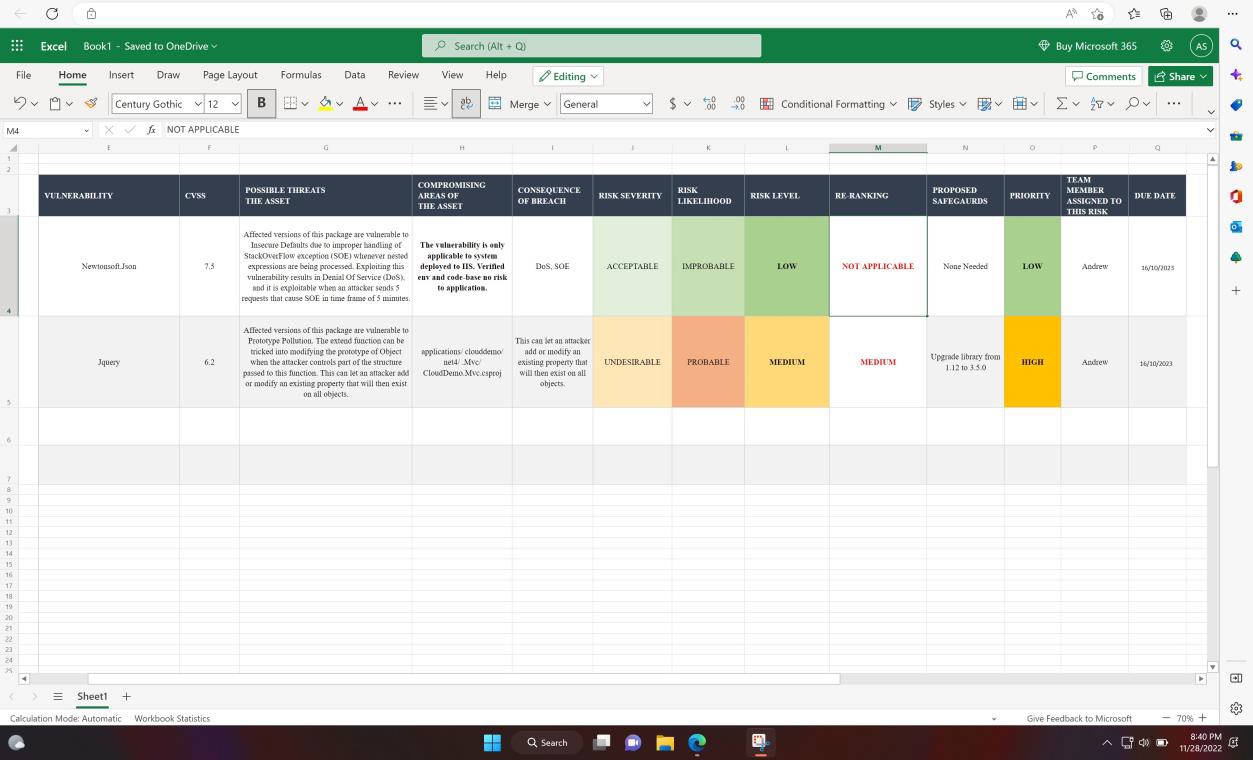
Beispielbeweis
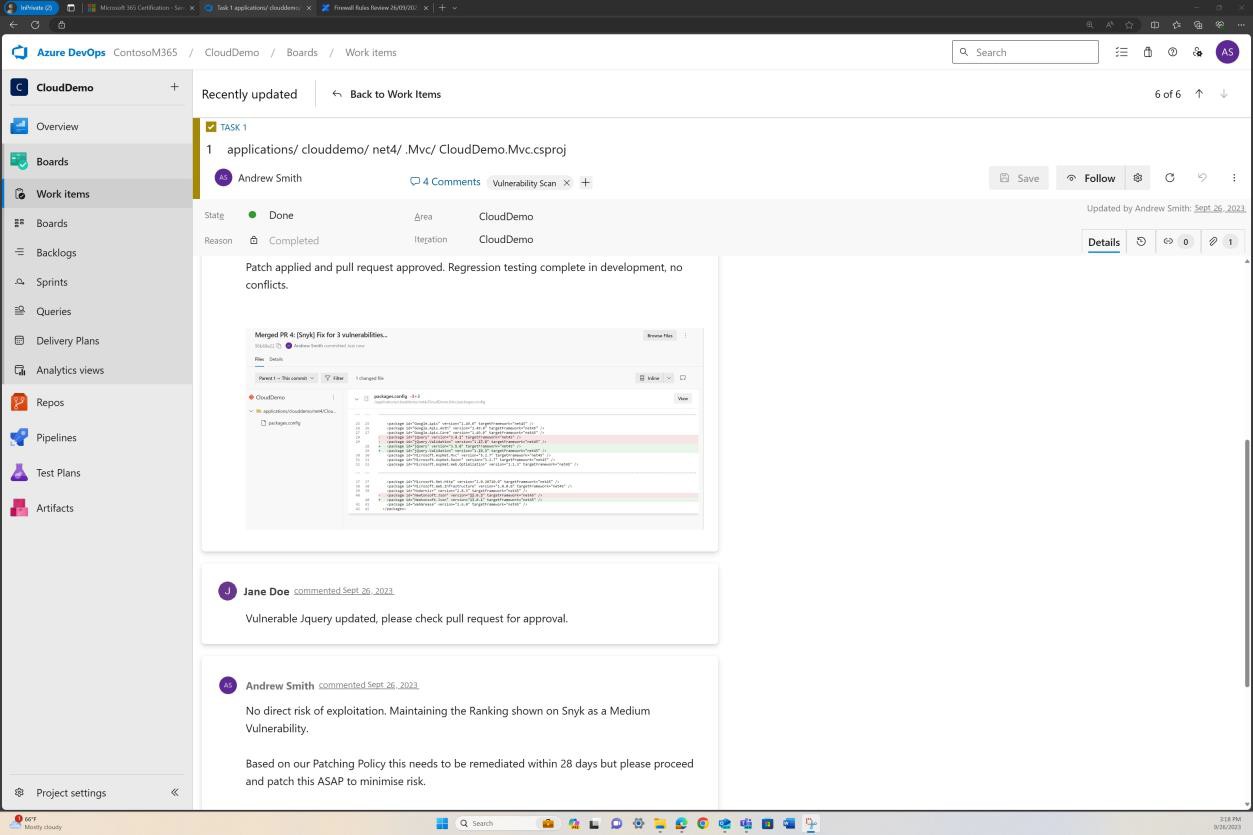
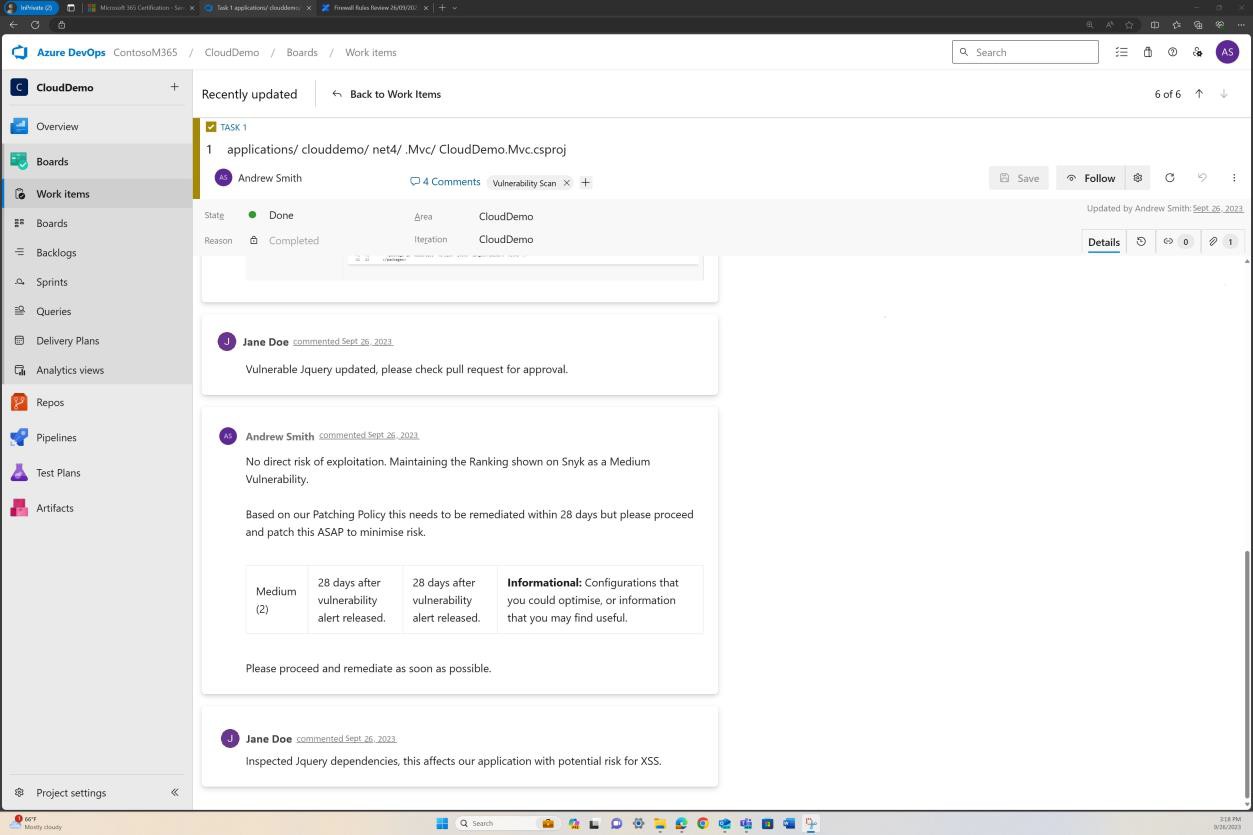
Die nächsten Screenshots zeigen Tickets, die in DevOps für jede gefundene Sicherheitslücke ausgelöst wurden.
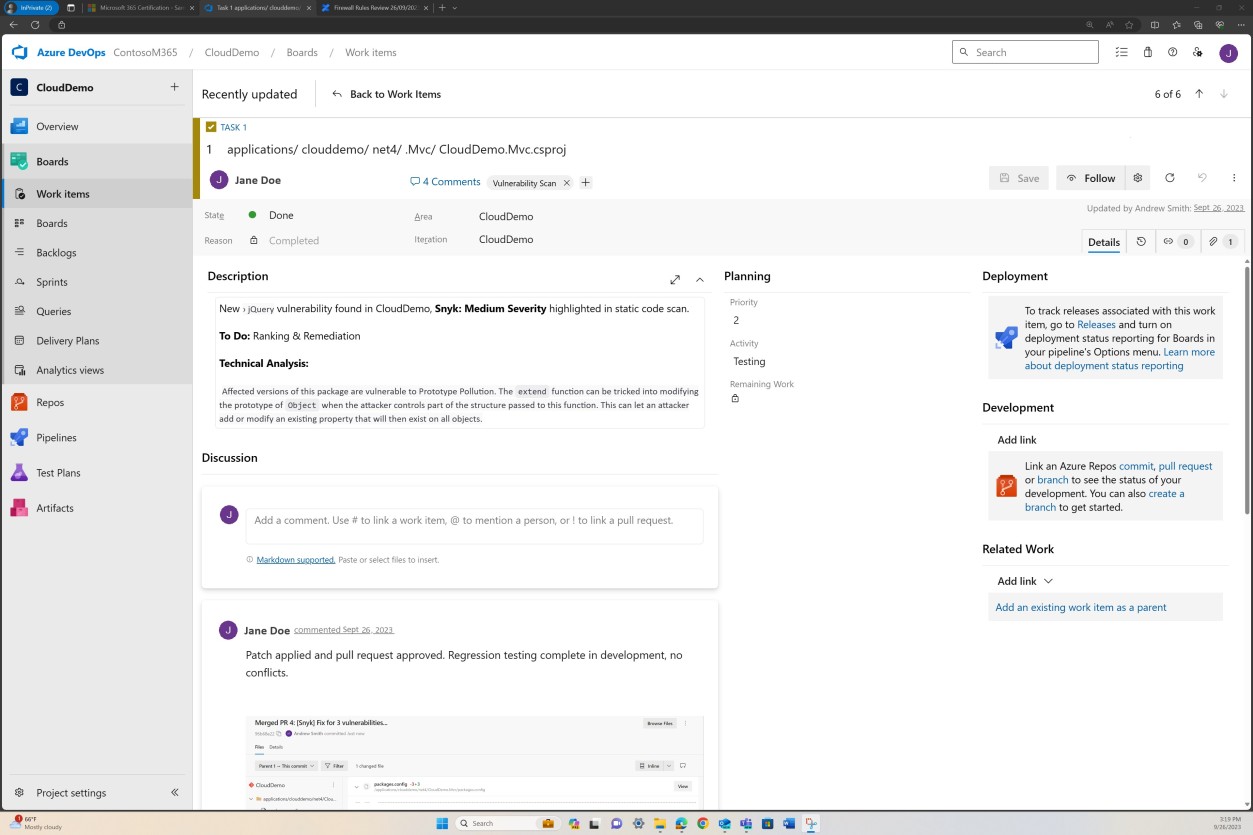
Die Bewertung, Bewertung und Überprüfung durch einen separaten Mitarbeiter erfolgt vor der Implementierung der Änderungen.
Steuerung Nr. 5
HARTER FEHLER
Stellen Sie Beweise für Folgendes bereit:
Alle erfassten Systemkomponenten, einschließlich der installierten Anwendungssoftware, und alle Codeabhängigkeiten von Drittanbietern werden gepatcht.
Nicht unterstützte Betriebssysteme und Anwendungssoftware, einschließlich Codeabhängigkeiten von Drittanbietern, werden nicht verwendet.
Für echte PaaS-Umgebungen gilt dieses Steuerelement nur für Codeabhängigkeiten von Drittanbietern.
Hinweis: Echte PaaS-Umgebungen sollten dem ISV-Administrator keinen Zugriff auf infrastrukturbasierte Komponenten erlauben. Beispielsweise, aber nicht beschränkt auf Windows/Linux Kubernetes-Knoten.
Absicht: Stichprobensystemkomponenten
Mit diesem Unterpunkt soll sichergestellt werden, dass nachweisbare Nachweise vorgelegt werden, um zu bestätigen, dass alle in der Stichprobe erfassten Systemkomponenten innerhalb der organization aktiv gepatcht werden. Die Beweise können unter anderem Patchverwaltungsprotokolle, Systemüberwachungsberichte oder dokumentierte Verfahren umfassen, die belegen, dass Patches angewendet wurden. Wenn serverlose Technologie oder PaaS (Platform-as-a-Service) verwendet wird, sollte dies auf die Codebasis erweitert werden, um zu bestätigen, dass die neuesten und sicheren Versionen von Bibliotheken und Abhängigkeiten verwendet werden.
Richtlinien: Stichprobensystemkomponenten
Stellen Sie einen Screenshot für jedes Gerät im Beispiel und unterstützende Softwarekomponenten bereit, der zeigt, dass Patches gemäß dem dokumentierten Patchprozess installiert werden. Stellen Sie außerdem Screenshots bereit, die das Patchen der Codebasis veranschaulich machen.
Beispielbeweis: Stichprobensystemkomponenten
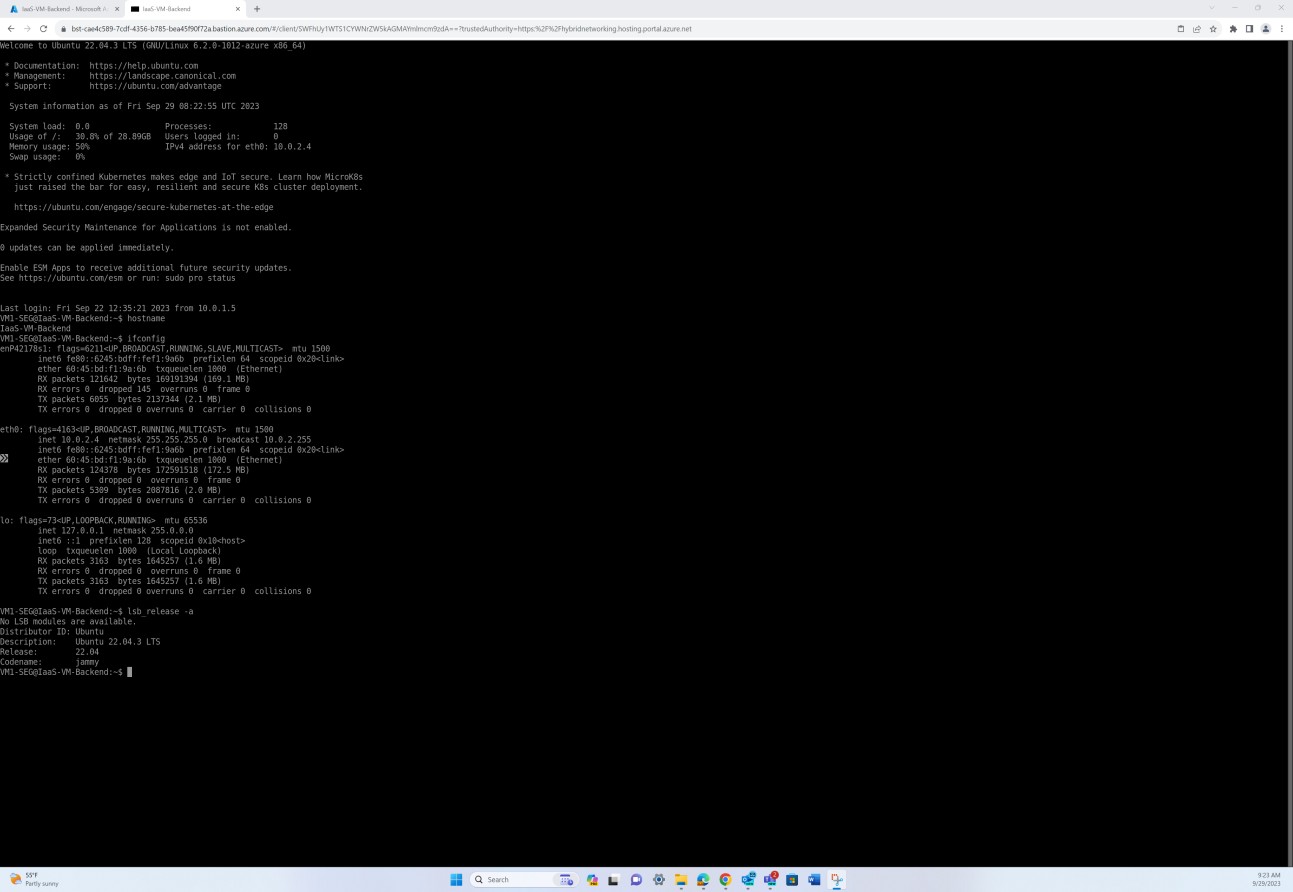
Der nächste Screenshot zeigt das Patchen eines virtuellen Linux-Betriebssystemcomputers "IaaS- VM-Backend".

Beispielbeweis
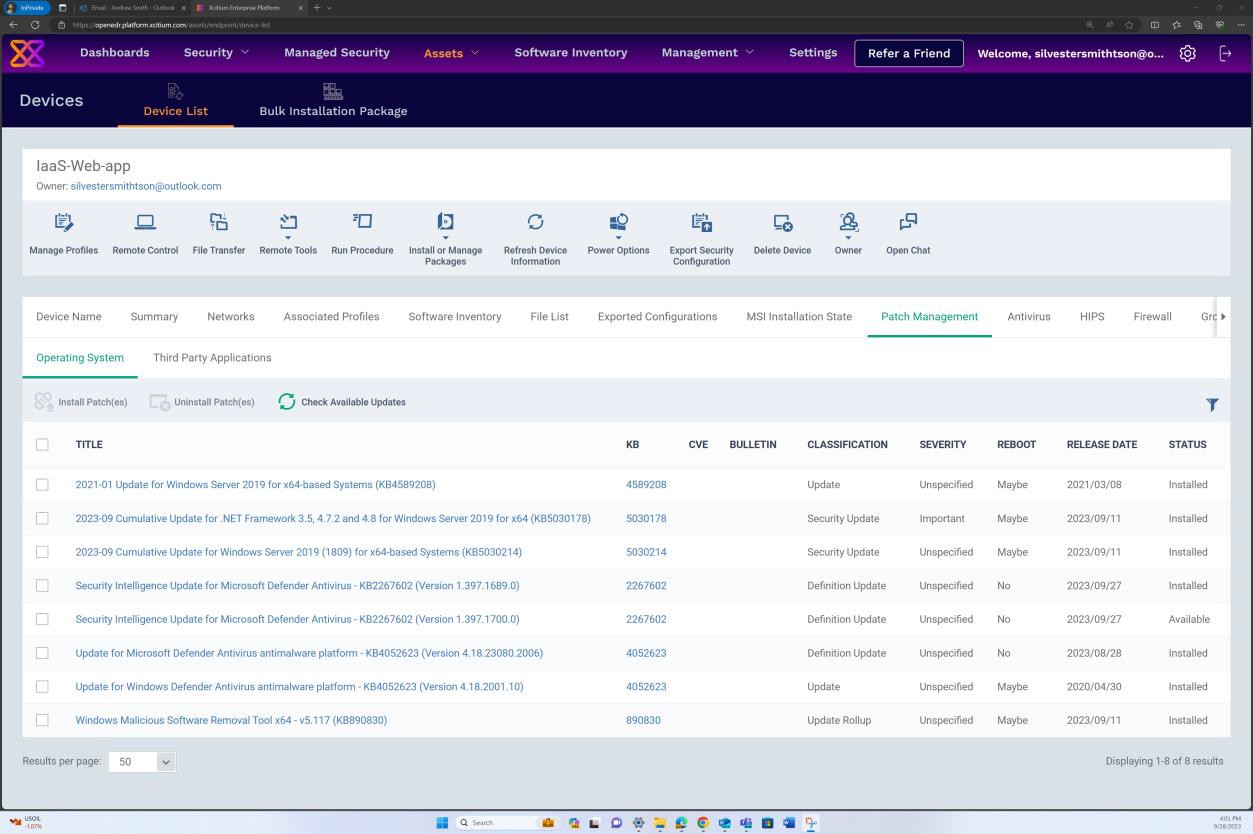
Der nächste Screenshot zeigt das Patchen eines virtuellen Windows-Betriebssystemcomputers "IaaS-Web-app".
Beispielbeweis
Wenn Sie das Patchen von anderen Tools wie Microsoft Intune, Defender für Cloud usw. verwalten, können Screenshots von diesen Tools bereitgestellt werden. Die nächsten Screenshots der OpenEDR-Lösung zeigen, dass die Patchverwaltung über das OpenEDR-Portal erfolgt.
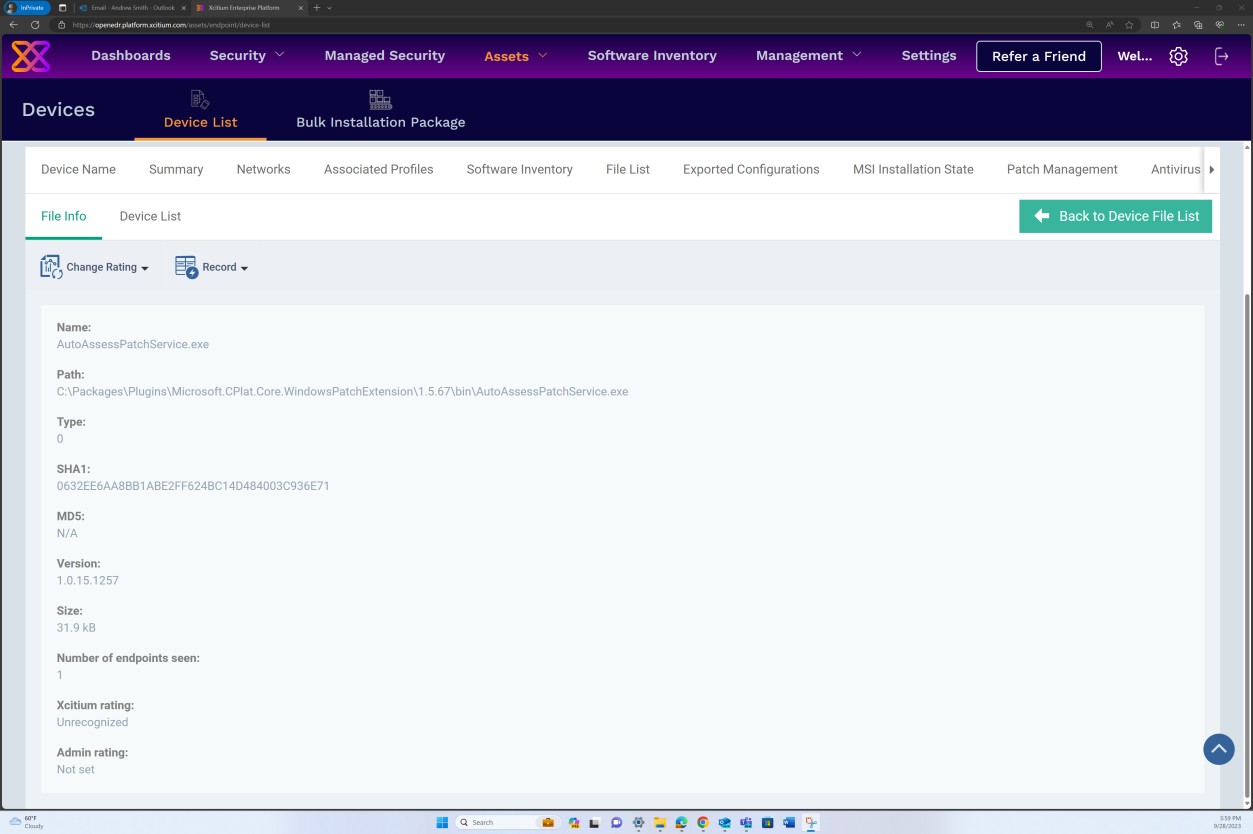
Der nächste Screenshot zeigt, dass die Patchverwaltung des Bereichsservers über die OpenEDR-Plattform erfolgt. Die Klassifizierung und die status sind unten sichtbar und zeigen, dass das Patchen erfolgt.
Der nächste Screenshot zeigt, dass Protokolle für die patches generiert werden, die erfolgreich auf dem Server installiert wurden.
Beispielbeweis
Der nächste Screenshot zeigt, dass die Abhängigkeiten der Codebasis-/Drittanbieterbibliothek über Azure DevOps gepatcht werden.
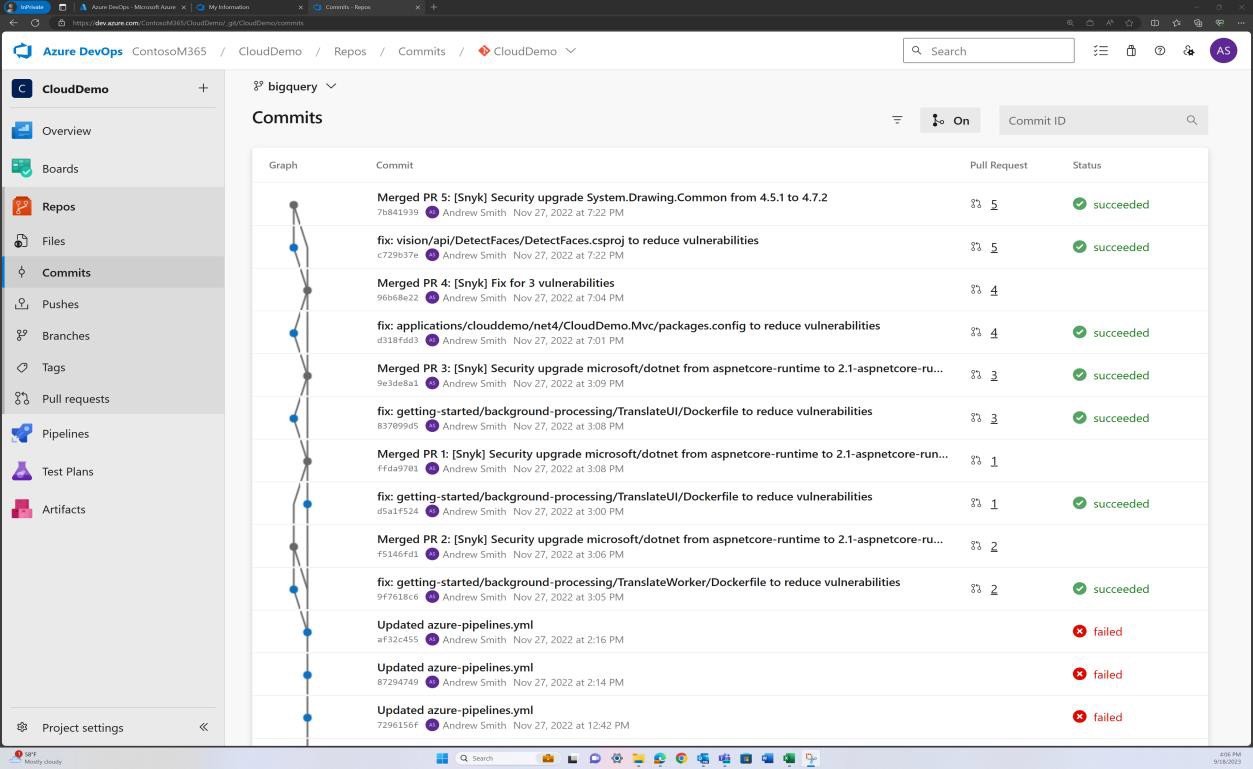
Der nächste Screenshot zeigt, dass eine Behebung von Sicherheitsrisiken, die von Snyk entdeckt wurden, in den Branch committet wird, um veraltete Bibliotheken zu beheben.
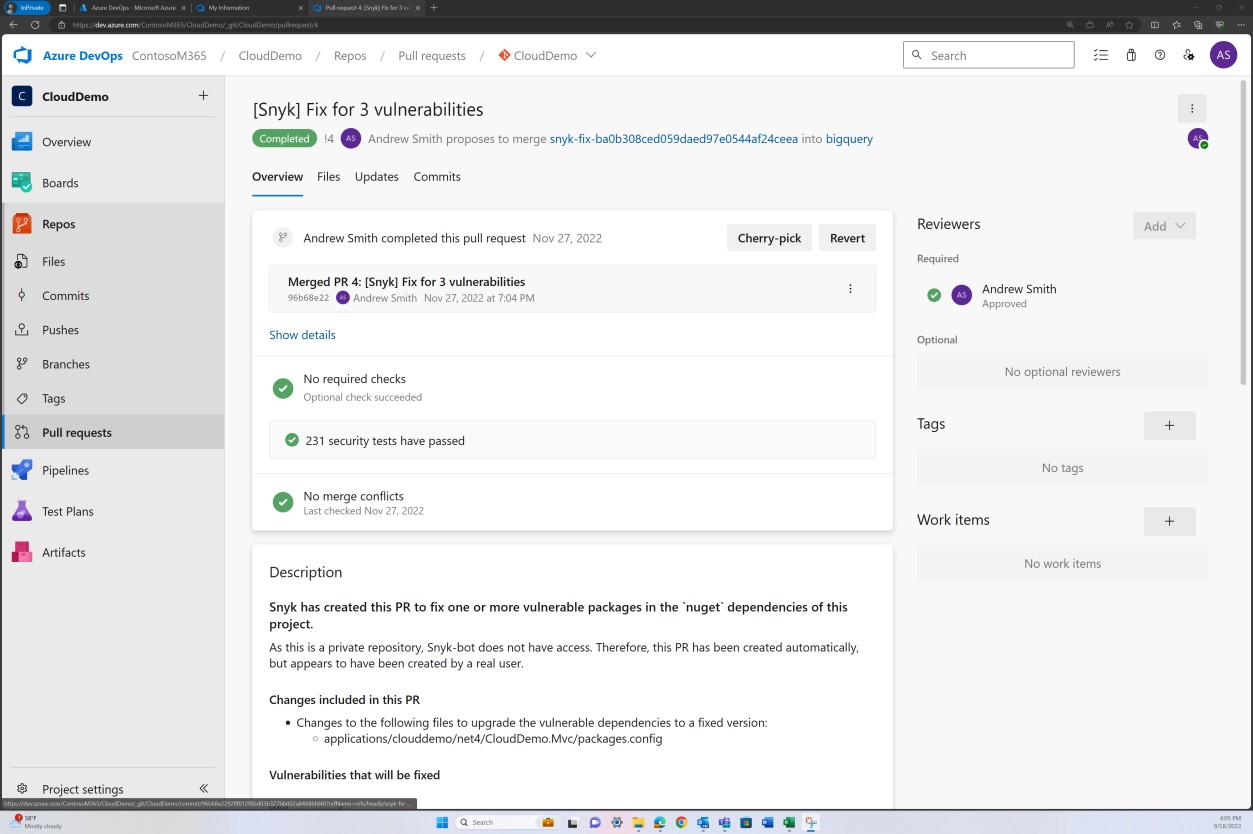
Der nächste Screenshot zeigt, dass die Bibliotheken auf unterstützte Versionen aktualisiert wurden.
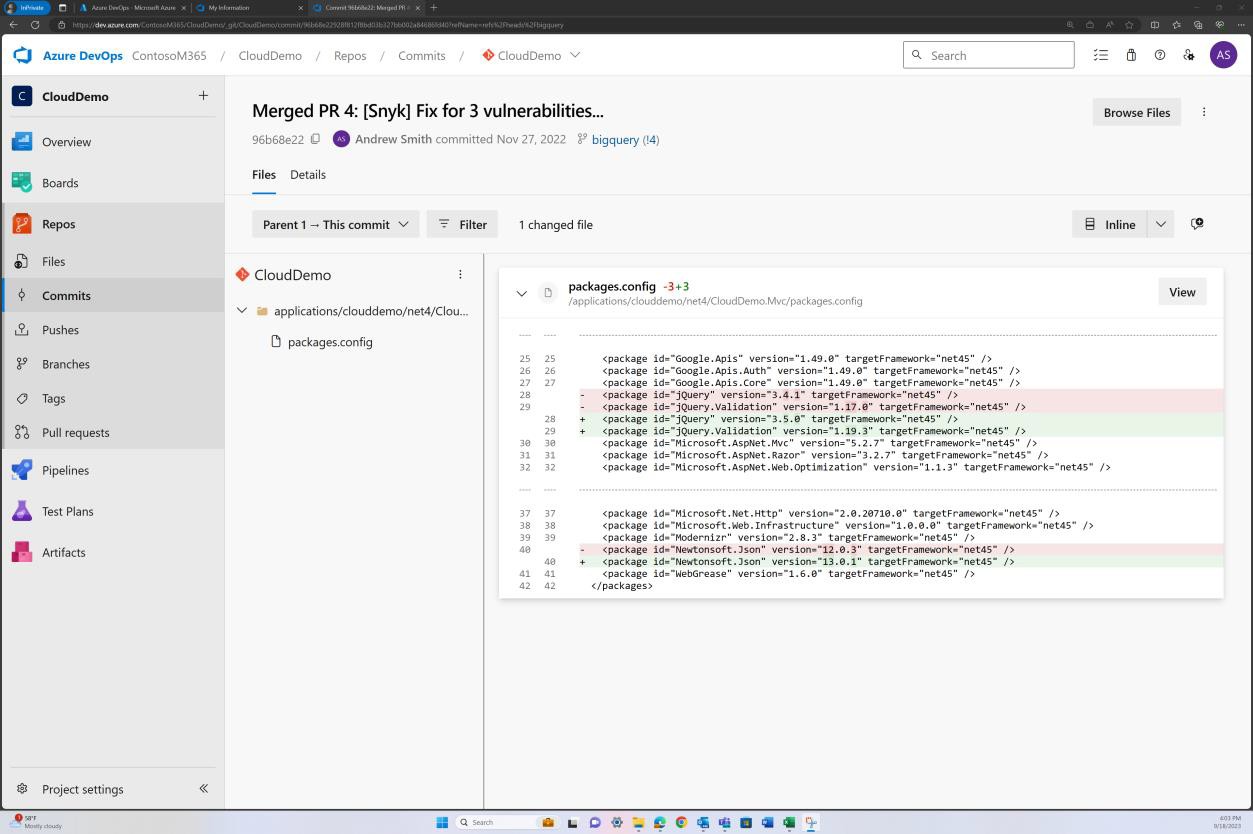
Beispielbeweis
Die nächsten Screenshots zeigen, dass das Patchen der Codebasis über GitHub Dependabot verwaltet wird. Geschlossene Elemente zeigen, dass patchen und Sicherheitsrisiken behoben wurden.
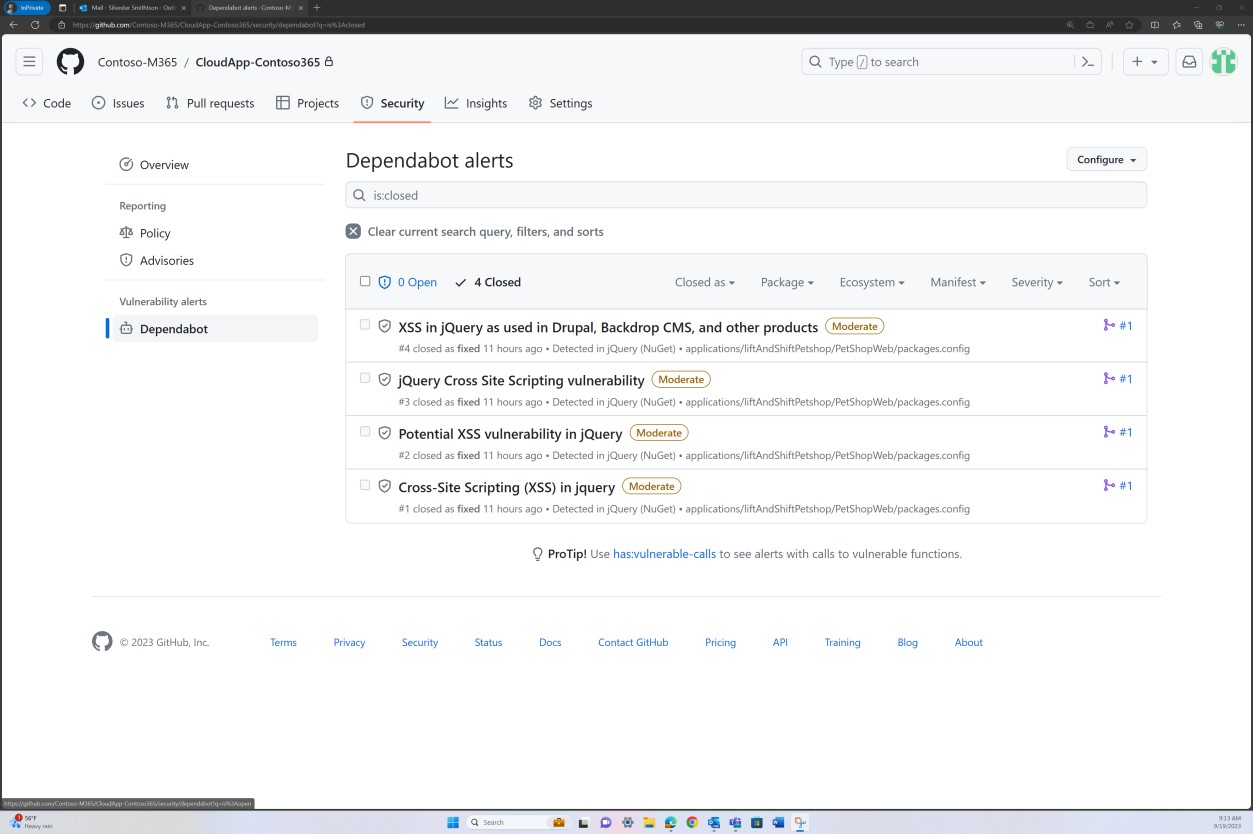
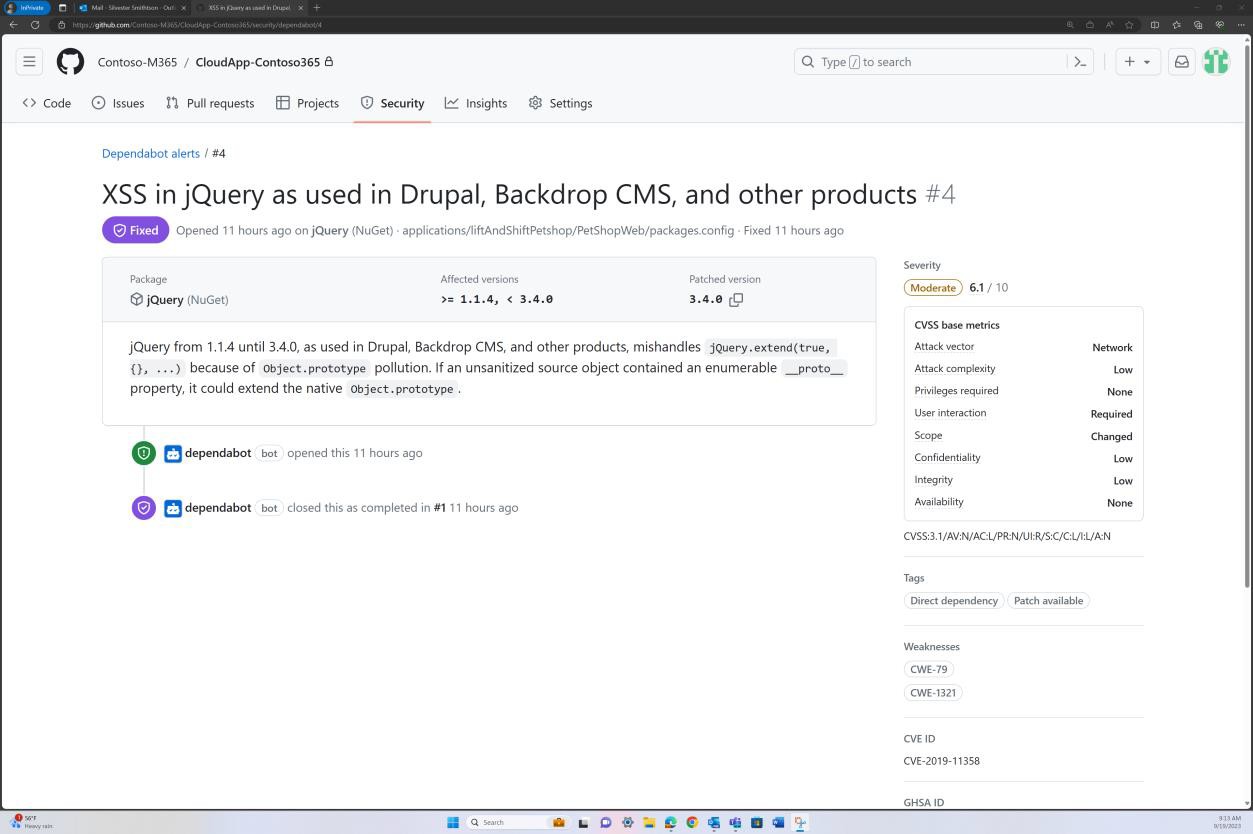
Absicht: nicht unterstütztes Betriebssystem
Software, die nicht von Anbietern gewartet wird, wird im Laufe der Zeit an bekannten Sicherheitsrisiken leiden, die nicht behoben sind. Daher darf die Verwendung nicht unterstützter Betriebssysteme und Softwarekomponenten nicht in Produktionsumgebungen verwendet werden. Wenn Infrastructure-as-a-Service (IaaS) bereitgestellt wird, wird die Anforderung für diesen Unterpunkt erweitert, um sowohl die Infrastruktur als auch die Codebasis einzuschließen, um sicherzustellen, dass jede Ebene des Technologiestapels mit der Richtlinie des organization zur Verwendung unterstützter Software konform ist.
Richtlinien: nicht unterstütztes Betriebssystem
Stellen Sie einen Screenshot für jedes Gerät in der von Ihrem Analysten ausgewählten Beispielgruppe bereit, um Beweise für die Anzeige der ausgeführten Version des Betriebssystems zu sammeln (fügen Sie den Namen des Geräts/Servers in den Screenshot ein). Stellen Sie darüber hinaus den Nachweis bereit, dass Softwarekomponenten, die in der Umgebung ausgeführt werden, unterstützte Versionen der Software ausführen. Dies kann durch die Bereitstellung der Ausgabe interner Berichte zur Überprüfung auf Sicherheitsrisiken (sofern authentifizierte Überprüfungen enthalten sind) und/oder die Ausgabe von Tools zur Überprüfung von Drittanbieterbibliotheken wie Snyk, Trivy oder NPM Audit erfolgen. Bei Ausführung in PaaS muss nur das Patchen von Bibliotheken von Drittanbietern abgedeckt werden.
Beispielbeweis: nicht unterstütztes Betriebssystem
Der nächste Screenshot von Azure DevOps NPM-Überwachung zeigt, dass in der Web-App keine nicht unterstützten Bibliotheken/Abhängigkeiten verwendet werden.
Hinweis: Im nächsten Beispiel wurde kein vollständiger Screenshot verwendet, aber ALLE von ISV übermittelten Beweisscreenshots müssen vollständige Screenshots mit URL, angemeldetem Benutzer und Systemzeit und -datum sein.
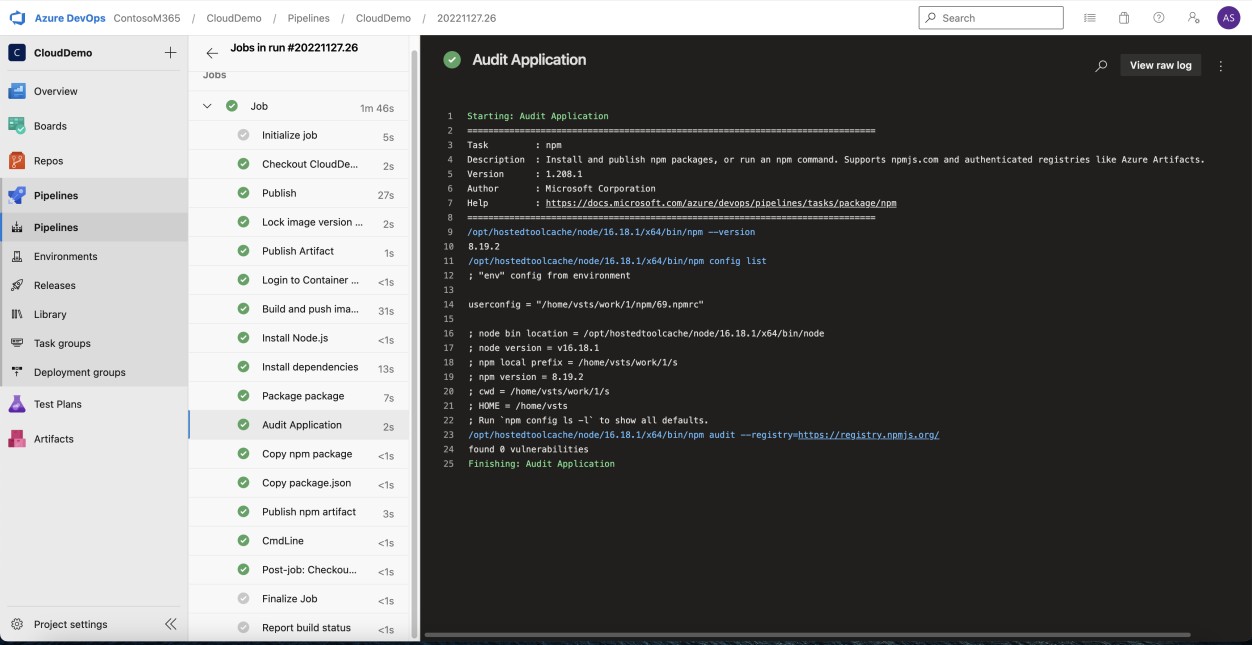
Beispielbeweis
Der nächste Screenshot von GitHub Dependabot zeigt, dass in der Web-App keine Bibliotheken/Abhängigkeiten verwendet werden.
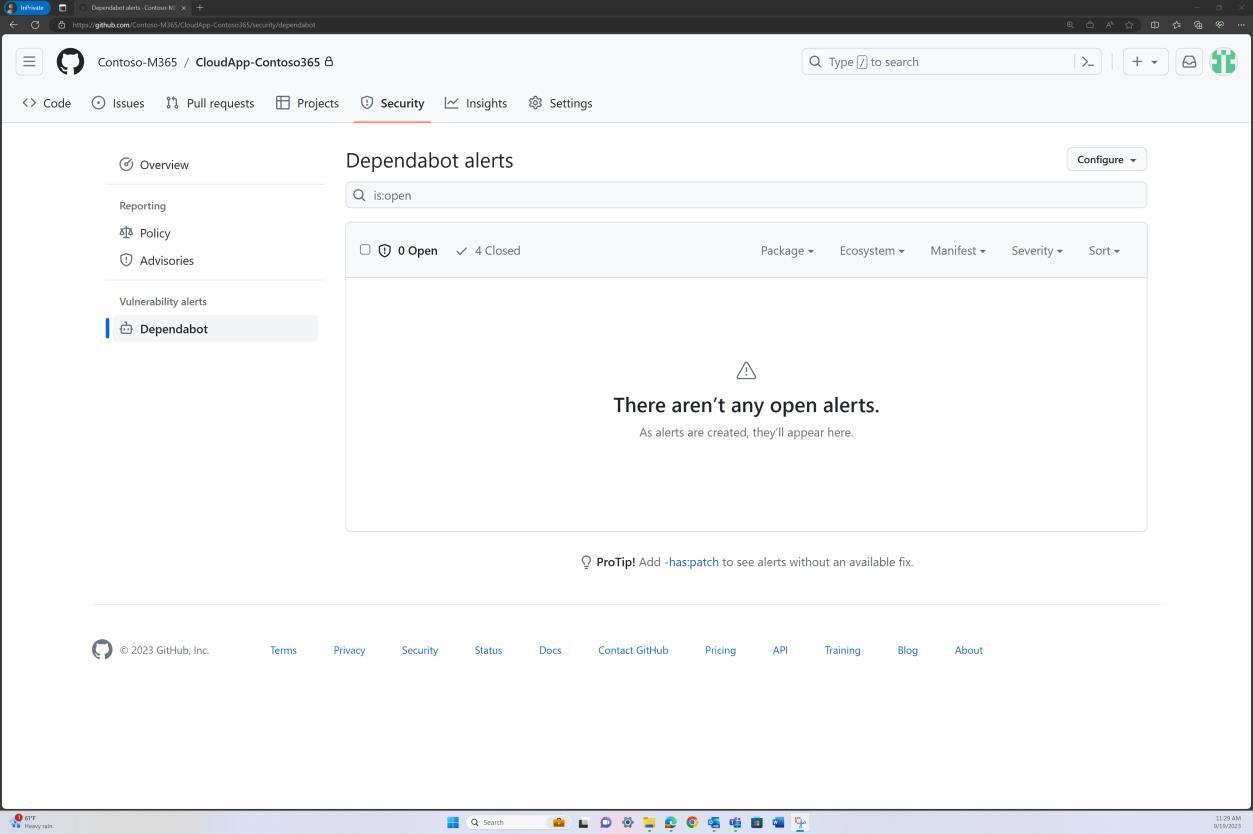
Beispielbeweis
Der nächste Screenshot der Softwareinventur für Windows-Betriebssysteme über OpenEDR zeigt, dass keine nicht unterstützten oder veralteten Betriebssystem- und Softwareversionen gefunden wurden.
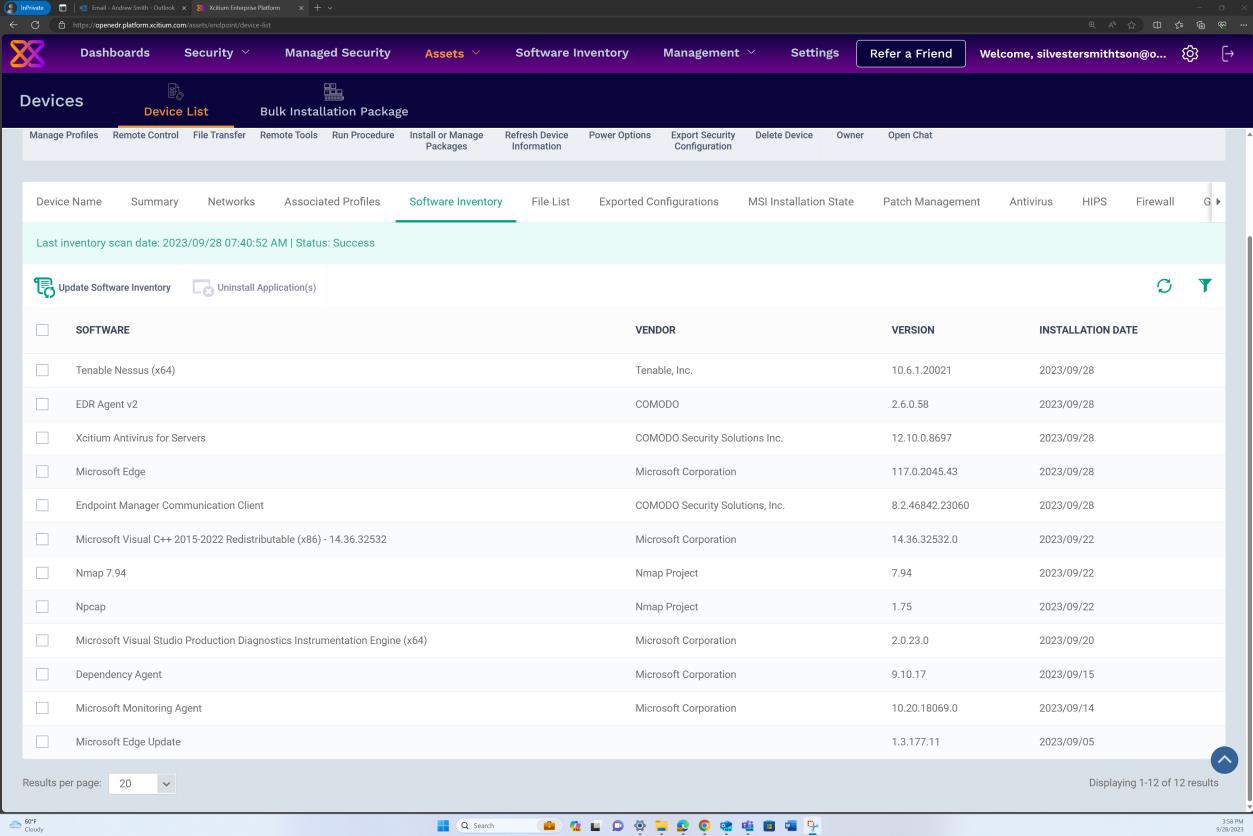
Beispielbeweis
Der nächste Screenshot ist von OpenEDR unter der Betriebssystemzusammenfassung mit Windows Server 2019 Datacenter (x64) und dem Vollständigen Betriebssystemversionsverlauf einschließlich Service Pack, Buildversion usw. Überprüfung, dass kein nicht unterstütztes Betriebssystem gefunden wurde.
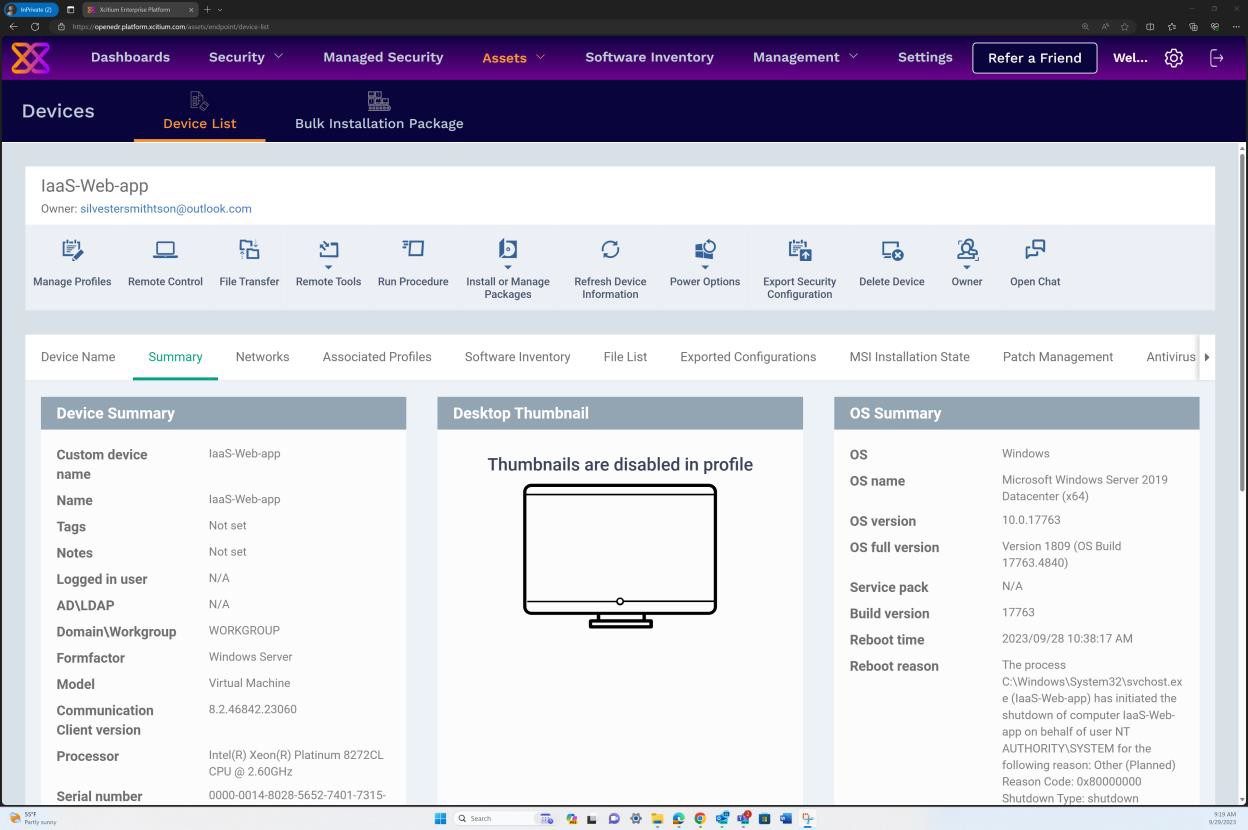
Beispielbeweis
Der nächste Screenshot eines Linux-Betriebssystemservers zeigt alle Versionsdetails, einschließlich Verteiler-ID, Beschreibung, Release und Codename, um zu überprüfen, ob kein nicht unterstütztes Linux-Betriebssystem gefunden wurde.
Beispielbeweis:
Der nächste Screenshot des Nessus-Berichts zur Sicherheitsrisikoüberprüfung zeigt, dass auf dem Zielcomputer kein nicht unterstütztes Betriebssystem und keine Software gefunden wurden.
Bitte beachten Sie: In den vorherigen Beispielen wurde kein vollständiger Screenshot verwendet, aber ALLE von ISV übermittelten Beweisscreenshots müssen vollständige Screenshots mit der URL, allen angemeldeten Benutzern und Systemzeit und -datum sein.
Prüfung auf Schwachstellen
Die Überprüfung auf Sicherheitsrisiken sucht nach möglichen Schwachstellen in einem organization Computersystem, Netzwerken und Webanwendungen, um Löcher zu identifizieren, die möglicherweise zu Sicherheitsverletzungen und der Offenlegung vertraulicher Daten führen könnten. Die Überprüfung auf Sicherheitsrisiken ist häufig durch Branchenstandards und behördliche Vorschriften erforderlich, z. B. pci DSS (Payment Card Industry Data Security Standard).
In einem Bericht von Security Metric mit dem Titel "2020 Security Metrics Guide to PCI DSS Compliance" heißt es: "Im Durchschnitt dauerte es 166 Tage, als ein organization festgestellt wurde, dass ein Angreifer Sicherheitsrisiken hatte, um das System zu kompromittieren. Nach der Kompromittierung hatten Angreifer durchschnittlich 127 Tage Zugriff auf vertrauliche Daten. Diese Kontrolle zielt daher darauf ab, potenzielle Sicherheitsschwächen innerhalb der Umgebung im Gültigkeitsbereich zu identifizieren.
Durch die Einführung regelmäßiger Sicherheitsrisikobewertungen können Organisationen Schwachstellen und Unsicherheiten in ihren Umgebungen erkennen, die einen Einstiegspunkt für böswillige Akteure bieten können, um die Umgebung zu kompromittieren. Die Überprüfung auf Sicherheitsrisiken kann helfen, fehlende Patches oder Fehlkonfigurationen in der Umgebung zu identifizieren. Durch die regelmäßige Durchführung dieser Überprüfungen kann ein organization geeignete Abhilfemaßnahmen bereitstellen, um das Risiko einer Kompromittierung aufgrund von Problemen zu minimieren, die häufig von diesen Tools zur Überprüfung auf Sicherheitsrisiken aufgegriffen werden.
Steuerelement Nr. 6
Stellen Sie Beweise für Folgendes bereit:
Vierteljährliche Überprüfungen auf externe Infrastruktur und Webanwendungen/API-Sicherheitsrisiken werden durchgeführt.
UND, wenn hybrid, lokal oder IaaS ebenfalls Nachweise für Folgendes liefern:
Die Überprüfung muss für den gesamten öffentlichen Speicherbedarf (IPs/URLs) und interne IP-Adressbereiche durchgeführt werden, wenn die Umgebung IaaS, Hybrid oder Lokal ist.
Hinweis: Dies muss den gesamten Bereich der Umgebung umfassen.
Absicht: Überprüfung auf Sicherheitsrisiken
Diese Kontrolle zielt darauf ab, sicherzustellen, dass der organization vierteljährlich Sicherheitsrisikoüberprüfungen durchführt, die sowohl auf seine Infrastruktur als auch auf Webanwendungen ausgerichtet sind. Die Überprüfung muss umfassend sein und sowohl öffentliche Fußabdrücke wie öffentliche IP-Adressen und URLs als auch interne IP-Adressbereiche abdecken. Der Umfang der Überprüfung hängt von der Art der Infrastruktur des organization ab:
Wenn ein organization hybride, lokale oder IaaS-Modelle (Infrastructure-as-a-Service) implementiert, muss die Überprüfung sowohl externe öffentliche IP-Adressen/URLs als auch interne IP-Adressbereiche umfassen.
Wenn ein organization PaaS (Platform-as-a-Service) implementiert, darf die Überprüfung nur externe öffentliche IP-Adressen/URLs umfassen.
Dieses Steuerelement schreibt außerdem vor, dass die Überprüfung den gesamten Bereich der Umgebung umfassen soll, sodass keine Komponente deaktiviert wird. Das Ziel besteht darin, Sicherheitsrisiken in allen Teilen des Technologiestapels des organization zu identifizieren und zu bewerten, um eine umfassende Sicherheit zu gewährleisten.
Richtlinien: Überprüfung auf Sicherheitsrisiken
Stellen Sie die vollständigen Überprüfungsberichte für die Sicherheitsrisikoüberprüfungen jedes Quartals bereit, die in den letzten 12 Monaten durchgeführt wurden. In den Berichten sollten die Ziele klar angegeben werden, um zu überprüfen, ob der vollständige öffentliche Speicherbedarf und ggf. jedes interne Subnetz enthalten ist. Geben Sie ALLE Überprüfungsberichte für JEDES Quartal an.
Beispielbeweis: Überprüfung auf Sicherheitsrisiken
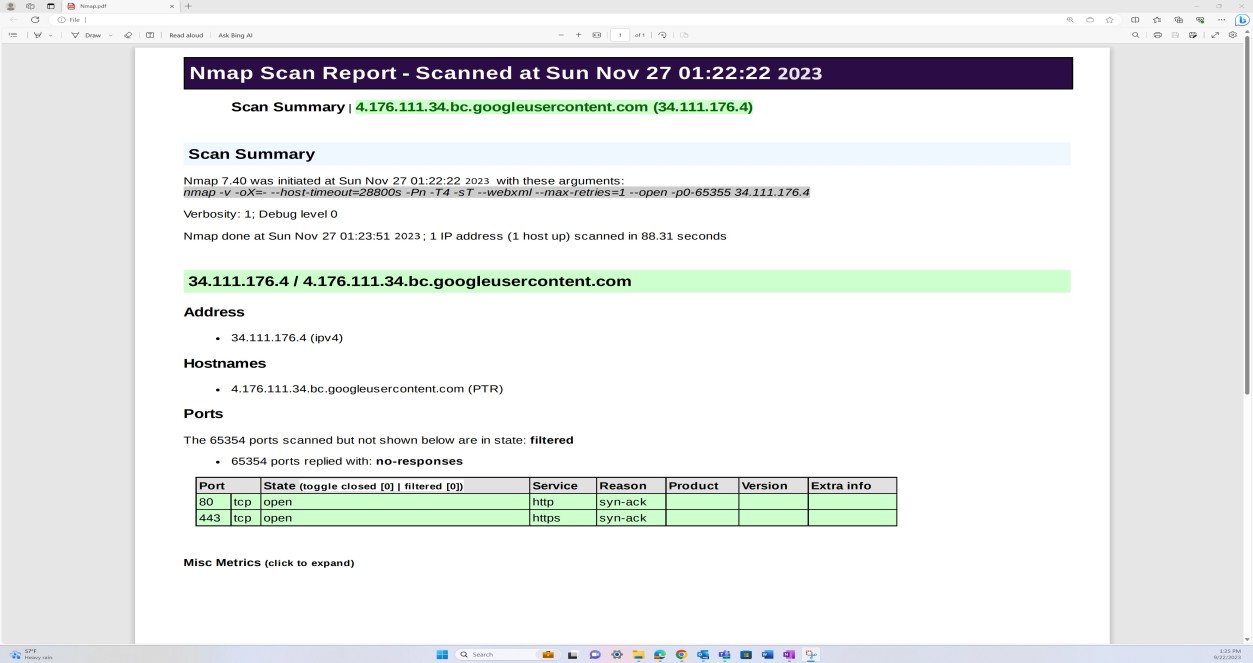
Der nächste Screenshot zeigt eine Netzwerkermittlung und eine Portüberprüfung, die über Nmap in der externen Infrastruktur ausgeführt werden, um ungesicherte offene Ports zu identifizieren.
Hinweis: Nmap allein kann nicht verwendet werden, um dieses Steuerelement zu erfüllen, da erwartet wird, dass eine vollständige Überprüfung auf Sicherheitsrisiken bereitgestellt werden muss. Die Nmap-Portermittlung ist Teil des unten gezeigten Prozesses zur Verwaltung von Sicherheitsrisiken und wird durch OpenVAS- und OWASP ZAP-Scans für die externe Infrastruktur ergänzt.
Der Screenshot zeigt die Überprüfung von Sicherheitsrisiken über OpenVAS für die externe Infrastruktur, um Fehlkonfigurationen und ausstehende Sicherheitsrisiken zu identifizieren.
Der nächste Screenshot zeigt den Bericht zur Überprüfung auf Sicherheitsrisiken von OWASP ZAP, der dynamische Anwendungssicherheitstests veranschaulicht.
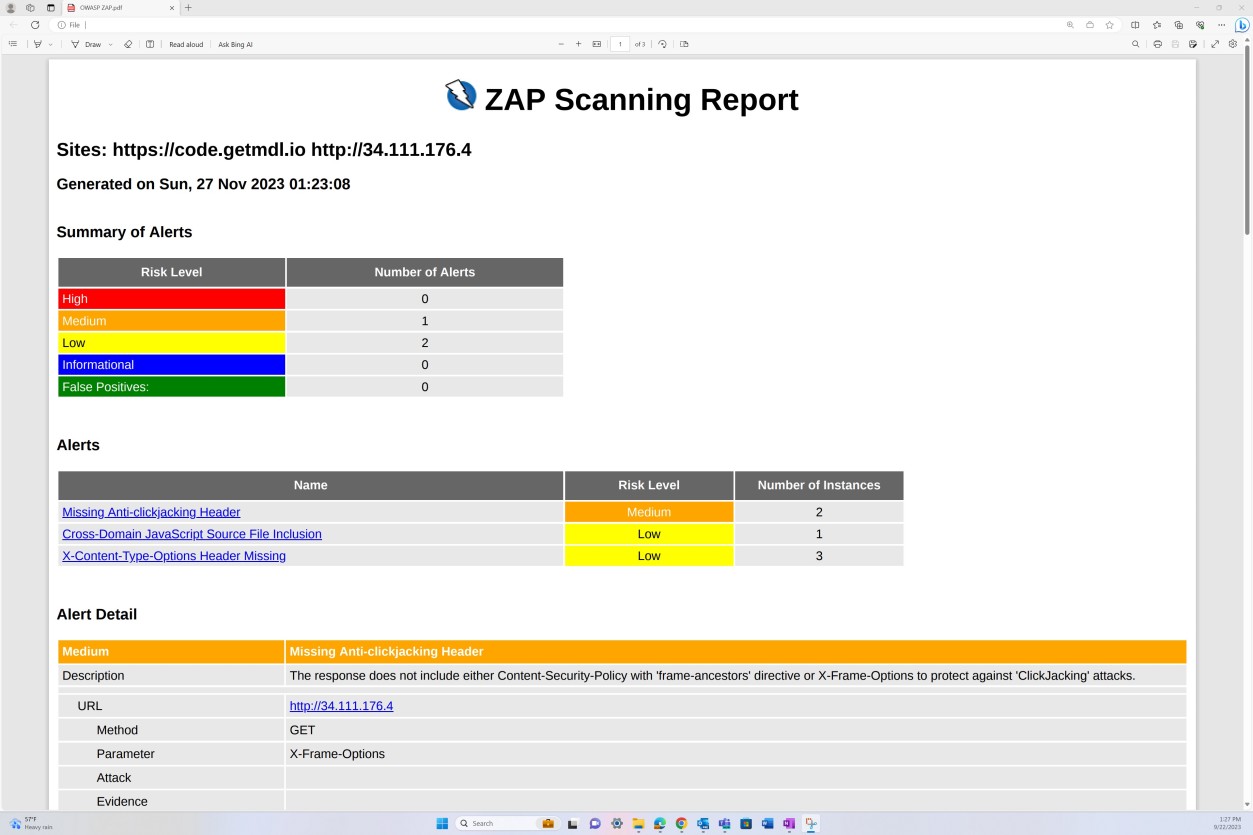
Beispielbeweis: Überprüfung auf Sicherheitsrisiken
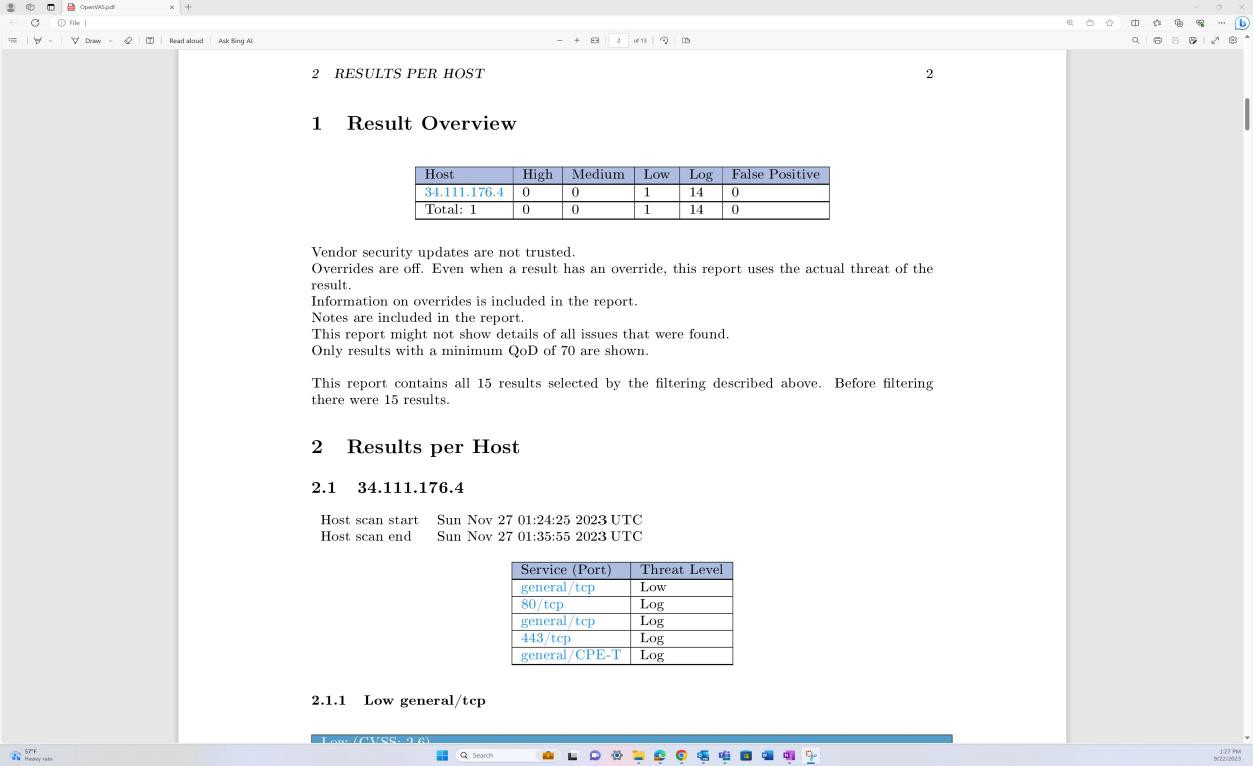
Die folgenden Screenshots aus dem Tenable Nessus Essentials-Bericht zur Überprüfung auf Sicherheitsrisiken zeigen, dass eine interne Infrastrukturüberprüfung durchgeführt wird.
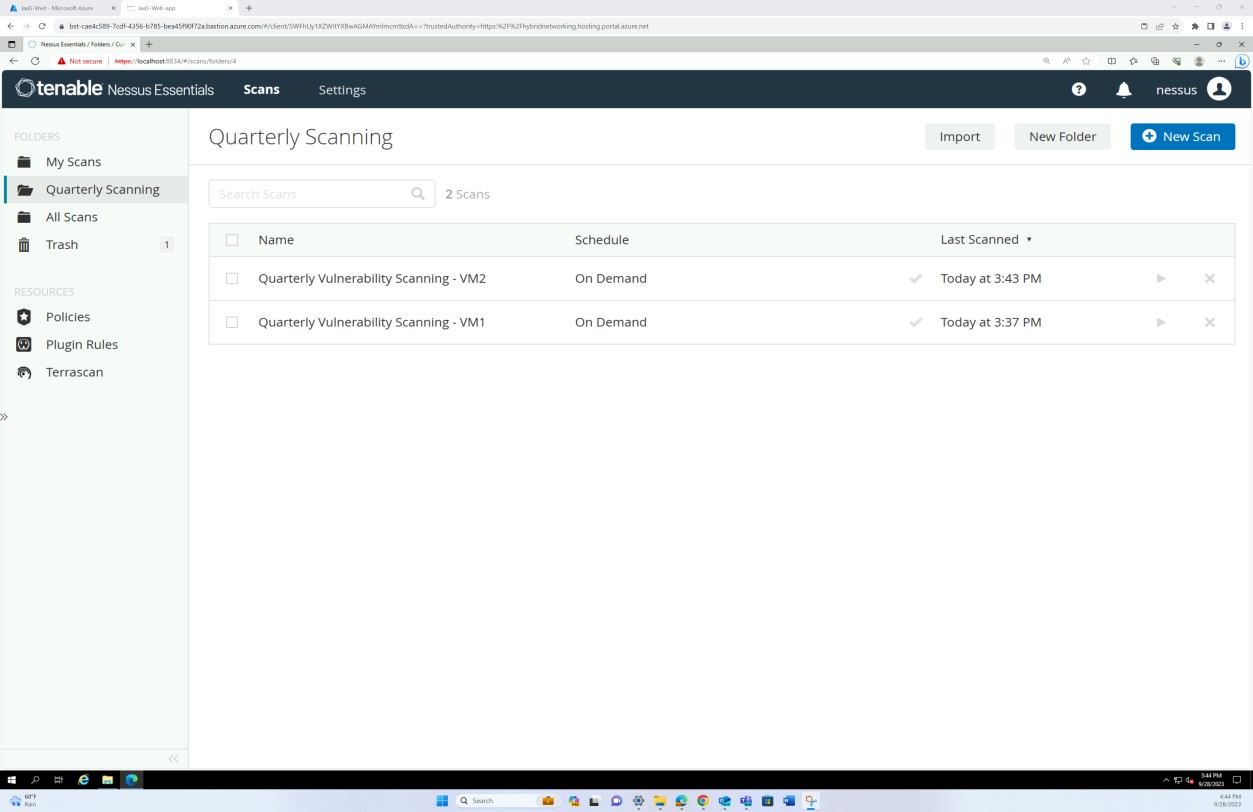
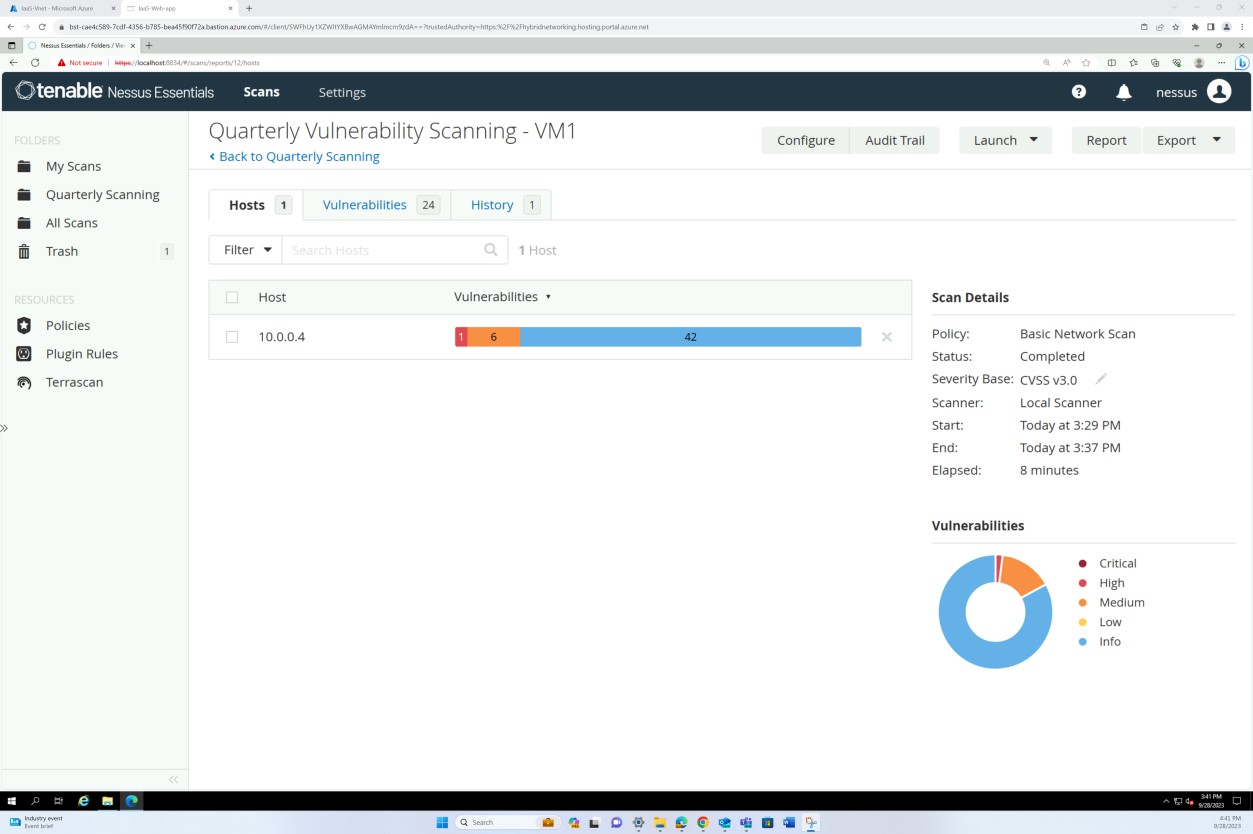
Die vorherigen Screenshots veranschaulichen die Ordner, die für vierteljährliche Überprüfungen der Host-VMs eingerichtet wurden.
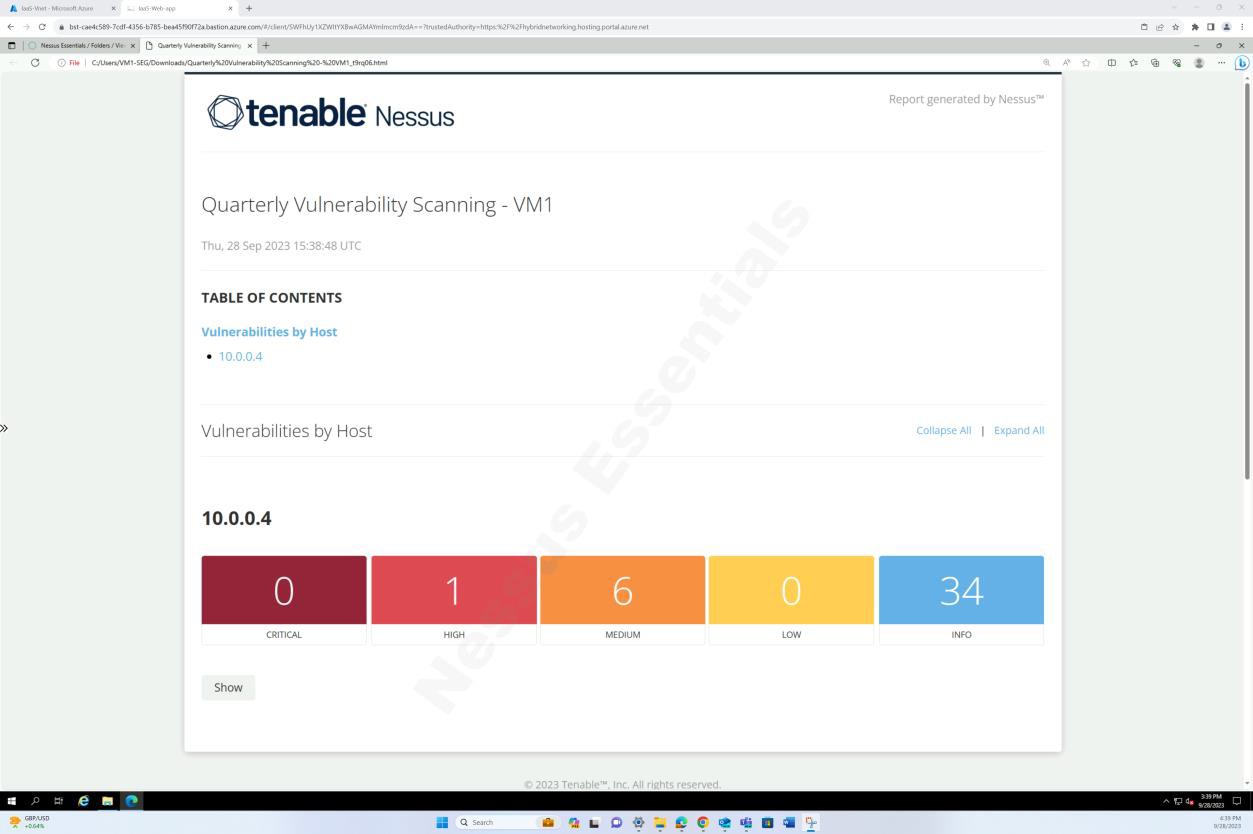
Die Screenshots oben und unten zeigen die Ausgabe des Berichts zur Überprüfung auf Sicherheitsrisiken.
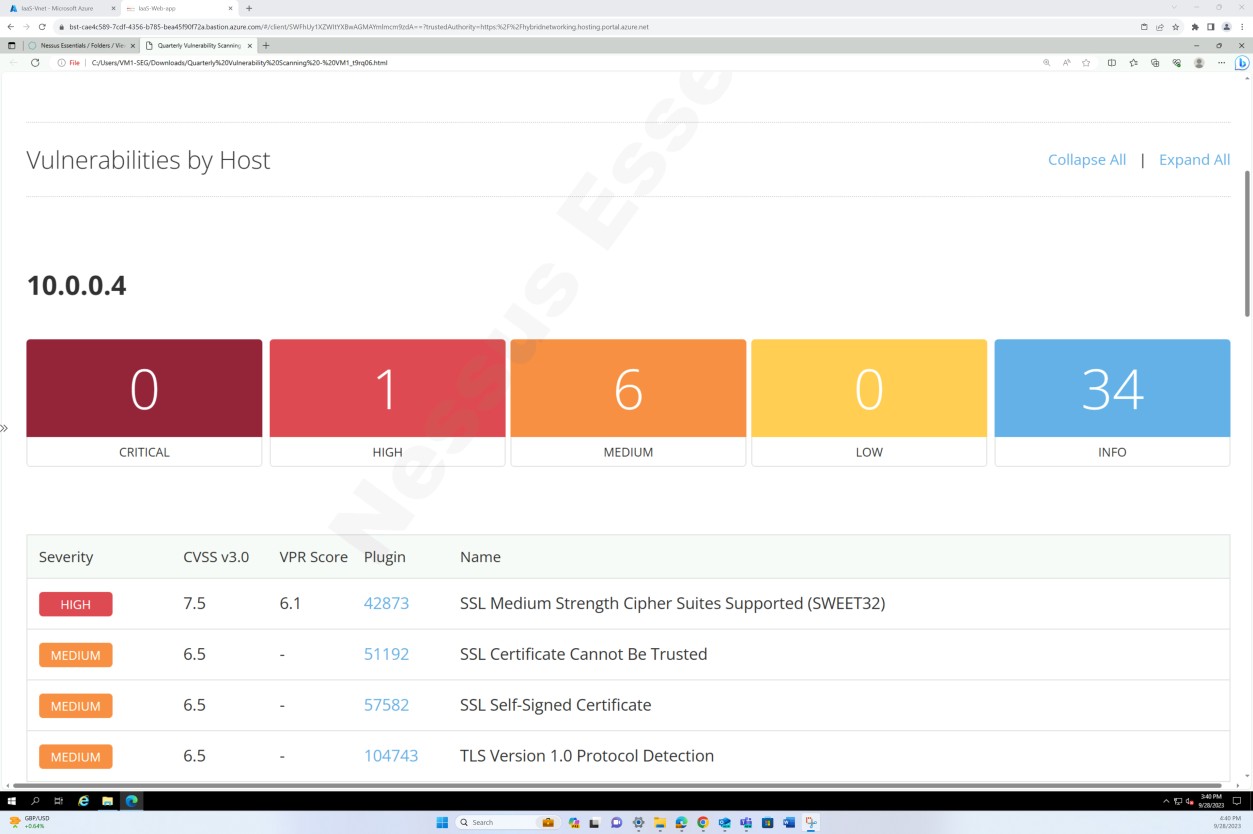
Der nächste Screenshot zeigt die Fortsetzung des Berichts, der alle gefundenen Probleme abdeckt.
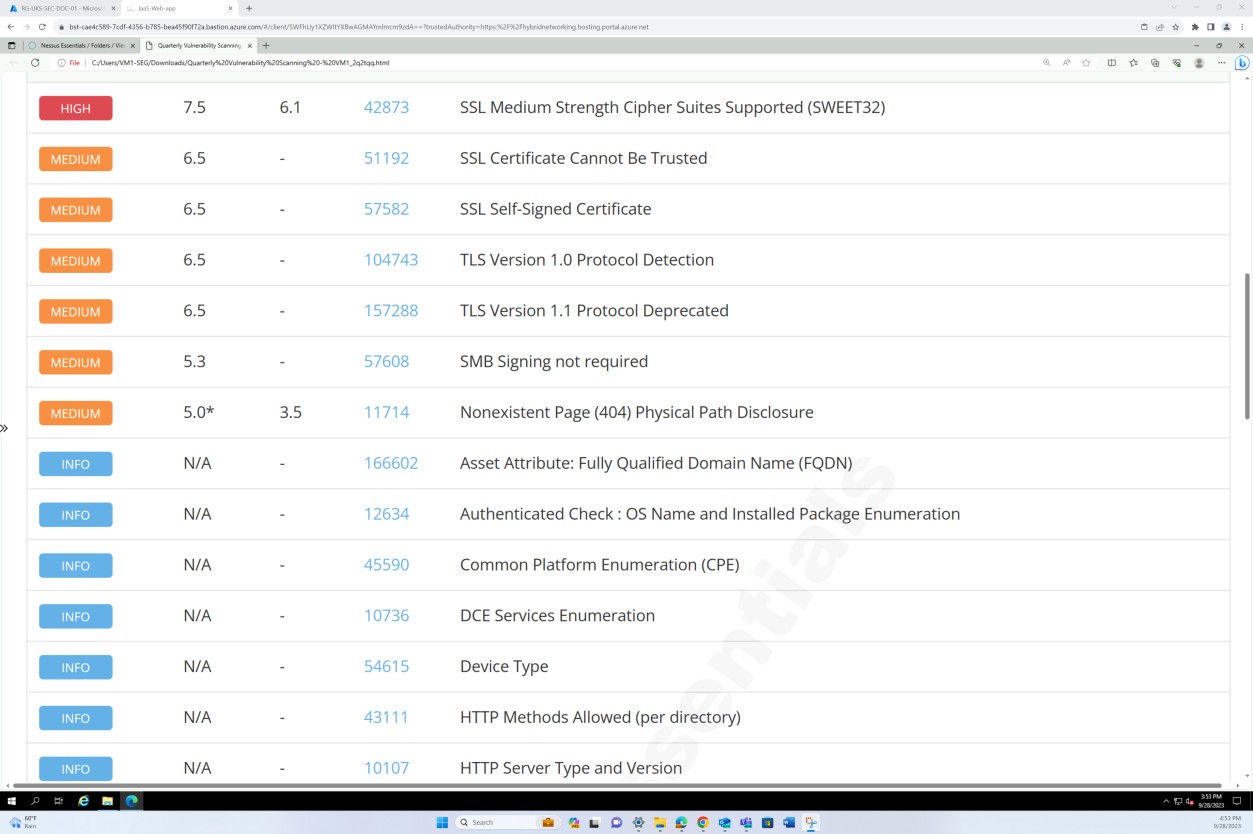
Steuerelement Nr. 7
HARTER FEHLER
Stellen Sie einen Nachweis für folgendes Erneutes Scannen bereit:
- Die Behebung aller in der vorherigen Kontrolle identifizierten Sicherheitsrisiken wird inline mit dem minimalen Patchfenster gepatcht, das in Ihrer Richtlinie definiert ist.
Absicht: Patchen
Wenn Sicherheitsrisiken und Fehlkonfigurationen nicht schnell erkannt, verwaltet und behoben werden, kann dies das Risiko einer kompromittierten Organization erhöhen, was zu potenziellen Datenschutzverletzungen führt. Die korrekte Identifizierung und Behebung von Problemen wird als wichtig für den gesamten Sicherheitsstatus und die Umgebung eines organization angesehen, was mit den bewährten Methoden verschiedener Sicherheitsframeworks wie ISO 27001 und PCI-DSS in Einklang steht.
Mit dieser Kontrolle soll sichergestellt werden, dass die organization glaubwürdige Beweise für erneute Überprüfungen liefert, die belegen, dass alle in Control 6 identifizierten Sicherheitsrisiken behoben wurden. Die Korrektur muss mit dem minimalen Patchfenster übereinstimmen, das in der Patchverwaltungsrichtlinie des organization definiert ist.
Richtlinien: Patchen
Stellen Sie Berichte zur erneuten Überprüfung bereit, in denen überprüft wird, dass alle in Steuerelement 6 identifizierten Sicherheitsrisiken gemäß den in Steuerelement 4 definierten Patchfenstern behoben wurden.
Beispielbeweis: Patchen
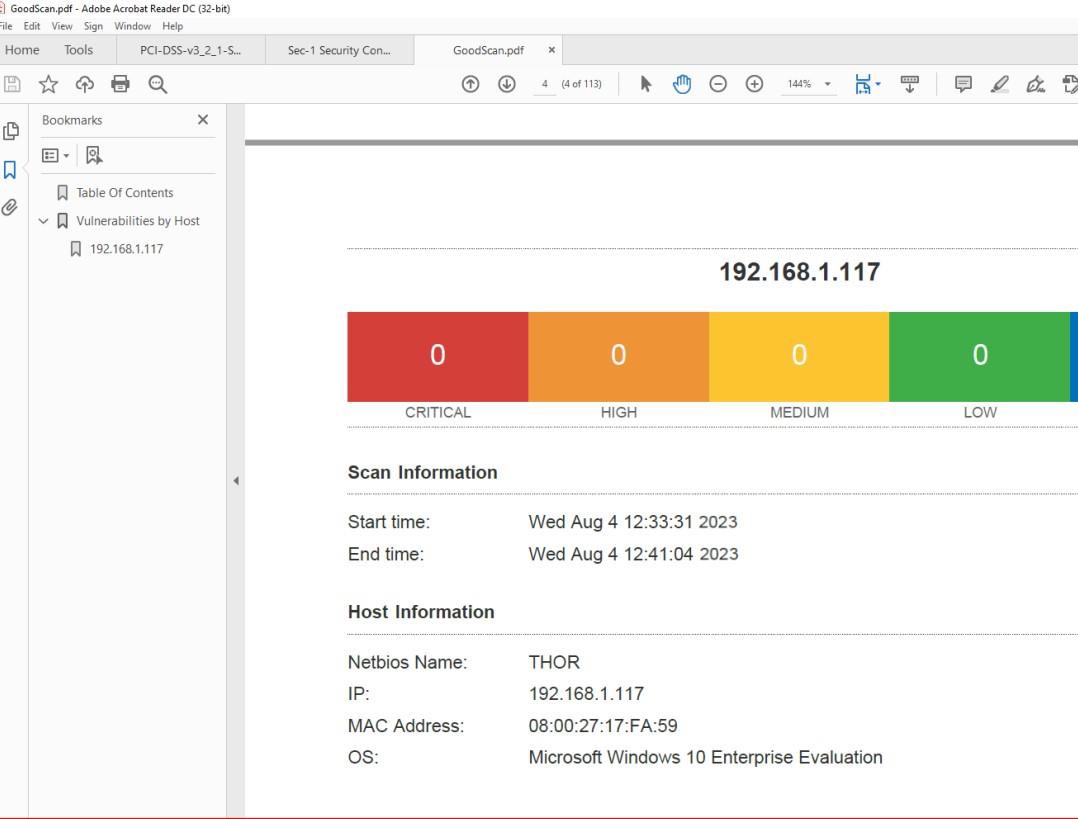
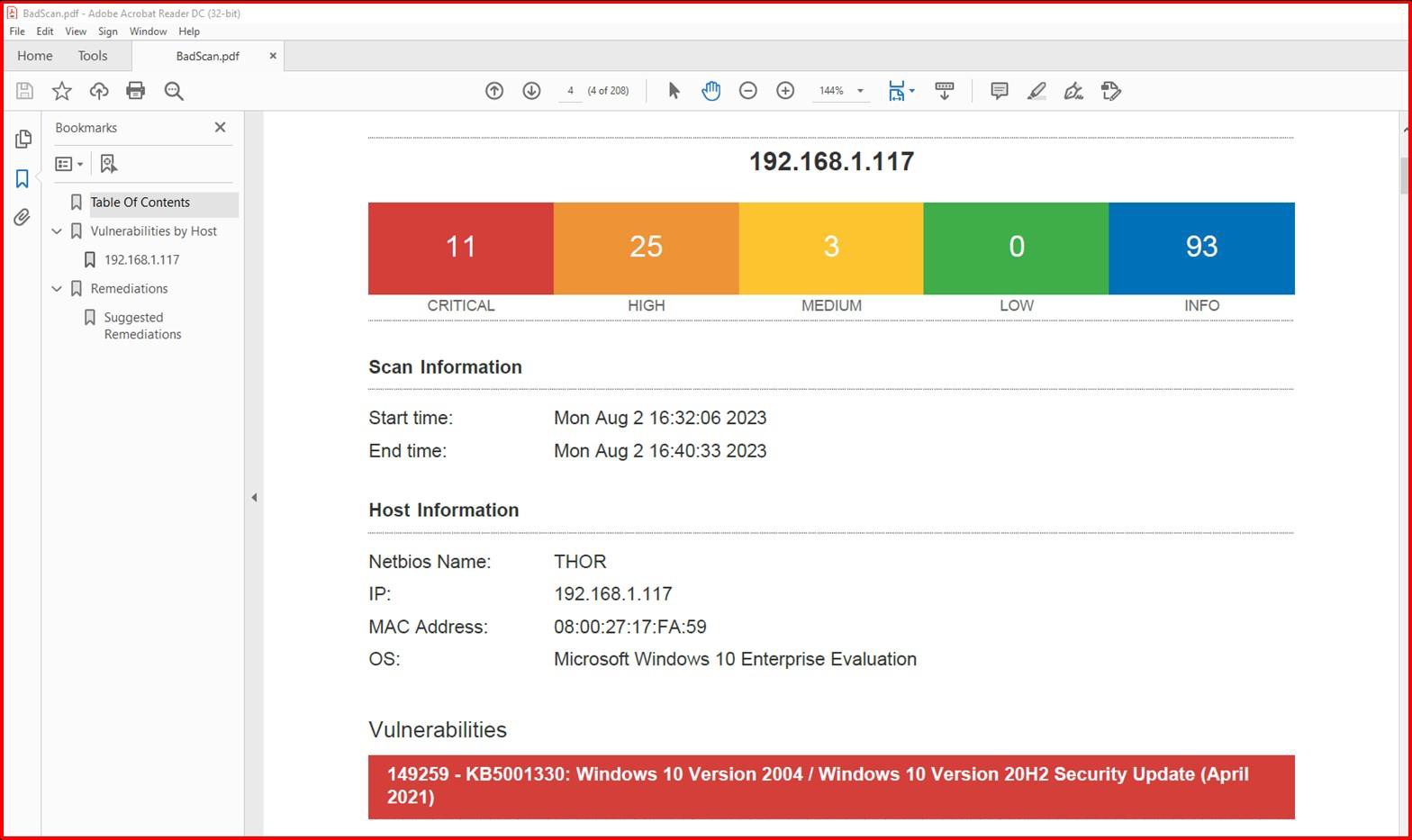
Der nächste Screenshot zeigt eine Nessus-Überprüfung der Bereichsumgebung (ein einzelner Computer mit dem Namen Thor) mit Sicherheitsrisiken am 2.August 2023.
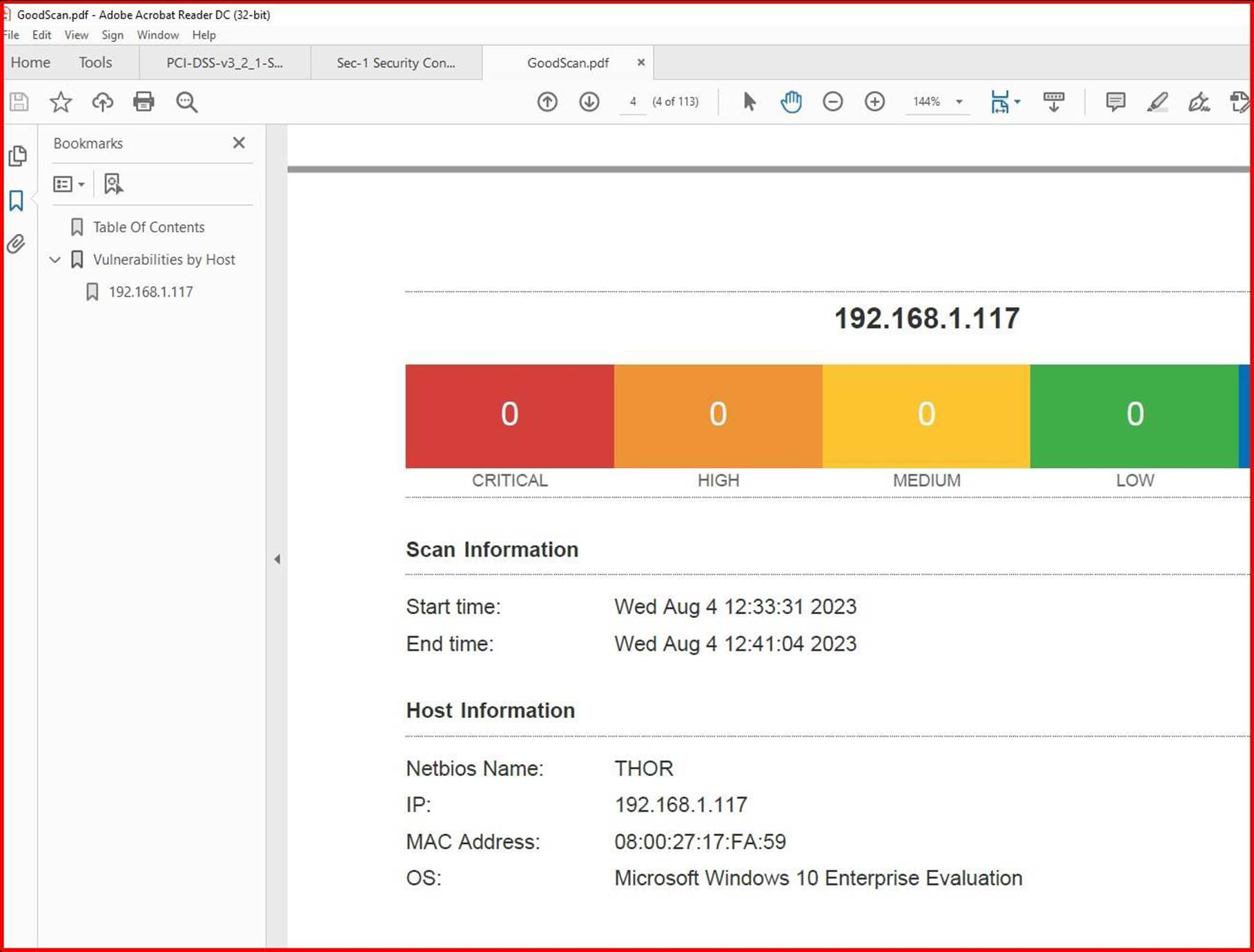
Der nächste Screenshot zeigt, dass die Probleme behoben wurden, 2 Tage später innerhalb des Patchfensters, das innerhalb der Patchrichtlinie definiert ist.
Hinweis: In den vorherigen Beispielen wurde kein vollständiger Screenshot verwendet, aber ALLE ISV übermittelt
Beweisscreenshots müssen vollständige Screenshots mit einer beliebigen URL, einem angemeldeten Benutzer und der Systemzeit und dem Systemdatum sein.
Netzwerksicherheitskontrollen (Network Security Controls, NSC)
Netzwerksicherheitskontrollen sind ein wesentlicher Bestandteil von Cybersicherheitsframeworks wie ISO 27001, CIS-Kontrollen und NIST Cybersecurity Framework. Sie helfen Organisationen dabei, Risiken im Zusammenhang mit Cyberbedrohungen zu bewältigen, vertrauliche Daten vor unbefugtem Zugriff zu schützen, gesetzliche Anforderungen einzuhalten, Cyberbedrohungen rechtzeitig zu erkennen und darauf zu reagieren und die Geschäftskontinuität sicherzustellen. Effektive Netzwerksicherheit schützt Organisationsressourcen vor einer Vielzahl von Bedrohungen innerhalb oder außerhalb der organization.
Steuerung Nr. 8
HARTER FEHLER
Stellen Sie Beweise für Folgendes bereit:
Netzwerksicherheitskontrollen (Network Security Controls, NSCs) werden an der Grenze der bereichsinternen Umgebung installiert, z. B.:
zwischen dem Internet und der In-Scope-Umgebung und/oder
zwischen weniger vertrauenswürdigen Netzwerken oder Systemen und der bereichsinternen Umgebung.
UND, wenn hybrid, lokal oder IaaS ebenfalls Nachweise für Folgendes liefern:
- Falls zutreffend, werden alle Systemkomponenten mit öffentlichen IP-Adressen entsprechend von allen anderen internen Systemkomponenten mit NSCs segmentiert.
Hinweis: NSCs beziehen sich auf Firewalls, Netzwerksicherheitsgruppen (NSGs), Sicherheitsgruppen (SGs), WAFs usw. Für diese Steuerung sind NSCs Technologien, die den Datenverkehr zwischen Netzwerken oder Systemen mit unterschiedlichen Sicherheitsstufen steuern, d. h. einer DMZ und dem internen Netzwerk, einem öffentlichen Netzwerk und dem internen Netzwerk, einem frontseitigen Webserver und einem Datenbankserver.
Absicht: NSC
Diese Kontrolle soll bestätigen, dass Netzwerksicherheitskontrollen (Network Security Controls, NSC) an wichtigen Stellen innerhalb der Netzwerktopologie des organization installiert sind. Insbesondere müssen NSCs an der Grenze der bereichsinternen Umgebung und zwischen dem Umkreisnetzwerk und den internen Netzwerken platziert werden. Mit dieser Kontrolle soll bestätigt werden, dass diese Sicherheitsmechanismen korrekt sind, um ihre Wirksamkeit beim Schutz der digitalen Ressourcen der organization zu maximieren.
Richtlinien: NSC
Es sollte nachgewiesen werden, dass Netzwerksicherheitskontrollen (Network Security Controls, NSC) an der Grenze installiert und zwischen Umkreisnetzwerken und internen Netzwerken konfiguriert sind. Dies kann erreicht werden, indem Sie die Screenshots aus den Konfigurationseinstellungen der Netzwerksicherheitskontrollen (Network Security Controls, NSC) und den Bereich bereitstellen, auf den sie angewendet wird, z. B. eine Firewall oder eine entsprechende Technologie wie Azure Netzwerksicherheitsgruppen (NSGs), Azure Front Door usw.
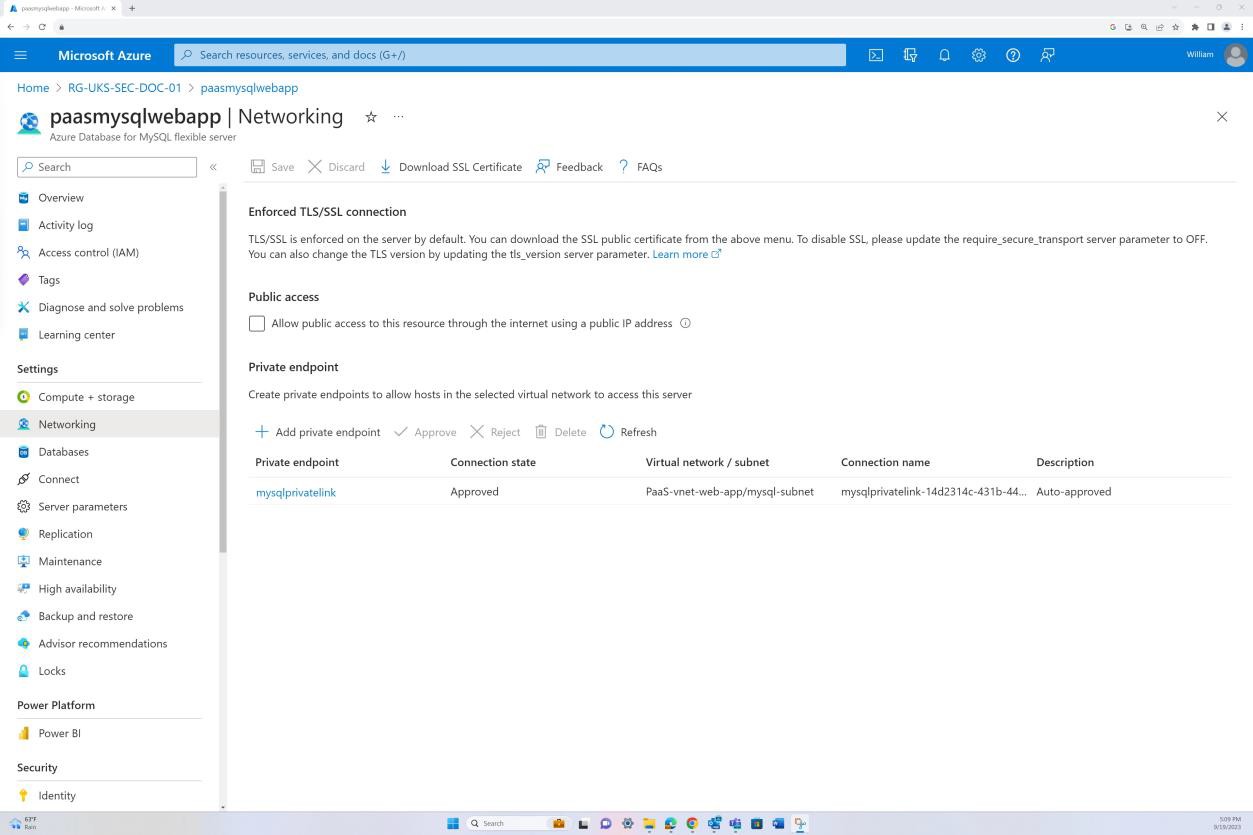
Beispielbeweis: NSC
Der nächste Screenshot stammt aus der Web-App "PaaS-web-app". Das Blatt "Netzwerk" zeigt, dass der gesamte eingehende Datenverkehr über Azure Front Door geleitet wird, während der gesamte Datenverkehr von der Anwendung zu anderen Azure Ressourcen über die Azure NSG über die VNET-Integration weitergeleitet und gefiltert wird.
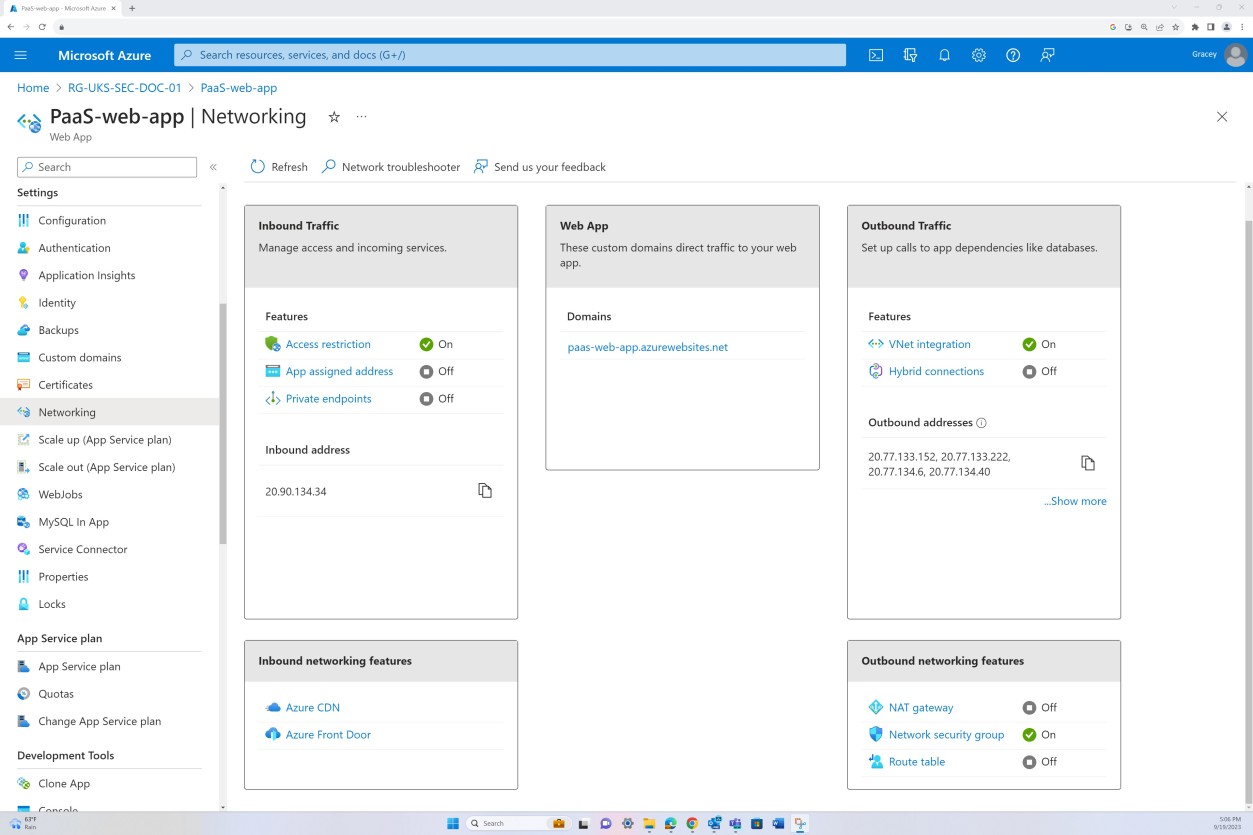
Ablehnungsregeln innerhalb der "Zugriffseinschränkungen" verhindern eingehenden Datenverkehr mit Ausnahme von Front Door (FD). Der Datenverkehr wird über FD weitergeleitet, bevor er die Anwendung erreicht.
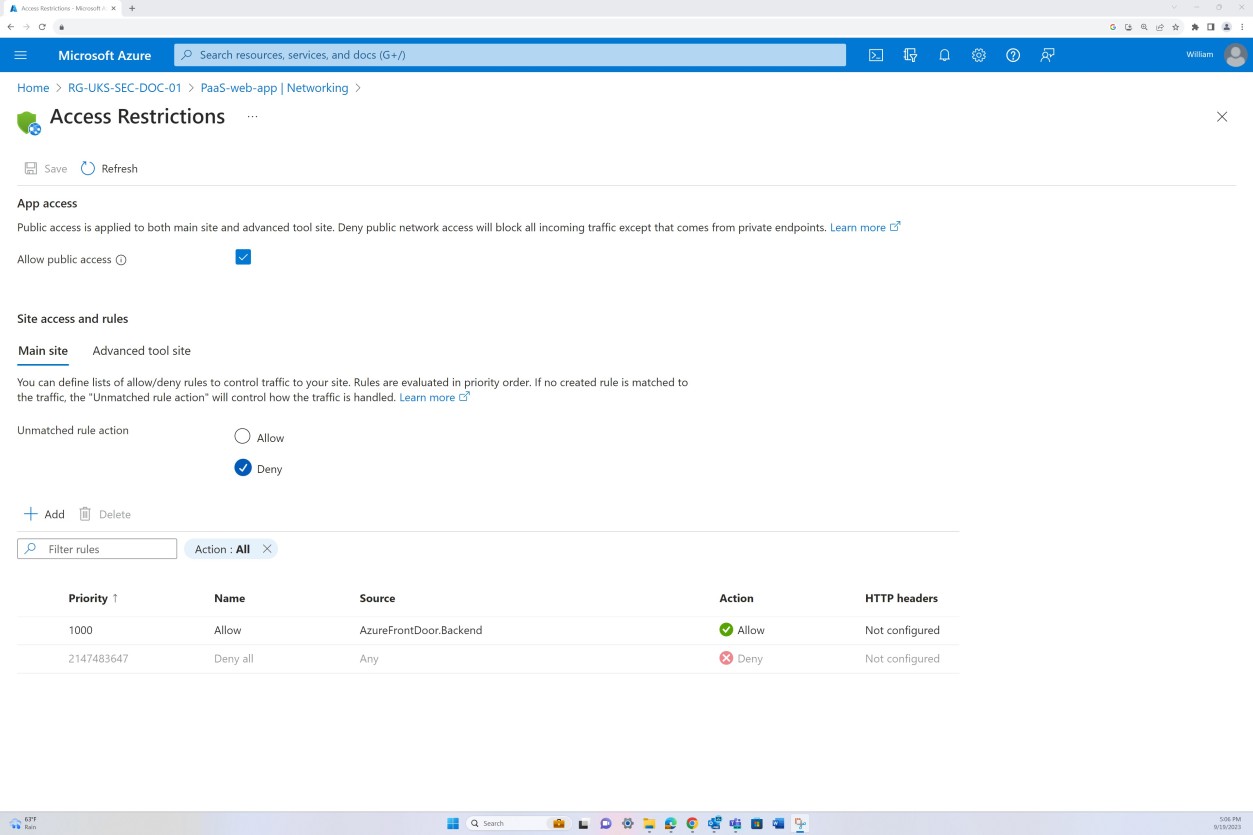

Beispielbeweis: NSC
Der folgende Screenshot zeigt Azure Standardroute von Front Door und dass der Datenverkehr über Front Door weitergeleitet wird, bevor er die Anwendung erreicht. Die WAF-Richtlinie wurde ebenfalls angewendet.
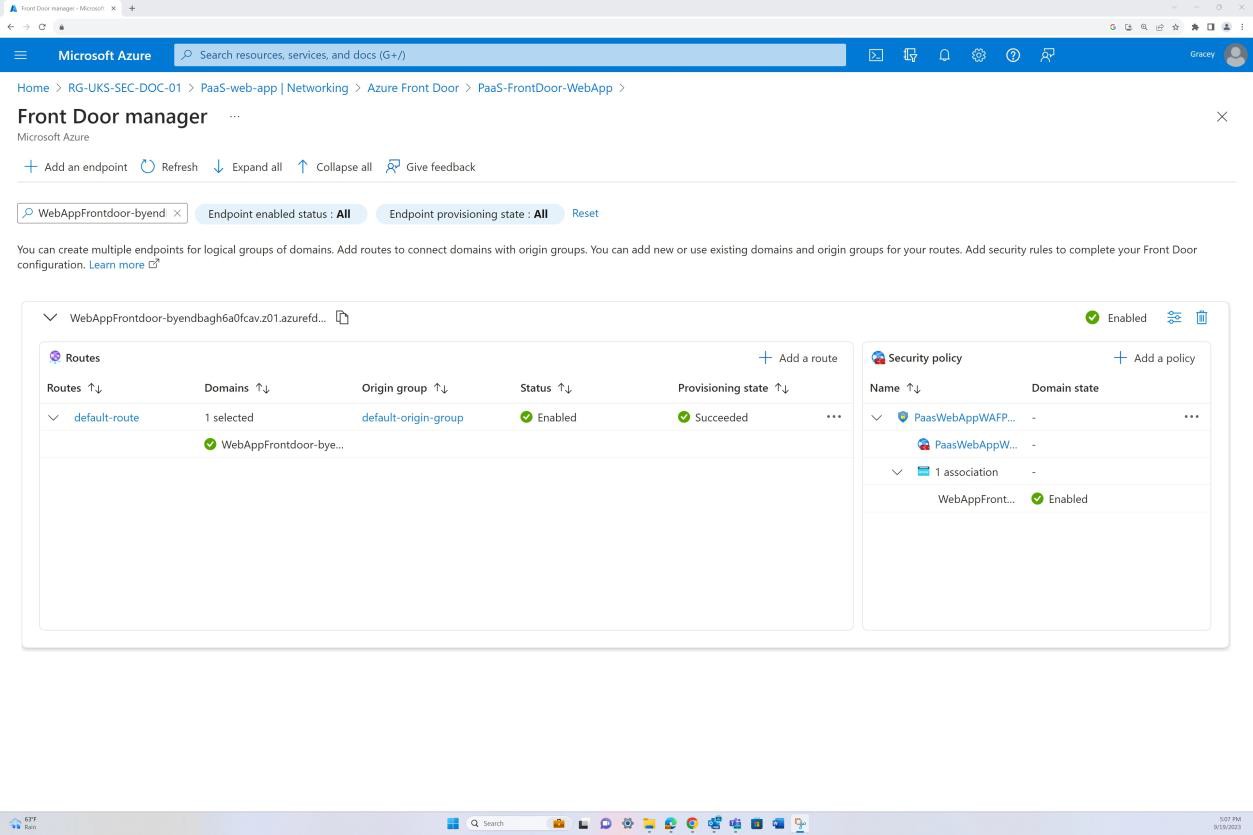
Beispielbeweis: NSC
Der erste Screenshot zeigt eine Azure Netzwerksicherheitsgruppe, die auf VNET-Ebene angewendet wird, um eingehenden und ausgehenden Datenverkehr zu filtern. Der zweite Screenshot zeigt, dass SQL Server nicht über das Internet routingfähig ist und über das VNET und über eine private Verbindung integriert ist.
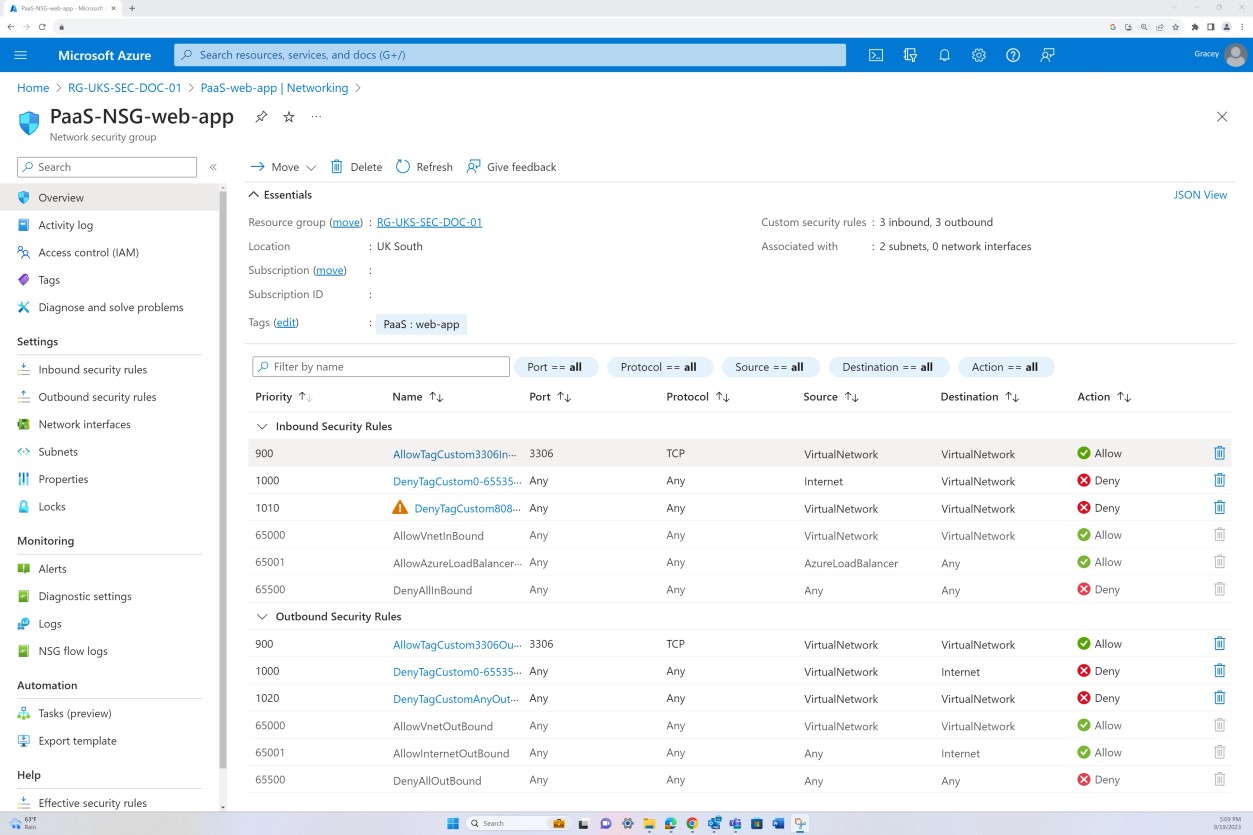
Dadurch wird sichergestellt, dass der interne Datenverkehr und die interne Kommunikation von der NSG gefiltert werden, bevor der SQL Server erreicht wird.
Intent**:** hybrid, lokal, IaaS
Dieser Unterpunkt ist wichtig für Organisationen, die Hybrid-, lokale oder IaaS-Modelle (Infrastructure-as-a-Service) betreiben. Es soll sichergestellt werden, dass der gesamte öffentliche Zugriff auf das Umkreisnetzwerk endet, was für die Steuerung der Eintrittspunkte in das interne Netzwerk und die Verringerung der potenziellen Gefährdung durch externe Bedrohungen von entscheidender Bedeutung ist. Nachweise für die Konformität können Firewallkonfigurationen, Netzwerkzugriffssteuerungslisten oder andere ähnliche Dokumentationen sein, die die Behauptung untermauern können, dass der öffentliche Zugriff nicht über das Umkreisnetzwerk hinausgeht.
Beispielbeweis: Hybrid, lokal, IaaS
Der Screenshot zeigt, dass SQL Server nicht über das Internet routingfähig ist und über das VNET und über eine private Verbindung integriert ist. Dadurch wird sichergestellt, dass nur interner Datenverkehr zulässig ist.
Beispielbeweis: Hybrid, lokal, IaaS
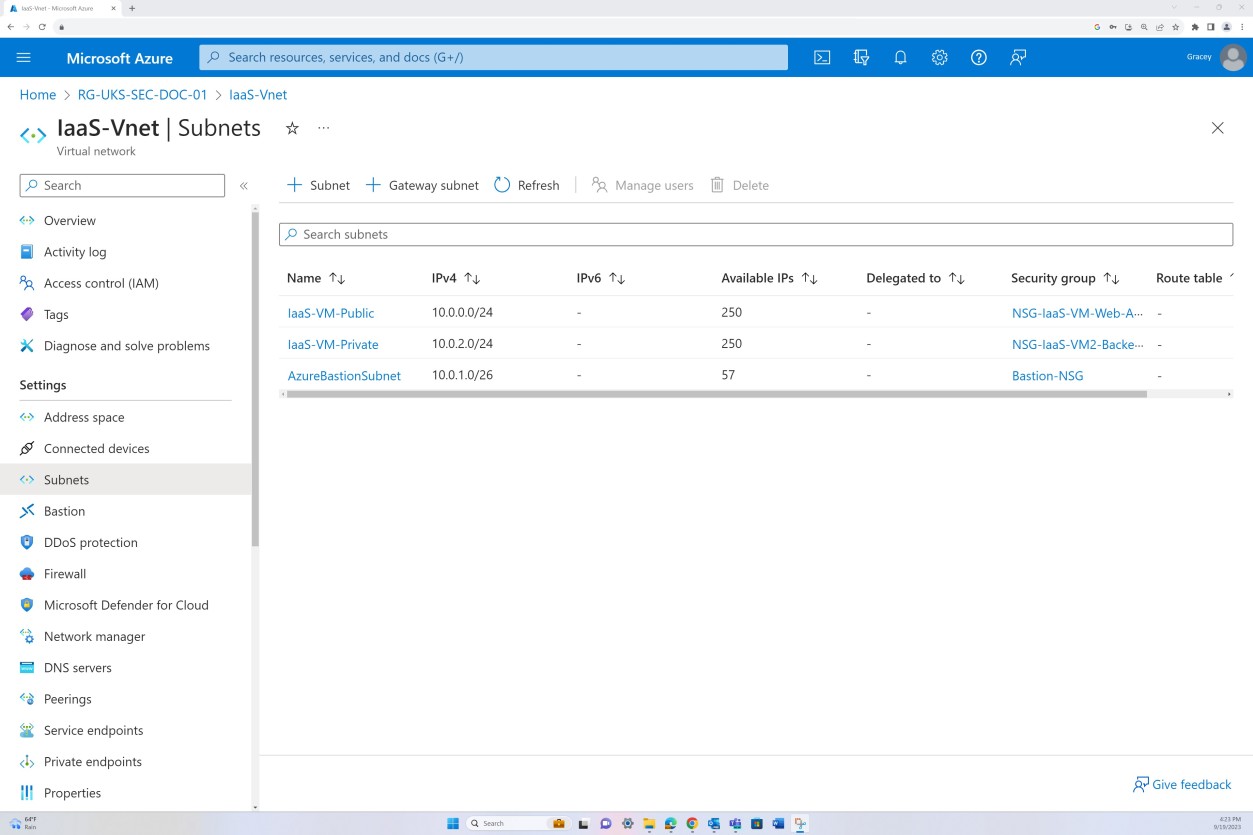
Die nächsten Screenshots zeigen, dass die Netzwerksegmentierung innerhalb des bereichsinternen virtuellen Netzwerks erfolgt. Das folgende VNET ist in drei Subnetze unterteilt, von denen jeweils eine NSG angewendet wird.
Das öffentliche Subnetz fungiert als Umkreisnetzwerk. Der gesamte öffentliche Datenverkehr wird durch dieses Subnetz geleitet und über die NSG mit bestimmten Regeln gefiltert, und nur explizit definierter Datenverkehr ist zulässig. Das Back-End besteht aus dem privaten Subnetz ohne öffentlichen Zugriff. Der gesamte VM-Zugriff ist nur über den Bastion-Host zulässig, für den eine eigene NSG auf Subnetzebene angewendet wird.
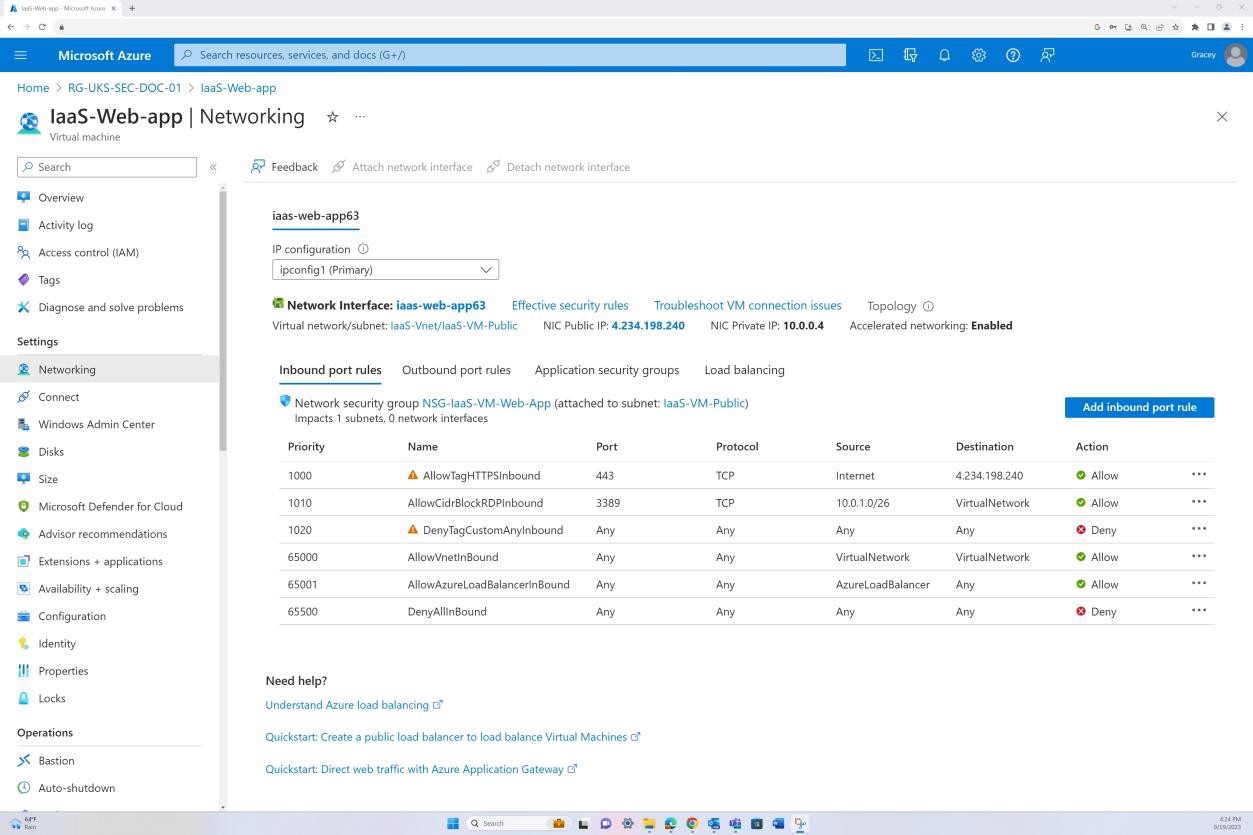
Der nächste Screenshot zeigt, dass Datenverkehr aus dem Internet zu einer bestimmten IP-Adresse nur an Port 443 zulässig ist. Darüber hinaus ist RDP nur vom Bastion-IP-Bereich zum virtuellen Netzwerk zulässig.
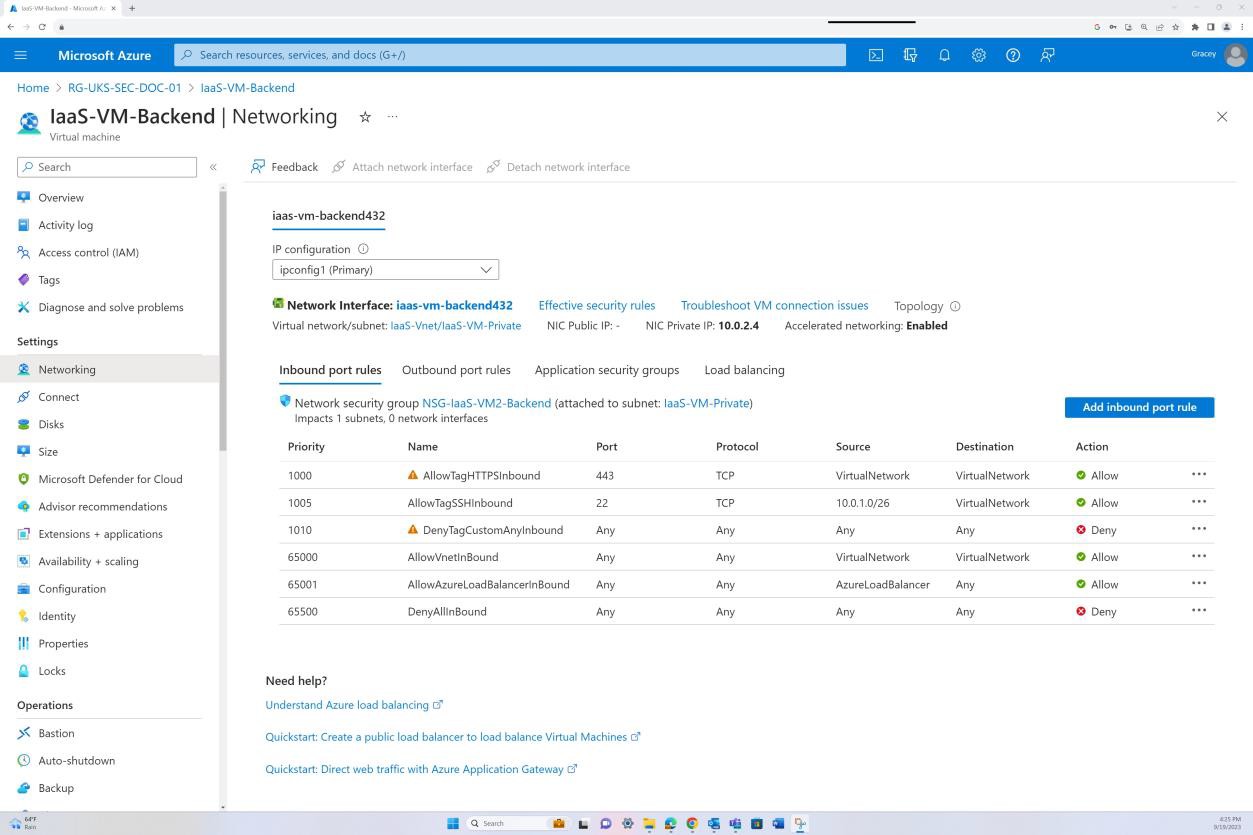
Der nächste Screenshot zeigt, dass das Back-End nicht über das Internet routingfähig ist (dies liegt daran, dass keine öffentliche IP-Adresse für die NIC vorhanden ist) und dass der Datenverkehr nur aus dem Virtual Network und Bastion stammen darf.
Der Screenshot zeigt, dass Azure Bastion-Host nur für den Zugriff auf die virtuellen Computer zu Wartungszwecken verwendet wird.
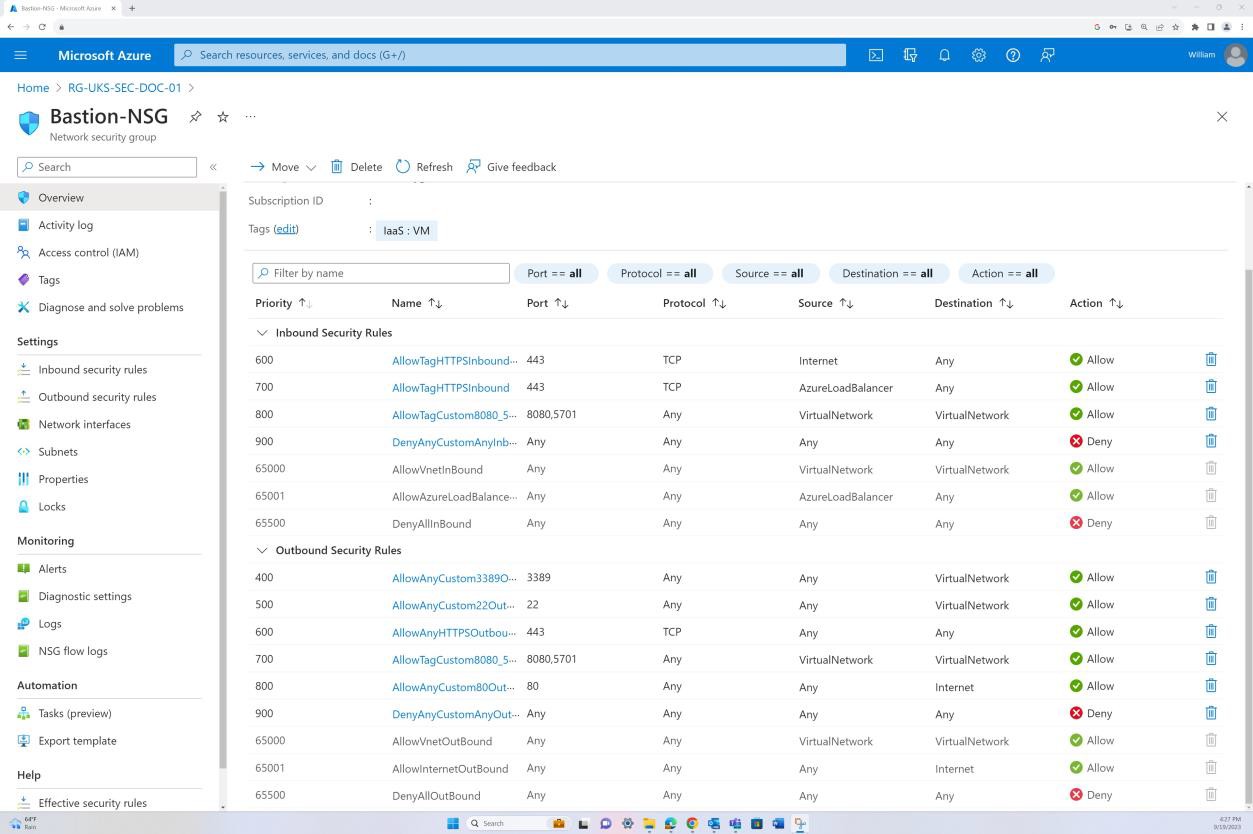
Steuerelement Nr. 9
Stellen Sie Beweise für Folgendes bereit:
Alle Netzwerksicherheitskontrollen (Network Security Controls, NSC) sind so konfiguriert, dass Datenverkehr gelöscht wird, der nicht explizit in der Regelbasis definiert ist.
NSC-Regelüberprüfungen werden mindestens alle sechs (6) Monate durchgeführt.
Absicht: NSC
Dieser Unterpunkt stellt sicher, dass alle Netzwerksicherheitskontrollen (Network Security Controls, NSC) in einem organization so konfiguriert sind, dass jeglicher Netzwerkdatenverkehr gelöscht wird, der nicht explizit in der Regelbasis definiert ist. Das Ziel besteht darin, das Prinzip der geringsten Rechte auf Netzwerkebene durchzusetzen, indem nur autorisierter Datenverkehr zugelassen wird und gleichzeitig der gesamte nicht angegebene oder potenziell schädliche Datenverkehr blockiert wird.
Richtlinien: NSC
Als Beweis hierfür könnten Regelkonfigurationen dienen, die die Eingehenden Regeln anzeigen und wo diese Regeln beendet werden; entweder durch Weiterleiten öffentlicher IP-Adressen an die Ressourcen oder durch Bereitstellen der NAT (Network Address Translation) des eingehenden Datenverkehrs.
Beispielbeweis: NSC
Der Screenshot zeigt die NSG-Konfiguration einschließlich des Standardregelsatzes und einer benutzerdefinierten Deny:All-Regel , um alle Standardregeln der NSG zurückzusetzen und sicherzustellen, dass der gesamte Datenverkehr verboten ist. In den zusätzlichen benutzerdefinierten Regeln definiert die Regel Deny:All explizit den zulässigen Datenverkehr.
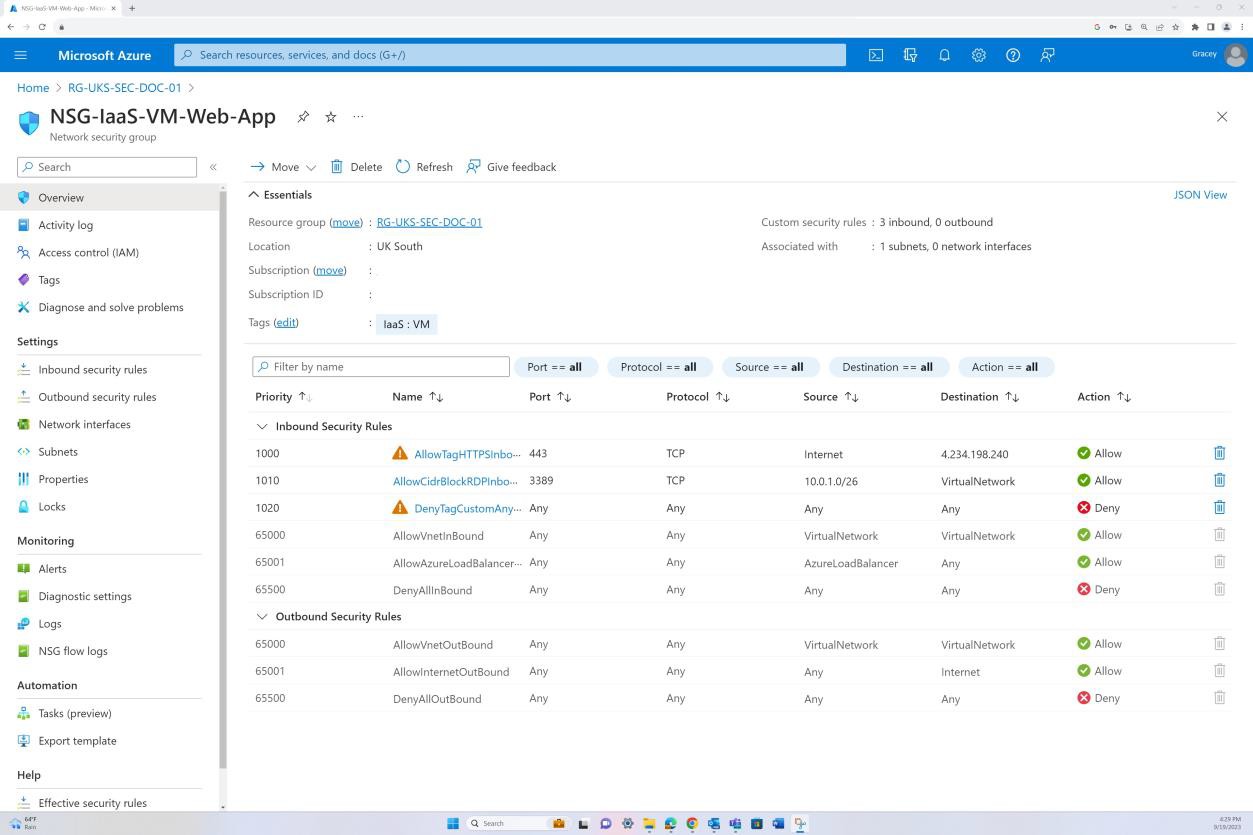
Beispielbeweis: NSC
Die folgenden Screenshots zeigen, dass Azure Front Door bereitgestellt wird, der gesamte Datenverkehr über Front Door weitergeleitet wird. Es wird eine WAF-Richtlinie im "Präventionsmodus" angewendet, die eingehenden Datenverkehr nach potenziellen schädlichen Nutzlasten filtert und blockiert.
Absicht: NSC
Ohne regelmäßige Überprüfungen können Netzwerksicherheitskontrollen (Network Security Controls, NSC) veraltet und ineffektiv werden, wodurch ein organization anfällig für Cyberangriffe wird. Dies kann zu Datenschutzverletzungen, dem Diebstahl vertraulicher Informationen und anderen Cybersicherheitsvorfällen führen. Regelmäßige NSC-Überprüfungen sind für das Management von Risiken, den Schutz vertraulicher Daten, die Einhaltung gesetzlicher Anforderungen, die rechtzeitige Erkennung und Reaktion auf Cyberbedrohungen sowie die Sicherstellung der Geschäftskontinuität unerlässlich. Dieser Unterpunkt erfordert, dass Netzwerksicherheitskontrollen (Network Security Controls, NSC) mindestens alle sechs Monate einer Regelbasisüberprüfung unterzogen werden. Regelmäßige Überprüfungen sind entscheidend für die Aufrechterhaltung der Effektivität und Relevanz der NSC-Konfigurationen, insbesondere in sich dynamisch ändernden Netzwerkumgebungen.
Richtlinien: NSC
Alle bereitgestellten Beweise müssen nachweisen können, dass Es zu Regelüberprüfungsbesprechungen gekommen ist. Dies kann durch die Freigabe von Besprechungsprotokollen der NSC-Überprüfung und allen zusätzlichen Änderungskontrollbeweis erfolgen, die alle aktionen zeigen, die aus der Überprüfung ausgeführt wurden. Stellen Sie sicher, dass Datumsangaben vorhanden sind, da der Zertifizierungsanalyst, der Ihre Übermittlung überprüft, mindestens zwei dieser Besprechungsüberprüfungsdokumente (d. h. alle sechs Monate) einsehen muss.
Beispielbeweis: NSC
Diese Screenshots zeigen, dass sechsmonatige Firewallüberprüfungen vorhanden sind und die Details auf der Confluence Cloud-Plattform verwaltet werden.
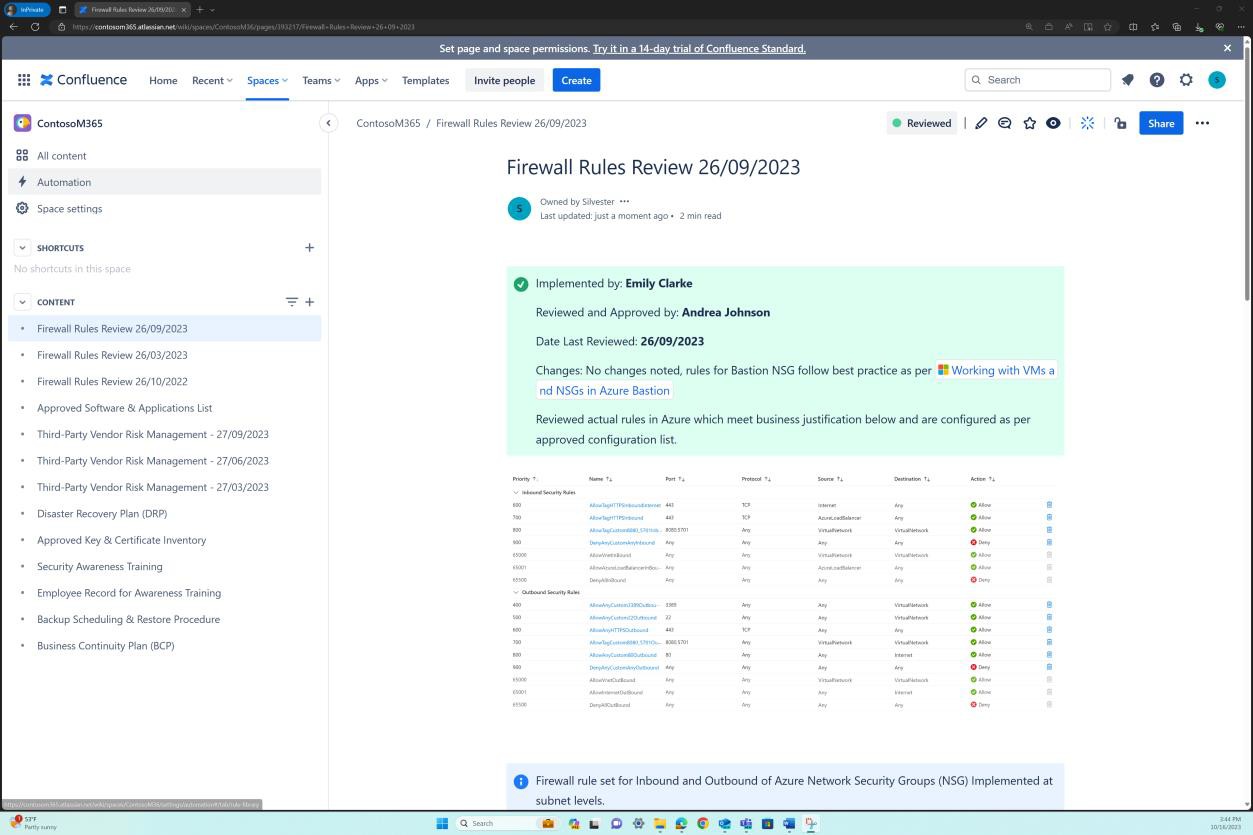
Der nächste Screenshot zeigt, dass jede Regelüberprüfung eine Seite in Confluence erstellt hat. Die Regelüberprüfung enthält eine genehmigte Regelsatzliste, die den zulässigen Datenverkehr, die Portnummer, das Protokoll usw. zusammen mit der geschäftlichen Begründung enthält.
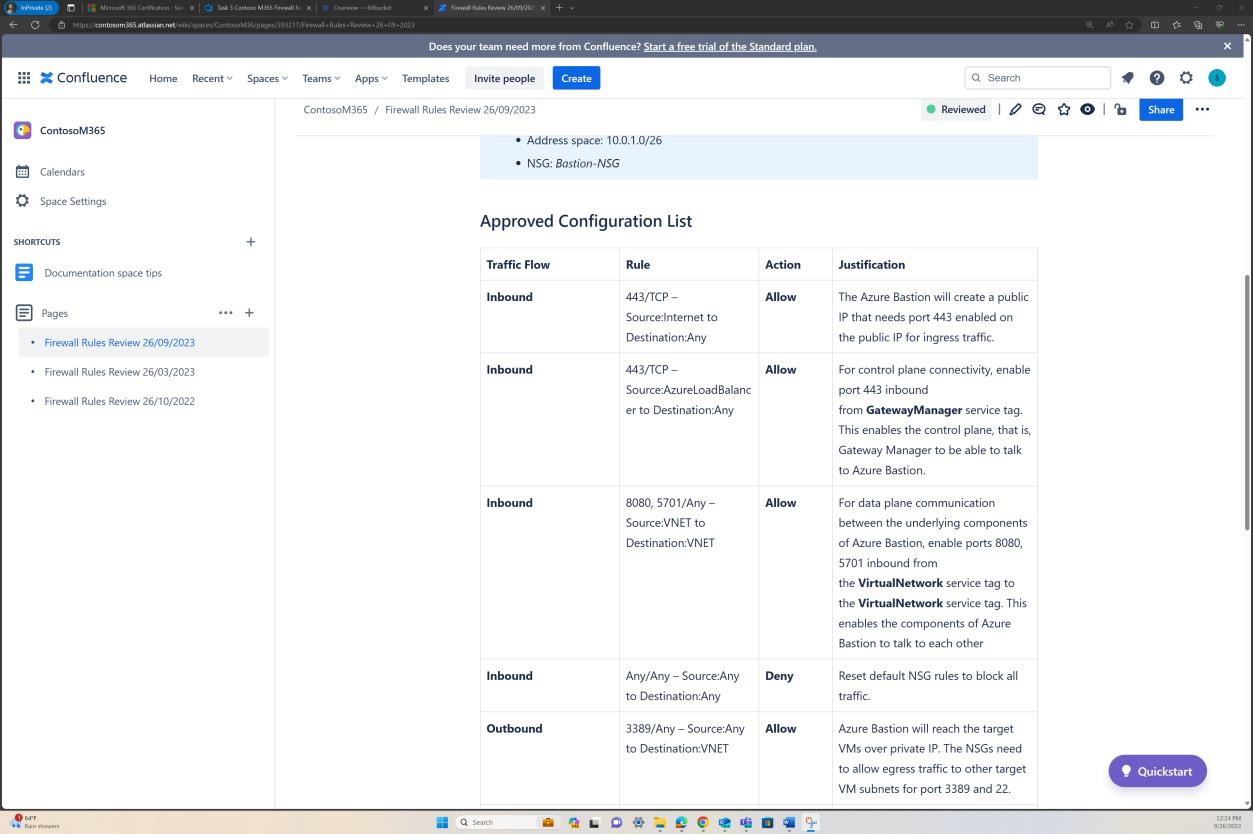
Beispielbeweis: NSC
Der nächste Screenshot zeigt ein alternatives Beispiel für eine sechsmonatige Regelüberprüfung in DevOps.
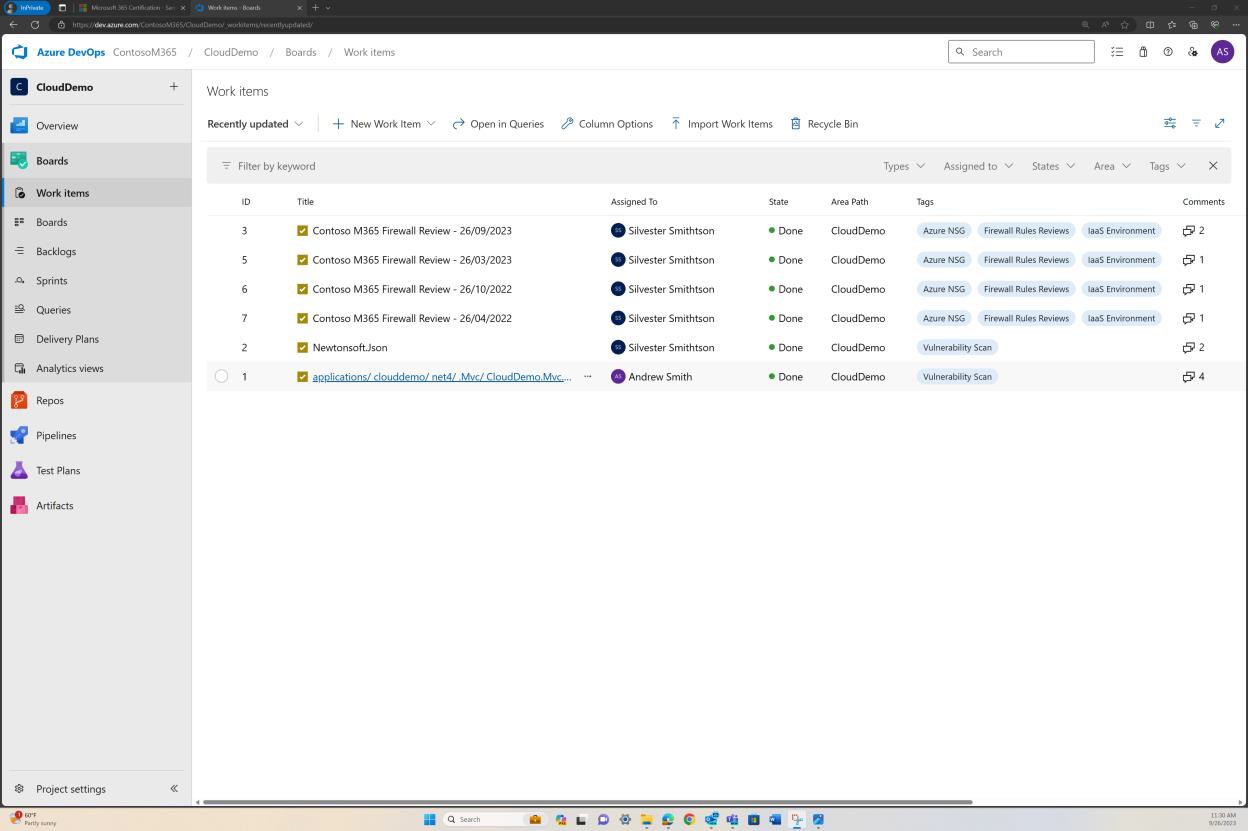
Beispielbeweis: NSC
Dieser Screenshot zeigt ein Beispiel für eine Regelüberprüfung, die als Ticket in DevOps ausgeführt und aufgezeichnet wird.
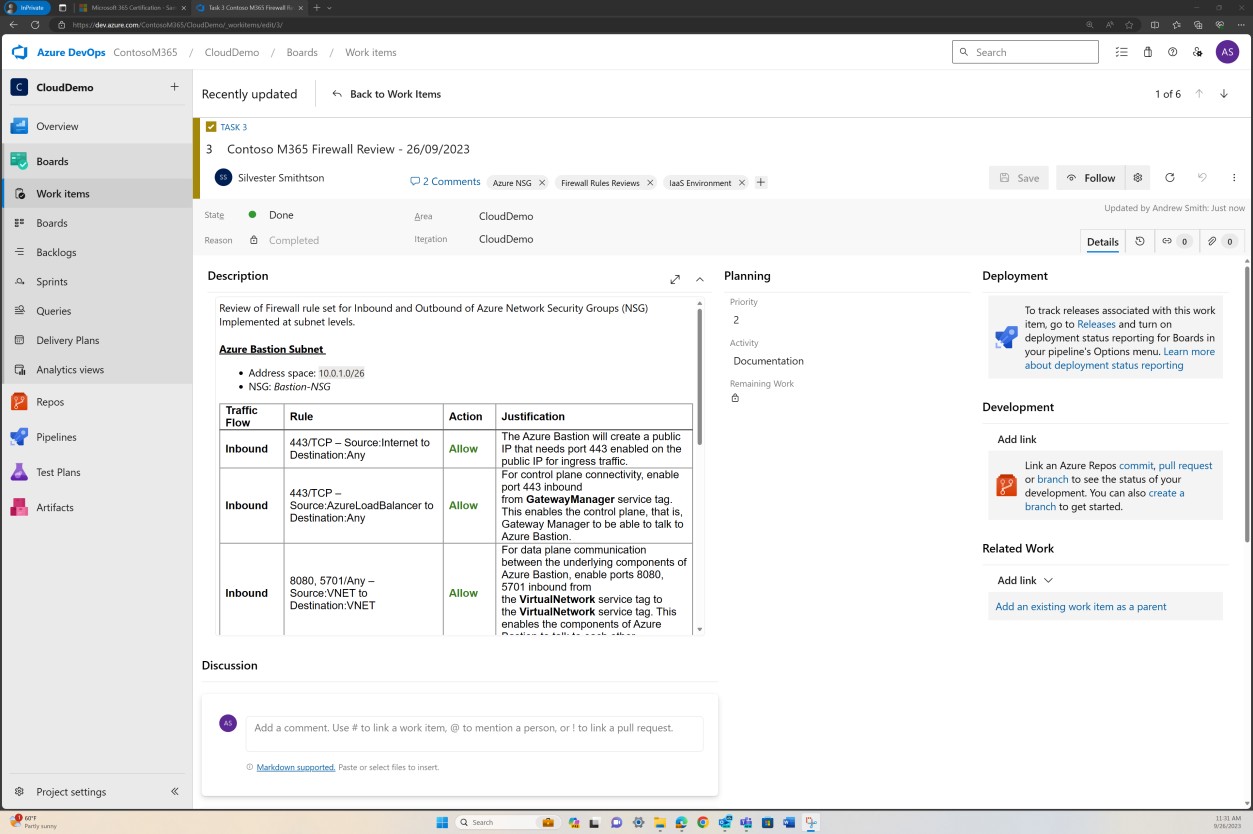
Der vorherige Screenshot zeigt die erstellte dokumentierte Regelliste neben der geschäftlichen Begründung, während die nächste Abbildung eine Momentaufnahme der Regeln innerhalb des Tickets aus dem tatsächlichen System zeigt.
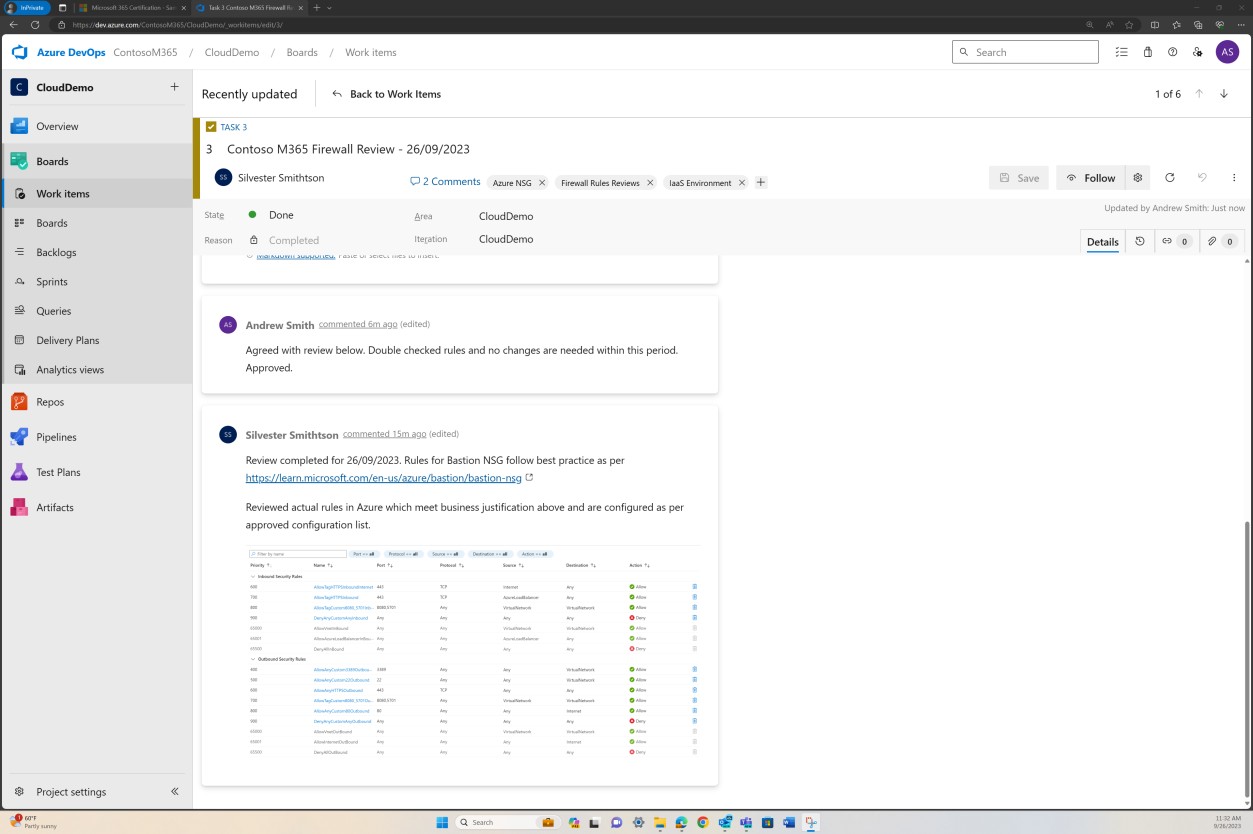
Änderungssteuerung
Ein etablierter und verstandener Change Control-Prozess ist unerlässlich, um sicherzustellen, dass alle Änderungen einen strukturierten Prozess durchlaufen, der wiederholbar ist. Indem sichergestellt wird, dass alle Änderungen einen strukturierten Prozess durchlaufen, können Organisationen sicherstellen, dass Änderungen effektiv verwaltet, peer reviewt und angemessen getestet werden, bevor sie abgemeldet werden. Dies trägt nicht nur dazu bei, das Risiko von Systemausfällen zu minimieren, sondern auch das Risiko potenzieller Sicherheitsvorfälle durch falsche Änderungen zu minimieren.
Steuerelement Nr. 10
Stellen Sie Beweise für Folgendes bereit:
Alle Änderungen, die in Produktionsumgebungen eingeführt werden, werden durch dokumentierte Änderungsanforderungen implementiert:
Auswirkungen der Änderung auf die Sicherheit
Details zu allen Back-Out-Verfahren
Details der durchzuführenden Tests, um sicherzustellen, dass die Änderung sicher implementiert wurde
Genehmigung durch autorisiertes Personal
Hinweis: Änderungen umfassen alle Änderungen innerhalb der Umgebung, z. B. Infrastruktur, Umgebungskonfigurationen (z. B. Cloud/Anwendungen/etc.) und Codeänderungen.
Absicht: Änderungssteuerung
Mit diesem Steuerelement soll sichergestellt werden, dass alle angeforderten Änderungen sorgfältig geprüft und dokumentiert wurden. Dies umfasst die Bewertung der Auswirkungen der Änderung auf die Sicherheit des Systems/der Umgebung, das Dokumentieren aller Back-Out-Verfahren zur Unterstützung der Wiederherstellung, wenn etwas schief geht, und das Detaillierte der Tests, die erforderlich sind, um den Erfolg der Änderung zu überprüfen.
Es müssen Prozesse implementiert werden, die die Durchführung von Änderungen ohne ordnungsgemäße Autorisierung und Abmeldung verbieten. Die Änderung muss vor der Implementierung autorisiert werden, und die Änderung muss nach Abschluss des Vorgangs abgemeldet werden. Dadurch wird sichergestellt, dass die Änderungsanforderungen ordnungsgemäß überprüft wurden und eine zuständige Person die Änderung abgemeldet hat.
Richtlinien: Änderungssteuerung
Der Nachweis kann durch Die Freigabe von Screenshots eines Beispiels von Änderungsanforderungen bereitgestellt werden, die zeigen, dass die Details der Auswirkungen der Änderung, back-out-Prozeduren und Tests innerhalb der Änderungsanforderung gespeichert werden.
Beispielbeweis: Änderungssteuerung
Der nächste Screenshot zeigt eine neue Cross-Site Scripting Vulnerability (XSS), die zugewiesen wird, und ein Dokument für die Änderungsanforderung. Die folgenden Tickets veranschaulichen die Informationen, die dem Ticket auf dem Weg zur Lösung festgelegt oder hinzugefügt wurden.
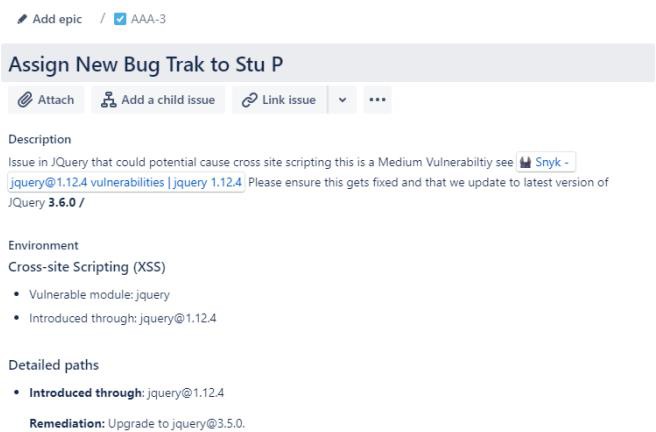
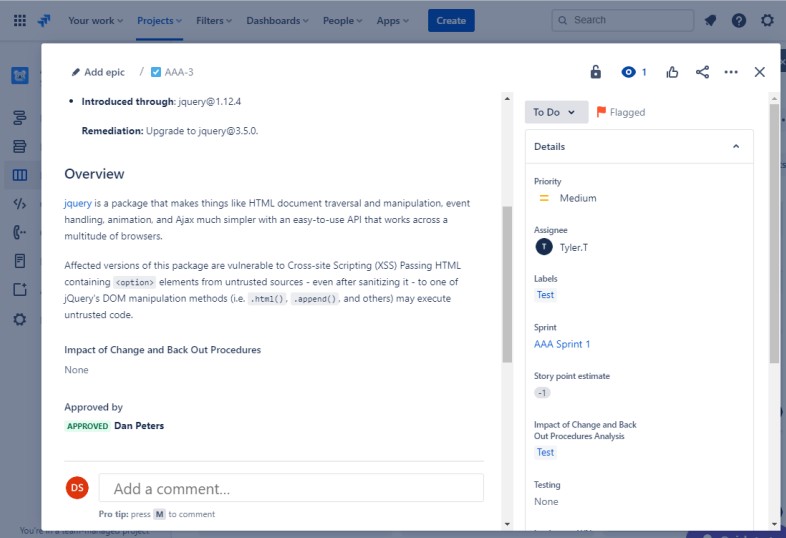
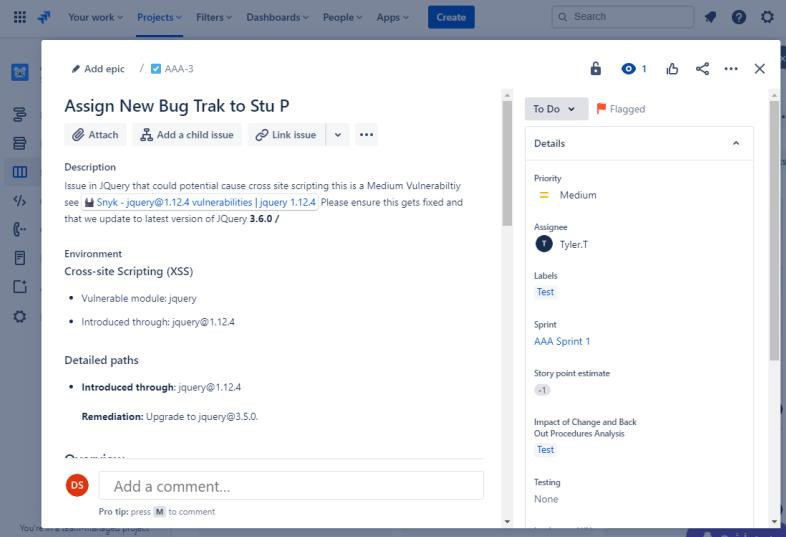
Die beiden folgenden Tickets zeigen die Auswirkungen der Änderung am System und die Back-Out-Prozeduren, die im Falle eines Problems erforderlich sein können. Die Auswirkungen von Änderungen und Back-Out-Verfahren haben einen Genehmigungsprozess durchlaufen und wurden für Tests genehmigt.
Im folgenden Screenshot wurde das Testen der Änderungen genehmigt, und auf der rechten Seite sehen Sie, dass die Änderungen nun genehmigt und getestet wurden.
Beachten Sie während des gesamten Prozesses, dass die Person, die die Arbeit ausführt, die Person, die darüber berichtet und die Person, die die zu erledigende Arbeit genehmigt, unterschiedliche Personen sind.

Das folgende Ticket zeigt, dass die Änderungen jetzt für die Implementierung in der Produktionsumgebung genehmigt wurden. Das rechte Feld zeigt, dass der Test erfolgreich war und dass die Änderungen nun in der Prod-Umgebung implementiert wurden.
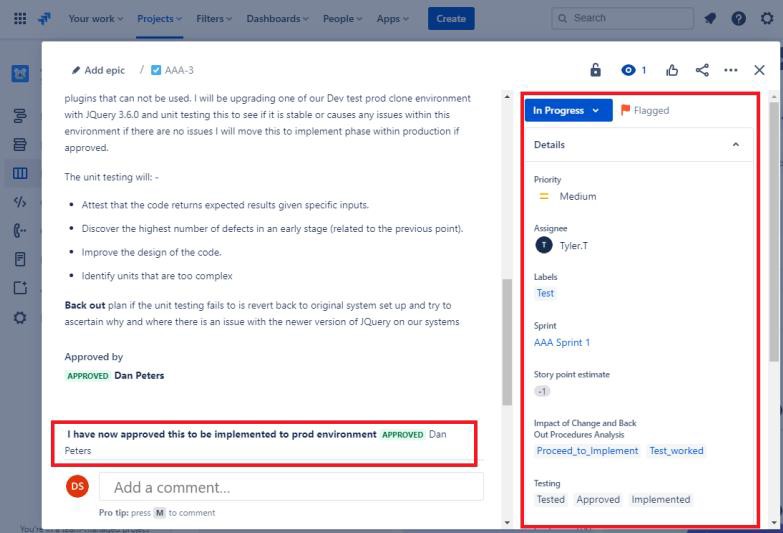
Beispielbeweis
Die nächsten Screenshots zeigen ein Jira-Beispielticket, das zeigt, dass die Änderung autorisiert werden muss, bevor sie von einer anderen Person als dem Entwickler/Anfordernden implementiert und genehmigt wird. Die Änderungen werden von einer person mit Autorität genehmigt. Die rechte Seite des Screenshots zeigt, dass die Änderung von DP signiert wurde, sobald sie abgeschlossen ist.
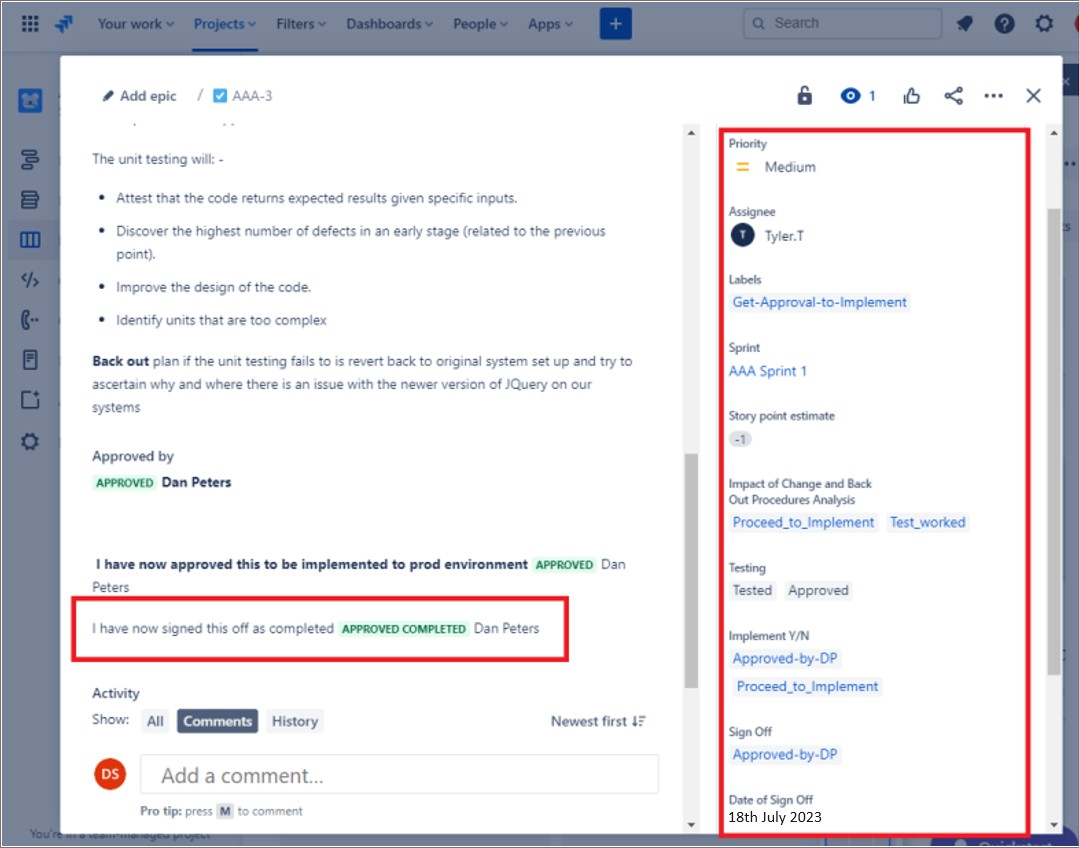
Im Ticket wurde die Änderung nach Abschluss des Vorgangs abgemeldet und zeigt an, dass der Auftrag abgeschlossen und geschlossen wurde.
Hinweis: - In diesen Beispielen wurde kein vollständiger Screenshot verwendet, aber ALLE von ISV übermittelten Beweisscreenshots müssen vollständige Screenshots sein, die eine URL, den angemeldeten Benutzer und die Systemzeit und das Systemdatum zeigen.
Steuerelement Nr. 11
HARTER FEHLER
Stellen Sie Beweise für Folgendes bereit:
Es ist eine separate Umgebung vorhanden, sodass:
Entwicklungs- und Test-/Stagingumgebungen werden über NSCs von der Produktionsumgebung isoliert.
Entwicklungs- und Test-/Stagingumgebungen erzwingen die Trennung von Aufgaben von der Produktionsumgebung über Zugriffssteuerungen.
vertrauliche Produktionsdaten werden in den Entwicklungs- oder Test-/Stagingumgebungen nicht verwendet.
Absicht: Separate Umgebungen
Die Entwicklungs-/Testumgebungen der meisten Organisationen sind nicht mit der gleichen Stärke wie die Produktionsumgebungen konfiguriert und daher weniger sicher. Darüber hinaus sollten Tests nicht innerhalb der Produktionsumgebung durchgeführt werden, da dies Sicherheitsprobleme mit sich bringen kann oder sich negativ auf die Dienstbereitstellung für Kunden auswirken kann. Durch die Verwaltung separater Umgebungen, die eine Aufgabentrennung erzwingen, können Organisationen sicherstellen, dass Änderungen auf die richtigen Umgebungen angewendet werden, wodurch das Risiko von Fehlern verringert wird, indem Änderungen an Produktionsumgebungen implementiert werden, wenn sie für die Entwicklungs-/Testumgebung vorgesehen waren.
Die Zugriffssteuerungen sollten so konfiguriert werden, dass die für Entwicklung und Tests zuständigen Mitarbeiter keinen unnötigen Zugriff auf die Produktionsumgebung haben und umgekehrt. Dies minimiert das Potenzial für nicht autorisierte Änderungen oder die Offenlegung von Daten.
Die Verwendung von Produktionsdaten in Entwicklungs-/Testumgebungen kann das Risiko einer Kompromittierung erhöhen und die organization für Datenschutzverletzungen oder nicht autorisierten Zugriff aussetzen. Die Absicht erfordert, dass alle Daten, die für Die Entwicklung oder Tests verwendet werden, bereinigt, anonymisiert oder speziell für diesen Zweck generiert werden.
Richtlinien: Separate Umgebungen
Screenshots können bereitgestellt werden, die verschiedene Umgebungen veranschaulichen, die für Entwicklungs-/Testumgebungen und Produktionsumgebungen verwendet werden. In der Regel verfügen Sie über unterschiedliche Personen/Teams mit Zugriff auf jede Umgebung. Wenn dies nicht möglich ist, verwenden die Umgebungen unterschiedliche Autorisierungsdienste, um sicherzustellen, dass sich Benutzer nicht fälschlicherweise bei der falschen Umgebung anmelden können, um Änderungen anzuwenden.
Beispielbeweis: separate Umgebungen
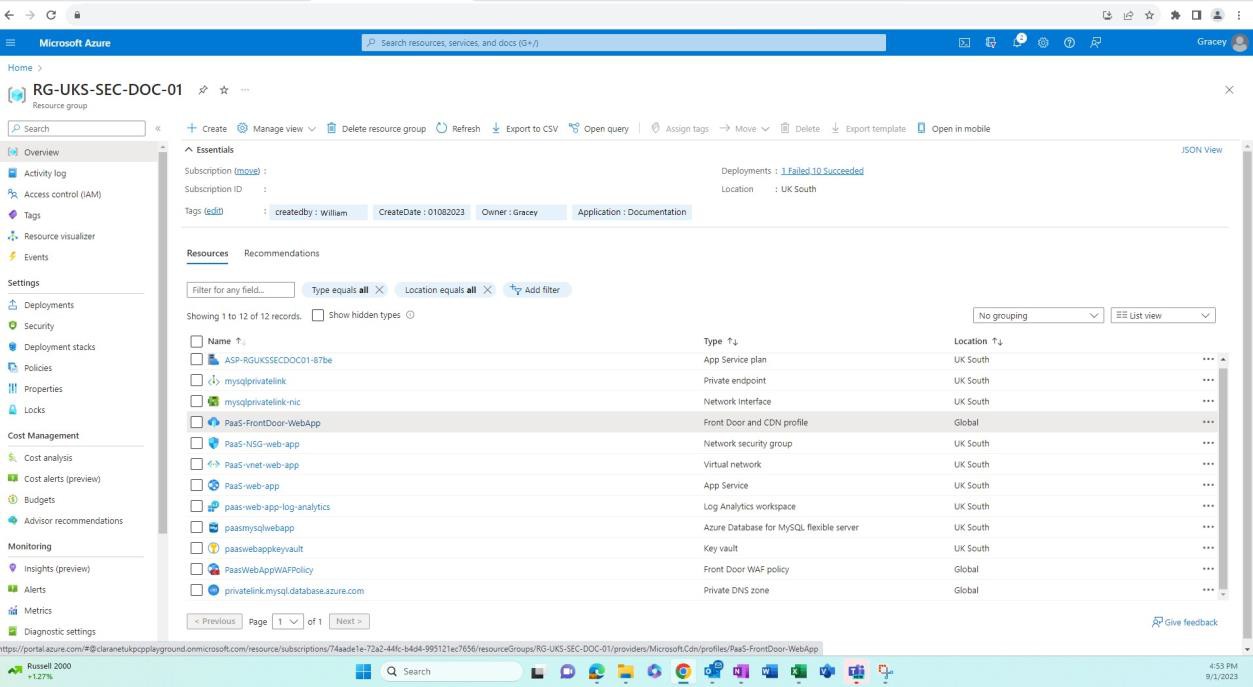
Die nächsten Screenshots zeigen, dass Umgebungen für Entwicklung/Tests von der Produktion getrennt sind. Dies wird über Ressourcengruppen in Azure erreicht. Dies ist eine Möglichkeit zum logischen Gruppieren von Ressourcen in einem Container. Andere Möglichkeiten, die Trennung zu erreichen, können verschiedene Azure Abonnements, Netzwerk und Subnetz usw. sein.
Der folgende Screenshot zeigt die Entwicklungsumgebung und die Ressourcen in dieser Ressourcengruppe.
Der nächste Screenshot zeigt die Produktionsumgebung und die Ressourcen in dieser Ressourcengruppe.
Beispielbeweis:
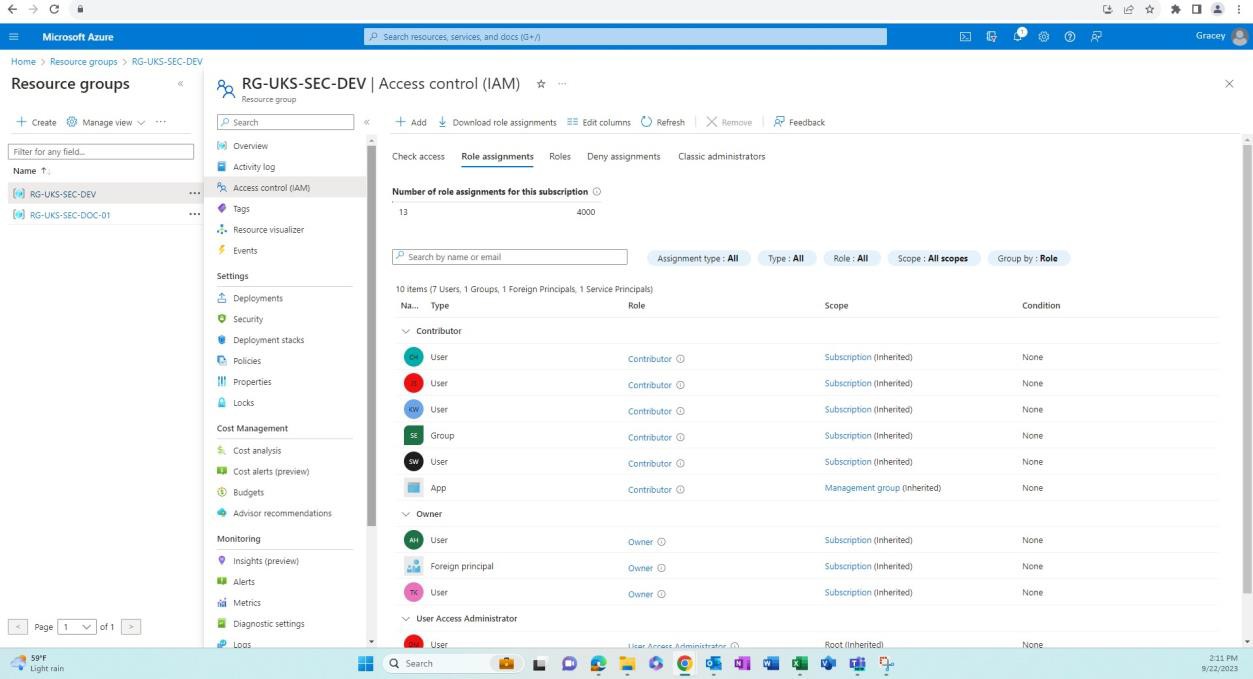
Die nächsten Screenshots zeigen, dass Umgebungen für Entwicklung/Tests von der Produktionsumgebung getrennt sind. Eine angemessene Trennung der Umgebungen wird über verschiedene Benutzer/Gruppen mit unterschiedlichen Berechtigungen erreicht, die jeder Umgebung zugeordnet sind.
Der nächste Screenshot zeigt die Entwicklungsumgebung und die Benutzer mit Zugriff auf diese Ressourcengruppe.
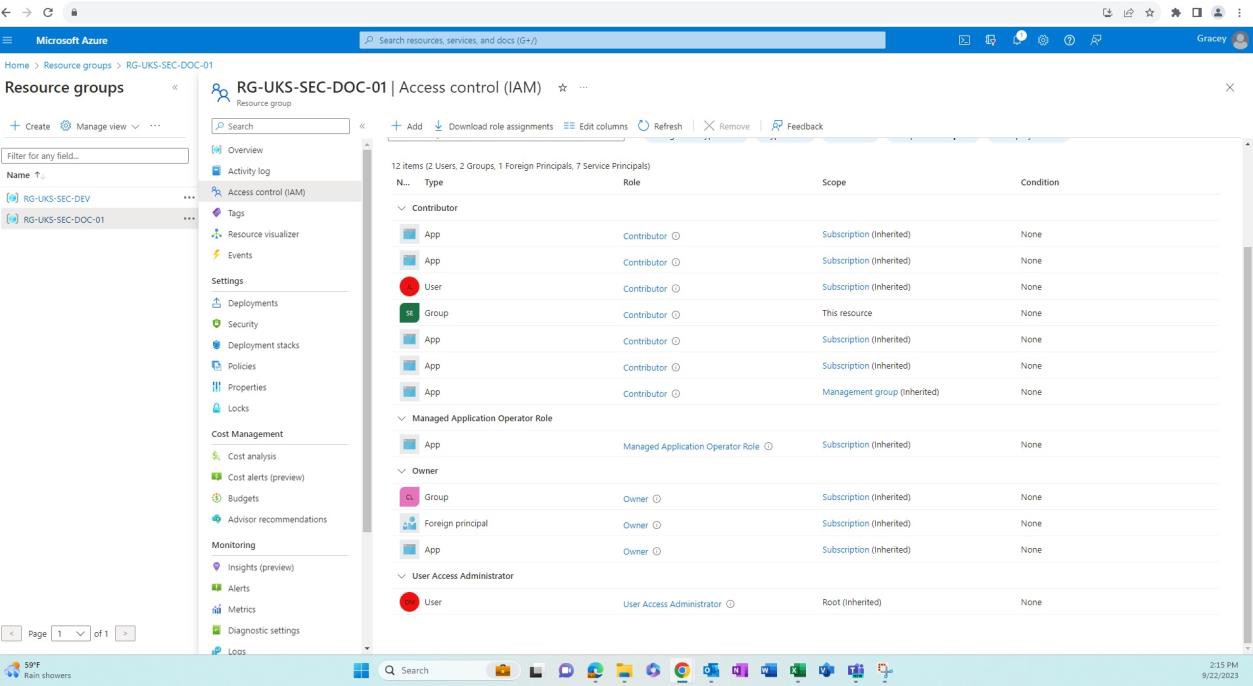
Der nächste Screenshot zeigt die Produktionsumgebung und die Benutzer (anders als die Entwicklungsumgebung), die Zugriff auf diese Ressourcengruppe haben.
Richtlinien:
Der Beweis kann durch Freigeben von Screenshots der Ausgabe derselben SQL-Abfrage für eine Produktionsdatenbank (Redigieren vertraulicher Informationen) und der Entwicklungs-/Testdatenbank bereitgestellt werden. Die Ausgabe der gleichen Befehle sollte unterschiedliche Datasets erzeugen. Wo Dateien gespeichert werden, sollte beim Anzeigen des Inhalts der Ordner in beiden Umgebungen auch unterschiedliche Datasets veranschaulicht werden.
Beispielbeweis
Der Screenshot zeigt die top 3 Datensätze (für die Übermittlung von Nachweisen geben Sie die top 20) aus der Produktionsdatenbank an.
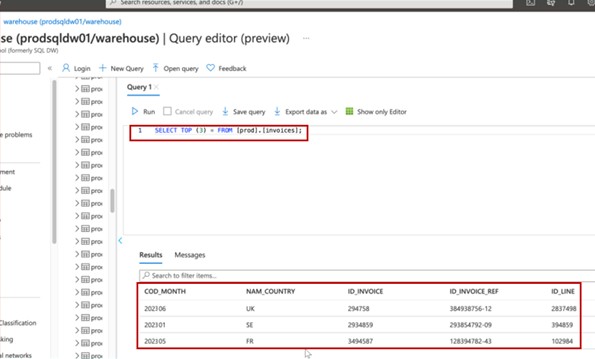
Der nächste Screenshot zeigt dieselbe Abfrage aus der Entwicklungsdatenbank mit unterschiedlichen Datensätzen.
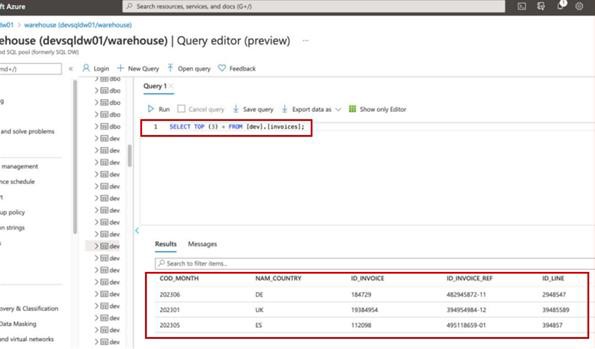
Hinweis: In diesem Beispiel wurde kein vollständiger Screenshot verwendet. Screenshots für ALLE von ISV übermittelten Nachweise müssen jedoch vollständige Screenshots mit url, angemeldeter Benutzer und Systemzeit und -datum sein.
Sichere Softwareentwicklung/-bereitstellung
Organisationen, die an Softwareentwicklungsaktivitäten beteiligt sind, sind häufig mit konkurrierenden Prioritäten zwischen Sicherheit und TTM-Druck (Time to Market) konfrontiert, aber die Implementierung von sicherheitsbezogenen Aktivitäten während des gesamten Softwareentwicklungslebenszyklus (SDLC) kann nicht nur Geld sparen, sondern auch Zeit sparen. Wenn die Sicherheit im Nachgang bleibt, werden Probleme in der Regel nur während der Testphase des (DSLC) identifiziert, was oft zeitaufwendiger und kostspieliger zu beheben sein kann. In diesem Sicherheitsabschnitt soll sichergestellt werden, dass sichere Methoden für die Softwareentwicklung befolgt werden, um das Risiko von Programmierfehlern zu verringern, die in die entwickelte Software eingeführt werden. Darüber hinaus enthält dieser Abschnitt einige Steuerelemente, die die sichere Bereitstellung von Software unterstützen.
Kontrolle Nr. 12
Stellen Sie Beweise für Folgendes bereit:
Richtlinien/Standards sind vorhanden und werden beibehalten, die:
unterstützt die Entwicklung sicherer Software und umfasst Branchenstandards und/oder bewährte Methoden für die sichere Codierung, z. B. Open Web Application Security Project (OWASP) Top 10 oder SysAdmin, Audit, Network and Security (SANS) Top 25 Common Weakness Enumeration (CWE).
Entwickler durchlaufen mindestens jährlich relevante Schulungen zur sicheren Codierung und sicheren Softwareentwicklung, die Branchenstandards und/oder bewährte Methoden für sichere Codierung abdeckt.
Alle Entwickler haben mindestens jährlich eine entsprechende Sicherheitscodierungs- und Softwareentwicklungsschulung durchlaufen.
Absicht: Sichere Entwicklung
Organisationen müssen alles in ihrer Macht Stehende tun, um sicherzustellen, dass Software sicher entwickelt und frei von Sicherheitsrisiken ist. Um dies zu erreichen, sollten ein robuster SDLC (Secure Software Development Lifecycle) und bewährte Methoden für sichere Codierung eingeführt werden, um sichere Codierungstechniken und sichere Entwicklung während des gesamten Softwareentwicklungsprozesses zu fördern. Die Absicht besteht darin, die Anzahl und den Schweregrad von Sicherheitsrisiken in der Software zu reduzieren.
Für alle Programmiersprachen gibt es bewährte Methoden und Techniken für die Codierung, um sicherzustellen, dass Code sicher entwickelt wird. Es gibt externe Schulungskurse, die Entwicklern die verschiedenen Arten von Softwaresicherheitsklassen und die Programmiertechniken vermitteln, die verwendet werden können, um die Einführung dieser Sicherheitsrisiken in die Software zu beenden. Die Absicht dieses Steuerelements besteht auch darin, diese Techniken allen Entwicklern beizubringen und sicherzustellen, dass diese Techniken nicht vergessen werden oder neuere Techniken erlernt werden, indem dies jährlich durchgeführt wird.
Richtlinien: Sichere Entwicklung
Stellen Sie die dokumentierte SDLC- und/oder Supportdokumentation bereit, die zeigt, dass ein sicherer Entwicklungslebenszyklus verwendet wird und dass allen Entwicklern Anleitungen zur Förderung bewährter Methoden für sichere Codierung zur Verfügung gestellt werden. Sehen Sie sich OWASP in SDLC und das OWASP Software Assurance MaturityModel (SAMM) an.
Beispielbeweis: sichere Entwicklung
Ein Beispiel für das Richtliniendokument für die sichere Softwareentwicklung ist unten dargestellt. Im Folgenden finden Sie einen Auszug aus dem Verfahren zur sicheren Softwareentwicklung von Contoso, das sichere Entwicklungs- und Codierungsmethoden veranschaulicht.
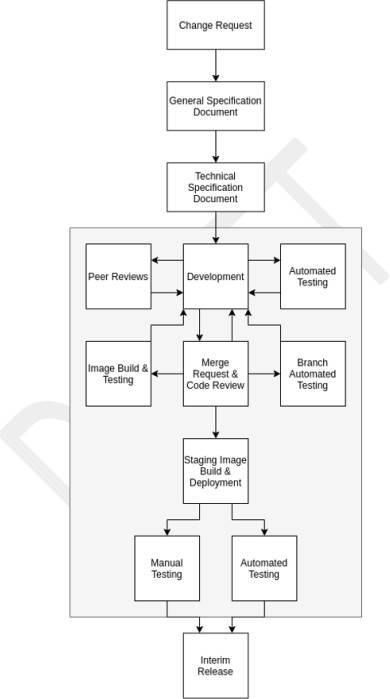

Hinweis: In den vorherigen Beispielen wurden keine vollständigen Screenshots verwendet, aber ALLE von ISV übermittelten Beweisscreenshots müssen vollständige Screenshots sein, die eine URL, den angemeldeten Benutzer und die Systemzeit und das Systemdatum zeigen.
Richtlinien: Sicheres Entwicklungstraining
Stellen Sie den Nachweis durch Zertifikate bereit, wenn die Schulung von einem externen Schulungsunternehmen durchgeführt wird, oder indem Sie Screenshots der Schulungstagebücher oder anderer Artefakte bereitstellen, die zeigen, dass Entwickler an der Schulung teilgenommen haben. Wenn diese Schulung über interne Ressourcen durchgeführt wird, stellen Sie auch den Nachweis des Schulungsmaterials bereit.
Beispielbeweis: Sicheres Entwicklungstraining
Der nächste Screenshot ist eine E-Mail, in der Mitarbeiter im DevOps-Team aufgefordert werden, sich für die jährliche OWASP Top Ten Training-Schulung zu registrieren.

Der nächste Screenshot zeigt, dass das Training mit geschäftlicher Begründung und Genehmigung angefordert wurde. Anschließend folgen Screenshots aus der Schulung und ein Abschlussdatensatz, der zeigt, dass die Person die jährliche Schulung abgeschlossen hat.
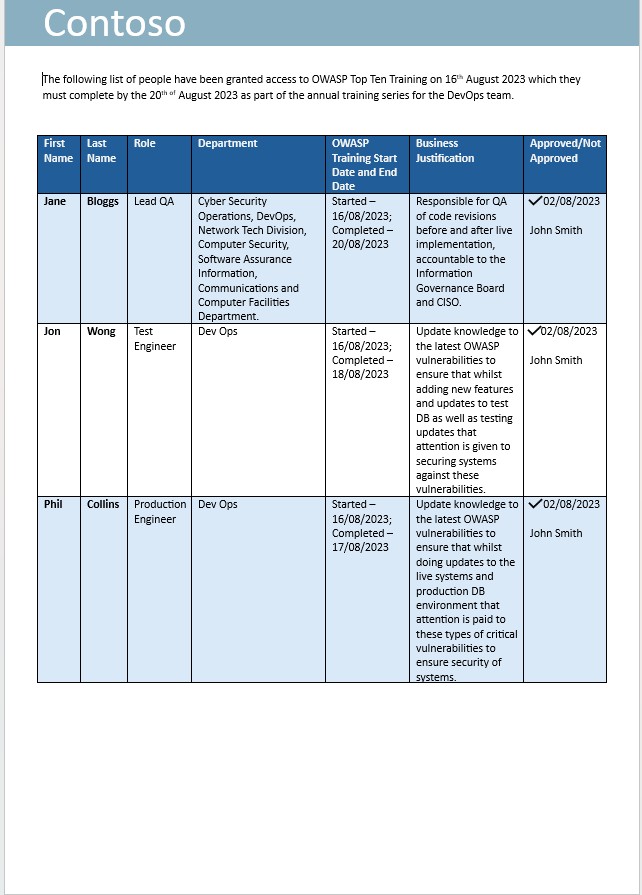
Hinweis: In diesem Beispiel wurde kein vollständiger Screenshot verwendet. Screenshots für ALLE von ISV übermittelten Nachweise müssen jedoch vollständige Screenshots mit url, angemeldeter Benutzer und Systemzeit und -datum sein.
Regelung Nr. 13
Stellen Sie Beweise für Folgendes bereit:
Coderepositorys sind so gesichert, dass:
Alle Codeänderungen durchlaufen einen Überprüfungs- und Genehmigungsprozess durch einen zweiten Prüfer, bevor sie mit dem Mainbranch zusammengeführt werden.
Geeignete Zugriffssteuerungen sind vorhanden
der gesamte Zugriff wird über die mehrstufige Authentifizierung (Multi-Factor Authentication, MFA) erzwungen.
Alle Releases, die in den Produktionsumgebungen vorgenommen werden, werden vor ihrer Bereitstellung genehmigt.
Absicht: Codeüberprüfung
Die Absicht dieses Unterpunkts besteht darin, eine Codeüberprüfung durch einen anderen Entwickler durchzuführen, um Codefehler zu identifizieren, die zu einem Sicherheitsrisiko in der Software führen könnten. Die Autorisierung sollte eingerichtet werden, um sicherzustellen, dass Code reviews durchgeführt werden, Tests durchgeführt werden usw. vor der Bereitstellung. Der Autorisierungsschritt überprüft, ob die richtigen Prozesse befolgt wurden, was dem in Steuerung 12 definierten SDLC zugrunde geht.
Das Ziel besteht darin, sicherzustellen, dass alle Codeänderungen einem strengen Überprüfungs- und Genehmigungsprozess durch einen zweiten Prüfer unterzogen werden, bevor sie mit dem Mainbranch zusammengeführt werden. Dieser Prozess der doppelten Genehmigung dient als Qualitätskontrollmaßnahme, die darauf abzielt, Codierungsfehler, Sicherheitslücken oder andere Probleme zu erfassen, die die Integrität der Anwendung beeinträchtigen könnten.
Richtlinien: Codeüberprüfung
Stellen Sie den Nachweis bereit, dass Code einer Peerüberprüfung unterzogen wird und autorisiert werden muss, bevor er auf die Produktionsumgebung angewendet werden kann. Dieser Nachweis kann über einen Export von Änderungstickets erfolgen, der nachweist, dass Code reviews durchgeführt und die Änderungen autorisiert wurden, oder es kann durch Code Review-Software wie Crucible erfolgen.
Beispielbeweis: Codeüberprüfung
Im Folgenden finden Sie ein Ticket, das zeigt, dass Codeänderungen einem Überprüfungs- und Autorisierungsprozess durch eine andere Person als den ursprünglichen Entwickler unterzogen werden. Es zeigt, dass vom Zugewiesenen eine Codeüberprüfung angefordert wurde und einer anderen Person für die Codeüberprüfung zugewiesen wird.
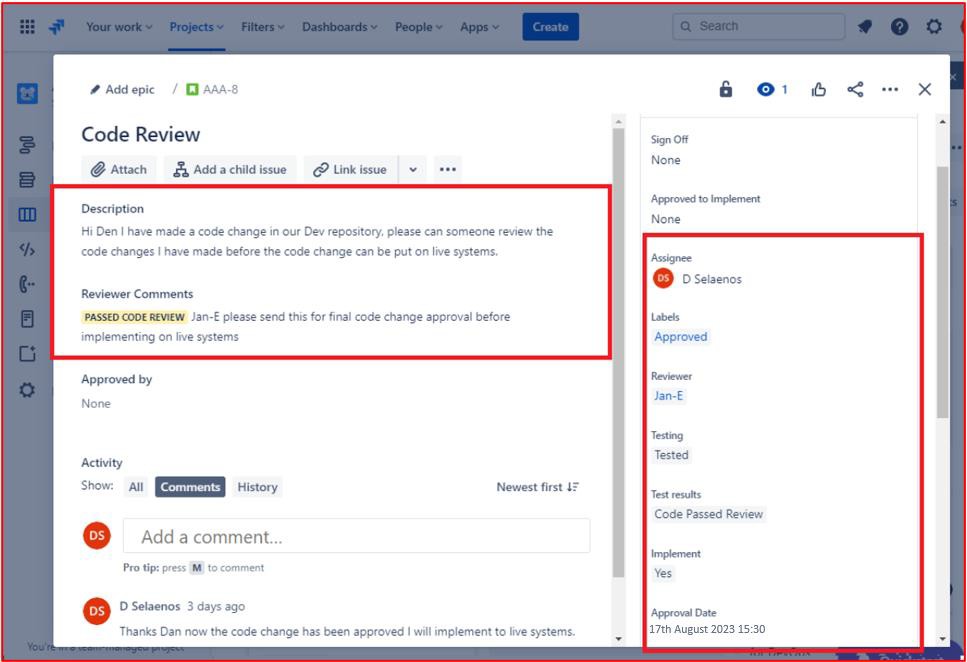
Die nächste Abbildung zeigt, dass die Codeüberprüfung einer anderen Person als dem ursprünglichen Entwickler zugewiesen wurde, wie im hervorgehobenen Abschnitt auf der rechten Seite des Bilds gezeigt. Auf der linken Seite wurde der Code überprüft und vom Codeprüfer eine "PASSED CODE REVIEW" status erhalten. Das Ticket muss nun von einem Vorgesetzten genehmigt werden, bevor die Änderungen in den Produktionssystemen in Betrieb genommen werden können.
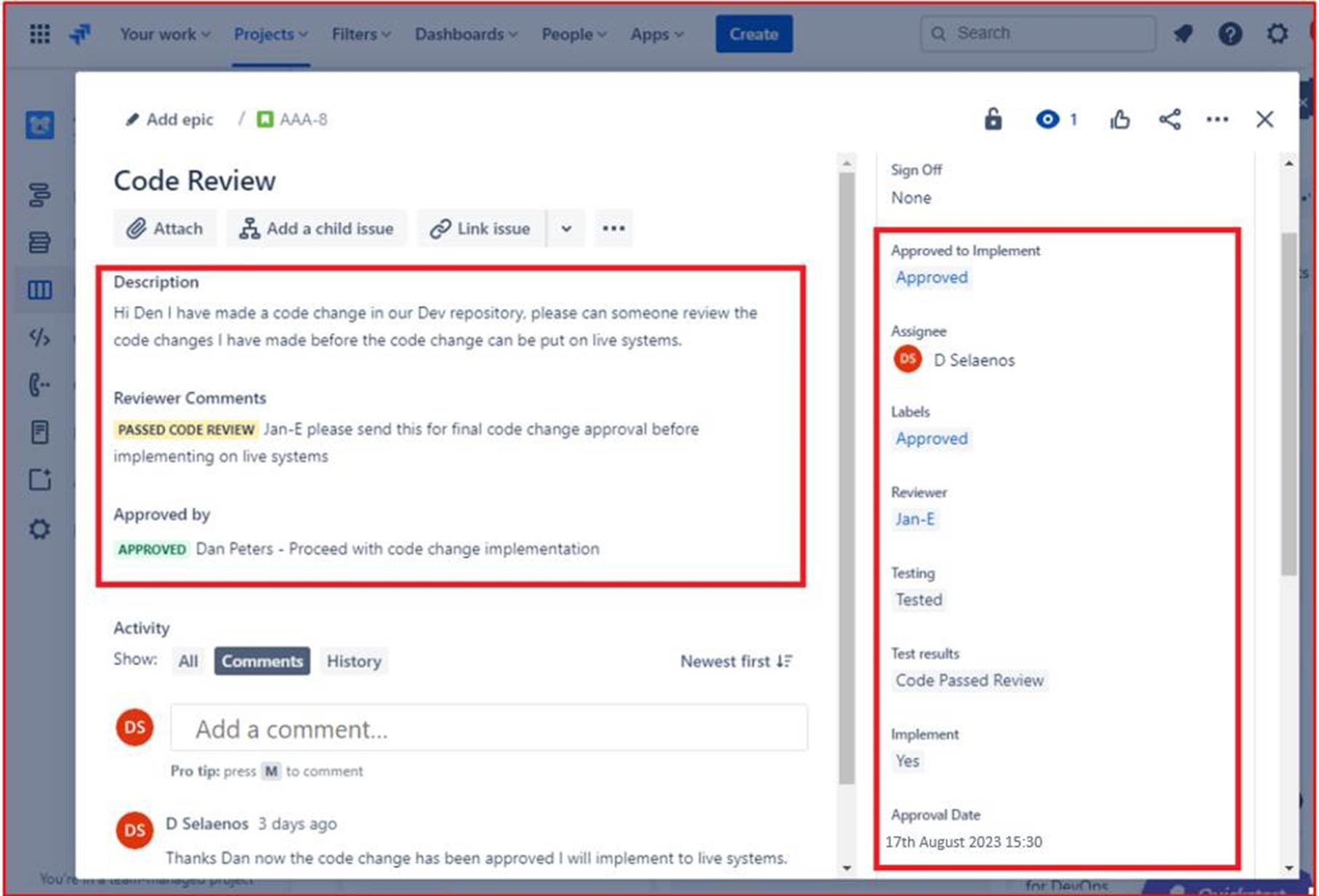
Die folgende Abbildung zeigt, dass der überprüfte Code für die Implementierung in den Liveproduktionssystemen genehmigt wurde. Nachdem die Codeänderungen vorgenommen wurden, wird der endgültige Auftrag abgemeldet. Beachten Sie, dass während des gesamten Prozesses drei Personen beteiligt sind: der ursprüngliche Entwickler des Codes, der Codeprüfer und ein Vorgesetzter, der genehmigungs- und abzeichnen muss. Um die Kriterien für dieses Steuerelement zu erfüllen, wäre es eine Erwartung, dass Ihre Tickets diesem Prozess folgen.
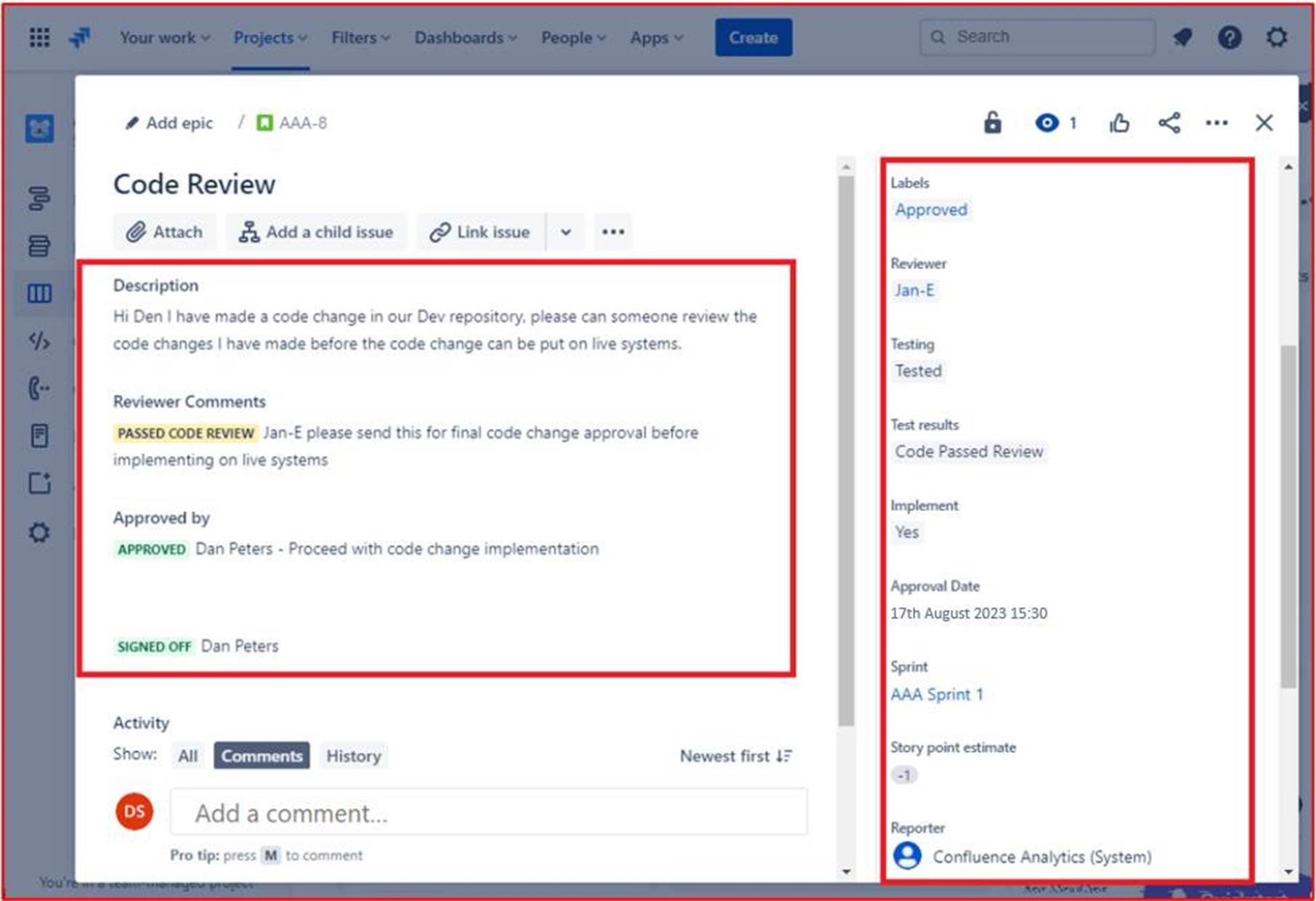
Hinweis: In diesem Beispiel wurde kein vollständiger Screenshot verwendet. Screenshots für ALLE von ISV übermittelten Nachweise müssen jedoch vollständige Screenshots mit url, angemeldeter Benutzer und Systemzeit und -datum sein.
Beispielbeweis: Codeüberprüfung
Neben dem administrativen Teil des oben gezeigten Prozesses können mit modernen Coderepositorys und Plattformen zusätzliche Kontrollen wie die Überprüfung durch Branchrichtlinien implementiert werden, um sicherzustellen, dass Zusammenführungen erst erfolgen können, wenn eine solche Überprüfung abgeschlossen ist. Das folgende Beispiel zeigt, dass dies in DevOps erreicht wird.
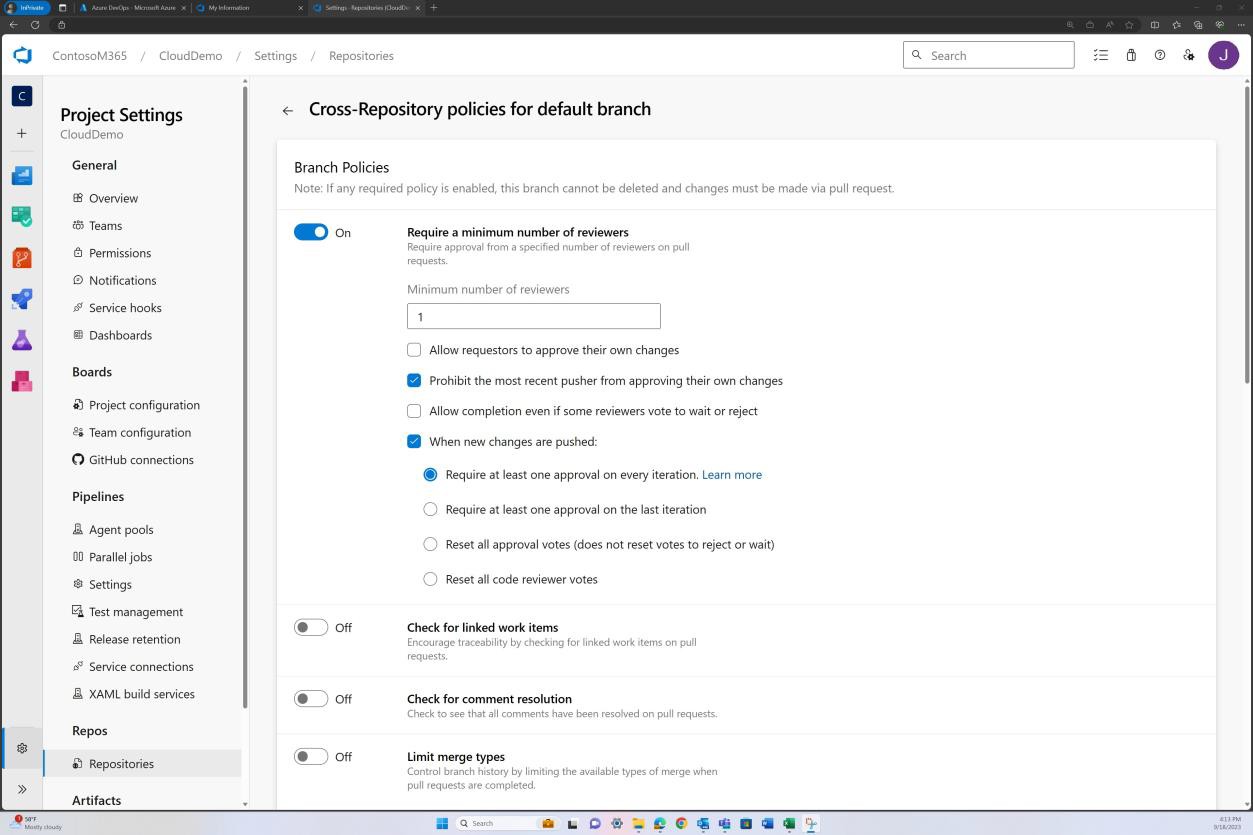
Der nächste Screenshot zeigt, dass Standardprüfer zugewiesen sind und die Überprüfung automatisch erforderlich ist.
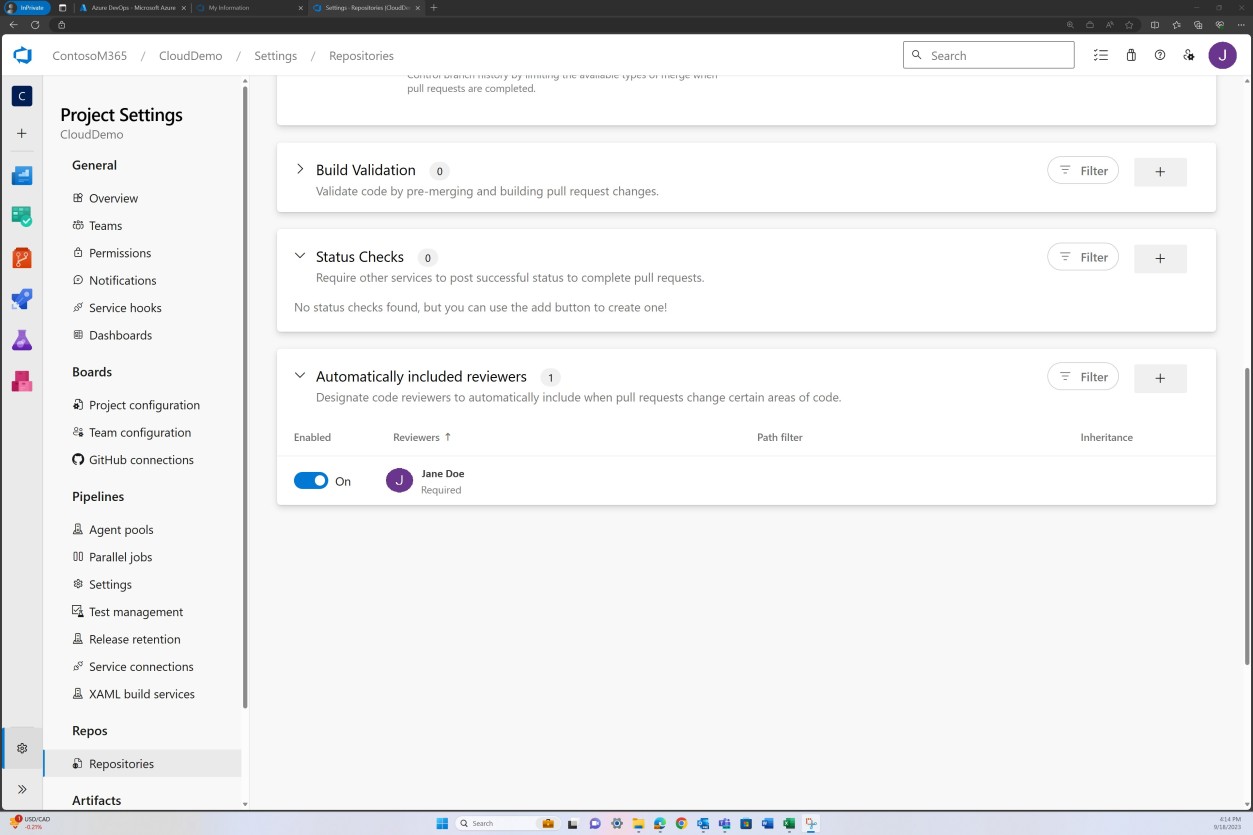
Beispielbeweis: Codeüberprüfung
Die Überprüfung von Branchrichtlinien kann auch in Bitbucket erreicht werden.
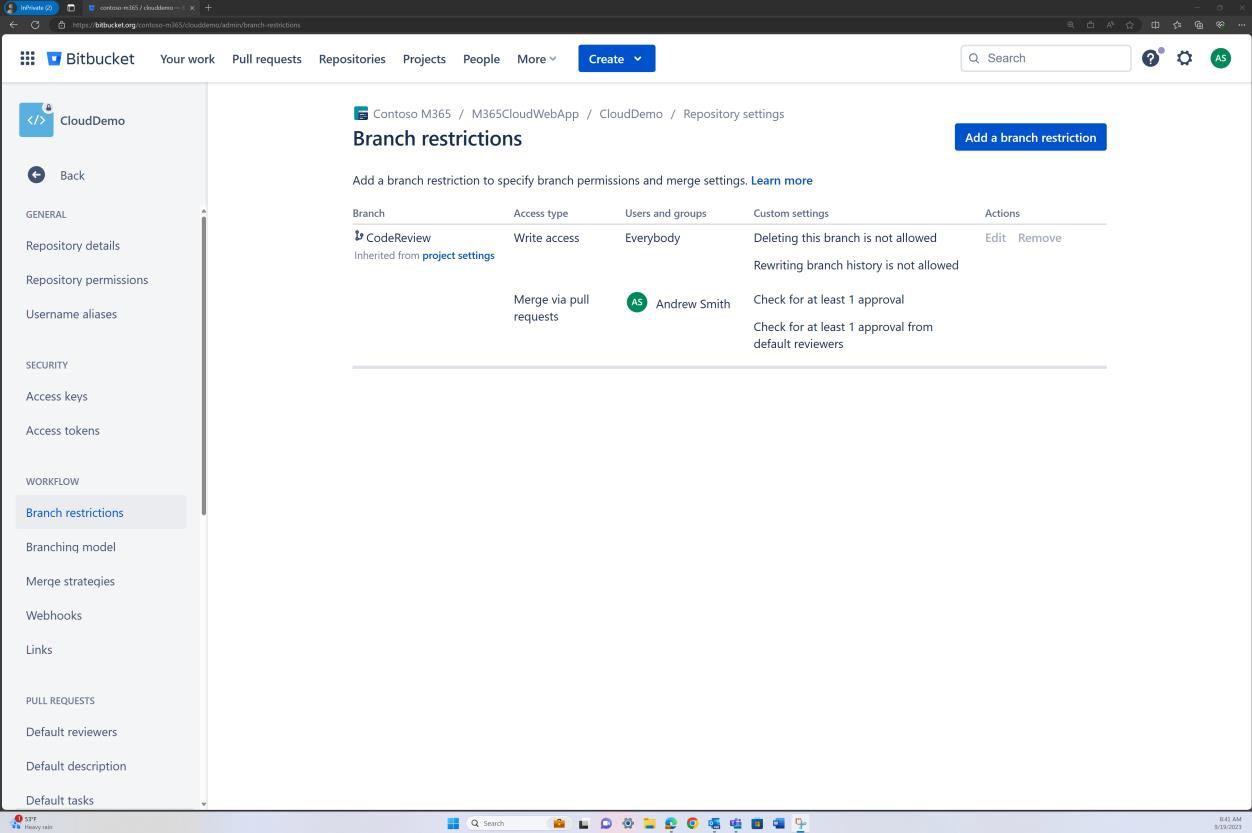
Im nächsten Screenshot wird ein Standardprüfer festgelegt. Dadurch wird sichergestellt, dass alle Zusammenführungen eine Überprüfung von der zugewiesenen Person erfordern, bevor die Änderung an den Mainbranch weitergegeben wird.
Die folgenden beiden Screenshots zeigen ein Beispiel für die angewendeten Konfigurationseinstellungen. Sowie ein abgeschlossener Pull Request, der vom Benutzer Silvester initiiert wurde und die Genehmigung durch den Standardprüfer Andrew erforderte, bevor er mit dem Mainbranch zusammengeführt wurde.
Bitte beachten Sie, dass bei der Bereitstellung des Nachweises davon ausgegangen wird, dass der End-to-End-Prozess nachgewiesen wird. Hinweis: Screenshots sollten bereitgestellt werden, die die Konfigurationseinstellungen zeigen, wenn eine Branchrichtlinie vorhanden ist (oder eine andere programmgesteuerte Methode/Steuerung) und Tickets/Datensätze der Genehmigung erteilt werden.
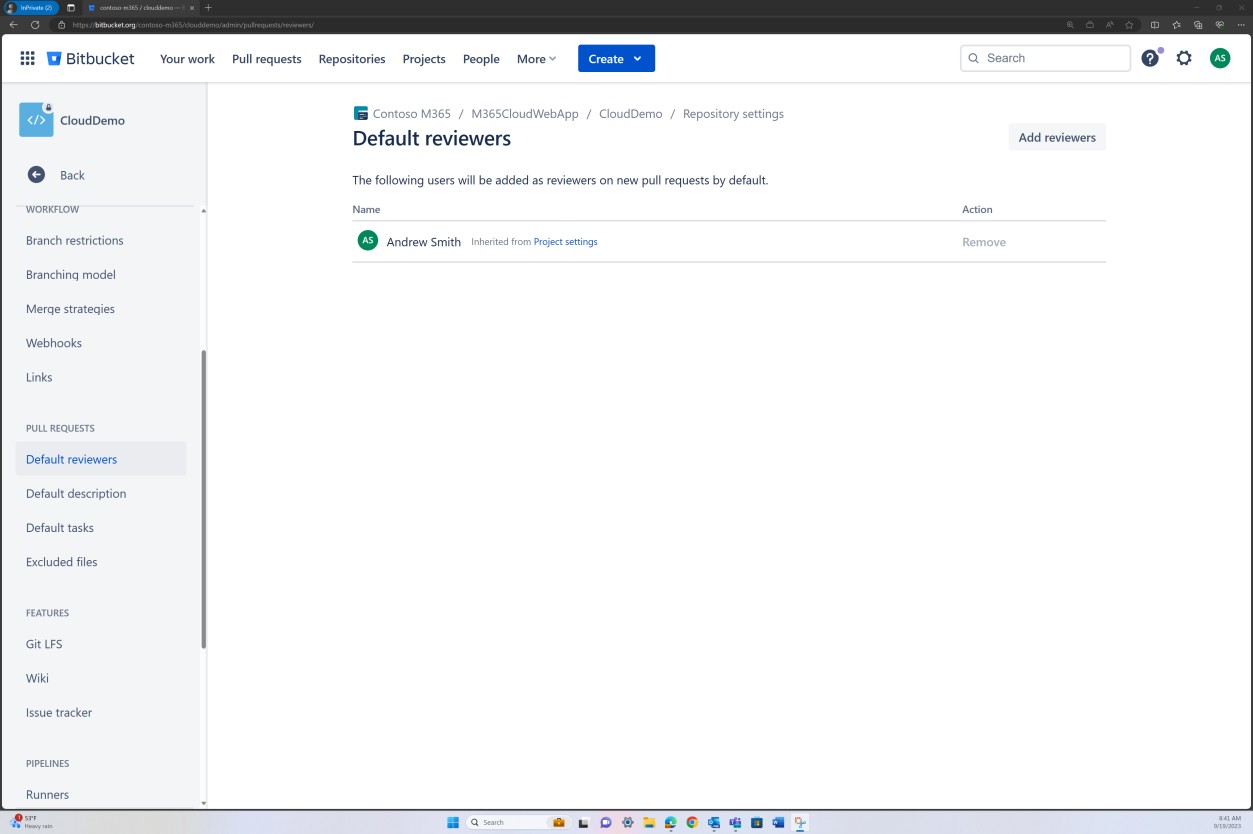
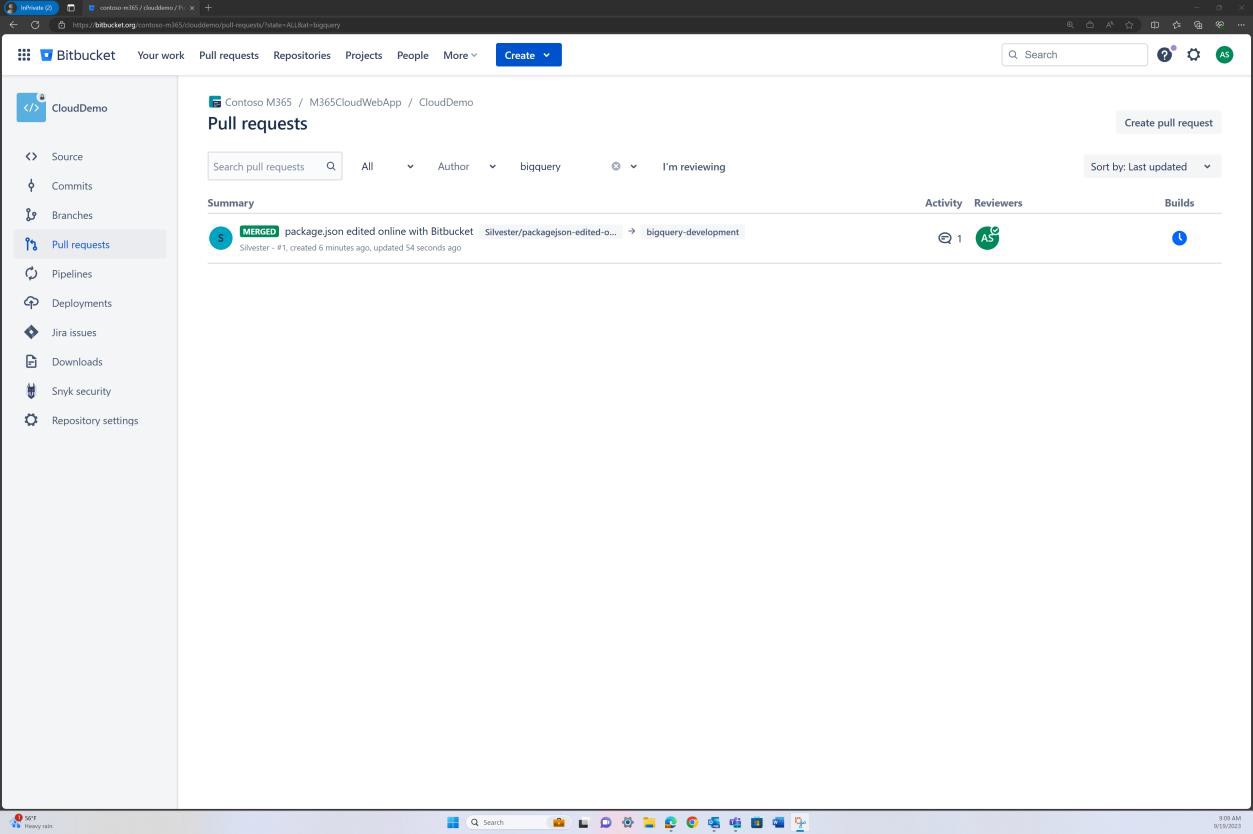
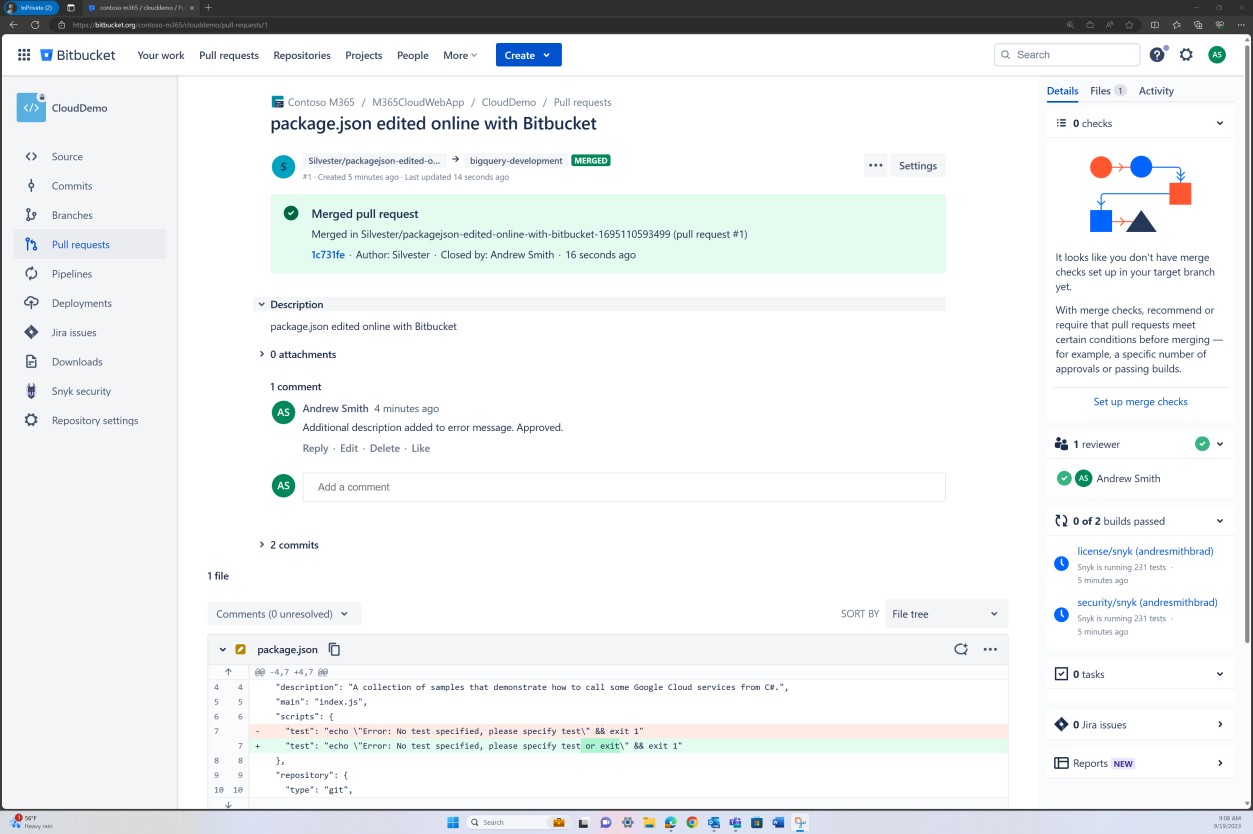
Absicht: Eingeschränkter Zugriff
Im Anschluss an die vorherige Steuerung sollten Zugriffssteuerungen implementiert werden, um den Zugriff nur auf einzelne Benutzer zu beschränken, die an bestimmten Projekten arbeiten. Durch die Einschränkung des Zugriffs können Sie das Risiko von nicht autorisierten Änderungen begrenzen und dadurch unsichere Codeänderungen einführen. Es sollte ein Ansatz mit den geringsten Rechten verwendet werden, um das Coderepository zu schützen.
Richtlinien: Eingeschränkter Zugriff
Stellen Sie anhand von Screenshots aus dem Coderepository den Nachweis bereit, dass der Zugriff auf erforderliche Personen beschränkt ist, einschließlich verschiedener Berechtigungen.
Beispielbeweis: eingeschränkter Zugriff
Die nächsten Screenshots zeigen die Zugriffssteuerungen, die in Azure DevOps implementiert wurden. Es wird angezeigt, dass das "CloudDemo-Team" zwei Mitglieder hat, und jedes Mitglied verfügt über unterschiedliche Berechtigungen.
Hinweis: Die nächsten Screenshots zeigen ein Beispiel für die Art der Beweise und das Format, von denen erwartet wird, dass sie diesem Steuerelement entsprechen. Dies ist keineswegs umfangreich, und die realen Fälle können sich hinsichtlich der Implementierung von Zugriffssteuerungen unterscheiden.
Wenn Berechtigungen auf Gruppenebene festgelegt werden, müssen beweise für jede Gruppe und die Benutzer dieser Gruppe bereitgestellt werden, wie im zweiten Beispiel für Bitbucket gezeigt.
Der folgende Screenshot zeigt die Mitglieder des "CloudDemo-Teams".
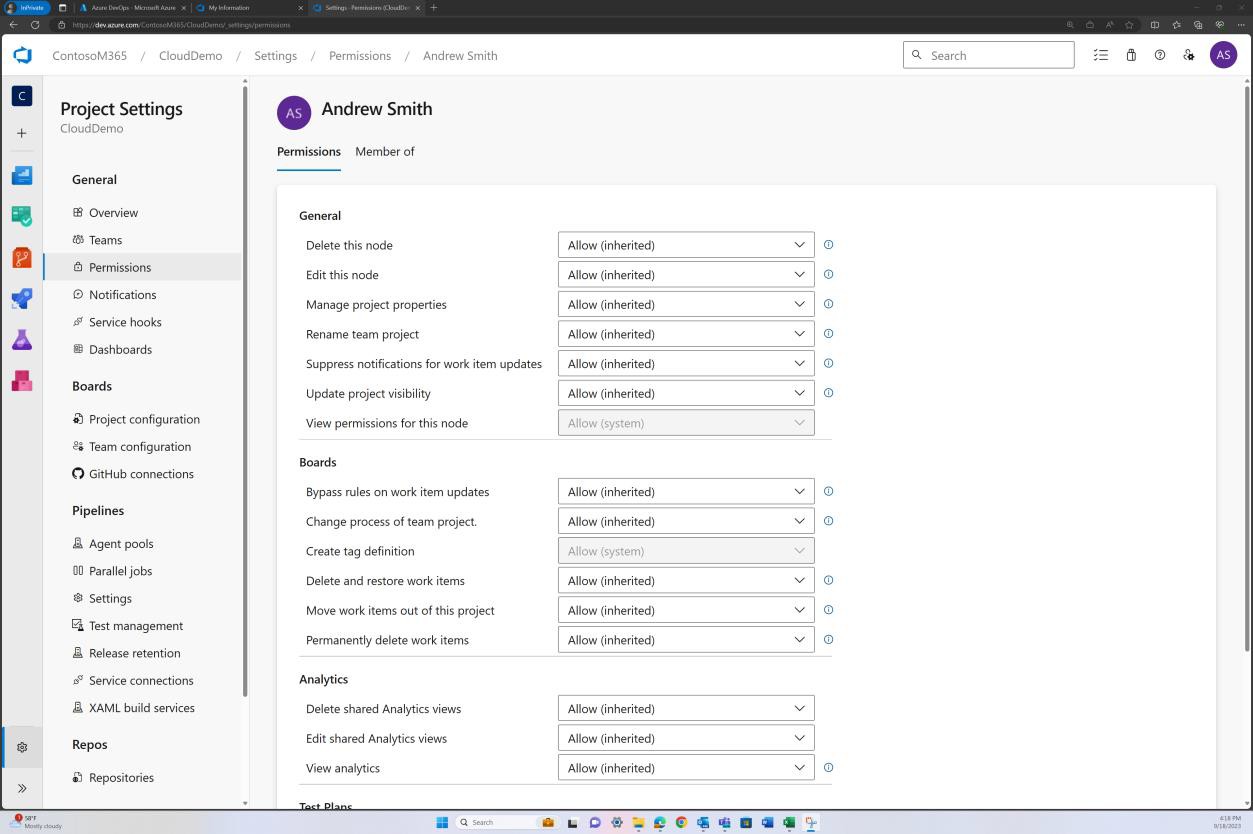
Die vorherige Abbildung zeigt, dass Andrew Smith deutlich höhere Berechtigungen als Projektbesitzer hat als Silvester unten.
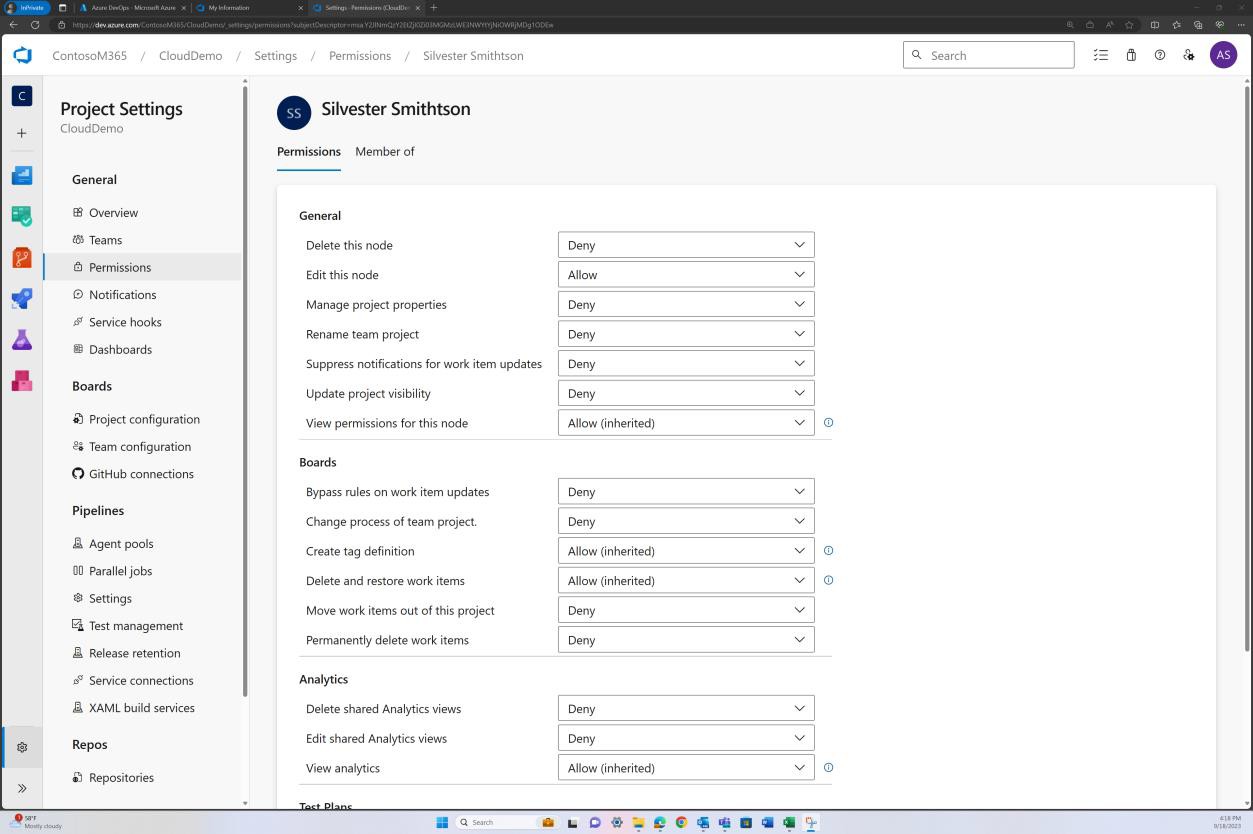
Beispielbeweis
Im nächsten Screenshot werden zugriffssteuerungen, die in Bitbucket implementiert sind, über Berechtigungen erreicht, die auf Gruppenebene festgelegt sind. Für die Repositoryzugriffsebene gibt es eine Gruppe "Administrator" mit einem Benutzer und eine Gruppe "Entwickler" mit einem anderen Benutzer.
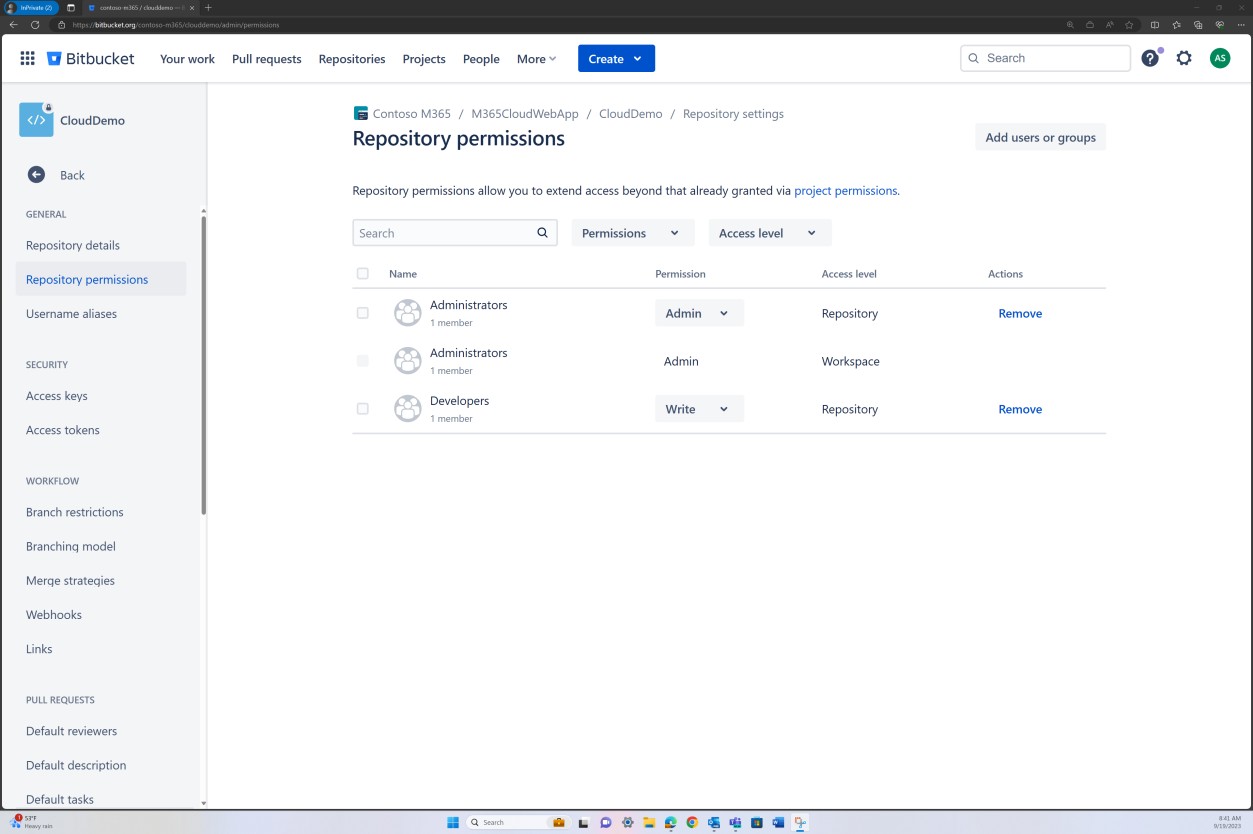
Die nächsten Screenshots zeigen, dass jeder Der Benutzer einer anderen Gruppe angehört und grundsätzlich über eine andere Berechtigungsebene verfügt. Andrew Smith ist der Administrator, und Silvester ist Teil der Entwicklergruppe, die ihm nur Entwicklerrechte gewährt.
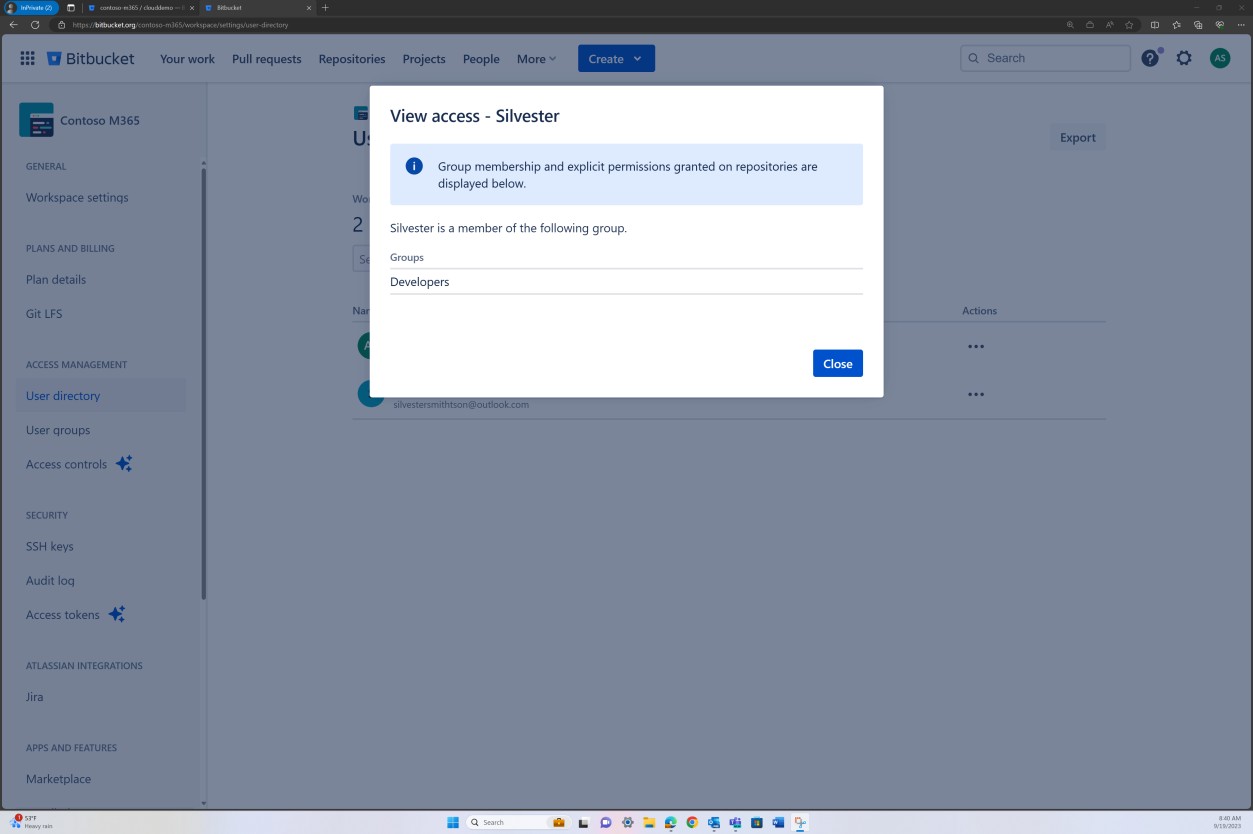
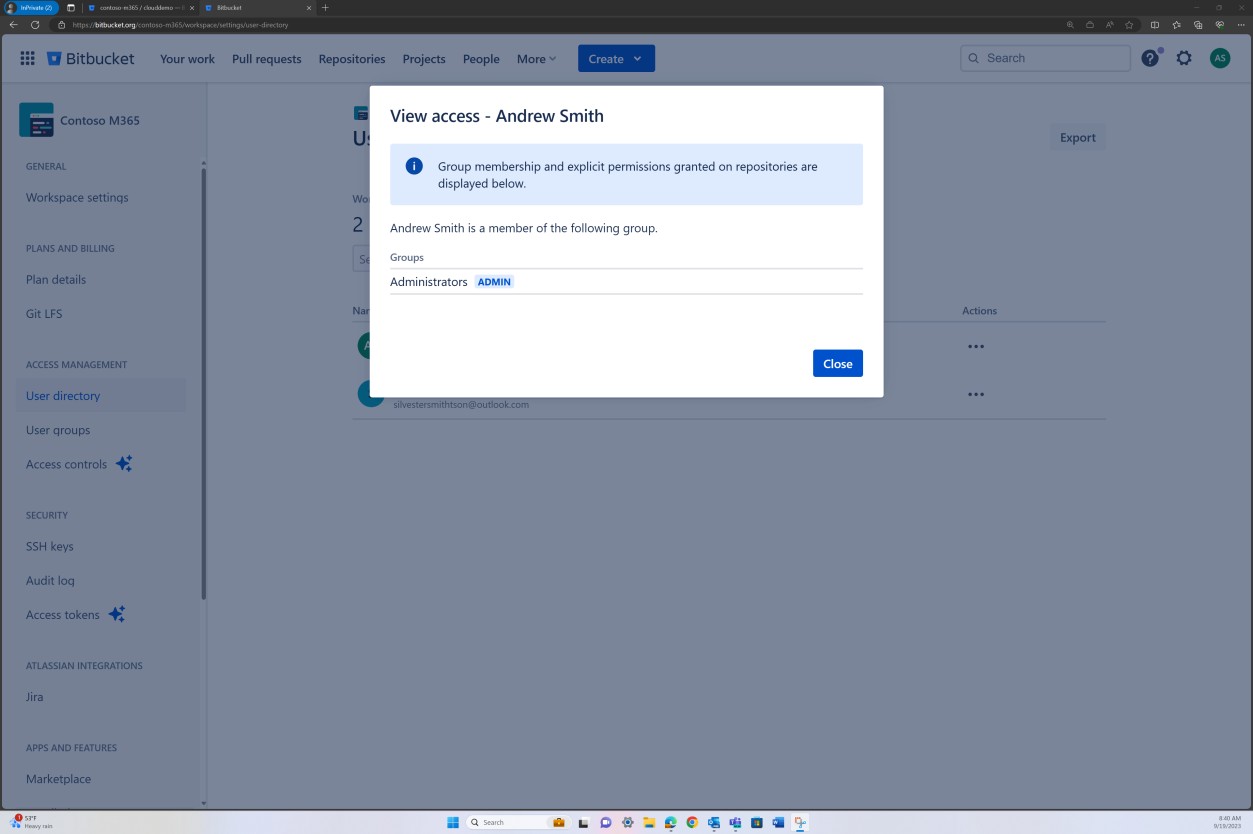
Absicht: MFA
Wenn ein Bedrohungsakteur auf die Codebasis einer Software zugreifen und diese ändern kann, könnte er Sicherheitsrisiken, Backdoors oder schädlichen Code in die Codebasis und damit in die Anwendung einführen. Es gab bereits mehrere Fälle davon, wobei wahrscheinlich der am meisten bekannt gemachte SolarWinds-Angriff von 2020 war, bei dem die Angreifer schädlichen Code in eine Datei eingefügt haben, die später in den Orion-Softwareupdates von SolarWinds enthalten war. Mehr als 18.000 SolarWinds-Kunden installierten die bösartigen Updates, wobei sich die Schadsoftware unentdeckt verbreitete.
Mit diesem Unterpunkt soll überprüft werden, ob der gesamte Zugriff auf Coderepositorys durch mehrstufige Authentifizierung (Multi-Factor Authentication, MFA) erzwungen wird.
Richtlinien: MFA
Stellen Sie anhand von Screenshots aus dem Coderepository den Nachweis bereit, dass für ALLE Benutzer MFA aktiviert ist.
Beispielbeweis: MFA
Wenn die Coderepositorys in Azure DevOps gespeichert und verwaltet werden, können abhängig davon, wie MFA auf Mandantenebene eingerichtet wurde, Beweise von AAD bereitgestellt werden, z. B. "Pro Benutzer-MFA". Der nächste Screenshot zeigt, dass MFA für alle Benutzer in AAD erzwungen wird. Dies gilt auch für Azure DevOps.
Beispielbeweis: MFA
Wenn die organization eine Plattform wie GitHub verwendet, können Sie zeigen, dass die 2FA aktiviert ist, indem Sie die Beweise aus dem Konto "Organisation" freigeben, wie in den nächsten Screenshots gezeigt.
Um anzuzeigen, ob die 2FA für alle Mitglieder Ihrer organization auf GitHub erzwungen wird, können Sie wie im nächsten Screenshot zur Registerkarte "Einstellungen" des organization navigieren.
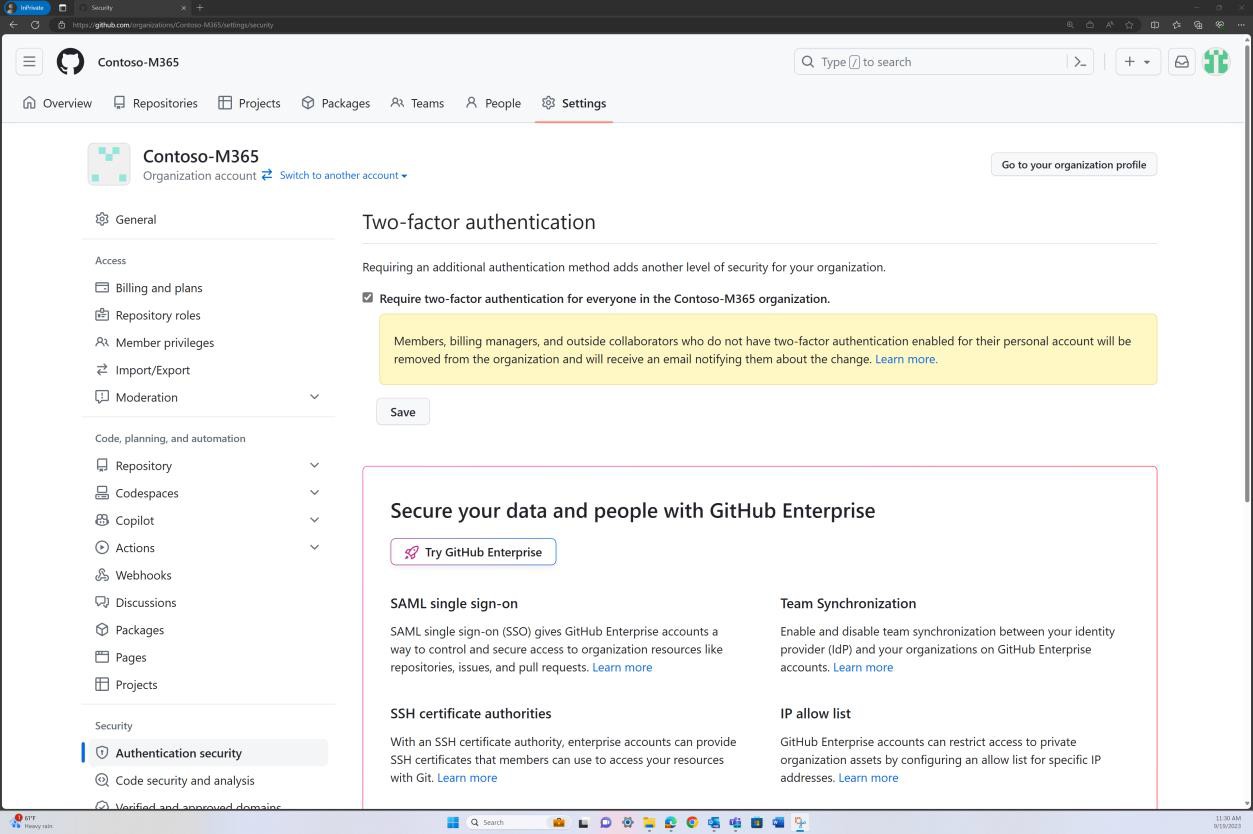
Wenn Sie zur Registerkarte "People" in GitHub navigieren, kann festgestellt werden, dass "2FA" für alle Benutzer innerhalb des organization aktiviert ist, wie im nächsten Screenshot gezeigt.
Absicht: Überprüfungen
Die Absicht dieses Steuerelements besteht darin, eine Überprüfung des Release in einer Entwicklungsumgebung durch einen anderen Entwickler durchzuführen, um Codierungsfehler sowie Fehlkonfigurationen zu identifizieren, die zu einer Sicherheitslücke führen könnten. Die Autorisierung sollte eingerichtet werden, um sicherzustellen, dass Releaseüberprüfungen durchgeführt werden, Tests durchgeführt werden usw. vor der Bereitstellung in der Produktion. Die Autorisierung. schritt kann überprüfen, ob die richtigen Prozesse befolgt wurden, was den SDLC-Prinzipien zugrunde geht.
Richtlinien
Stellen Sie beweise, dass alle Releases aus der Test-/Entwicklungsumgebung in die Produktionsumgebung von einer anderen Person/einem anderen Entwickler als dem Initiator überprüft werden. Wenn dies über eine Continuous Integration/Continuous Deployment-Pipeline erreicht wird, müssen die bereitgestellten Beweise (wie bei Code reviews) zeigen, dass Überprüfungen erzwungen werden.
Beispielbeweis
Im nächsten Screenshot sehen Sie, dass eine CI/CD-Pipeline in Azure DevOps verwendet wird. Die Pipeline enthält zwei Phasen: Entwicklung und Produktion. Ein Release wurde ausgelöst und erfolgreich in der Entwicklungsumgebung bereitgestellt, wurde aber noch nicht in die zweite Phase (Produktion) weitergegeben, und die Genehmigung durch Andrew Smith steht noch aus.
Es wird davon ausgegangen, dass sicherheitsrelevante Tests nach der Bereitstellung für die Entwicklung vom relevanten Team durchgeführt werden, und nur wenn die zugewiesene Person mit der richtigen Berechtigung zum Überprüfen der Bereitstellung eine sekundäre Überprüfung durchgeführt hat und erfüllt ist, dass alle Bedingungen erfüllt sind, dann eine Genehmigung erteilt wird, die die Freigabe in die Produktion ermöglicht.
Die E-Mail-Warnung, die normalerweise vom zugewiesenen Prüfer empfangen wird und informiert, dass eine Bedingung vor der Bereitstellung ausgelöst wurde und dass eine Überprüfung und Genehmigung aussteht.
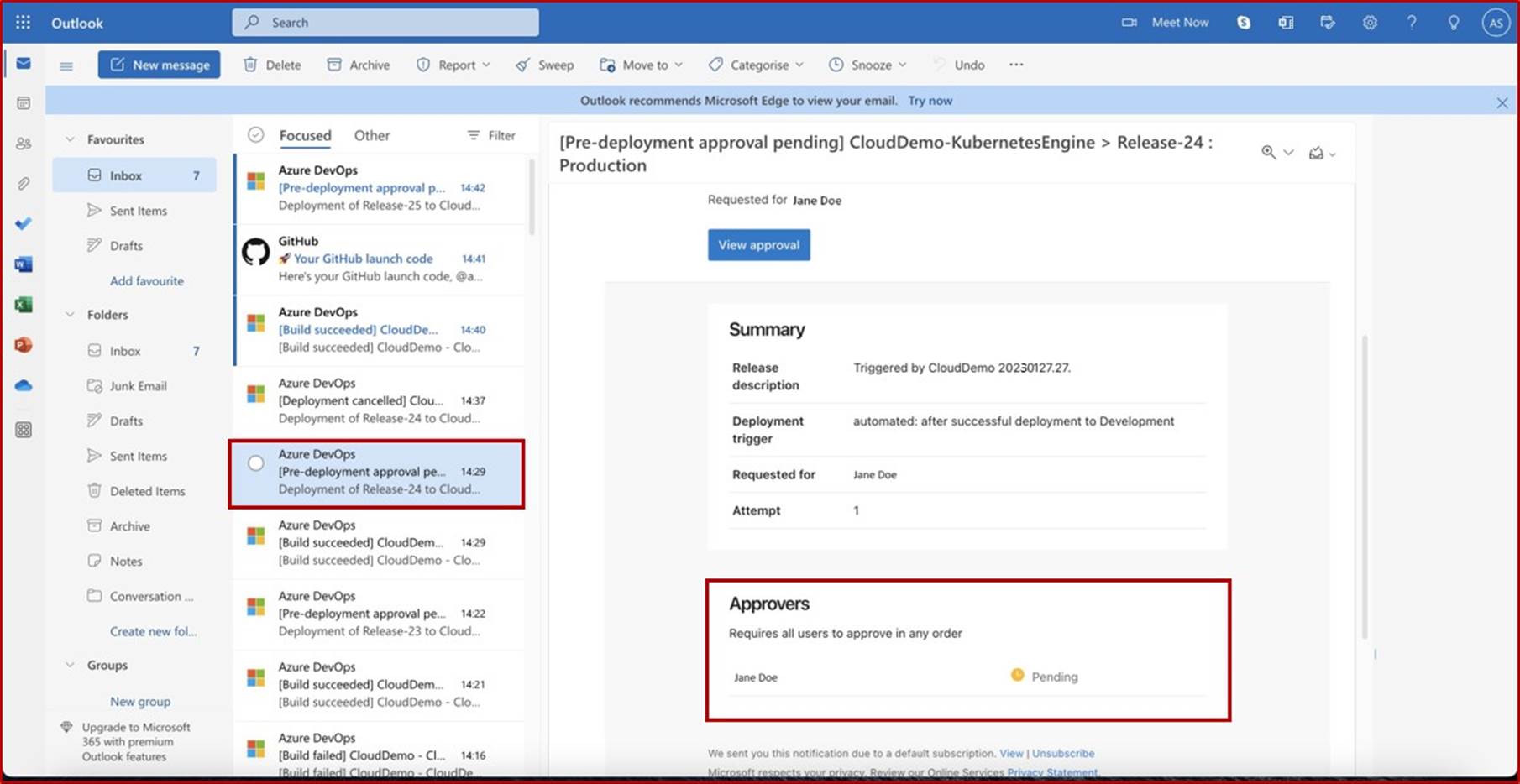
Mithilfe der E-Mail-Benachrichtigung kann der Prüfer zur Releasepipeline in DevOps navigieren und die Genehmigung erteilen. Im Folgenden sehen Wir, dass Kommentare hinzugefügt werden, die die Genehmigung rechtfertigen.
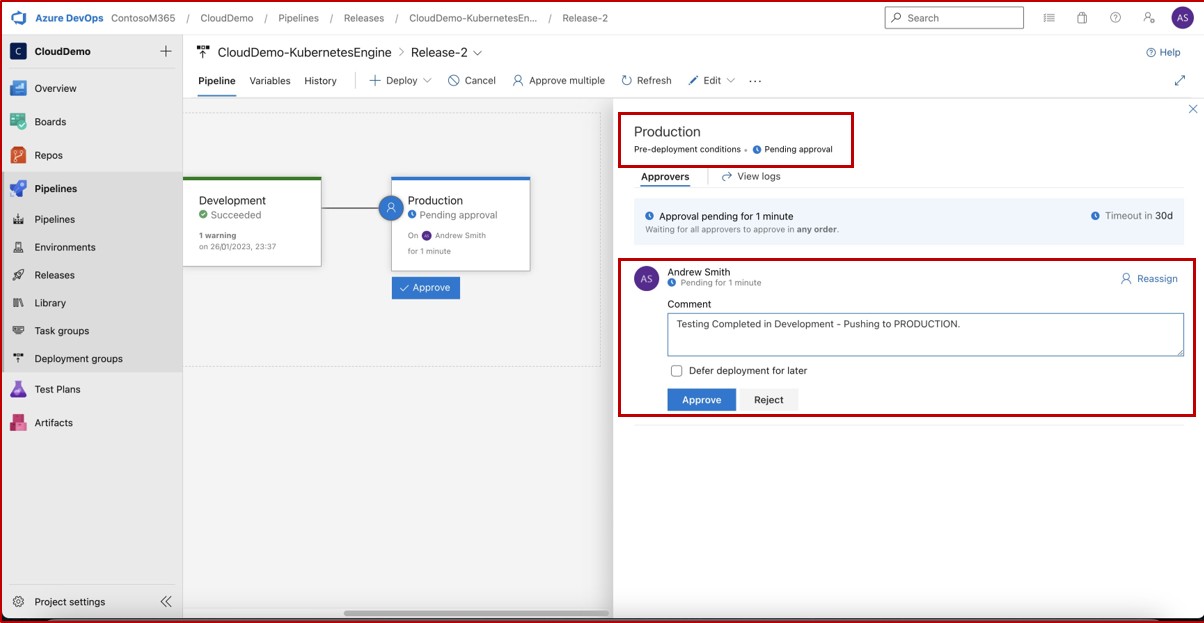
Im zweiten Screenshot ist zu sehen, dass die Genehmigung erteilt wurde und dass die Freigabe in die Produktion erfolgreich war.
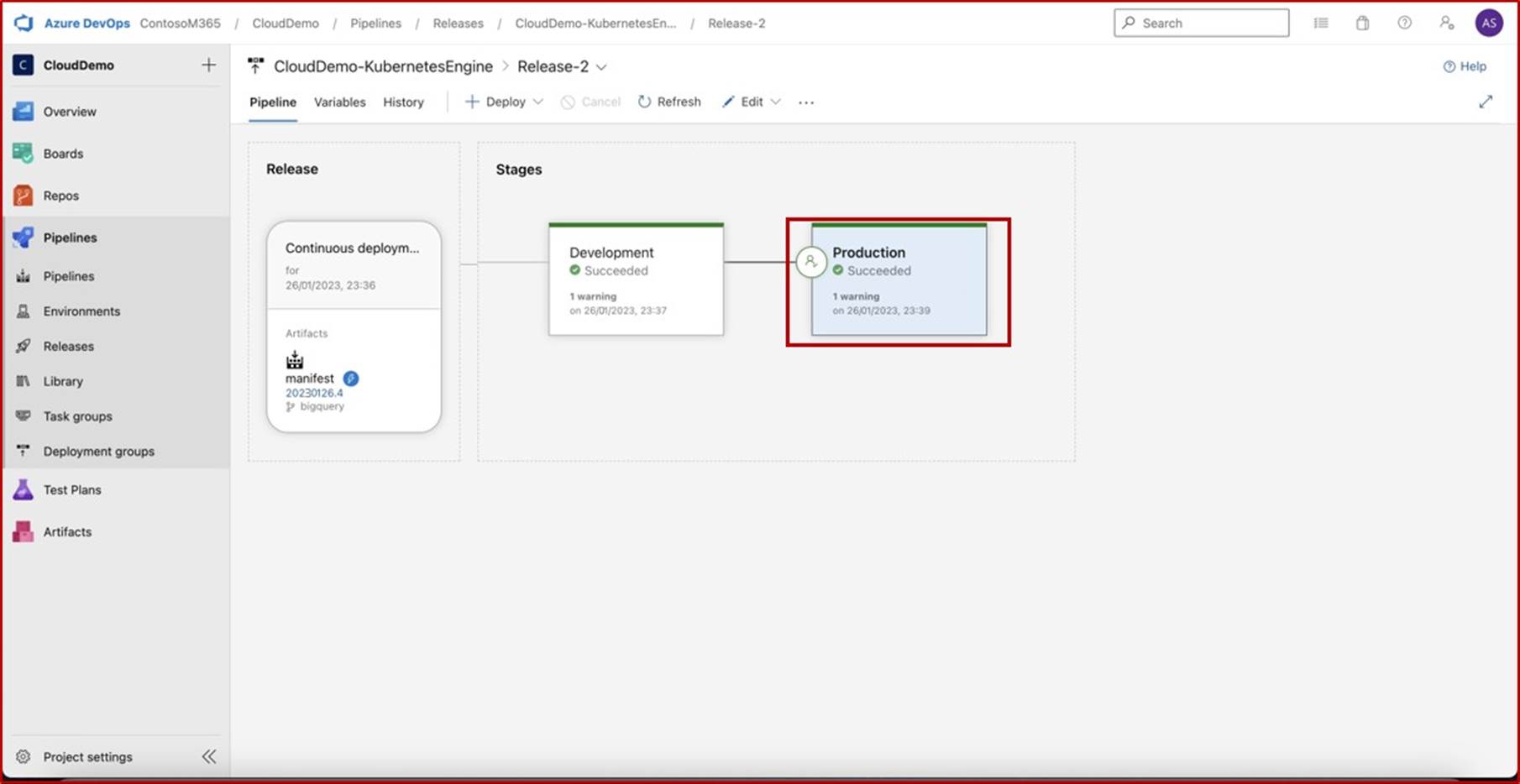
Die nächsten beiden Screenshots zeigen ein Beispiel für die zu erwartenden Beweise.
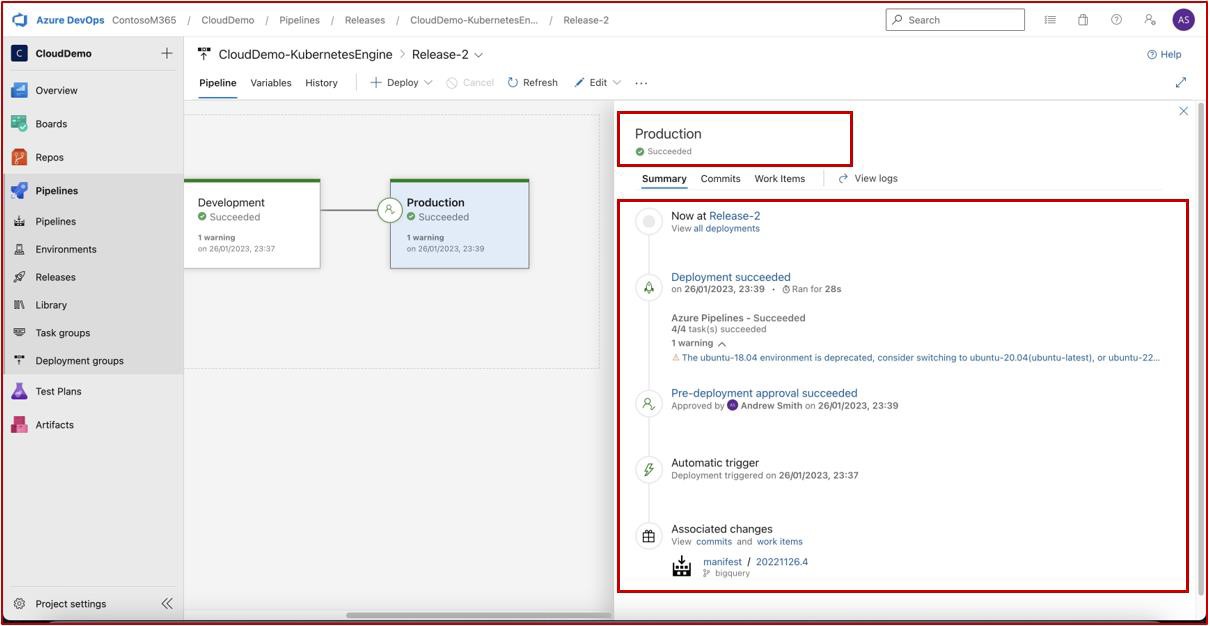
Die Beweise zeigen historische Releases und dass Bedingungen vor der Bereitstellung erzwungen werden, und eine Überprüfung und Genehmigung sind erforderlich, bevor die Bereitstellung in der Produktionsumgebung erfolgen kann.
Der nächste Screenshot zeigt den Verlauf der Releases, einschließlich der aktuellen Version, die sowohl in der Entwicklung als auch in der Produktion erfolgreich bereitgestellt wurde.
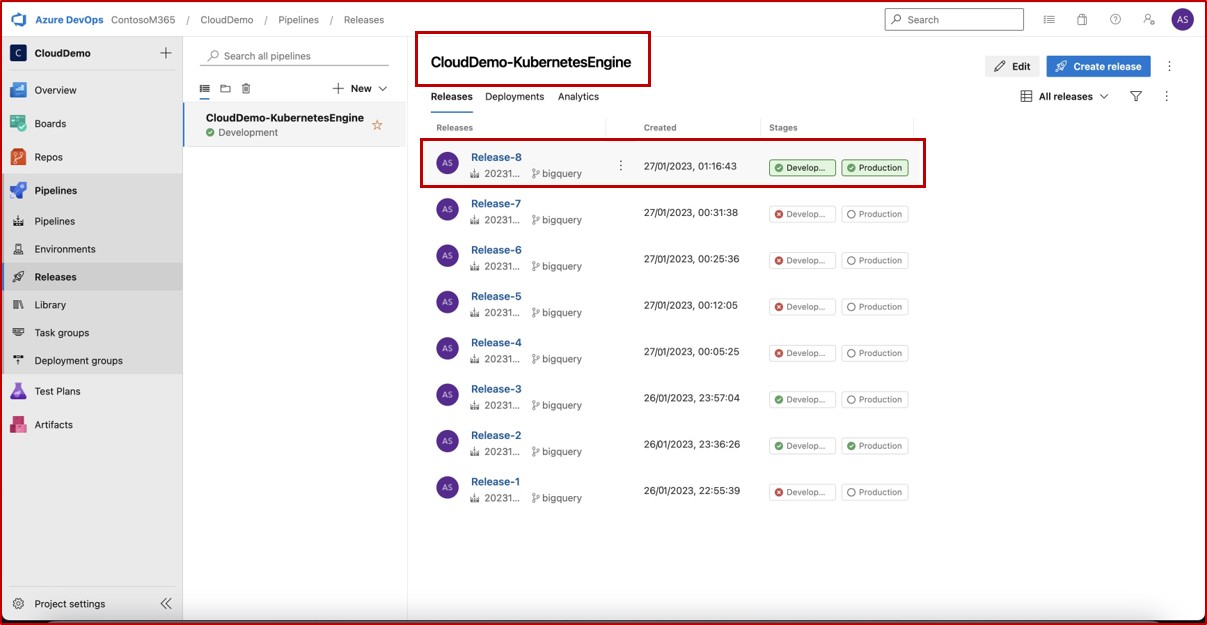
Hinweis: In den vorherigen Beispielen wurde kein vollständiger Screenshot verwendet, jedoch müssen ALLE von ISV übermittelten Beweisscreenshots vollständige Screenshots mit url, allen angemeldeten Benutzern und Systemzeit und -datum sein.
Kontoverwaltung
Sichere Kontoverwaltungsverfahren sind wichtig, da Benutzerkonten die Grundlage für den Zugriff auf Informationssysteme, Systemumgebungen und Daten bilden. Benutzerkonten müssen ordnungsgemäß geschützt werden, da eine Kompromittierung der Anmeldeinformationen des Benutzers nicht nur einen Fuß in die Umgebung und den Zugriff auf vertrauliche Daten bieten kann, sondern auch administrative Kontrolle über die gesamte Umgebung oder Schlüsselsysteme bieten kann, wenn die Anmeldeinformationen des Benutzers Über Administratorrechte verfügen.
Regelung Nr. 14
Stellen Sie Beweise für Folgendes bereit:
Standardanmeldeinformationen werden für die erfassten Systemkomponenten entweder deaktiviert, entfernt oder geändert.
Es ist ein Prozess vorhanden, um Dienstkonten zu schützen (festigen) und dass dieser Prozess befolgt wird.
Absicht: Standardanmeldeinformationen
Obwohl dies immer weniger populär wird, gibt es immer noch Fälle, in denen Bedrohungsakteure standardmäßige und gut dokumentierte Benutzeranmeldeinformationen nutzen können, um Produktionssystemkomponenten zu kompromittieren. Ein beliebtes Beispiel hierfür ist Dell iDRAC (Integrated Dell Remote Access Controller). Dieses System kann verwendet werden, um einen Dell Server remote zu verwalten, der von einem Bedrohungsakteur genutzt werden kann, um die Kontrolle über das Betriebssystem des Servers zu erlangen. Die Standardanmeldeinformationen von root::calvin sind dokumentiert und können häufig von Bedrohungsakteuren genutzt werden, um Zugriff auf Systeme zu erhalten, die von Organisationen verwendet werden. Mit diesem Steuerelement soll sichergestellt werden, dass Standardanmeldeinformationen entweder deaktiviert oder entfernt werden, um die Sicherheit zu erhöhen.
Richtlinien: Standardanmeldeinformationen
Es gibt verschiedene Möglichkeiten, wie Beweise gesammelt werden können, um dieses Steuerelement zu unterstützen. Screenshots von konfigurierten Benutzern in allen Systemkomponenten können hilfreich sein, d. h. Screenshots der Windows-Standardkonten über die Eingabeaufforderung (CMD) und für Linux-Dateien "/etc/shadow" und "/etc/passwd" helfen zu veranschaulichen, ob Konten deaktiviert wurden.
Beispielbeweis: Standardanmeldeinformationen
Der nächste Screenshot zeigt die Datei "/etc/shadow", um zu veranschaulichen, dass Standardkonten ein gesperrtes Kennwort und die neuen erstellten/aktiven Konten über ein verwendbares Kennwort verfügen.
Beachten Sie, dass die Datei "/etc/shadow" erforderlich wäre, um zu veranschaulichen, dass Konten wirklich deaktiviert sind, indem sie beobachten, dass der Kennworthash mit einem ungültigen Zeichen wie "!" beginnt, das angibt, dass das Kennwort nicht verwendet werden kann. In den nächsten Screenshots bedeutet "L", dass das Kennwort des benannten Kontos gesperrt wird. Diese Option deaktiviert ein Kennwort, indem es in einen Wert geändert wird, der keinem möglichen verschlüsselten Wert entspricht (es wird am Anfang des Kennworts ein! hinzugefügt). "P" bedeutet, dass es sich um ein verwendbares Kennwort handelt.
Der zweite Screenshot zeigt, dass auf dem Windows-Server alle Standardkonten deaktiviert wurden. Mithilfe des Befehls "net user" in einem Terminal (CMD) können Sie Details zu jedem vorhandenen Konto auflisten und dabei feststellen, dass nicht alle diese Konten aktiv sind.
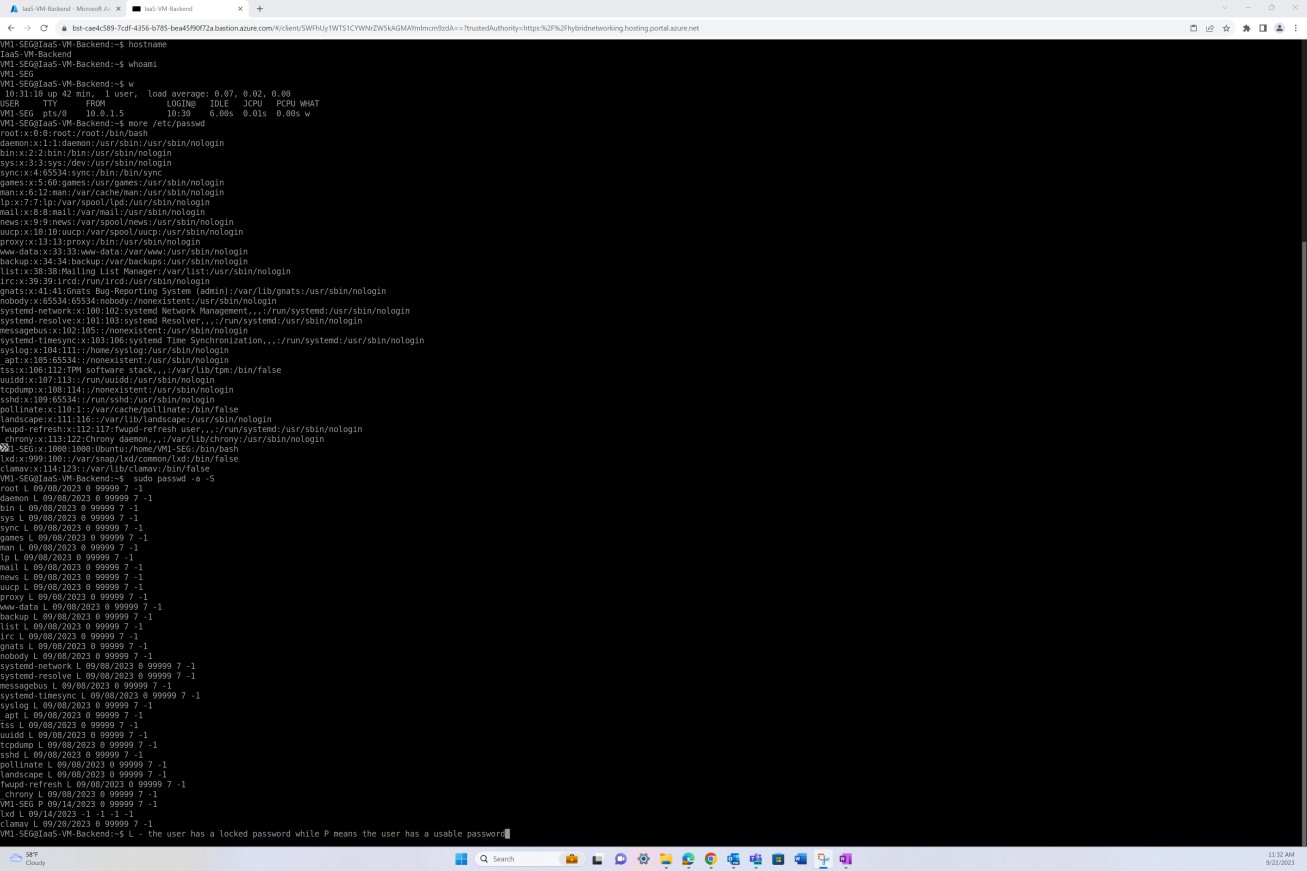
Mithilfe des Befehls net user in CMD können Sie alle Konten anzeigen und feststellen, dass nicht alle Standardkonten aktiv sind.
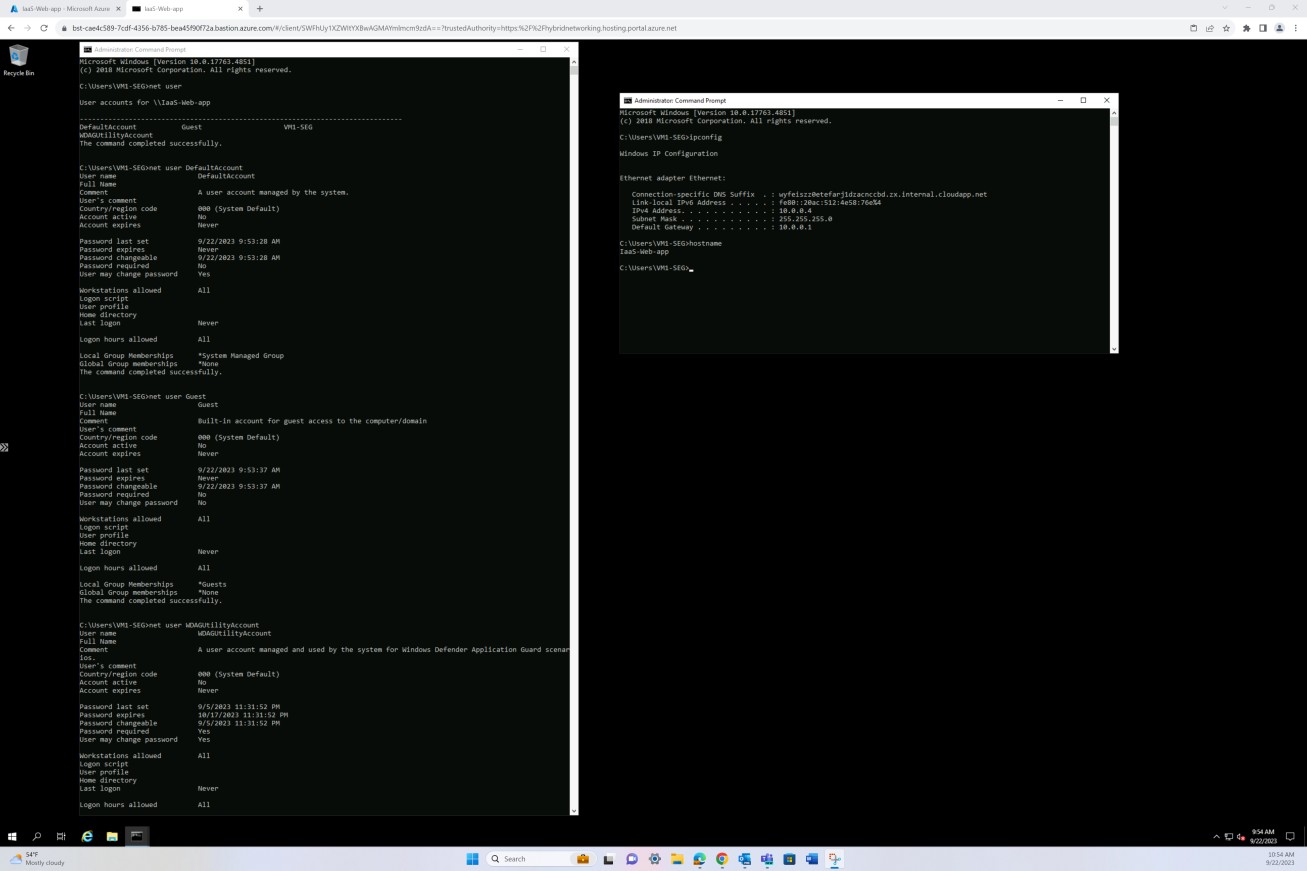
Absicht: Standardanmeldeinformationen
Dienstkonten werden häufig von Bedrohungsakteuren ins Visier genommen, da sie häufig mit erhöhten Berechtigungen konfiguriert sind. Diese Konten folgen möglicherweise nicht den Standardkennwortrichtlinien, da der Ablauf von Dienstkontokennwörtern häufig die Funktionalität beeinträchtigt. Daher können sie mit schwachen Kennwörtern oder Kennwörtern konfiguriert werden, die innerhalb der organization wiederverwendet werden. Ein weiteres potenzielles Problem, insbesondere in einer Windows-Umgebung, kann sein, dass das Betriebssystem den Kennworthash zwischenspeichert. Dies kann ein großes Problem sein, wenn eines der folgenden Probleme besteht:
das Dienstkonto innerhalb eines Verzeichnisdiensts konfiguriert ist, da dieses Konto über mehrere Systeme hinweg mit konfigurierten Berechtigungen verwendet werden kann, oder
Das Dienstkonto ist lokal. Die Wahrscheinlichkeit ist, dass dasselbe Konto/Kennwort auf mehreren Systemen innerhalb der Umgebung verwendet wird.
Die vorherigen Probleme können dazu führen, dass ein Bedrohungsakteur Zugriff auf mehr Systeme innerhalb der Umgebung erhält, und zu einer weiteren Erhöhung der Rechte und/oder lateralen Bewegung führen. Die Absicht besteht daher darin, sicherzustellen, dass Dienstkonten ordnungsgemäß gehärtet und gesichert sind, um sie vor der Übernahme durch einen Bedrohungsakteur zu schützen, oder indem das Risiko begrenzt wird, wenn eines dieser Dienstkonten kompromittiert wird. Die Kontrolle erfordert, dass ein formaler Prozess für die Härtung dieser Konten vorhanden ist, der das Einschränken von Berechtigungen, die Verwendung komplexer Kennwörter und die regelmäßige Rotation von Anmeldeinformationen umfassen kann.
Richtlinien
Es gibt viele Anleitungen im Internet, um Dienstkonten zu härten. Der Beweis kann in Form von Screenshots vorliegen, die zeigen, wie die organization eine sichere Härtung des Kontos implementiert hat. Einige Beispiele (es wird davon ausgegangen, dass mehrere Techniken verwendet werden) sind:
Beschränken der Konten auf eine Gruppe von Computern in Active Directory,
Festlegen des Kontos, sodass die interaktive Anmeldung nicht zulässig ist,
Festlegen eines äußerst komplexen Kennworts,
Aktivieren Sie für Active Directory das Flag "Konto ist vertraulich und kann nicht delegiert werden".
Beispielbeweis
Es gibt mehrere Möglichkeiten, ein Dienstkonto zu härten, das von jeder einzelnen Umgebung abhängig ist. Im Folgenden finden Sie einige der Mechanismen, die verwendet werden können:
Der nächste Screenshot zeigt, dass die Option "Konto ist vertraulich und Verbindung delegiert werden" für das Dienstkonto "_Prod SQL-Dienstkonto" ausgewählt ist.
Dieser zweite Screenshot zeigt, dass das Dienstkonto "_Prod SQL-Dienstkonto" für den SQL Server gesperrt ist und sich nur bei diesem Server anmelden kann.
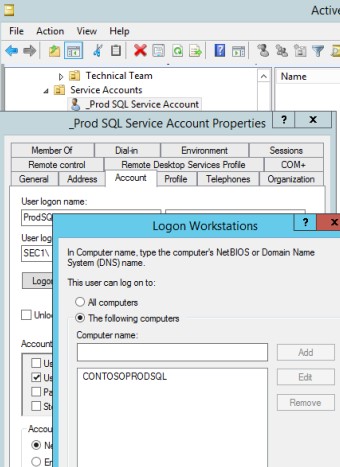
Der nächste Screenshot zeigt, dass das Dienstkonto "_Prod SQL-Dienstkonto" nur als Dienst angemeldet werden darf.
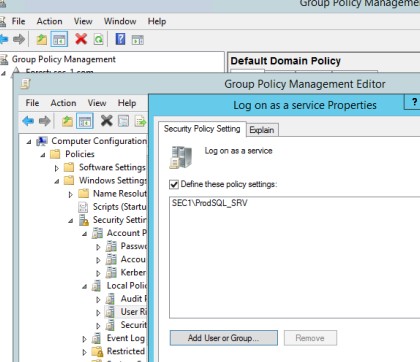
Hinweis: In den vorherigen Beispielen wurde kein vollständiger Screenshot verwendet, jedoch müssen ALLE von ISV übermittelten Beweisscreenshots vollständige Screenshots mit url, allen angemeldeten Benutzern und Systemzeit und -datum sein.
Kontrolle Nr. 15
Stellen Sie Beweise für Folgendes bereit:
Eindeutige Benutzerkonten werden für alle Benutzer ausgestellt.
Die Prinzipien der geringsten Benutzerberechtigungen werden innerhalb der Umgebung befolgt.
Eine Richtlinie für sichere Kennwörter/Passphrasen oder andere geeignete Abhilfemaßnahmen sind vorhanden.
Es wird ein Prozess durchgeführt, der mindestens alle drei (3) Monate ausgeführt wird, um entweder deaktivierte oder gelöschte Konten zu erhalten, die seit drei Monaten nicht verwendet werden.
Absicht: Sichere Dienstkonten
Die Absicht dieses Steuerelements ist die Verantwortlichkeit. Indem Benutzer ihre eigenen eindeutigen Benutzerkonten ausstellen, sind Benutzer für ihre Aktionen verantwortlich, da Benutzeraktivitäten für einen einzelnen Benutzer nachverfolgt werden können.
Richtlinien: Sichere Dienstkonten
Der Beweis wäre durch Screenshots, die konfigurierte Benutzerkonten für die systeminternen Komponenten zeigen, die Server, Coderepositorys, Cloudverwaltungsplattformen, Active Directory, Firewalls usw. umfassen können.
Beispielbeweis: Sichere Dienstkonten
Der nächste Screenshot zeigt Benutzerkonten, die für die bereichsinterne Azure-Umgebung konfiguriert sind und dass alle Konten eindeutig sind.
Absicht: Berechtigungen
Die Benutzer sollten nur über die Berechtigungen verfügen, die zur Erfüllung ihrer Funktion erforderlich sind. Dies soll das Risiko begrenzen, dass ein Benutzer absichtlich oder unbeabsichtigt auf Daten zugreift, die er nicht verwenden sollte, oder ein
böswillige Handlung. Durch die Anwendung dieses Prinzips wird auch die potenzielle Angriffsfläche (d. h. privilegierte Konten) reduziert, die von einem böswilligen Bedrohungsakteur angegriffen werden kann.
Richtlinien: Berechtigungen
Die meisten Organisationen verwenden Gruppen, um Berechtigungen basierend auf Teams innerhalb der organization zuzuweisen. Ein Beweis könnten Screenshots sein, die die verschiedenen privilegierten Gruppen und nur Benutzerkonten aus den Teams zeigen, die diese Berechtigungen benötigen. In der Regel wird dies mit unterstützenden Richtlinien/Prozessen gesichert, die jede definierte Gruppe mit den erforderlichen Berechtigungen und geschäftlichen Begründungen definieren, und eine Hierarchie von Teammitgliedern, um zu überprüfen, ob die Gruppenmitgliedschaft ordnungsgemäß konfiguriert ist.
Beispiel: Innerhalb Azure sollte die Gruppe Besitzer sehr begrenzt sein. Daher sollte dies dokumentiert werden und dieser Gruppe eine begrenzte Anzahl von Personen zugewiesen sein. Ein weiteres Beispiel wäre eine begrenzte Anzahl von Mitarbeitern mit der Möglichkeit, Codeänderungen vorzunehmen. Eine Gruppe kann mit dieser Berechtigung mit den Mitarbeitern eingerichtet werden, die diese Berechtigung benötigen. Dies sollte dokumentiert werden, damit der Zertifizierungsanalyst auf das Dokument mit den konfigurierten Gruppen usw. verweisen kann.
Beispielbeweis: Berechtigungen
Die nächsten Screenshots veranschaulichen das Prinzip der geringsten Rechte in einer Azure-Umgebung.
Der nächste Screenshot zeigt die Verwendung verschiedener Gruppen in Azure Active Directory (AAD)/Microsoft Entra. Beachten Sie, dass es drei Sicherheitsgruppen gibt: Entwickler, Leitende Techniker und Sicherheitsvorgänge.
Wenn Sie zur Gruppe "Entwickler" navigieren, sind auf Gruppenebene die einzigen zugewiesenen Rollen "Anwendungsentwickler" und "Verzeichnisleser".
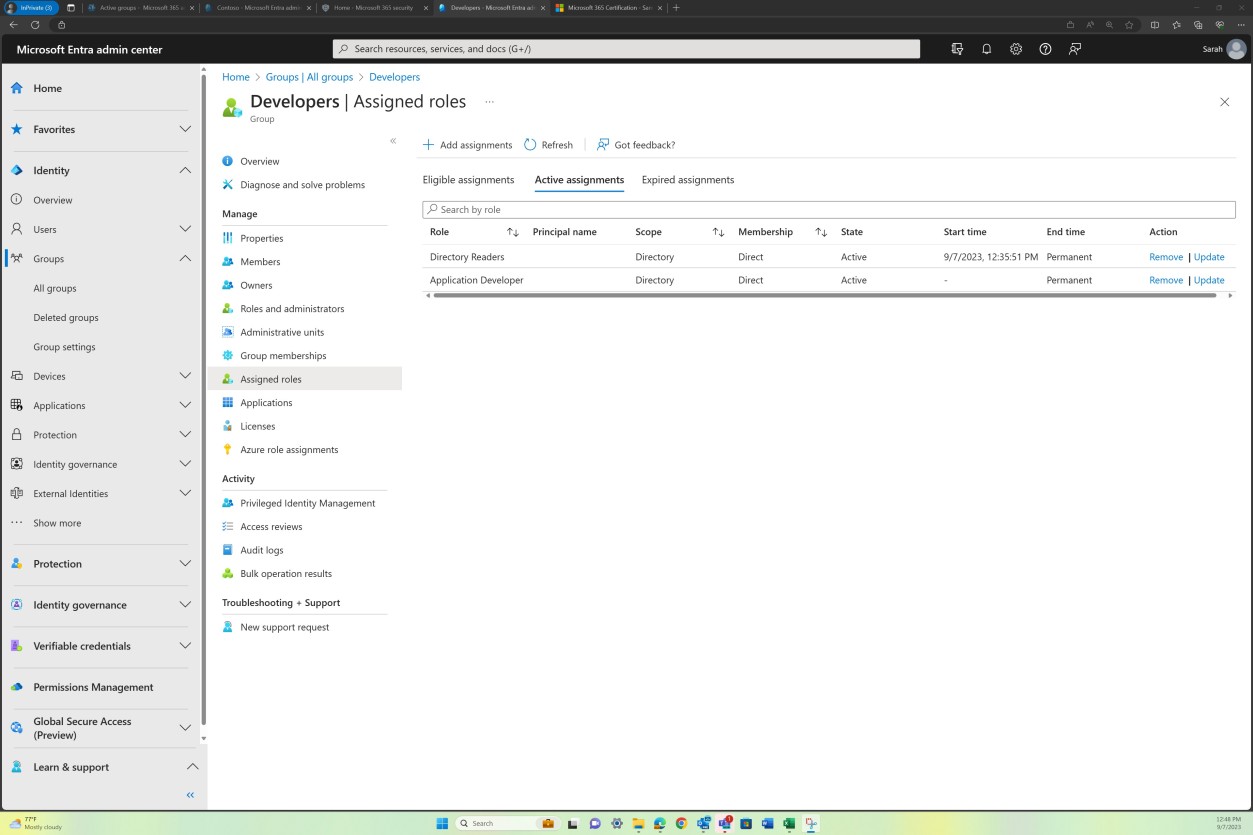
Der nächste Screenshot zeigt die Mitglieder der Gruppe "Entwickler".
Schließlich zeigt der nächste Screenshot den Besitzer der Gruppe.
Im Gegensatz zur Gruppe "Entwickler" sind den "Sicherheitsvorgängen" verschiedene Rollen zugewiesen, d.h. "Sicherheitsoperator", was der Auftragsanforderung entspricht.
Der nächste Screenshot zeigt, dass es verschiedene Mitglieder gibt, die Teil der Gruppe "Sicherheitsvorgänge" sind.
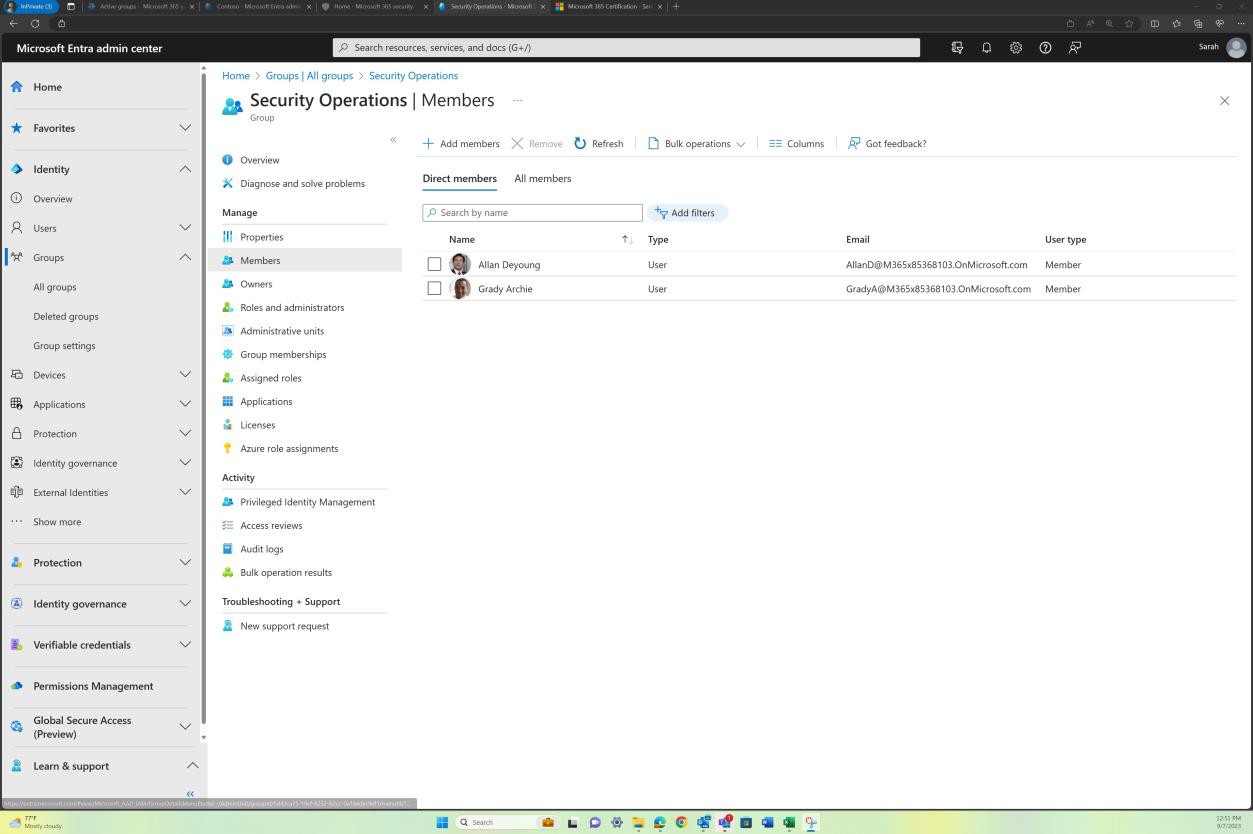
Schließlich hat die Gruppe einen anderen Besitzer.
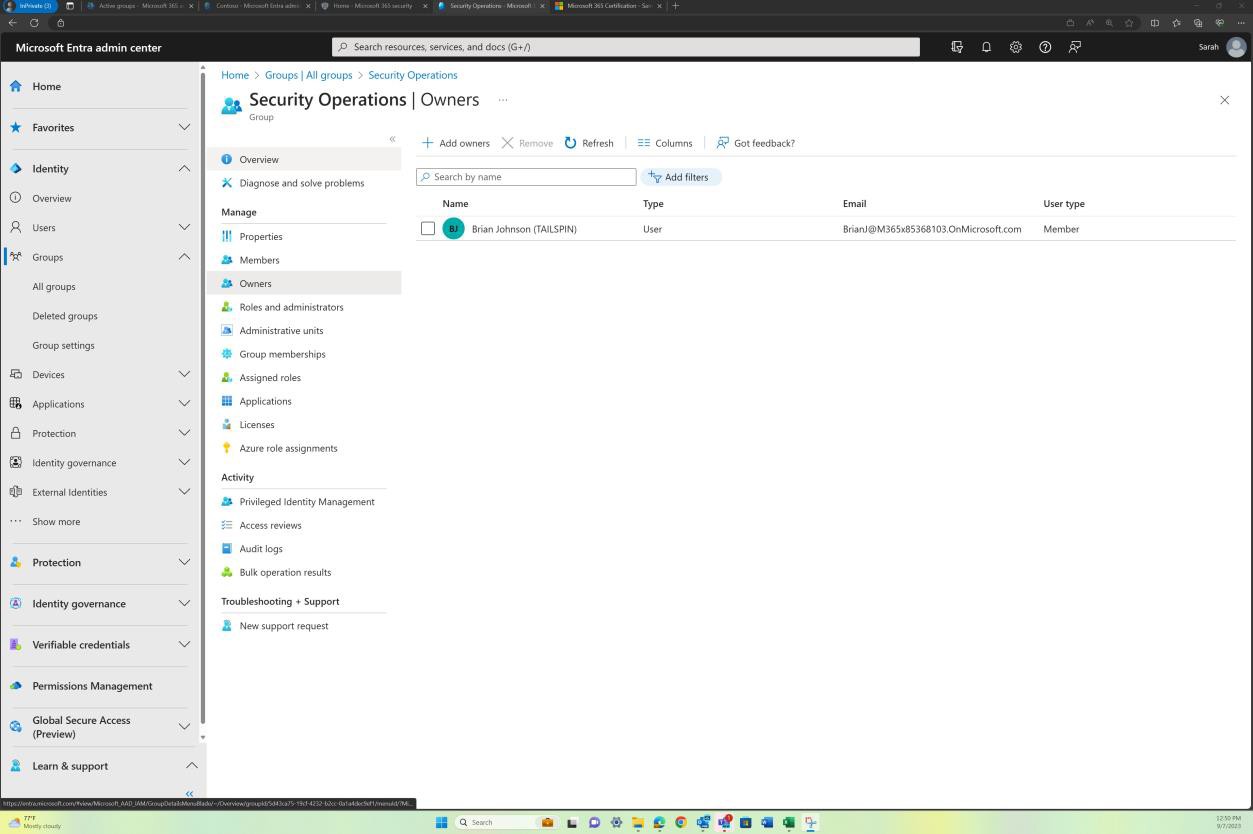
Globale Administratoren sind eine Rolle mit hohen Berechtigungen, und Organisationen müssen entscheiden, welche Risikostufe sie akzeptieren möchten, wenn sie diese Art von Zugriff bereitstellen. Im angegebenen Beispiel gibt es nur zwei Benutzer, die über diese Rolle verfügen. Dadurch soll sichergestellt werden, dass die Angriffsfläche und die Auswirkung verringert werden.
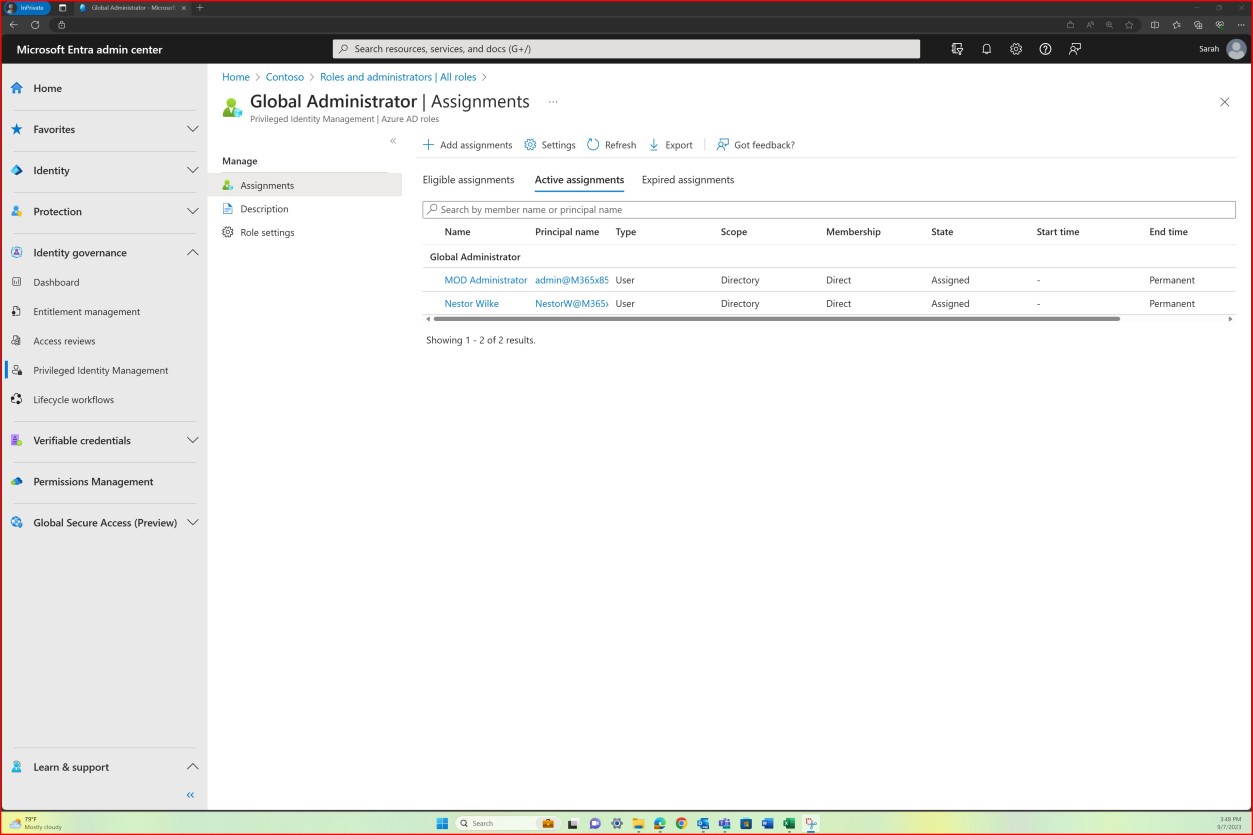
Absicht: Kennwortrichtlinie
Benutzeranmeldeinformationen sind häufig das Ziel eines Angriffs von Bedrohungsakteuren, die versuchen, Zugriff auf die Umgebung eines organization zu erhalten. Die Absicht einer Richtlinie für sichere Kennwörter besteht darin, Benutzer dazu zu zwingen, sichere Kennwörter auszuwählen, um die Wahrscheinlichkeit zu verringern, dass Bedrohungsakteure in der Lage sind, sie mit Brute-Force zu versehen. Die Absicht, die "oder andere geeignete Gegenmaßnahmen" hinzuzufügen, besteht darin, zu erkennen, dass Organisationen andere Sicherheitsmaßnahmen implementieren können, um Benutzeranmeldeinformationen basierend auf Branchenentwicklungen wie NISTSpecial Publication 800-63B zu schützen.
Richtlinien: Kennwortrichtlinie
Der Beweis für eine Richtlinie für sichere Kennwörter kann in Form eines Screenshots einer Organisation Gruppenrichtlinie Objekt oder lokale Sicherheitsrichtlinie "Kontorichtlinien → Kennwortrichtlinie" und "Kontorichtlinien → Kontosperrungsrichtlinie" vorliegen. Die Beweise hängen von den verwendeten Technologien ab, d. h. für Linux könnte es sich um die Konfigurationsdatei /etc/pam.d/common-password handeln, für Bitbucket der Abschnitt "Authentifizierungsrichtlinien" im Admin-Portal [Verwalten Ihrer Kennwortrichtlinie | AtlassianSupport usw.
Beispielbeweis: Kennwortrichtlinie
Der folgende Beweis zeigt die Kennwortrichtlinie, die in der "Lokalen Sicherheitsrichtlinie" der bereichsinternen Systemkomponente "CONTOSO-SRV1" konfiguriert wurde.
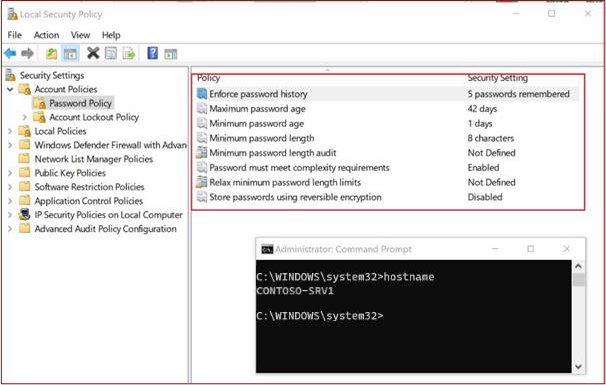
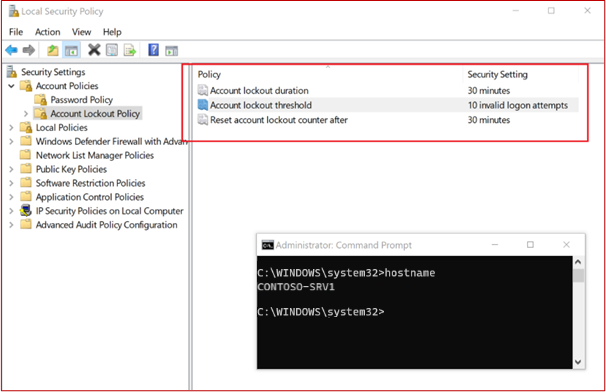
Der nächste Screenshot zeigt die Einstellungen für die Kontosperrung für eine WatchGuard-Firewall.
Es folgt ein Beispiel für eine minimale Passphrasenlänge für die WatchGuard-Firewall.
Bitte beachten Sie: In den vorherigen Beispielen wurde kein vollständiger Screenshot verwendet, aber ALLE von ISV übermittelten Beweisscreenshots müssen vollständige Screenshots mit der URL, allen angemeldeten Benutzern und Systemzeit und -datum sein.
Absicht: inaktive Konten
Inaktive Konten können manchmal kompromittiert werden, weil sie auf Brute-Force-Angriffe abzielen, die möglicherweise nicht gekennzeichnet werden, da der Benutzer nicht versucht, sich bei den Konten anzumelden, oder aufgrund einer Kennwortdatenbankverletzung, bei der das Kennwort eines Benutzers wiederverwendet wurde und innerhalb eines Benutzernamen-/Kennwortabbilds im Internet verfügbar ist. Nicht verwendete Konten sollten deaktiviert/entfernt werden, um die Angriffsfläche zu verringern, die ein Bedrohungsakteur für die Durchführung von Kontokompromittierungsaktivitäten hat. Diese Konten können darauf zurückzuführen sein, dass ein Abgängerprozess nicht ordnungsgemäß durchgeführt wird, ein Mitarbeiter, der langfristig krank ist, oder ein Mitarbeiter, der mutterschafts-/vaterschaftsurlaub geht. Durch die Implementierung eines vierteljährlichen Prozesses zur Identifizierung dieser Konten können Organisationen die Angriffsfläche minimieren.
Diese Kontrolle schreibt vor, dass ein Prozess eingerichtet und mindestens alle drei Monate befolgt werden muss, um Konten zu deaktivieren oder zu löschen, die in den letzten drei Monaten nicht verwendet wurden, um das Risiko zu verringern, indem regelmäßige Kontoüberprüfungen und die rechtzeitige Deaktivierung nicht verwendeter Konten sichergestellt werden.
Richtlinien: inaktive Konten
Der Beweis sollte zweifach sein:
Zunächst ein Screenshot oder Dateiexport, der die "letzte Anmeldung" aller Benutzerkonten in der Bereichsumgebung anzeigt. Dies können sowohl lokale Konten als auch Konten in einem zentralisierten Verzeichnisdienst sein, z. B. AAD (Azure Active Directory). Dies zeigt, dass keine Konten aktiviert sind, die älter als 3 Monate sind.
Zweitens der Nachweis des vierteljährlichen Überprüfungsprozesses, der nachweisbar sein kann, dass die Aufgabe innerhalb von ADO-Tickets (Azure DevOps) oder JIRA-Tickets oder durch Papieraufzeichnungen abgeschlossen wird, die abgemeldet werden sollten.
Beispielbeweis: inaktive Konten
Der nächste Screenshot zeigt, dass eine Cloudplattform verwendet wurde, um Zugriffsüberprüfungen durchzuführen. Dies wurde mithilfe des Identity Governance-Features in Azure erreicht.
Der nächste Screenshot zeigt den Überprüfungsverlauf, den Überprüfungszeitraum und die status.
Die Dashboard und Metriken aus der Überprüfung enthalten zusätzliche Details, z. B. den Bereich, der alle Benutzer des organization und das Ergebnis der Überprüfung ist, sowie die Häufigkeit, die vierteljährlich ist.
Bei der Bewertung der Ergebnisse der Überprüfung gibt das Bild an, dass eine empfohlene Aktion bereitgestellt wurde, die auf vorkonfigurierten Bedingungen basiert. Darüber hinaus muss eine zugewiesene Person die Entscheidungen der Überprüfung manuell anwenden.
Sie können im Folgenden sehen, dass für jeden Mitarbeiter eine Empfehlung und eine Begründung angegeben wird. Wie bereits erwähnt, ist eine Entscheidung, die Empfehlung zu akzeptieren oder zu ignorieren, bevor die Überprüfung angewendet wird, von einer zugewiesenen Person erforderlich. Wenn die endgültige Entscheidung gegen die Empfehlung ist, wird erwartet, dass Beweise vorgelegt werden, um den Grund zu erläutern.
Regelung Nr. 16
HARTER FEHLER
Stellen Sie Beweise für Folgendes bereit:
- MFA ist für den gesamten Remotezugriff und alle Verwaltungsschnittstellen ohne Konsole und Cloudverwaltungsschnittstellen konfiguriert.
Bedeutung dieser Begriffe
Remotezugriff: Dies bezieht sich auf Technologien, die für den Zugriff auf die unterstützende Umgebung verwendet werden. Beispiel: REMOTE Access IPSec VPN, SSL VPN oder Jumpbox/Bastian Host.
Verwaltungsschnittstellen ohne Konsole: Dies bezieht sich auf die Netzwerkadministratorverbindungen mit Systemkomponenten. Dies kann über Remotedesktop, SSH oder eine Webschnittstelle erfolgen.
Cloudverwaltungsschnittstellen: Hierbei wird die Umgebung teilweise oder die gesamte Umgebung innerhalb des Clouddienstanbieters (Cloud Service Provider, CSP) gehostet. Die Verwaltungsschnittstelle für die Cloudverwaltung ist hier enthalten.
Absicht: MFA
Die Absicht dieser Kontrolle besteht darin, Maßnahmen gegen Brute-Force-Angriffe auf privilegierte Konten mit sicherem Zugriff auf die Umgebung durch Implementierung der mehrstufigen Authentifizierung (Multi-Factor Authentication , MFA) bereitzustellen. Selbst wenn ein Kennwort kompromittiert wird, sollte der MFA-Mechanismus weiterhin geschützt werden, um sicherzustellen, dass alle Zugriffs- und Verwaltungsaktionen nur von autorisierten und vertrauenswürdigen Mitarbeitern durchgeführt werden.
Um die Sicherheit zu erhöhen, ist es wichtig, eine zusätzliche Sicherheitsebene für Remotezugriffsverbindungen und Nicht-Konsolen-Verwaltungsschnittstellen mit MFA hinzuzufügen. Remotezugriffsverbindungen sind besonders anfällig für nicht autorisierten Zugriff, und Verwaltungsschnittstellen steuern Funktionen mit hohen Berechtigungen, was beide kritische Bereiche macht, die erhöhte Sicherheitsmaßnahmen erfordern. Darüber hinaus enthalten Coderepositorys sensible Entwicklungsarbeit, und Cloudverwaltungsschnittstellen bieten umfassenden Zugriff auf die Cloudressourcen eines organization, sodass sie zusätzliche kritische Punkte darstellen, die mit MFA geschützt werden sollten.
Richtlinien: MFA
Es muss nachgewiesen werden, dass MFA für alle Technologien aktiviert ist, die in die vorherigen Kategorien passen. Dies kann ein Screenshot sein, der zeigt, dass MFA auf Systemebene aktiviert ist. Auf Systemebene benötigen wir einen Nachweis, dass es für alle Benutzer aktiviert ist, und nicht nur ein Beispiel für ein Konto mit aktivierter MFA. Wenn die Technologie auf eine MFA-Lösung zurückgesichert wird, benötigen wir den Nachweis, dass sie aktiviert und verwendet wird. Was damit gemeint ist, ist; Wenn die Technologie für die Radius-Authentifizierung eingerichtet ist, die auf einen MFA-Anbieter verweist, müssen Sie auch nachweisen, dass der Radius-Server, auf den sie verweist, eine MFA-Lösung ist und dass Konten für die Verwendung konfiguriert sind.
Beispielbeweis: MFA
Die nächsten Screenshots veranschaulichen, wie eine bedingte MFA-Richtlinie in AAD/Entra implementiert werden kann, um die Anforderung der zweistufigen Authentifizierung im gesamten organization zu erzwingen. Wir können im Folgenden sehen, dass die Richtlinie "ein" ist.
Der nächste Screenshot zeigt, dass die MFA-Richtlinie auf alle Benutzer innerhalb des organization angewendet werden soll und dass dies aktiviert ist.
Der nächste Screenshot zeigt, dass der Zugriff gewährt wird, wenn die MFA-Bedingung erfüllt wird. Auf der rechten Seite des Screenshots sehen Wir, dass der Zugriff nur einem Benutzer gewährt wird, nachdem MFA implementiert wurde.
Beispielbeweis: MFA
Zusätzliche Kontrollen können implementiert werden, z. B. eine MFA-Registrierungsanforderung, die sicherstellt, dass Benutzer bei der Registrierung MFA konfigurieren müssen, bevor der Zugriff auf ihr neues Konto gewährt wird. Im Folgenden sehen Sie die Konfiguration einer MFA-Registrierungsrichtlinie, die auf alle Benutzer angewendet wird.
In Fortsetzung des vorherigen Screenshots, der die Richtlinie zeigt, die ohne Ausschlüsse angewendet werden soll, zeigt der nächste Screenshot, dass alle Benutzer in die Richtlinie eingeschlossen sind.
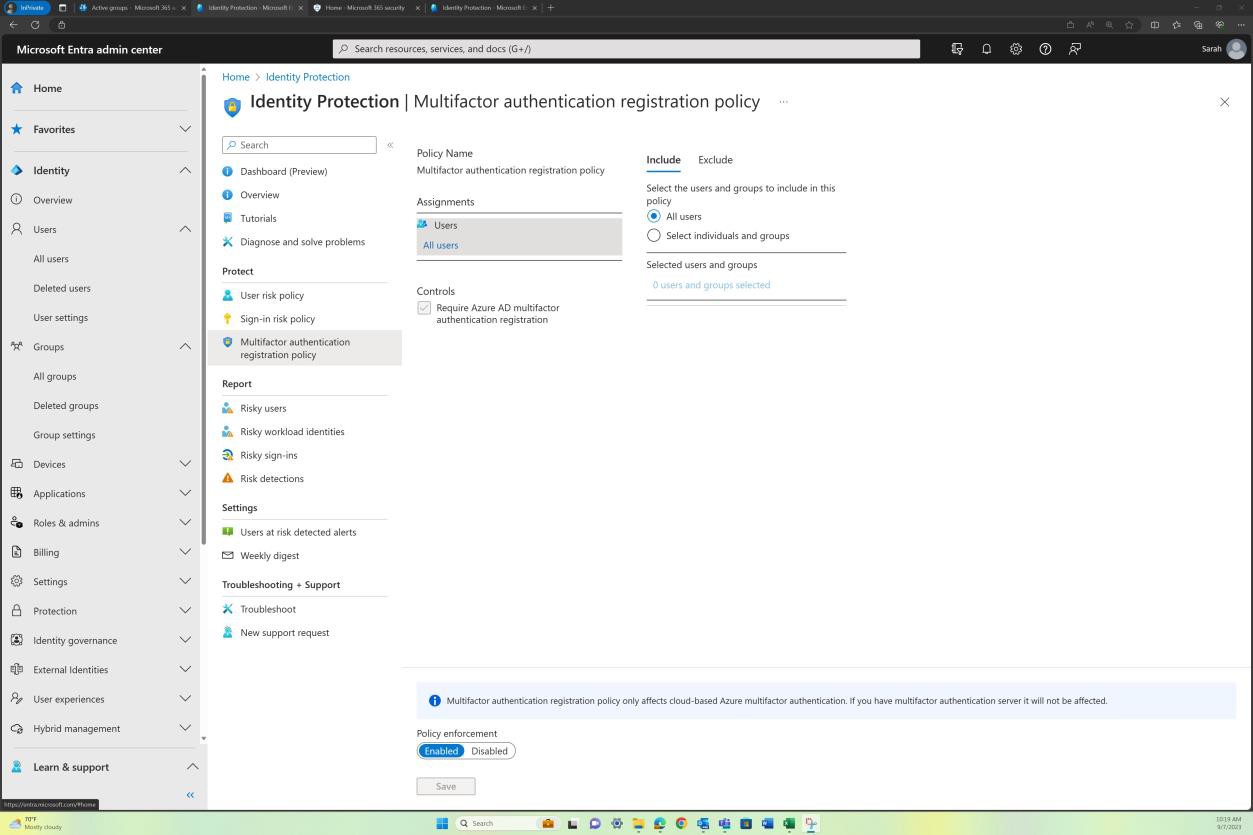
Beispielbeweis: MFA
Der nächste Screenshot zeigt, dass die Seite "MFA pro Benutzer" zeigt, dass MFA für alle Benutzer erzwungen wird.
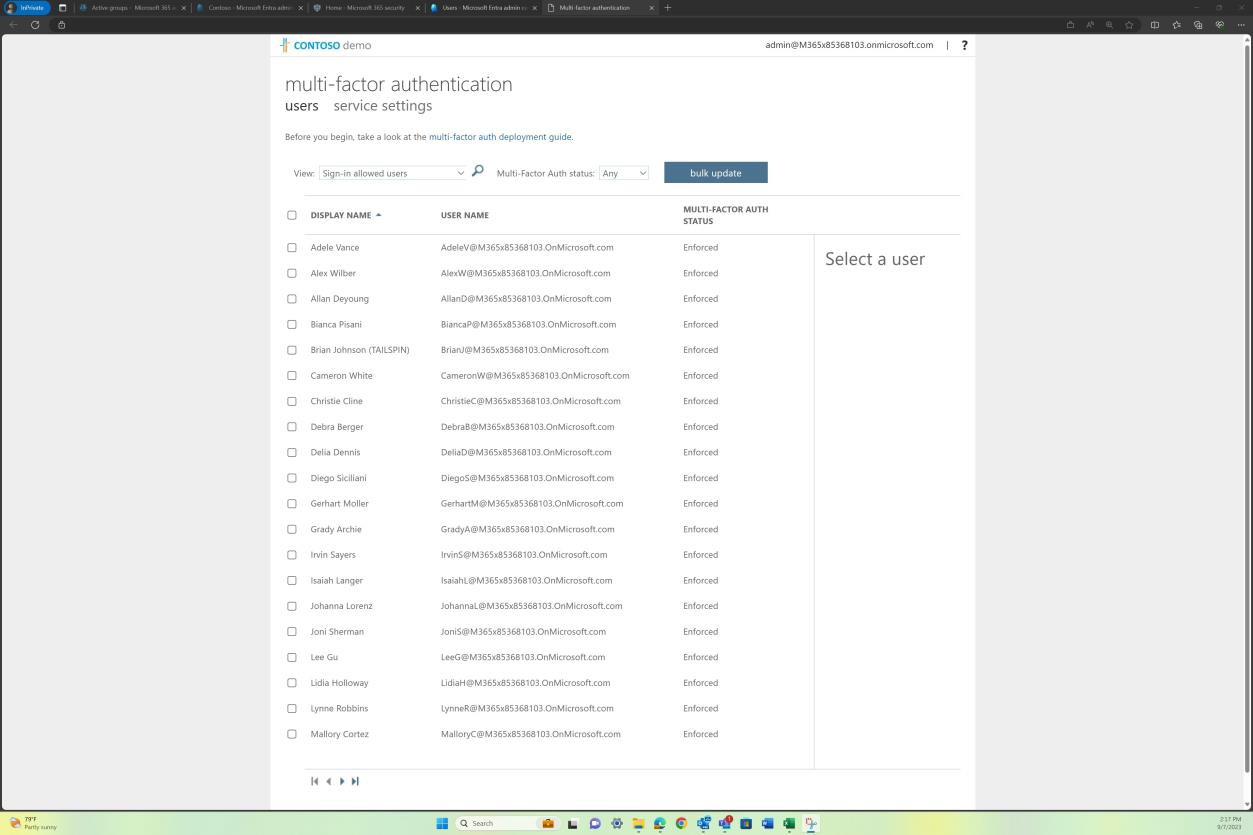
Beispielbeweis: MFA
Die nächsten Screenshots zeigen die in Pulse Secure konfigurierten Authentifizierungsbereiche, die für den Remotezugriff auf die Umgebung verwendet werden. Die Authentifizierung wird vom Duo SaaS Service for MFA-Support gesichert.
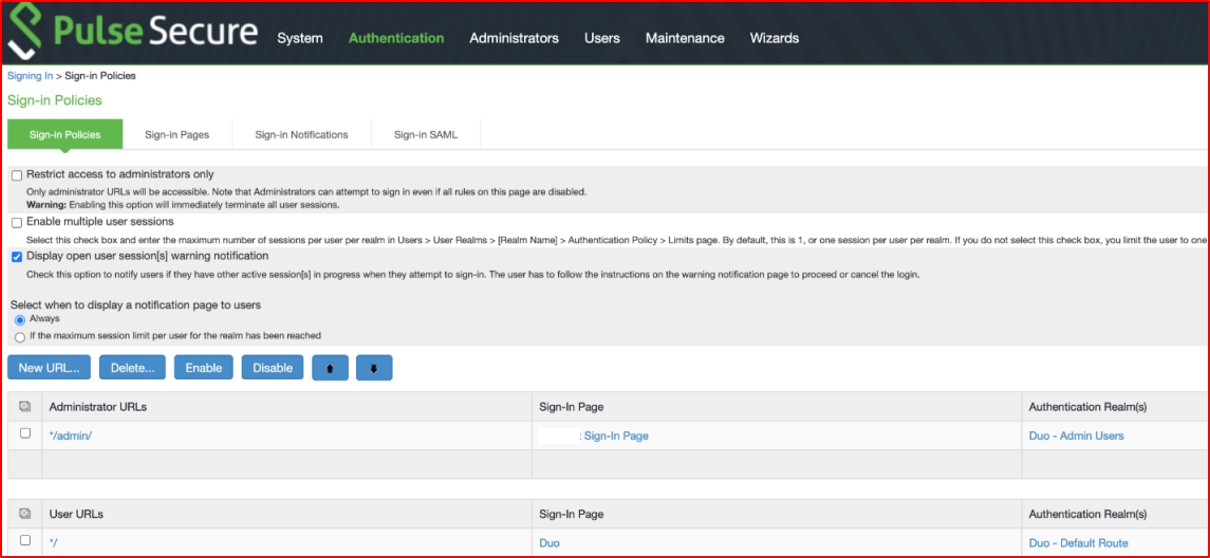
Dieser Screenshot zeigt, dass ein zusätzlicher Authentifizierungsserver aktiviert ist, der auf "Duo-LDAP" für den Authentifizierungsbereich "Duo - Standardroute" verweist.
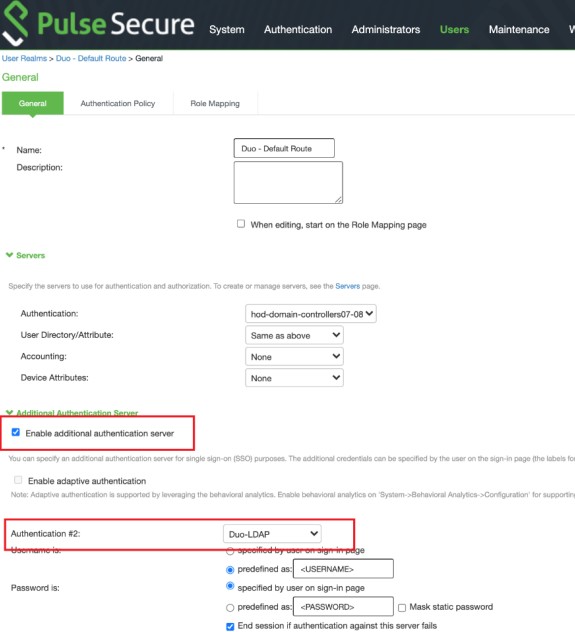
Dieser letzte Screenshot zeigt die Konfiguration für den Duo-LDAP-Authentifizierungsserver, der zeigt, dass dieser auf den Duo SaaS-Dienst für MFA verweist.
Hinweis: In den vorherigen Beispielen wurde kein vollständiger Screenshot verwendet, jedoch müssen ALLE von ISV übermittelten Beweisscreenshots vollständige Screenshots mit url, allen angemeldeten Benutzern und Systemzeit und -datum sein.
Protokollieren, Überprüfen und Warnen von Sicherheitsereignissen
Die Protokollierung von Sicherheitsereignissen ist ein integraler Bestandteil des Sicherheitsprogramms eines organization. Eine angemessene Protokollierung von Sicherheitsereignissen in Verbindung mit optimierten Warnungs- und Überprüfungsprozessen hilft Organisationen dabei, Sicherheitsverletzungen oder versuchte Sicherheitsverletzungen zu identifizieren, die vom organization verwendet werden können, um Die Sicherheit und defensive Sicherheitsstrategien zu verbessern. Darüber hinaus ist eine angemessene Protokollierung von entscheidender Bedeutung für die Reaktion auf Vorfälle in Organisationen, die in andere Aktivitäten einfließen können, z. B. in der Lage zu sein, genau zu identifizieren, welche daten kompromittiert wurden, den Zeitraum der Kompromittierung, die Bereitstellung detaillierter Analyseberichte für Regierungsbehörden usw.
Das Überprüfen von Sicherheitsprotokollen ist eine wichtige Funktion, um Organisationen bei der Identifizierung von Sicherheitsereignissen zu unterstützen, die auf eine Sicherheitsverletzung oder Reconnaissance-Aktivitäten hindeuten können, die ein Hinweis auf eine bevorstehende Aktion sein können. Dies kann entweder über einen täglichen manuellen Prozess oder mithilfe einer SIEM-Lösung (Security Information and Event Management) erfolgen, die bei der Analyse von Überwachungsprotokollen hilft und nach Korrelationen und Anomalien sucht, die für eine manuelle Überprüfung gekennzeichnet werden können.
Kritische Sicherheitsereignisse müssen sofort untersucht werden, um die Auswirkungen auf die Daten- und Betriebsumgebung zu minimieren. Warnungen helfen, potenzielle Sicherheitsverletzungen sofort für mitarbeiter zu markieren, um eine rechtzeitige Reaktion sicherzustellen, damit die organization das Sicherheitsereignis so schnell wie möglich eindämmen kann. Indem sichergestellt wird, dass Warnungen effektiv funktionieren, können Organisationen die Auswirkungen einer Sicherheitsverletzung minimieren und so die Wahrscheinlichkeit einer schwerwiegenden Sicherheitsverletzung verringern, die die Marke des Unternehmens beschädigen und finanzielle Verluste durch Geldbußen und Reputationsschäden verursachen könnte.
Kontrolle Nr. 17
Stellen Sie Beweise für Folgendes bereit:
Die Sicherheitsereignisprotokollierung wird in der bereichsinternen Umgebung eingerichtet, einschließlich der Systemkomponenten mit Stichproben, um Ereignisse zu protokollieren, sofern zutreffend, z. B.:
Logischer Benutzerzugriff auf Systemkomponenten (gültiger & ungültiger Zugriff)
alle Aktionen, die von einem Benutzer mit hohen Berechtigungen ausgeführt werden
Erstellung/Änderung privilegierter Konten
Manipulation des Ereignisprotokolls
Deaktivieren von Sicherheitstools (Beispiel: Ereignisprotokollierung)
Antischadsoftwareprotokollierung (Beispiel: Updates, Schadsoftwareerkennung, Scanfehler)
Absicht: Ereignisprotokollierung
Um versuchte und tatsächliche Sicherheitsverletzungen zu identifizieren, ist es wichtig, dass von allen Systemen, aus denen die Umgebung besteht, angemessene Sicherheitsereignisprotokolle gesammelt werden. Mit diesem Steuerelement soll sichergestellt werden, dass die richtigen Arten von Sicherheitsereignissen erfasst werden, die dann in Überprüfungs- und Warnungsprozesse einfließen können, um diese Ereignisse zu identifizieren und darauf zu reagieren.
Dieser Unterpunkt erfordert, dass ein ISV die Protokollierung von Sicherheitsereignissen eingerichtet hat, um alle Instanzen des Benutzerzugriffs auf Systemkomponenten und Anwendungen zu erfassen. Dies ist wichtig für die Überwachung, wer innerhalb des organization auf die Systemkomponenten und Anwendungen zugreift, und ist sowohl für Sicherheits- als auch für Überwachungszwecke unerlässlich.
Dieser Unterpunkt erfordert, dass alle Aktionen von Benutzern mit allgemeinen Berechtigungen protokolliert werden. Benutzer mit hohen Berechtigungen können erhebliche Änderungen vornehmen, die sich auf den Sicherheitsstatus des organization auswirken können. Daher ist es wichtig, ihre Aktionen zu protokollieren.
Dieser Unterpunkt erfordert die Protokollierung aller ungültigen Versuche, logischen Zugriff auf Systemkomponenten oder Anwendungen zu erhalten. Eine solche Protokollierung ist eine primäre Möglichkeit, nicht autorisierte Zugriffsversuche und potenzielle Sicherheitsbedrohungen zu erkennen.
Dieser Unterpunkt erfordert die Protokollierung jeglicher Erstellung oder Änderung von Konten mit privilegiertem Zugriff. Diese Art der Protokollierung ist entscheidend für die Nachverfolgung von Änderungen an Konten, die über einen hohen Systemzugriff verfügen und das Ziel von Angreifern sein könnten.
Dieser Unterpunkt erfordert die Protokollierung aller Manipulationsversuche mit Ereignisprotokollen. Die Manipulation von Protokollen kann eine Möglichkeit sein, nicht autorisierte Aktivitäten zu verbergen, und daher ist es wichtig, dass solche Aktionen protokolliert und ausgeführt werden.
Dieser Unterpunkt erfordert die Protokollierung aller Aktionen, die Sicherheitstools deaktivieren, einschließlich der Ereignisprotokollierung selbst. Das Deaktivieren von Sicherheitstools kann eine rote Kennzeichnung sein, die auf einen Angriff oder eine interne Bedrohung hinweist.
Dieser Unterpunkt erfordert die Protokollierung von Aktivitäten im Zusammenhang mit Antischadsoftwaretools, einschließlich Updates, Schadsoftwareerkennung und Überprüfungsfehlern. Das ordnungsgemäße Funktionieren und Aktualisieren von Anti-Malware-Tools ist für die Sicherheit eines organization unerlässlich, und Protokolle im Zusammenhang mit diesen Aktivitäten helfen bei der Überwachung.
Richtlinien: Ereignisprotokollierung
Der Nachweis durch Screenshots oder Konfigurationseinstellungen sollte für alle erfassten Geräte und alle relevanten Systemkomponenten bereitgestellt werden, um zu veranschaulichen, wie die Protokollierung konfiguriert ist, um sicherzustellen, dass diese Arten von Sicherheitsereignissen erfasst werden.
Beispielbeweis
Die nächsten Screenshots zeigen die Konfigurationen von Protokollen und Metriken, die von verschiedenen Ressourcen in Azure generiert werden und dann im zentralen Log Analytics-Arbeitsbereich erfasst werden.
Wir sehen im ersten Screenshot, dass der Protokollspeicherort "PaaS-web-app-log-analytics" ist.
In Azure können Diagnoseeinstellungen für Azure Ressourcen für den Zugriff auf Überwachungs-, Sicherheits- und Diagnoseprotokolle aktiviert werden, wie unten gezeigt. Aktivitätsprotokolle, die automatisch verfügbar sind, enthalten Ereignisquelle, Datum, Benutzer, Zeitstempel, Quelladressen, Zieladressen und andere nützliche Elemente.
Hinweis: Die folgenden Beispiele zeigen eine Art von Beweis, die bereitgestellt werden kann, um dieses Steuerelement zu erfüllen. Dies hängt davon ab, wie Ihr organization die Sicherheitsereignisprotokollierung in der bereichsinternen Umgebung eingerichtet hat. Weitere Beispiele können Azure Sentinel, Datadog usw. sein.
Mithilfe der Option "Diagnoseeinstellungen" für die Web-App, die auf Azure-App Services gehostet wird, können Sie konfigurieren, welche Protokolle generiert und wohin diese zur Speicherung und Analyse gesendet werden.
Im folgenden Screenshot sind "Zugriffsüberwachungsprotokolle" und "IPSecurity-Überwachungsprotokolle" so konfiguriert, dass sie generiert und im Log Analytics-Arbeitsbereich erfasst werden.
Ein weiteres Beispiel ist Azure Front Door, das so konfiguriert ist, dass Protokolle an denselben zentralen Log Analytics-Arbeitsbereich gesendet werden.
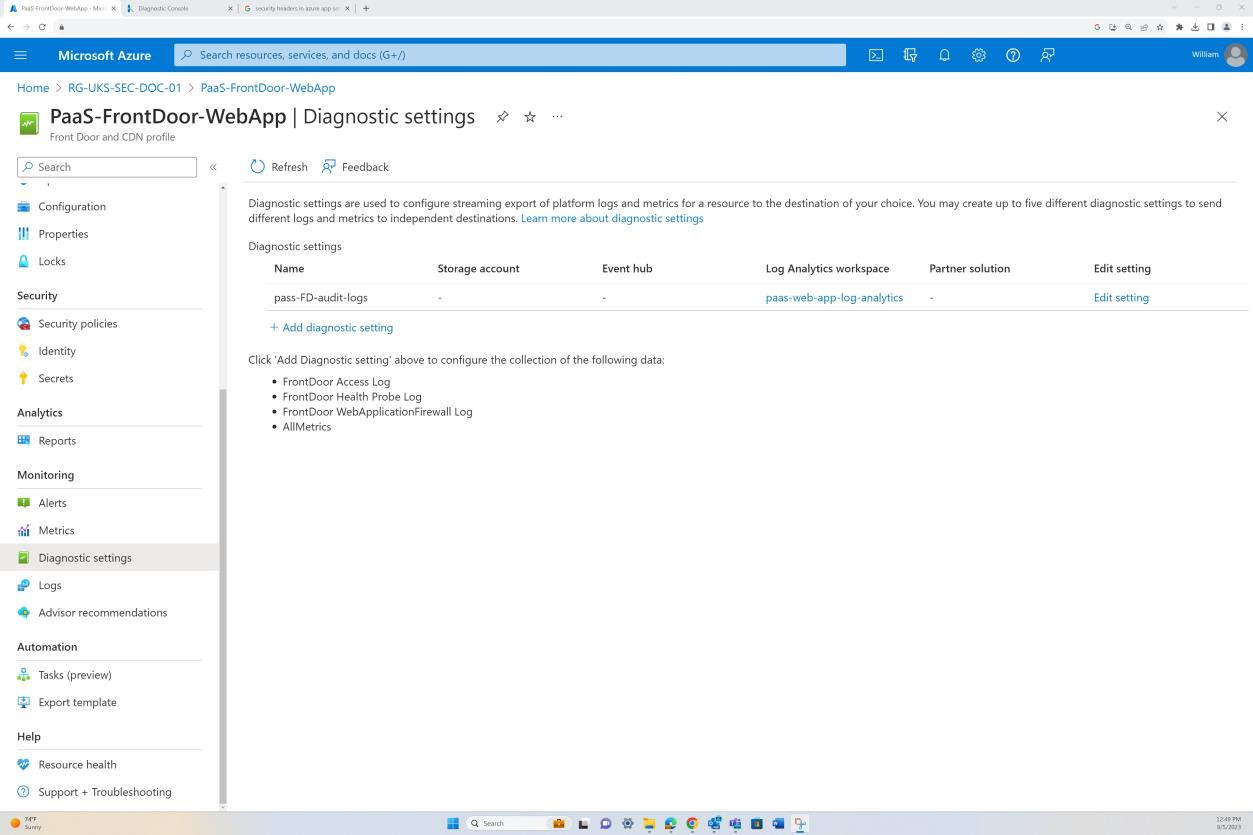
Konfigurieren Sie wie zuvor mit der Option "Diagnoseeinstellungen", welche Protokolle generiert werden und wohin diese zur Speicherung und Analyse gesendet werden. Der nächste Screenshot zeigt, dass "Zugriffsprotokolle" und "WAF-Protokolle" konfiguriert wurden.
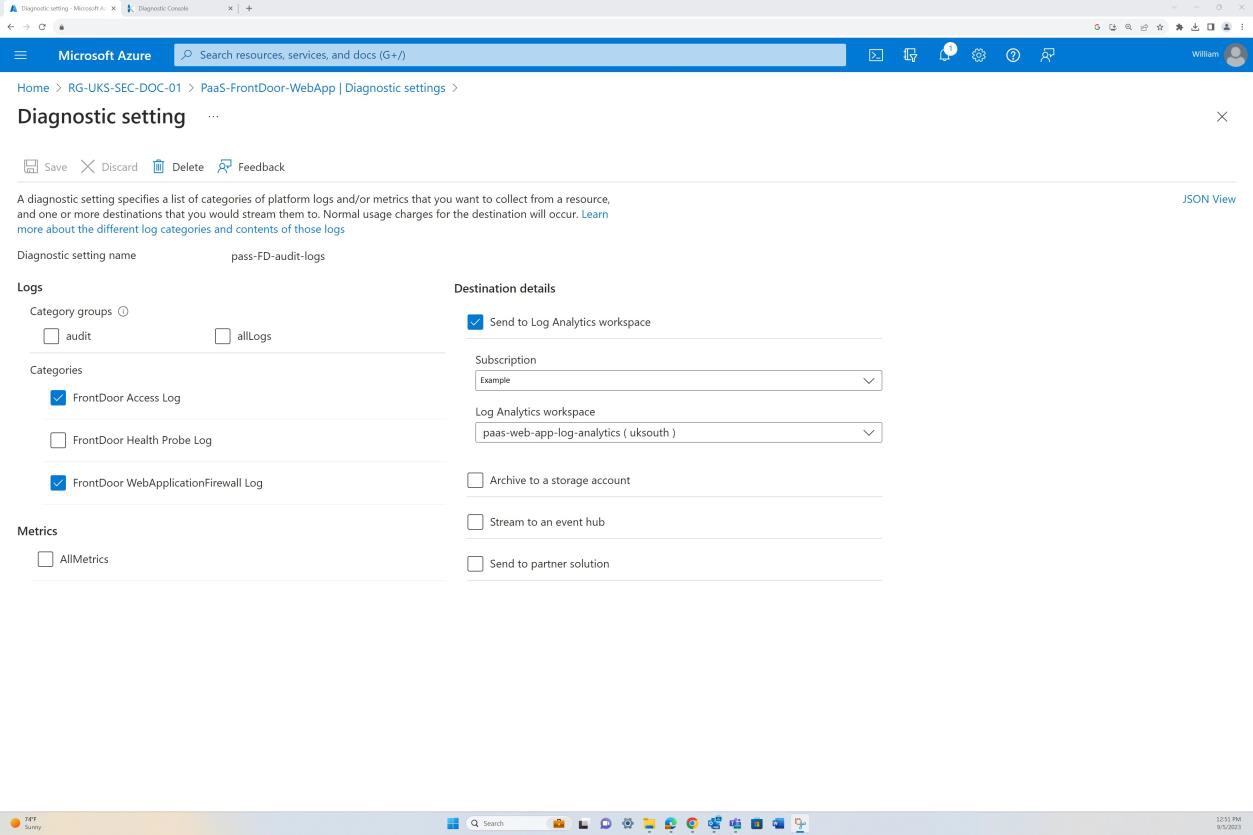
Auf ähnliche Weise können die "Diagnoseeinstellungen" für den Azure SQL Server konfigurieren, welche Protokolle generiert werden und wohin diese zur Speicherung und Analyse gesendet werden.
Der folgende Screenshot zeigt, dass Überwachungsprotokolle für den SQL Server generiert und an den Log Analytics-Arbeitsbereich gesendet werden.
Beispielbeweis
Der folgende Screenshot von AAD/Entra zeigt, dass Überwachungsprotokolle für privilegierte Rollen und Administratoren generiert werden. Die Informationen umfassen status, Aktivität, Dienst, Ziel und Initiator.
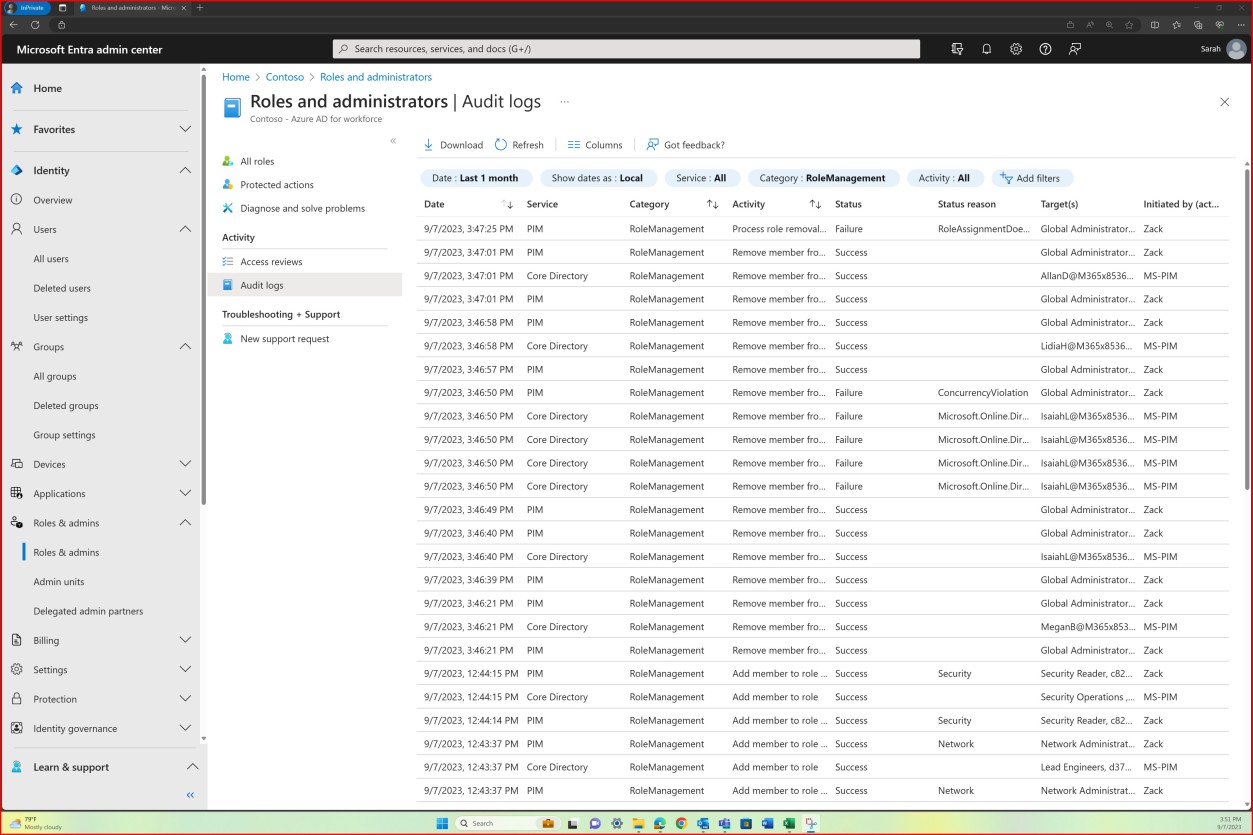
Der folgende Screenshot zeigt die Anmeldeprotokolle. Die Protokollinformationen umfassen IP-Adresse, Status, Standort und Datum.
Beispielbeweis
Das nächste Beispiel konzentriert sich auf Protokolle, die für Computeinstanzen wie Virtual Machines (VMs) generiert werden. Eine Datensammlungsregel wurde implementiert, und Windows-Ereignisprotokolle, einschließlich Sicherheitsüberwachungsprotokolle, werden erfasst.
Der folgende Screenshot zeigt ein weiteres Beispiel für Konfigurationseinstellungen von einem Stichprobengerät namens "Galaxy-Compliance". Die Einstellungen veranschaulichen die verschiedenen Überwachungseinstellungen, die in der lokalen Sicherheitsrichtlinie aktiviert sind.
Der nächste Screenshot zeigt ein Ereignis, bei dem ein Benutzer das Ereignisprotokoll vom Beispielgerät "Galaxy-Compliance" gelöscht hat.
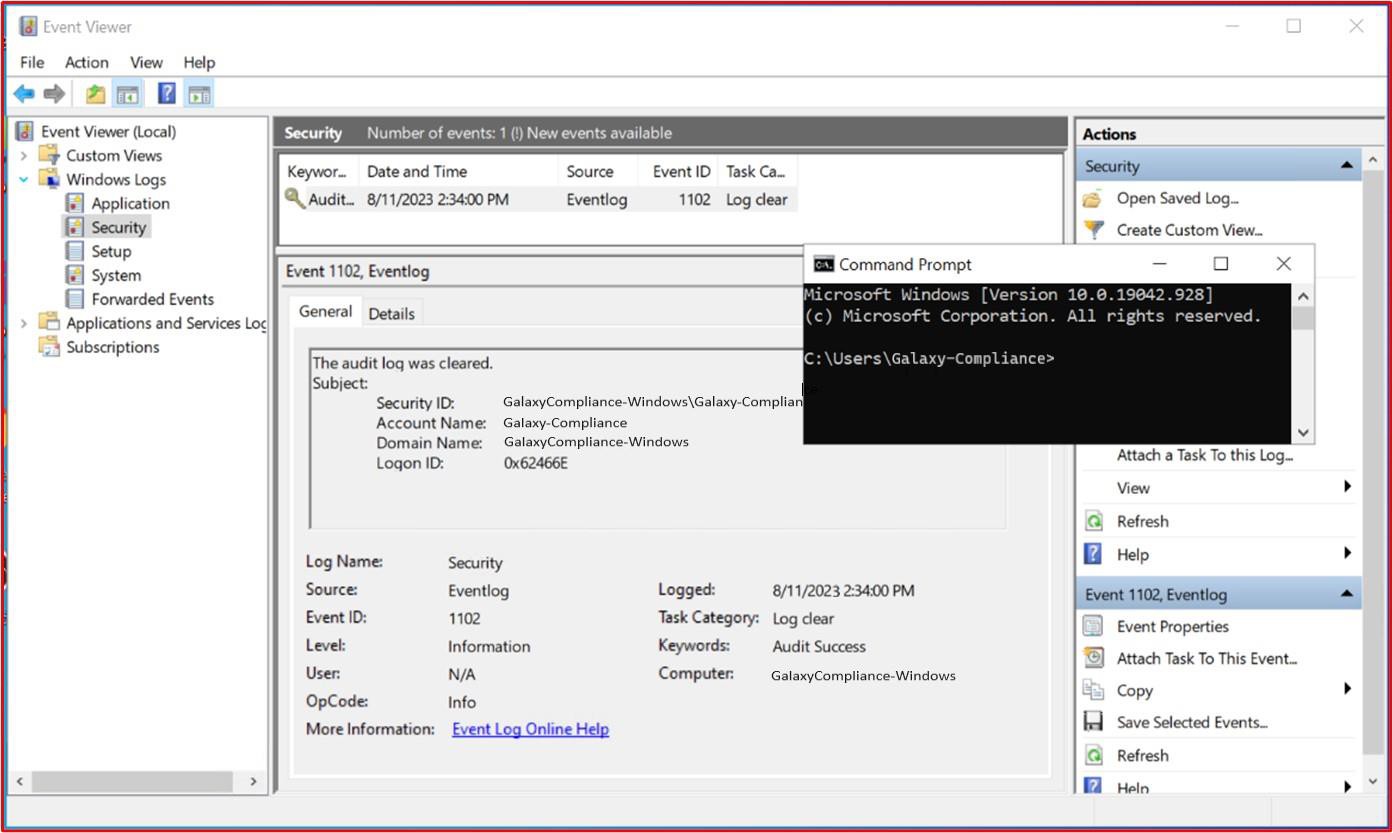
Bitte beachten Sie: Da es sich bei den vorherigen Beispielen nicht um Screenshots im Vollbildmodus handelt, müssen Sie Screenshots im Vollbildmodus mit einer beliebigen URL, angemeldetem Benutzer und dem Zeit- und Datumsstempel zur Beweisüberprüfung übermitteln. Wenn Sie ein Linux-Benutzer sind, kann dies über die Eingabeaufforderung erfolgen.
Kontrolle Nr. 18
Stellen Sie Beweise für Folgendes bereit:
Protokolldaten für Sicherheitsereignisse im Wert von mindestens 30 Tagen sind sofort verfügbar, wobei Sicherheitsereignisprotokolle für 90 Tage aufbewahrt werden.
Absicht: Ereignisprotokollierung
Manchmal gibt es eine Zeitlücke zwischen einer Kompromittierung oder einem Sicherheitsereignis und einem organization es zu identifizieren. Mit diesem Steuerelement soll sichergestellt werden, dass die organization Zugriff auf historische Ereignisdaten hat, um die Reaktion auf Vorfälle und alle forensischen Untersuchungen zu unterstützen, die möglicherweise erforderlich sind. Sicherstellen, dass die organization mindestens 30 Tage lang Daten zur Protokollierung von Sicherheitsereignissen beibehält, die sofort für die Analyse zur Verfügung stehen, um eine schnelle Untersuchung und Reaktion auf Sicherheitsvorfälle zu ermöglichen. Darüber hinaus werden sicherheitsrelevante Ereignisprotokolle von insgesamt 90 Tagen aufbewahrt, um eine eingehende Analyse zu ermöglichen.
Richtlinien: Ereignisprotokollierung
Der Beweis hierfür ist in der Regel die Anzeige der Konfigurationseinstellungen der zentralen Protokollierungslösung, die zeigt, wie lange Die Daten aufbewahrt werden. Daten zur Protokollierung von Sicherheitsereignissen im Wert von 30 Tagen müssen innerhalb der Lösung sofort verfügbar sein. Wenn Daten archiviert werden, muss jedoch nachgewiesen werden, dass der Wert von 90 Tagen verfügbar ist. Dies kann sein, indem Archivordner mit Datumsangaben der exportierten Daten angezeigt werden.
Beispielbeweis: Ereignisprotokollierung
Nach dem vorherigen Beispiel in Steuerelement 17, in dem ein zentralisierter Log Analytics-Arbeitsbereich verwendet wird, um alle protokolle zu speichern, die von den Cloudressourcen generiert werden, können Sie unten sehen, dass Protokolle in einzelnen Tabellen für jede Protokollkategorie gespeichert werden. Darüber hinaus beträgt die interaktive Aufbewahrungsdauer für alle Tabellen 90 Tage.
Der nächste Screenshot zeigt zusätzliche Beweise für die Konfigurationseinstellungen für den Aufbewahrungszeitraum des Log Analytics-Arbeitsbereichs.
Beispielbeweis
Die folgenden Screenshots zeigen, dass Protokolle im Wert von 30 Tagen in AlienVault verfügbar sind.
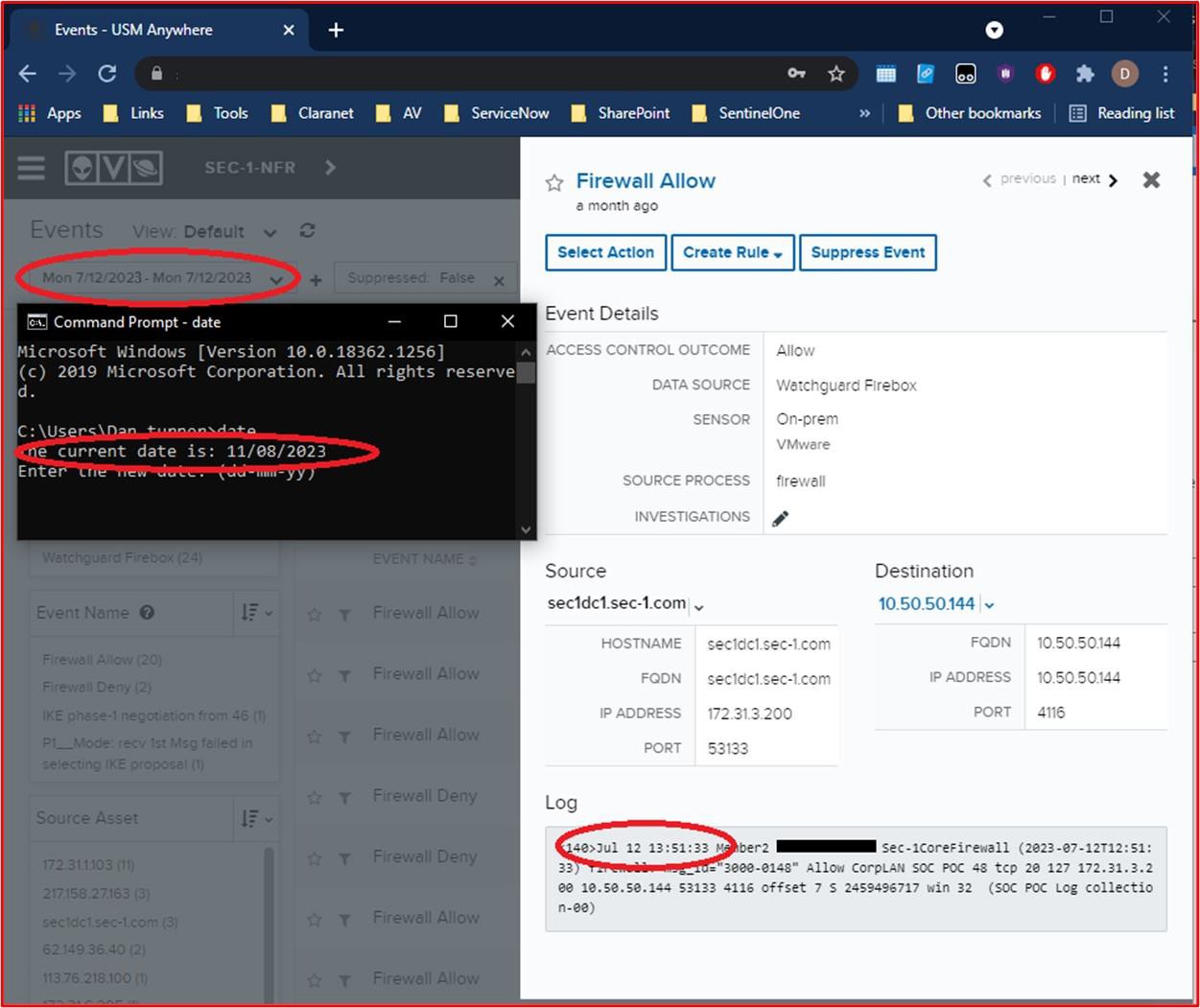
Hinweis: Da es sich um ein öffentlich zugängliches Dokument handelt, wurde die Seriennummer der Firewall bearbeitet. IsVs müssen diese Informationen jedoch ohne Bearbeitungen übermitteln, es sei denn, sie enthalten personenbezogene Informationen (Personally Identifiable Information, PII), die an ihren Analysten weitergegeben werden müssen.
Dieser nächste Screenshot zeigt, dass Protokolle verfügbar sind, indem ein Protokollextrakt angezeigt wird, der fünf Monate zurückgeht.
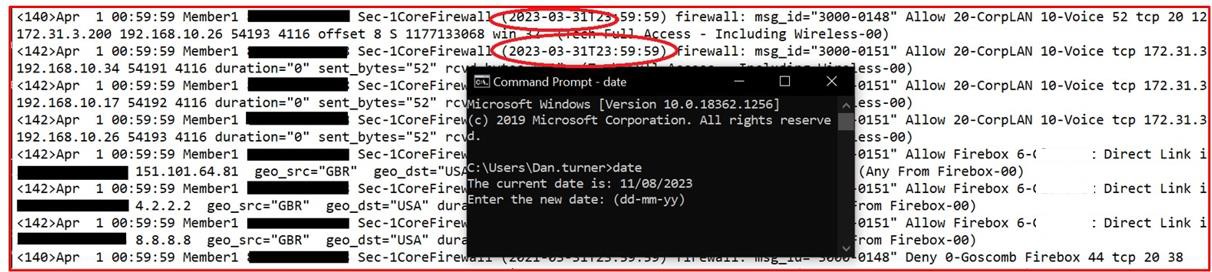
Hinweis: Da es sich um ein öffentlich zugängliches Dokument handelt, wurden die öffentlichen IP-Adressen redigiert. IsVs müssen diese Informationen jedoch ohne Bearbeitungen übermitteln, es sei denn, sie enthalten personenbezogene Informationen (Personally Identifiable Information, PII), die sie zuerst mit ihrem Analysten besprechen müssen.
Hinweis: Die vorherigen Beispiele sind keine Screenshots im Vollbildmodus. Sie müssen Screenshots im Vollbildmodus mit einer beliebigen URL, einem angemeldeten Benutzer und dem Zeit- und Datumsstempel für die Beweisüberprüfung übermitteln. Wenn Sie ein Linux-Benutzer sind, kann dies über die Eingabeaufforderung erfolgen.
Beispielbeweis
Der nächste Screenshot zeigt, dass Protokollereignisse 30 Tage live verfügbar und 90 Tage lang in cold storage innerhalb Azure aufbewahrt werden.
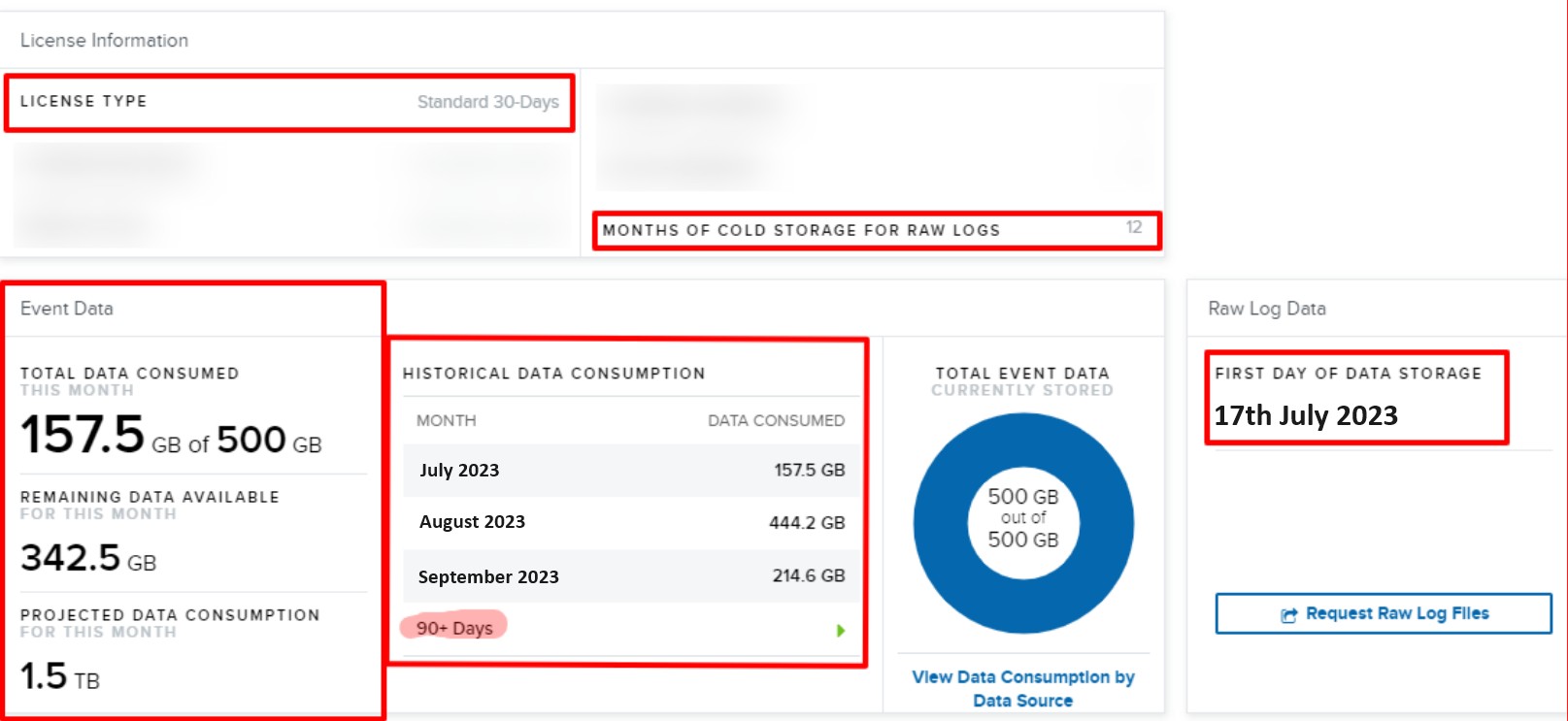
Hinweis: Es wird erwartet, dass neben allen Konfigurationseinstellungen, die die konfigurierte Aufbewahrung veranschaulich machen, ein Beispiel von Protokollen aus dem 90-Tage-Zeitraum bereitgestellt wird, um zu überprüfen, ob Protokolle 90 Tage lang aufbewahrt werden.
Bitte beachten Sie: Bei diesen Beispielen handelt es sich nicht um Screenshots im Vollbildmodus. Sie müssen Screenshots im Vollbildmodus mit einer beliebigen URL, angemeldetem Benutzer und dem Zeit- und Datumsstempel zur Beweisüberprüfung übermitteln. Wenn Sie ein Linux-Benutzer sind, kann dies über die Eingabeaufforderung erfolgen.
Kontrolle Nr. 19
Stellen Sie Folgendes bereit:
Protokolle werden in regelmäßigen Abständen überprüft, und alle potenziellen Sicherheitsereignisse/Anomalien, die während des Überprüfungsprozesses identifiziert wurden, werden untersucht und behoben.
Absicht: Ereignisprotokollierung
Mit dieser Kontrolle soll sichergestellt werden, dass regelmäßige Protokollüberprüfungen durchgeführt werden. Dies ist wichtig, um Anomalien zu identifizieren, die möglicherweise nicht von den Warnungsskripts/Abfragen erfasst werden, die für die Bereitstellung von Sicherheitsereigniswarnungen konfiguriert sind. Außerdem werden alle Anomalien untersucht, die während der Protokollüberprüfungen identifiziert werden, und es werden geeignete Korrekturen oder Maßnahmen durchgeführt. Dies umfasst in der Regel einen Selektierungsprozess, um zu ermitteln, ob die Anomalien eine Aktion erfordern, und dann kann es erforderlich sein, den Prozess zur Reaktion auf Vorfälle aufzurufen.
Richtlinien: Ereignisprotokollierung
Der Beweis wird durch Screenshots bereitgestellt, die zeigen, dass Protokollüberprüfungen durchgeführt werden. Dies kann über Formulare erfolgen, die jeden Tag ausgefüllt werden, oder über ein JIRA- oder DevOps-Ticket mit
relevante Kommentare, die gepostet werden, um dies zu zeigen, werden durchgeführt. Wenn Anomalien gekennzeichnet werden, kann dies in diesem Ticket dokumentiert werden, um zu zeigen, dass anomalien, die als Teil der Protokollüberprüfung identifiziert wurden, weiterverfolgt und dann detailliert beschrieben wird, welche Aktivitäten danach ausgeführt wurden. Dies kann dazu führen, dass ein bestimmtes JIRA-Ticket erstellt wird, um alle ausgeführten Aktivitäten nachzuverfolgen, oder es kann einfach im Protokollüberprüfungsticket dokumentiert werden. Wenn eine Reaktion auf Vorfälle erforderlich ist, sollte dies im Rahmen des Reaktionsprozesses für Vorfälle dokumentiert werden, und es sollten Beweise bereitgestellt werden, um dies zu veranschaulichen.
Beispielbeweis: Ereignisprotokollierung
Dieser erste Screenshot zeigt, wo ein Benutzer der Gruppe "Domänenadministratoren" hinzugefügt wurde.

Dieser nächste Screenshot zeigt, wo auf mehrere fehlgeschlagene Anmeldeversuche dann eine erfolgreiche Anmeldung folgt, die einen erfolgreichen Brute-Force-Angriff hervorheben kann.

Dieser letzte Screenshot zeigt, wo eine Kennwortrichtlinie geändert wurde, die die Richtlinie festlegt, sodass Kontokennwörter nicht ablaufen.

Dieser nächste Screenshot zeigt, dass ein Ticket automatisch im ServiceNow Tool des SOC ausgelöst wird, wodurch die vorherige Regel oben ausgelöst wird.
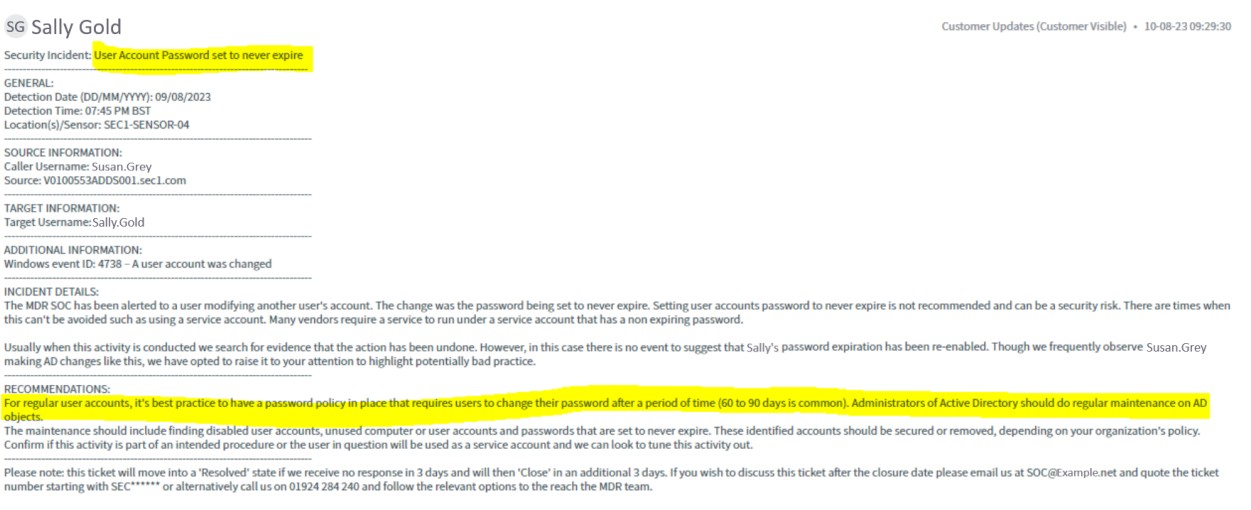
Bitte beachten Sie: Bei diesen Beispielen handelt es sich nicht um Screenshots im Vollbildmodus. Sie müssen Screenshots im Vollbildmodus mit einer beliebigen URL, angemeldetem Benutzer und dem Zeit- und Datumsstempel zur Beweisüberprüfung übermitteln. Wenn Sie ein Linux-Benutzer sind, kann dies über die Eingabeaufforderung erfolgen.
Steuerung Nr. 20
HARTER FEHLER
Stellen Sie Beweise für Folgendes bereit:
Warnungsregeln sind so konfiguriert, dass Warnungen zur sofortigen Untersuchung für die folgenden Sicherheitsereignisse ausgelöst werden, sofern zutreffend:
Erstellung/Änderung privilegierter Konten
Privilegierte/Risikoaktivitäten oder -vorgänge
Schadsoftwareereignisse (falls zutreffend)
Manipulation des Ereignisprotokolls
IDPS/WAF-Ereignisse (sofern konfiguriert)
Absicht: Warnungen
Dies sind einige Arten von Sicherheitsereignissen, die ein Sicherheitsereignis hervorheben können, das auf eine Sicherheitsverletzung bzw. Datenverletzung hinweisen kann.
Dieser Unterpunkt soll sicherstellen, dass Warnungsregeln speziell so konfiguriert sind, dass Untersuchungen bei der Erstellung oder Änderung privilegierter Konten ausgelöst werden. Bei der Erstellung oder Änderung privilegierter Konten sollten Protokolle generiert und Warnungen ausgelöst werden, wenn ein neues privilegiertes Konto erstellt oder vorhandene Berechtigungen für privilegierte Konten geändert werden. Dies hilft bei der Nachverfolgung von nicht autorisierten oder verdächtigen Aktivitäten.
Dieser Unterpunkt zielt darauf ab, Warnungsregeln festzulegen, um geeignete Mitarbeiter zu benachrichtigen, wenn privilegierte oder risikoreiche Aktivitäten oder Vorgänge durchgeführt werden. Für privilegierte oder risikoreiche Aktivitäten oder Vorgänge müssen Warnungen eingerichtet werden, um die entsprechenden Mitarbeiter zu benachrichtigen, wenn solche Aktivitäten initiiert werden. Dies kann Änderungen an Firewallregeln, Datenübertragungen oder den Zugriff auf vertrauliche Dateien umfassen.
Die Absicht dieses Unterpunkts besteht darin, die Konfiguration von Warnungsregeln zu schreiben, die durch Schadsoftwareereignisse ausgelöst werden. Schadsoftwareereignisse sollten nicht nur protokolliert werden, sondern auch eine sofortige Warnung zur Untersuchung auslösen. Diese Warnungen sollten so konzipiert sein, dass sie Details wie Ursprung, Art von Schadsoftware und betroffene Systemkomponenten enthalten, um die Antwortzeit zu beschleunigen.
Dieser Unterpunkt soll sicherstellen, dass jede Manipulation von Ereignisprotokollen eine sofortige Warnung zur Untersuchung auslöst. In Bezug auf die Manipulation von Ereignisprotokollen sollte das System so konfiguriert werden, dass Warnungen ausgelöst werden, wenn nicht autorisierter Zugriff auf Protokolle oder Änderungen an Protokollen erkannt werden. Dadurch wird die Integrität von Ereignisprotokollen sichergestellt, die für forensische Analysen und Complianceüberwachungen von entscheidender Bedeutung sind.
Dieser Unterpunkt soll sicherstellen, dass bei konfiguration von Intrusion Detection and Prevention Systems (IDPS) oder Web Application Firewalls (WAF) Warnungen zur Untersuchung ausgelöst werden. Wenn Intrusion Detection and Prevention Systems (IDPS) oder Web Application Firewalls (WAF) konfiguriert sind, sollten sie auch so festgelegt werden, dass warnungen für verdächtige Aktivitäten wie wiederholte Anmeldefehler, SQL-Einschleusungsversuche oder Muster, die auf einen Denial-of-Service-Angriff hindeuten, ausgelöst werden.
Richtlinien: Warnungen
Der Nachweis sollte anhand von Screenshots der Warnungskonfiguration UND des Nachweises der empfangenen Warnungen bereitgestellt werden. Die Konfigurationsscreenshots sollten die Logik zeigen, die die Warnungen auslöst, und wie die Warnungen gesendet werden. Warnungen können über SMS, Email, Teams-Kanäle, Slack-Kanäle usw. gesendet werden.
Beispielbeweis: Warnungen
Der nächste Screenshot zeigt ein Beispiel für Warnungen, die in Azure konfiguriert werden. Wir können auf dem ersten Screenshot sehen, dass eine Warnung ausgelöst wurde, wenn die VM beendet und die Zuordnung aufgehoben wurde. Beachten Sie, dass dies ein Beispiel für Warnungen darstellt, die in Azure konfiguriert werden, und es wird davon ausgegangen, dass Beweise dafür bereitgestellt werden, dass Warnungen für alle in der Steuerelementbeschreibung angegebenen Ereignisse generiert werden.
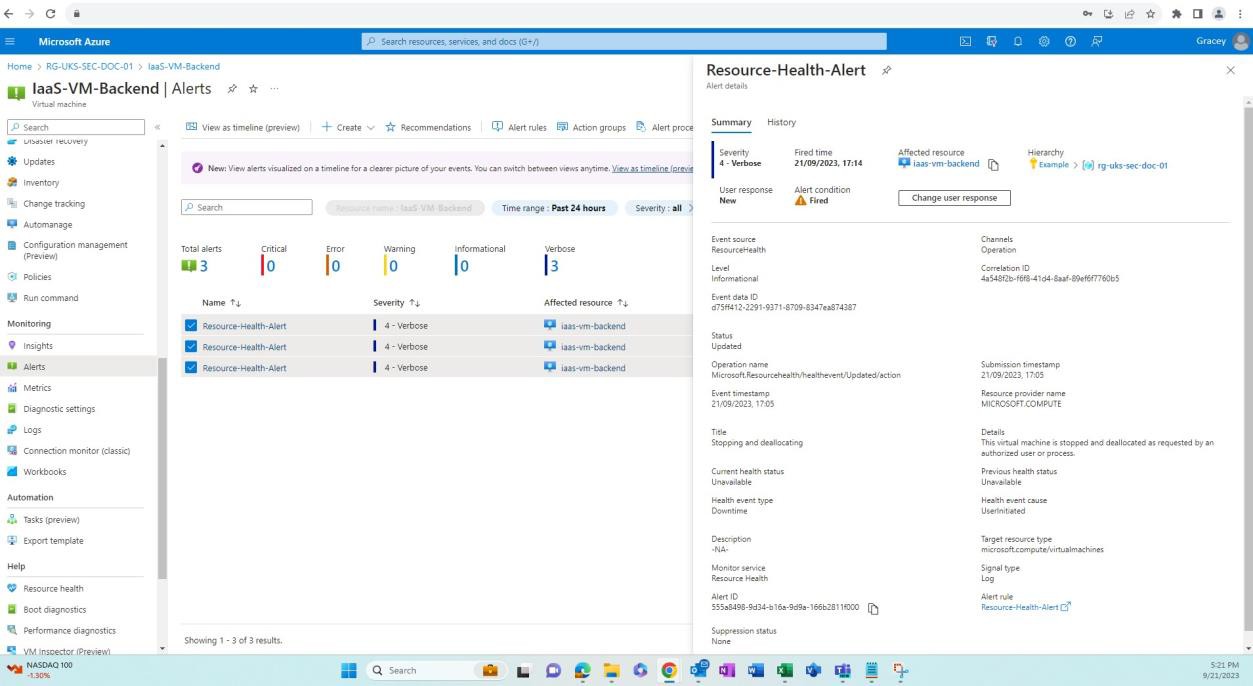
Der folgende Screenshot zeigt Warnungen, die für alle administrativen Aktionen konfiguriert sind, die auf Azure App Service- und Azure Ressourcengruppenebene ausgeführt werden.
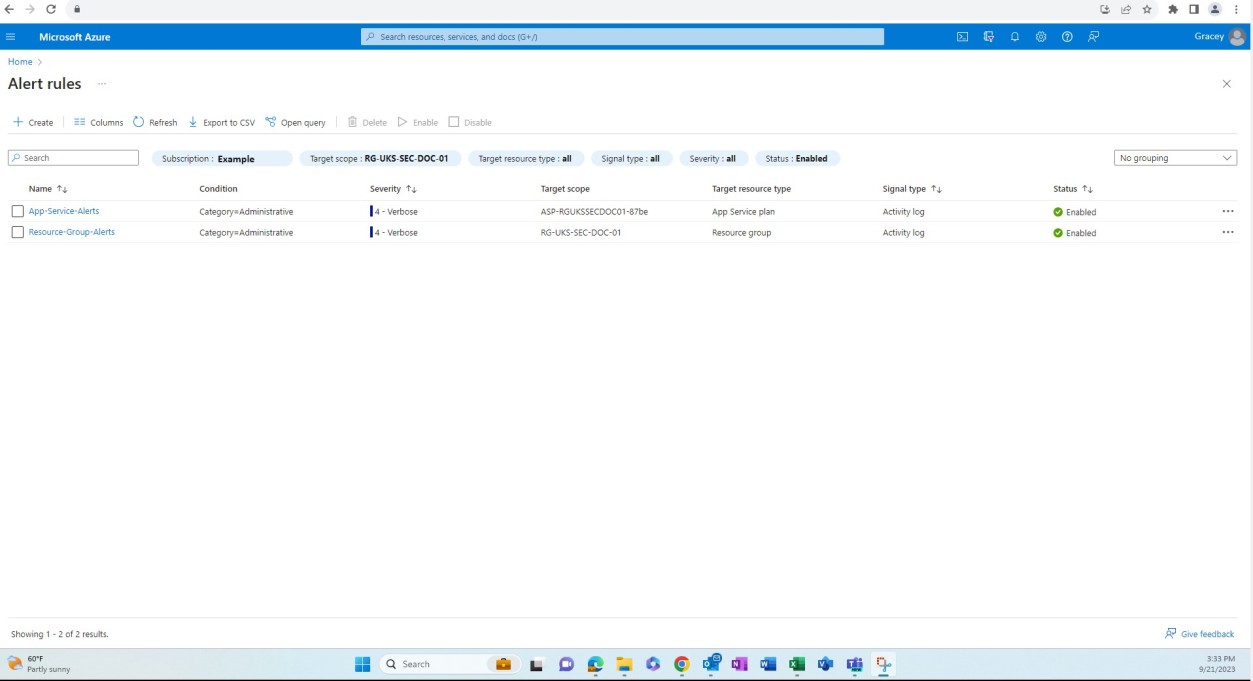
Beispielbeweis
Contoso nutzt ein Security Operations Center (SOC) eines Drittanbieters, das von Contoso Security bereitgestellt wird. Das Beispiel zeigt, dass Warnungen in AlienVault, die vom SOC verwendet werden, so konfiguriert sind, dass eine Warnung an ein Mitglied des SOC-Teams, Sally Gold bei Contoso Security, gesendet wird.
Der nächste Screenshot zeigt eine Warnung, die von Sally empfangen wird.
Bitte beachten Sie: Bei diesen Beispielen handelt es sich nicht um Screenshots im Vollbildmodus. Sie müssen Screenshots im Vollbildmodus mit einer beliebigen URL, angemeldetem Benutzer und dem Zeit- und Datumsstempel zur Beweisüberprüfung übermitteln. Wenn Sie ein Linux-Benutzer sind, kann dies über die Eingabeaufforderung erfolgen.
Risikomanagement der Informationssicherheit
Das Informationssicherheits-Risikomanagement ist eine wichtige Aktivität, die alle Organisationen mindestens jährlich durchführen sollten. Organisationen müssen ihre Risiken verstehen, um Bedrohungen effektiv zu mindern. Ohne ein effektives Risikomanagement können Organisationen Sicherheitsressourcen in Bereichen implementieren, die sie als wichtig empfinden, wenn andere Bedrohungen wahrscheinlicher sind. Ein effektives Risikomanagement hilft Organisationen, sich auf Risiken zu konzentrieren, die die größte Bedrohung für das Unternehmen darstellen. Dies sollte jährlich durchgeführt werden, da sich die Sicherheitslandschaft ständig ändert und sich daher Bedrohungen und Risiken im Laufe der Zeit ändern können. Beispielsweise gab es während des kürzlichen COVID-19-Lockdowns eine große Zunahme von Phishing-Angriffen mit der Umstellung auf Remotearbeit.
Regelung Nr. 21
Stellen Sie Beweise für Folgendes bereit:
Eine ratifizierte formale Richtlinie/ein prozess für das Risikomanagement der Informationssicherheit wird dokumentiert und eingerichtet.
Absicht: Risikomanagement
Ein robuster Prozess für das Risikomanagement der Informationssicherheit ist wichtig, um Organisationen dabei zu helfen, Risiken effektiv zu verwalten. Dies hilft Organisationen bei der Planung effektiver Maßnahmen gegen Bedrohungen für die Umgebung. Mit dieser Kontrolle soll bestätigt werden, dass die organization über eine formell ratifizierte Richtlinie oder einen Prozess für das Informationssicherheitsrisikomanagement verfügt, der umfassend dokumentiert ist. Die Richtlinie sollte beschreiben, wie die organization Informationssicherheitsrisiken identifiziert, bewertet und verwaltet. Sie sollte Rollen und Zuständigkeiten, Methoden für die Risikobewertung, Kriterien für die Risikoakzeptanz und Verfahren zur Risikominderung umfassen.
Hinweis: Die Risikobewertung muss sich auf Informationssicherheitsrisiken konzentrieren, nicht nur auf allgemeine Geschäftsrisiken.
Richtlinien: Risikomanagement
Der formal dokumentierte Prozess zur Risikomanagementverwaltung sollte bereitgestellt werden.
Beispielbeweis: Risikomanagement
Der folgende Beweis ist ein Screenshot eines Teils des Risikobewertungsprozesses von Contoso.
Hinweis: Es wird erwartet, dass ISVs die tatsächliche Unterstützende Richtlinien-/Verfahrensdokumentation freigeben und nicht einfach einen Screenshot bereitstellen.
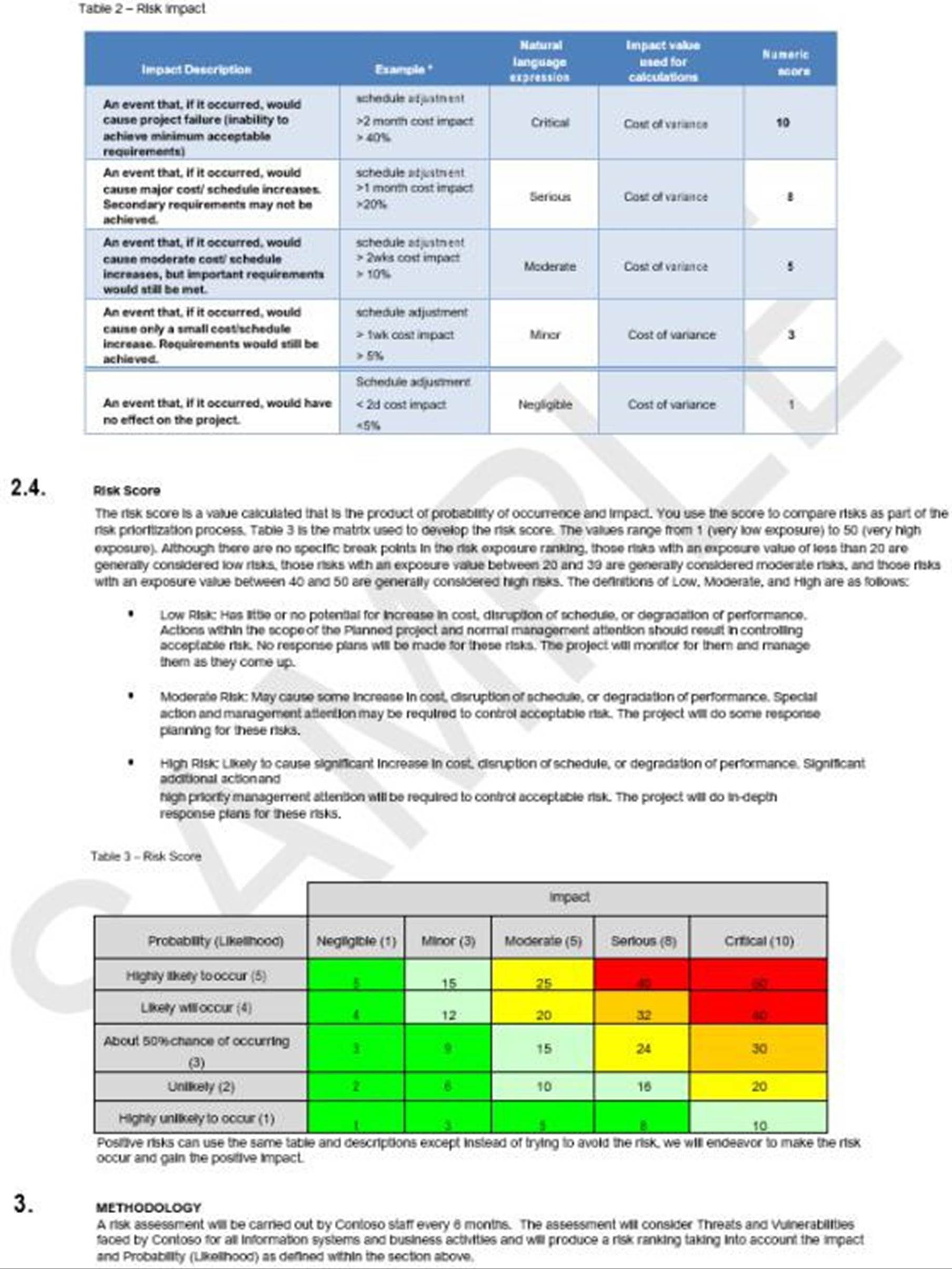
Hinweis: Es wird erwartet, dass ISVs die tatsächliche Unterstützende Richtlinien-/Verfahrensdokumentation freigeben und nicht einfach einen Screenshot bereitstellen.
Kontrolle Nr. 22
HARTER FEHLER
Stellen Sie Beweise für Folgendes bereit:
Eine formale unternehmensweite Informationssicherheitsrisikobewertung wird mindestens jährlich oder nach einer erheblichen Veränderung der Umwelt durchgeführt.
Die Risikobewertung umfasst die bereichsinterne Umgebung.
Hinweis: Änderungen können technologische Änderungen umfassen, die sich auf Umweltrisiken auswirken, rechtliche, betriebliche und Fusionen/Übernahmen.
Absicht: jährliche Bewertung
Sicherheitsbedrohungen ändern sich ständig, basierend auf Änderungen der Umgebung, Änderungen der angebotenen Dienste, externen Einflüssen, der Entwicklung der Sicherheitsbedrohungslandschaft usw. Organisationen müssen den Risikobewertungsprozess mindestens jährlich durchlaufen. Es wird empfohlen, dass dieser Prozess auch bei wesentlichen Änderungen durchgeführt wird, da sich Bedrohungen ändern können.
Mit dieser Kontrolle soll festgestellt werden, dass die organization mindestens einmal im Jahr eine formelle unternehmensweite Informationssicherheitsrisikobewertung und/oder eine gezielte Risikoanalyse bei Systemänderungen, Vorfällen, Sicherheitsrisikoermittlungen, Infrastrukturänderungen usw. durchführt. Diese Bewertung sollte alle Ressourcen, Prozesse und Daten der Organisation umfassen, um potenzielle Sicherheitsrisiken und Bedrohungen zu identifizieren und zu bewerten.
Bei der gezielten Risikoanalyse betont dieses Steuerelement die Notwendigkeit, eine Risikoanalyse für bestimmte Szenarien durchzuführen. Dies konzentriert sich auf einen engeren Bereich, z. B. eine Ressource, eine Bedrohung, ein System oder ein Steuerelement. Damit soll sichergestellt werden, dass Organisationen risiken, die durch Abweichungen von bewährten Sicherheitsmethoden oder Systementwurfseinschränkungen entstehen, kontinuierlich bewerten und identifizieren. Durch gezielte Risikoanalysen, die mindestens jährlich durchgeführt werden, wenn Kontrollen fehlen, wenn technologische Einschränkungen Sicherheitsrisiken schaffen, und als Reaktion auf mutmaßliche oder bestätigte Sicherheitsvorfälle können die organization Schwachstellen und Gefährdungen ermitteln. Dies ermöglicht fundierte risikobasierte Entscheidungen über die Priorisierung von Korrekturmaßnahmen und die Implementierung kompensierender Kontrollen, um die Wahrscheinlichkeit und Auswirkungen der Nutzung zu minimieren. Das Ziel besteht darin, fortlaufende Sorgfaltspflichten, Anleitungen und Beweise dafür bereitzustellen, dass bekannte Lücken risikobewusst behoben werden, anstatt auf unbestimmte Zeit ignoriert zu werden. Die Durchführung dieser gezielten Risikobewertungen zeigt das Engagement der Organisation, den Sicherheitsstatus im Laufe der Zeit proaktiv zu verbessern.
Richtlinien: jährliche Bewertung
Der Beweis kann durch Versionsnachverfolgung oder datierte Beweise erfolgen. Es sollten Nachweise vorgelegt werden, die das Ergebnis der Bewertung des Informationssicherheitsrisikos und KEINE Daten zum Prozess der Informationssicherheitsrisikobewertung selbst enthalten.
Beispielbeweis: jährliche Bewertung
Der nächste Screenshot zeigt eine Risikobewertungsbesprechung, die alle sechs Monate geplant wird.
Die nächsten beiden Screenshots zeigen ein Beispiel für Besprechungsminuten aus zwei Risikobewertungen. Es wird erwartet, dass ein Bericht/ein Besprechungsprotokoll oder ein Bericht über die Risikobewertung bereitgestellt wird.

Hinweis: Dieser Screenshot zeigt ein Richtlinien-/Prozessdokument. Es wird erwartet, dass ISVs die tatsächliche unterstützende Richtlinien-/Verfahrensdokumentation freigeben und nicht nur einen Screenshot bereitstellen.
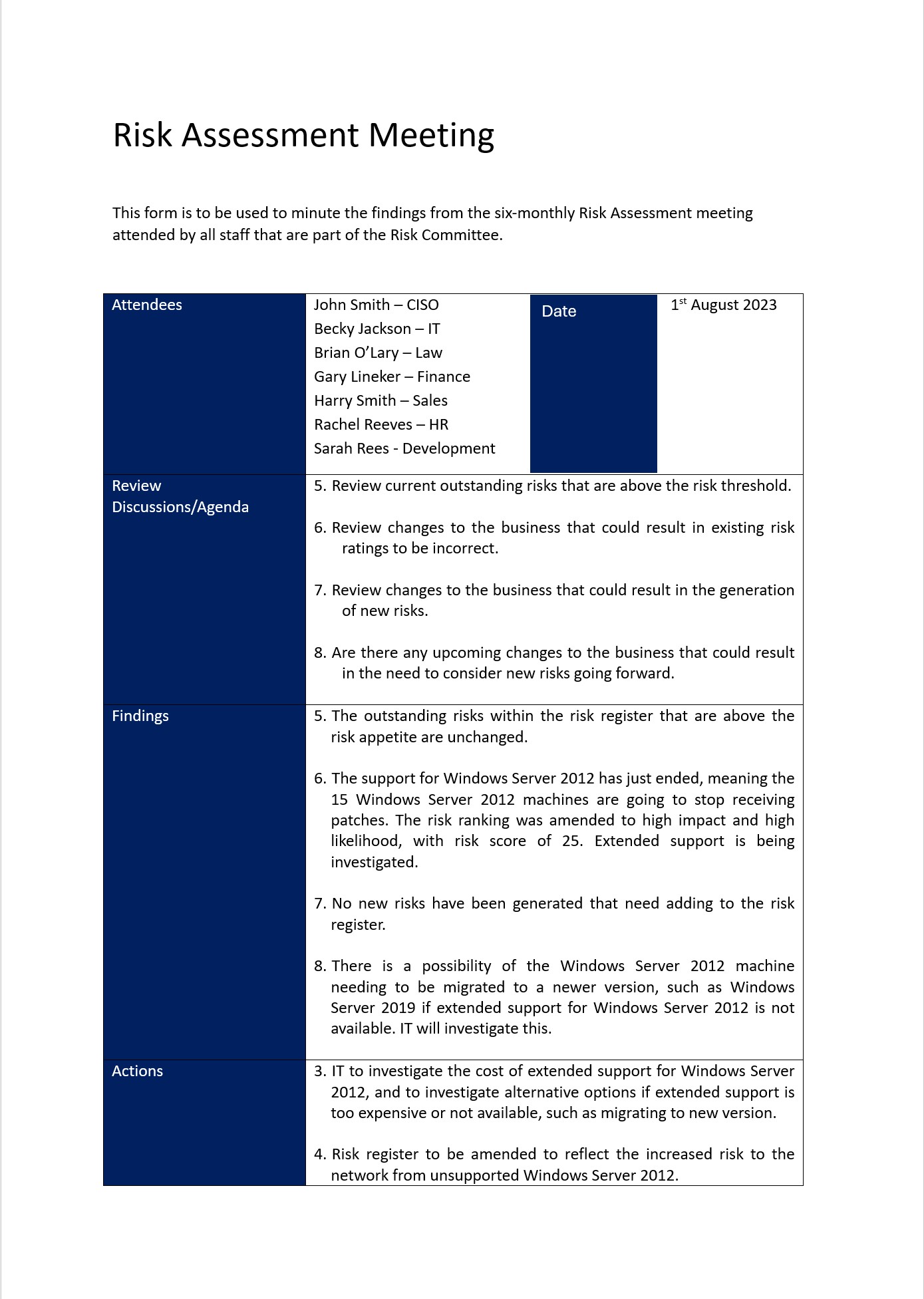
Hinweis: Dieser Screenshot zeigt ein Richtlinien-/Prozessdokument. Es wird erwartet, dass ISVs die tatsächliche unterstützende Richtlinien-/Verfahrensdokumentation freigeben und nicht einfach einen Screenshot bereitstellen.
Kontrolle Nr. 23
Stellen Sie Beweise für Folgendes bereit:
Die Bewertung des Informationssicherheitsrisikos umfasst Folgendes:
Betroffene Systemkomponente oder Ressource
Bedrohungen und Sicherheitsrisiken oder gleichwertige
Auswirkungs- und Wahrscheinlichkeitsmetriken oder gleichwertig
Erstellung eines Risikoregisters/Risikobehandlungsplans
Absicht: Risikobewertung
Die Absicht besteht darin, dass die Risikobewertung Systemkomponenten und Ressourcen umfasst, da sie dabei hilft, die kritischsten IT-Ressourcen und deren Wert zu identifizieren. Durch die Identifizierung und Analyse potenzieller Bedrohungen für das Unternehmen können sich die organization zuerst auf die Risiken konzentrieren, die die größten potenziellen Auswirkungen und die höchste Wahrscheinlichkeit haben. Das Verständnis der potenziellen Auswirkungen auf die IT-Infrastruktur und die damit verbundenen Kosten kann dem Management helfen, fundierte Entscheidungen zu Budget, Richtlinien, Verfahren und mehr zu treffen. Eine Liste der Systemkomponenten oder Ressourcen, die in die Sicherheitsrisikobewertung einbezogen werden können, sind:
Server
Datenbanken
Anwendungen
Netzwerke
Datenspeichergeräte
Personen
Um Informationssicherheitsrisiken effektiv zu verwalten, sollten Organisationen Risikobewertungen für Bedrohungen für die Umgebung und Daten sowie mögliche Sicherheitsrisiken durchführen, die vorhanden sein können. Dies hilft Organisationen, die Vielzahl von Bedrohungen und Sicherheitsrisiken zu identifizieren, die ein erhebliches Risiko darstellen können. Risikobewertungen sollten Auswirkungen und Wahrscheinlichkeitsbewertungen dokumentieren, die zur Identifizierung des Risikowerts verwendet werden können. Dies kann verwendet werden, um die Risikobehandlung zu priorisieren und den Gesamtrisikowert zu reduzieren. Risikobewertungen müssen ordnungsgemäß nachverfolgt werden, um eine der vier angewendeten Risikobehandlungen zu erfassen. Diese Risikobehandlungen sind:
Vermeiden/Beenden: Das Unternehmen kann bestimmen, dass die Kosten für die Behandlung des Risikos höher sind als die Einnahmen, die mit dem Dienst generiert werden. Das Unternehmen kann sich daher dafür entscheiden, die Ausführung des Diensts einzustellen.
Übertragung/Freigabe: Das Unternehmen kann das Risiko auf einen Dritten übertragen, indem es die Verarbeitung an einen Dritten überträgt.
Akzeptieren/Tolerieren/Beibehalten: Das Unternehmen kann entscheiden, dass das Risiko akzeptabel ist. Dies hängt stark vom Risikoappetit des Unternehmens ab und kann je nach organization variieren.
Behandeln/Entschärfen/Ändern: Das Unternehmen beschließt, Risikominderungskontrollen zu implementieren, um das Risiko auf ein akzeptables Niveau zu reduzieren.
Richtlinien: Risikobewertung
Der Nachweis sollte nicht nur durch den bereits bereitgestellten Prozess der Risikobewertung der Informationssicherheit, sondern auch durch das Ergebnis der Risikobewertung (mittels Eines Risikoregisters/Risikobehandlungsplans) erbracht werden, um nachzuweisen, dass der Risikobewertungsprozess ordnungsgemäß durchgeführt wird. Das Risikoregister sollte Risiken, Sicherheitsrisiken, Auswirkungen und Wahrscheinlichkeitsbewertungen enthalten.
Beispielbeweis: Risikobewertung
Der nächste Screenshot zeigt das Risikoregister, das zeigt, dass Bedrohungen und Sicherheitsrisiken enthalten sind. Außerdem wird veranschaulicht, dass Auswirkungen und Wahrscheinlichkeiten enthalten sind.
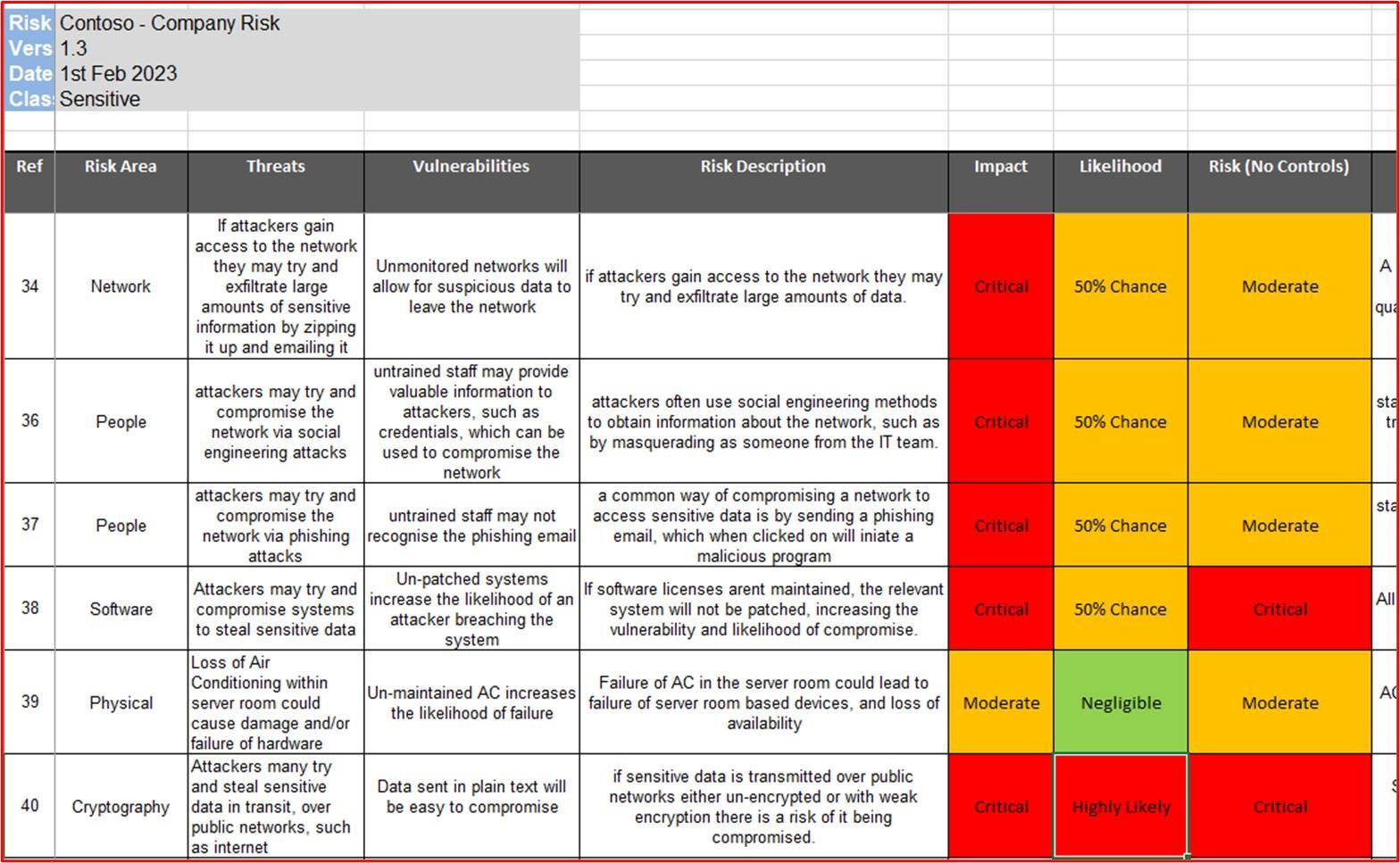
Hinweis: Die vollständige Dokumentation zur Risikobewertung sollte anstelle eines Screenshots bereitgestellt werden. Der nächste Screenshot zeigt einen Risikobehandlungsplan.
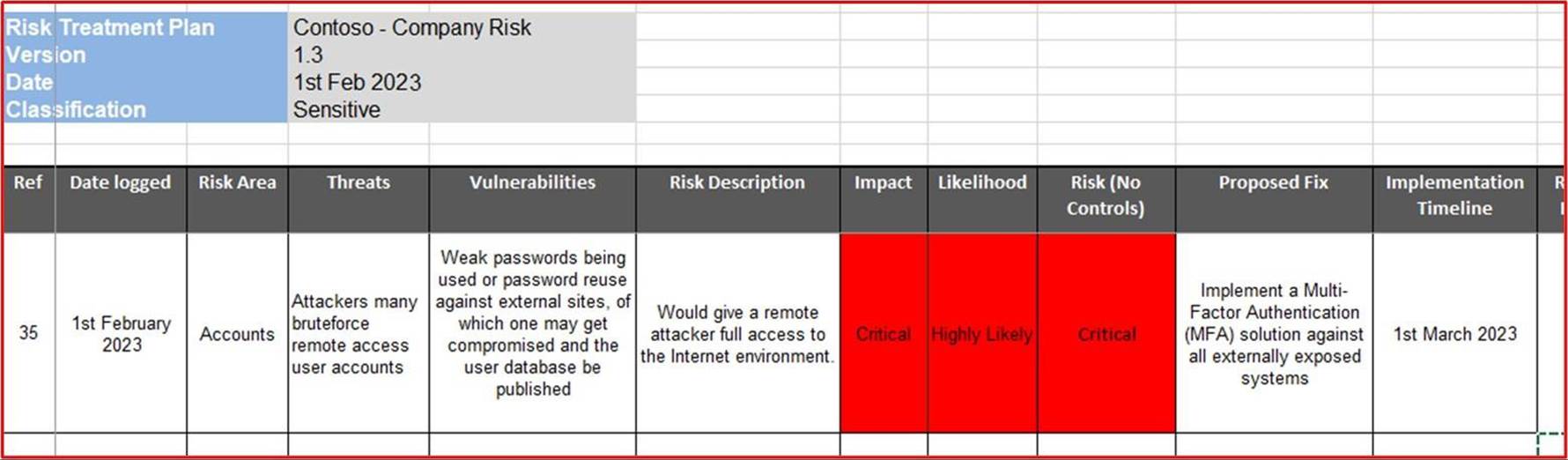
Regelung Nr. 24
Stellen Sie Beweise für Folgendes bereit:
Es ist ein Risikomanagementprozess vorhanden, der Risiken im Zusammenhang mit Lieferanten und Geschäftspartnern bewertet und verwaltet.
Das Risikomanagement für Lieferanten und Geschäftspartner wurde mindestens innerhalb der letzten zwölf (12) Monate durchgeführt.
Absicht: Anbieter und Partner
Lieferantenrisikomanagement ist die Praxis, die Risikostatus von Geschäftspartnern, Lieferanten oder Drittanbietern zu bewerten, bevor eine Geschäftsbeziehung eingerichtet wird und während der gesamten Dauer der Beziehung. Durch die Verwaltung von Lieferantenrisiken können Organisationen Unterbrechungen der Geschäftskontinuität vermeiden, finanzielle Auswirkungen verhindern, ihren Ruf schützen, Vorschriften einhalten und Risiken im Zusammenhang mit der Zusammenarbeit mit einem Anbieter identifizieren und minimieren. Um Anbieterrisiken effektiv zu verwalten, ist es wichtig, Prozesse zu eingerichtet zu haben, die Due Diligence-Bewertungen, vertragliche Verpflichtungen im Zusammenhang mit der Sicherheit und eine kontinuierliche Überwachung der Lieferantenkonformität umfassen.
Richtlinien: Anbieter und Partner
Nachweise können vorgelegt werden, um den Prozess der Kreditrisikobewertung zu veranschaulichen, z. B. die Beschaffung und Überprüfung der etablierten Dokumentation, Checklisten und Fragebögen für das Onboarding neuer Anbieter und Auftragnehmer, durchgeführte Bewertungen, Konformitätsprüfungen usw.
Beispielbeweis: Anbieter und Partner
Der nächste Screenshot zeigt, dass der Onboarding- und Überprüfungsprozess des Anbieters in Confluence als JIRA-Aufgabe beibehalten wird. Für jeden neuen Anbieter erfolgt eine erste Risikobewertung, um den Compliancestatus zu überprüfen. Während des Beschaffungsprozesses wird ein Fragebogen zur Risikobewertung ausgefüllt, und das Gesamtrisiko wird anhand des Zugangs zu Systemen und Daten bestimmt, die dem Anbieter zur Verfügung gestellt werden.
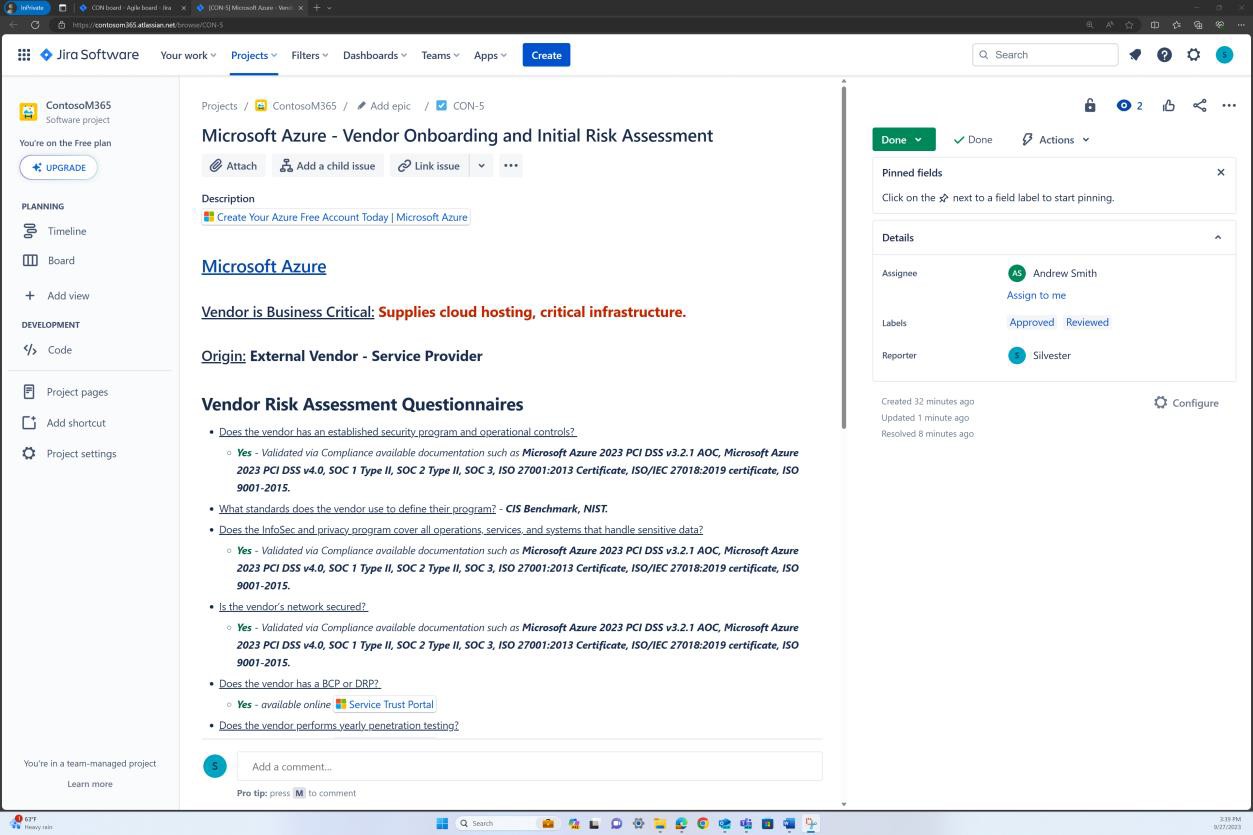
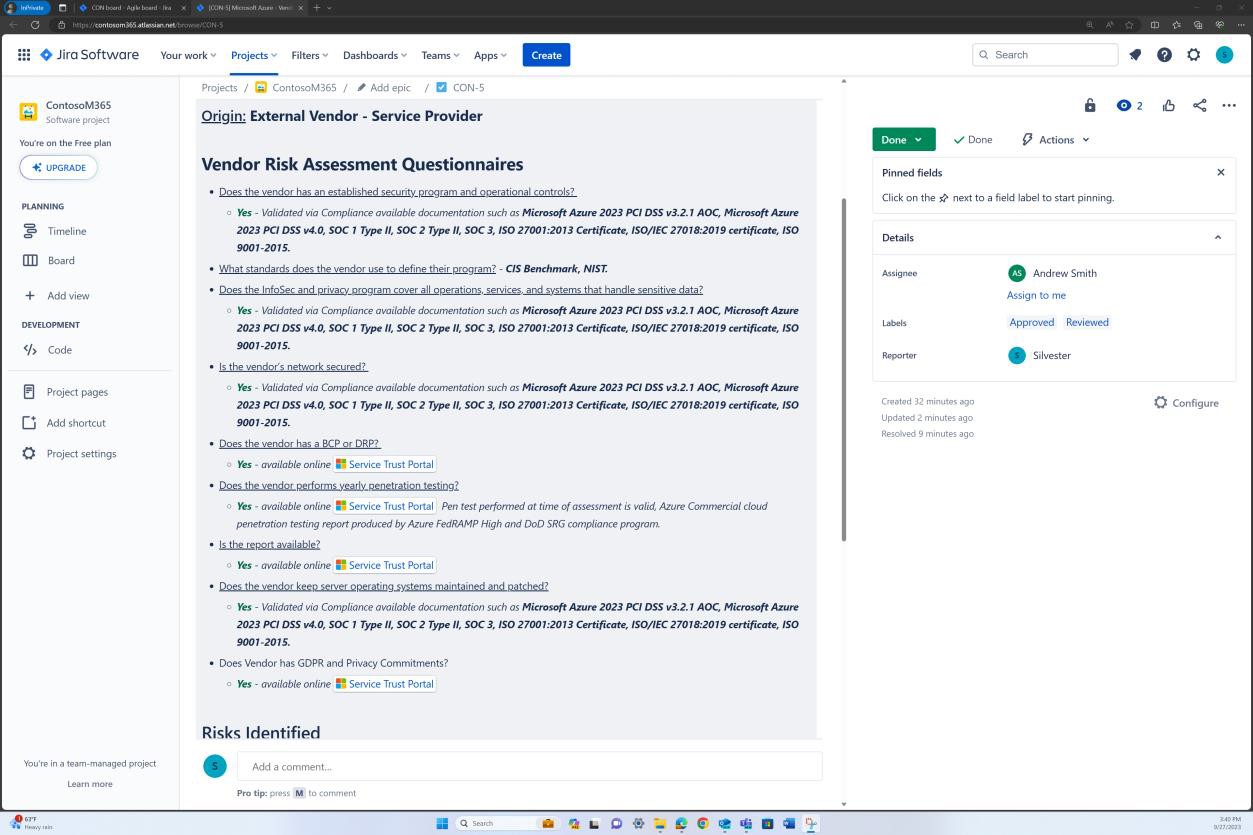
Der folgende Screenshot zeigt das Ergebnis der Bewertung und das Gesamtrisiko, das auf der Grundlage der ersten Überprüfung identifiziert wurde.
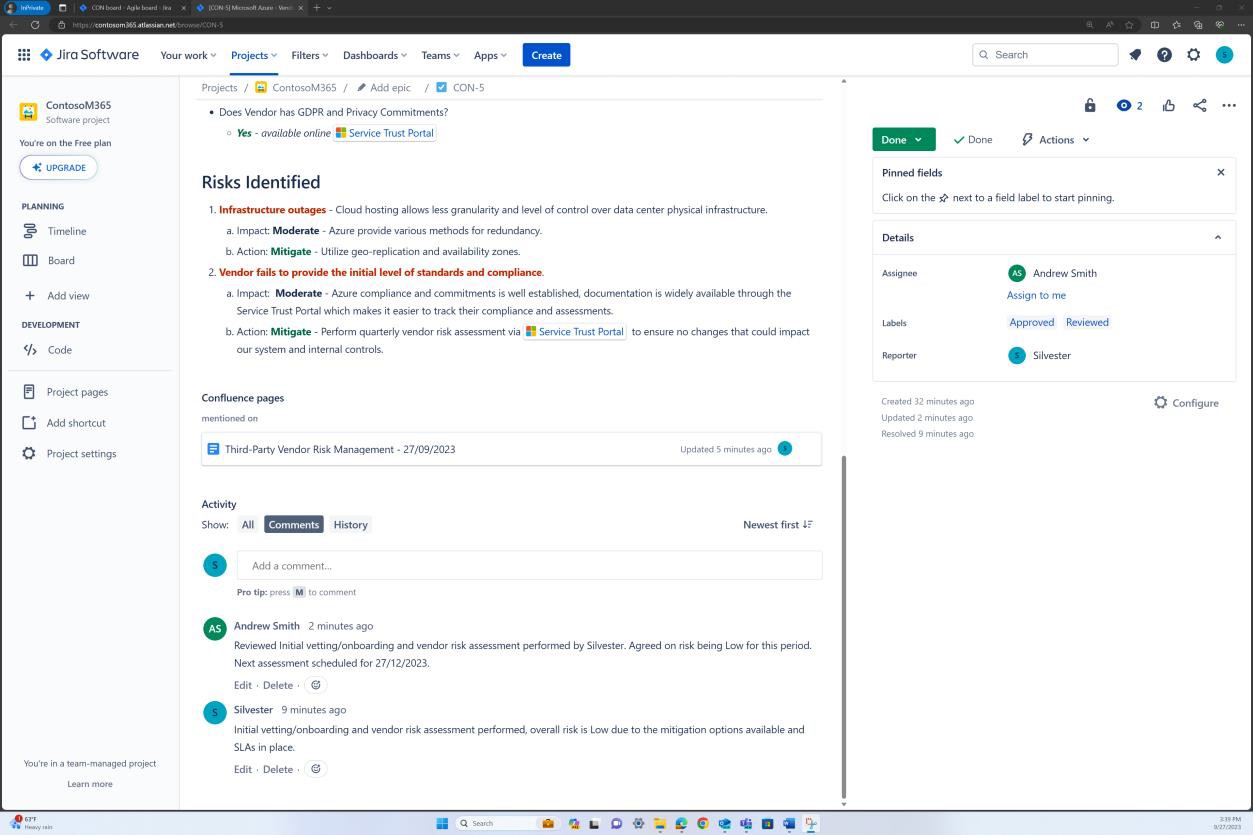
Absicht: interne Kontrollen
Der Schwerpunkt dieses Unterpunkts liegt auf der Erkennung und Bewertung von Änderungen und Risiken, die sich auf die internen Kontrollsysteme eines organization auswirken könnten, um sicherzustellen, dass die internen Kontrollen im Laufe der Zeit wirksam bleiben. Wenn sich der Geschäftsbetrieb ändert, sind Ihre internen Kontrollen möglicherweise nicht mehr wirksam. Risiken entwickeln sich im Laufe der Zeit, und es können neue Risiken entstehen, die zuvor nicht berücksichtigt wurden. Indem Sie diese Risiken identifizieren und bewerten, können Sie sicherstellen, dass Ihre internen Kontrollen darauf ausgelegt sind, diese zu beheben. Dies trägt dazu bei, Betrug und Fehler zu verhindern, die Geschäftskontinuität aufrechtzuerhalten und die Einhaltung gesetzlicher Bestimmungen sicherzustellen.
Richtlinien: interne Kontrollen
Es können Nachweise bereitgestellt werden, z. B. Besprechungsprotokolle und Berichte, die zeigen können, dass der Risikobewertungsprozess des Anbieters zu einem festgelegten Zeitraum aktualisiert wird, um sicherzustellen, dass potenzielle Änderungen des Anbieters berücksichtigt und bewertet werden.
Beispielbeweis: interne Kontrollen
Die folgenden Screenshots zeigen, dass eine dreimonatige Überprüfung der Liste des genehmigten Anbieters und Auftragnehmers durchgeführt wird, um sicherzustellen, dass seine Compliancestandards und der Grad der Konformität mit der anfänglichen Bewertung während des Onboardings übereinstimmen.
Der erste Screenshot zeigt die etablierten Richtlinien für die Durchführung der Bewertung und des Risikofragebogens.
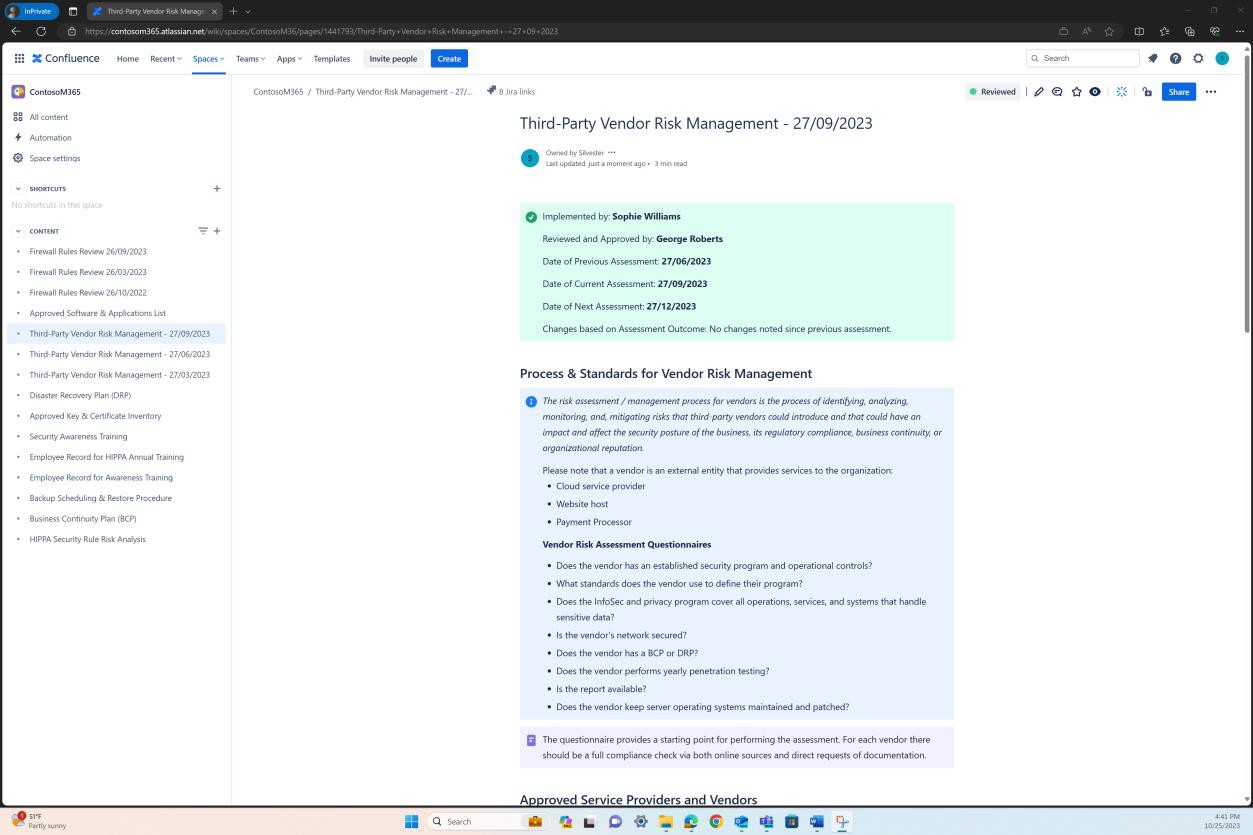
Die folgenden Screenshots zeigen die tatsächliche vom Anbieter genehmigte Liste und deren Compliancegrad, die durchgeführte Bewertung, den Bewerter, genehmigenden Personen usw. Bitte beachten Sie, dass dies nur ein Beispiel für eine rudimentäre Lieferantenrisikobewertung ist, die ein Basisszenario zum Verstehen der Kontrollanforderung und zum Anzeigen des Formats der erwarteten Beweise bietet. Als ISV sollten Sie Ihre eigene, auf Ihre organization anwendbare Anbieterrisikobewertung bereitstellen.
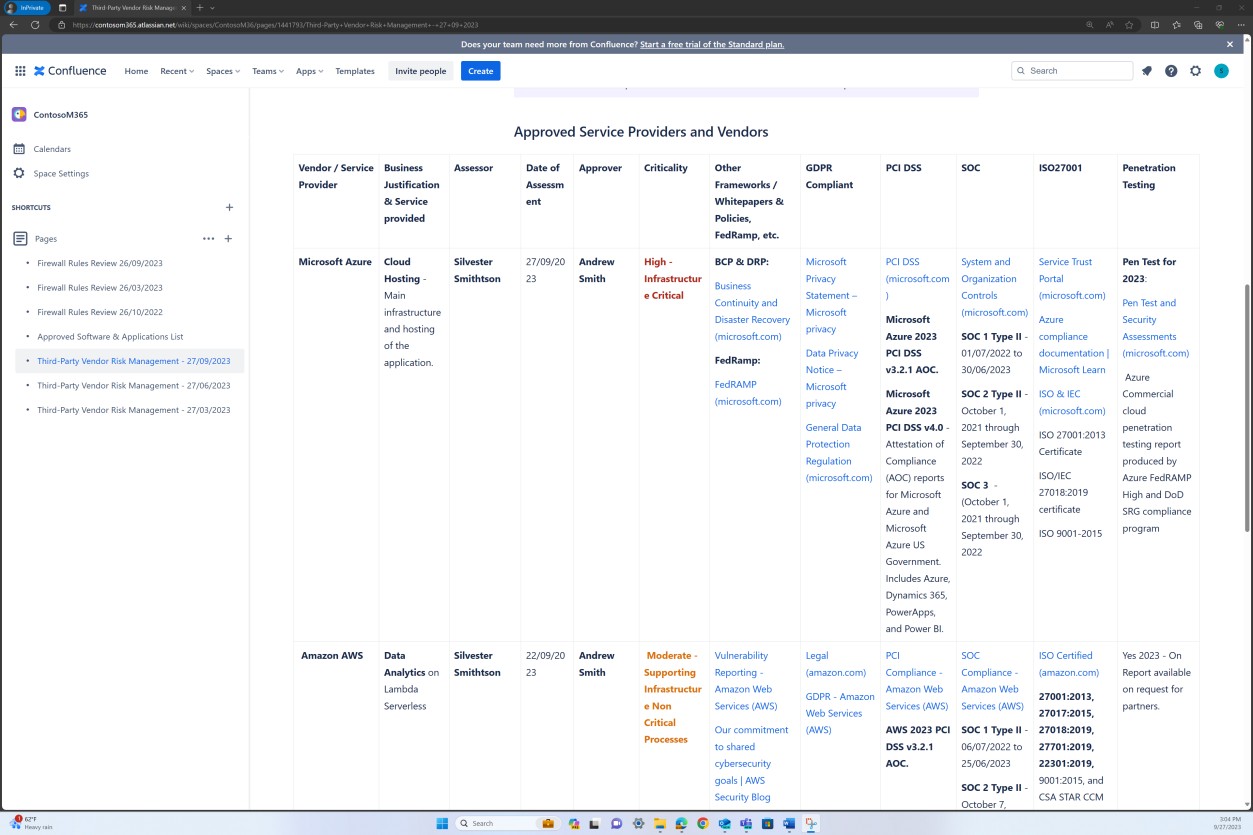
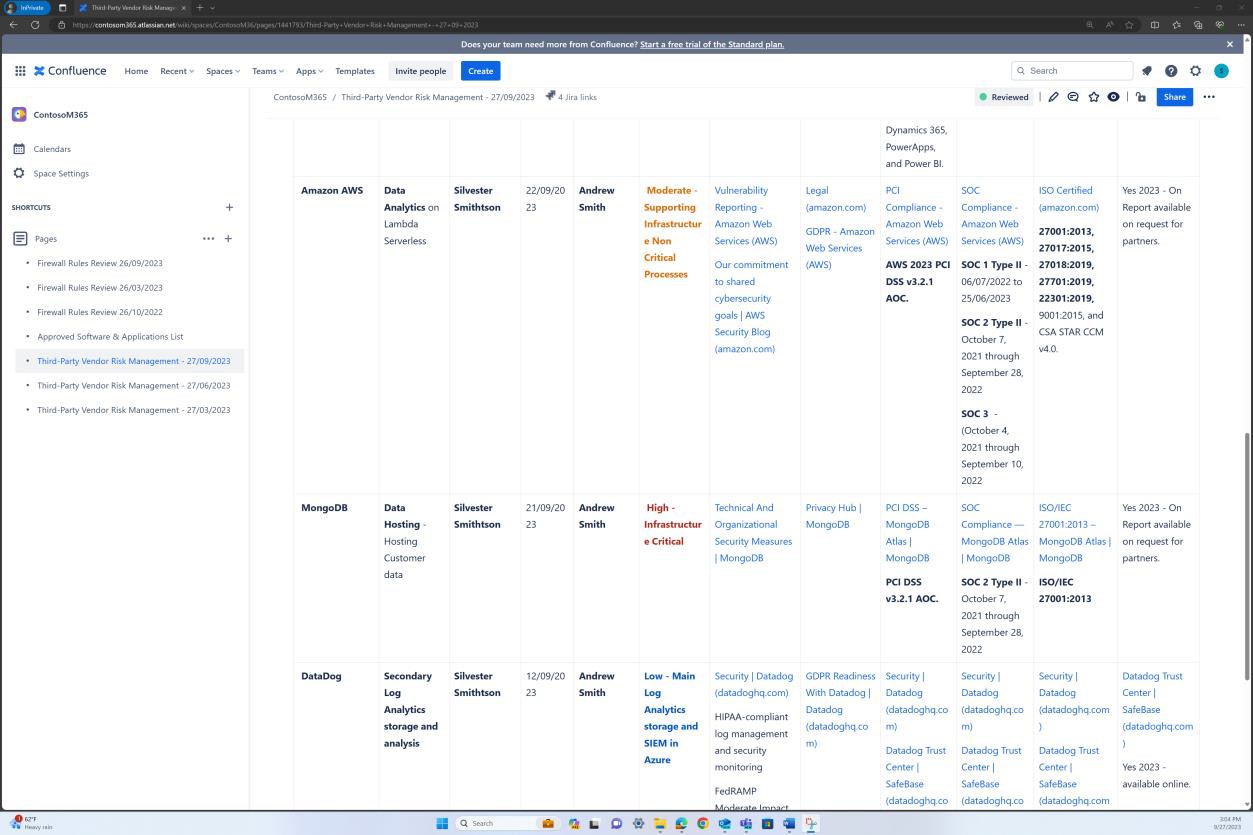
Reaktion auf Sicherheitsvorfälle
Die Reaktion auf Sicherheitsvorfälle ist für alle Organisationen wichtig, da dies den Zeitaufwand eines organization, der einen Sicherheitsvorfall enthält, reduzieren und die Organization durch Datenexfiltration einschränken kann. Durch die Entwicklung eines umfassenden und detaillierten Plans zur Reaktion auf Sicherheitsvorfälle kann diese Exposition vom Zeitpunkt der Identifizierung bis zum Zeitpunkt der Eindämmung reduziert werden.
Ein Bericht von IBM mit dem Titel "Cost of a data breach Report 2020" (Kosten einer Datenverletzungsbericht 2020) hebt hervor, dass die Zeit für die Eindämmung einer Sicherheitsverletzung im Durchschnitt 73 Tage betrug. Darüber hinaus identifiziert derselbe Bericht den größten Kostensparer für organization, die eine Sicherheitsverletzung erlitten haben, war die Bereitschaft zur Reaktion auf Vorfälle, was einen Durchschnitt von
Kosteneinsparungen in Höhe von 2.000.000 USD. Organisationen sollten bewährte Methoden für die Sicherheitskonformität mit Branchenstandardframeworks wie ISO 27001, NIST, SOC 2, PCI DSS usw. befolgen.
Kontrolle Nr. 25
HARTER FEHLER
Stellen Sie Beweise für Folgendes bereit:
Es gibt einen ratifizierten Plan/ein Prozedur zur Reaktion auf Sicherheitsvorfälle (Security Incident Response Plan/IRP), in dem beschrieben wird, wie Ihr organization auf Incidents reagiert, wie er verwaltet wird und folgendes umfasst:
Details des Teams zur Reaktion auf Vorfälle, einschließlich Kontaktinformationen.
ein interner Kommunikationsplan, der während des Vorfalls und für die externe Kommunikation mit relevanten Parteien wie wichtigen Stakeholdern, Zahlungsmarken und Acquirern, Aufsichtsbehörden (z. B. 72 Stunden für die DSGVO), Aufsichtsbehörden, Direktoren, Kunden folgen soll.
Schritte für Aktivitäten wie Klassifizierung, Eindämmung, Entschärfung, Wiederherstellung und Rückkehr zum normalen Geschäftsbetrieb, abhängig von der Art des Incidents.
Absicht: Incident Response Plan (IRP)
Mit dieser Kontrolle soll sichergestellt werden, dass ein formal dokumentierter Vorfallreaktionsplan (Incident Response Plan, IRP) vorhanden ist, der ein bestimmtes Team für die Reaktion auf Vorfälle mit klar dokumentierten Rollen, Zuständigkeiten und Kontaktinformationen umfasst. Das IRP sollte einen strukturierten Ansatz für die Verwaltung von Sicherheitsvorfällen von der Erkennung bis zur Lösung bieten, einschließlich der Klassifizierung der Art des Vorfalls, der Eindämmung der unmittelbaren Auswirkungen, der Risikominderung, der Wiederherstellung nach dem Vorfall und der Wiederherstellung des normalen Geschäftsbetriebs. Jeder Schritt sollte mit klaren Protokollen klar definiert sein, um sicherzustellen, dass die ergriffenen Maßnahmen den Risikomanagementstrategien und Compliance-Verpflichtungen des organization entsprechen.
Die detaillierte Spezifikation des Vorfallreaktionsteams innerhalb des IRP stellt sicher, dass jedes Teammitglied seine Rolle bei der Verwaltung des Incidents versteht und eine koordinierte und effiziente Reaktion ermöglicht. Durch die Einrichtung eines IRP kann ein organization eine Reaktion auf Sicherheitsvorfälle effizienter verwalten, was letztendlich die Offenlegung von Datenverlusten des organization begrenzen und die Kosten der Kompromittierung reduzieren kann.
Organisationen haben möglicherweise Benachrichtigungspflichten aufgrund des Landes/der Länder, in dem sie tätig sind (z. B. dsgvo), oder basierend auf der angebotenen Funktionalität (z. B. PCI-DSS, wenn Zahlungsdaten verarbeitet werden). Das Versäumnis einer rechtzeitigen Benachrichtigung kann schwerwiegende Auswirkungen haben; Um sicherzustellen, dass die Meldepflichten erfüllt sind, sollten daher Pläne zur Reaktion auf Vorfälle einen Kommunikationsprozess umfassen, der die Kommunikation mit allen Beteiligten, Medienkommunikationsprozesse und die Personen, die mit den Medien sprechen können und nicht sprechen können, umfasst.
Richtlinien: interne Kontrollen
Geben Sie die Vollständige Version des Plans bzw. der Prozedur zur Reaktion auf Vorfälle an. Der Plan zur Reaktion auf Vorfälle sollte einen Abschnitt enthalten, der den Prozess für die Behandlung von Vorfällen von der Identifizierung bis zur Lösung sowie einen dokumentierten Kommunikationsprozess abdeckt.
Beispielbeweis: interne Kontrollen
Der nächste Screenshot zeigt den Beginn des Plans zur Reaktion auf Vorfälle von Contoso.
Hinweis: Im Rahmen Ihrer Beweisübermittlung müssen Sie den gesamten Plan zur Reaktion auf Vorfälle bereitstellen.

Beispielbeweis: interne Kontrollen
Der nächste Screenshot zeigt einen Auszug aus dem Plan zur Reaktion auf Vorfälle, der den Kommunikationsprozess zeigt.
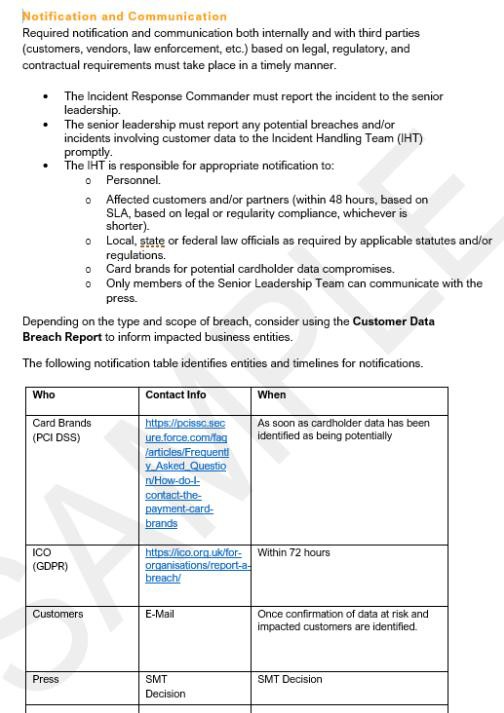
Kontrolle Nr. 26
Stellen Sie Beweise für Folgendes bereit:
Alle Mitglieder des Teams zur Reaktion auf Sicherheitsvorfälle haben jährlich organization spezifischen Reaktionsschulungen zur Reaktion auf Vorfälle erhalten, mit denen sie auf Sicherheitsvorfälle reagieren können.
Absicht: Schulung
Je länger es dauert, bis ein organization eine Kompromittierung eindämmte, desto größer ist das Risiko der Datenexfiltration, was möglicherweise zu einer größeren Menge exfiltrierter Daten und desto höher sind die Gesamtkosten der Kompromittierung. Es ist wichtig, dass die Organization-Teams für die Reaktion auf Vorfälle in der Lage sind, rechtzeitig auf Sicherheitsvorfälle zu reagieren. Durch regelmäßige Schulungen und Die Durchführung von Tischübungen ist das Team darauf vorbereitet, Sicherheitsvorfälle schnell und effizient zu behandeln. Diese Schulung sollte verschiedene Aspekte wie die Identifizierung potenzieller Bedrohungen, erste Reaktionsmaßnahmen, Eskalationsverfahren und langfristige Strategien zur Entschärfung umfassen.
Die Empfehlung besteht darin, sowohl interne Schulungen zur Reaktion auf Vorfälle für das Incident-Reaktionsteam als auch regelmäßige Tabletop-Übungen durchzuführen, die mit dem Informationssicherheitsrisiko verknüpft sein sollten.
Bewertung, um die Sicherheitsvorfälle zu identifizieren, die am wahrscheinlichsten auftreten. Die Tabletop-Übung sollte reale Szenarien simulieren, um die Fähigkeiten des Teams zu testen und zu verfeinern, unter Druck zu reagieren. Auf diese Weise kann die organization sicherstellen, dass ihre Mitarbeiter wissen, wie sie mit sicherheitsrelevanten Sicherheitsverletzungen oder Cyberangriffen umgehen können. Und das Team weiß, welche Schritte unternommen werden müssen, um die wahrscheinlichsten Sicherheitsvorfälle schnell einzudämmen und zu untersuchen.
Richtlinien: Schulung
Es sollten Nachweise vorgelegt werden, die belegen, dass die Schulung durch Die Weitergabe der Schulungsinhalte durchgeführt wurde, und Aufzeichnungen, die zeigen, wer teilgenommen hat (die das gesamte Team für die Reaktion auf Vorfälle umfassen sollte). Alternativ können sie oder auch Datensätze enthalten, die zeigen, dass eine Tabletop-Übung durchgeführt wurde. All dies muss innerhalb eines Zeitraums von 12 Monaten ab dem Zeitpunkt der Beweisaufnahme abgeschlossen worden sein.
Beispielbeweis: Training
Contoso hat eine Tabletop-Übung zur Reaktion auf Vorfälle mithilfe eines externen Sicherheitsunternehmens durchgeführt. Es folgt ein Beispiel des Berichts, der im Rahmen der Beratung generiert wurde.

Hinweis: Der vollständige Bericht muss freigegeben werden. Diese Übung könnte auch intern durchgeführt werden, da es keine Microsoft 365-Anforderung für die Durchführung durch ein Drittanbieterunternehmen gibt.
Hinweis: Der vollständige Bericht muss freigegeben werden. Diese Übung könnte auch intern durchgeführt werden, da es keine Microsoft 365-Anforderung gibt, die von einem Drittanbieter durchgeführt werden muss.
Kontroll Nr. 27
Stellen Sie Beweise für Folgendes bereit:
Die Strategie zur Reaktion auf Sicherheitsvorfälle und die unterstützende Dokumentation werden auf der Grundlage von ENTWEDER:
Erkenntnisse aus einer Tabletop-Übung
Erkenntnisse aus der Reaktion auf einen Sicherheitsvorfall oder
bedeutende organisatorische Änderungen
Absicht: Planüberprüfungen
Im Laufe der Zeit sollte sich der Plan zur Reaktion auf Vorfälle basierend auf organisatorischen Änderungen oder basierend auf den Bei der Umsetzung des Plans gewonnenen Erkenntnissen weiterentwickeln. Änderungen an der Betriebsumgebung erfordern möglicherweise Änderungen am Plan zur Reaktion auf Vorfälle, da sich die Bedrohungen ändern oder sich die gesetzlichen Anforderungen ändern können. Darüber hinaus können bei der Durchführung von Tabletop-Übungen und tatsächlichen Reaktionen auf Sicherheitsvorfälle häufig Bereiche des Plans identifiziert werden, die verbessert werden können. Dies muss in den Plan integriert werden, und die Absicht dieses Steuerelements besteht darin, sicherzustellen, dass dieser Prozess enthalten ist. Ziel dieser Kontrolle ist es, die Überprüfung und Aktualisierung der Reaktionsstrategie des organization und der unterstützenden Dokumentation auf der Grundlage von drei unterschiedlichen Triggern vorzusehen:
Nachdem die simulierten Übungen zur Überprüfung der Wirksamkeit der Strategie zur Reaktion auf Vorfälle durchgeführt wurden, sollten alle identifizierten Lücken oder Verbesserungsbereiche sofort in den bestehenden Plan zur Reaktion auf Vorfälle aufgenommen werden.
Ein tatsächlicher Vorfall bietet wertvolle Einblicke in die Stärken und Schwächen der aktuellen Reaktionsstrategie. Wenn ein Incident auftritt, sollte eine Überprüfung nach dem Vorfall durchgeführt werden, um diese Lektionen zu erfassen, die dann verwendet werden sollten, um die Reaktionsstrategie und -verfahren zu aktualisieren.
Alle wesentlichen Änderungen innerhalb der organization, z. B. Fusionen, Übernahmen oder Änderungen an wichtigen Mitarbeitern, sollten eine Überprüfung der Strategie zur Reaktion auf Vorfälle auslösen. Diese organisatorischen Änderungen können neue Risiken mit sich bringen oder vorhandene Risiken verschieben, und der Plan zur Reaktion auf Vorfälle sollte entsprechend aktualisiert werden, um wirksam zu bleiben.
Richtlinien: Planüberprüfungen
Dies wird häufig durch die Überprüfung der Ergebnisse von Sicherheitsvorfällen oder Tabellenübungen belegt, bei denen die gewonnenen Erkenntnisse identifiziert wurden und zu einer Aktualisierung des Plans zur Reaktion auf Vorfälle geführt haben. Der Plan sollte ein Änderungsprotokoll beibehalten, das auch auf Änderungen verweisen sollte, die basierend auf gewonnenen Erkenntnissen oder organisatorischen Änderungen implementiert wurden.
Beispielbeweis: Planüberprüfungen
Die nächsten Screenshots stammen aus dem bereitgestellten Plan zur Reaktion auf Vorfälle, der einen Abschnitt zum Aktualisieren basierend auf gewonnenen Erkenntnissen und/oder organization Änderungen enthält.



Hinweis: Bei diesen Beispielen handelt es sich nicht um Screenshots im Vollbildmodus. Sie müssen Screenshots im Vollbildmodus mit einer beliebigen URL, einem angemeldeten Benutzer und dem Zeit- und Datumsstempel zur Beweisüberprüfung übermitteln. Wenn Sie ein Linux-Benutzer sind, kann dies über die Eingabeaufforderung erfolgen.
Geschäftskontinuitätsplan und Notfallwiederherstellungsplan
Die Planung der Geschäftskontinuität und die Planung der Notfallwiederherstellung sind zwei wichtige Komponenten der Risikomanagementstrategie einer organization. Die Geschäftskontinuitätsplanung ist der Prozess der Erstellung eines Plans, um sicherzustellen, dass wichtige Geschäftsfunktionen während und nach einem Notfall weiterhin ausgeführt werden können, während die Planung der Notfallwiederherstellung der Prozess ist, einen Plan zur Wiederherstellung nach einem Notfall und zur schnellstmöglichen Wiederherstellung des normalen Geschäftsbetriebs zu erstellen. Beide Pläne ergänzen sich – Sie müssen beides haben, um den betrieblichen Herausforderungen standzuhalten, die durch Katastrophen oder unerwartete Unterbrechungen verursacht werden. Diese Pläne sind wichtig, da sie dazu beitragen, dass ein organization während eines Notfalls weiter betrieben werden kann, seinen Ruf schützen, gesetzliche Anforderungen einhalten, das Kundenvertrauen wahren, Risiken effektiv verwalten und mitarbeiter schützen können.
Regelung Nr. 28
Stellen Sie Beweise für Folgendes bereit:
Die Dokumentation ist vorhanden und wird gepflegt, die den Geschäftskontinuitätsplan umreißt, der Folgendes umfasst:
Details der relevanten Mitarbeiter, einschließlich ihrer Rollen und Zuständigkeiten
Details aller kritischen Geschäftsfunktionen mit zugehörigen Notfallanforderungen und -zielen
Wiederherstellungspriorität und Zeitrahmen zielen auf die Systemwiederherstellung ab und kehren in den ursprünglichen Zustand zurück.
Absicht: Geschäftskontinuitätsplan
Die Absicht hinter dieser Kontrolle besteht darin, sicherzustellen, dass eine klar definierte Liste von Mitarbeitern mit zugewiesenen Rollen und Zuständigkeiten im Geschäftskontinuitätsplan enthalten ist. Diese Rollen sind entscheidend für die effektive Aktivierung und Ausführung des Plans während eines Incidents.
Richtlinien: Geschäftskontinuitätsplan
Geben Sie die vollständige Version des Notfallwiederherstellungsplans bzw. -verfahrens an, die Abschnitte mit der verarbeiteten Gliederung in der Kontrollbeschreibung enthalten sollte. Geben Sie das tatsächliche PDF/WORD-Dokument in einer digitalen Version an, oder wenn der Prozess über eine Online-Plattform verwaltet wird, stellen Sie einen Export oder Screenshots der Prozesse bereit.
Beispielbeweis: Geschäftskontinuitätsplan
Die nächsten Screenshots zeigen einen Auszug eines Geschäftskontinuitätsplans, der vorhanden ist und beibehalten wird.
Hinweis: Dieser Screenshot(n) zeigt Momentaufnahmen eines Richtlinien-/Prozessdokuments. Es wird erwartet, dass ISVs die tatsächliche unterstützende Richtlinien-/Prozedurdokumentation freigeben und nicht einfach einen Screenshot bereitstellen.
Die nächsten Screenshots zeigen einen Auszug der Richtlinie, in der der Abschnitt "Wichtige Mitarbeiter" einschließlich des relevanten Teams, der Kontaktdetails und der auszuführenden Schritte beschrieben ist.

Absicht: Priorisierung
Der Zweck dieses Steuerelements besteht darin, Geschäftsfunktionen entsprechend ihrer Wichtigkeit zu dokumentieren und zu priorisieren. Dies sollte von einer Gliederung der entsprechenden Notfallanforderungen begleitet werden, die erforderlich sind, um jede Funktion während einer ungeplanten Unterbrechung aufrechtzuerhalten oder schnell wiederherzustellen.
Richtlinien: Priorisierung
Geben Sie die vollständige Version des Notfallwiederherstellungsplans bzw. -verfahrens an, die Abschnitte mit der verarbeiteten Gliederung in der Kontrollbeschreibung enthalten sollte. Geben Sie das tatsächliche PDF/WORD-Dokument in einer digitalen Version an, oder wenn der Prozess über eine Online-Plattform verwaltet wird, stellen Sie einen Export oder Screenshots der Prozesse bereit.
Beispielbeweis: Priorisierung
Die nächsten Screenshots zeigen einen Auszug aus einem Geschäftskontinuitätsplan und eine Gliederung der Geschäftsfunktionen und deren Wichtigkeitsstufe sowie ob Notfallpläne vorhanden sind.
Hinweis: Dieser Screenshot(n) zeigt ein Richtlinien-/Prozessdokument. Es wird erwartet, dass ISVs die tatsächliche unterstützende Richtlinien-/Prozedurdokumentation freigeben und nicht einfach einen Screenshot bereitstellen.

Absicht: Sicherungen
Ziel dieses Unterpunkts ist die Aufrechterhaltung dokumentierter Verfahren zur Sicherung wesentlicher Systeme und Daten. In der Dokumentation sollten auch die Konfigurationseinstellungen sowie Sicherungsplanungs- und Aufbewahrungsrichtlinien angegeben werden, um sicherzustellen, dass Die Daten sowohl aktuell als auch abrufbar sind.
Richtlinien: Sicherungen
Geben Sie die vollständige Version des Notfallwiederherstellungsplans bzw. -verfahrens an, die Abschnitte mit der verarbeiteten Gliederung in der Kontrollbeschreibung enthalten sollte. Geben Sie das tatsächliche PDF/WORD-Dokument in einer digitalen Version an, oder wenn der Prozess über eine Online-Plattform verwaltet wird, stellen Sie einen Export oder Screenshots der Prozesse bereit.
Beispielbeweis: Sicherungen
Die nächsten Screenshots zeigen den Auszug des Notfallwiederherstellungsplans von Contoso und dass für jedes System eine dokumentierte Sicherungskonfiguration vorhanden ist. Beachten Sie, dass im nächsten Screenshot, dass auch der Sicherungszeitplan dargestellt ist, beachten Sie, dass für dieses Beispiel die Sicherungskonfiguration als Teil des Notfallwiederherstellungsplans dargestellt wird, da Geschäftskontinuitäts- und Notfallwiederherstellungspläne zusammenarbeiten.
Hinweis: Dieser Screenshot(n) zeigt eine Momentaufnahme eines Richtlinien-/Prozedurdokuments. Es wird erwartet, dass ISVs die tatsächliche unterstützende Richtlinien-/Prozedurdokumentation freigeben und nicht einfach einen Screenshot bereitstellen.
Absicht: Zeitachsen
Dieses Steuerelement zielt darauf ab, priorisierte Zeitachsen für Wiederherstellungsaktionen festzulegen. Diese Wiederherstellungszeitziele (Recovery Time Objectives, RTOs) sollten an der Analyse der geschäftlichen Auswirkungen ausgerichtet und klar definiert werden, damit das Personal versteht, welche Systeme und Funktionen zuerst wiederhergestellt werden müssen.
Richtlinien: Zeitpläne
Geben Sie die vollständige Version des Notfallwiederherstellungsplans bzw. -verfahrens an, die Abschnitte mit der verarbeiteten Gliederung in der Kontrollbeschreibung enthalten sollte. Geben Sie das tatsächliche PDF/WORD-Dokument in einer digitalen Version an, oder wenn der Prozess über eine Online-Plattform verwaltet wird, stellen Sie einen Export oder Screenshots der Prozesse bereit.
Beispielbeweis: Zeitachsen
Der folgende Screenshot zeigt die Fortsetzung der Geschäftsfunktionen und die Klassifizierung der Wichtigkeit sowie das etablierte Recovery Time Objective (RTO).
Hinweis: Dieser Screenshot(n) zeigt ein Richtlinien-/Prozessdokument. Es wird erwartet, dass ISVs die tatsächliche unterstützende Richtlinien-/Prozedurdokumentation freigeben und nicht einfach einen Screenshot bereitstellen.


Absicht: Wiederherstellung
Mit diesem Steuerelement soll ein schrittweises Verfahren bereitgestellt werden, das befolgt werden soll, um kritische Informationssysteme, Geschäftsfunktionen und Dienste an operative status zurückzugeben. Dies sollte detailliert genug sein, um die Entscheidungsfindung in Situationen mit hohem Druck zu steuern, in denen schnelle und wirksame Maßnahmen von entscheidender Bedeutung sind.
Richtlinien: Wiederherstellung
Geben Sie die vollständige Version des Notfallwiederherstellungsplans bzw. -verfahrens an, die Abschnitte mit der verarbeiteten Gliederung in der Kontrollbeschreibung enthalten sollte. Geben Sie das tatsächliche PDF/WORD-Dokument in einer digitalen Version an, oder wenn der Prozess über eine Online-Plattform verwaltet wird, stellen Sie einen Export oder Screenshots der Prozesse bereit.
Beispielbeweis: Wiederherstellung
Die nächsten Screenshots zeigen den Auszug unseres Notfallwiederherstellungsplans und dass ein dokumentierter Wiederherstellungsplan für jedes System und jede Geschäftsfunktion vorhanden ist. Beachten Sie, dass für dieses Beispiel das Systemwiederherstellungsverfahren Teil des Notfallwiederherstellungsplans ist, da Geschäftskontinuitäts- und Notfallwiederherstellungspläne zusammenarbeiten, um eine vollständige Wiederherstellung/Wiederherstellung zu erreichen.
Hinweis: Dieser Screenshot(n) zeigt ein Richtlinien-/Prozessdokument. Es wird erwartet, dass ISVs die tatsächliche unterstützende Richtlinien-/Prozedurdokumentation freigeben und nicht einfach einen Screenshot bereitstellen.
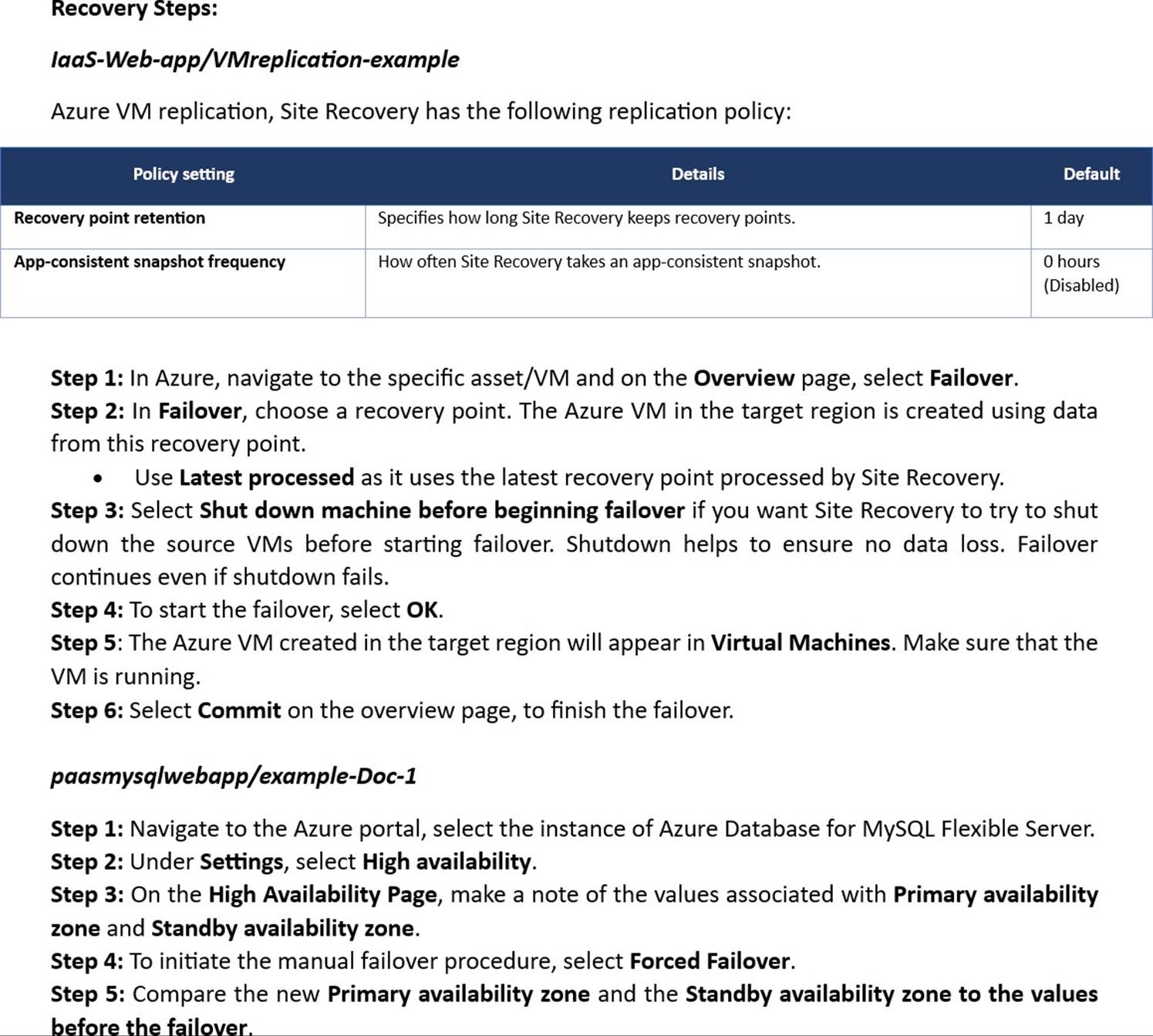
Absicht: Überprüfung
Dieser Kontrollpunkt soll sicherstellen, dass der Geschäftskontinuitätsplan einen strukturierten Prozess umfasst, der die organization bei der Wiederherstellung der Systeme in ihren ursprünglichen Zustand nach der Bewältigung der Krise führt. Dies umfasst Validierungsschritte, um sicherzustellen, dass Systeme vollständig betriebsbereit sind und ihre Integrität beibehalten haben.
Richtlinien: Validierung
Geben Sie die vollständige Version des Notfallwiederherstellungsplans bzw. -verfahrens an, die Abschnitte mit der verarbeiteten Gliederung in der Kontrollbeschreibung enthalten sollte. Geben Sie das tatsächliche PDF/WORD-Dokument in einer digitalen Version an, oder wenn der Prozess über eine Online-Plattform verwaltet wird, stellen Sie einen Export oder Screenshots der Prozesse bereit.
Beispielbeweis: Validierung
Der folgende Screenshot zeigt den in der Richtlinie für den Geschäftskontinuitätsplan beschriebenen Wiederherstellungsprozess und die auszuführenden Schritte/Aktionen.
Hinweis: Dieser Screenshot(n) zeigt eine Momentaufnahme eines Richtlinien-/Prozedurdokuments. Es wird erwartet, dass ISVs die tatsächliche unterstützende Richtlinien-/Prozedurdokumentation freigeben und nicht einfach einen Screenshot bereitstellen.

Kontrolle Nr. 29
Stellen Sie Beweise für Folgendes bereit:
Die Dokumentation ist vorhanden und wird verwaltet, in der der Plan für die Notfallwiederherstellung beschrieben wird, der mindestens Folgendes umfasst:
Personal seine Rollen, Zuständigkeiten und Eskalationsprozess
Inventarisierung der Informationssysteme, die zur Unterstützung kritischer Geschäftsfunktionen und -dienste verwendet werden
System- und Datensicherungsverfahren und Konfiguration
einen Wiederherstellungsplan, in dem die Maßnahmen und Verfahren beschrieben sind, die befolgt werden müssen, um kritische Informationssysteme und Daten wieder in Betrieb zu bringen.
Absicht: DRP
Das Ziel dieser Kontrolle besteht darin, gut dokumentierte Rollen und Zuständigkeiten für jedes Mitglied des Notfallwiederherstellungsteams zu haben. Außerdem sollte ein Eskalationsprozess skizziert werden, um sicherzustellen, dass Probleme während eines Notfallszenarios schnell erhöht und von entsprechenden Mitarbeitern behoben werden.
Richtlinien: DRP
Geben Sie die vollständige Version des Notfallwiederherstellungsplans bzw. -verfahrens an, die Abschnitte mit der verarbeiteten Gliederung in der Kontrollbeschreibung enthalten sollte. Geben Sie das tatsächliche PDF/WORD-Dokument in einer digitalen Version an, oder wenn der Prozess über eine Online-Plattform verwaltet wird, stellen Sie einen Export oder Screenshots der Prozesse bereit.
Beispielbeweis: DRP
Die nächsten Screenshots zeigen den Auszug eines Notfallwiederherstellungsplans, der vorhanden ist und verwaltet wird.
Hinweis: Dieser Screenshot(n) zeigt ein Richtlinien-/Prozessdokument. Es wird erwartet, dass ISVs die tatsächliche unterstützende Richtlinien-/Prozedurdokumentation freigeben und nicht einfach einen Screenshot bereitstellen.
Der nächste Screenshot zeigt einen Auszug der Richtlinie, in der der "Notfallplan" einschließlich des relevanten Teams, Kontaktdetails und Eskalationsschritten beschrieben ist.
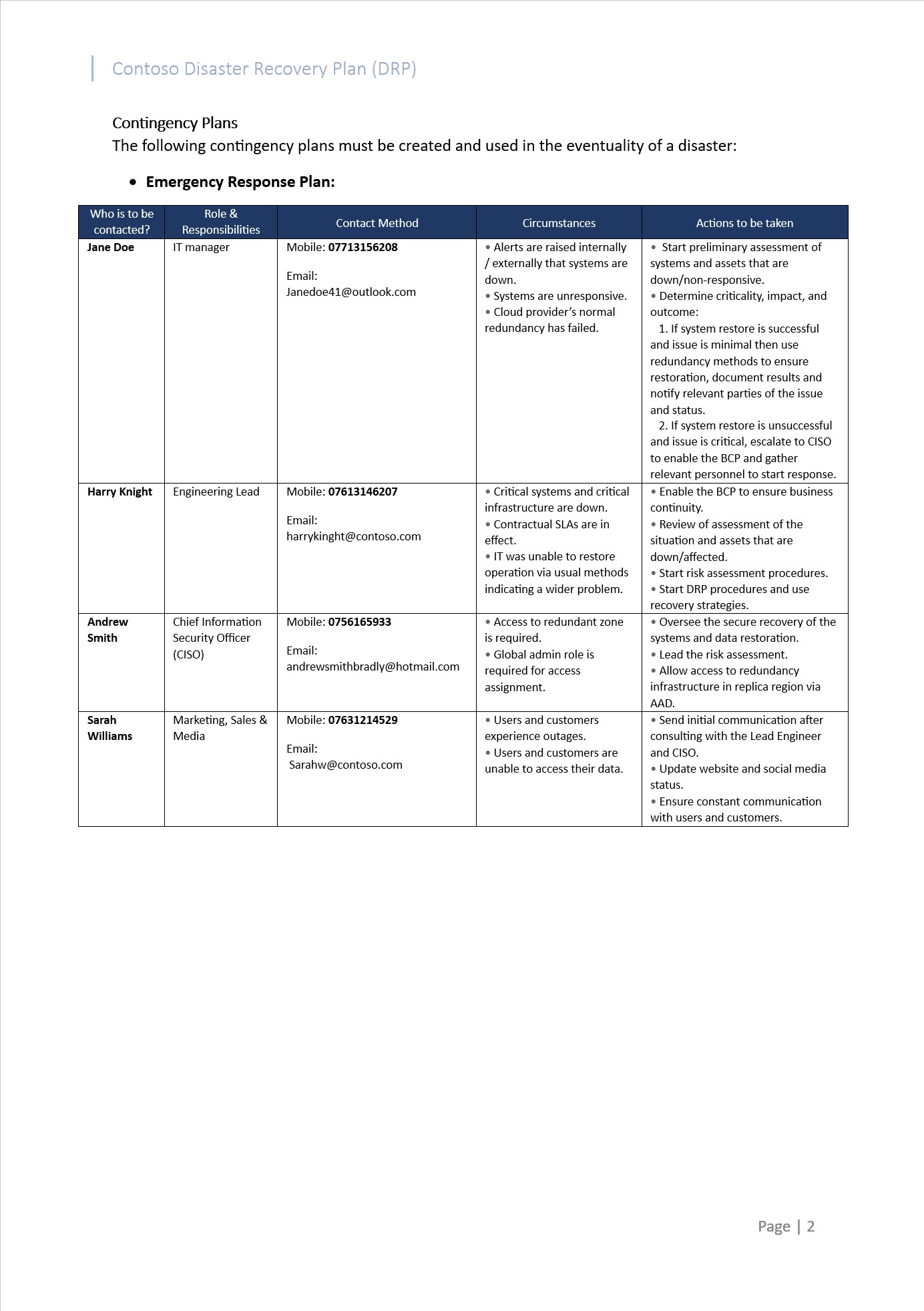
Absicht: Inventur
Die Absicht hinter dieser Kontrolle besteht darin, eine aktuelle Bestandsliste aller Informationssysteme zu verwalten, die für die Unterstützung von Geschäftsvorgängen von entscheidender Bedeutung sind. Diese Liste ist von grundlegender Bedeutung, um zu verstehen, welche Systeme während einer Notfallwiederherstellung priorisiert werden müssen.
Richtlinien: Bestand
Geben Sie die vollständige Version des Notfallwiederherstellungsplans bzw. -verfahrens an, die Abschnitte mit der verarbeiteten Gliederung in der Kontrollbeschreibung enthalten sollte. Geben Sie das tatsächliche PDF/WORD-Dokument in einer digitalen Version an, oder wenn der Prozess über eine Online-Plattform verwaltet wird, stellen Sie einen Export oder Screenshots der Prozesse bereit.
Beispielbeweis: Bestand
Die nächsten Screenshots zeigen den Auszug eines DRP und dass eine Bestandsaufnahme kritischer Systeme und deren Wichtigkeitsgrad sowie Systemfunktionen vorhanden sind.
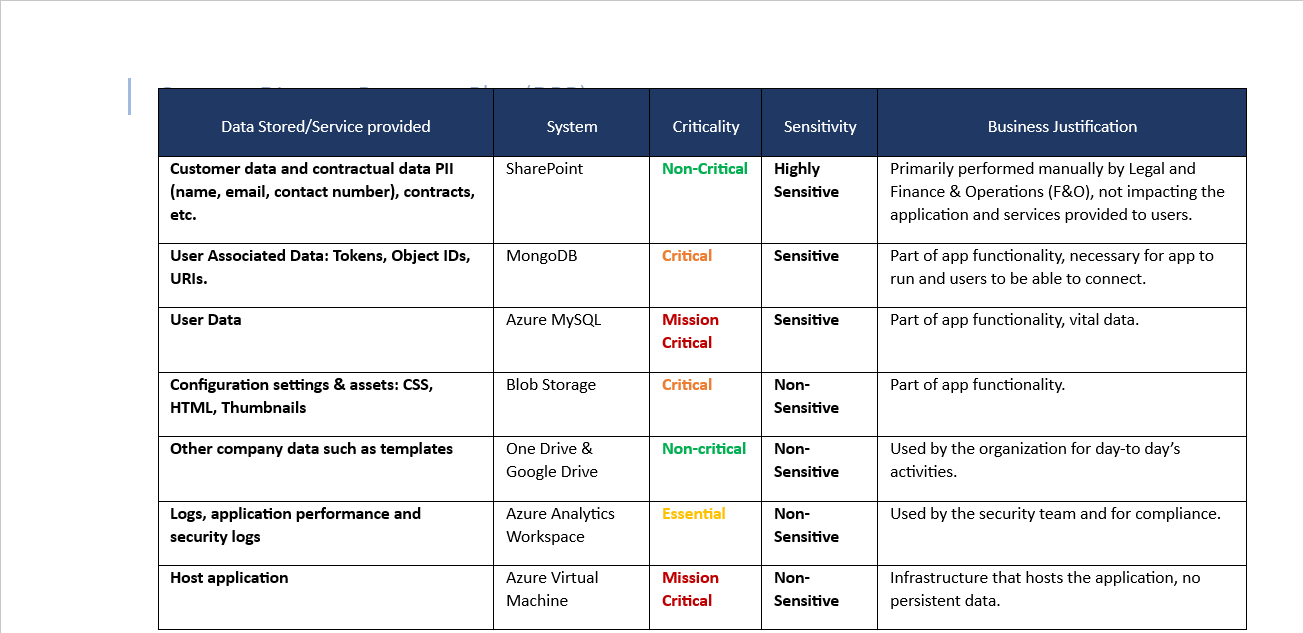
Hinweis: Dieser Screenshot(n) zeigt ein Richtlinien-/Prozessdokument. Es wird erwartet, dass ISVs die tatsächliche unterstützende Richtlinien-/Prozedurdokumentation freigeben und nicht einfach einen Screenshot bereitstellen.
Der nächste Screenshot zeigt die Klassifizierungs- und Dienstkritikalitätsdefinition.
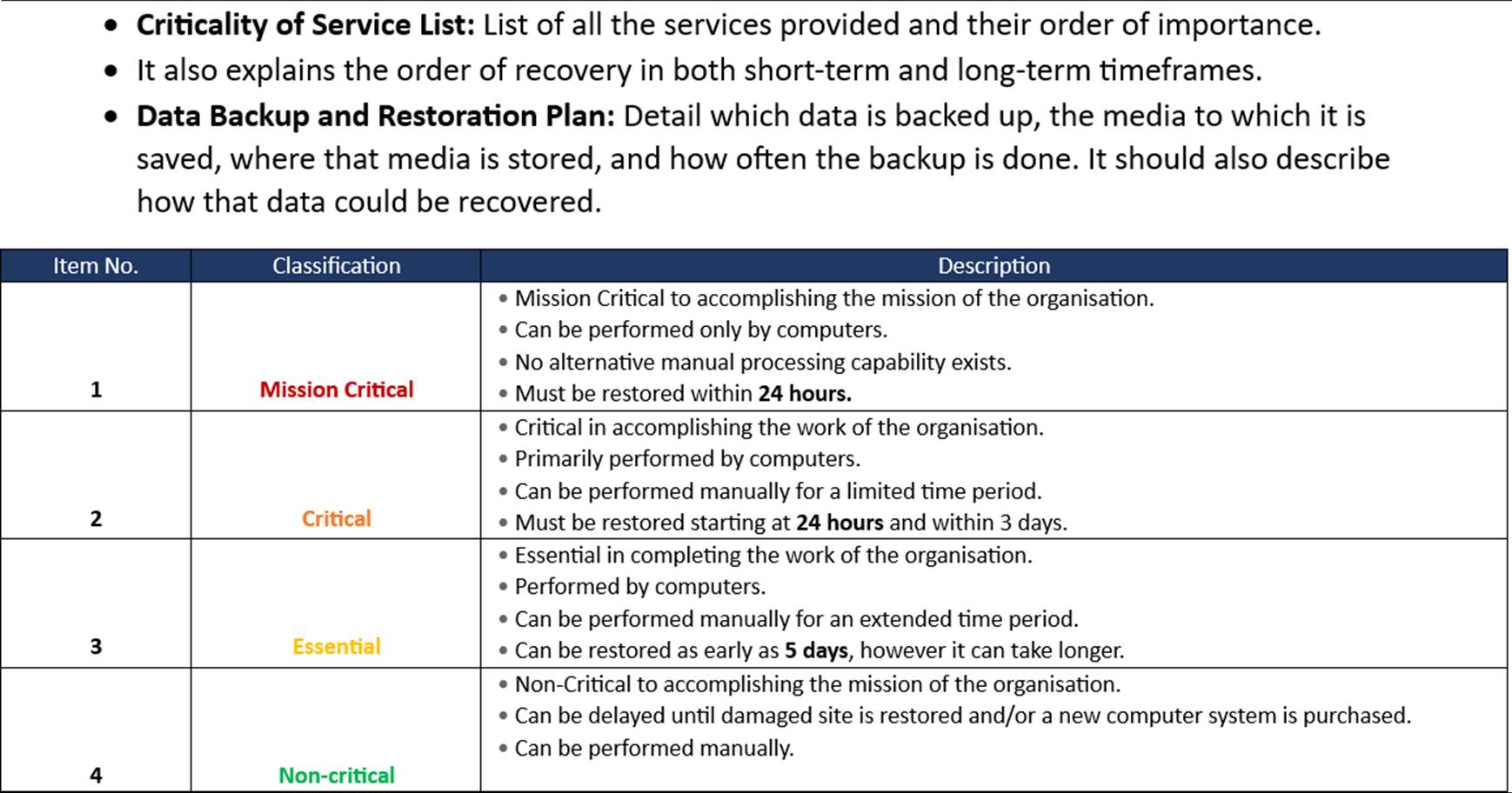
Hinweis: Dieser Screenshot(n) zeigt ein Richtlinien-/Prozessdokument. Es wird erwartet, dass ISVs die tatsächliche unterstützende Richtlinien-/Prozedurdokumentation freigeben und nicht einfach einen Screenshot bereitstellen.
Absicht: Sicherungen
Diese Kontrolle erfordert, dass klar definierte Prozeduren für System- und Datensicherungen vorhanden sind. Diese Verfahren sollten die Häufigkeit, Konfiguration und Speicherorte von Sicherungen beschreiben, um sicherzustellen, dass alle kritischen Daten im Falle eines Ausfalls oder notfalls wiederhergestellt werden können.
Richtlinien: Sicherungen
Geben Sie die vollständige Version des Notfallwiederherstellungsplans bzw. -verfahrens an, die Abschnitte mit der verarbeiteten Gliederung in der Kontrollbeschreibung enthalten sollte. Geben Sie das tatsächliche PDF/WORD-Dokument in einer digitalen Version an, oder wenn der Prozess über eine Online-Plattform verwaltet wird, stellen Sie einen Export oder Screenshots der Prozesse bereit.
Beispielbeweis: Sicherungen
Die nächsten Screenshots zeigen den Auszug eines Notfallwiederherstellungsplans und dass für jedes System eine dokumentierte Sicherungskonfiguration vorhanden ist. Beachten Sie, dass der Sicherungszeitplan ebenfalls beschrieben ist.
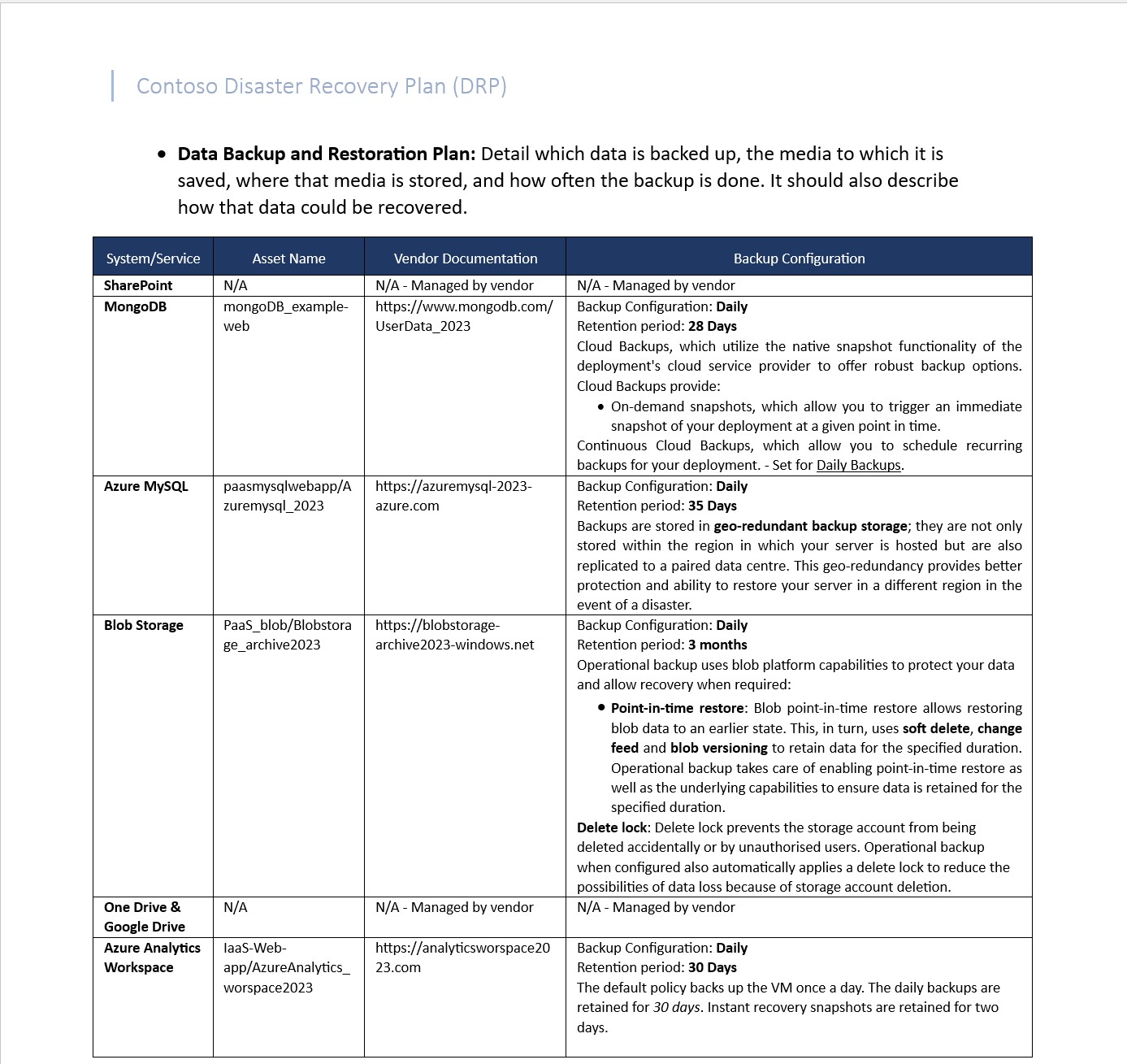
Hinweis: Diese Screenshots zeigen eine Momentaufnahme eines Richtlinien-/Prozessdokuments. Es wird erwartet, dass ISVs die tatsächliche unterstützende Richtlinien-/Prozedurdokumentation freigeben und nicht einfach einen Screenshot bereitstellen.
Absicht: Wiederherstellung
Diese Kontrolle erfordert einen umfassenden Wiederherstellungsplan, der schrittweise Verfahren zum Wiederherstellen wichtiger Systeme und Daten beschreibt. Dies dient als Roadmap für das Notfallwiederherstellungsteam und stellt sicher, dass alle Wiederherstellungsaktionen bei der Wiederherstellung des Geschäftsbetriebs prämeditiert und effektiv sind.
Richtlinien: Wiederherstellung
Geben Sie die vollständige Version des Notfallwiederherstellungsplans bzw. -verfahrens an, die Abschnitte mit der verarbeiteten Gliederung in der Kontrollbeschreibung enthalten sollte. Geben Sie das tatsächliche PDF/WORD-Dokument in einer digitalen Version an, oder wenn der Prozess über eine Online-Plattform verwaltet wird, stellen Sie einen Export oder Screenshots der Prozesse bereit.
Beispielbeweis: Wiederherstellung
Die nächsten Screenshots zeigen den Auszug eines Notfallwiederherstellungsplans, die Schritte und Anweisungen zur Wiederherstellung eines Geräts und die Systemwiederherstellung, sowie das Wiederherstellungsverfahren, das Wiederherstellungszeitrahmen, Die auszuführenden Maßnahmen zur Wiederherstellung der Cloudinfrastruktur usw. enthält.

Hinweis: Diese Screenshots zeigen eine Momentaufnahme eines Richtlinien-/Prozessdokuments. Es wird erwartet, dass ISVs die tatsächliche unterstützende Richtlinien-/Prozedurdokumentation freigeben und nicht einfach einen Screenshot bereitstellen.
Steuerung Nr. 30
Stellen Sie Beweise für Folgendes bereit:
Die Pläne für Geschäftskontinuität und Notfallwiederherstellung werden mindestens jährlich überprüft, um sicherzustellen, dass sie in ungünstigen Situationen gültig und wirksam bleiben.
Alle relevanten Mitarbeiter erhalten Schulungen zu ihren Rollen und Zuständigkeiten, die im Rahmen der Notfallpläne zugewiesen sind.
Beide Pläne werden durch jährliche Übungen zur Geschäftskontinuität und Notfallwiederherstellung getestet.
Beide Pläne werden basierend auf den Erkenntnissen aktualisiert, die aus der Umsetzung der Pläne oder den jährlichen Übungen gewonnen wurden, oder nach erheblichen organisatorischen Änderungen aktualisiert werden.
Absicht: jährliche Überprüfung
Mit dieser Kontrolle soll sichergestellt werden, dass die Pläne für Geschäftskontinuität und Notfallwiederherstellung jährlich überprüft werden. Die Überprüfung sollte bestätigen, dass die Pläne weiterhin effektiv, genau und an den aktuellen Geschäftszielen und technologischen Architekturen ausgerichtet sind.
Absicht: jährliche Schulung
Diese Kontrolle schreibt vor, dass alle Personen mit bestimmten Rollen in den Plänen für Geschäftskontinuität und Notfallwiederherstellung jährlich geeignete Schulungen erhalten. Das Ziel besteht darin, sicherzustellen, dass sie sich ihrer Verantwortung bewusst sind und in der Lage sind, diese im Falle eines Notfalls oder einer Geschäftsunterbrechung effektiv auszuführen.
Absicht: Übungen
Die Absicht besteht darin, die Wirksamkeit der Geschäftskontinuitäts- und Notfallwiederherstellungspläne durch praktische Übungen zu überprüfen. Diese Übungen sollten so konzipiert sein, dass sie verschiedene widrige Bedingungen simulieren, um zu testen, wie gut die organization den Geschäftsbetrieb aufrechterhalten oder wiederherstellen kann.
Absicht: Analyse
Der letzte Kontrollpunkt zielt auf eine gründliche Dokumentation aller Testergebnisse ab, einschließlich einer Analyse, was gut funktioniert hat und was nicht. Die gewonnenen Erkenntnisse sollten wieder in die Pläne integriert werden, und alle Mängel sollten sofort behoben werden, um die Resilienz der organization zu verbessern.
Richtlinien: Überprüfungen
Beweise wie Berichte, Besprechungsnotizen und Ausgaben der jährlich ausgeführten Geschäftskontinuitäts- und Notfallwiederherstellungspläne sollten zur Überprüfung vorgelegt werden.
Beispielbeweis: Überprüfungen
Die nächsten Screenshots zeigen eine Berichtsausgabe eines Drills zum Geschäftskontinuitäts- und Notfallwiederherstellungsplan (Übung), in dem ein Szenario erstellt wurde, mit dem das Team den Plan für Geschäftskontinuität und Notfallwiederherstellung umsetzen und die Situation bis zur erfolgreichen Wiederherstellung von Geschäftsfunktionen und Systembetrieb exemplarische Schritte durchgehen kann.
Hinweis: Diese Screenshots zeigen eine Momentaufnahme eines Richtlinien-/Prozessdokuments. Es wird erwartet, dass ISVs die tatsächliche unterstützende Richtlinien-/Prozedurdokumentation freigeben und nicht einfach einen Screenshot bereitstellen.





Hinweis: Diese Screenshots zeigen eine Momentaufnahme eines Richtlinien-/Prozessdokuments. Es wird erwartet, dass ISVs die tatsächliche unterstützende Richtlinien-/Prozedurdokumentation freigeben und nicht einfach einen Screenshot bereitstellen.