Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
Die Eingabeaufforderungs-API ist eine experimentelle Web-API, mit der Sie ein in Microsoft Edge integriertes kleines Sprachmodell (SLM) aus dem JavaScript-Code Ihrer Website oder Browsererweiterung auffordern können. Verwenden Sie die Eingabeaufforderungs-API, um Text zu generieren und zu analysieren oder Anwendungslogik basierend auf Benutzereingaben zu erstellen, und entdecken Sie innovative Möglichkeiten zum Integrieren von Prompt Engineering-Funktionen in Ihre Webanwendung.
Ausführlicher Inhalt:
- Verfügbarkeit der Eingabeaufforderungs-API
- Alternativen und Vorteile der Eingabeaufforderungs-API
- In Microsoft Edge integrierte kleine Sprachmodelle
- Das Phi-4-mini-Modell
- Das Aion-1.0-Instruct-Modell
- Aktivieren der Eingabeaufforderungs-API
- Sehen Sie sich ein funktionierendes Beispiel an
- Verwenden der Eingabeaufforderungs-API
- Senden von Feedback
- Siehe auch
Verfügbarkeit der Eingabeaufforderungs-API
Die Eingabeaufforderungs-API ist als Entwicklervorschau in den Kanälen Microsoft Edge Canary und Edge Dev ab Version 138.0.3309.2 verfügbar.
Die Eingabeaufforderungs-API soll dabei helfen, Anwendungsfälle zu ermitteln und Die Herausforderungen für integrierte SLMs zu verstehen. Es wird erwartet, dass diese API von anderen experimentellen APIs für bestimmte KI-gestützte Aufgaben wie Schreibunterstützung und Textübersetzung abgelöst wird. Weitere Informationen zu diesen anderen APIs finden Sie unter:
- Zusammenfassen, Schreiben und Erneutes Schreiben von Text mit den ApIs für die Schreibunterstützung
- Übersetzen von Text mit der Übersetzer-API
- Erkennen von Sprachen mit der Spracherkennungs-API
Alternativen und Vorteile der Eingabeaufforderungs-API
Um KI-Funktionen in Websites und Browsererweiterungen zu nutzen, können Sie auch die folgenden Methoden verwenden:
Senden von Netzwerkanforderungen an cloudbasierte KI-Dienste, z. B. Azure KI-Lösungen.
Führen Sie lokale KI-Modelle mithilfe der WebNN-API (Web Neural Network) oder ONNX Runtime for Web aus.
Die Eingabeaufforderungs-API verwendet eine SLM, die auf demselben Gerät ausgeführt wird, auf dem die Eingaben und Ausgaben des Modells verwendet werden (also lokal). Dies hat im Vergleich zu cloudbasierten Lösungen die folgenden Vorteile:
Reduzierte Kosten: Für die Verwendung eines KI-Clouddiensts fallen keine Kosten an.
Netzwerkunabhängigkeit: Über den ursprünglichen Modelldownload hinaus gibt es keine Netzwerklatenz, wenn das Modell aufgefordert wird, und kann auch verwendet werden, wenn das Gerät offline ist.
Verbesserter Datenschutz: Die Dateneingabe für das Modell verlässt nie das Gerät und wird nicht zum Trainieren von KI-Modellen gesammelt.
Die Eingabeaufforderungs-API verwendet ein Modell, das von Microsoft Edge bereitgestellt und in den Browser integriert ist, das zusätzliche Vorteile gegenüber benutzerdefinierten lokalen Lösungen bietet, z. B. solche, die auf WebGPU, WebNN oder WebAssembly basieren:
Gemeinsame Einmalige Kosten: Das vom Browser bereitgestellte Modell wird heruntergeladen, wenn die API zum ersten Mal aufgerufen und für alle Websites freigegeben wird, die im Browser ausgeführt werden, wodurch die Netzwerkkosten für Benutzer und Entwickler reduziert werden.
Vereinfachte Nutzung für Webentwickler: Das integrierte Modell kann mit einfachen Web-APIs ausgeführt werden und erfordert keine KI/ML-Kenntnisse oder Die Verwendung von Frameworks von Drittanbietern.
In Microsoft Edge integrierte kleine Sprachmodelle
In den Microsoft Edge Canary- und Dev-Kanälen verwendet die Eingabeaufforderungs-API ab Version 138.0.3309.2 das in Microsoft Edge integrierte Phi-4-mini-Modell.
Ab Version 150.0.4070 kann die Eingabeaufforderungs-API auch mit dem Vorabversionsmodell Aion-1.0-Instruct verwendet werden, das ebenfalls in Microsoft Edge integriert ist. Aion-1.0-Instruct ist ein kleineres, schnelleres und effizienteres Modell als Phi-4-mini und wird auf Geräten mit weniger fähigen GPUs oder ohne GPU über CPU-Rückschlüsse unterstützt. Wenn die Leistungsklasse Ihres Geräts nicht hoch genug ist, um Phi-4-mini zu unterstützen, können Sie das Vorabversionsmodell Aion-1.0-Instruct testen.
Weitere Informationen zu beiden Modellen und zum Aktivieren von Aion-1.0-Instruct finden Sie in den folgenden Abschnitten.
Das Phi-4-mini-Modell
Mit der Eingabeaufforderungs-API können Sie Phi-4-mini auffordern, das in Microsoft Edge integriert ist. Phi-4-mini ist ein leistungsstarkes kleines Sprachmodell, das sich bei textbasierten Aufgaben auszeichnet. Weitere Informationen zu Phi-4-mini und seinen Funktionen finden Sie im Karte modell unter microsoft/Phi-4-mini-instruct.
Haftungsausschluss
Wie andere Sprachmodelle kann sich die Phi-Modellfamilie potenziell unfair, unzuverlässig oder anstößig verhalten. Weitere Informationen zu den KI-Überlegungen des Modells finden Sie unter Überlegungen zu verantwortungsvoller KI.
Hardwareanforderungen
Die Vorschauversion der Eingabeaufforderungs-API für Entwickler soll auf Geräten mit Hardwarefunktionen verwendet werden, die SLM-Ausgaben mit vorhersagbarer Qualität und Latenz erzeugen. Die Eingabeaufforderungs-API ist derzeit auf Folgendes beschränkt:
Betriebssystem: Windows 10 oder 11 und macOS 13.3 oder höher.
Speicher: Mindestens 20 GB sind auf dem Volume verfügbar, das Ihr Edge-Profil enthält. Wenn der verfügbare Speicher unter 10 GB sinkt, wird das Modell gelöscht, um sicherzustellen, dass andere Browserfeatures über genügend Speicherplatz verfügen, um zu funktionieren.
GPU: 5,5 GB VRAM oder mehr.
Netzwerk: Unbegrenzter Datentarif oder unmeter Verbindung. Das Modell wird nicht heruntergeladen, wenn eine getaktete Verbindung verwendet wird.
Um zu überprüfen, ob Ihr Gerät die Entwicklervorschau der Eingabeaufforderungs-API unterstützt, lesen Sie unten Aktivieren der Eingabeaufforderungs-API , und überprüfen Sie ihre Geräteleistungsklasse.
Aufgrund der experimentellen Natur der Eingabeaufforderungs-API können Probleme bei bestimmten Hardwarekonfigurationen auftreten. Wenn Probleme bei bestimmten Hardwarekonfigurationen auftreten, geben Sie Feedback an, indem Sie ein neues Problem im MSEdgeExplainers-Repository öffnen.
Verfügbarkeit des Phi-4-mini-Modells
Ein erster Download des Phi-4-mini-Modells ist erforderlich, wenn eine Website zum ersten Mal eine API aufruft, die ein Modell auf dem Gerät erfordert. Sie können das Herunterladen des Phi-4-mini-Modells überwachen, indem Sie beim Erstellen einer neuen Eingabeaufforderungs-API-Sitzung die Monitoroption verwenden. Weitere Informationen finden Sie weiter unten unter Überwachen des Status des Modelldownloads.
Das Aion-1.0-Instruct-Modell
In Microsoft Edge Canary oder Edge Dev kann die Eingabeaufforderungs-API ab Version 150.0.4070 auch mit dem in Microsoft Edge integrierten Vorabversionsmodell Aion-1.0-Instruct verwendet werden.
Dieses Aion-1.0-Instruct-Modell ist deutlich kleiner, schneller und effizienter als Phi-4-mini und wird auf Geräten mit weniger fähigen GPUs oder ohne GPU über CPU-Rückschlüsse unterstützt.
Aion-1.0-Instruct wird voraussichtlich im Juli 2026 als Open Source-Modell verfügbar gemacht.
Aktivieren von Aion-1.0-Instruct für die Eingabeaufforderungs-API
Standardmäßig verwendet die Eingabeaufforderungs-API das Phi-4-mini-Modell. Um Aion-1.0-Instruct in Microsoft Edge Canary oder Edge Dev zu verwenden, aktivieren Sie das Flag Vorabversion des Gerätesprachmodells aktivieren , wie in den folgenden Schritten beschrieben. Wenn dieses Flag aktiviert ist, überschreibt Aion-1.0-Instruct Phi-4-mini als Standardmodell für die Eingabeaufforderungs-API.
Stellen Sie sicher, dass Sie die neueste Version von Edge Canary oder Edge Dev (Version 150.0.4070 oder höher) verwenden. Weitere Informationen finden Sie unter Werden Sie ein Microsoft Edge-Insider.
Öffnen Sie in Edge Canary oder Edge Dev eine neue Registerkarte oder ein neues Fenster, und wechseln Sie zu
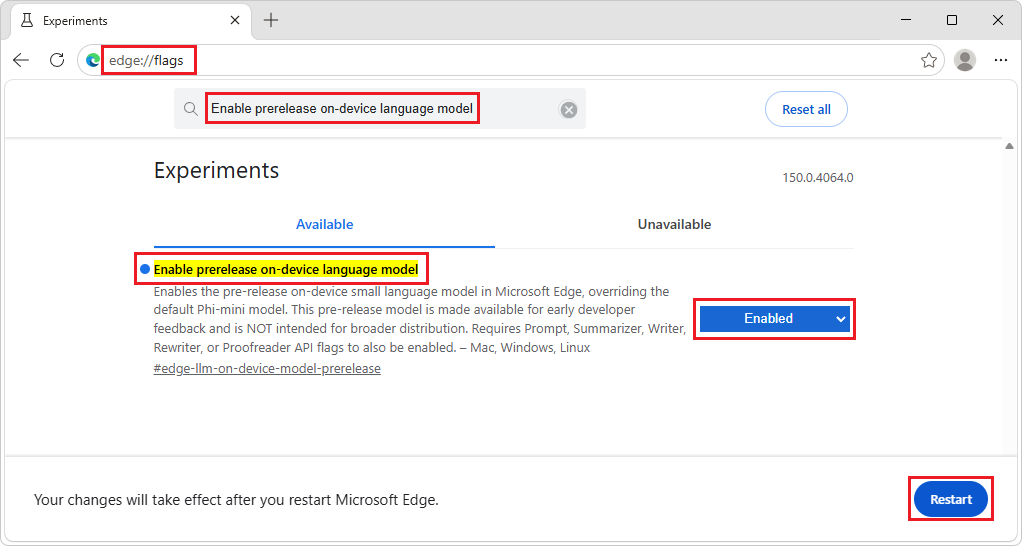
edge://flags.Geben Sie im Suchfeld oben auf der Seite Vorabversion auf dem Gerät sprachmodell aktivieren ein.
Wählen Sie in der Dropdownliste Vorabversion des Gerätesprachmodells aktivieren die Option Aktiviert aus, und klicken Sie dann auf die Schaltfläche Neu starten :
Um zu überprüfen, ob Aion-1.0-Instruct als sprachbasiertes Modell auf dem Gerät verwendet wird, wechseln Sie zu
edge://on-device-internals, klicken Sie auf Modellstatus, und überprüfen Sie, ob Modellname auf Aion-1.0-Instruct festgelegt ist.
Haftungsausschluss
Das Aion-1.0-Instruct-Modell wird in Microsoft Edge 150.0.4070 für frühe Tests und Feedback für Entwickler verfügbar gemacht. Beachten Sie zusätzlich zu den oben aufgeführten Überlegungen zur verantwortungsvollen KI, dass sich das Modellverhalten und die Funktionen aufgrund des Vorabversionszustands ändern können.
Verfügbarkeit des Aion-1.0-Instruct-Modells
Ein erster Download des Aion-1.0-Instruct-Modells ist erforderlich, wenn eine Website zum ersten Mal eine API aufruft, die ein Gerätemodell erfordert. Sie können das Herunterladen des Aion-1.0-Instruct-Modells überwachen, indem Sie beim Erstellen einer neuen Eingabeaufforderungs-API-Sitzung die Monitoroption verwenden. Weitere Informationen finden Sie weiter unten unter Überwachen des Status des Modelldownloads.
Aktivieren der Eingabeaufforderungs-API
So verwenden Sie die Eingabeaufforderungs-API in Microsoft Edge:
Stellen Sie sicher, dass Sie die neueste Version von Microsoft Edge Canary oder Edge Dev (Version 138.0.3309.2 oder höher) verwenden. Weitere Informationen finden Sie unter Werden Sie ein Microsoft Edge-Insider.
Öffnen Sie in Edge Canary oder Edge Dev eine neue Registerkarte oder ein neues Fenster, und wechseln Sie zu
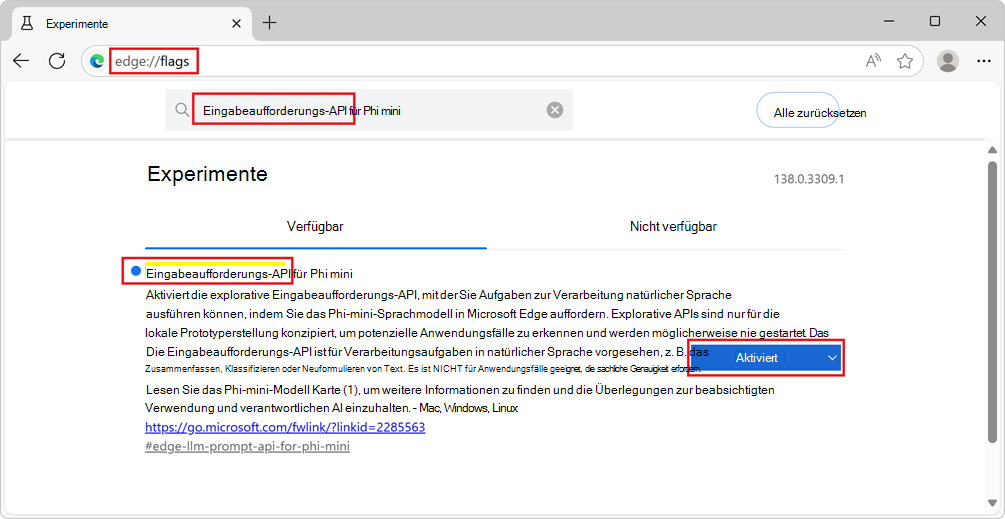
edge://flags/.Geben Sie oben auf der Seite in das Suchfeld Eingabeaufforderungs-API für das Sprachmodell auf dem Gerät ein.
Die Seite wird gefiltert, um das übereinstimmende Flag anzuzeigen.
Wählen Sie unter Eingabeaufforderungs-API für das Sprachmodell auf dem Gerätdie Option Aktiviert aus:
Wenn Sie informationen lokal protokollieren möchten, die für Debugprobleme nützlich sein können, aktivieren Sie optional auch das Flag Enable on device AI model debug logs (Auf Gerät aktivieren, KI-Modell debugprotokolle aktivieren).
Starten Sie Edge Canary oder Edge Dev neu.
Um zu überprüfen, ob Ihr Gerät die Hardwareanforderungen für die Vorschauversion der Eingabeaufforderungs-API erfüllt, öffnen Sie eine neue Registerkarte, wechseln Sie zu
edge://on-device-internals, und überprüfen Sie den Wert der Geräteleistungsklasse .Wenn ihre Geräteleistungsklasse hoch oder höher ist, sollte die Eingabeaufforderungs-API auf Ihrem Gerät unterstützt werden.
Wenn Ihre Geräteleistungsklasse mittel oder niedrig ist, wird die Eingabeaufforderungs-API nur über das Vorabversionsmodell Aion-1.0-Instruct unterstützt, das ab Edge-Version 150.0.4070 verfügbar ist. Informationen zum Testen des Aion-1.0-Instruct-Modells finden Sie oben unter Aktivieren von Aion-1.0-Instruct für die Eingabeaufforderungs-API.
Wenn Sie Probleme mit diesen Modellen feststellen, erstellen Sie ein neues Problem im MSEdgeExplainers-Repository.
Sehen Sie sich ein funktionierendes Beispiel an
So sehen Sie die Eingabeaufforderungs-API in Aktion und überprüfen vorhandenen Code, der die API verwendet:
Aktivieren Sie die Eingabeaufforderungs-API, wie oben beschrieben.
Öffnen Sie in Edge Canary oder Edge Dev eine Registerkarte oder ein Fenster, und wechseln Sie zum Playground für die Eingabeaufforderungs-API.
Im Navigationsbereich Integrierte KI-Playgrounds auf der linken Seite ist Die Eingabeaufforderung ausgewählt.
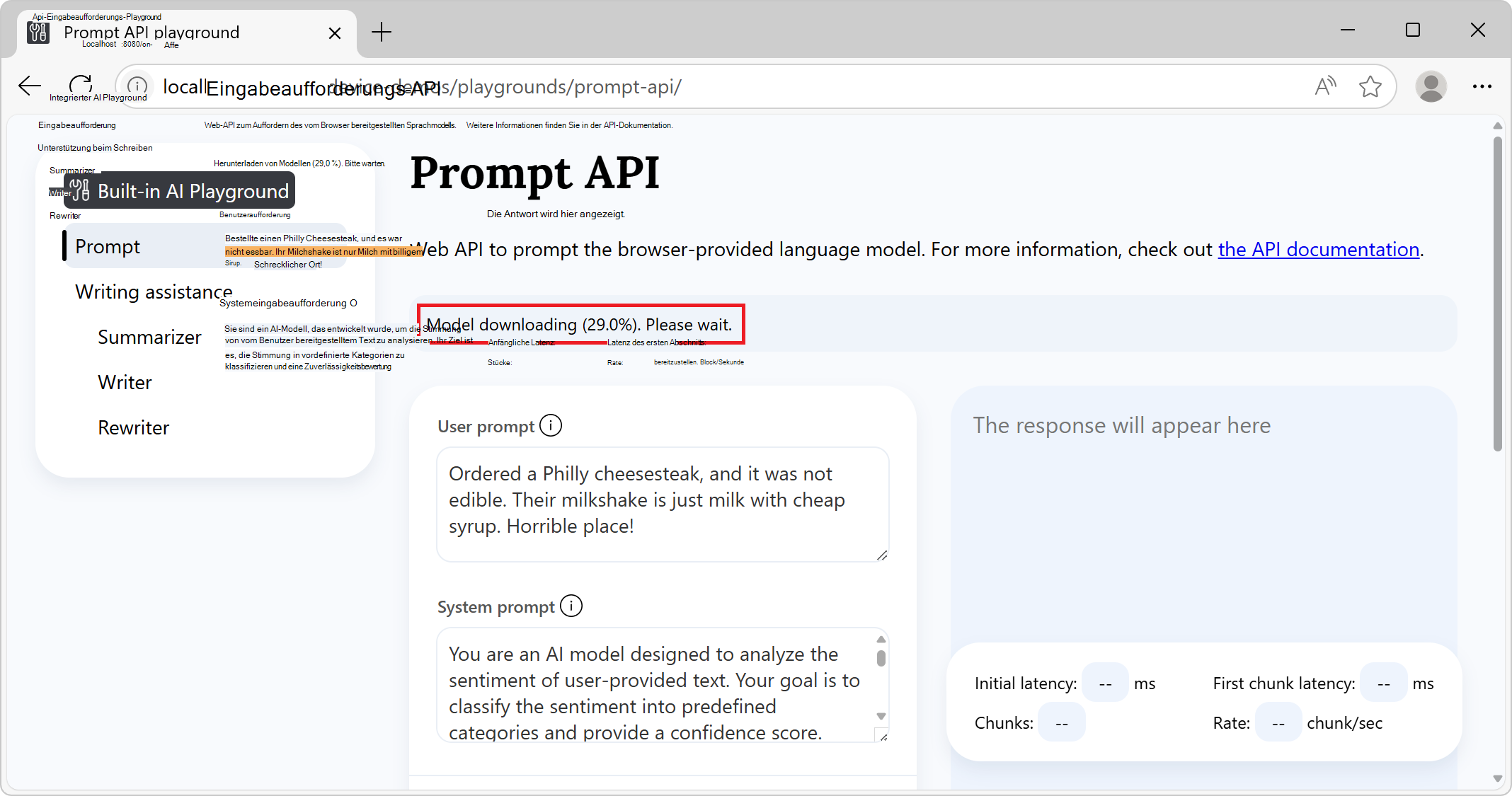
Überprüfen Sie im Informationsbanner oben die status: Zunächst heißt es Modelldownloading, bitte warten Sie:
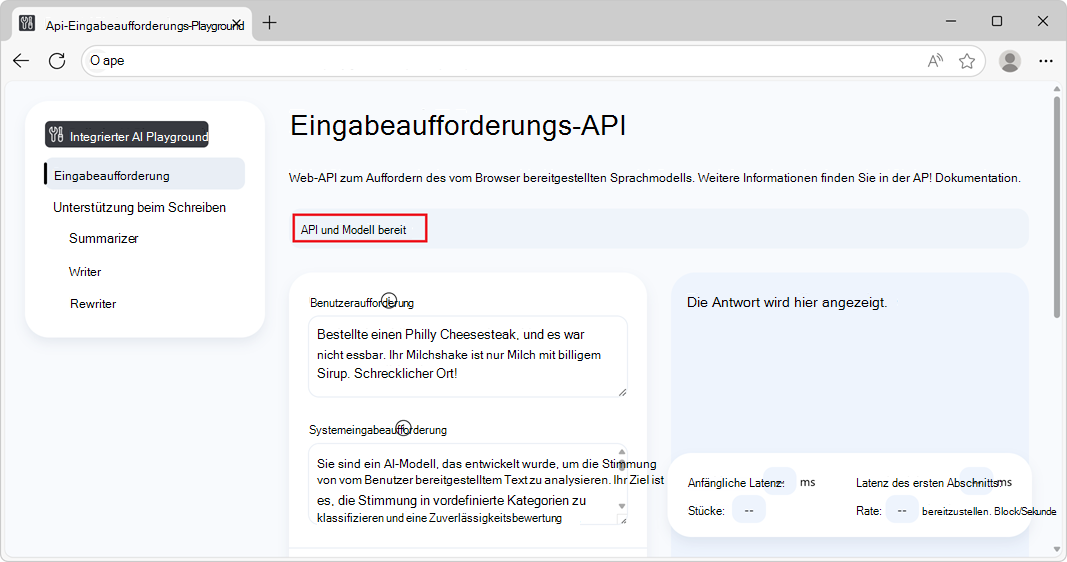
Nachdem das Modell heruntergeladen wurde, liest das Informationsbanner API und Modell bereit und gibt an, dass die API und das Modell verwendet werden können:
Wenn der Modelldownload nicht gestartet wird, starten Sie Microsoft Edge neu, und versuchen Sie es erneut.
Die Eingabeaufforderungs-API wird nur auf Geräten unterstützt, die bestimmte Hardwareanforderungen erfüllen. Weitere Informationen finden Sie weiter oben unter Hardwareanforderungen.
Ändern Sie optional die Werte für die Eingabeaufforderungseinstellungen, z. B.:
- Benutzeraufforderung
- Systemeingabeaufforderung
- Antworteinschränkungsschema
- Weitere Einstellungen>N-Shot-Eingabeaufforderungsanweisungen
Klicken Sie unten auf der Seite auf die Schaltfläche Eingabeaufforderung .
Die Antwort wird im Antwortabschnitt der Seite generiert:
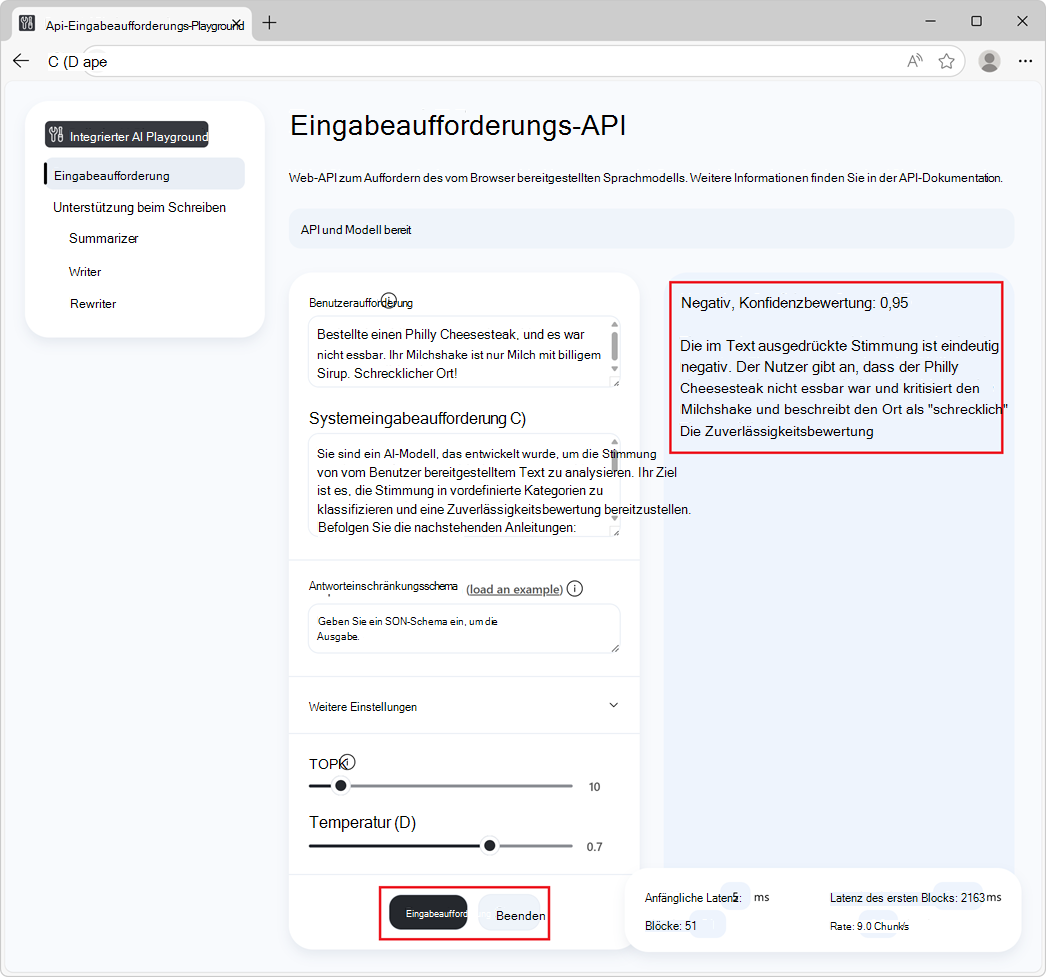
Um die Generierung der Antwort zu beenden, klicken Sie auf die Schaltfläche Beenden .
Siehe auch:
- /built-in-ai/ – Quellcode und Infodatei für integrierte KI-Playgrounds, einschließlich des Prompt-API-Playgrounds.
Verwenden der Eingabeaufforderungs-API
Überprüfen, ob die API aktiviert ist
Bevor Sie die API im Code Ihrer Website oder Erweiterung verwenden, überprüfen Sie, ob die API aktiviert ist, indem Sie das Vorhandensein des LanguageModel Objekts testen:
if (!LanguageModel) {
// The Prompt API is not available.
} else {
// The Prompt API is available.
}
Überprüfen, ob das Modell verwendet werden kann
Die Eingabeaufforderungs-API kann nur verwendet werden, wenn das Gerät die Ausführung des Modells unterstützt und nachdem das Sprachmodell und die Modellruntime von Microsoft Edge heruntergeladen wurden.
Verwenden Sie die -Methode, um zu überprüfen, ob die LanguageModel.availability() API verwendet werden kann:
const availability = await LanguageModel.availability();
if (availability == "unavailable") {
// The model is not available.
}
if (availability == "downloadable" || availability == "downloading") {
// The model can be used, but it needs to be downloaded first.
}
if (availability == "available") {
// The model is available and can be used.
}
Erstellen einer neuen Sitzung
Beim Erstellen einer Sitzung wird der Browser angewiesen, das Sprachmodell in den Arbeitsspeicher zu laden, damit es verwendet werden kann. Bevor Sie das Sprachmodell auffordern können, erstellen Sie mithilfe der create() -Methode eine neue Sitzung:
// Create a LanguageModel session.
const session = await LanguageModel.create();
Zum Anpassen der Modellsitzung können Sie Optionen an die create() -Methode übergeben:
// Create a LanguageModel session with options.
const session = await LanguageModel.create(options);
Folgende Optionen sind verfügbar:
monitor, um den Fortschritt des Modelldownloads zu verfolgen.initialPrompts, um dem Modell Kontext über die Eingabeaufforderungen zu geben, die an das Modell gesendet werden, und um ein Muster von Benutzer-/Assistent Interaktionen festzulegen, die das Modell für zukünftige Eingabeaufforderungen befolgen sollte.
Diese Optionen sind unten dokumentiert.
Überwachen des Fortschritts des Modelldownloads
Sie können den Fortschritt des Modelldownloads verfolgen, indem Sie die monitor Option verwenden. Dies ist nützlich, wenn das Modell noch nicht vollständig auf das Gerät heruntergeladen wurde, auf dem es verwendet wird, um die Benutzer Ihrer Website darüber zu informieren, dass sie warten sollten.
// Create a LanguageModel session with the monitor option to monitor the model
// download.
const session = await LanguageModel.create({
monitor: m => {
// Use the monitor object argument to add an listener for the
// downloadprogress event.
m.addEventListener("downloadprogress", event => {
// The event is an object with the loaded and total properties.
if (event.loaded == event.total) {
// The model is fully downloaded.
} else {
// The model is still downloading.
const percentageComplete = (event.loaded / event.total) * 100;
}
});
}
});
Bereitstellen einer Systemaufforderung für das Modell
Um eine Systemeingabeaufforderung zu definieren, die eine Möglichkeit darstellt, dem Modell Anweisungen zu geben, die beim Generieren von Text als Reaktion auf eine Eingabeaufforderung verwendet werden sollen, verwenden Sie die initialPrompts -Option.
Die Systemaufforderung, die Sie beim Erstellen einer neuen Sitzung angeben, wird für die gesamte Existenz der Sitzung beibehalten, auch wenn das Kontextfenster aufgrund zu vieler Eingabeaufforderungen überläuft.
// Create a LanguageModel session with a system prompt.
const session = await LanguageModel.create({
initialPrompts: [{
role: "system",
content: "You are a helpful assistant."
}]
});
Wenn Sie die { role: "system", content: "You are a helpful assistant." } Eingabeaufforderung an einer beliebigen Stelle an der 0. Position in initialPrompts platzieren, wird mit einem TypeErrorabgelehnt.
N-Shot-Eingabeaufforderung mit initialPrompts
Mit initialPrompts der Option können Sie auch Beispiele für Benutzer-/Assistent-Interaktionen bereitstellen, die das Modell weiterhin verwenden soll, wenn Sie dazu aufgefordert werden.
Diese Technik wird auch als N-Shot-Eingabeaufforderung bezeichnet und ist nützlich, um die vom Modell generierten Antworten deterministischer zu gestalten.
// Create a LanguageModel session with multiple initial prompts, for N-shot
// prompting.
const session = await LanguageModel.create({
initialPrompts: [
{ role: "system", content: "Classify the following product reviews as either OK or Not OK." },
{ role: "user", content: "Great shoes! I was surprised at how comfortable these boots are for the price. They fit well and are very lightweight." },
{ role: "assistant", content: "OK" },
{ role: "user", content: "Terrible product. The manufacturer must be completely incompetent." },
{ role: "assistant", content: "Not OK" },
{ role: "user", content: "Could be better. Nice quality overall, but for the price I was expecting something more waterproof" },
{ role: "assistant", content: "OK" }
]
});
Klonen einer Sitzung, um die Konversation mit den gleichen Optionen erneut zu starten
Klonen Sie eine vorhandene Sitzung, um das Modell ohne die Kenntnisse aus den vorherigen Interaktionen, aber mit den gleichen Sitzungsoptionen aufzufordern.
Das Klonen einer Sitzung ist nützlich, wenn Sie die Optionen aus einer vorherigen Sitzung verwenden möchten, ohne das Modell mit vorherigen Antworten zu beeinflussen.
// Create a first LanguageModel session.
const firstSession = await LanguageModel.create({
initialPrompts: [
role: "system",
content: "You are a helpful assistant."
]
});
// Later, create a new session by cloning the first session to start a new
// conversation with the model, but preserve the first session's settings.
const secondSession = await firstSession.clone();
Eingabeaufforderung für das Modell
Verwenden Sie nach dem Erstellen einer Modellsitzung die -Methode oder session.promptStreaming() die -Methode, um das session.prompt() Modell aufzufordern.
Warten Auf die endgültige Antwort
Die prompt -Methode gibt eine Zusage zurück, die aufgelöst wird, sobald das Modell die Textgenerierung als Reaktion auf Ihre Eingabeaufforderung abgeschlossen hat:
// Create a LanguageModel session.
const session = await LanguageModel.create();
// Prompt the model and wait for the response to be generated.
const result = await session.prompt(promptString);
// Use the generated text.
console.log(result);
Anzeigen von Token beim Generieren
Die promptStreaming -Methode gibt sofort ein Datenstromobjekt zurück. Verwenden Sie den Stream, um die Antworttoken anzuzeigen, während sie generiert werden:
// Create a LanguageModel session.
const session = await LanguageModel.create();
// Prompt the model.
const stream = session.promptStreaming(myPromptString);
// Use the stream object to display tokens that are generated by the model, as
// they are being generated.
for await (const chunk of stream) {
console.log(chunk);
}
Sie können die prompt Methoden und promptStreaming mehrmals innerhalb desselben Sitzungsobjekts aufrufen, um weiterhin Text zu generieren, der auf vorherigen Interaktionen mit dem Modell innerhalb dieser Sitzung basiert.
Einschränken der Modellausgabe mithilfe eines JSON-Schemas oder eines regulären Ausdrucks
Um das Format der Modellantworten deterministischer und programmgesteuerter zu verwenden, verwenden Sie die responseConstraint Option, wenn Sie das Modell auffordern.
Die responseConstraint Option akzeptiert ein JSON-Schema oder einen regulären Ausdruck:
Damit das Modell mit einem json-Objekt mit Zeichenfolgen reagiert, das einem bestimmten Schema folgt, legen Sie auf das json-Schema fest
responseConstraint, das Sie verwenden möchten.Damit das Modell mit einer Zeichenfolge antwortet, die einem regulären Ausdruck entspricht, legen Sie auf diesen regulären Ausdruck fest
responseConstraint.
Das folgende Beispiel zeigt, wie das Modell auf eine Eingabeaufforderung mit einem JSON-Objekt reagiert, das einem bestimmten Schema folgt:
// Create a LanguageModel session.
const session = await LanguageModel.create();
// Define a JSON schema for the Prompt API to constrain the generated response.
const schema = {
"type": "object",
"required": ["sentiment", "confidence"],
"additionalProperties": false,
"properties": {
"sentiment": {
"type": "string",
"enum": ["positive", "negative", "neutral"],
"description": "The sentiment classification of the input text."
},
"confidence": {
"type": "number",
"minimum": 0,
"maximum": 1,
"description": "A confidence score indicating certainty of the sentiment classification."
}
}
}
;
// Prompt the model, by providing a system prompt and the JSON schema in the
// responseConstraints option.
const response = await session.prompt(
"Ordered a Philly cheesesteak, and it was not edible. Their milkshake is just milk with cheap syrup. Horrible place!",
{
initialPrompts: [
{
role: "system",
content: "You are an AI model designed to analyze the sentiment of user-provided text. Your goal is to classify the sentiment into predefined categories and provide a confidence score. Follow these guidelines:\n\n- Identify whether the sentiment is positive, negative, or neutral.\n- Provide a confidence score (0-1) reflecting the certainty of the classification.\n- Ensure the sentiment classification is contextually accurate.\n- If the sentiment is unclear or highly ambiguous, default to neutral.\n\nYour responses should be structured and concise, adhering to the defined output schema."
},
],
responseConstraint: schema
}
);
Das Ausführen des obigen Codes gibt eine Antwort zurück, die ein zeichenfolgenisiertes JSON-Objekt enthält, z. B.:
{"sentiment": "negative", "confidence": 0.95}
Anschließend können Sie die Antwort in Ihrer Codelogik verwenden, indem Sie sie mithilfe der JSON.parse() -Funktion analysieren:
// Parse the JSON string generated by the model and extract the sentiment and
// confidence values.
const { sentiment, confidence } = JSON.parse(response);
// Use the values.
console.log(`Sentiment: ${sentiment}`);
console.log(`Confidence: ${confidence}`);
Senden mehrerer Nachrichten pro Eingabeaufforderung
Zusätzlich zu Zeichenfolgen akzeptieren die prompt Methoden und promptStreaming auch ein Array von Objekten, das zum Senden mehrerer Nachrichten mit benutzerdefinierten Rollen verwendet wird. Die von Ihnen gesendeten Objekte sollten im Format { role, content }vorliegen, wobei role entweder user oder ist assistantund content die Nachricht ist.
Um beispielsweise mehrere Benutzernachrichten und eine Assistent Nachricht in derselben Eingabeaufforderung bereitzustellen:
// Create a LanguageModel session.
const session = await LanguageModel.create();
// Prompt the model by sending multiple messages at once.
const result = await session.prompt([
{ role: "user", content: "First user message" },
{ role: "user", content: "Second user message" },
{ role: "assistant", content: "The assistant message" }
]);
Beenden der Textgenerierung
Um eine Eingabeaufforderung abzubrechen, bevor die von session.prompt() zurückgegebene Zusage aufgelöst wurde oder bevor der von session.promptStreaming() zurückgegebene Stream beendet wurde, verwenden Sie ein AbortController Signal:
// Create a LanguageModel session.
const session = await LanguageModel.create();
// Create an AbortController object.
const abortController = new AbortController();
// Prompt the model by passing the AbortController object by using the signal
// option.
const stream = session.promptStreaming(myPromptString , {
signal: abortController.signal
});
// Later, perhaps when the user presses a "Stop" button, call the abort()
// method on the AbortController object to stop generating text.
abortController.abort();
Zerstören einer Sitzung
Löschen Sie die Sitzung, um dem Browser mitzuteilen, dass Sie das Sprachmodell nicht mehr benötigen, damit das Modell aus dem Arbeitsspeicher entladen werden kann.
Sie können eine Sitzung auf zwei verschiedene Arten zerstören:
- Mithilfe der
destroy()-Methode. - Mithilfe von
AbortController.
Zerstören einer Sitzung mithilfe der destroy()-Methode
// Create a LanguageModel session.
const session = await LanguageModel.create();
// Later, destroy the session by using the destroy method.
session.destroy();
Zerstören einer Sitzung mithilfe eines AbortControllers
// Create an AbortController object.
const controller = new AbortController();
// Create a LanguageModel session and pass the AbortController object by using
// the signal option.
const session = await LanguageModel.create({ signal: controller.signal });
// Later, perhaps when the user interacts with the UI, destroy the session by
// calling the abort() function of the AbortController object.
controller.abort();
Feedback senden
Die Vorschau der Eingabeaufforderungs-API für Entwickler soll ihnen helfen, Anwendungsfälle für vom Browser bereitgestellte Sprachmodelle zu ermitteln.
Wir sind daran interessiert, mehr über Folgendes zu erfahren:
- Der Bereich der Szenarien, für die Sie die Eingabeaufforderungs-API verwenden möchten.
- Alle Probleme mit der Eingabeaufforderungs-API.
- Alle Probleme mit den Sprachmodellen.
- Gibt an, ob neue aufgabenspezifische APIs nützlich wären.
Um Feedback zu Ihren Szenarien und den Aufgaben zu senden, die Sie ausführen möchten, fügen Sie dem Problem Api-Feedback einfordern einen Kommentar hinzu.
Wenn Sie probleme bei der Verwendung der API feststellen, melden Sie dies im Repository.
Sie können auch an der Diskussion über den Entwurf der Eingabeaufforderungs-API im W3C Web Machine Learning Working Group-Repository mitwirken.
Siehe auch
- Spezifikation des API-Entwurfs eingabeaufforderung
- webmachinelearning/prompt-api GitHub-Repository
- Schreiben, Umschreiben und Zusammenfassen von Text mit den Schreibunterstützungs-APIs
- Korrigieren von Grammatik-, Rechtschreib- und Interpunktionsfehlern in Text mit der Korrekturlese-API
- Übersetzen von Text mit der Übersetzer-API
- /built-in-ai/ – Quellcode und Infodatei für integrierte KI-Playgrounds, einschließlich des Prompt-API-Playgrounds.